
「Apache Hudi系列」核心概念與架構設計總結

簡介
Apache Hudi依賴 HDFS 做底層的存儲,所以可以支撐非常大規(guī)模的數(shù)據(jù)存儲。同時基于下面兩個原語,Hudi可以解決流批一體的存儲問題。
提供了在hadoop兼容的存儲之上存儲大量數(shù)據(jù),同時它還提供兩種原語:
Update/Delete 記錄:Hudi 支持更新/刪除記錄,使用文件/記錄級別索引,同時對寫操作提供事務保證。查詢可獲取最新提交的快照來產(chǎn)生結果。
變更流:支持增量獲取表中所有更新/插入/刪除的記錄,從指定時間點開始進行增量查詢,可以實現(xiàn)類似 Kafka 的增量消費機制。
一些設計原則
流式讀/寫:Hudi借鑒了數(shù)據(jù)庫設計的原理,從零設計,應用于大型數(shù)據(jù)集記錄流的輸入和輸出。為此,Hudi提供了索引實現(xiàn),可以將記錄的鍵快速映射到其所在的文件位置。同樣,對于流式輸出數(shù)據(jù),Hudi通過其特殊列添加并跟蹤記錄級的元數(shù)據(jù),從而可以提供所有發(fā)生變更的精確增量流。
自管理:Hudi注意到用戶可能對數(shù)據(jù)新鮮度(寫友好)與查詢性能(讀/查詢友好)有不同的期望,它支持了三種查詢類型,這些類型提供實時快照,增量流以及稍早的純列數(shù)據(jù)。在每一步,Hudi都努力做到自我管理(例如自動優(yōu)化編寫程序的并行性,保持文件大小)和自我修復(例如:自動回滾失敗的提交),即使這樣做會稍微增加運行時成本(例如:在內(nèi)存中緩存輸入數(shù)據(jù)已分析工作負載)。如果沒有這些內(nèi)置的操作杠桿/自我管理功能,這些大型流水線的運營成本通常會翻倍。
萬物皆日志:Hudi還具有 append only、云數(shù)據(jù)友好的設計,該設計實現(xiàn)了日志結構化存儲系統(tǒng)的原理,可以無縫管理所有云提供商的數(shù)據(jù)。
鍵-值數(shù)據(jù)模型:在寫方面,Hudi表被建模為鍵值對數(shù)據(jù)集,其中每條記錄都有一個唯一的記錄鍵。此外,一個記錄鍵還可以包括分區(qū)路徑,在該路徑下,可以對記錄進行分區(qū)和存儲。這通常有助于減少索引查詢的搜索空間。
Hudi表設計
Hudi表的三個主要組件:
有序的時間軸元數(shù)據(jù):類似于數(shù)據(jù)庫事務日志。 分層布局的數(shù)據(jù)文件:實際寫入表中的數(shù)據(jù)。 索引(多種實現(xiàn)方式):映射包含指定記錄的數(shù)據(jù)集。
另外,針對數(shù)據(jù)的寫入和查詢,Hudi提供一些非常重要的功能例如upsert、mvvc等。
時間軸TimeLine
Timeline 是 HUDI 用來管理提交(commit)的抽象,每個 commit 都綁定一個固定時間戳,分散到時間線上。在 Timeline 上,每個 commit 被抽象為一個 HoodieInstant,一個 instant 記錄了一次提交 (commit) 的行為、時間戳、和狀態(tài)。HUDI 的讀寫 API 通過 Timeline 的接口可以方便的在 commits 上進行條件篩選,對 history 和 on-going 的 commits 應用各種策略,快速篩選出需要操作的目標 commit。
如圖所示:

Hudi維護了一條包含在不同的即時時間(instant time)對數(shù)據(jù)集做的所有instant操作的timeline,從而提供表的即時視圖,同時還有效支持按到達順序進行數(shù)據(jù)檢索。時間軸類似于數(shù)據(jù)庫的redo/transaction日志,由一組時間軸實例組成。Hudi保證在時間軸上執(zhí)行的操作的原子性和基于即時時間的時間軸一致性。時間軸被實現(xiàn)為表基礎路徑下.hoodie元數(shù)據(jù)文件夾下的一組文件。具體來說,最新的instant被保存為單個文件,而較舊的instant被存檔到時間軸歸檔文件夾中,以限制writers和queries列出的文件數(shù)量。
