
集成YYDS!讓你的模型更快更準(zhǔn)!
 點(diǎn)藍(lán)色字關(guān)注“機(jī)器學(xué)習(xí)算法工程師”
點(diǎn)藍(lán)色字關(guān)注“機(jī)器學(xué)習(xí)算法工程師”
設(shè)為星標(biāo),干貨直達(dá)!
集成學(xué)習(xí)是機(jī)器學(xué)習(xí)中重要的分支,比如常用的Bagging和Boosting方法,以及一些機(jī)器學(xué)習(xí)模型如Random Forest,AdaBoost也都屬于集成學(xué)習(xí)的范疇。在深度學(xué)習(xí)領(lǐng)域,通過集成多個模型往往也能提升效果,但模型集成相比單個模型的效率并沒有得到系統(tǒng)的研究。近期,Google的一篇論文Wisdom of Committees: An Overlooked Approach To Faster and More Accurate Models系統(tǒng)地研究了基于委員會的模型(committee-based models,即model ensembles or cascades)的效率問題,發(fā)現(xiàn)最簡單的模型集成或級聯(lián)方法就能達(dá)到甚至超過單個SOTA模型的精度,而且計算量和速度上更有優(yōu)勢,比如兩個EfficientNet-B5模型集成可以達(dá)到EfficientNet-B7的精度,但是FLOPs降低了50%(20.5B vs 37B),而級聯(lián)兩個EfficientNet-B5模型同樣能達(dá)到相同的精度,但FLOPs可以進(jìn)一步降低到13.1B。論文雖然主要研究了模型集成和級聯(lián)在圖像分類問題上的效率,但也在其它任務(wù)上(視頻分類和語義分割)做了進(jìn)一步驗證。本文將簡單介紹這篇論文的主要研究內(nèi)容以及結(jié)論。
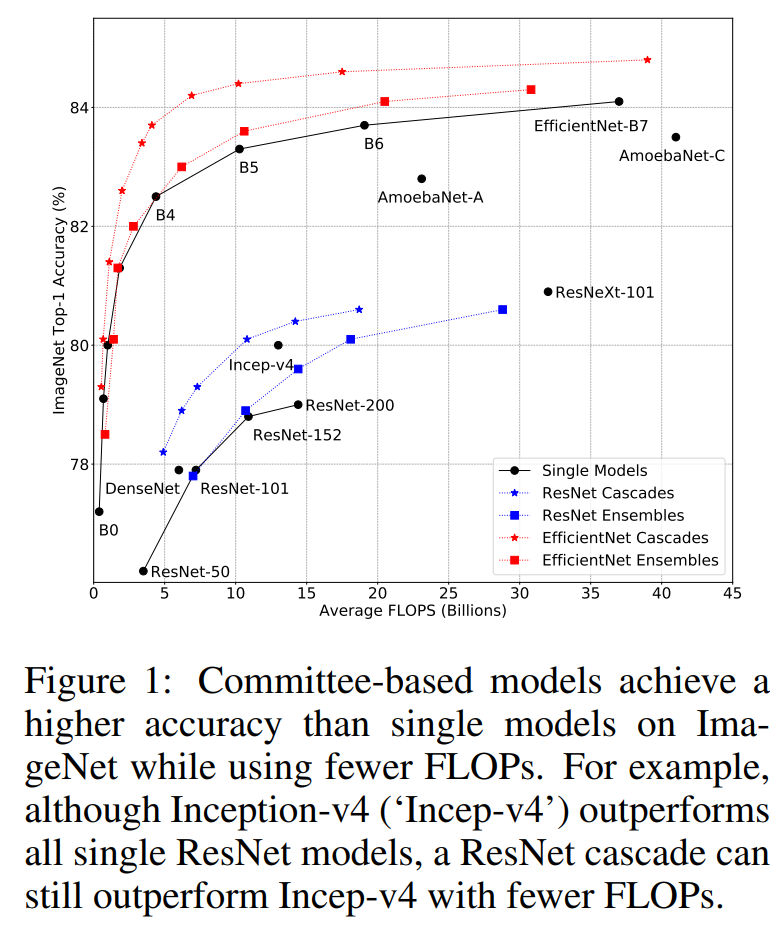
模型集成
眾所周知,集成多個模型往往能提升準(zhǔn)確度,但引入了額外的計算量;如果固定計算量,那么模型集成是否能夠超越單個模型呢?這里以三個不同的圖像分類模型EfficientNet,ResNet和MobileNetV2在ImageNet數(shù)據(jù)集上的表現(xiàn)來研究這個問題,這個三個架構(gòu)都包含一系列不同計算量和分類準(zhǔn)確度的模型,比如EfficientNet從B0到B7,模型FLOPs增加的同時分類準(zhǔn)確度也同步增加。對每個架構(gòu),可以訓(xùn)練很多的模型(對于同樣的模型設(shè)定,可以采用不同的隨機(jī)種子訓(xùn)練多個模型)來進(jìn)行集成來和單個模型進(jìn)行對比。