
Elasticsearch 的 30 個(gè)調(diào)優(yōu)最佳實(shí)踐!
你知道的越多,不知道的就越多,業(yè)余的像一棵小草!
你來(lái),我們一起精進(jìn)!你不來(lái),我和你的競(jìng)爭(zhēng)對(duì)手一起精進(jìn)!
編輯:業(yè)余草
推薦:https://www.xttblog.com/?p=5263
ES 發(fā)布時(shí)帶有的默認(rèn)值,可為 es 的開(kāi)箱即用帶來(lái)很好的體驗(yàn)。全文搜索、高亮、聚合、索引文檔 等功能無(wú)需用戶修改即可使用,當(dāng)你更清楚的知道你想如何使用 es 后,你可以作很多的優(yōu)化以提高你的用例的性能,下面的內(nèi)容告訴你 你應(yīng)該/不應(yīng)該 修改哪些配置。
第一部分:調(diào)優(yōu)索引速度
?https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-indexing-speed.html
?
「使用批量請(qǐng)求批量請(qǐng)求將產(chǎn)生比單文檔索引請(qǐng)求好得多的性能。」
為了知道批量請(qǐng)求的最佳大小,您應(yīng)該在具有單個(gè)分片的單個(gè)節(jié)點(diǎn)上運(yùn)行基準(zhǔn)測(cè)試。首先嘗試索引 100 個(gè)文件,然后是 200,然后是 400,等等。當(dāng)索引速度開(kāi)始穩(wěn)定時(shí),您知道您達(dá)到了數(shù)據(jù)批量請(qǐng)求的最佳大小。在配合的情況下,最好在太少而不是太多文件的方向上犯錯(cuò)。請(qǐng)注意,如果群集請(qǐng)求太大,可能會(huì)使群集受到內(nèi)存壓力,因此建議避免超出每個(gè)請(qǐng)求幾十兆字節(jié),即使較大的請(qǐng)求看起來(lái)效果更好。

「發(fā)送端使用多 worker/多線程向 es 發(fā)送數(shù)據(jù) 發(fā)送批量請(qǐng)求的單個(gè)線程不太可能將 Elasticsearch 群集的索引容量最大化。為了使用集群的所有資源,您應(yīng)該從多個(gè)線程或進(jìn)程發(fā)送數(shù)據(jù)。除了更好地利用集群的資源,這應(yīng)該有助于降低每個(gè) fsync 的成本。」
請(qǐng)確保注意 TOOMANYREQUESTS(429)響應(yīng)代碼(Java客戶端的EsRejectedExecutionException),這是 Elasticsearch 告訴您無(wú)法跟上當(dāng)前索引速率的方式。發(fā)生這種情況時(shí),應(yīng)該再次嘗試暫停索引,理想情況下使用隨機(jī)指數(shù)回退。
與批量調(diào)整大小請(qǐng)求類似,只有測(cè)試才能確定最佳的 worker 數(shù)量。這可以通過(guò)逐漸增加工作者數(shù)量來(lái)測(cè)試,直到集群上的 I/O 或 CPU 飽和。
「1.調(diào)大 refresh interval」
默認(rèn)的 index.refresh_interval 是 1s,這迫使 Elasticsearch 每秒創(chuàng)建一個(gè)新的分段。增加這個(gè)價(jià)值(比如說(shuō) 30s)將允許更大的部分 flush 并減少未來(lái)的合并壓力。
「2.加載大量數(shù)據(jù)時(shí)禁用 refresh 和 replicas」
如果您需要一次加載大量數(shù)據(jù),則應(yīng)該將 index.refreshinterval 設(shè)置為 -1 并將 index.numberofreplicas 設(shè)置為 0 來(lái)禁用刷新。這會(huì)暫時(shí)使您的索引處于危險(xiǎn)之中,因?yàn)槿魏畏制膩G失都將導(dǎo)致數(shù)據(jù) 丟失,但是同時(shí)索引將會(huì)更快,因?yàn)槲臋n只被索引一次。初始加載完成后,您可以將 index.refreshinterval 和 index.numberofreplicas 設(shè)置回其原始值。
「3.設(shè)置參數(shù),禁止 OS 將 es 進(jìn)程 swap 出去」
您應(yīng)該確保操作系統(tǒng)不會(huì) swapping out the java 進(jìn)程,通過(guò)禁止 swap (https://www.elastic.co/guide/en/elasticsearch/reference/current/setup-configuration-memory.html)
「4.為 filesystem cache 分配一半的物理內(nèi)存」
