本文約6700字,建議閱讀10分鐘
本文介紹了pytorch模型性能分析和優(yōu)化。?????????????????????????

照片由 Torsten Dederichs 拍攝,上傳到 Unsplash
訓(xùn)練深度學(xué)習(xí)模型,尤其是大型模型,可能是一筆昂貴的開支。性能優(yōu)化是我們降低成本的主要方法之一。性能優(yōu)化是一個(gè)迭代過程,在這個(gè)過程中,我們不斷尋找提高應(yīng)用程序性能的機(jī)會(huì)并加以利用。在以前的文章中,我們強(qiáng)調(diào)過使用適當(dāng)工具進(jìn)行分析的重要性。工具的選擇可能取決于多種因素,包括訓(xùn)練加速器的類型(如GPU、HPU 或其他)和訓(xùn)練框架。

性能優(yōu)化流程(來自作者)
這篇文章的重點(diǎn)是在 GPU 上使用 PyTorch 進(jìn)行訓(xùn)練。具體地說,我們將關(guān)注PyTorch內(nèi)置性能分析器、 PyTorch Profiler 以及查看其結(jié)果的方法之一,即 PyTorch Profiler TensorBoard 插件。
這篇文章并不是要取代關(guān)于PyTorch Profiler 或使用 TensorBoard 插件分析剖析器結(jié)果的PyTorch官方文檔。我們的目的是演示如何在日常開發(fā)過程中使用這些工具。事實(shí)上,如果您還沒有閱讀過官方文檔,我們建議您在閱讀這篇文章之前先閱讀一下官方文檔。
一段時(shí)間以來,我一直對 TensorBoard-plugin 教程感興趣。該教程介紹了一個(gè)基于 Resnet 架構(gòu)的分類模型,該模型是在流行的Cifar10 數(shù)據(jù)集上訓(xùn)練的。接下來,它將演示如何使用PyTorch Profiler 和 TensorBoard 插件來識別和修復(fù)數(shù)據(jù)加載器的瓶頸。輸入數(shù)據(jù)管道中的性能瓶頸并不罕見,我們在以前的一些文章中已經(jīng)詳細(xì)討論過。教程中令人驚訝的是最終(優(yōu)化后)結(jié)果(截至本文撰寫時(shí)),我們將其粘貼在下面:
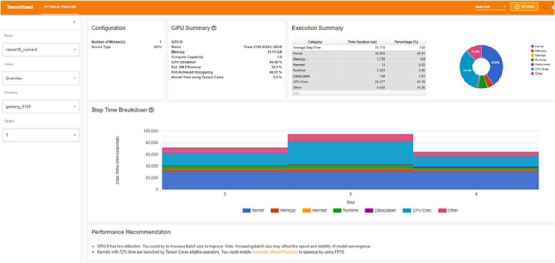
???
優(yōu)化后的性能(摘自 PyTorch 網(wǎng)站)
如果仔細(xì)觀察,你會(huì)發(fā)現(xiàn)優(yōu)化后的 GPU 利用率為 40.46%。現(xiàn)在,沒有任何辦法來粉飾這一點(diǎn):這些結(jié)果絕對慘不忍睹,應(yīng)該讓你徹夜難眠。正如我們在過去所闡述的, GPU 是訓(xùn)練機(jī)中最昂貴的資源,我們的目標(biāo)應(yīng)該是最大限度地提高其利用率。40.46% 的利用率通常代表著訓(xùn)練加速和成本節(jié)約的重要機(jī)會(huì)。當(dāng)然,我們可以做得更好!在本博文中,我們將嘗試做得更好。首先,我們將嘗試重現(xiàn)官方教程中介紹的結(jié)果,看看能否使用相同的工具進(jìn)一步提高訓(xùn)練性能。
簡單示例
下面的代碼塊包含由 TensorBoard-plugin 教程中定義的訓(xùn)練循環(huán),并做了兩處小修改:
我們使用了一個(gè)假數(shù)據(jù)集,其屬性和行為與教程中使用的 CIFAR10 數(shù)據(jù)集相同。這一改變的動(dòng)機(jī)可在此處找到。
我們初始化 我們初始化初始化時(shí),預(yù)熱標(biāo)志設(shè)置為 3,重復(fù)標(biāo)志設(shè)置為 1。我們發(fā)現(xiàn),熱身步驟數(shù)的輕微增加提高了結(jié)果的穩(wěn)定性。
import numpy as np import torch import torch.nn import torch.optim import torch.profiler import torch.utils.data import torchvision.datasets import torchvision.models import torchvision.transforms as T from torchvision.datasets.vision import VisionDataset from PIL import Image