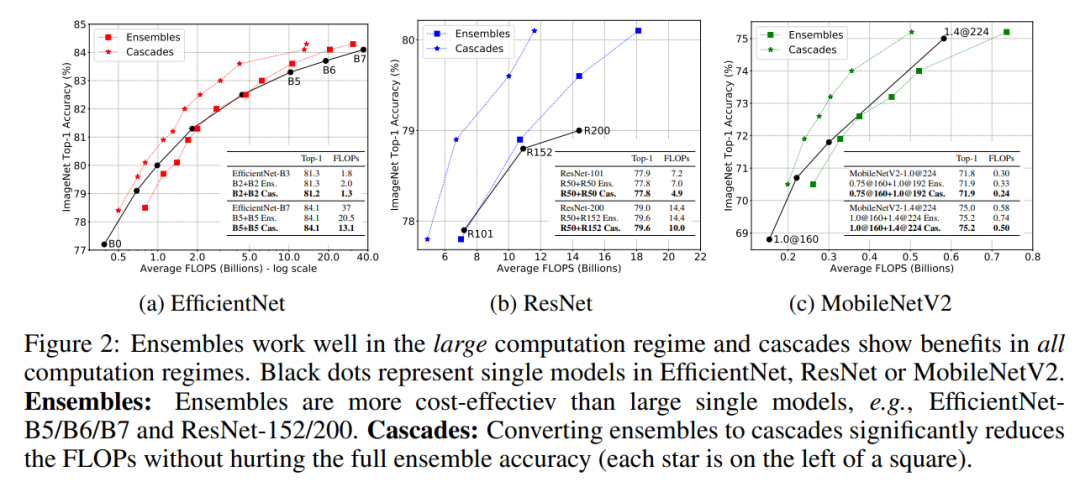 集成策略可以采用最簡單的求平均方法:假定要對個不同的模型進(jìn)行集成,對于給定的輸入圖像,模型預(yù)測的logits為(分類層的輸出向量),取各個模型預(yù)測logits的平均值來作為模型集成的預(yù)測結(jié)果(用模型預(yù)測分類概率取平均是模型集成更常用的方法,不過論文實驗發(fā)現(xiàn)兩種方案效果是類似的),直接對logits取argmax就可以得到預(yù)測的分類類別。模型集成后的FLOPs是各個模型的FLOPs之和。模型集成和單個模型的對比效果如上圖所示,可以看到:
集成策略可以采用最簡單的求平均方法:假定要對個不同的模型進(jìn)行集成,對于給定的輸入圖像,模型預(yù)測的logits為(分類層的輸出向量),取各個模型預(yù)測logits的平均值來作為模型集成的預(yù)測結(jié)果(用模型預(yù)測分類概率取平均是模型集成更常用的方法,不過論文實驗發(fā)現(xiàn)兩種方案效果是類似的),直接對logits取argmax就可以得到預(yù)測的分類類別。模型集成后的FLOPs是各個模型的FLOPs之和。模型集成和單個模型的對比效果如上圖所示,可以看到:
對于大計算量設(shè)置,達(dá)到同樣的分類性能,模型集成要比單個模型在計算上更高效,比如對于EfficientNetB5/B6/B7和ResNet-152/200模型,集成后的模型的FLOPs要更小; 對于小計算量設(shè)置,達(dá)到同樣的分類性能,單個模型比模型集成更高效,比如對于MobileNetV2模型,集成后的模型的FLOPs更大一些;
對于這種現(xiàn)象,可以用機(jī)器學(xué)習(xí)中的bias-variance tradeoff理論給出一個合理的解釋。大模型擁有小的bias但大的variance,此時variance對測試誤差影響較大,而模型集成能有效降低variance;但是小模型的bias大,此時bias往往主導(dǎo)測試誤差,模型集成帶來的variance收益無法抵消小模型bias的影響。
上面的實驗可以看出對于大模型,通過模型集成可以在達(dá)到相同的性能時降低計算量,而且多個模型還可以并行計算從進(jìn)一步加速。同時,模型集成的總訓(xùn)練時間也是優(yōu)于單個模型的,比如兩個EfficientNetB5模型的訓(xùn)練總時長為96,,比單個EfficientNetB7的訓(xùn)練時長160要小不少,但集成后與單個模型效果相當(dāng)。
模型級聯(lián)
