
滴滴把Hive SQL遷移Spark SQL了!

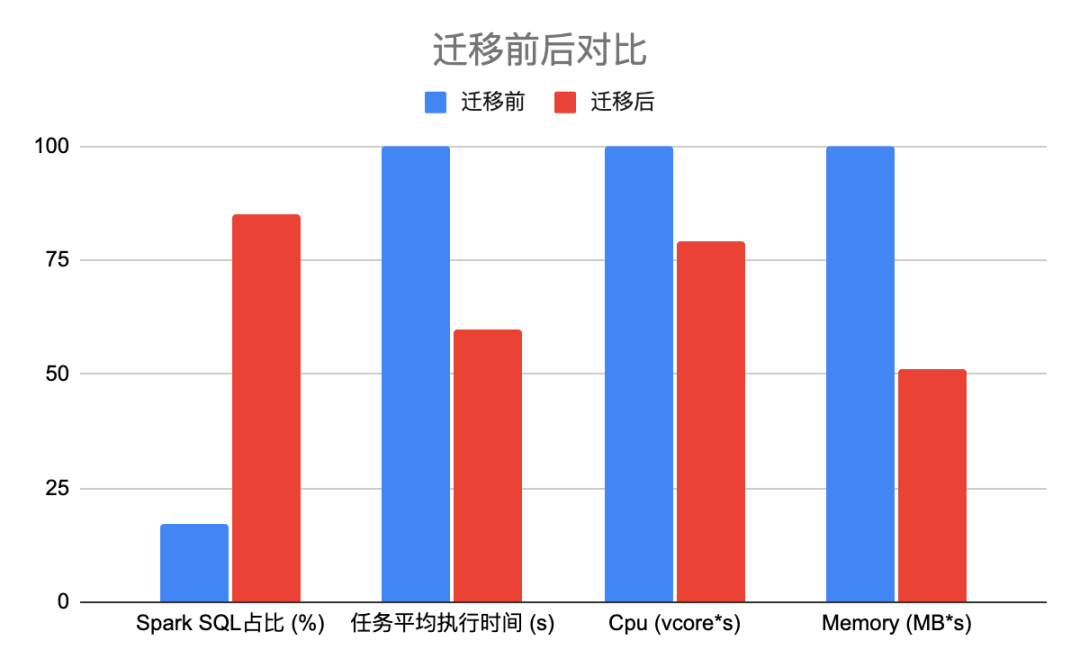
桔妹導(dǎo)讀:在滴滴SQL任務(wù)從Hive遷移到Spark后,Spark SQL任務(wù)占比提升至85%,任務(wù)運(yùn)行時(shí)間節(jié)省40%,運(yùn)行任務(wù)需要的計(jì)算資源節(jié)省21%,內(nèi)存資源節(jié)省49%。在遷移過(guò)程中我們沉淀出一套遷移流程, 并且發(fā)現(xiàn)并解決了兩個(gè)引擎在語(yǔ)法,UDF,性能和功能方面的差異。

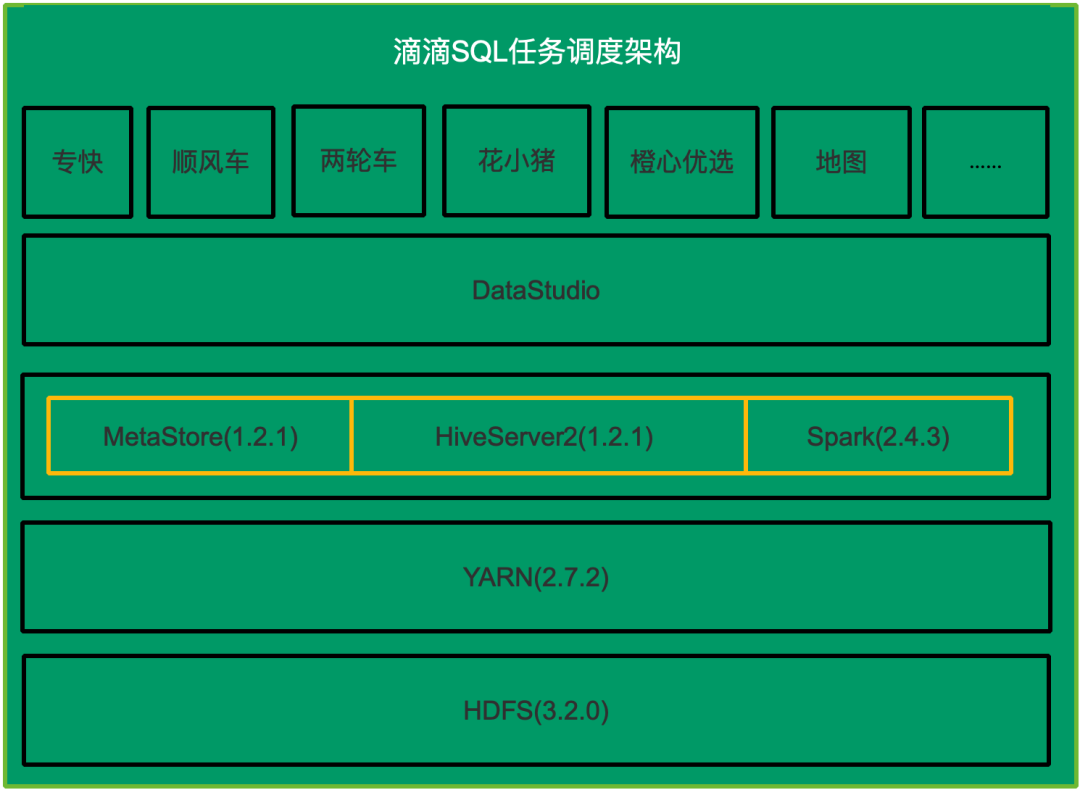
在遷移之前我們面臨的主要問(wèn)題有:
SQL任務(wù)運(yùn)行慢:遷移前SQL任務(wù)運(yùn)行的平均時(shí)間是20分鐘,主要原因是占比高達(dá)83%的Hive SQL任務(wù)運(yùn)行時(shí)間長(zhǎng),Hive任務(wù)執(zhí)行過(guò)程中會(huì)啟動(dòng)多個(gè)MR Job,Job間的中間結(jié)果存儲(chǔ)在HDFS,所以同一個(gè)SQL, Hive比Spark執(zhí)行的時(shí)間更長(zhǎng);
Hive SQL穩(wěn)定性差:一個(gè)HS2會(huì)同時(shí)執(zhí)行多個(gè)用戶的Hive SQL任務(wù),當(dāng)一個(gè)異常任務(wù)導(dǎo)致HS2進(jìn)程響應(yīng)慢甚至異常退出時(shí),運(yùn)行在同一個(gè)實(shí)例的SQL任務(wù)也會(huì)運(yùn)行緩慢甚至失敗。而異常任務(wù)場(chǎng)景各異。我們?cè)?jīng)遇到的異常任務(wù)有多個(gè)大SQL加載過(guò)多的分區(qū)元數(shù)據(jù)導(dǎo)致HS2 FullGC,加載UDF時(shí)導(dǎo)致HS2進(jìn)程core dump,UDF訪問(wèn)HDFS沒(méi)有關(guān)閉流導(dǎo)致HS2機(jī)器端口被打滿,這些沒(méi)有通用解法, 問(wèn)題很難收斂;
人力分散:兩個(gè)引擎需要投入雙倍的人力,在人員有限的情況下,對(duì)引擎的掌控力會(huì)減弱;
所以為了SQL任務(wù)運(yùn)行更快,更穩(wěn),團(tuán)隊(duì)人力聚焦,對(duì)引擎有更強(qiáng)的掌控力,我們決定把Hive SQL遷移到Spark SQL。
Hive SQL遷移到Spark SQL后需滿足以下條件:
保證數(shù)據(jù)一致性,也就是相同的SQL使用Spark和Hive執(zhí)行的結(jié)果應(yīng)該是一樣的; 保證用戶有收益,也就是使用Spark執(zhí)行SQL后應(yīng)該節(jié)省資源,包括時(shí)間,cpu和memroy; 遷移過(guò)程對(duì)用戶透明;
為了滿足以上三個(gè)條件, 一個(gè)很直觀的思路就是使用兩個(gè)引擎執(zhí)行用戶SQL,然后對(duì)比每個(gè)引擎的執(zhí)行結(jié)果和資源消耗。?
為了不影響用戶線上數(shù)據(jù),使用兩個(gè)引擎執(zhí)行用戶SQL有兩個(gè)可選方案:
復(fù)用現(xiàn)有的SQL任務(wù)調(diào)度系統(tǒng),再部署一套SQL任務(wù)調(diào)度系統(tǒng)用來(lái)遷移,這個(gè)系統(tǒng)與生產(chǎn)環(huán)境物理隔離;
開發(fā)一個(gè)SQL雙跑工具,可以支持使用兩個(gè)引擎執(zhí)行同一個(gè)SQL任務(wù);
下面詳細(xì)介紹這兩個(gè)方案:
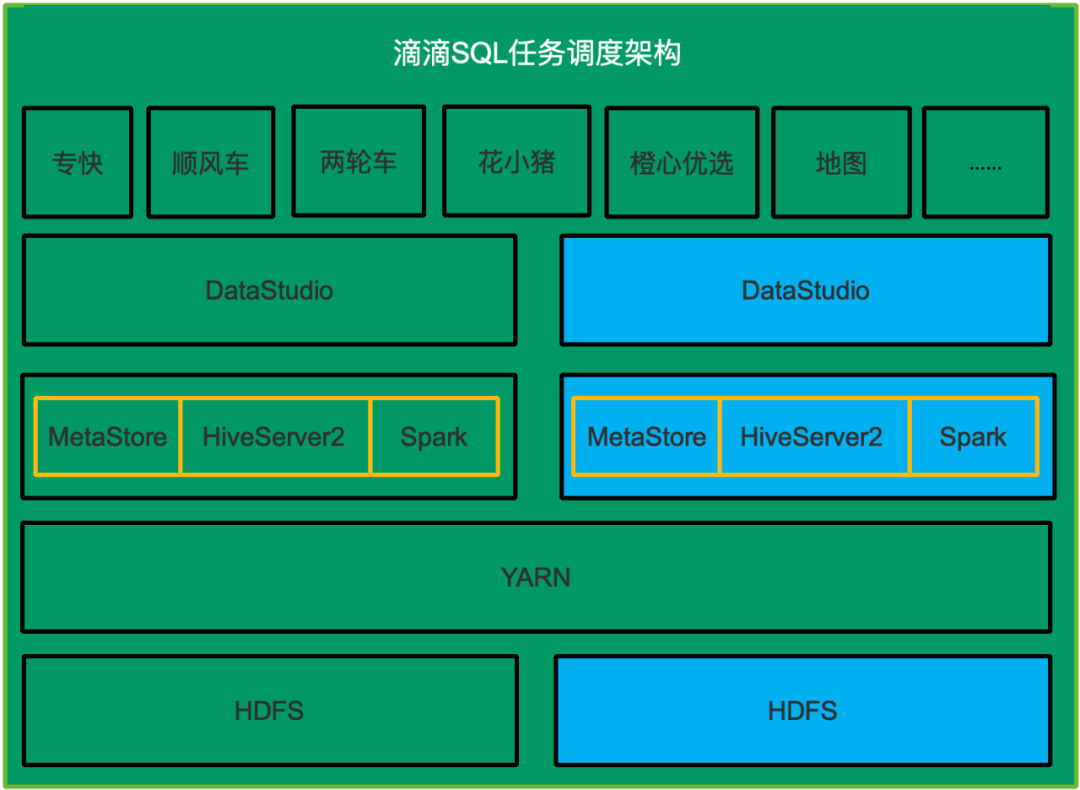
▍1. 方案一:復(fù)用現(xiàn)有的SQL任務(wù)調(diào)度系統(tǒng)
再部署一套SQL任務(wù)執(zhí)行系統(tǒng)用來(lái)使用Spark執(zhí)行所有的SQL,包括HDFS,HiveServer2&MetaStore和Spark,DataStudio。新部署的系統(tǒng)需要周期性從生產(chǎn)環(huán)境同步任務(wù)信息,元數(shù)據(jù)信息和HDFS數(shù)據(jù),在這個(gè)新部署的系統(tǒng)中把Hive SQL任務(wù)改成Spark SQL類型任務(wù),這樣一個(gè)用戶的SQL在原有系統(tǒng)中使用Hive SQL執(zhí)行,在新部署的系統(tǒng)中使用Spark執(zhí)行。如下圖所示,藍(lán)色的表示需要新部署的子系統(tǒng)。
▍2. 方案二:開發(fā)一個(gè)SQL雙跑工具
SQL收集:用戶的SQL是在HS2上執(zhí)行的,所以理論上通過(guò)HS2可以收集到所有的SQL;
SQL改寫:執(zhí)行用戶原始SQL會(huì)覆蓋線上數(shù)據(jù),所以在執(zhí)行前需要改寫SQL,把SQL的輸出的庫(kù)表名替換為用來(lái)遷移測(cè)試的的庫(kù)表名;
SQL雙跑:分別使用Hive和Spark執(zhí)行改寫后的SQL;
▍3. 方案對(duì)比
方案一
優(yōu)勢(shì)
隔離性好,單獨(dú)的SQL執(zhí)行系統(tǒng)不會(huì)影響生產(chǎn)任務(wù),也不會(huì)影響業(yè)務(wù)數(shù)據(jù);
劣勢(shì)
需要的資源多:運(yùn)行多個(gè)子系統(tǒng)需要較多物理資源;
