
淺談消息隊(duì)列及常見(jiàn)的分布式消息隊(duì)列中間件
背景
分布式消息隊(duì)列中間件是是大型分布式系統(tǒng)不可缺少的中間件,通過(guò)消息隊(duì)列,應(yīng)用程序可以在不知道彼此位置的情況下獨(dú)立處理消息,或者在處理消息前不需要等待接收此消息。所以消息隊(duì)列主要解決應(yīng)用耦合、異步消息、流量削鋒等問(wèn)題,實(shí)現(xiàn)高性能、高可用、可伸縮和最終一致性架構(gòu)。消息隊(duì)列已經(jīng)逐漸成為企業(yè)應(yīng)用系統(tǒng)內(nèi)部通信的核心手段,當(dāng)前使用較多的消息隊(duì)列有 RabbitMQ、RocketMQ、ActiveMQ、Kafka、ZeroMQ、MetaMQ 等,而部分?jǐn)?shù)據(jù)庫(kù)如 Redis、MySQL 以及 PhxSQL 也可實(shí)現(xiàn)消息隊(duì)列的功能。
在日常學(xué)習(xí)與開(kāi)發(fā)過(guò)程中,消息隊(duì)列作為系統(tǒng)不可缺少的中間件,顯得十分的重要。在現(xiàn)代云架構(gòu)中,應(yīng)用程序被分解為多個(gè)規(guī)模較小且更易于開(kāi)發(fā)、部署和維護(hù)的獨(dú)立構(gòu)建塊。消息隊(duì)列可為這些分布式應(yīng)用程序提供通信和協(xié)調(diào)。而本人也在工作的過(guò)程中,前前后后后接觸到了 Kafka、RabbitMQ 兩款消息隊(duì)列。所以,本系列文章也主要以 RabbitMQ 和 Kafka 兩款典型的消息中間件來(lái)做分析。本文是該系列的開(kāi)篇,主要講解消息隊(duì)列的概述、特點(diǎn)等,然后對(duì)消息隊(duì)列使用場(chǎng)景進(jìn)行分析,最后對(duì)市面上比較常見(jiàn)的消息隊(duì)列產(chǎn)品進(jìn)行技術(shù)對(duì)比。
消息隊(duì)列概述
消息隊(duì)列(Message Queue,簡(jiǎn)稱 MQ)是指利用高效可靠的消息傳遞機(jī)制進(jìn)行與平臺(tái)無(wú)關(guān)的數(shù)據(jù)交流,并基于數(shù)據(jù)通信來(lái)進(jìn)行分布式系統(tǒng)的集成。通過(guò)提供消息傳遞和消息排隊(duì)模型,它可以在分布式環(huán)境下提供應(yīng)用解耦、彈性伸縮、冗余存儲(chǔ)、流量削峰、異步通信、數(shù)據(jù)同步等等功能,其作為分布式系統(tǒng)架構(gòu)中的一個(gè)重要組件,有著舉足輕重的地位。消息隊(duì)列是構(gòu)建分布式互聯(lián)網(wǎng)應(yīng)用的基礎(chǔ)設(shè)施,通過(guò) MQ 實(shí)現(xiàn)的松耦合架構(gòu)設(shè)計(jì)可以提高系統(tǒng)可用性以及可擴(kuò)展性,是適用于現(xiàn)代應(yīng)用的最佳設(shè)計(jì)方案。

消息隊(duì)列特點(diǎn)
為什么要用消息隊(duì)列?
通過(guò)異步處理提高系統(tǒng)性能
講解該特點(diǎn)之前,我們先了解一下同步架構(gòu)和異步架構(gòu)的區(qū)別:
同步調(diào)用:是指從請(qǐng)求的發(fā)起一直到最終的處理完成期間,請(qǐng)求的調(diào)用方一直在同步阻塞等待調(diào)用的處理完成。
異步調(diào)用:是指在請(qǐng)求發(fā)起的處理過(guò)程中,客戶端的代碼已經(jīng)返回了,它可以繼續(xù)進(jìn)行自己的后續(xù)操作,而不需要等待調(diào)用處理完成,這就叫做異步調(diào)用。
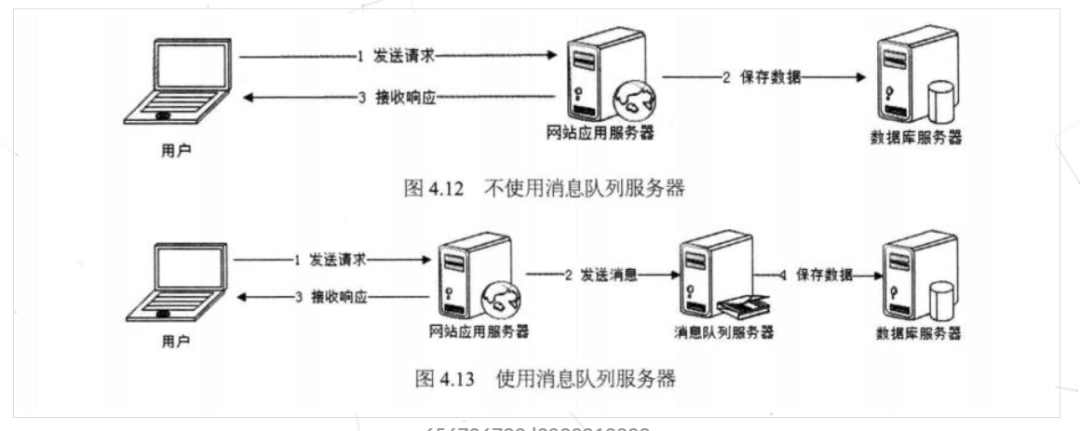