一個Hudi 時間軸instant由下面幾個組件構成:
操作類型:對數(shù)據(jù)集執(zhí)行的操作類型; 即時時間:即時時間通常是一個時間戳(例如:20190117010349),該時間戳按操作開始時間的順序單調增加; 即時狀態(tài):instant的當前狀態(tài);每個instant都有avro或者json格式的元數(shù)據(jù)信息,詳細的描述了該操作的狀態(tài)以及這個即時時刻instant的狀態(tài)。
關鍵的Instant操作類型有:
COMMIT:一次提交表示將一組記錄原子寫入到數(shù)據(jù)集中; CLEAN: 刪除數(shù)據(jù)集中不再需要的舊文件版本的后臺活動; DELTA_COMMIT:將一批記錄原子寫入到MergeOnRead存儲類型的數(shù)據(jù)集中,其中一些/所有數(shù)據(jù)都可以只寫到增量日志中; COMPACTION: 協(xié)調Hudi中差異數(shù)據(jù)結構的后臺活動,例如:將更新從基于行的日志文件變成列格式。在內(nèi)部,壓縮表現(xiàn)為時間軸上的特殊提交; ROLLBACK: 表示提交/增量提交不成功且已回滾,刪除在寫入過程中產(chǎn)生的所有部分文件; SAVEPOINT: 將某些文件組標記為"已保存",以便清理程序不會將其刪除。在發(fā)生災難/數(shù)據(jù)恢復的情況下,它有助于將數(shù)據(jù)集還原到時間軸上的某個點;
任何給定的即時都會處于以下狀態(tài)之一:
REQUESTED:表示已調度但尚未初始化; INFLIGHT: 表示當前正在執(zhí)行該操作; COMPLETED: 表示在時間軸上完成了該操作.
數(shù)據(jù)文件

Hudi將表組織成DFS上基本路徑下的文件夾結構中。如果表是分區(qū)的,則在基本路徑下還會有其他的分區(qū),這些分區(qū)是包含該分區(qū)數(shù)據(jù)的文件夾,與Hive表非常類似。每個分區(qū)均由相對于基本路徑的分區(qū)路徑唯一標識。在每個分區(qū)內(nèi),文件被組織成文件組,由文件ID唯一標識。其中每個切片包含在某個提交/壓縮即時時間生成的基本列文件(.parquet)以及一組日志文件(.log*),該文件包含自生成基本文件以來對基本文件的插入/更新。Hudi采用了MVCC設計,壓縮操作會將日志和基本文件合并以產(chǎn)生新的文件片,而清理操作則將未使用的/較舊的文件片刪除以回收HDFS上的空間。
下圖展示了一個分區(qū)內(nèi)的文件結構:
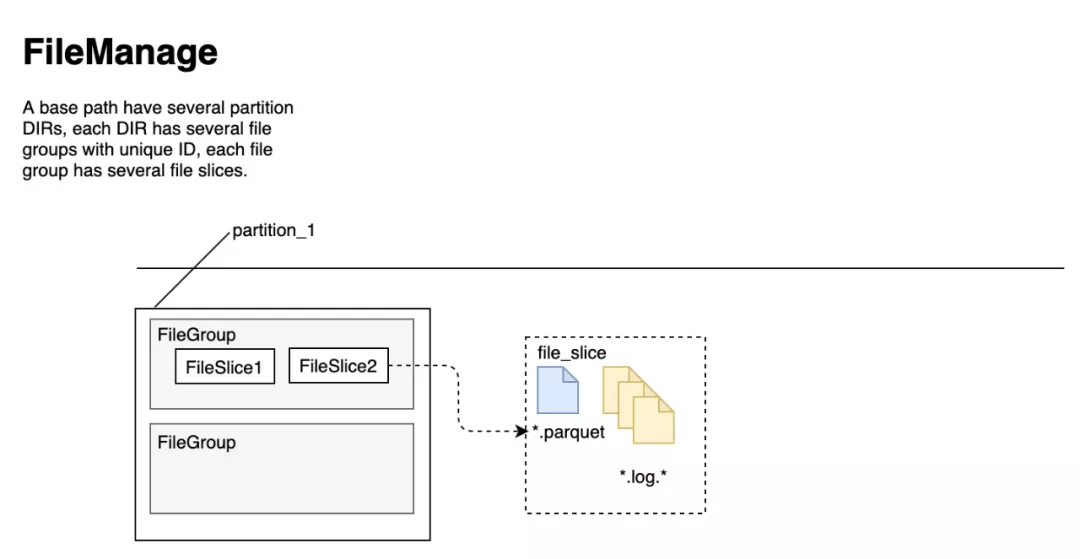
文件版本
一個新的 base commit time 對應一個新的 FileSlice,實際就是一個新的數(shù)據(jù)版本。HUDI 通過 TableFileSystemView 抽象來管理 table 對應的文件,比如找到所有最新版本 FileSlice 中的 base file (Copy On Write Snapshot 讀)或者 base + log files(Merge On Read 讀)。通過 Timeline 和 TableFileSystemView 抽象,HUDI 實現(xiàn)了非常便捷和高效的表文件查找。
文件格式
Hoodie 的每個 FileSlice 中包含一個 base file (merge on read 模式可能沒有)和多個 log file (copy on write 模式?jīng)]有)。
