
寫給前端的編譯原理科普
昊昊是一個(gè)前端工程師,最近涉及到工程化領(lǐng)域,想了解一些編譯的知識(shí)。恰好我比他研究的早一些,所以把我了解的東西給他介紹了一遍,于是就有了下面的對(duì)話。
什么是編譯啊?
昊昊:最近想了解一些編譯的東西,光哥,編譯到底是什么啊?
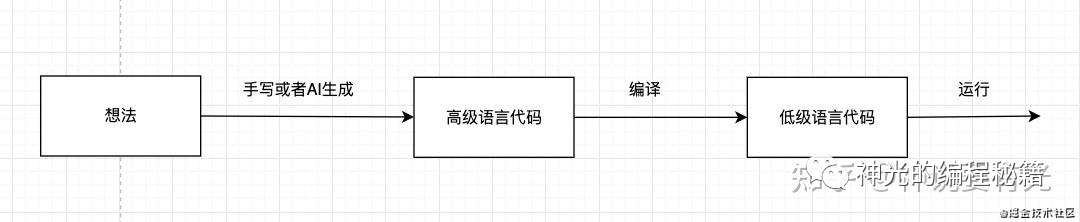
我:編譯啊就是一種轉(zhuǎn)換技術(shù),從一門編程語言到另一門編程語言,從高級(jí)語言轉(zhuǎn)換成低級(jí)語言,或者從高級(jí)語言到高級(jí)語言,這樣的轉(zhuǎn)換技術(shù)。
昊昊:什么是高級(jí)語言,什么是低級(jí)語言啊?
我: 低級(jí)語言是與機(jī)器有關(guān)的,涉及到寄存器、cpu指令等,特別“低”,描述具體在機(jī)器上的執(zhí)行過程,比如機(jī)器語言、匯編語言、字節(jié)碼等。高級(jí)語言則沒有這些具體執(zhí)行的東西,主要用來表達(dá)邏輯,而且提供了條件、循環(huán)、函數(shù)、面向?qū)ο蟮忍匦詠斫M織邏輯,然后通過編譯來把這些描述好的高級(jí)語言邏輯自動(dòng)轉(zhuǎn)換為低級(jí)語言的指令,這樣既能夠方便的表達(dá)邏輯,又不影響具體執(zhí)行。說不影響執(zhí)行也不太對(duì),因?yàn)槿绻苯訉憛R編,能寫出效率最高的代碼,但是如果是高級(jí)語言通過編譯來自動(dòng)轉(zhuǎn)換為低級(jí)語言,那么就難以保證生成代碼的執(zhí)行效率了,需要各種編譯優(yōu)化,這是編譯領(lǐng)域的難點(diǎn)。
其實(shí)想想,我們把腦中的想法,把制訂好的方案轉(zhuǎn)換為高級(jí)語言代碼,這個(gè)過程是不是也是轉(zhuǎn)換,可不可以自動(dòng)化呢,這就涉及到ai了。現(xiàn)在有理解需求文檔生成代碼的智能化技術(shù)的研究方向。
昊昊:那具體是怎么轉(zhuǎn)換的呢?