部署復(fù)雜:部署多個(gè)子系統(tǒng),需要多個(gè)不同的團(tuán)隊(duì)相互配合;
容易出錯(cuò):子系統(tǒng)間需要周期性同步,任何一個(gè)子系統(tǒng)同步出問(wèn)題,都可能導(dǎo)致執(zhí)行SQL失敗;
方案二
優(yōu)勢(shì)
非常輕量,不需要部署很多系統(tǒng),而且對(duì)物理資源需要不高;
劣勢(shì)
與生產(chǎn)公共一套環(huán)境,回放時(shí)有影響用戶數(shù)據(jù)對(duì)風(fēng)險(xiǎn);
需要開發(fā)SQL收集,SQL改寫和SQL雙跑系統(tǒng);
通過(guò)HiveServer收集所有SQL,SQL改寫和SQL雙跑邏輯清晰,開發(fā)成本可控;
創(chuàng)建超讀帳號(hào),對(duì)所有庫(kù)表有讀權(quán)限,但只對(duì)用戶遷移的測(cè)試庫(kù)有寫權(quán)限,可以避免影響用戶數(shù)據(jù)的風(fēng)險(xiǎn);
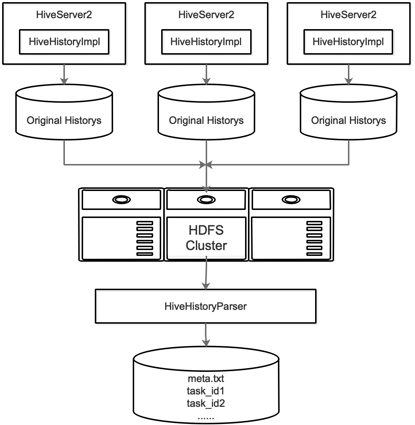
Hive SQL提取包括以下步驟:
改造HiveHistoryImpl,每個(gè)session內(nèi)執(zhí)行的所有SQL和command保存到HiveServer2的一個(gè)本地文件中,這些文件按天組織,每天一個(gè)目錄
定時(shí)將前一天的History目錄上傳到hdfs
開發(fā)HiveHistoryParser
HiveHistoryParser的主要功能是:
每天從HDFS下載所有HiveServer2的History文件;
SQL去重:DataStudio上的一個(gè)SQL任務(wù)可能一天執(zhí)行多次(比如小時(shí)任務(wù)),任務(wù)執(zhí)行一次會(huì)生成一個(gè)新的執(zhí)行Id,只保留一天中最大的執(zhí)行Id的SQL;
合并SQL:一個(gè)shell任務(wù)可能建立多個(gè)session執(zhí)行SQL,為了后面遷移shell任務(wù),需要把多個(gè)session的SQL合并到一起;
輸出Parse結(jié)果:包括多個(gè)SQL文件和meta文件:
每個(gè)任務(wù)執(zhí)行的SQL保存到一個(gè)文件中,文件名是任務(wù)名稱加執(zhí)行Id,我們稱作原始SQL文件;
meta文件包含SQL文件路徑,任務(wù)名稱,項(xiàng)目名稱,用戶名;
SQL改寫會(huì)對(duì)上一步生成的每個(gè)原始SQL文件執(zhí)行以下步驟:
使用Spark的SessionState對(duì)SQL文件逐行分析,識(shí)別是否包含以下兩類子句:
insert overwrite into
create table as select
如果包含上面的兩類子句,則提取寫入的目標(biāo)庫(kù)表名稱;
在測(cè)試庫(kù)中創(chuàng)建與目標(biāo)庫(kù)表schema完全一致的兩個(gè)測(cè)試表;
分別使用上一步創(chuàng)建的測(cè)試庫(kù)表替換原始SQL文件中的庫(kù)表名生成用于回放的SQL文件,一個(gè)原始SQL文件改寫后會(huì)生成兩個(gè)SQL文件,用于后面兩個(gè)引擎分別執(zhí)行;
SQL雙跑步驟如下:
并發(fā)的使用Spark和Hive執(zhí)行上一步生成的兩個(gè)SQL文件;
記錄使用兩種引擎執(zhí)行SQL時(shí)啟動(dòng)的Application和運(yùn)行時(shí)間;
輸出回放結(jié)果到文件中,執(zhí)行每個(gè)SQL文件對(duì)會(huì)生成一條結(jié)果記錄, 包括Hive 和Spark 執(zhí)行SQL的時(shí)間,啟動(dòng)的Application列表,和輸出的目標(biāo)庫(kù)表名稱等,?如下圖所示:

結(jié)果對(duì)比時(shí)會(huì)遍歷每個(gè)回放記錄,統(tǒng)計(jì)以下指標(biāo):
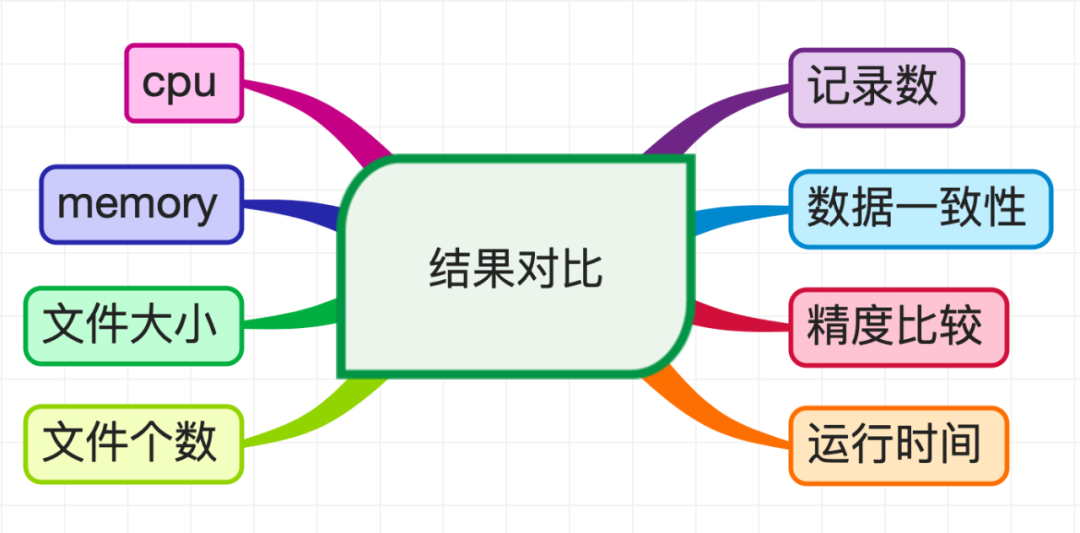
具體流程如下:
查詢Spark SQL和Hive SQL輸出的庫(kù)表的記錄數(shù);
查詢兩種引擎輸出的HDFS文件個(gè)數(shù)和大小;
對(duì)比兩種引擎的輸出數(shù)據(jù);
分別對(duì)Spark和Hive的產(chǎn)出表執(zhí)行以下SQL,獲取表的概要信息
比較兩張表的概要信息:
如果所有對(duì)應(yīng)列的值相同則認(rèn)為結(jié)果一致;
如果存在不一致的列,如果該列是數(shù)值類型,則對(duì)該列計(jì)算最大精度差異, SQL如下:
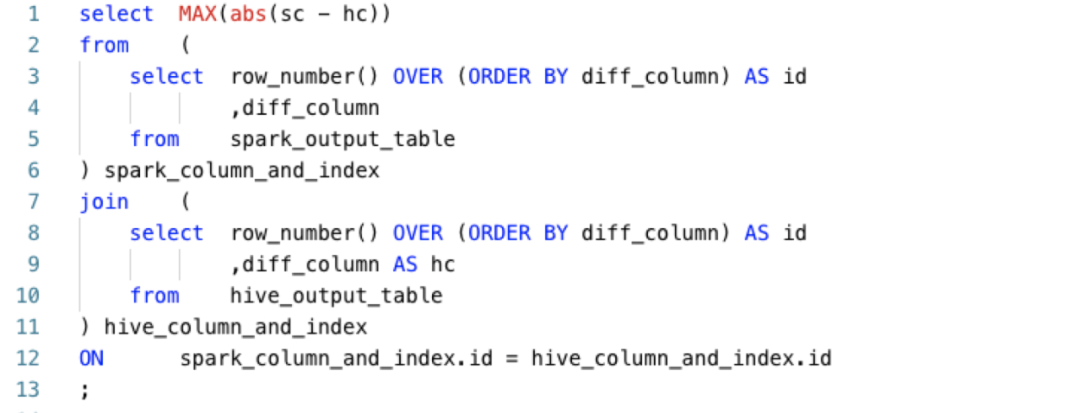
統(tǒng)計(jì)兩種引擎啟動(dòng)的Application消耗的vcore和memory資源;
輸出對(duì)比結(jié)果, 包括運(yùn)行時(shí)間, 消耗的vcore和memory,是否一致,如果不一致輸出不一致的列名以及最大差異;
匯總數(shù)據(jù)結(jié)果,并對(duì)回放的SQL分為以下幾類:
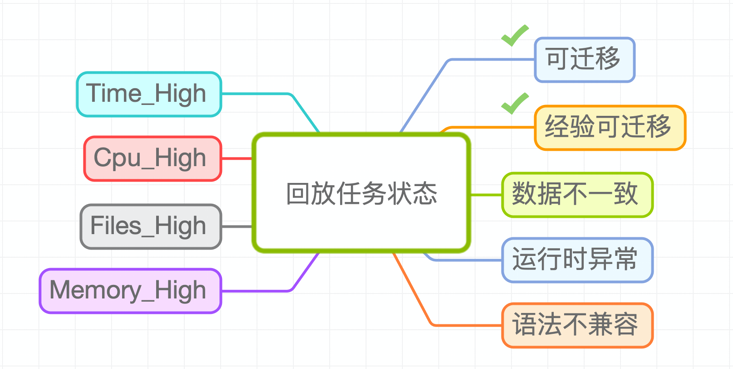
可遷移:數(shù)據(jù)完全一致, 并且使用Spark SQL執(zhí)行使用更少資源,包括運(yùn)行時(shí)間,vcore和memory以及文件數(shù);