如上圖,在不使用消息隊(duì)列服務(wù)器的時(shí)候,用戶的請(qǐng)求數(shù)據(jù)直接寫入數(shù)據(jù)庫(kù),在高并發(fā)的情況下數(shù)據(jù)庫(kù)壓力劇增,使得響應(yīng)速度變慢。但是在使用消息隊(duì)列之后,用戶的請(qǐng)求數(shù)據(jù)發(fā)送給消息隊(duì)列之后立即 返回,再由消息隊(duì)列的消費(fèi)者進(jìn)程從消息隊(duì)列中獲取數(shù)據(jù),異步寫入數(shù)據(jù)庫(kù)。由于消息隊(duì)列服務(wù)器處理速度快于數(shù)據(jù)庫(kù)(消息隊(duì)列也比數(shù)據(jù)庫(kù)有更好的伸縮性),因此響應(yīng)速度得到大幅改善。
通過(guò)以上分析我們可以得出消息隊(duì)列具有很好的削峰作用的功能——即通過(guò)異步處理,將短時(shí)間高并發(fā)產(chǎn)生的事務(wù)消息存儲(chǔ)在消息隊(duì)列中,從而削平高峰期的并發(fā)事務(wù)。舉例:在電子商務(wù)一些秒殺、促銷活動(dòng)中,合理使用消息隊(duì)列可以有效抵御促銷活動(dòng)剛開(kāi)始大量訂單涌入對(duì)系統(tǒng)的沖擊。如下圖所示:

因?yàn)橛脩粽?qǐng)求數(shù)據(jù)寫入消息隊(duì)列之后就立即返回給用戶了,但是請(qǐng)求數(shù)據(jù)在后續(xù)的業(yè)務(wù)校驗(yàn)、寫數(shù)據(jù)庫(kù)等操作中可能失敗。因此使用消息隊(duì)列進(jìn)行異步處理之后,需要適當(dāng)修改業(yè)務(wù)流程進(jìn)行配合,比如用戶在提交訂單之后,訂單數(shù)據(jù)寫入消息隊(duì)列,不能立即返回用戶訂單提交成功,需要在消息隊(duì)列的訂單消費(fèi)者進(jìn)程真正處理完該訂單之后,甚至出庫(kù)后,再通過(guò)電子郵件或短信通知用戶訂單成功,以免交易糾紛。這就類似我們平時(shí)手機(jī)訂火車票和電影票。
降低系統(tǒng)耦合性
我們知道如果模塊之間不存在直接調(diào)用,那么新增模塊或者修改模塊就對(duì)其他模塊影響較小,這樣系統(tǒng)的可擴(kuò)展性無(wú)疑更好一些。
我們最常見(jiàn)的事件驅(qū)動(dòng)架構(gòu)類似生產(chǎn)者消費(fèi)者模式,在大型網(wǎng)站中通常用利用消息隊(duì)列實(shí)現(xiàn)事件驅(qū)動(dòng)結(jié)構(gòu)。如下圖所示:
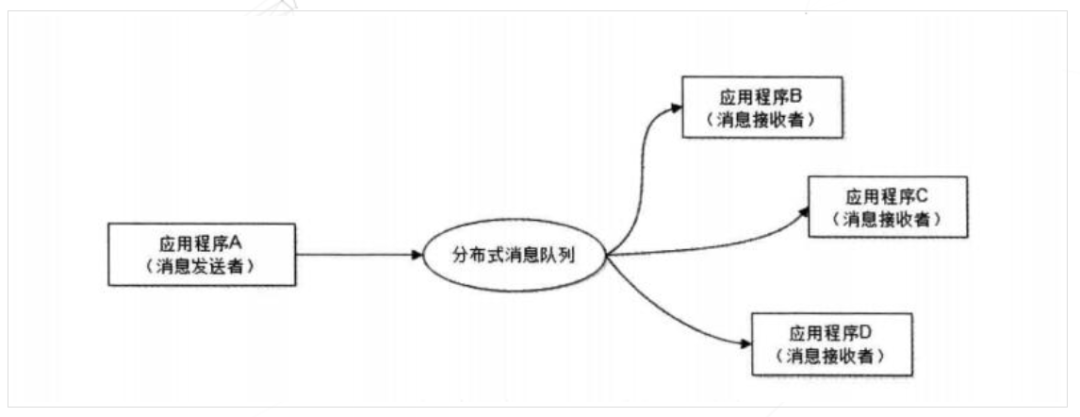
消息隊(duì)列使利用發(fā)布 - 訂閱模式工作,消息發(fā)送者(生產(chǎn)者)發(fā)布消息,一個(gè)或多個(gè)消息接受者(消費(fèi)者)訂閱消息。從上圖可以看到消息發(fā)送者(生產(chǎn)者)和消息接受者(消費(fèi)者)之間沒(méi)有直接耦合,消息發(fā)送者將消息發(fā)送至分布式消息隊(duì)列即結(jié)束對(duì)消息的處理,消息接受者從分布式消息隊(duì)列獲取該消息后進(jìn)行后續(xù)處理,并不需要知道該消息從何而來(lái)。對(duì)新增業(yè)務(wù),只要對(duì)該類消息感興趣,即可訂閱該消息,對(duì)原有系統(tǒng)和業(yè)務(wù)沒(méi)有任何影響,從而實(shí)現(xiàn)網(wǎng)站業(yè)務(wù)的可擴(kuò)展性設(shè)計(jì)。
消息接受者對(duì)消息進(jìn)行過(guò)濾、處理、包裝后,構(gòu)造成一個(gè)新的消息類型,將消息繼續(xù)發(fā)送出去,等待其他消息接受者訂閱該消息。因此基于事件(消息對(duì)象)驅(qū)動(dòng)的業(yè)務(wù)架構(gòu)可以是一系列流程。
另外為了避免消息隊(duì)列服務(wù)器宕機(jī)造成消息丟失,會(huì)將成功發(fā)送到消息隊(duì)列的消息存儲(chǔ)在消息生產(chǎn)者服務(wù)器上,等消息真正被消費(fèi)者服務(wù)器處理后才刪除消息。在消息隊(duì)列服務(wù)器宕機(jī)后,生產(chǎn)者服務(wù)器會(huì)選擇分布式消息隊(duì)列服務(wù)器集群中的其他服務(wù)器發(fā)布消息。
使用消息隊(duì)列帶來(lái)的一些問(wèn)題?