class FakeCIFAR(VisionDataset): def __init__(self, transform): super().__init__(root=None, transform=transform) self.data = np.random.randint(low=0,high=256,size=(1,000,032,323),dtype=np.uint8) self.targets = np.random.randint(low=0,high=10,size=(10000),dtype=np.uint8).tolist()
def __getitem__(self, index): img, target = self.data[index], self.targets[index] img = Image.fromarray(img) if self.transform is not None: img = self.transform(img) return img, target
def __len__(self) -> int: return len(self.data)
transform = T.Compose( [T.Resize(224), T.ToTensor(), T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_set = FakeCIFAR(transform=transform) train_loader = torch.utils.data.DataLoader(train_set, batch_size=32, shuffle=True)
device = torch.device("cuda:0") model = torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device) criterion = torch.nn.CrossEntropyLoss().cuda(device) optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9) model.train()
# train step def train(data): inputs, labels = data[0].to(device=device), data[1].to(device=device) outputs = model(inputs) loss = criterion(outputs, labels) optimizer.zero_grad() loss.backward() optimizer.step()
# training loop wrapped with profiler object with torch.profiler.profile( schedule=torch.profiler.schedule(wait=1, warmup=4, active=3, repeat=1), on_trace_ready=torch.profiler.tensorboard_trace_handler('./log/resnet18'), record_shapes=True, profile_memory=True, with_stack=True ) as prof: for step, batch_data in enumerate(train_loader): if step >= (1 + 4 + 3) * 1: break train(batch_data) prof.step() # Need to call this at the end of each step
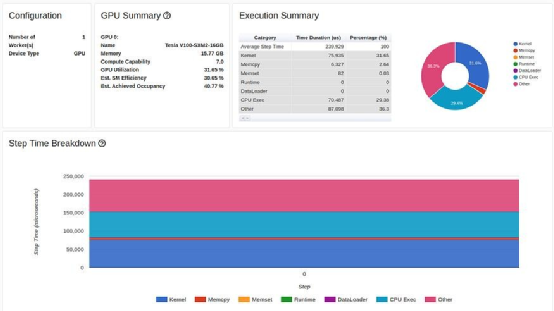
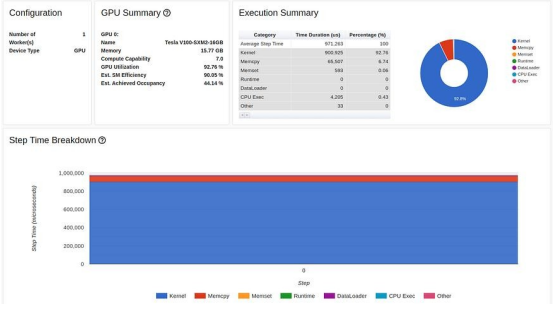