我:要轉(zhuǎn)換首先得了解轉(zhuǎn)換的雙方,要轉(zhuǎn)換的是什么,轉(zhuǎn)換到什么。比如高級(jí)語言到高級(jí)語言,要轉(zhuǎn)換的是字符串,按照一定的格式組織的,這些格式分別叫做詞法、語法,整體叫做文法,那要轉(zhuǎn)換的目標(biāo)呢,目標(biāo)如果也是高級(jí)語言那么要了解目標(biāo)語言的格式,如果目標(biāo)是低級(jí)語言,比如匯編,那要了解每條指令時(shí)干啥的。然后就要進(jìn)行語義等價(jià)的轉(zhuǎn)換,注意這個(gè)“語義等價(jià)”,通過一門語言解釋另一門語言,不能丟失或者添加一些語義,一定要前后一致才可以。
知道了轉(zhuǎn)換的雙方都是什么,就可以進(jìn)行轉(zhuǎn)換了,首先得讓計(jì)算機(jī)理解要轉(zhuǎn)換的東西,什么叫“計(jì)算機(jī)理解“呢?就是把我們規(guī)定的那些詞法、語法格式告訴計(jì)算機(jī),怎么告訴呢?就是數(shù)據(jù)結(jié)構(gòu),要按照一定的數(shù)據(jù)結(jié)構(gòu)把源碼字符串解析后的結(jié)果組織起來,計(jì)算機(jī)就能處理了。這個(gè)過程叫做 parse,要先分詞,再構(gòu)造成語法樹。
其實(shí)不只是編譯領(lǐng)域需要“理解”,很有很多別的領(lǐng)域也要“理解”:
全文搜索引擎也要先把搜索的字符串通過分詞器分詞,然后根據(jù)這些詞去用同樣分詞器分詞并做好索引的數(shù)據(jù)庫中去查,對(duì)詞的匹配結(jié)果進(jìn)行打分排序,這樣就是全文搜索。
人工智能領(lǐng)域要處理的是自然語言,他也要按照詞法、語法、句法等等去“理解”,變成一定的數(shù)據(jù)結(jié)構(gòu)之后,計(jì)算機(jī)才懂才能處理,然后就是各種處理算法的介入了。
分詞是按照狀態(tài)機(jī)來分的(有限狀態(tài)機(jī) DFA),這個(gè)是干啥的,為啥分詞需要它,我知道你肯定有疑問。因?yàn)樵~法描述的是最小的單詞的格式,比如標(biāo)識(shí)符不能以數(shù)字開頭,然后后面加字母數(shù)字下劃線等,這種,還有關(guān)鍵字 if、while、continue 等,這些不能再細(xì)分了,再細(xì)分沒意義啊。分詞就是把字符串變成一個(gè)個(gè)的最小單元的不能再拆的單詞,也叫 token,因?yàn)椴煌膯卧~格式不同,總不能寫if else來處理不同的格式吧。其實(shí)還真可以,wenyan 就是if else,吐槽一下。但是當(dāng)有100中單詞的格式要處理,全部寫成if else,我的天,那代碼還能看么。所以要把每個(gè)單詞的處理過程當(dāng)成一種狀態(tài),處理到不同的單詞格式就跳到不同的狀態(tài),跳轉(zhuǎn)的方式自然是根據(jù)當(dāng)前處理的字符來的,處理一個(gè)字符串從開始狀態(tài)流轉(zhuǎn)到不同的狀態(tài)來處理,這樣就是狀態(tài)自動(dòng)機(jī),每個(gè)token識(shí)別完了就可以拋出來,最終產(chǎn)出的就是一個(gè)token數(shù)組。
其實(shí)狀態(tài)也不只一級(jí)的,你想想比如一個(gè) html 標(biāo)簽的開始標(biāo)簽,可以作為一個(gè)狀態(tài)來處理,但這個(gè)狀態(tài)內(nèi)部又要處理屬性、開始標(biāo)簽等,這就是二級(jí)狀態(tài),屬性又可以再細(xì)分幾個(gè)狀態(tài)來處理,這是三級(jí)狀態(tài),這是分治的思想,一層層的處理。
