
我的 百度搜索記錄 被同事用Python監(jiān)控,我哭了!
來源 |?python數(shù)據(jù)分析之禪
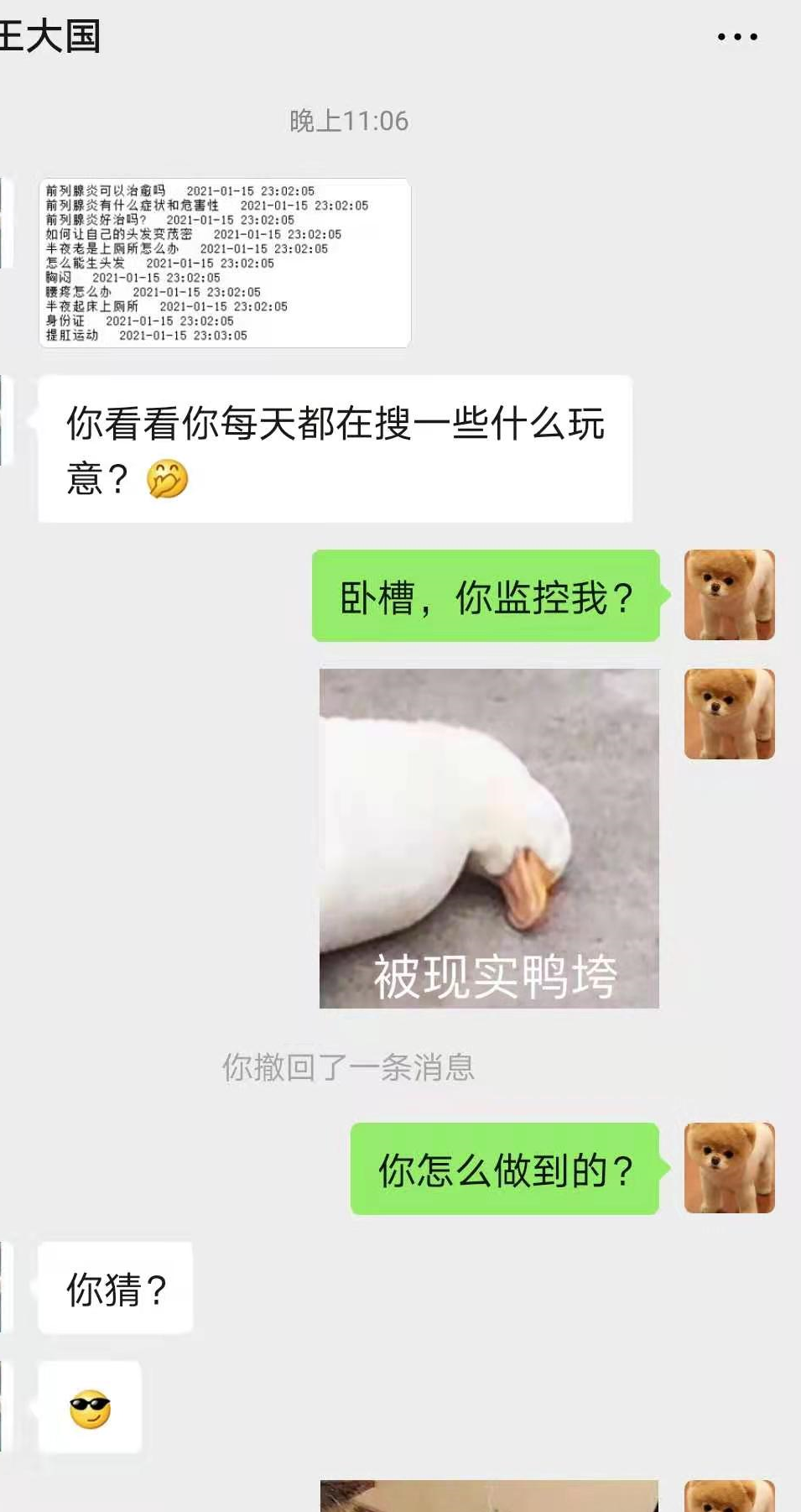
尷尬的想找個地縫鉆進去
經(jīng)過一番詢問,他終于道出了實情,原來百度的賬號會自動同步。
例如,在登錄了網(wǎng)頁版的百度地圖、百度API等賬號后,瀏覽器會自動保持,你的所有百度賬號就自動登上了。
當(dāng)你使用已登錄百度賬號手機或電腦的百度搜索框時,他那里就會自動彈出歷史搜索記錄,如下圖:

然后可以用python爬蟲定時獲取搜索記錄
首先抓包獲取數(shù)據(jù)接口:
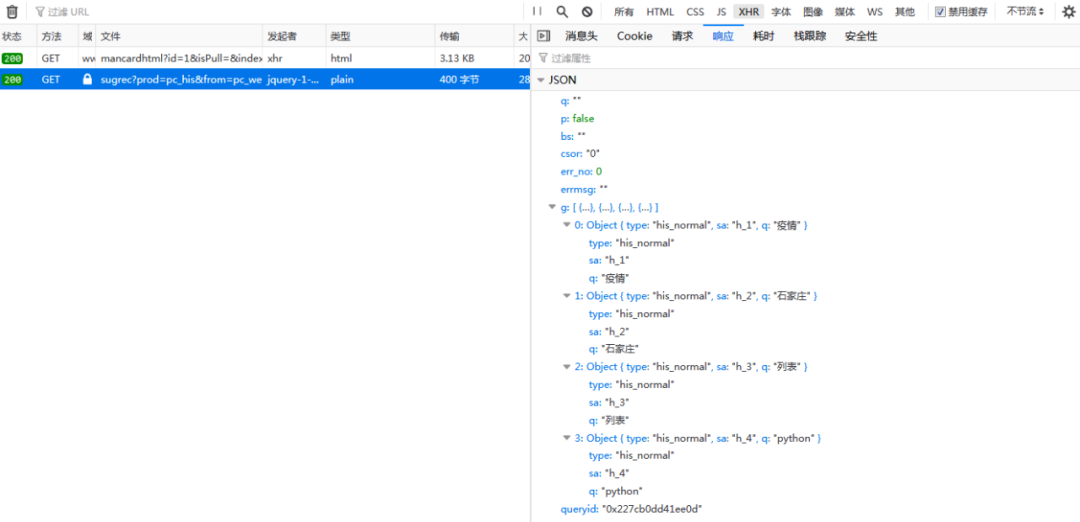
然后寫個小爬蟲,因為要有賬號信息,所以要帶上cookie:
import?requests
header={
????'User-Agent':'Mozilla/5.0?(Windows?NT?6.1;?Win64;?x64;?rv:82.0)?Gecko/20100101?Firefox/82.0',
????"Cookie":'',????
url='https://www.baidu.com/sugrec?prod=pc_his&from=pc_web&json=1'
response=requests.get(url,headers=header)
print(response.text)
UnicodeEncodeError: 'latin-1' codec can't encode character '\u2026' in position 518: ordinal not in range(256)但是你可能會遇到上面這種情況,報編碼錯誤
我去網(wǎng)上查了一下,以為是編碼的問題,然后給cookie加了“utf-8”編碼方式,如下:
import?requests
header={
????'User-Agent':'Mozilla/5.0?(Windows?NT?6.1;?Win64;?x64;?rv:82.0)?Gecko/20100101?Firefox/82.0',
????"Cookie":''.encode("utf-8"),
url='https://www.baidu.com/sugrec?prod=pc_his&from=pc_web&json=1'
response=requests.get(url,headers=header)
print(response.text)
{"err_no":0,"errmsg":"","queryid":"0x21a1c8a90872b8"}又報錯了。。。。。