系統(tǒng)可用性降低:系統(tǒng)可用性在某種程度上降低,為什么這樣說(shuō)呢?在加入 MQ 之前,你不用考慮消息丟失或者說(shuō) MQ 掛掉等情況,但是,引入 MQ 之后你就需要如何保證消息隊(duì)列的高可用。
系統(tǒng)復(fù)雜性提高:加入 MQ 之后,你需要保證消息沒(méi)有被重復(fù)消費(fèi)、處理消息丟失的情況、保證消息傳遞的順序性等等問(wèn)題,系統(tǒng)復(fù)發(fā)性提高。
一致性問(wèn)題:消息隊(duì)列帶來(lái)的異步確實(shí)可以提高系統(tǒng)響應(yīng)速度。但是,萬(wàn)一消息的真正消費(fèi)者并沒(méi)有正確消費(fèi)消息怎么辦?這樣就會(huì)導(dǎo)致數(shù)據(jù)不一致的情況。
JMS VS AMQP
JMS
Java 消息服務(wù)(Java Message Service,JMS)應(yīng)用程序接口是一個(gè) Java 平臺(tái)中關(guān)于面向消息中間件(MOM)的 API,用于在兩個(gè)應(yīng)用程序之間,或分布式系統(tǒng)中發(fā)送消息,進(jìn)行異步通信。JMS 的客戶端之間可以通過(guò) JMS 服務(wù)進(jìn)行異步的消息傳輸。JMS PI 是一個(gè)消息服務(wù)的標(biāo)準(zhǔn)或者說(shuō)是規(guī)范,允許應(yīng)用程序組件基于 JavaEE 平臺(tái)創(chuàng)建、發(fā)送、接收和讀取消息。它使分布式通信耦合度更低,消息服務(wù)更加可靠以及異步性。點(diǎn)對(duì)點(diǎn)與發(fā)布訂閱最初是由 JMS 定義的。這兩種模式主要區(qū)別或解決的問(wèn)題就是發(fā)送到隊(duì)列的消息能否重復(fù)消費(fèi)。
JMS 規(guī)范目前支持兩種消息模型:點(diǎn)對(duì)點(diǎn)(point to point,queue)和發(fā)布 / 訂閱(publish/subscribe,topic)。

點(diǎn)對(duì)點(diǎn)(P2P)模型
消息生產(chǎn)者向消息隊(duì)列中發(fā)送了一個(gè)消息之后,只能被一個(gè)消費(fèi)者消費(fèi)一次。點(diǎn)對(duì)點(diǎn)(P2P)使用隊(duì)列(Queue)作為消息通信載體;滿足生產(chǎn)者與消費(fèi)者模式,一條消息只能被一個(gè)消費(fèi)者使用,未被消費(fèi)的消息在隊(duì)列中保留直到被消費(fèi)或超時(shí)。
Queue 實(shí)現(xiàn)了負(fù)載均衡,一個(gè)消息只能被一個(gè)消費(fèi)者接受,當(dāng)沒(méi)有消費(fèi)者可用時(shí),這個(gè)消息會(huì)被保存直到有 一個(gè)可用的消費(fèi)者,一個(gè) queue 可以有很多消費(fèi)者,他們之間實(shí)現(xiàn)了負(fù)載均衡, 所以 Queue 實(shí)現(xiàn)了一個(gè)可靠的負(fù)載均衡。

特點(diǎn):
每個(gè)消息只用一個(gè)消費(fèi)者;
發(fā)送者和接受者沒(méi)有時(shí)間依賴;
接受者確認(rèn)消息接受和處理成功。
發(fā)布 / 訂閱(Pub/Sub)模型
消息生產(chǎn)者向頻道發(fā)送一個(gè)消息之后,多個(gè)消費(fèi)者可以從該頻道訂閱到這條消息并消費(fèi)。發(fā)布訂閱模型(Pub/Sub) 使用主題(Topic)作為消息通信載體,類似于廣播模式;發(fā)布者發(fā)布一條消息,該消息通過(guò)主題傳遞給所有的訂閱者,在一條消息廣播之后才訂閱的用戶則是收不到該條消息的。
Topic 實(shí)現(xiàn)了發(fā)布和訂閱,當(dāng)你發(fā)布一個(gè)消息,所有訂閱這個(gè) Topic 的服務(wù)都能得到這個(gè)消息,所以從 1 到 N 個(gè)訂閱者都能得到一個(gè)消息的拷貝, 只有在消息代理收到消息時(shí)有一個(gè)有效訂閱時(shí)的訂閱者才能得到這個(gè)消息的拷貝。
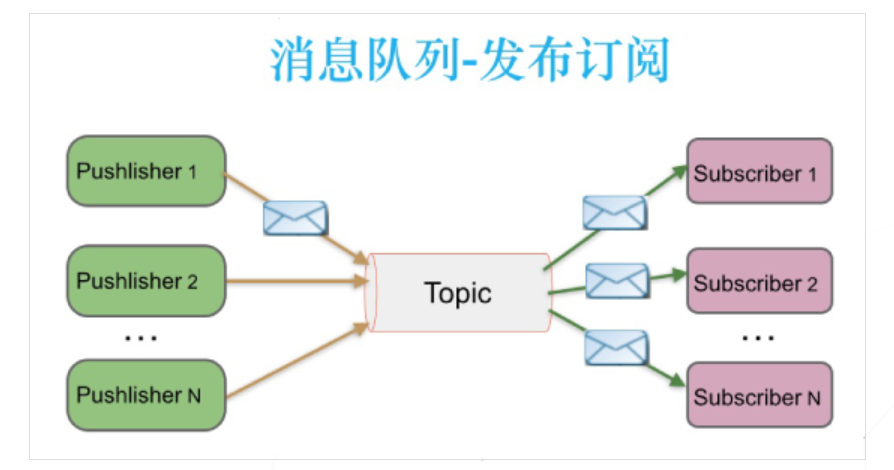
特點(diǎn):
每個(gè)消息可以有多個(gè)訂閱者;
客戶端只有訂閱后才能接收到消息;
持久訂閱和非持久訂閱。
注意:
發(fā)布者和訂閱者有時(shí)間依賴:接受者和發(fā)布者只有建立訂閱關(guān)系才能收到消息;
持久訂閱:訂閱關(guān)系建立后,消息就不會(huì)消失,不管訂閱者是否都在線;
非持久訂閱:訂閱者為了接受消息,必須一直在線。當(dāng)只有一個(gè)訂閱者時(shí)約等于點(diǎn)對(duì)點(diǎn)模型。
點(diǎn)對(duì)點(diǎn)(P2P)模型與發(fā)布 / 訂閱(Pub/Sub)模型應(yīng)用
點(diǎn)對(duì)點(diǎn)模型:主要用于一些耗時(shí)較長(zhǎng)的、邏輯相對(duì)獨(dú)立的業(yè)務(wù)。
比如說(shuō)發(fā)送郵件這樣一個(gè)操作。因?yàn)榘l(fā)送郵件比較耗時(shí),而且應(yīng)用程序其實(shí)也并不太關(guān)心郵件發(fā)送是否成功,發(fā)送郵件的邏輯也相對(duì)比較獨(dú)立,所以它只需要把郵件消息丟到消息隊(duì)列中就可以返回了,而消費(fèi)者也不需要關(guān)心是哪個(gè)生產(chǎn)者去發(fā)送的郵件,它只需要把郵件消息內(nèi)容取出來(lái)以后進(jìn)行消費(fèi),通過(guò)遠(yuǎn)程服務(wù)器將郵件發(fā)送出去就可以了。而且每個(gè)郵件只需要被發(fā)送一次。所以消息只被一個(gè)消費(fèi)者消費(fèi)就可以了。
發(fā)布訂閱模型:如新用戶注冊(cè)這樣一個(gè)消息,需要使用按主題發(fā)布的方式。
比如新用戶注冊(cè),一個(gè)新用戶注冊(cè)成功以后,需要給用戶發(fā)送一封激活郵件,發(fā)送一條歡迎短信,還需要將用戶注冊(cè)數(shù)據(jù)寫入數(shù)據(jù)庫(kù),甚至需要將新用戶信息發(fā)送給關(guān)聯(lián)企業(yè)的系統(tǒng),比如淘寶新用戶信息發(fā)送給支付寶,這樣允許用戶可以一次注冊(cè)就能登錄使用多個(gè)關(guān)聯(lián)產(chǎn)品。一個(gè)新用戶注冊(cè),會(huì)把注冊(cè)消息發(fā)送給一個(gè)主題,多種消費(fèi)者可以訂閱這個(gè)主題。比如發(fā)送郵件的消費(fèi)者、發(fā)送短信的消費(fèi)者、將注冊(cè)信息寫入數(shù)據(jù)庫(kù)的消費(fèi)者,跨系統(tǒng)同步消息的消費(fèi)者等。
AMQP
AMQP(advanced message queuing protocol)在 2003 年時(shí)被提出,最早用于解決金融領(lǐng)不同平臺(tái)之間的消息傳遞交互問(wèn)題。顧名思義,AMQP 是一種協(xié)議,更準(zhǔn)確的說(shuō)是一種 binary wire-level protocol(鏈接協(xié)議)。這是其和 JMS 的本質(zhì)差別,AMQP 不從 API 層進(jìn)行限定,而是直接定義網(wǎng)絡(luò)交換的數(shù)據(jù)格式。這使得實(shí)現(xiàn)了 AMQP 的 provider 天然性就是跨平臺(tái)的。意味著我們可以使用 Java 的 AMQP provider,同時(shí)使用一個(gè) python 的 producer 加一個(gè) rubby 的 consumer。
在 AMQP 中,消息路由(message routing)和 JMS 存在一些差別,在 AMQP 中增加了 Exchange 和 binding 的角色。producer 將消息發(fā)送給 Exchange,binding 決定 Exchange 的消息應(yīng)該發(fā)送到那個(gè) queue,而 consumer 直接從 queue 中消費(fèi)消息。
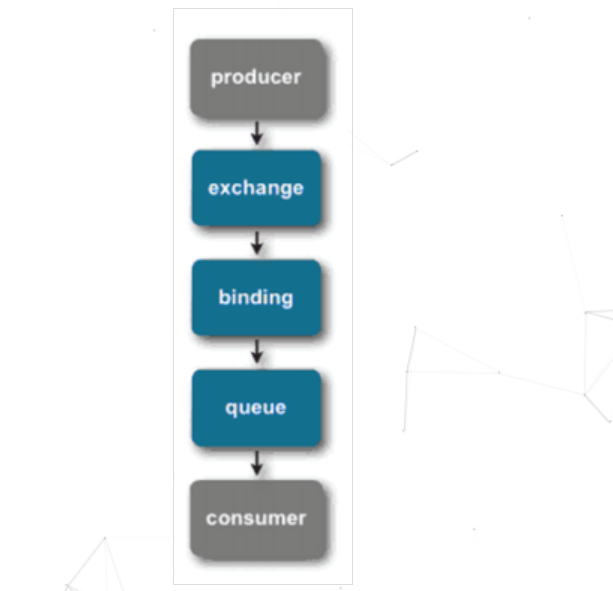
AMQP 提供五種消息模型:①Direct Exchange;②Fanout Exchange;③Topic Exchange;④Headers Exchange;⑤System Exchange。本質(zhì)來(lái)講,后四種和 JMS 的 pub/sub 模型沒(méi)有太大差別,僅是在路由機(jī)制上做了更詳細(xì)的劃分。
JMS 與 AMQP 對(duì)比
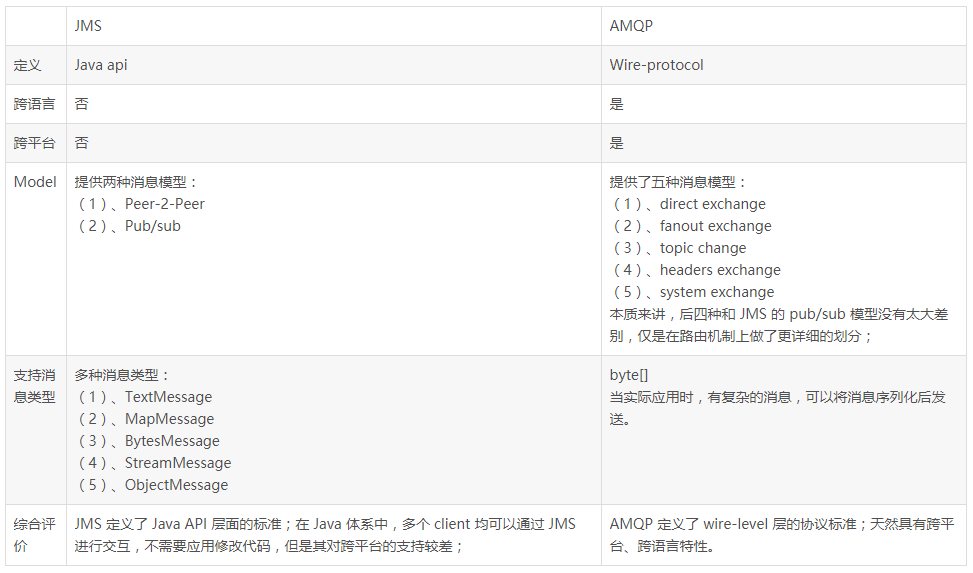
總結(jié):