教程中使用的 GPU 是 Tesla V100-DGXS-32GB。在這篇文章中,我們嘗試使用包含 Tesla V100-SXM2-16GB GPU 的Amazon EC2 p3.2xlarge 實(shí)例重現(xiàn)并改進(jìn)教程中的性能結(jié)果。雖然它們采用相同的架構(gòu),但這兩種 GPU 之間存在一些差異。您可以在此處了解這些差異。我們使用 AWS PyTorch 2.0 Docker 映像運(yùn)行了訓(xùn)練腳本。訓(xùn)練腳本的性能結(jié)果顯示在TensorBoard 查看器的預(yù)覽頁面中,如下圖所示:
TensorBoard Profiler 概述選項(xiàng)卡中顯示的基線性能結(jié)果(作者截圖)
首先,我們注意到,與教程相反,我們實(shí)驗(yàn)中的概述頁面(torrent-tb-profiler 0.4.1 版)將三個(gè)步驟合并為一個(gè)。因此,整個(gè)步驟的平均時(shí)間是 80 毫秒,而不是報(bào)告中的 240 毫秒。從跟蹤選項(xiàng)卡(根據(jù)我們的經(jīng)驗(yàn),跟蹤選項(xiàng)卡幾乎總能提供更準(zhǔn)確的報(bào)告)中可以清楚地看到這一點(diǎn),其中每個(gè)步驟耗時(shí)約為80毫秒。
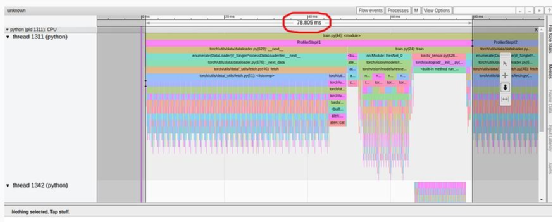
TensorBoard Profiler 跟蹤視圖選項(xiàng)卡中顯示的基線性能結(jié)果(作者截圖)
請注意,我們的起點(diǎn)(31.65% 的 GPU 利用率和 80 毫秒的步進(jìn)時(shí)間)與教程中介紹的起點(diǎn)(分別為 23.54% 和 132 毫秒)有所不同。這可能是包括 GPU 類型和 PyTorch 版本在內(nèi)的訓(xùn)練環(huán)境不同造成的。我們還注意到,教程的基線結(jié)果將性能問題明確診斷為數(shù)據(jù)加載器的瓶頸,而我們的結(jié)果并非如此。我們經(jīng)常發(fā)現(xiàn),數(shù)據(jù)加載瓶頸會(huì)偽裝成 "概覽 "選項(xiàng)卡中"CPU 執(zhí)行 "或 "其他 "的高百分比。
優(yōu)化 #1:多進(jìn)程數(shù)據(jù)加載
首先,讓我們按照教程中的描述使用多進(jìn)程數(shù)據(jù)加載。鑒于Amazon EC2 p3.2xlarge 實(shí)例有 8 個(gè) vCPU,我們將數(shù)據(jù)加載器工作者的數(shù)量設(shè)置為 8,以獲得最高性能:
train_loader = torch.utils.data.DataLoader(train_set, batch_size=32, shuffle=True, num_workers=8)
優(yōu)化結(jié)果如下:
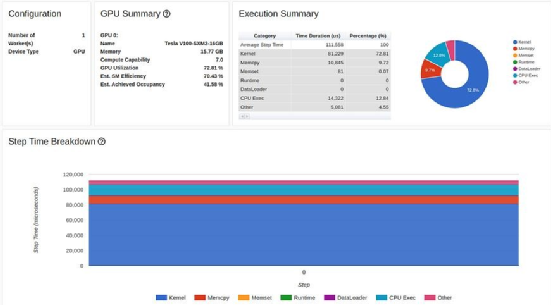
TensorBoard Profiler 概述選項(xiàng)卡中的多進(jìn)程數(shù)據(jù)加載結(jié)果(作者截圖)
只需修改一行代碼,GPU 利用率就提高了 200% 以上(從31.65% 提高到 72.81%),訓(xùn)練步驟時(shí)間縮短了一半以上(從80 毫秒縮短到 37 毫秒)。
教程中的優(yōu)化過程到此為止。雖然我們的 GPU 利用率(72.81%)比教程中的結(jié)果(40.46%)高出不少,但我毫不懷疑,你也會(huì)像我們一樣,覺得這些結(jié)果仍不盡如人意。
作者評論:試想一下,如果 PyTorch 在 GPU 上訓(xùn)練時(shí)默認(rèn)應(yīng)用多進(jìn)程數(shù)據(jù)加載,那么全球可以節(jié)省多少錢?誠然,使用多進(jìn)程可能會(huì)有一些不必要的副作用。不過,一定有某種形式的自動(dòng)檢測算法可以運(yùn)行,以排除潛在的問題場景,并相應(yīng)地應(yīng)用這種優(yōu)化。
優(yōu)化#2:固定內(nèi)存
如果我們分析一下上次實(shí)驗(yàn)的跟蹤視圖,就會(huì)發(fā)現(xiàn)大量時(shí)間(37 毫秒中的 10 毫秒)仍然花在將訓(xùn)練數(shù)據(jù)加載到 GPU上。
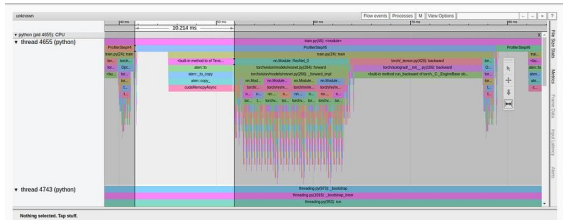
跟蹤視圖選項(xiàng)卡中的多進(jìn)程數(shù)據(jù)加載結(jié)果(作者截圖)