經(jīng)驗(yàn)可遷移:在排查不一致時(shí)發(fā)現(xiàn)有些是邏輯正確的 (比如collect_set結(jié)果順序不一致),如果有些任務(wù)符合這些經(jīng)驗(yàn),則認(rèn)為是經(jīng)驗(yàn)可遷移;
數(shù)據(jù)不一致:兩種引擎產(chǎn)出的結(jié)果存在不一致的列,而且沒(méi)有命中經(jīng)驗(yàn);
Time_High:兩種引擎產(chǎn)出的結(jié)果完全一致,但是Spark執(zhí)行SQL的運(yùn)行時(shí)間大于Hive執(zhí)行SQL的時(shí)間;
Cpu_High:兩種引擎產(chǎn)出的結(jié)果完全一致,但是Spark執(zhí)行SQL消耗的cpu資源大于Hive執(zhí)行SQL消耗的cpu資源;
Memory_High:兩種引擎產(chǎn)出的結(jié)果完全一致,但是Spark執(zhí)行SQL消耗的memory資源大于Hive執(zhí)行SQL消耗的memory資源;
Files_High:兩種引擎產(chǎn)出的結(jié)果完全一致,但是Spark執(zhí)行SQL產(chǎn)生的文件數(shù)大于Hive執(zhí)行SQL產(chǎn)生的文件數(shù);
語(yǔ)法不兼容:在SQL改寫階段解析SQL時(shí)報(bào)語(yǔ)法錯(cuò)誤;
運(yùn)行時(shí)異常:在雙跑階段,Hive SQL或者Spark SQL在運(yùn)行過(guò)程中失敗;
▍4. 遷移
遷移比較簡(jiǎn)單, 步驟如下:
整理遷移任務(wù)列表以及對(duì)應(yīng)的配置參數(shù);
調(diào)用DataStudio接口把任務(wù)類型修改為SparkSQL類型;
重跑任務(wù);
▍5. 問(wèn)題排查&修復(fù)
如果SQL是“可遷移”或者“經(jīng)驗(yàn)可遷移”,可以執(zhí)行遷移,其它的任務(wù)需要排查,這部分是最耗時(shí)耗力的,遷移過(guò)程中大部分時(shí)間都是在調(diào)查和修復(fù)這些問(wèn)題。修復(fù)之后再執(zhí)行從頭開始,提取最新任務(wù)的SQL,然后SQL改寫和雙跑,結(jié)果對(duì)比,滿足遷移條件則說(shuō)明修復(fù)了問(wèn)題,可以遷移,否則繼續(xù)排查,因此遷移過(guò)程是一個(gè)循環(huán)往復(fù)的過(guò)程,直到SQL滿足遷移條件,整體過(guò)程如下圖所示:
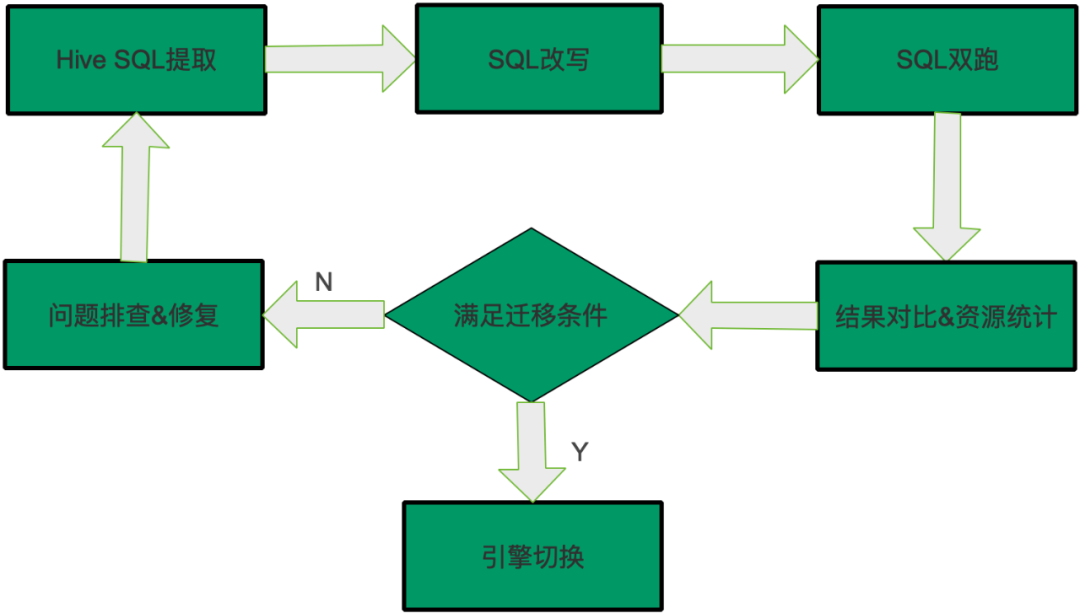
在遷移的過(guò)程中我們發(fā)現(xiàn)了很多兩種引擎不同的地方,主要包括語(yǔ)法差異,UDF差異,功能差異和性能差異。
▍1. 語(yǔ)法差異