AMQP 為消息定義了線路層(wire-level protocol)的協(xié)議,而 JMS 所定義的是 API 規(guī)范。在 Java 體系中,多個(gè) client 均可以通過(guò) JMS 進(jìn)行交互,不需要應(yīng)用修改代碼,但是其對(duì)跨平臺(tái)的支持較差。而 AMQP 天然具有跨平臺(tái)、跨語(yǔ)言特性。
JMS 支持 TextMessage、MapMessage 等復(fù)雜的消息類型;而 AMQP 僅支持 byte[] 消息類型(復(fù)雜的類型可序列化后發(fā)送)。
由于 Exchange 提供的路由算法,AMQP 可以提供多樣化的路由方式來(lái)傳遞消息到消息隊(duì)列,而 JMS 僅支持 隊(duì)列 和 主題 / 訂閱 方式兩種。
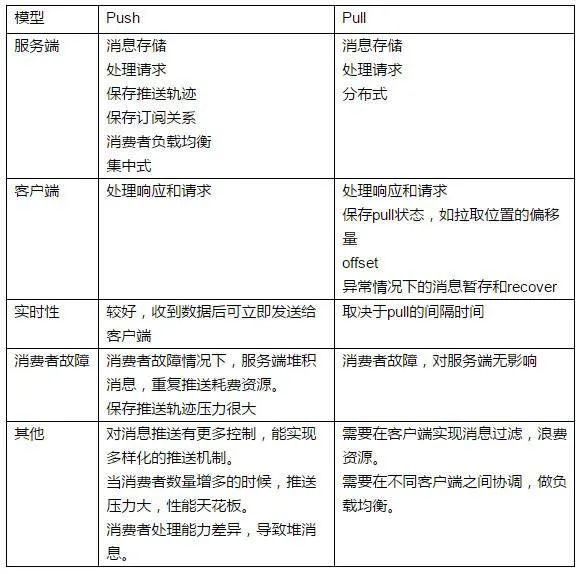
消息隊(duì)列推拉模型
Push 推消息模型:消息生產(chǎn)者將消息發(fā)送給消息隊(duì)列,消息隊(duì)列又將消息推給消息消費(fèi)者。
Pull 拉消息模型:消費(fèi)者請(qǐng)求消息隊(duì)列接受消息,消息生產(chǎn)者從消息隊(duì)列中拉該消息。
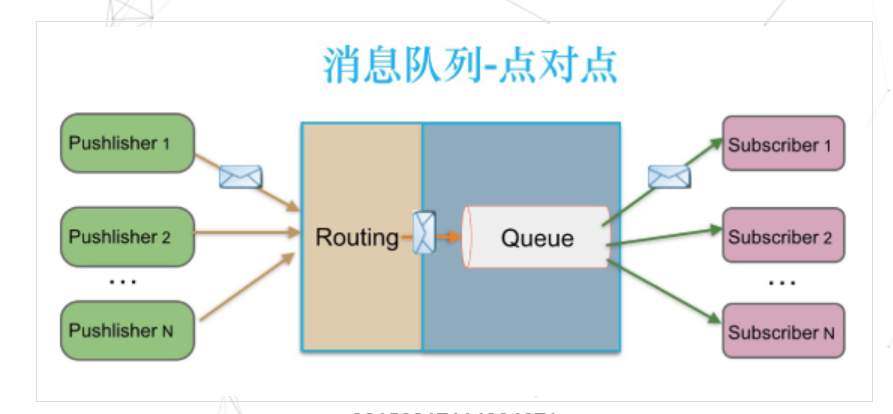
RabbitMQ
RabbitMQ 實(shí)現(xiàn)了 AQMP 協(xié)議,AQMP 協(xié)議定義了消息路由規(guī)則和方式。生產(chǎn)端通過(guò)路由規(guī)則發(fā)送消息到不同 queue,消費(fèi)端根據(jù) queue 名稱消費(fèi)消息。此外 RabbitMQ 是向消費(fèi)端推送消息,訂閱關(guān)系和消費(fèi)狀態(tài)保存在服務(wù)端。

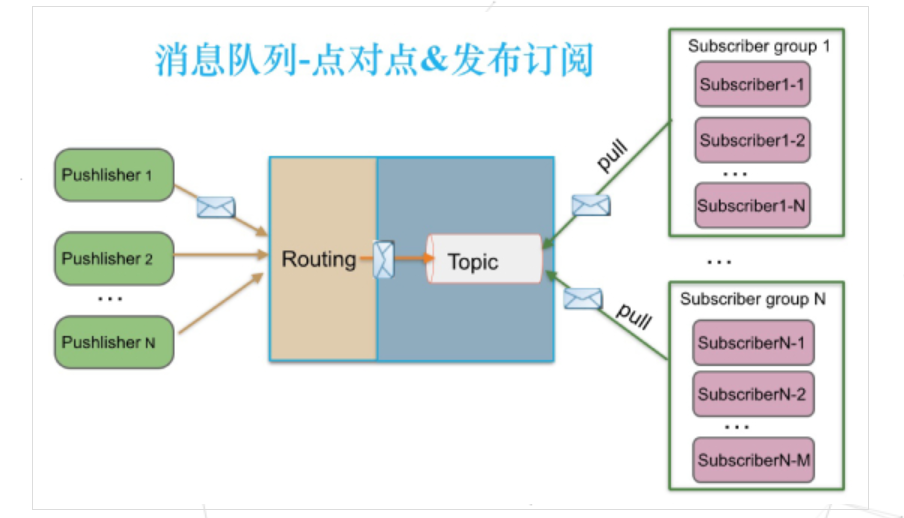
Kafka
Kafka 只支持消息持久化,消費(fèi)端為拉模型,消費(fèi)狀態(tài)和訂閱關(guān)系由客戶端端負(fù)責(zé)維護(hù),消息消費(fèi)完后不會(huì)立即刪除,會(huì)保留歷史消息。因此支持多訂閱時(shí),消息只會(huì)存儲(chǔ)一份就可以了。同一個(gè)訂閱組會(huì)消費(fèi) topic 所有消息,每條消息只會(huì)被同一個(gè)訂閱組的一個(gè)消費(fèi)節(jié)點(diǎn)消費(fèi),同一個(gè)訂閱組內(nèi)不同消費(fèi)節(jié)點(diǎn)會(huì)消費(fèi)不同消息。
消息隊(duì)列使用場(chǎng)景
異步處理:實(shí)現(xiàn)異步處理,提升處理性能
對(duì)一些比較耗時(shí)的操作,可以把處理過(guò)程通過(guò)消息隊(duì)列進(jìn)行異步處理。這樣做可以推遲耗時(shí)操作的處理,使耗時(shí)操作異步化,而不必阻塞客戶端的程序,客戶端的程序在得到處理結(jié)果之前就可以繼續(xù)執(zhí)行,從而提高客戶端程序的處理性能。非核心流程異步化,減少系統(tǒng)響應(yīng)時(shí)間,提高吞吐量。
例如:短信通知、終端狀態(tài)推送、App 推送、用戶注冊(cè)等。
解耦:可以使生產(chǎn)者和消費(fèi)者的代碼實(shí)現(xiàn)解耦合
可以多個(gè)生產(chǎn)者發(fā)布消息,多個(gè)消費(fèi)者處理消息,共同完成完整的業(yè)務(wù)處理邏輯,但是它們的不需要直接的交互調(diào)用,沒(méi)有代碼的依賴耦合。在傳統(tǒng)的同步調(diào)用中,調(diào)用者代碼必須要依賴被調(diào)用者的代碼,也就是生產(chǎn)者代碼必須要依賴消費(fèi)者的處理邏輯代碼,代碼需要直接的耦合,而使用消息隊(duì)列,這兩部分的代碼不需要進(jìn)行任何的耦合。因?yàn)轳詈铣潭仍降偷拇a越容易維護(hù),也越容易進(jìn)行擴(kuò)展。
比如新用戶注冊(cè),如果用傳統(tǒng)同步調(diào)用的方式,那么發(fā)郵件、發(fā)短信、寫數(shù)據(jù)庫(kù)、通知關(guān)聯(lián)系統(tǒng)這些代碼會(huì)和用戶注冊(cè)代碼直接耦合起來(lái),整個(gè)代碼看起來(lái)就是完成用戶注冊(cè)邏輯后,后面必然跟著發(fā)郵件、發(fā)短信這些代碼。如果要新增一個(gè)功能,比如將監(jiān)控用戶注冊(cè)情況,將注冊(cè)信息發(fā)送到業(yè)務(wù)監(jiān)控系統(tǒng),就必須要修改前面的代碼,至少增加一行代碼,發(fā)送注冊(cè)信息到監(jiān)控系統(tǒng),我們知道,任何代碼的修改都可能會(huì)引起 bug。