為了解決這個(gè)問題,我們將應(yīng)用 PyTorch 推薦的另一種優(yōu)化方法來簡化數(shù)據(jù)輸入流,即固定內(nèi)存。使用固定內(nèi)存可以提高主機(jī)到 GPU 數(shù)據(jù)拷貝的速度,更重要的是,我們可以將它們異步化。這意味著我們可以在 GPU 中準(zhǔn)備下一個(gè)訓(xùn)練批次,同時(shí)在當(dāng)前批次上進(jìn)行訓(xùn)練。要注意的是,雖然異步化處理可以優(yōu)化性能,但他可能會(huì)降低時(shí)間測量的精度。在本博文中,我們將繼續(xù)使用 PyTorch Profiler 報(bào)告的測量結(jié)果。更多詳情以及固定內(nèi)存的潛在副作用,有關(guān)如何精確測量的說明,請參見此處。請參閱 PyTorch 文檔。
這一優(yōu)化需要修改兩行代碼。首先,我們在數(shù)據(jù)加載器中把pinn_memory置為 True。
train_loader = torch.utils.data.DataLoader(train_set, batch_size=32, shuffle=True, num_workers=8, pin_memory=True)
然后,我們將主機(jī)到設(shè)備的內(nèi)存?zhèn)鬏敚ㄔ谟?xùn)練函數(shù)中)修改為non-blocking:
inputs, labels = data[0].to(device=device, non_blocking=True), \ data[1].to(device=device, non_blocking=True)
|
固定內(nèi)存優(yōu)化后的結(jié)果顯示如下:
|
|
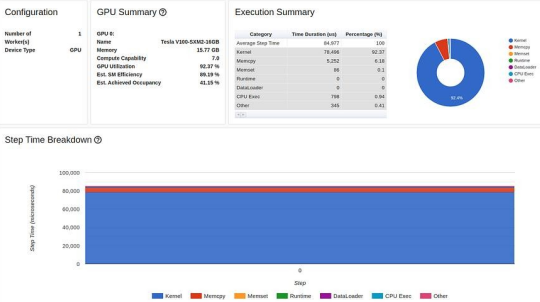
TensorBoard Profiler 概述選項(xiàng)卡中的固定內(nèi)存結(jié)果(作者截圖)
現(xiàn)在,我們的 GPU 利用率達(dá)到了 92.37%,步進(jìn)時(shí)間進(jìn)一步縮短。但我們還可以做得更好。請注意,盡管進(jìn)行了優(yōu)化,但性能報(bào)告仍然顯示我們在將數(shù)據(jù)復(fù)制到 GPU 上花費(fèi)了大量時(shí)間。我們將在下文第 4 步中再次討論這個(gè)問題。
優(yōu)化 #3:增加batch大小
在下一步優(yōu)化中,我們將關(guān)注上次實(shí)驗(yàn)中的 "內(nèi)存視圖":
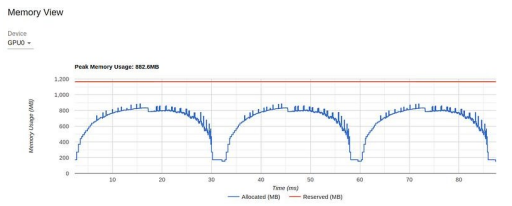
TensorBoard Profiler 中的內(nèi)存視圖(由作者截圖)
圖表顯示,在 16 GB 的 GPU 內(nèi)存中,我們的峰值利用率不到1 GB。這是一個(gè)資源利用率不足的極端例子,通常(但不總是)表明有機(jī)會(huì)提高性能。控制內(nèi)存利用率的方法之一是增加批次大小。在下圖中,我們顯示了當(dāng)批處理大小增加到 512(內(nèi)存利用率增加到 11.3 GB)時(shí)的性能結(jié)果。
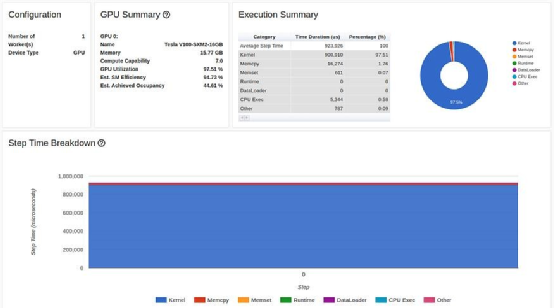
在 TensorBoard Profiler 概述選項(xiàng)卡中增加批次大小的結(jié)果(作者截圖)
雖然GPU 利用率沒有太大變化,但我們的訓(xùn)練速度卻大幅提高,從每秒 1200 個(gè)樣本(批量大小為 32 時(shí)為 46 毫秒)提高到每秒 1584 個(gè)樣本(批量大小為 512 時(shí)為 324 毫秒)。
注意:與我們之前的優(yōu)化相反,增加批次大小可能會(huì)對訓(xùn)練應(yīng)用程序的行為產(chǎn)生影響。不同的模型對批量大小變化的敏感程度不同。有些模型可能只需要對優(yōu)化設(shè)置進(jìn)行一些調(diào)整。而對于其他模型,調(diào)整到大的批次規(guī)模可能會(huì)更加困難,甚至不可能。請參閱上一篇文章,了解大批量訓(xùn)練所面臨的一些挑戰(zhàn)。
優(yōu)化 #4:減少主機(jī)到設(shè)備的復(fù)制??