有些Hive SQL使用Spark SQL執(zhí)行在語(yǔ)法分析階段就會(huì)出錯(cuò),有些語(yǔ)法差異我們?cè)趦?nèi)部版本已經(jīng)修復(fù),目前正在反饋社區(qū),正在和社區(qū)討論,還有一些目前沒(méi)有修復(fù)。
1.1?用例設(shè)計(jì)
UDTF新版initialize接口支持,對(duì)齊Hive SQL? [SPARK-33704]
Window Function 不支持沒(méi)有order by子句的場(chǎng)景
Join 子查詢支持rand 隨機(jī)分布條件,增強(qiáng)語(yǔ)法兼容
Orc/Orcfile 存儲(chǔ)類型創(chuàng)建語(yǔ)句屏蔽ROW FORMAT DELIMITED限制 [SPARK-33755]
`DB.TB` 識(shí)別支持,對(duì)齊Hive SQL [SPARK-33686]
支持CREATE TEMPORARY TABLE
各類Hive UDF的支持調(diào)用,主要包括get_json_object,datediff,unix_timestamp,to_date,collect_set,date_sub? [SPARK-33721]
DROP不存在的表和分區(qū),Spark SQL報(bào)錯(cuò),Hive SQL 正常? [SPARK-33637]
刪除分區(qū)時(shí)支持設(shè)置過(guò)濾條件 [SPARK-33691]
1.2?未修復(fù)
Map類型字段不支持GROUP BY操作
Operation not allowed:ALTER TABLE CONCATENATE
▍2.?UDF差異
在排查數(shù)據(jù)不一致的SQL過(guò)程中,我們發(fā)現(xiàn)有些是因?yàn)檩斎霐?shù)據(jù)的順序不同造成的, 這些差異邏輯上是正確的,而有些是UDF對(duì)異常值的處理方式不一致造成的,還有需要注意的是UDF執(zhí)行環(huán)境不同造成的結(jié)果差異。
2.1?順序差異
這些因?yàn)檩斎霐?shù)據(jù)的順序不同造成的結(jié)果差異邏輯上是一致的,對(duì)業(yè)務(wù)無(wú)影響,因此在遷移過(guò)程中可以忽略這些差異,這類差異的SQL任務(wù)屬于經(jīng)驗(yàn)可遷移。
2.1.1?collect_set
假設(shè)數(shù)據(jù)表如下:
執(zhí)行如下SQL:
執(zhí)行結(jié)果:
差異說(shuō)明:
collect_set執(zhí)行結(jié)果的順序取決于記錄被掃描的順序,Spark SQL執(zhí)行過(guò)程中是多個(gè)任務(wù)并發(fā)執(zhí)行的,因此記錄被讀取的順序是無(wú)法保證的.