文件系統(tǒng)緩存將用于緩沖 I/O 操作。您應(yīng)該確保將運(yùn)行 Elasticsearch 的計(jì)算機(jī)的內(nèi)存至少減少到文件系統(tǒng)緩存的一半。
「5.使用自動(dòng)生成的id(auto-generated ids)」
索引具有顯式 id 的文檔時(shí),Elasticsearch 需要檢查具有相同 id 的文檔是否已經(jīng)存在于相同的分片中,這是昂貴的操作,并且隨著索引增長(zhǎng)而變得更加昂貴。通過(guò)使用自動(dòng)生成的 ID,Elasticsearch 可以跳過(guò)這個(gè)檢查,這使索引更快。
「6.買(mǎi)更好的硬件」
搜索一般是 I/O 密集的,此時(shí),你需要
為 filesystem cache 分配更多的內(nèi)存
使用 SSD 硬盤(pán)
使用 local storage(不要使用 NFS、SMB 等 remote filesystem)
亞馬遜的 彈性塊存儲(chǔ)(Elastic Block Storage)也是極好的,當(dāng)然,和 local storage 比起來(lái),它還是要慢點(diǎn)
如果你的搜索是 CPU 密集的,買(mǎi)好的 CPU 吧
「7.加大 indexing buffer size」
如果你的節(jié)點(diǎn)只做大量的索引,確保 index.memory.indexbuffersize 足夠大,每個(gè)分區(qū)最多可以提供 512 MB 的索引緩沖區(qū),而且索引的性能通常不會(huì)提高。Elasticsearch 采用該設(shè)置(java 堆的一個(gè)百分比或絕對(duì)字節(jié)大小),并將其用作所有活動(dòng)分片的共享緩沖區(qū)。非常活躍的碎片自然會(huì)使用這個(gè)緩沖區(qū),而不是執(zhí)行輕量級(jí)索引的碎片。
「默認(rèn)值是 10%,通常很多:例如,如果你給 JVM 10GB 的內(nèi)存,它會(huì)給索引緩沖區(qū) 1GB,這足以承載兩個(gè)索引很重的分片。」
「8.禁用 fieldnames 字段」
fieldnames 字段引入了一些索引時(shí)間開(kāi)銷(xiāo),所以如果您不需要運(yùn)行存在查詢,您可能需要禁用它。(fieldnames:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-field-names-field.html)
「9.剩下的,再去看看 “調(diào)優(yōu) 磁盤(pán)使用”吧」
(https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-disk-usage.html)中有許多磁盤(pán)使用策略也提高了索引速度。
第二部分-調(diào)優(yōu)搜索速度
「1.filesystem cache越大越好」
為了使得搜索速度更快,es 嚴(yán)重依賴 filesystem cache
一般來(lái)說(shuō),需要至少一半的可用內(nèi)存 作為 filesystem cache,這樣es可以在物理內(nèi)存中 保有 索引的熱點(diǎn)區(qū)域(hot regions of the index)
「2.用更好的硬件」
搜索一般是 I/O bound 的,此時(shí),你需要
為 filesystem cache 分配更多的內(nèi)存
使用 SSD 硬盤(pán)
使用 local storage(不要使用NFS、SMB 等remote filesystem)
亞馬遜的 彈性塊存儲(chǔ)(Elastic Block Storage)也是極好的,當(dāng)然,和 local storage 比起來(lái),它還是要慢點(diǎn)
如果你的搜索是 CPU-bound,買(mǎi)好的 CPU 吧
「3.文檔模型(document modeling)」
文檔需要使用合適的類型,從而使得 search-time operations 消耗更少的資源。咋作呢?答:避免 join 操作。具體是指
nested 會(huì)使得查詢慢 好幾倍
parent-child關(guān)系 更是使得查詢慢幾百倍
如果 無(wú)需 join 能解決問(wèn)題,則查詢速度會(huì)快很多
「4.預(yù)索引 數(shù)據(jù)」
根據(jù)“搜索數(shù)據(jù)最常用的方式”來(lái)最優(yōu)化索引數(shù)據(jù)的方式
?舉個(gè)例子:所有文檔都有price字段,大部分query 在 fixed ranges 上運(yùn)行 range aggregation。你可以把給定范圍的數(shù)據(jù) 預(yù)先索引下。然后,使用 terms aggregation
?