您可能注意到了,在我們之前的結(jié)果中,餅狀圖中代表主機(jī)到設(shè)備數(shù)據(jù)拷貝的紅色大塊。要解決這種瓶頸,最直接的方法就是看能否減少每批數(shù)據(jù)的數(shù)量。請注意,在圖像輸入的情況下,我們將數(shù)據(jù)類型從 8位無符號整數(shù)轉(zhuǎn)換為 32 位浮點(diǎn)數(shù),并在執(zhí)行數(shù)據(jù)復(fù)制之前進(jìn)行歸一化處理。在下面的代碼塊中,我們建議對輸入數(shù)據(jù)流進(jìn)行修改,將數(shù)據(jù)類型轉(zhuǎn)換和歸一化推遲到數(shù)據(jù)進(jìn)入 GPU 后進(jìn)行:
# maintain the image input as an 8-bit uint8 tensor transform = T.Compose( [T.Resize(224), T.PILToTensor() ]) train_set = FakeCIFAR(transform=transform) train_loader = torch.utils.data.DataLoader(train_set, batch_size=1024, shuffle=True, num_workers=8, pin_memory=True)
device = torch.device("cuda:0") model = torch.compile(torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device), fullgraph=True) criterion = torch.nn.CrossEntropyLoss().cuda(device) optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9) model.train()
# train step def train(data): inputs, labels = data[0].to(device=device, non_blocking=True), \ data[1].to(device=device, non_blocking=True) # convert to float32 and normalize inputs = (inputs.to(torch.float32) / 255. - 0.5) / 0.5 outputs = model(inputs) loss = criterion(outputs, labels) optimizer.zero_grad() loss.backward() optimizer.step()
由于這一改變,從 CPU 復(fù)制到 GPU 的數(shù)據(jù)量減少了 4 倍, 礙眼的紅色塊也幾乎消失了:
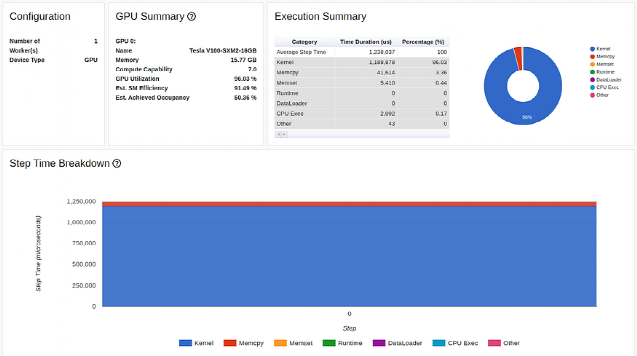
在 TensorBoard Profiler 概述選項(xiàng)卡中減少 CPU 到 GPU 副本的結(jié)果(作者截圖)
現(xiàn)在,我們的 GPU 利用率達(dá)到了 97.51%(!!)的新高,訓(xùn)練速度達(dá)到了每秒 1670 個(gè)采樣點(diǎn)!讓我們看看我們還能做些什么。
優(yōu)化 #5:將梯度設(shè)置為無
現(xiàn)階段我們似乎已經(jīng)充分利用了 GPU,但這并不意味著我們不能更有效地利用它。據(jù)說有一種流行的優(yōu)化方法可以減少 GPU 中的內(nèi)存操作,那就是在每個(gè)訓(xùn)練步驟中將模型參數(shù)梯度設(shè)置為 "無 "而不是零。請參閱 PyTorch 文檔了解有關(guān)該優(yōu)化的更多詳情。要實(shí)現(xiàn)這一優(yōu)化,只需將 optimizer.zero_grad 調(diào)用的 set_too_none 設(shè)置為 True:
optimizer.zero_grad(set_to_none=True)
在我們的例子中,這種優(yōu)化并沒有在提高我們的性能方面有意義。
優(yōu)化 #6:自動(dòng)混合精度
GPU 內(nèi)核視圖顯示 GPU 內(nèi)核的活動(dòng)時(shí)間,是提高 GPU 利用率的有用資源:
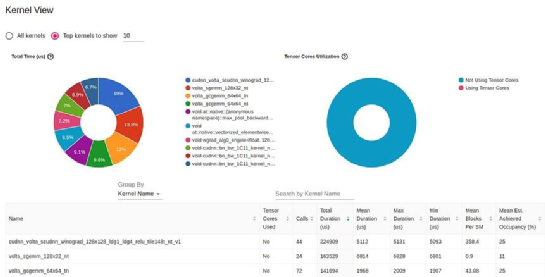
TensorBoard Profiler 中的內(nèi)核視圖(由作者捕獲)
這份報(bào)告中最明顯的一個(gè)細(xì)節(jié)是沒有使用 GPU Tensors Corses。Tensor Cores,是矩陣乘法的專用處理單元,且可用于較新的 GPU 架構(gòu),它可顯著提升人工智能應(yīng)用的性能。缺乏使用張量核意味著這可能是一個(gè)重大的優(yōu)化機(jī)會(huì)。
由于張量核是專為混合精度計(jì)算而設(shè)計(jì)的,因此提高其利用率的一個(gè)直接方法就是修改我們的模型,使其使用自動(dòng)混合精度(AMP)。在 AMP 模式下,模型的部分內(nèi)容會(huì)自動(dòng)轉(zhuǎn)換為精度較低的 16 位浮點(diǎn)數(shù),并在 GPU 張量核上運(yùn)行。
重要的是,請注意 AMP 的全面實(shí)施可能需要梯度縮放,而我們的演示并不包括這一點(diǎn)。在調(diào)整之前,請務(wù)必查看混合精度訓(xùn)練的相關(guān)文檔。
下面碼塊演示了為啟用 AMP 而對訓(xùn)練步驟進(jìn)行的修改。
def train(data): inputs, labels = data[0].to(device=device, non_blocking=True), \ data[1].to(device=device, non_blocking=True) inputs = (inputs.to(torch.float32) / 255. - 0.5) / 0.5 with torch.autocast(device_type='cuda', dtype=torch.float16): outputs = model(inputs) loss = criterion(outputs, labels) # Note - torch.cuda.amp.GradScaler() may be required optimizer.zero_grad(set_to_none=True) loss.backward() optimizer.step()
下圖顯示了對“張量核心”利用率的影響。雖然它繼續(xù)表明還有進(jìn)一步改進(jìn)的機(jī)會(huì),但僅憑一行代碼,
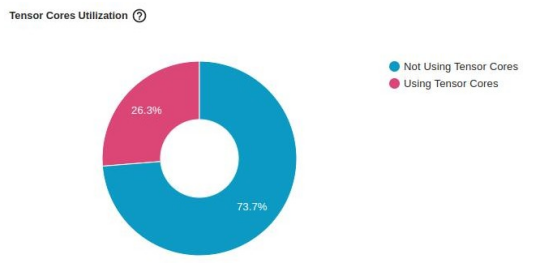
利用率就從 0% 躍升至26.3%。
TensorBoard Profiler 內(nèi)核視圖中使用 AMP 優(yōu)化的張量核利用率(作者截圖)
除了提高張量核心利用率外,使用 AMP 還能降低 GPU 內(nèi)存利用率,從而騰出更多空間來增加批次大小。下圖展示了 AMP 優(yōu)化后的訓(xùn)練性能結(jié)果,其中批量大小設(shè)置為 1024:
TensorBoard Profiler 概述選項(xiàng)卡中的 AMP 優(yōu)化結(jié)果(作者截圖)
雖然 GPU 利用率略有下降,但我們的主要吞吐量指標(biāo)卻進(jìn)一步提高了近 50%,從每秒 1670 個(gè)樣本提高到 2477 個(gè)。我們的優(yōu)化正在發(fā)揮作用!
