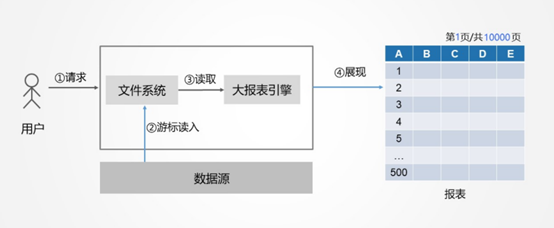
怎樣提高報表呈現(xiàn)的性能

開源 SPL 提速保險公司團保明細(xì)單查詢 2000+ 倍
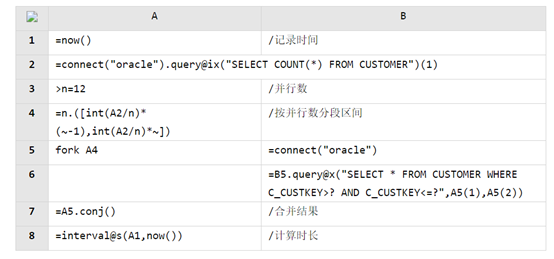

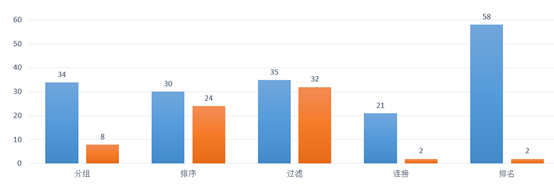
報表內(nèi)計算和呈現(xiàn)

感興趣的小伙伴,請識別右側(cè)二維碼與我們聯(lián)系
微信號|RUNQIAN_RAQSOFT
評論
圖片
表情
<b id="afajh"><abbr id="afajh"></abbr></b>
 下載APP
下載APP
開源 SPL 提速保險公司團保明細(xì)單查詢 2000+ 倍
感興趣的小伙伴,請識別右側(cè)二維碼與我們聯(lián)系
微信號|RUNQIAN_RAQSOFT
<b id="afajh"><abbr id="afajh"></abbr></b>