「5.Mappings(能用 keyword 最好了)」
數(shù)字類型的數(shù)據(jù),并不意味著一定非得使用numeric類型的字段。
一般來(lái)說(shuō),存儲(chǔ)標(biāo)識(shí)符的 字段(書(shū)號(hào) ISBN、或來(lái)自數(shù)據(jù)庫(kù)的 標(biāo)識(shí)一條記錄的 數(shù)字),使用 keyword 更好(integer,long 不好哦,親)
「6.避免運(yùn)行腳本」
一般來(lái)說(shuō),腳本應(yīng)該避免。如果他們是絕對(duì)需要的,你應(yīng)該使用 painless 和 expressions 引擎。
「7.搜索 rounded 日期」
日期字段上使用 now,一般來(lái)說(shuō)不會(huì)被緩存。但,rounded date 則可以利用上query cache
rounded 到分鐘等
「8.強(qiáng)制 merge只讀的index」
只讀的 index 可以從“merge 成一個(gè)單獨(dú)的大 segment”中收益
「9.預(yù)熱 全局序數(shù)(global ordinals)」
全局序數(shù)用于在 keyword 字段上 運(yùn)行 terms aggregations。
es 不知道 哪些fields 將用于/不用于 term aggregation,因此 全局序數(shù)在需要時(shí)才加載進(jìn)內(nèi)存。
但,可以在 mapping type 上,定義 eagerglobalordinals==true,這樣, refresh 時(shí)就會(huì)加載 全局序數(shù)
「10.預(yù)熱 filesystem cache」
機(jī)器重啟時(shí),filesystem cache 就被清空。OS 將 index 的熱點(diǎn)區(qū)域(hot regions of the index)加載進(jìn) filesystem cache 是需要花費(fèi)一段時(shí)間的。
設(shè)置 index.store.preload 可以告知 OS 這些文件需要提早加載進(jìn)入內(nèi)存
「11.使用索引排序來(lái)加速連接」
索引排序?qū)τ谝暂^慢的索引為代價(jià)來(lái)加快連接速度非常有用。在索引分類文檔中閱讀更多關(guān)于它的信息。
「12.使用 preference 來(lái)優(yōu)化高速緩存利用率」
有多個(gè)緩存可以幫助提高搜索性能,例如文件系統(tǒng)緩存,請(qǐng)求緩存或查詢緩存。然而,所有這些緩存都維護(hù)在節(jié)點(diǎn)級(jí)別,這意味著如果連續(xù)運(yùn)行兩次相同的請(qǐng)求,則有一個(gè)或多個(gè)副本,并使用循環(huán)(默認(rèn)路由算法),那么這兩個(gè)請(qǐng)求將轉(zhuǎn)到不同的分片副本,阻止節(jié)點(diǎn)級(jí)別的緩存幫助。
由于搜索應(yīng)用程序的用戶一個(gè)接一個(gè)地運(yùn)行類似的請(qǐng)求是常見(jiàn)的,例如為了分析索引的較窄的子集,使用標(biāo)識(shí)當(dāng)前用戶或會(huì)話的優(yōu)選值可以幫助優(yōu)化高速緩存的使用。
「13.副本可能有助于吞吐量,但不會(huì)一直存在」
除了提高彈性外,副本可以幫助提高吞吐量。例如,如果您有單個(gè)分片索引和三個(gè)節(jié)點(diǎn),則需要將副本數(shù)設(shè)置為 2,以便共有 3 個(gè)分片副本,以便使用所有節(jié)點(diǎn)。