假設(shè)數(shù)據(jù)表如下:
執(zhí)行如下SQL:
執(zhí)行結(jié)果:
差異說(shuō)明:
collect_list執(zhí)行結(jié)果的順序取決于記錄被掃描的順序,Spark SQL執(zhí)行過(guò)程中是多個(gè)任務(wù)并發(fā)執(zhí)行的,因此記錄被讀取的順序是無(wú)法保證的。
假設(shè)數(shù)據(jù)表如下:
執(zhí)行如下SQL:
執(zhí)行結(jié)果:
差異說(shuō)明:
數(shù)據(jù)表建表語(yǔ)句:
假設(shè)數(shù)據(jù)表如下:
執(zhí)行如下SQL:
執(zhí)行結(jié)果:
差異說(shuō)明:
Map類型是無(wú)序的,同一份數(shù)據(jù),在query時(shí)顯示的各個(gè)key的順序會(huì)有變化。
2.1.5?sum(double/float)
假設(shè)數(shù)據(jù)表如下:
執(zhí)行如下SQL:
執(zhí)行結(jié)果:
差異說(shuō)明:
這是由float/double類型的表示方式?jīng)Q定的,浮點(diǎn)數(shù)不能表示所有的實(shí)數(shù),在執(zhí)行運(yùn)算過(guò)程中會(huì)有精度丟失,對(duì)于幾個(gè)浮點(diǎn)數(shù),執(zhí)行加法時(shí)的順序不同,結(jié)果有時(shí)就會(huì)不同。

對(duì)于24點(diǎn)Spark認(rèn)為是非法的返回NULL,而Hive任務(wù)是正常的,下表時(shí)執(zhí)行unix_timestamp(concat('2020-06-01', ' 24:00:00'))時(shí)的差異。
當(dāng)月或者日是00時(shí)Hive仍然會(huì)返回一個(gè)日期,但是Spark會(huì)返回NULL。
這些差異是是因?yàn)閷?duì)異常UDF參數(shù)的處理邏輯不同造成的,雖然Spark SQL返回NULL更合理,但是現(xiàn)有的Hive SQL任務(wù)用戶適應(yīng)了這種處理邏輯,所以為了不影響現(xiàn)有SQL任務(wù),我們對(duì)這類UDF做了兼容處理,用戶可以通過(guò)配置來(lái)決定使用Hive內(nèi)置函數(shù)還是Spark的內(nèi)置UDF。
2.3?UDF執(zhí)行環(huán)境差異
2.3.1?差異說(shuō)明
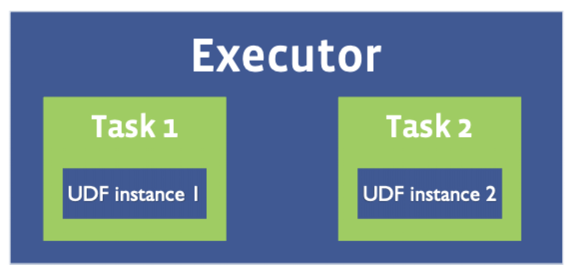
基于MapReduce的Hive SQL一個(gè)Task會(huì)啟動(dòng)一個(gè)進(jìn)程,進(jìn)程中的主線程負(fù)責(zé)數(shù)據(jù)處理, 因此在Hive SQL中UDF只會(huì)在單程中執(zhí)行。
而Spark 一個(gè)Executor可能會(huì)啟動(dòng)多個(gè)Task,如下圖所示。因此在Spark SQL中自定義UDF時(shí)需要考慮線程安全問(wèn)題。

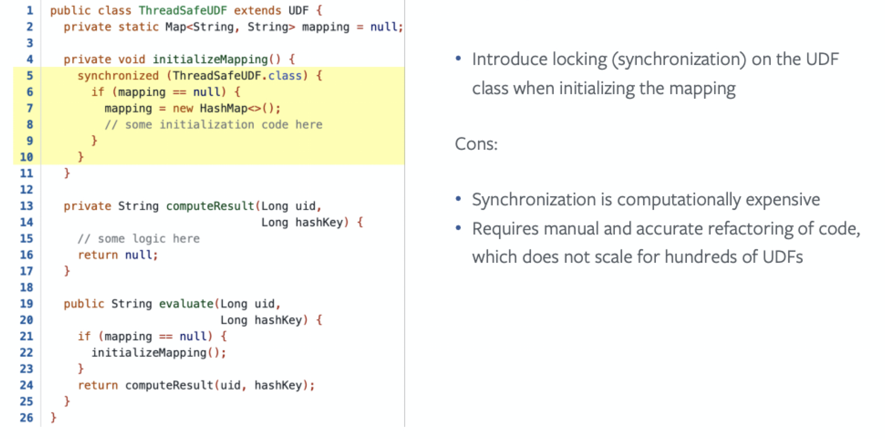
另一種是取消靜態(tài)成員,如下圖所示:

▍3.?性能&功能差異
3.1?小文件合并
Hive SQL可以通過(guò)設(shè)置以下配置合并小文件,MR Job結(jié)束后,判斷生成文件的平均大小,如果小于閥值,就再啟動(dòng)一個(gè)Job來(lái)合并文件。

目前Spark SQL不支持小文件合并,在遷移過(guò)程中,我們經(jīng)常發(fā)現(xiàn)Spark SQL生成的文件數(shù)多于Hive SQL,為此我們參考Hive SQL的實(shí)現(xiàn)在Spark SQL中引入了小文件合并功能。
在InsertIntoHiveTable 中判斷如果開啟小文件合并,并且文件的平均大小低于閾值則執(zhí)行合并,合并之后再執(zhí)行l(wèi)oadTable或者loadPartition操作。