模型集成雖然簡單,但是存在計算冗余,因為大量的簡單樣本只需要單個模型就能給出正確的分類結(jié)果。一種有效降低計算量的方法是采用模型級聯(lián)(model cascades),模型集成是并行計算多個模型,而級聯(lián)是串行計算多個模型,它允許中間提前終止計算,從而減少計算量,具體如下: 可以看到級聯(lián)是逐漸地集成多個模型,如果中間滿足了一定條件,就終止后面模型的計算。這里需要一個置信度函數(shù)(confidence function)來決定是否停止后面模型的使用,這個置信度函數(shù)能給出模型對當(dāng)前樣本預(yù)測的確信度,如果模型對預(yù)測結(jié)果已經(jīng)很確信了,那么就沒有必要集成后面的模型了。一種最簡單的置信度函數(shù)是計算模型預(yù)測的最大概率值:,因為往往預(yù)測概率值越大,模型的預(yù)測越準(zhǔn)確,實際上論文實驗發(fā)現(xiàn)大部分的模型存在稍微的underconfident,如下圖所示,比如模型的預(yù)測概率為0.6時,模型的分類準(zhǔn)確度理論上要接近60%,但實際上模型分類準(zhǔn)確度比這個值要高一些(紅色線),這說明模型對自己的預(yù)測有點(diǎn)不自信(低估了自己的能力),對于這種問題,可以通過模型校準(zhǔn)來解決(藍(lán)色線),不過論文發(fā)現(xiàn)校準(zhǔn)幾乎不影響效果,這大概是模型只存在少量的underconfident。
可以看到級聯(lián)是逐漸地集成多個模型,如果中間滿足了一定條件,就終止后面模型的計算。這里需要一個置信度函數(shù)(confidence function)來決定是否停止后面模型的使用,這個置信度函數(shù)能給出模型對當(dāng)前樣本預(yù)測的確信度,如果模型對預(yù)測結(jié)果已經(jīng)很確信了,那么就沒有必要集成后面的模型了。一種最簡單的置信度函數(shù)是計算模型預(yù)測的最大概率值:,因為往往預(yù)測概率值越大,模型的預(yù)測越準(zhǔn)確,實際上論文實驗發(fā)現(xiàn)大部分的模型存在稍微的underconfident,如下圖所示,比如模型的預(yù)測概率為0.6時,模型的分類準(zhǔn)確度理論上要接近60%,但實際上模型分類準(zhǔn)確度比這個值要高一些(紅色線),這說明模型對自己的預(yù)測有點(diǎn)不自信(低估了自己的能力),對于這種問題,可以通過模型校準(zhǔn)來解決(藍(lán)色線),不過論文發(fā)現(xiàn)校準(zhǔn)幾乎不影響效果,這大概是模型只存在少量的underconfident。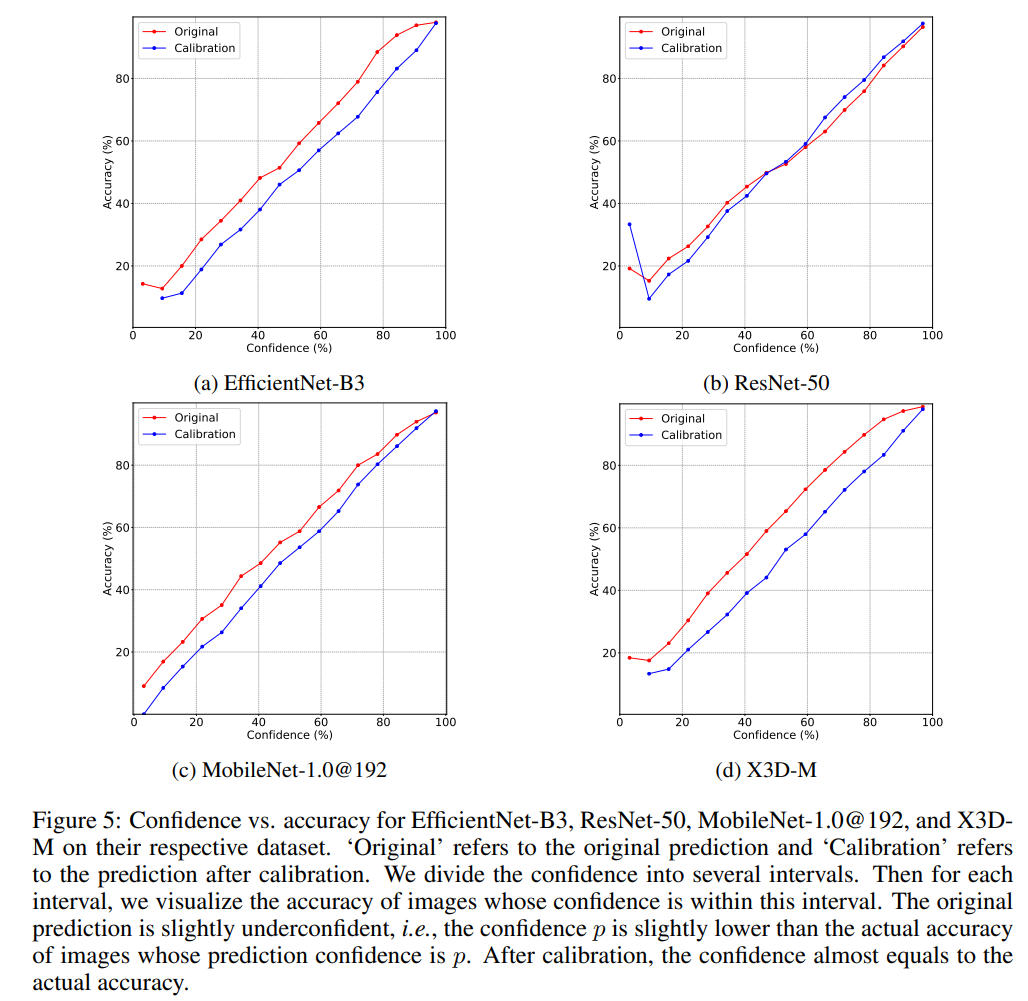 除了用最大預(yù)測概率作為置信度外,還可以用其它的指標(biāo),比如用最大的概率和第二大概率的gap,最大的logits和第二大logits的gap以及預(yù)測分布的負(fù)熵,它們都表現(xiàn)相似的性能,如下圖所示(按置信度排序,計算不同topk樣本下的準(zhǔn)確度),論文默認(rèn)采用最大概率。