現(xiàn)在假設(shè)你有一個(gè) 2-shards 索引和兩個(gè)節(jié)點(diǎn)。在一種情況下,副本的數(shù)量是0,這意味著每個(gè)節(jié)點(diǎn)擁有一個(gè)分片。在第二種情況下,副本的數(shù)量是1,這意味著每個(gè)節(jié)點(diǎn)都有兩個(gè)碎片。哪個(gè)設(shè)置在搜索性能方面表現(xiàn)最好?通常情況下,每個(gè)節(jié)點(diǎn)的碎片數(shù)少的設(shè)置將會(huì)更好。
原因在于它將可用文件系統(tǒng)緩存的份額提高到了每個(gè)碎片,而文件系統(tǒng)緩存可能是 Elasticsearch 的 1 號(hào)性能因子。同時(shí),要注意,沒(méi)有副本的設(shè)置在發(fā)生單個(gè)節(jié)點(diǎn)故障的情況下會(huì)出現(xiàn)故障,因此在吞吐量和可用性之間進(jìn)行權(quán)衡。
那么復(fù)制品的數(shù)量是多少?如果您有一個(gè)具有 numnodes 節(jié)點(diǎn)的群集,那么numprimaries 總共是主分片,如果您希望能夠一次處理 maxfailures 節(jié)點(diǎn)故障,那么正確的副本數(shù)是 max(maxfailures,ceil(numnodes / numprimaries) - 1)。
「14.打開(kāi)自適應(yīng)副本選擇」
當(dāng)存在多個(gè)數(shù)據(jù)副本時(shí),elasticsearch 可以使用一組稱為自適應(yīng)副本選擇的標(biāo)準(zhǔn),根據(jù)包含分片的每個(gè)副本的節(jié)點(diǎn)的響應(yīng)時(shí)間,服務(wù)時(shí)間和隊(duì)列大小來(lái)選擇數(shù)據(jù)的最佳副本。這可以提高查詢吞吐量并減少搜索量大的應(yīng)用程序的延遲。
第三部分:通用的一些建議
「1、不要 返回大的結(jié)果集」
es 設(shè)計(jì)來(lái)作為搜索引擎,它非常擅長(zhǎng)返回匹配 query 的 top n 文檔。但,如“返回滿足某個(gè) query 的 所有文檔”等數(shù)據(jù)庫(kù)領(lǐng)域的工作,并不是 es 最擅長(zhǎng)的領(lǐng)域。如果你確實(shí)需要返回所有文檔,你可以使用 Scroll API
「2、避免 大的doc。即,單個(gè)doc 小了 會(huì)更好」
given that(考慮到) http.maxcontextlength 默認(rèn) ==100MB,es 拒絕索引操作 100MB 的文檔。當(dāng)然你可以提高這個(gè)限制,但,Lucene 本身也有限制的,其為2GB 即使不考慮上面的限制,大的 doc 會(huì)給 network/memory/disk 帶來(lái)更大的壓力;
任何搜索請(qǐng)求,都需要獲取 _id 字段,由于 filesystem cache 工作方式。即使它不請(qǐng)求 _source字段,獲取大 doc _id 字段消耗更大
索引大 doc 時(shí)消耗內(nèi)存會(huì)是 doc 本身大小的好幾倍
大 doc 的 proximity search, highlighting 也更加昂貴。它們的消耗直接取決于 doc 本身的大小
「3、避免 稀疏」
不相關(guān)數(shù)據(jù) 不要 放入同一個(gè)索引
一般化文檔結(jié)構(gòu)(Normalize document structures)
避免類型
在 稀疏 字段上,禁用 norms & doc_values 屬性
「稀疏為什么不好?」
Lucene 背后的數(shù)據(jù)結(jié)構(gòu)更擅長(zhǎng)處理緊湊的數(shù)據(jù)