每個文件的文件名都帶有其歸屬的 FileID(即 FileGroup Identifier)和 base commit time(即 InstanceTime)。通過文件名的 group id 組織 FileGroup 的 logical 關系;通過文件名的 base commit time 組織 FileSlice 的邏輯關系。
HUDI 的 base file (parquet 文件) 在 footer 的 meta 去記錄了 record key 組成的 BloomFilter,用于在 file based index 的實現(xiàn)中實現(xiàn)高效率的 key contains 檢測。只有不在 BloomFilter 的 key 才需要掃描整個文件消滅假陽。
HUDI 的 log (avro 文件)是自己編碼的,通過積攢數(shù)據(jù) buffer 以 LogBlock 為單位寫出,每個 LogBlock 包含 magic number、size、content、footer 等信息,用于數(shù)據(jù)讀、校驗和過濾。
索引設計
Hudi通過索引機制提供高效的upsert操作,該機制會將一個記錄鍵+分區(qū)路徑組合一致性的映射到一個文件ID.這個記錄鍵和文件組/文件ID之間的映射自記錄被寫入文件組開始就不會再改變。簡而言之,這個映射文件組包含了一組文件的所有版本。Hudi當前提供了3種索引實現(xiàn)(HBaseIndex、HoodieBloomIndex(HoodieGlobalBloomIndex)、InMemoryHashIndex)來映射一個記錄鍵到包含該記錄的文件ID。這將使我們無需掃描表中的每條記錄,就可顯著提高upsert速度。
Hudi索引可以根據(jù)其查詢分區(qū)記錄的能力進行分類:
1. 全局索引:不需要分區(qū)信息即可查詢記錄鍵映射的文件ID。比如,寫程序可以傳入null或者任何字符串作為分區(qū)路徑(partitionPath),但索引仍然會查找到該記錄的位置。全局索引在記錄鍵在整張表中保證唯一的情況下非常有用,但是查詢的消耗隨著表的大小呈函數(shù)式增加。
2. 非全局索引:與全局索引不同,非全局索引依賴分區(qū)路徑(partitionPath),對于給定的記錄鍵,它只會在給定分區(qū)路徑下查找該記錄。這比較適合總是同時生成分區(qū)路徑和記錄鍵的場景,同時還能享受到更好的擴展性,因為查詢索引的消耗只與寫入到該分區(qū)下數(shù)據(jù)集大小有關系。
表類型
Copy On Write
COW表寫的時候數(shù)據(jù)直接寫入basefile,(parquet)不寫log文件。所以COW表的文件片只包含basefile(一個parquet文件構成一個文件片)。這種的存儲方式的Spark DAG相對簡單。關鍵目標是是使用partitioner將tagged Hudi記錄RDD(所謂的tagged是指已經(jīng)通過索引查詢,標記每條輸入記錄在表中的位置)分成一些列的updates和inserts.為了維護文件大小,我們先對輸入進行采樣,獲得一個工作負載profile,這個profile記錄了輸入記錄的insert和update、以及在分區(qū)中的分布等信息。把數(shù)據(jù)從新打包,這樣:
對于updates,該文件ID的最新版本都將被重寫一次,并對所有已更改的記錄使用新值。 對于inserts,記錄首先打包到每個分區(qū)路徑中的最小文件中,直到達到配置的最大大小。之后的所有剩余記錄將再次打包到新的文件組,新的文件組也會滿足最大文件大小要求。

Copy On Write 類型表每次寫入都會生成一個新的持有base file(對應寫入的 instant time)的 FileSlice。