分詞之后我們拿到了一個(gè)個(gè)的單詞,之后要把這些單詞進(jìn)行組裝,生成 ast,為啥一定要ast呢?我知道你肯定想問。其實(shí)高級(jí)語言的代碼都是嵌套的,你看低級(jí)語言比如匯編,就是一條條指令,線性的結(jié)構(gòu),但是高級(jí)語言呢,有函數(shù)、if、else、while等各種塊,塊之間又可以嵌套。所以自然要組織成一棵樹形數(shù)據(jù)結(jié)構(gòu)讓計(jì)算機(jī)理解,就是Abtract Syntaxt Tree,語法樹、而且是抽象的,也就是忽略了一些沒有含義的分隔符,比如html的<、>、</等字符,js的{ }() [] ;就是細(xì)節(jié),不需要關(guān)心,注釋也會(huì)忽略掉,注釋只是分詞會(huì)分出來,但是不放到ast里面。
怎么組裝呢,還是嵌套的組裝,那是不是要遞歸組裝,是的,你想的沒錯(cuò)需要遞歸,不只是這里的ast組裝需要遞歸,后面的處理也很多遞歸,除非到了線性的代碼的階段,就像匯編那樣,你遞歸啥,沒嵌套的結(jié)構(gòu)可以遞歸了。
詞法我們剛才分析了,就是一個(gè)個(gè)的字符串格式,語法呢,是組裝格式,是單詞之間的組合方式。這也是為啥我們剛剛要先分詞了,要是直接從字符串來組裝ast,那么處理的是字符串級(jí)別,而從token開始是單詞級(jí)別, 這就像讓你用積木造個(gè)城堡,但是積木也要你自己用泥巴造,那你怎么造呢,可以先把一個(gè)個(gè)積木造好,然后再去組裝成城堡,也可以邊造積木邊組裝。不過小汽車的話你可以邊制作積木,邊組裝,城堡級(jí)別的邊做積木邊組裝你能理清要造啥積木么,就很難,所以還是要看情況。用這兩種方式來做parser的都有,簡單的可以邊詞法分析,分析出熱乎乎的單詞然后馬上組裝到ast中, 比如html、css這種,但是像js、c++這種,如果不先分詞,直接從字符串開始造ast,我只能說太生猛了。
說了半天積木和組裝,那么怎么組裝呢,從左到右的處理token,遇到一個(gè)token怎么知道他是啥語法呢,這就像怎么知道一塊積木是屬于那個(gè)部件的。也有兩種思路,一種是你先確定這個(gè)積木是屬于那個(gè)部件,然后找到那個(gè)部件的圖紙,按照?qǐng)D紙來組裝,另一種是你先組裝,組裝完了再看看這個(gè)是啥部件。這就是兩種方式,先根據(jù)一兩個(gè)積木確定是哪個(gè)部件,再按照?qǐng)D紙組裝這個(gè)部件,這種是 ll 的方式,先組裝,組裝完了看看是啥部件,這種是 lr 的方式。ll的方式要確定組裝的是啥ast節(jié)點(diǎn)要往下看幾個(gè),根據(jù)要看幾個(gè)來確定組裝的是什么就分別是LL(1),LL(2)等算法。ll也就是遞歸下降,這是最簡單的組裝方式,當(dāng)然有人覺得lr的方式也挺簡單。ll有個(gè)問題還必須得用lr解決,那就是遞歸下降遇到了左邊一直往下遞歸不到頭的情況,要消除左遞歸,也就是你按照?qǐng)D紙來組裝搞不定的時(shí)候,就先組裝再看看組裝出來的是啥吧。這其實(shí)和人生挺像的,一種方式是往下看兩步然后決定當(dāng)前怎么走,另一種方式是先走,走到哪步再說。其實(shí)我就屬于第二種,沒啥計(jì)劃性。
經(jīng)過詞法、語法分析之后就產(chǎn)生了ast。用一棵樹形的數(shù)據(jù)結(jié)構(gòu)來描述源代碼,從這里開始就是計(jì)算機(jī)可以理解的了,后續(xù)可以解釋執(zhí)行、可以編譯轉(zhuǎn)換。不管是解釋還是編譯都需要先parse,也就是要先讓計(jì)算機(jī)理解他是什么,然后再?zèng)Q定怎么處理。
后面把樹形的ast轉(zhuǎn)換為另一個(gè)ast,然后再打印成目標(biāo)代碼的字符串,這是轉(zhuǎn)譯器,把a(bǔ)st解釋執(zhí)行或者專成線性的中間代碼再解釋執(zhí)行,這是解釋器,把a(bǔ)st轉(zhuǎn)成線性中間代碼,然后生成匯編代碼,之后做匯編和鏈接,生成機(jī)器碼,這是編譯器。
編譯器是咋處理AST的?
昊昊:光哥,那編譯器是怎么處理ast的啊?