text 類型的字段,norms 默認(rèn)開(kāi)啟;numerics, date, ip, keyword,docvalues 默認(rèn)開(kāi)啟 Lucene 內(nèi)部使用 integer 的 docid 來(lái)標(biāo)識(shí)文檔和內(nèi)部API 交互。
?舉個(gè)例子:使用 match 查詢時(shí)生成 docid 的迭代器,這些 docid 被用于獲取它們的norm,以便計(jì)算 score。當(dāng)前的實(shí)現(xiàn)是每個(gè) doc 中保留一個(gè) byte 用于存儲(chǔ) norm 值。獲取 norm 值其實(shí)就是讀取 doc_id 位置處的一個(gè)字節(jié)
?
這非常高效,Lucene 通過(guò)此值可以快速訪問(wèn)任何一個(gè) doc 的 norm 值;但,給定一個(gè) doc,即使某個(gè) field 沒(méi)有值,仍需要為此 doc 的此 field 保留一個(gè)字節(jié)
docvalues 也有同樣的問(wèn)題。2.0 之前的 fielddata 被現(xiàn)在的 docvalues 所替代了。
稀疏性 最明顯的影響是 對(duì)存儲(chǔ)的需求(任何 doc 的每個(gè) field,都需要一個(gè)byte);但是呢,稀疏性 對(duì) 索引速度和查詢速度 也是有影響的,因?yàn)椋杭词?doc并沒(méi)有某些字段值,但,索引時(shí),依然需要寫(xiě)這些字段,查詢時(shí),需要 skip 這些字段的值
某個(gè)索引中擁有少量稀疏字段,這完全沒(méi)有問(wèn)題。但,這不應(yīng)該成為常態(tài)
稀疏性影響最大的是 norms&docvalues ,但,倒排索引(用于索引 text以及keyword字段),二維點(diǎn)(用于索引geopoint字段)也會(huì)受到較小的影響。
「如何避免稀疏呢?」
1、不相關(guān)數(shù)據(jù) 不要 放入同一個(gè)索引 給個(gè)tip:索引小(即:doc的個(gè)數(shù)較少),則,primary shard也要少
2、一般化文檔結(jié)構(gòu)(Normalize document structures)
3、避免類型(Avoid mapping type) 同一個(gè)index,最好就一個(gè)mapping type。在同一個(gè)index下面,使用不同的mapping type來(lái)存儲(chǔ)數(shù)據(jù),聽(tīng)起來(lái)不錯(cuò),但,其實(shí)不好。given that(考慮到)每一個(gè)mapping type會(huì)把數(shù)據(jù)存入 同一個(gè)index,因此,多個(gè)不同mapping type,各個(gè)的field又互不相同,這同樣帶來(lái)了稀疏性 問(wèn)題
4、在 稀疏 字段上,禁用 norms & doc_values 屬性
norms用于計(jì)算score,無(wú)需score,則可以禁用它(所有filtering字段,都可以禁用norms)
docvlaues用于sort&aggregations,無(wú)需這兩個(gè),則可以禁用它 但是,不要輕率的做出決定,因?yàn)?norms&docvalues無(wú)法修改。只能reindex
「秘訣1:混合 精確查詢和提取詞干(mixing exact search with stemming)」
對(duì)于搜索應(yīng)用,提取詞干(stemming)都是必須的。例如:查詢 skiing時(shí),ski和skis都是期望的結(jié)果
但,如果用戶就是要查詢skiing呢?