而使用分布式消息隊(duì)列實(shí)現(xiàn)生產(chǎn)者和消費(fèi)者解耦合以后,用戶注冊(cè)以后,不需要調(diào)用任何后續(xù)處理代碼,只需要將注冊(cè)消息發(fā)送到分布式消息隊(duì)列就可以了。如果要增加新功能,只需要寫個(gè)新功能的消費(fèi)者程序,在分布式消息隊(duì)列中,訂閱用戶注冊(cè)主題就可以了,不需要修改原來(lái)任何一行代碼。
流量削峰和流控:可以平衡流量峰值,削峰填谷
當(dāng)上下游系統(tǒng)處理能力存在差距的時(shí)候,利用消息隊(duì)列做一個(gè)通用的 “漏斗”,進(jìn)行限流控制。在下游有能力處理的時(shí)候,再進(jìn)行分發(fā)。
使用消息隊(duì)列,即便是訪問(wèn)流量持續(xù)的增長(zhǎng),系統(tǒng)依然可以持續(xù)地接收請(qǐng)求。這種情況下,雖然生產(chǎn)者發(fā)布消息的速度比消費(fèi)者消費(fèi)消息的速度快,但是可以持續(xù)的將消息納入到消息隊(duì)列中,用消息隊(duì)列作為消息的緩沖,因此短時(shí)間內(nèi),發(fā)布者不會(huì)受到消費(fèi)處理能力的影響。
在訪問(wèn)高峰,用戶的并發(fā)訪問(wèn)數(shù)可能超過(guò)了系統(tǒng)的處理能力,所以在高峰期就可能會(huì)導(dǎo)致系統(tǒng)負(fù)載過(guò)大,響應(yīng)速度變慢,更嚴(yán)重的可能會(huì)導(dǎo)致系統(tǒng)崩潰。這種情況下,通過(guò)消息隊(duì)列將用戶請(qǐng)求的消息納入到消息隊(duì)列中,通過(guò)消息隊(duì)列緩沖消費(fèi)者處理消息的速度。
消息的生產(chǎn)者它有高峰有低谷,但是到了消費(fèi)者這里,只會(huì)按照自己的最佳處理能力去消費(fèi)消息。高峰期它會(huì)把消息緩沖在消息隊(duì)列中,而在低谷期它也還是使用自己最大的處理能力去獲取消息,將前面緩沖起來(lái)、來(lái)不及及時(shí)處理的消息處理掉。那么,通過(guò)這種手段可以實(shí)現(xiàn)系統(tǒng)負(fù)載消峰填谷,也就是說(shuō)將訪問(wèn)的高峰消掉,而將訪問(wèn)的低谷填平,使系統(tǒng)處在一個(gè)最佳的處理狀態(tài)之下,不會(huì)對(duì)系統(tǒng)的負(fù)載產(chǎn)生太大的沖擊。
舉個(gè)例子:用戶在支付系統(tǒng)成功結(jié)賬后,訂單系統(tǒng)會(huì)通過(guò)短信系統(tǒng)向用戶推送扣費(fèi)通知。短信系統(tǒng)可能由于短板效應(yīng),速度卡在網(wǎng)關(guān)上(每秒幾百次請(qǐng)求),跟前端的并發(fā)量不是一個(gè)數(shù)量級(jí)。于是,就造成支付系統(tǒng)和短信系統(tǒng)的處理能力出現(xiàn)差異化。
然而用戶晚上個(gè)半分鐘左右收到短信,一般是不會(huì)有太大問(wèn)題的。如果沒(méi)有消息隊(duì)列,兩個(gè)系統(tǒng)之間通過(guò)協(xié)商、滑動(dòng)窗口等復(fù)雜的方案也不是說(shuō)不能實(shí)現(xiàn)。但系統(tǒng)復(fù)雜性指數(shù)級(jí)增長(zhǎng),勢(shì)必在上游或者下游做存儲(chǔ),并且要處理定時(shí)、擁塞等一系列問(wèn)題。而且每當(dāng)有處理能力有差距的時(shí)候,都需要單獨(dú)開(kāi)發(fā)一套邏輯來(lái)維護(hù)這套邏輯。所以,利用中間系統(tǒng)轉(zhuǎn)儲(chǔ)兩個(gè)系統(tǒng)的通信內(nèi)容,并在下游系統(tǒng)有能力處理這些消息的時(shí)候,再處理這些消息,是一套相對(duì)較通用的方式。
易伸縮:可以讓系統(tǒng)獲得更好的伸縮性
耗時(shí)的任務(wù)可以通過(guò)分布式消息隊(duì)列,向多臺(tái)消費(fèi)者服務(wù)器并行發(fā)送消息,然后在很多臺(tái)消費(fèi)者服務(wù)器上并行處理消息,也就是說(shuō)可以在多臺(tái)物理服務(wù)器上運(yùn)行消費(fèi)者。那么當(dāng)負(fù)載上升的時(shí)候,可以很容易地添加更多的機(jī)器成為消費(fèi)者。