用戶在snapshot讀取的時候會掃描所有最新的FileSlice下的base file。
Merge On Read
MOR表寫數(shù)據(jù)時,記錄首先會被快速的寫進日志文件,稍后會使用時間軸上的壓縮操作將其與基礎文件合并。根據(jù)查詢是讀取日志中的合并快照流還是變更流,還是僅讀取未合并的基礎文件,MOR表支持多種查詢類型。在高層次上,MOR writer在讀取數(shù)據(jù)時會經(jīng)歷與COW writer 相同的階段。這些更新將追加到最新文件篇的最新日志文件中,而不會合并。對于insert,Hudi支持兩種模式:
插入到日志文件:有可索引日志文件的表會執(zhí)行此操作(HBase索引); 插入parquet文件:沒有索引文件的表(例如布隆索引)
與寫時復制(COW)一樣,對已標記位置的輸入記錄進行分區(qū),將所有發(fā)往相同文件id的upsert分到一組。這批upsert會作為一個或多個日志塊寫入日志文件。Hudi允許客戶端控制日志文件大小。對于寫時復制(COW)和讀時合并(MOR)writer來說,Hudi的WriteClient是相同的。幾輪數(shù)據(jù)的寫入將會累積一個或多個日志文件。這些日志文件與基本的parquet文件(如果有)一起構成一個文件片,而這個文件片代表該文件的一個完整版本。
這種表是用途最廣、最高級的表。為寫(可以指定不同的壓縮策略,吸收突發(fā)寫流量)和查詢(例如權衡數(shù)據(jù)的時效性和查詢性能)提供了很大的靈活性。
Merge On Read 表的寫入行為,依據(jù) index 的不同會有細微的差別:
對于 BloomFilter 這種無法對 log file 生成 index 的索引方案,對于 INSERT 消息仍然會寫 base file (parquet format),只有 UPDATE 消息會 append log 文件(因為 base file 已經(jīng)記錄了該 UPDATE 消息的 FileGroup ID)。 對于可以對 log file 生成 index 的索引方案,例如 Flink writer 中基于 state 的索引,每次寫入都是 log format,并且會不斷追加和 roll over。
Merge On Read 表的讀在 READ OPTIMIZED 模式下,只會讀最近的經(jīng)過 compaction 的 commit。

數(shù)據(jù)讀寫流程
讀流程
Snapshot讀
讀取所有 partiiton 下每個 FileGroup 最新的 FileSlice 中的文件,Copy On Write 表讀 parquet 文件,Merge On Read 表讀 parquet + log 文件
Incremantal讀
根據(jù)https://hudi.apache.org/docs/querying_data.html#spark-incr-query描述,當前的 Spark data source 可以指定消費的起始和結束 commit 時間,讀取 commit 增量的數(shù)據(jù)集。但是內(nèi)部的實現(xiàn)不夠高效:拉取每個 commit 的全部目標文件再按照系統(tǒng)字段 hoodie_commit_time apply 過濾條件。
Streaming 讀
HUDI Flink writer 支持實時的增量訂閱,可用于同步 CDC 數(shù)據(jù),日常的數(shù)據(jù)同步 ETL pipeline。Flink 的 streaming 讀做到了真正的流式讀取,source 定期監(jiān)控新增的改動文件,將讀取任務下派給讀 task。
寫流程
寫操作