我:有了ast之后,計(jì)算機(jī)就能理解高級(jí)語言代碼了,但是編譯器要產(chǎn)生低級(jí)語言,比如匯編代碼,直接從ast開始距離比較遠(yuǎn)。因?yàn)橐粋€(gè)是嵌套的、樹形的,一個(gè)是線性的、順序的,所以啊,需要先轉(zhuǎn)成一種線性的代碼,再生成低級(jí)代碼。我覺得ast也可以算一種樹形IR,IR是immediate representation中間表示的意思。要先把AST轉(zhuǎn)成線性IR,然后再生成匯編、字節(jié)碼等。

咋翻譯,樹形的結(jié)構(gòu)咋變成線性的呢?明顯要遞歸啊,按照語法結(jié)構(gòu)遞歸ast,進(jìn)行每個(gè)節(jié)點(diǎn)的翻譯,這叫做語法制導(dǎo)翻譯,用線性IR中的指令來翻譯AST節(jié)點(diǎn)的屬性。每個(gè)節(jié)點(diǎn)的翻譯方式,if咋翻譯、while咋翻譯等可以去看下相關(guān)資料,搜中間代碼生成就好了。
但是ast不能上來就轉(zhuǎn)中間代碼。
昊昊:為啥,ast不就能表示源碼信息了么,為啥不能直接翻譯成線性ir?
我:因?yàn)檫€沒做語義檢查啊,結(jié)構(gòu)對(duì)不一定意思對(duì),就像“昊昊是只豬”,這個(gè)符合語法吧,但是語義明顯不對(duì)啊,這不是罵人么,所以要先做語義檢查。還有就是要推導(dǎo)出一些信息來,才能做后續(xù)的翻譯。
語義分析要檢查出語義的錯(cuò)誤,比如類型是否匹配、引用的變量是否存在、break是否在while中等,主要要做作用域分析、引用消解、類型推導(dǎo)和檢查、正確性檢查等。
作用域分析就是分析函數(shù)、塊等,這些作用域內(nèi)的變量都有啥,作用域之間的聯(lián)系是怎樣的,其實(shí)作用域是一棵樹,從頂層作用域到子作用域可以生成一個(gè)樹形數(shù)據(jù)結(jié)構(gòu)。我記得有個(gè)做scope分析的webpack插件,他是把模塊也給鏈接起來了,形成了一個(gè)大的 scope graph,然后做分析。
作用域中有各種聲明,要把它們的類型、初始值、訪問修飾符等信息記錄下來,保存這個(gè)信息的結(jié)構(gòu)叫符號(hào)表,這相當(dāng)于是一個(gè)緩存,之后處理這個(gè)符號(hào)的時(shí)候直接去查符號(hào)表就行,不用再次從ast來找。
引用消解呢就是對(duì)每個(gè)符號(hào)檢查下是否都能查找到定義,如果查找不到就報(bào)錯(cuò)。類型方面你比較熟,js的源碼中肯定不可能都寫類型,很多地方可以直接推導(dǎo)出來,根據(jù)ast可以得出類型的聲明,記錄到符號(hào)表中,之后遍歷ast,對(duì)各種節(jié)點(diǎn)取出聲明時(shí)的類型來進(jìn)行檢查,不一致就報(bào)錯(cuò)。還有其他一些瑣碎的檢查,比如continue、break只能出現(xiàn)在while中等等一些檢查。
昊昊:語義分析我懂了,就是檢查錯(cuò)誤和記錄一些分析出的信息到符號(hào)表,那語義分析之后呢?