解決方法是:使用multi-field。同一份內(nèi)容,以兩種不同的方式來(lái)索引存儲(chǔ) query.simplequerystring.quotefieldsuffix,竟然是 查詢完全匹配的
「秘訣2:獲取一致性的打分」
score不能重現(xiàn) 同一個(gè)請(qǐng)求,連續(xù)運(yùn)行2次,但,兩次返回的文檔順序不一致。這是相當(dāng)壞的用戶體驗(yàn)
如果存在 replica,則就可能發(fā)生這種事,這是因?yàn)椋簊earch時(shí),replication group中的shard是按round-robin方式來(lái)選擇的,因此兩次運(yùn)行同樣的請(qǐng)求,請(qǐng)求如果打到 replication group中的不同shard,則兩次得分就可能不一致
那問(wèn)題來(lái)了,“你不是整天說(shuō) primary和replica是in-sync的,是完全一致的”嘛,為啥打到“in-sync的,完全一致的shard”卻算出不同的得分?
原因就是標(biāo)注為“已刪除”的文檔。如你所知,doc更新或刪除時(shí),舊doc并不刪除,而是標(biāo)注為“已刪除”,只有等到 舊doc所在的segment被merge時(shí),“已刪除”的doc才會(huì)從磁盤(pán)刪除掉
索引統(tǒng)計(jì)(index statistic)是打分時(shí)非常重要的一部分,但,由于 deleted doc 的存在,在同一個(gè)shard的不同copy(即:各個(gè)replica)上 計(jì)算出的 索引統(tǒng)計(jì) 并不一致
個(gè)人理解:
所謂 索引統(tǒng)計(jì) 應(yīng)該就是df,即 doc_freq
索引統(tǒng)計(jì) 是基于shard來(lái)計(jì)算的
搜索時(shí),“已刪除”的doc 當(dāng)然是 永遠(yuǎn)不會(huì) 出現(xiàn)在 結(jié)果集中的 索引統(tǒng)計(jì)時(shí),for practical reasons,“已刪除”doc 依然是統(tǒng)計(jì)在內(nèi)的
假設(shè),shard A0 剛剛完成了一次較大的segment merge,然后移除了很多“已刪除”doc,shard A1 尚未執(zhí)行 segment merge,因此 A1 依然存在那些“已刪除”doc
于是:兩次請(qǐng)求打到 A0 和 A1 時(shí),兩者的 索引統(tǒng)計(jì) 是顯著不同的
「如何規(guī)避 score 不能重現(xiàn) 的問(wèn)題?使用 preference 查詢參數(shù)」
發(fā)出搜索請(qǐng)求時(shí)候,用標(biāo)識(shí)字符串來(lái)標(biāo)識(shí)用戶,將標(biāo)識(shí)字符串作為查詢請(qǐng)求的 preference參數(shù)。這確保多次執(zhí)行同一個(gè)請(qǐng)求時(shí)候,給定用戶的請(qǐng)求總是達(dá)到同一個(gè) shard,因此得分會(huì)更為一致(當(dāng)然,即使同一個(gè) shard,兩次請(qǐng)求 跨了 segment merge,則依然會(huì)得分不一致)