UPSERT:默認行為,數(shù)據(jù)先通過 index 打標(INSERT/UPDATE),有一些啟發(fā)式算法決定消息的組織以優(yōu)化文件的大小 => CDC 導入 INSERT:跳過 index,寫入效率更高 => Log Deduplication BULK_INSERT:寫排序,對大數(shù)據(jù)量的 Hudi 表初始化友好,對文件大小的限制 best effort(寫 HFile)
寫流程(UPSERT)
Copy On Write
先對 records 按照 record key 去重 首先對這批數(shù)據(jù)創(chuàng)建索引 (HoodieKey => HoodieRecordLocation);通過索引區(qū)分哪些 records 是 update,哪些 records 是 insert(key 第一次寫入) 對于 update 消息,會直接找到對應 key 所在的最新 FileSlice 的 base 文件,并做 merge 后寫新的 base file (新的 FileSlice) 對于 insert 消息,會掃描當前 partition 的所有 SmallFile(小于一定大小的 base file),然后 merge 寫新的 FileSlice;如果沒有 SmallFile,直接寫新的 FileGroup + FileSlice
Merge On Read
先對 records 按照 record key 去重(可選) 首先對這批數(shù)據(jù)創(chuàng)建索引 (HoodieKey => HoodieRecordLocation);通過索引區(qū)分哪些 records 是 update,哪些 records 是 insert(key 第一次寫入) 如果是 insert 消息,如果 log file 不可建索引(默認),會嘗試 merge 分區(qū)內(nèi)最小的 base file (不包含 log file 的 FileSlice),生成新的 FileSlice;如果沒有 base file 就新寫一個 FileGroup + FileSlice + base file;如果 log file 可建索引,嘗試 append 小的 log file,如果沒有就新寫一個 FileGroup + FileSlice + base file 如果是 update 消息,寫對應的 file group + file slice,直接 append 最新的 log file(如果碰巧是當前最小的小文件,會 merge base file,生成新的 file slice)log file 大小達到閾值會 roll over 一個新的
寫流程(INSERT)
Copy On Write
先對 records 按照 record key 去重(可選) 不會創(chuàng)建 Index 如果有小的 base file 文件,merge base file,生成新的 FileSlice + base file,否則直接寫新的 FileSlice + base file
Merge On Read
先對 records 按照 record key 去重(可選) 不會創(chuàng)建 Index 如果 log file 可索引,并且有小的 FileSlice,嘗試追加或寫最新的 log file;如果 log file 不可索引,寫一個新的 FileSlice + base file
總結
主要是我個人收集和翻閱Hudi社區(qū)的一些資料過程中的總結。目前Hudi版本到了0.11版本。細節(jié)上可能有所差異,以社區(qū)為準。
Hi,我是王知無,一個大數(shù)據(jù)領域的原創(chuàng)作者。? 放心關注我,獲取更多行業(yè)的一手消息。