3.2?Spark SQL支持Cluster模式
Hive SQL任務(wù)是DataStudio通過(guò)beeline -f執(zhí)行的,客戶端只負(fù)責(zé)發(fā)送SQL語(yǔ)句給HS2,已經(jīng)獲取執(zhí)行結(jié)果,因此是非常輕量的。而Spark SQL只支持Client模式,Driver在Client進(jìn)程中,因此Client模式執(zhí)行Spark SQL時(shí),有時(shí)會(huì)占用很多的資源,DataStudio無(wú)法感知Spark Driver的資源開銷,所以在DataStudio層面會(huì)帶來(lái)以下問(wèn)題:
形成資源熱點(diǎn),影響任務(wù)執(zhí)行;
隨著遷移到Spark SQL的任務(wù)越來(lái)越多,DataStudio需要越來(lái)越多的機(jī)器調(diào)度SQL任務(wù);
Client模式日志保留在本地,排查問(wèn)題時(shí)不方便看日志;
所以我們開發(fā)了Spark SQL支持Cluster模式,該模式只支持非交互式方式執(zhí)行SQL,包括spark-sql -e和spark-sql -f,不支持交互式模式。
3.3?分區(qū)剪裁優(yōu)化
遷移過(guò)程中我們發(fā)現(xiàn)大部分任務(wù)的分區(qū)條件包括concat, concat_ws, substr等UDF, HiveServer2會(huì)調(diào)用MetaStore的getPartitionsByExpr方法返回符合分區(qū)條件的有效分區(qū),避免無(wú)效的掃描,?但是Spark SQL的分區(qū)剪裁只支持由Attribute和Literal組成key/value結(jié)構(gòu)的謂詞條件,這一方面導(dǎo)致無(wú)法有效分區(qū)剪裁,會(huì)查詢所有分區(qū)的數(shù)據(jù), 造成讀取大量無(wú)效數(shù)據(jù),另一方面查詢所有分區(qū)的元數(shù)據(jù),導(dǎo)致MetaStore對(duì)MySQL查詢壓力激增,導(dǎo)致mysql進(jìn)程把cpu打滿。我們?cè)谏鐓^(qū)版本的基礎(chǔ)上迭代支持了多種場(chǎng)景的分區(qū)聯(lián)合剪裁,目前能夠覆蓋生產(chǎn)任務(wù)90%以上的場(chǎng)景。
concat/concat_ws聯(lián)合剪裁場(chǎng)景

substr 聯(lián)合剪裁場(chǎng)景

concat/concat_ws&substr組合場(chǎng)景

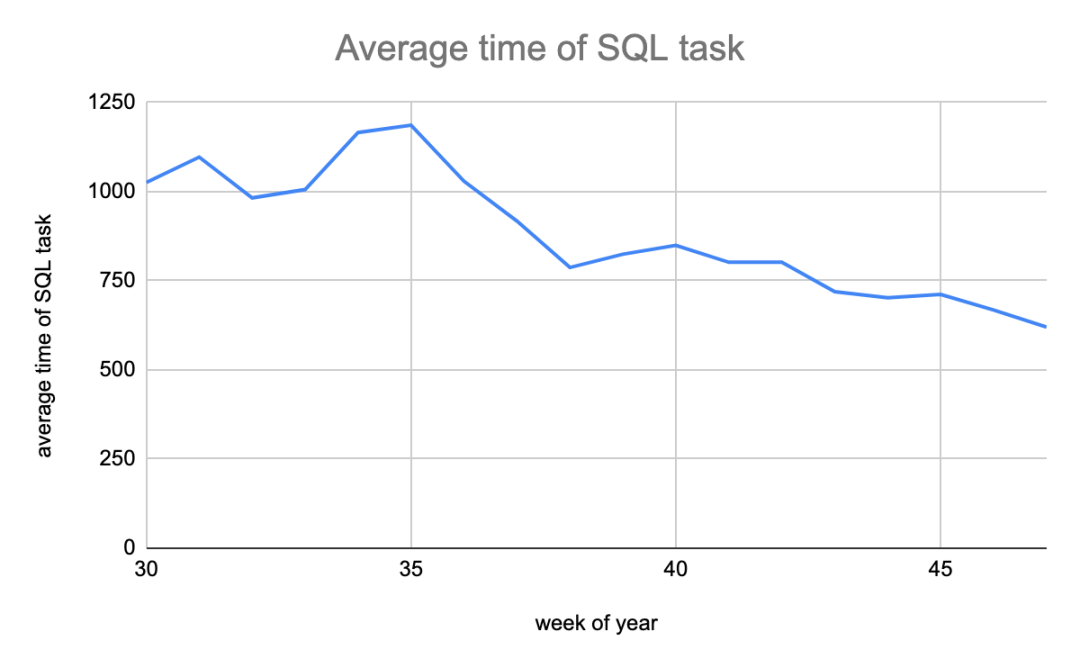
經(jīng)過(guò)6個(gè)多月的團(tuán)隊(duì)的努力,我們遷移了1萬(wàn)多個(gè)Hive SQL任務(wù)到Spark SQL,在遷移過(guò)程中,隨著spark SQL任務(wù)的增加,SQL任務(wù)的執(zhí)行時(shí)間在逐漸減少,從最初的1000+秒下降到600+秒如下圖所示:
遷移之后Spark已經(jīng)成為SQL任務(wù)的主流引擎,但是還有大量的shell類型任務(wù)使用Hive執(zhí)行SQL,所以后續(xù)我們會(huì)遷移shell類型任務(wù),把shell中的Hive SQL遷移到Spark SQL。
在生產(chǎn)環(huán)境中,有些shuffle 比較中的任務(wù)經(jīng)常會(huì)因?yàn)閟huffle fetch重試甚至失敗,我們想優(yōu)化Spark External Shuffle Service。
社區(qū)推出Spark 3.x也半年多了,在功能和性能上有很大提升,所以我們也想和社區(qū)保持同步,升級(jí)Spark到3.x版本。

推薦閱讀
歡迎長(zhǎng)按掃碼關(guān)注「數(shù)據(jù)管道」