語義分析之后就代表著程序已經(jīng)沒有語法和語義的錯(cuò)誤了,可以放心進(jìn)行各種后續(xù)轉(zhuǎn)換,不會(huì)再有開發(fā)者的錯(cuò)誤。之后先翻譯成線性IR,然后對(duì)線性IR進(jìn)行優(yōu)化,需要優(yōu)化就是因?yàn)樽詣?dòng)生成的代碼難免有很多冗余,需要把各種沒必要的處理去掉。但是要保證語義不變。比如死代碼刪除、公共子表達(dá)式刪除、常量傳播等等。
線性IR的分析要建立流圖,就是控制流圖,控制流就是根據(jù)if、while、函數(shù)調(diào)用等導(dǎo)致的程序跳轉(zhuǎn),把順序執(zhí)行的代碼和跳轉(zhuǎn)到的代碼之間連接起來就是一個(gè)圖,順序執(zhí)行的代碼看成一個(gè)整體,叫做基本快。之后根據(jù)這個(gè)流圖做數(shù)據(jù)流分析,也就是分析一個(gè)變量流經(jīng)了那些代碼,然后基于這些做各種優(yōu)化。
這個(gè)部分叫做程序分析,或者靜態(tài)分析,是一個(gè)專門的方向,可以用于代碼漏洞的靜態(tài)檢查,可以用于編譯優(yōu)化,這個(gè)是比較難的。研究這個(gè)的博士都比較少。國內(nèi)只有北大和南大開設(shè)程序分析課程。
優(yōu)化之后的線性IR就可以生成匯編代碼了,然后通過匯編器轉(zhuǎn)成機(jī)器碼,再鏈接一些標(biāo)準(zhǔn)庫,比如v8目錄下可以看到builtins目錄,這里就是各種編譯好的機(jī)器碼文件,可以靜態(tài)鏈接成一個(gè)可執(zhí)行文件。
昊昊:哦,感覺匯編和鏈接這兩步前端接觸不到啊。
我:對(duì)的,因?yàn)閖s是解釋型語言,直接從源碼解釋執(zhí)行,不要說js了,java的字節(jié)碼也不需要靜態(tài)鏈接。像c、c++這些生成可執(zhí)行文件的才需要通過匯編器把代碼專成機(jī)器碼然后鏈接成一個(gè)文件。而且如果目標(biāo)平臺(tái)有這些庫,那么不需要靜態(tài)鏈接到一起,可以動(dòng)態(tài)鏈接。你可能聽過.dll和.so這就分別是windows和linux的用于運(yùn)行時(shí)動(dòng)態(tài)加載的保存機(jī)器碼的文件。
你說的沒錯(cuò),前端領(lǐng)域基本不需要匯編和鏈接,就算是wasm,也是生成wasm 字節(jié)碼,之后解釋執(zhí)行。前端主要還是轉(zhuǎn)譯器。
轉(zhuǎn)譯器是咋處理AST的?
昊昊:那轉(zhuǎn)譯器在ast之后又做了哪些處理呢?
我:轉(zhuǎn)譯器的目標(biāo)代碼也是高級(jí)語言,也是嵌套的結(jié)構(gòu),所以從高級(jí)語言到高級(jí)語言是從樹形結(jié)構(gòu)到樹形結(jié)構(gòu),不像翻譯成低級(jí)的指令方式組織的語言,還得先翻譯成線性IR,高級(jí)到高級(jí)語言的轉(zhuǎn)換,只需要ast,對(duì)ast做各種轉(zhuǎn)換之后,就可以做代碼生成了。
昊昊:我說呢,我就沒聽說babel中有線性IR的概念。
我:對(duì)的,不管是跨語言的轉(zhuǎn)換,比如 ts 轉(zhuǎn) rust,還是同語言的轉(zhuǎn)換js轉(zhuǎn)js都不需要線性結(jié)構(gòu),兩棵樹的轉(zhuǎn)換要啥線性中間代碼啊。所以一般轉(zhuǎn)譯器都是 parse、transform、generate 這3個(gè)階段。

parse 廣義上來說包含詞法、語法和語義的分析,狹義的parse單指語法分析。這個(gè)不必糾結(jié)。
transform 就是對(duì)ast的增刪改,之后generator再把a(bǔ)st打印成字符串,我們解析ast的時(shí)候把[]{} () 等分隔符去掉了,generate的時(shí)候再把細(xì)節(jié)加回來。
其實(shí)前端領(lǐng)域主要還是轉(zhuǎn)譯器,因?yàn)橹髁鱦s引擎執(zhí)行的是源代碼,但是這個(gè)源代碼和我們寫的源代碼還不太一樣,所以前端很多源碼到源碼的轉(zhuǎn)譯器來做這種轉(zhuǎn)換,比如babel、typescript、terser、eslint、postcss、prettier等。
babel 是把高版本es代碼轉(zhuǎn)成低版本的,并且注入polyfill。typescript是類型檢查和轉(zhuǎn)成js代碼。eslint是根據(jù)規(guī)范檢查,但--fix也可以生成修復(fù)后的代碼。prettier也是用于格式化代碼的,比eslint處理的更多,不只限于js。postcss主要是處理css的,posthtml用于處理html。相信你也用過很多了。taro這種小程序轉(zhuǎn)譯器就是基于babel封裝的。
解釋器是咋處理AST的?