除了用最大預(yù)測概率作為置信度外,還可以用其它的指標(biāo),比如用最大的概率和第二大概率的gap,最大的logits和第二大logits的gap以及預(yù)測分布的負(fù)熵,它們都表現(xiàn)相似的性能,如下圖所示(按置信度排序,計算不同topk樣本下的準(zhǔn)確度),論文默認(rèn)采用最大概率。 除了置信度函數(shù),個模型級聯(lián)還需要確定個閾值,當(dāng)置信度大于這個閾值時,說明模型預(yù)測比較自信,就停止后面的模型計算。當(dāng)置信度選擇最大概率時,閾值取值范圍為[0,1],閾值越小,后面模型集成的概率越小,當(dāng)為0時就退化成單個模型,而為1時就變成完全的模型集成了。模型級聯(lián)的FLOPs是變動的,但可以用驗證集上所有圖片的FLOPs的平均值來表示。當(dāng)閾值從0到1變化時,F(xiàn)LOPs是逐漸增加的,只到全部模型的FLOPs之和。下圖展示了模型級聯(lián)在閾值變化下FLOPs和分類準(zhǔn)確度的變化,可以看到每個曲線都會收斂到一條平線,這說明模型級聯(lián)在達(dá)到和模型集成相似的效果下大大降低計算量。如果將之前的模型集成直接轉(zhuǎn)成模型級聯(lián),模型級聯(lián)在不同架構(gòu)和不同計算量設(shè)置下均比單個模型計算更高效(見文中第2個圖)。
除了置信度函數(shù),個模型級聯(lián)還需要確定個閾值,當(dāng)置信度大于這個閾值時,說明模型預(yù)測比較自信,就停止后面的模型計算。當(dāng)置信度選擇最大概率時,閾值取值范圍為[0,1],閾值越小,后面模型集成的概率越小,當(dāng)為0時就退化成單個模型,而為1時就變成完全的模型集成了。模型級聯(lián)的FLOPs是變動的,但可以用驗證集上所有圖片的FLOPs的平均值來表示。當(dāng)閾值從0到1變化時,F(xiàn)LOPs是逐漸增加的,只到全部模型的FLOPs之和。下圖展示了模型級聯(lián)在閾值變化下FLOPs和分類準(zhǔn)確度的變化,可以看到每個曲線都會收斂到一條平線,這說明模型級聯(lián)在達(dá)到和模型集成相似的效果下大大降低計算量。如果將之前的模型集成直接轉(zhuǎn)成模型級聯(lián),模型級聯(lián)在不同架構(gòu)和不同計算量設(shè)置下均比單個模型計算更高效(見文中第2個圖)。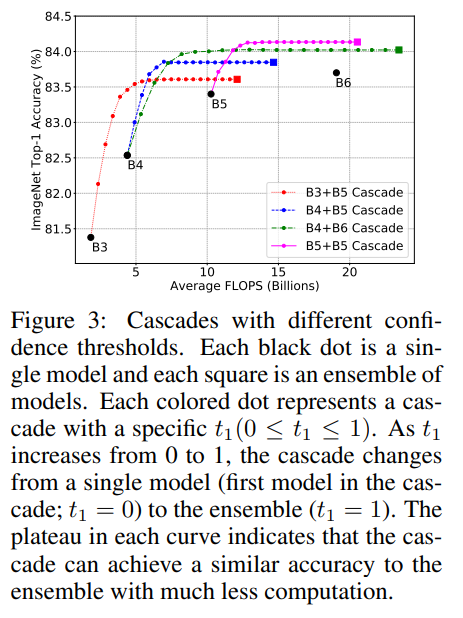