例如:用戶上傳文件后,通過(guò)發(fā)布消息的方式,通知后端的消費(fèi)者獲取數(shù)據(jù)、讀取文件,進(jìn)行異步的文件處理操作。那么當(dāng)前端發(fā)布更多文件的時(shí)候,或者處理邏輯比較復(fù)雜的時(shí)候,就可以通過(guò)添加后端的消費(fèi)者服務(wù)器,提供更強(qiáng)大的處理能力。
隔離失效機(jī)器以及自我修復(fù):失敗隔離和自我修復(fù)
因?yàn)榘l(fā)布者不直接依賴消費(fèi)者,所以分布式消息隊(duì)列可以將消費(fèi)者系統(tǒng)產(chǎn)生的錯(cuò)誤異常與生產(chǎn)者系統(tǒng)隔離開(kāi)來(lái),生產(chǎn)者不受消費(fèi)者失敗的影響。當(dāng)在消息消費(fèi)過(guò)程中出現(xiàn)處理邏輯失敗的時(shí)候,這個(gè)錯(cuò)誤只會(huì)影響到消費(fèi)者自身,而不會(huì)傳遞給消息的生產(chǎn)者,也就是應(yīng)用程序可以按照原來(lái)的處理邏輯繼續(xù)執(zhí)行。
所以,這也就意味著在任何時(shí)候都可以對(duì)后端的服務(wù)器執(zhí)行維護(hù)和發(fā)布操作。可以重啟、添加或刪除服務(wù)器,而不影響生產(chǎn)者的可用性,這樣簡(jiǎn)化了部署和服務(wù)器管理的難度。
日志處理
日志處理是指將消息隊(duì)列用在日志處理中,比如 Kafka 的應(yīng)用,解決大量日志傳輸和緩沖的問(wèn)題。日志采集客戶端,負(fù)責(zé)日志數(shù)據(jù)采集,定時(shí)寫受寫入 Kafka 隊(duì)列;Kafka 消息隊(duì)列,負(fù)責(zé)日志數(shù)據(jù)的接收,存儲(chǔ)和轉(zhuǎn)發(fā);日志處理應(yīng)用,訂閱并消費(fèi) kafka 隊(duì)列中的日志數(shù)據(jù)。
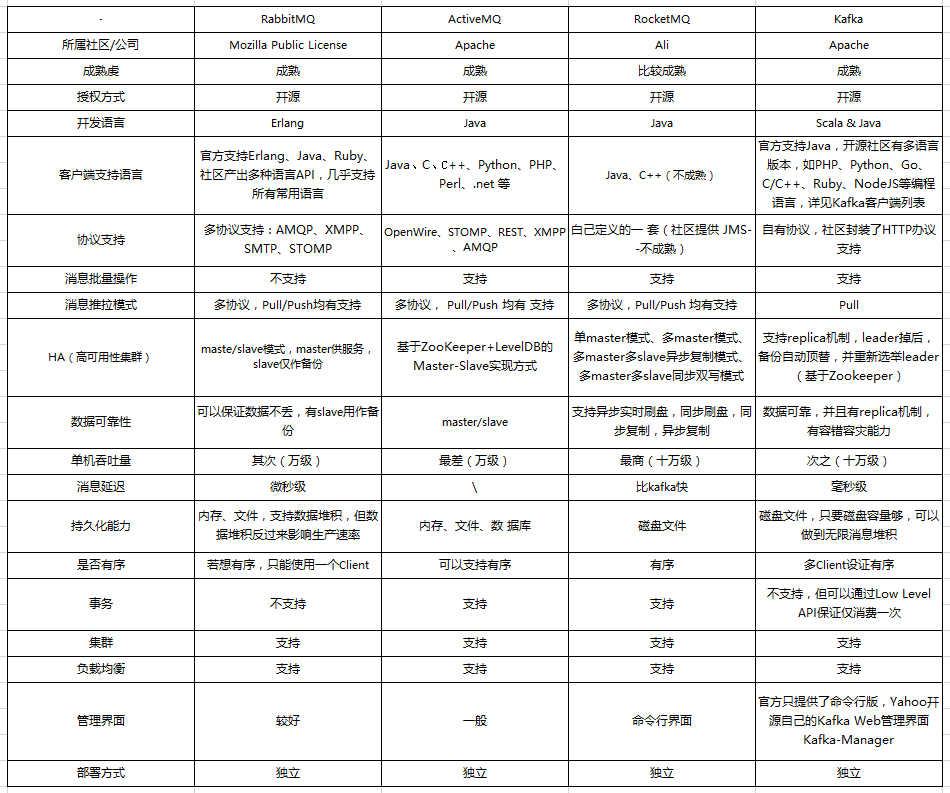
消息隊(duì)列技術(shù)對(duì)比
ActiveMQ?是 Apache 出品的、采用 Java 語(yǔ)言編寫的完全基于 JMS1.1 規(guī)范的面向消息的中間件,為應(yīng)用程序提供高效的、可擴(kuò)展的、穩(wěn)定的和安全的企業(yè)級(jí)消息通信。不過(guò)由于歷史原因包袱太重,目前市場(chǎng)份額沒(méi)有后面三種消息中間件多,其最新架構(gòu)被命名為 Apollo,號(hào)稱下一代 ActiveMQ,有興趣的同學(xué)可行了解。
RabbitMQ?是采用 Erlang 語(yǔ)言實(shí)現(xiàn)的 AMQP 協(xié)議的消息中間件,最初起源于金融系統(tǒng),用于在分布式系統(tǒng)中存儲(chǔ)轉(zhuǎn)發(fā)消息。RabbitMQ 發(fā)展到今天,被越來(lái)越多的人認(rèn)可,這和它在可靠性、可用性、擴(kuò)展性、功能豐富等方面的卓越表現(xiàn)是分不開(kāi)的。主要特點(diǎn)是性能好,社區(qū)活躍,但是 RabbitMQ 用 Erlang 開(kāi)發(fā),我們的應(yīng)用很少用 Erlang,所以不便于二次開(kāi)發(fā)和維護(hù)。
Kafka?是由 LinkedIn 公司采用 Scala 語(yǔ)言開(kāi)發(fā)的一個(gè)分布式、多分區(qū)、多副本且基于 zookeeper 協(xié)調(diào)的分布式消息系統(tǒng),現(xiàn)已捐獻(xiàn)給 Apache 基金會(huì)。它是一種高吞吐量的分布式發(fā)布訂閱消息系統(tǒng),以可水平擴(kuò)展和高吞吐率而被廣泛使用。目前越來(lái)越多的開(kāi)源分布式處理系統(tǒng)如 Cloudera、Apache Storm、Spark、Flink 等都支持與 Kafka 集成。