昊昊:哦,光哥,我大概知道編譯器和轉(zhuǎn)譯器都對(duì)ast做了啥處理了,這倆都是生成代碼的,那解釋器呢?
我:對(duì),首先轉(zhuǎn)譯器也是編譯器的一種,只不過比較特殊,叫做 transpiler,一般的編譯器叫做compiler。解釋器和編譯器的區(qū)別確實(shí)是是否生成代碼,提前編譯成機(jī)器代碼的叫做 AOT 編譯器,運(yùn)行時(shí)編譯成機(jī)器代碼的叫做 JIT 編譯器,
解釋器并不生成機(jī)器代碼,那它是怎么執(zhí)行的呢?知道你肯定有疑問。
其實(shí)解釋器是用一門高級(jí)語言來解釋另一門高級(jí)語言,比如c++,一般都用c++來寫解釋器,因?yàn)榭梢宰鰞?nèi)存管理。用c++來寫js解釋器,像v8、spidermonkey等都是。我們?cè)谟辛薬st并且做完語義分析之后就可以遍歷ast,然后用c++來執(zhí)行不同的節(jié)點(diǎn)了,這種叫做tree walker解釋器,直接解釋執(zhí)行ast,v8引擎在17年之前都是這么干的。但是在17年之后引入了字節(jié)碼,因?yàn)樽止?jié)碼可以緩存啊,這樣下次再直接執(zhí)行字節(jié)碼就不需要parse了。字節(jié)碼是種線性結(jié)構(gòu),也要做ast到線性ir的轉(zhuǎn)換,之后在vm上執(zhí)行字節(jié)碼。
一般解釋線性代碼的比如匯編代碼、字節(jié)碼等這種的程序才叫做虛擬機(jī),因?yàn)闄C(jī)器代碼就是線性的,其實(shí)從ast開始就可以解釋了,但是卻不叫vm,我覺得就是因?yàn)檫@個(gè),和機(jī)器碼比較像的線性代碼的解釋器才叫 vm。
不管是解釋 ast 也好,還是轉(zhuǎn)成字節(jié)碼再解釋也好,效率都不會(huì)特別高,因?yàn)槭怯脛e的高級(jí)語言來執(zhí)行當(dāng)前語言的代碼,所以要提高效率還是得編譯成機(jī)器代碼,這種運(yùn)行時(shí)編譯就是JIT編譯器,編譯是耗時(shí)的,所以也不是啥代碼都JIT,要做熱度的統(tǒng)計(jì),到達(dá)了閾值才會(huì)做JIT。然后把機(jī)器碼緩存下來,當(dāng)然也可能是緩存的匯編代碼,用到的時(shí)候再用匯編器轉(zhuǎn)成機(jī)器碼,因?yàn)闄C(jī)器代碼占的空間比較大。
可以對(duì)比v8來理解,v8 有parser、ignation解釋器、turbofan編譯器,還有g(shù)c。
ignation解釋器就是把parse出的ast轉(zhuǎn)成字節(jié)碼,然后解釋執(zhí)行字節(jié)碼,熱度到達(dá)閾值之后會(huì)交給turbofan編譯為匯編代碼之后生成機(jī)器代碼,來加速。gc是獨(dú)立的做內(nèi)存管理的。
turbofan是渦輪增壓器,這個(gè)名字就能體現(xiàn)出 JIT 的意義。但JIT提升了執(zhí)行速度,也有缺點(diǎn),比如會(huì)使得js引擎體積更大,占用內(nèi)存更大,所以輕量級(jí)的js引擎不包含jit,這就是運(yùn)行速度和包大小、內(nèi)存空間之間的權(quán)衡。架構(gòu)設(shè)計(jì)也經(jīng)常要做這種兩邊都可以,但是要做選擇的trade off,我們叫做方案勾兌。
說到權(quán)衡,我想起rn的js引擎hermes就改成支持直接執(zhí)行字節(jié)碼了,在編譯期間把js代碼編譯成字節(jié)碼,然后直接執(zhí)行字節(jié)碼,這就是在跨端領(lǐng)域的js引擎的trade off。
前端領(lǐng)域都有哪些地方用到編譯知識(shí)?