模型級聯(lián)涉及組合不同的模型,而且也需要確定閾值超參數(shù),在特定的條件下,這就變成了一個尋優(yōu)問題。假定為模型候選集(可用于級聯(lián)的模型集合),并限制FLOPs不能超過,模型級聯(lián)共選擇個模型,閾值設(shè)定為,此時就需要求解一個約束優(yōu)化問題: 同樣地,如果限定的條件是分類準(zhǔn)確度下限,那么優(yōu)化目標(biāo)變成了最小化FLOPs。由于現(xiàn)實中和往往較小,比如EfficientNet架構(gòu)設(shè)定,此時這個優(yōu)化問題可以用窮舉法來求解。下表給出了兩種不同的限定條件下,EfficientNet,ResNet和MobileNetV2三種不同的架構(gòu)模型級聯(lián)的效果。可以看到,在相似的FLOPs下,模型級聯(lián)的分類準(zhǔn)確度要比單個模型有提升;而在相似的分類準(zhǔn)確度下,模型級聯(lián)的計算量較單個模型降低。
同樣地,如果限定的條件是分類準(zhǔn)確度下限,那么優(yōu)化目標(biāo)變成了最小化FLOPs。由于現(xiàn)實中和往往較小,比如EfficientNet架構(gòu)設(shè)定,此時這個優(yōu)化問題可以用窮舉法來求解。下表給出了兩種不同的限定條件下,EfficientNet,ResNet和MobileNetV2三種不同的架構(gòu)模型級聯(lián)的效果。可以看到,在相似的FLOPs下,模型級聯(lián)的分類準(zhǔn)確度要比單個模型有提升;而在相似的分類準(zhǔn)確度下,模型級聯(lián)的計算量較單個模型降低。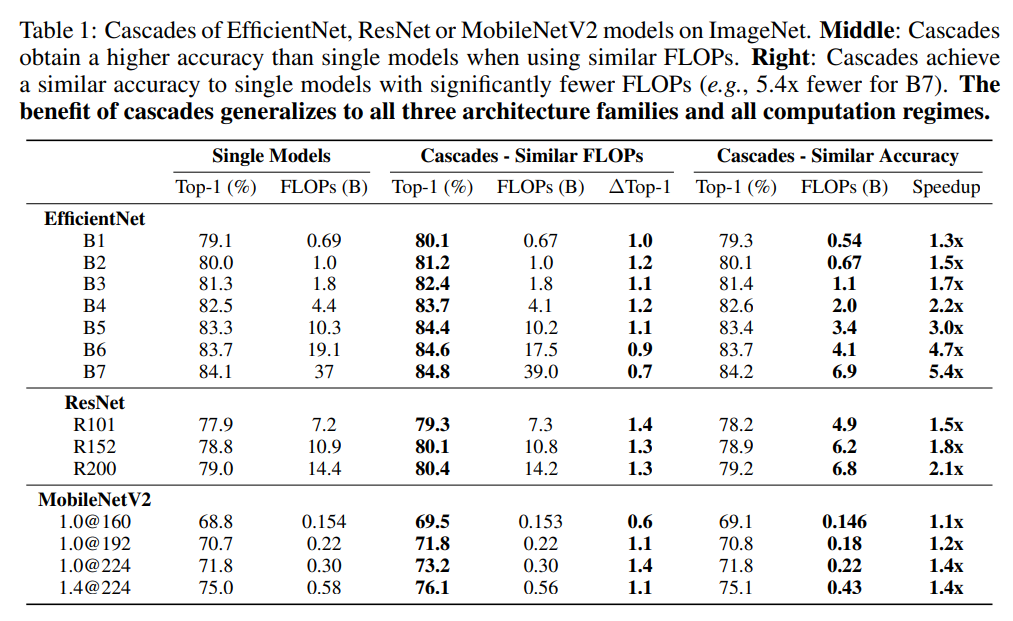 對于ViT架構(gòu),通過模型級聯(lián)也可以得到類似的結(jié)論,如下表所示:
對于ViT架構(gòu),通過模型級聯(lián)也可以得到類似的結(jié)論,如下表所示: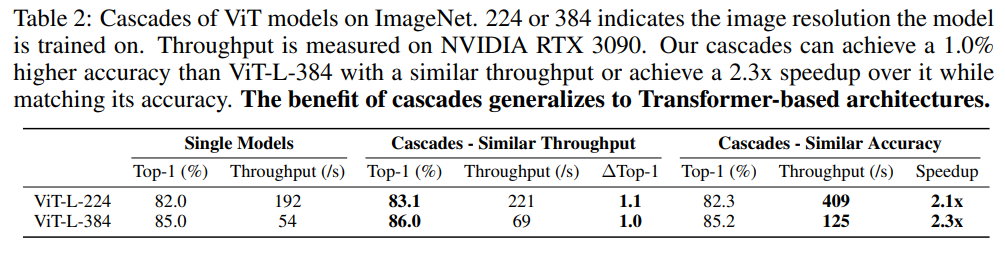 FLOPs并不直接等價于推理速度,論文同樣對比了模型級聯(lián)在TPU上的latency和throughput,如下表所示,可以看到FLOPs的減少確實帶來的推理速度的提升。
FLOPs并不直接等價于推理速度,論文同樣對比了模型級聯(lián)在TPU上的latency和throughput,如下表所示,可以看到FLOPs的減少確實帶來的推理速度的提升。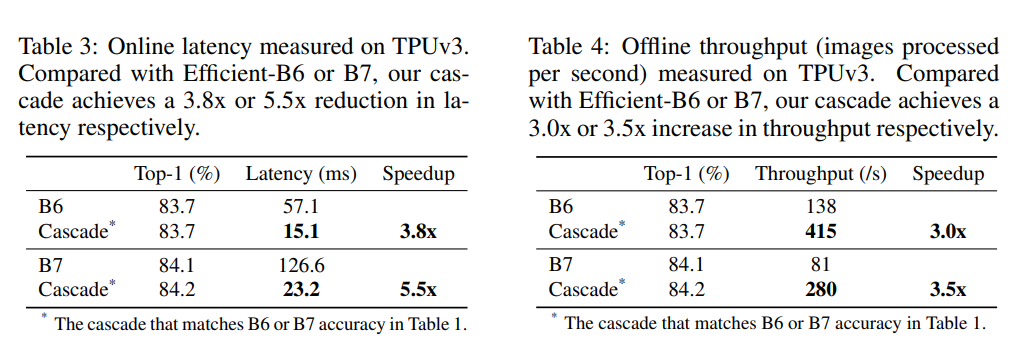 模型級聯(lián)提升效率的優(yōu)勢主要在于提前停止,比如對于對標(biāo)B7性能的一個4模型級聯(lián):[B3,B5,B5,B5],67.3%的圖像只用了B3,而只有5.5%的圖像用了所有的模型,這相比單個B7大模型可以大幅度減少計算量。