這個(gè)方式還有另外一個(gè)優(yōu)點(diǎn),當(dāng)兩個(gè) doc 得分一致時(shí),則默認(rèn)按著 doc 的內(nèi)部 Lucene doc id 來(lái)排序(注意:這并不是es中的 _id 或 _uid)。但是呢,shard 的不同 copy 間,同一個(gè) doc 的內(nèi)部 Lucene doc id 可能并不相同。因此,如果總是達(dá)到同一個(gè) shard,則,具有相同得分的兩個(gè) doc,其順序是一致的
「score錯(cuò)了」
score 錯(cuò)了(Relevancy looks wrong)
如果你發(fā)現(xiàn)
具有相同內(nèi)容的文檔,其得分不同
完全匹配 的查詢 并沒(méi)有排在第一位 這可能都是由 sharding 引起的
默認(rèn)情況下,搜索文檔時(shí),每個(gè)shard自己計(jì)算出自己的得分。
索引統(tǒng)計(jì) 又是打分時(shí)一個(gè)非常重要的因素。
如果每個(gè) shard 的 索引統(tǒng)計(jì)相似,則 搜索工作的很好
文檔是平分到每個(gè) primary shard 的,因此 索引統(tǒng)計(jì) 會(huì)非常相似,打分也會(huì)按著預(yù)期工作。但,萬(wàn)事都有個(gè)但是:
索引時(shí)使用了 routing(文檔不能平分到每個(gè)primary shard 啦)
查詢多個(gè)索引
索引中文檔的個(gè)數(shù) 非常少
這會(huì)導(dǎo)致:參與查詢的各個(gè) shard,各自的 索引統(tǒng)計(jì) 并不相似(而,索引統(tǒng)計(jì)對(duì) 最終的得分 又影響巨大),于是 打分出錯(cuò)了(relevancy looks wrong)
「那,如何繞過(guò) score錯(cuò)了(Relevancy looks wrong)?」
如果數(shù)據(jù)集較小,則,只使用一個(gè) primary shard(es 默認(rèn)是5個(gè)),這樣兩次查詢 索引統(tǒng)計(jì) 不會(huì)變化,因而得分也就一致啦
另一種方式是,將 searchtype 設(shè)置為:dfsquerythenfetech(默認(rèn)是querythenfetch)
dfsquerythen_fetch 的作用是
向 所有相關(guān) shard 發(fā)出請(qǐng)求,要求 所有相關(guān)shard 返回針對(duì)當(dāng)前查詢的 索引統(tǒng)計(jì)
然后,coordinating node 將 merge這些 索引統(tǒng)計(jì),從而得到 merged statistics
coordinating node 要求 所有相關(guān)shard 執(zhí)行 query phase,于是 發(fā)出請(qǐng)求,這時(shí),也帶上 merged statistics。這樣,執(zhí)行query的shard 將使用 全局的索引統(tǒng)計(jì)
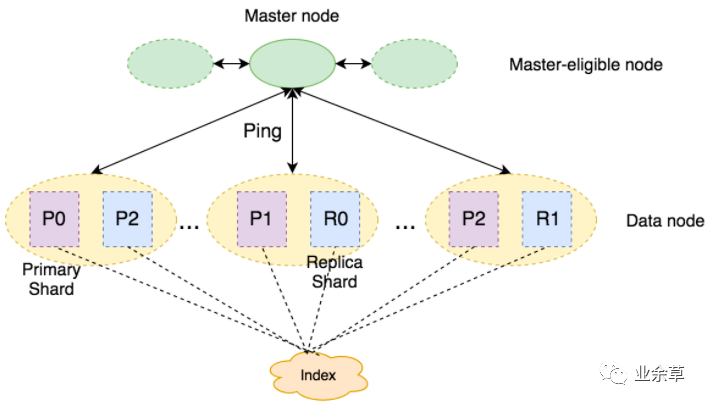
大部分情況下,要求 所有相關(guān) shard 返回針對(duì)當(dāng)前查詢的 索引統(tǒng)計(jì),這是非常cheap的。但,如果查詢中 包含 非常大量的 字段/term查詢,或者有 fuzzy 查詢,此時(shí),獲取 索引統(tǒng)計(jì) 可能并不 cheap,因?yàn)?為了得到 索引統(tǒng)計(jì) 可能 term dictionary 中 所有的 term 都需要被查詢一遍。
英文原文:https://www.elastic.co/guide/en/elasticsearch/reference/current/how-to.html