昊昊:哦,光哥,我明白解釋器、編譯器、轉(zhuǎn)譯器都干啥的了,那前端領(lǐng)域都有那些地方用到編譯原理的知識(shí)呢?
我:其實(shí)你也肯定有個(gè)大概的了解了,但是不夠明確,我列一下我知道的。
工程化領(lǐng)域各種轉(zhuǎn)譯器:babel、typescript、eslint、terser、prettier、postcss、posthtml、taro、vue template compiler等
js引擎:v8、javascriptcore、quickjs、hermes等
wasm:llvm可以生成wasm字節(jié)碼,所以c++、rust等可以轉(zhuǎn)為llvm ir的語言都可以做wasm開發(fā)
ide 的 lsp:編程語言的語法高亮、智能提示、錯(cuò)誤檢查等通過language service protocol協(xié)議來通信,而lsp服務(wù)端主要是基于parser對(duì)正在編輯的文本做分析
自己如何實(shí)現(xiàn)一門語言呢?
昊昊:我學(xué)了編譯原理可以實(shí)現(xiàn)一門語言么?
我:其實(shí)編程語言主要還是設(shè)計(jì),實(shí)現(xiàn)的話首先實(shí)現(xiàn) parser 和語義分析,后面分為兩條路,一種是解釋執(zhí)行的解釋器配合JIT編譯器的路,一種是編譯成匯編代碼碼,然后生成機(jī)器碼再鏈接成可執(zhí)行文件的編譯器的路。
parser部分比較繁瑣,可以用 antlr 這種parser生成器來生成,語義分析要自己寫,這個(gè)不太難,主要是對(duì)ast的各種處理。之后如果想做成編譯器,可以用 llvm 這種通用的優(yōu)化器和代碼生成器,clang、rust、swift都是基于它,所以很靠譜,可以直接用。如果做解釋器可以寫 tree walker解釋器,或者再進(jìn)一步生成線性字節(jié)碼,然后寫個(gè)vm來解釋字節(jié)碼。JIT編譯器也可以用llvm來做。要把a(bǔ)st轉(zhuǎn)成llvm ir,也是樹形結(jié)構(gòu)轉(zhuǎn)線性結(jié)構(gòu),這個(gè)還是編譯領(lǐng)域很常見的操作。
其實(shí)編譯原理只是告訴你怎么去實(shí)現(xiàn),語言設(shè)計(jì)不關(guān)心實(shí)現(xiàn),一門語言可以實(shí)現(xiàn)為編譯型也可以實(shí)現(xiàn)為解釋型,也可以做成 java 那種先編譯后解釋,你看 hermes(react native 實(shí)現(xiàn)的 js 引擎) 不就是先把 js 編譯為字節(jié)碼然后解釋執(zhí)行字節(jié)碼么。語言不分編譯解釋,這個(gè)概念要有,c也有解釋器,js也有編譯器,我們說一門語言是編譯型還是解釋型主要是主流的方式是編譯還是解釋來決定的。
編程語言可以分為 GPL 和 DSL 兩種。
GPL是通用編程語言,它是圖靈完備的,也就是能夠描述任何可計(jì)算問題,像c++、java、python、go、rust等這些語言都是圖靈完備的,所以一門語言能實(shí)現(xiàn)的另一門語言都能實(shí)現(xiàn),只不過實(shí)現(xiàn)難度不同。比如go語言內(nèi)置協(xié)程實(shí)現(xiàn),那么寫高并發(fā)程序就簡單,java沒有語言級(jí)別的協(xié)程,那么就要上層來實(shí)現(xiàn)。你可能聽到過設(shè)計(jì)模式是對(duì)語言缺陷的補(bǔ)充就是這個(gè)意思,不同語言設(shè)計(jì)思路不同,內(nèi)置的東西也不同,有的時(shí)候需要運(yùn)行時(shí)來彌補(bǔ)。、