模型級聯(lián)提升效率的優(yōu)勢主要在于提前停止,比如對于對標(biāo)B7性能的一個4模型級聯(lián):[B3,B5,B5,B5],67.3%的圖像只用了B3,而只有5.5%的圖像用了所有的模型,這相比單個B7大模型可以大幅度減少計算量。
模型級聯(lián)計算的是平均FLOPs,對于少量的樣本會用到所有的模型,此時FLOPs就是所有模型的FLOPs之和,這是最差的情況。某些實際的應(yīng)用場景往往需要保證最大的計算延遲,此時在尋優(yōu)過程中就需要加上這個限制:。基于這個新增約束,新的實驗結(jié)果如下所示,可以看到模型級聯(lián)在得到相似的分類性能下,不僅能夠加速,而且也能保證最差的FLOPs小于單個模型。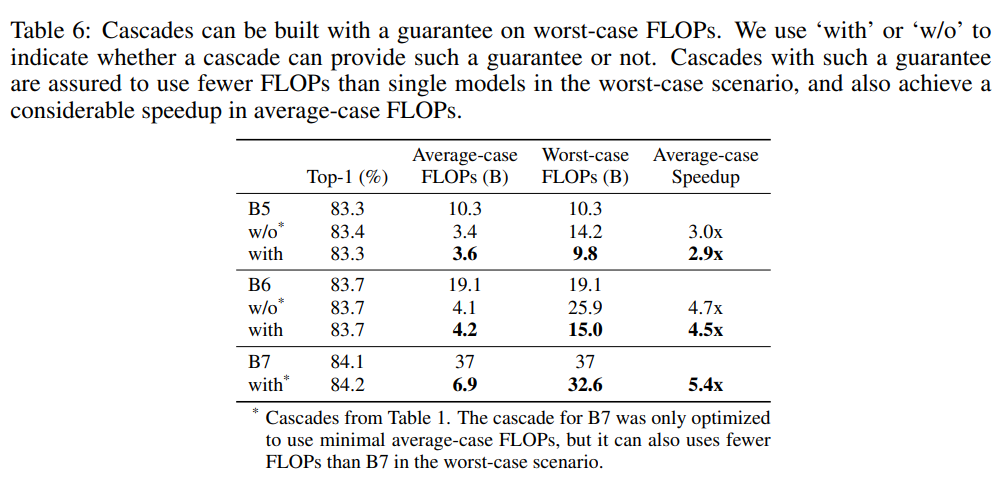 對于模型級聯(lián),除了閾值外,還有一個超參數(shù)就是模型數(shù)量,論文以EfficientNet實驗,發(fā)現(xiàn)3-model級聯(lián)要比2-model級聯(lián)效果要好一些,但是4-model級聯(lián)提升效果就不太明顯了。這說明模型級聯(lián)也存在性能上限。
對于模型級聯(lián),除了閾值外,還有一個超參數(shù)就是模型數(shù)量,論文以EfficientNet實驗,發(fā)現(xiàn)3-model級聯(lián)要比2-model級聯(lián)效果要好一些,但是4-model級聯(lián)提升效果就不太明顯了。這說明模型級聯(lián)也存在性能上限。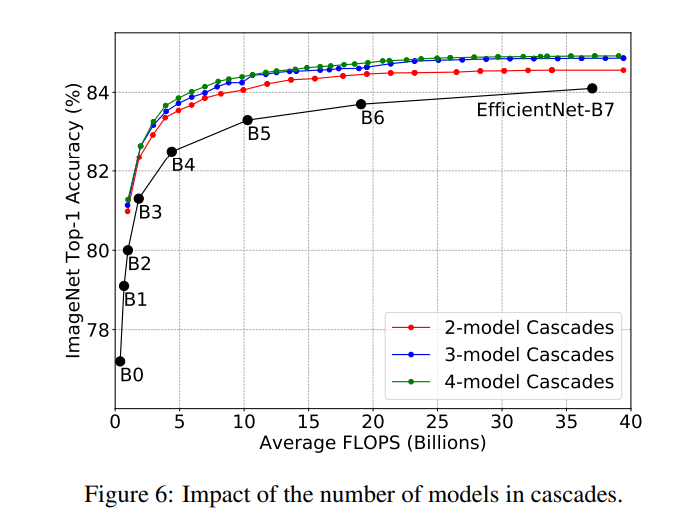
自級聯(lián)
模型級聯(lián)需要訓(xùn)練多個模型,如果只有一個模型,其實也可以進(jìn)行級聯(lián),只不過是改變輸入圖像的分辨率。大部分情況下,提升輸入圖像分辨率會提升模型效果(存在上限),據(jù)此,在單模型級聯(lián)可以逐漸提升圖像分辨率。論文實驗2-model級聯(lián),如下表所示,可以看到單模型多尺度級聯(lián)相比單個模型也能提升計算效率,比如B6模型在528和600尺度上級聯(lián),性能可以達(dá)到B7效果,而且加速1.6x。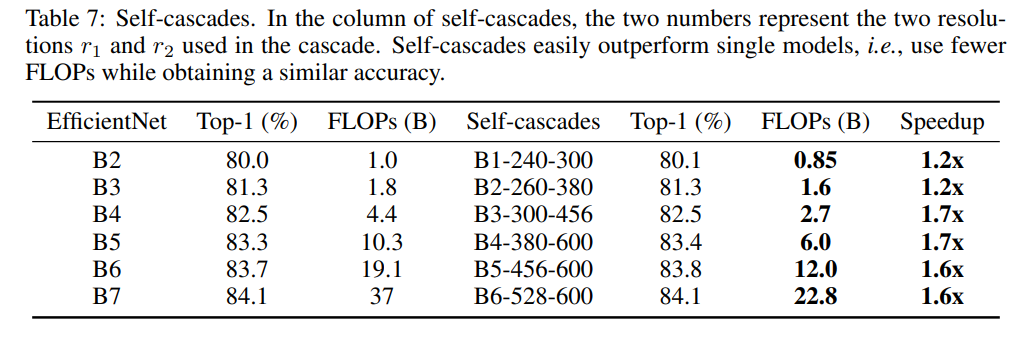
模型級聯(lián)縮放