RocketMQ?是阿里開(kāi)源的消息中間件,目前在 Apache 孵化,使用純 Java 開(kāi)發(fā),具有高吞吐量、高可用性、適合大規(guī)模分布式系統(tǒng)應(yīng)用的特點(diǎn)。RocketMQ 思路起源于 Kafka,但并不是簡(jiǎn)單的復(fù)制,它對(duì)消息的可靠傳輸及事務(wù)性做了優(yōu)化,目前在阿里集團(tuán)被廣泛應(yīng)用于交易、充值、流計(jì)算、消息推送、日志流式處理、binglog 分發(fā)等場(chǎng)景,支撐了阿里多次雙十一活動(dòng)。
ZeroMQ?是基于 C 語(yǔ)言開(kāi)發(fā),號(hào)稱史上最快的消息隊(duì)列。ZeroMQ 是一個(gè)消息處理隊(duì)列庫(kù),可在多線程、多內(nèi)核和主機(jī)之間彈性伸縮,雖然大多數(shù)時(shí)候我們習(xí)慣將其歸入消息隊(duì)列家族之中,但是其和前面的幾款有著本質(zhì)的區(qū)別,ZeroMQ 本身就不是一個(gè)消息隊(duì)列服務(wù)器,更像是一組底層網(wǎng)絡(luò)通訊庫(kù),對(duì)原有的 Socket API 上加上一層封裝而已。
總結(jié):
ActiveMQ 的社區(qū)算是比較成熟,但是較目前來(lái)說(shuō),ActiveMQ 的性能比較差,而且版本迭代很慢,不推薦使用。
RabbitMQ 在吞吐量方面雖然稍遜于 Kafka 和 RocketMQ ,但是由于它基于 erlang 開(kāi)發(fā),所以并發(fā)能力很強(qiáng),性能極其好,延時(shí)很低,達(dá)到微秒級(jí)。但是也因?yàn)?RabbitMQ 基于 erlang 開(kāi)發(fā),所以國(guó)內(nèi)很少有公司有實(shí)力做 erlang 源碼級(jí)別的研究和定制。如果業(yè)務(wù)場(chǎng)景對(duì)并發(fā)量要求不是太高(十萬(wàn)級(jí)、百萬(wàn)級(jí)),那這四種消息隊(duì)列中,RabbitMQ 一定是你的首選。如果是大數(shù)據(jù)領(lǐng)域的實(shí)時(shí)計(jì)算、日志采集等場(chǎng)景,用 Kafka 是業(yè)內(nèi)標(biāo)準(zhǔn)的,絕對(duì)沒(méi)問(wèn)題,社區(qū)活躍度很高,絕對(duì)不會(huì)黃,何況幾乎是全世界這個(gè)領(lǐng)域的事實(shí)性規(guī)范。
RocketMQ 阿里出品,Java 系開(kāi)源項(xiàng)目,源代碼我們可以直接閱讀,然后可以定制自己公司的 MQ,并且 RocketMQ 有阿里巴巴的實(shí)際業(yè)務(wù)場(chǎng)景的實(shí)戰(zhàn)考驗(yàn)。RocketMQ 社區(qū)活躍度相對(duì)較為一般,不過(guò)也還可以,文檔相對(duì)來(lái)說(shuō)簡(jiǎn)單一些,然后接口這塊不是按照標(biāo)準(zhǔn) JMS 規(guī)范走的有些系統(tǒng)要遷移需要修改大量代碼。還有就是阿里出臺(tái)的技術(shù),你得做好這個(gè)技術(shù)萬(wàn)一被拋棄,社區(qū)黃掉的風(fēng)險(xiǎn),那如果你們公司有技術(shù)實(shí)力我覺(jué)得用 RocketMQ 挺好的
kafka 最初設(shè)計(jì)時(shí)就是針對(duì)互聯(lián)網(wǎng)的分布式、高可用應(yīng)用場(chǎng)景而設(shè)計(jì),所以其特點(diǎn)其實(shí)很明顯,就是僅僅提供較少的核心功能,但是提供超高的吞吐量,ms 級(jí)的延遲,極高的可用性以及可靠性,而且分布式可以任意擴(kuò)展。同時(shí) kafka 最好是支撐較少的 topic 數(shù)量即可,保證其超高吞吐量。kafka 唯一的一點(diǎn)劣勢(shì)是有可能消息重復(fù)消費(fèi),那么對(duì)數(shù)據(jù)準(zhǔn)確性會(huì)造成極其輕微的影響,在大數(shù)據(jù)領(lǐng)域中以及日志采集中,這點(diǎn)輕微影響可以忽略這個(gè)特性天然適合大數(shù)據(jù)實(shí)時(shí)計(jì)算以及日志收集。
參考博文
[1].?淺談消息隊(duì)列及常見(jiàn)的消息中間件
[2].?消息中間件選型分析
[3].?新手也能看懂,消息隊(duì)列其實(shí)很簡(jiǎn)單
[4].?10 分鐘搞懂:95% 的程序員都拎不清的分布式消息隊(duì)列中間件
source:https://morning-pro.github.io/archives/1c55560e.html

喜歡,在看