注意:降低部分模型的精度可能會(huì)對其收斂性產(chǎn)生重大影響。與增加批量大小的情況一樣(見上文),使用混合精度的影響因模型而異。在某些情況下,使用 AMP 幾乎基本不會(huì)改變2。其他情況下,您可能需要花更多精力來調(diào)整autoscaler。還有一些時(shí)候,您可能需要明確設(shè)置模型不同部分的精度類型(即手動(dòng)混合精度)。
有關(guān)使用混合精度作為內(nèi)存優(yōu)化方法的更多詳情,請參閱我們之前的相關(guān)博文。
優(yōu)化 #7:在圖形模式下進(jìn)行訓(xùn)練
我們將應(yīng)用的最后一項(xiàng)優(yōu)化是模型編譯。與 PyTorch 默認(rèn)的急切執(zhí)行模式(每個(gè) PyTorch 操作都會(huì) "急切地 "運(yùn)行)相反, 編譯 API 會(huì)將你的模型轉(zhuǎn)換成中間計(jì)算圖,然后以對底層訓(xùn)練加速器最優(yōu)的方式編譯成底層計(jì)算內(nèi)核。有關(guān) PyTorch 2 中模型編譯的更多信息,請查看我們之前發(fā)布的相關(guān)文章。
以下代碼塊演示了應(yīng)用模型編譯所需的更改:
model = torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device) model = torch.compile(model)
TensorBoard Profiler 概述選項(xiàng)卡中的圖形編譯結(jié)果(作者截圖)
模型編譯將我們的吞吐量進(jìn)一步提高到每秒 3268 個(gè)采樣點(diǎn),而之前實(shí)驗(yàn)中為每秒 2477 個(gè)采樣點(diǎn),性能提高了 32%(!!)。
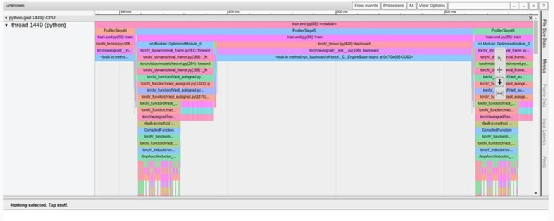
圖形編譯改變訓(xùn)練步驟的方式在 TensorBoard 插件的不同視圖中非常明顯。例如,"內(nèi)核視圖 "顯示使用了新的(融合的) GPU 內(nèi)核,而 "跟蹤視圖"(如下圖所示)顯示的模式與我們之前看到的完全不同。
TensorBoard Profiler 跟蹤視圖選項(xiàng)卡中的圖形編譯結(jié)果(作者截圖)
臨時(shí)成果
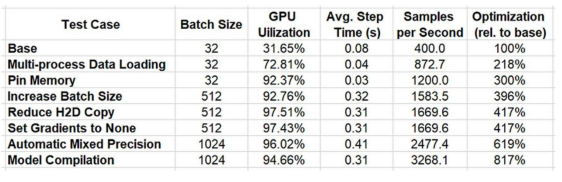
我們在下表中總結(jié)了一系列優(yōu)化的結(jié)果。
通過使用 PyTorch Profiler 和 TensorBoard 插件進(jìn)行迭代分析和優(yōu)化,我們將性能提高了 817%!
我們的工作完成了嗎?絕對沒有!我們實(shí)施的每一次優(yōu)化都會(huì)發(fā)現(xiàn)新的潛在性能改進(jìn)機(jī)會(huì)。這些機(jī)會(huì)以釋放資源的形式出現(xiàn)(例如,轉(zhuǎn)向混合精度使我們能夠增加批量大小),或者以新發(fā)現(xiàn)的性能瓶頸的形式出現(xiàn)(例如,我們的最終優(yōu)化發(fā)現(xiàn)了主機(jī)到設(shè)備數(shù)據(jù)傳輸?shù)钠款i)。此外,還有許多其他眾所周知的優(yōu)化形式,我們在本篇文章中并未嘗試(例如,請參見此處和此處)。最后,新的優(yōu)化庫(例如我們在第 7 步中演示的模型編譯功能)不斷發(fā)布,進(jìn)一步實(shí)現(xiàn)了我們的性能提升目標(biāo)。正如我們在導(dǎo)言中強(qiáng)調(diào)的,要充分利用這些機(jī)會(huì),性能優(yōu)化必須成為開發(fā)工作流程中迭代和持續(xù)的一部分。
總結(jié)
在這篇文章中,我們展示了簡單模型性能優(yōu)化的巨大潛力。雖然您還可以使用其他性能分析器,它們各有利弊,但我們還是選擇了 PyTorch Profiler 和 TensorBoard 插件,因?yàn)樗鼈円子诩伞?/span>
我們需要強(qiáng)調(diào)的是,根據(jù)培訓(xùn)項(xiàng)目的具體情況,包括模型結(jié)構(gòu)和訓(xùn)練環(huán)境,成功優(yōu)化的途徑會(huì)有很大不同。在實(shí)踐中,實(shí)現(xiàn)目標(biāo)可能比我們在這里介紹的例子更加困難。我們介紹的某些技術(shù)可能對性能影響甚微,甚至?xí)剐阅芟陆怠N覀冞€注意到,我們所選擇的精確優(yōu)化方法以及應(yīng)用它們的順序有些隨意。我們強(qiáng)烈建議您根據(jù)自己項(xiàng)目的具體細(xì)節(jié)開發(fā)自己的工具和技術(shù),以實(shí)現(xiàn)優(yōu)化目標(biāo)。
機(jī)器學(xué)習(xí)工作負(fù)載的性能優(yōu)化有時(shí)被視為次要的、非關(guān)鍵的和令人厭煩的。我希望我們能夠成功地說服您,節(jié)省開發(fā)時(shí)間和成本的潛力值得您在性能分析和優(yōu)化進(jìn)行投入。而且,嘿嘿,您甚至可能會(huì)覺得這很有趣:)。
下一個(gè)是?