單個模型可以進(jìn)行縮放來得到不同F(xiàn)LOPs的模型,比如EfficientNet設(shè)計了一個統(tǒng)一縮放因子來縮放模型的depth,width和resolution:,這里。當(dāng)時,就是EfficientNetB0模型,而對應(yīng)EfficientNetB7模型。那么模型級聯(lián)是否也能夠縮放呢,比如已經(jīng)建立了一個base模型級聯(lián),是否能對級聯(lián)的模型進(jìn)行縮放,從而得到不同F(xiàn)LOPs下的級聯(lián)模型。這里建立一個3-model級聯(lián)的模型C0來對應(yīng)EfficientNetB0,建立C0的候選模型包括13個模型,它們的縮放因子分別為:-4.0, -3.0, -2.0, -1.0, 0.0, 0.25, 0.5, 0.75, 1.0, 1.25, 1.50, 1.75, 2.0 ,部分比EfficientNetB0小,部分比EfficientNetB0大,最終尋優(yōu)得到的C0其級聯(lián)模型為-2.0,0.0,0.75。有了C0,就可以對C0的3個模型分別進(jìn)行縮放(增加),從而得到不同F(xiàn)LOPs的級聯(lián)模型。具體的結(jié)果如下所示,構(gòu)建的C0~C7可以和EfficientNetB0~B7得到相似的效果。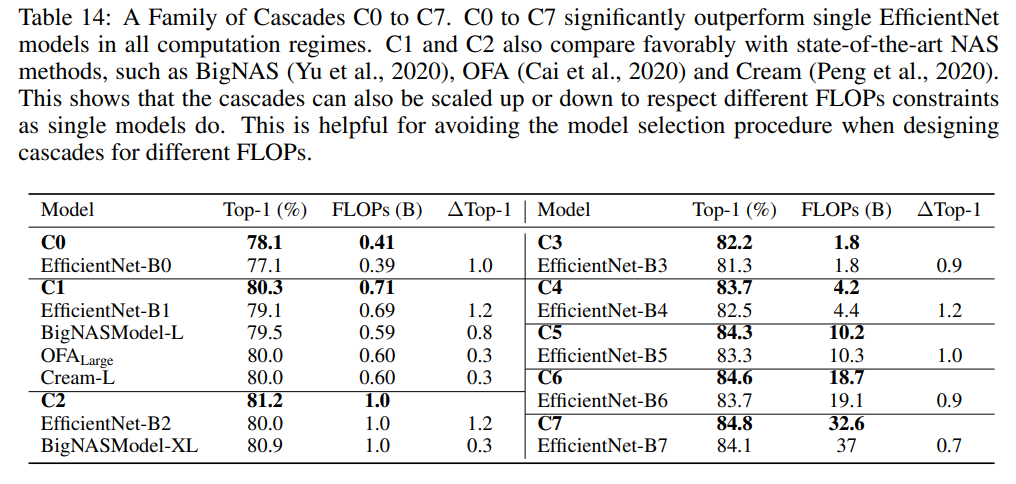
視頻分類
與圖像分類類似,視頻分類模型最后的分類層也是預(yù)測logits,所以也可以用相同的方法對模型進(jìn)行級聯(lián)。這里以X3D架構(gòu)和Kinetics-600數(shù)據(jù)集為例,X3D架構(gòu)包括3個不同F(xiàn)LOPs的模型X3D-M,X3D-L和X3D-XL。對比結(jié)果如下表所示,可以看到無論是限定FLOPs還是分類準(zhǔn)確度,級聯(lián)后的模型均優(yōu)于單個模型。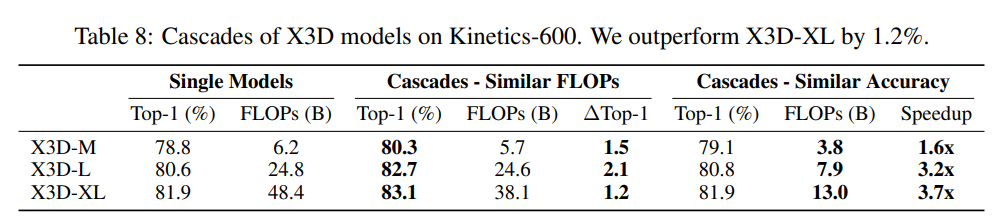
語義分割
對于語義分割,情況更復(fù)雜一些,因為語義分割預(yù)測圖像中每個像素的分類logits,所以需要調(diào)整置信度函數(shù)。具體地,先計算每個像素點(diǎn)的最大預(yù)測概率值:,然后需要聚合所有像素的結(jié)果來得到整個圖像的置信度,這里計算的是圖像中所有像素點(diǎn)置信度的平均值:,這種方式比較簡答粗暴,但是語義分割的一個現(xiàn)實難點(diǎn)是不同區(qū)域的分割難度可能不一樣,如果只采用一個置信度來代表整個圖像可能會不夠準(zhǔn)確,一個簡單的解決方案是將圖像分成不同的網(wǎng)格,對每個格子單獨(dú)做級聯(lián)。