就在我認為百度是不是有什么高端的反爬措施時,突然發(fā)現(xiàn)cookie的“BDUSS”參數(shù)有點問題,如下:
BDUSS=JkRjIyUFR2T01Yd3QxcTZ…AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAP4Gzl~-Bs5fZX中間多了省略號,這是因為字符太長了,被自動省略了,于是我趕緊把該參數(shù)補全,重新嘗試了一下:
import?requests
header={
????'User-Agent':'Mozilla/5.0?(Windows?NT?6.1;?Win64;?x64;?rv:82.0)?Gecko/20100101?Firefox/82.0',
????"Cookie":'',
}
url='https://www.baidu.com/sugrec?prod=pc_his&from=pc_web&json=1'
response=requests.get(url,headers=header)
print(response.text)
大功告成
最后加個循環(huán)程序:
import?requests
import?json
import?datetime,time
header={
????'User-Agent':'Mozilla/5.0?(Windows?NT?6.1;?Win64;?x64;?rv:82.0)?Gecko/20100101?Firefox/82.0',
????"Cookie":'',
}
url='https://www.baidu.com/sugrec?prod=pc_his&from=pc_web&json=1'
result=[]
while?True:
????dt?=?datetime.datetime.now().strftime('%Y-%m-%d?%H:%M:%S')?#時間戳
????response=requests.get(url,headers=header)
????datas=json.loads(response.text)['g']
????for?data?in?datas:
????????if?data['q']?not?in?result:
????????????print(data['q']+'???'+dt)
????????????result.append(data['q'])
????time.sleep(60)
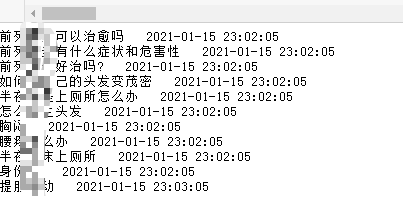
以自己的親身經(jīng)歷告訴大家,千萬不要在被人電腦上亂登賬號,小則丟人、大則丟金,切記切記!

評論
圖片
表情