這只是冰山一角。性能優(yōu)化的內(nèi)容遠(yuǎn)不止這些。在本篇文章的續(xù)篇中,我們將深入探討 PyTorch 模型中非常常見的一個(gè)性能問題,即在 CPU 而不是 GPU 上運(yùn)行了過多的計(jì)算量,而開發(fā)者往往對此并不知情。我們還鼓勵(lì)您查看我們在 medium 上發(fā)布的其他文章,其中很多都涉及機(jī)器學(xué)習(xí)工作負(fù)載性能優(yōu)化的不同要素。
原文標(biāo)題:
PyTorch Model Performance Analysis and Optimization
原文鏈接:
PyTorch Model Performance Analysis and Optimization | by Chaim Rand | Towards Data Science
林立錕,香港城市大學(xué)計(jì)算數(shù)學(xué)本科,數(shù)據(jù)科學(xué)愛好者,對數(shù)學(xué)和計(jì)算機(jī)特別感興趣,尤其是兩者的結(jié)合部分特別感興趣。興趣是打羽毛球,以及琢磨一些奇奇怪怪的學(xué)習(xí)工具。希望能夠通過自己的努力,將一些更優(yōu)質(zhì)的文章,更有價(jià)值的內(nèi)容分享給讀者,讓大家在學(xué)習(xí)數(shù)據(jù)科學(xué)時(shí)能夠更加順利!
工作內(nèi)容:需要一顆細(xì)致的心,將選取好的外文文章翻譯成流暢的中文。如果你是數(shù)據(jù)科學(xué)/統(tǒng)計(jì)學(xué)/計(jì)算機(jī)類的留學(xué)生,或在海外從事相關(guān)工作,或?qū)ψ约和庹Z水平有信心的朋友歡迎加入翻譯小組。
你能得到:定期的翻譯培訓(xùn)提高志愿者的翻譯水平,提高對于數(shù)據(jù)科學(xué)前沿的認(rèn)知,海外的朋友可以和國內(nèi)技術(shù)應(yīng)用發(fā)展保持聯(lián)系,THU數(shù)據(jù)派產(chǎn)學(xué)研的背景為志愿者帶來好的發(fā)展機(jī)遇。
其他福利:來自于名企的數(shù)據(jù)科學(xué)工作者,北大清華以及海外等名校學(xué)生他們都將成為你在翻譯小組的伙伴。
點(diǎn)擊文末“閱讀原文”加入數(shù)據(jù)派團(tuán)隊(duì)~
轉(zhuǎn)載須知
如需轉(zhuǎn)載,請?jiān)陂_篇顯著位置注明作者和出處(轉(zhuǎn)自:數(shù)據(jù)派ID:DatapiTHU),并在文章結(jié)尾放置數(shù)據(jù)派醒目二維碼。有原創(chuàng)標(biāo)識文章,請發(fā)送【文章名稱-待授權(quán)公眾號名稱及ID】至聯(lián)系郵箱,申請白名單授權(quán)并按要求編輯。
發(fā)布后請將鏈接反饋至聯(lián)系郵箱(見下方)。未經(jīng)許可的轉(zhuǎn)載以及改編者,我們將依法追究其法律責(zé)任。