這里以DeepLabV3架構(gòu)和Cityscapes數(shù)據(jù)集為例,建立一個2-model級聯(lián)( DeepLabv3-ResNet-50和DeepLabv3-ResNet-101 ),具體的結(jié)果如下所示,這里的 指的是網(wǎng)格的大小,圖像的輸入為1024x2048大小,表示將圖像分成8個網(wǎng)格。可以看到,如果不分成網(wǎng)格,雖然級聯(lián)后模型的mIoU提升了但是FLOPs卻增加了,如果分成網(wǎng)格能有加速效果。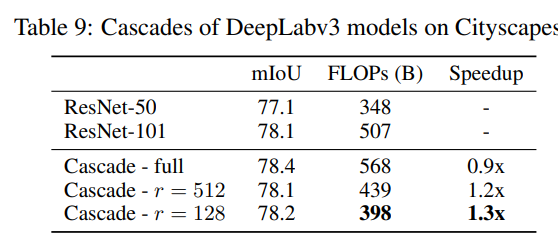 一個要注意的點(diǎn)是,對于語義分割Cityscapes數(shù)據(jù)集,很多像素點(diǎn)是沒有標(biāo)注的(訓(xùn)練和測試時忽略),這對計算置信度帶來噪音,所以在實際計算整圖置信度時只考慮置信度大于某個固定閾值下的像素點(diǎn),即,這里設(shè)為0.5。
一個要注意的點(diǎn)是,對于語義分割Cityscapes數(shù)據(jù)集,很多像素點(diǎn)是沒有標(biāo)注的(訓(xùn)練和測試時忽略),這對計算置信度帶來噪音,所以在實際計算整圖置信度時只考慮置信度大于某個固定閾值下的像素點(diǎn),即,這里設(shè)為0.5。
小結(jié)
對于模型集成或者級聯(lián),直觀上會覺得增加了計算成本,但如果合理設(shè)計后反而是提升計算效率,這在工業(yè)部署實踐中還是有比較大的應(yīng)用意義。不過對于比較復(fù)雜的任務(wù)如分割和檢測,模型集成就需要比較特殊的設(shè)計。
參考
Wisdom of Committees: An Overlooked Approach To Faster and More Accurate Models
推薦閱讀
RegNet:設(shè)計網(wǎng)絡(luò)設(shè)計空間
PyTorch1.10發(fā)布:ZeroRedundancyOptimizer和Join
谷歌AI用30億數(shù)據(jù)訓(xùn)練了一個20億參數(shù)Vision Transformer模型,在ImageNet上達(dá)到新的SOTA!
"未來"的經(jīng)典之作ViT:transformer is all you need!
PVT:可用于密集任務(wù)backbone的金字塔視覺transformer!
漲點(diǎn)神器FixRes:兩次超越ImageNet數(shù)據(jù)集上的SOTA
不妨試試MoCo,來替換ImageNet上pretrain模型!
機(jī)器學(xué)習(xí)算法工程師
? ??? ? ? ? ? ? ? ? ? ? ????????? ??一個用心的公眾號