編程語言有不同的設(shè)計(jì)思路,大的方向是編程范式,比如命令式、聲明式、函數(shù)式、邏輯式等,這些大的思路會(huì)導(dǎo)致語言的語法,內(nèi)置的實(shí)現(xiàn)都不同,表達(dá)能力也不同。這基本確定了語言基調(diào),后續(xù)再補(bǔ)也很難,就像js里面實(shí)現(xiàn)函數(shù)式,你又不能限制人家不能用命令式,就很難寫出純粹的函數(shù)式代碼。
DSL 不是圖靈完備的,卻換取了某領(lǐng)域的更強(qiáng)的表達(dá)能力,比如html、css、正則表達(dá)式,jq的選擇器語法等等,比較像一種偽代碼,特定領(lǐng)域的表達(dá)能力很強(qiáng),但是卻不是圖靈完備的不能描述所有可計(jì)算問題。
編譯原理是實(shí)現(xiàn)編程語言的步驟要學(xué)習(xí)的,更上層的語言設(shè)計(jì)還要學(xué)很多東西,最好能熟悉多門編程語言的特性。
我該怎么學(xué)習(xí)編譯原理呢?
昊昊:光哥,那我該怎么學(xué)習(xí)編譯原理呢?
我:首先你要理解編譯都學(xué)什么,看我上面對(duì)編譯、轉(zhuǎn)譯、解釋的科普大概能有個(gè)印象,然后查下相關(guān)資料。知道都可以干啥了之后先寫parser,因?yàn)椴还苌抖家萷arse成ast才能被“理解”和后續(xù)處理,學(xué)下有限狀態(tài)機(jī)來分詞和遞歸下降構(gòu)造ast。推薦看下vue template compiler 的 parser,這種xml的parser比較簡單,適合入門。語言級(jí)別的parser細(xì)節(jié)很多,還是得找一個(gè)來debug看。不過我覺得沒太大必要,一般也就寫個(gè)html parser,要是語言的,可以用antlr生成。轉(zhuǎn)譯器肯定要了解babel,這個(gè)是前端領(lǐng)域很不錯(cuò)的轉(zhuǎn)譯器。
js引擎可以嘗試用babel做parser,自己做語義分析,解釋執(zhí)行ast試試,之后進(jìn)一步生成字節(jié)碼或其他線性ir,然后寫個(gè)vm來解釋字節(jié)碼。
還可以學(xué)習(xí)wasm相關(guān)技術(shù),那個(gè)是涉及到其他語言編譯到wasm 字節(jié)碼的過程的。
當(dāng)你學(xué)完了編譯原理,就大概知道怎么實(shí)現(xiàn)一門編程語言了,之后想深入語言設(shè)計(jì)可以多學(xué)一些其他編程范式的語言,了解下各種語言特性,怎么設(shè)計(jì)一門表達(dá)性強(qiáng)的gpl或者dsl。
也可以進(jìn)一步學(xué)習(xí)一下操作系統(tǒng)和體系結(jié)構(gòu),因?yàn)榫幾g以后的代碼還是要在操作系統(tǒng)上以進(jìn)程的形式運(yùn)行的,那么運(yùn)行時(shí)該怎么設(shè)計(jì)就要了解操作系統(tǒng)了。然后cpu指令集是怎么用電路實(shí)現(xiàn)的,這個(gè)想深入可以去看下計(jì)算機(jī)體系結(jié)構(gòu)。
不過,前端工程師不需要達(dá)到那種深度,但是眼界開闊點(diǎn)沒啥壞處。
關(guān)注我,一起一步步“通關(guān)”前端工程化!