
高效大語言模型的前世今生
文末《大模型項(xiàng)目開發(fā)線上營》秒殺!!!
前20人報(bào)名,除了VIP年卡外,還多送兩個(gè)大模型小課:類ChatGPT微調(diào)實(shí)戰(zhàn)、LLM與langchain/知識(shí)圖譜/數(shù)據(jù)庫的實(shí)戰(zhàn),如已有這兩課,可以選同等價(jià)位別的課?
序言
1
語言模型
在計(jì)算機(jī)科學(xué)的早期階段,人們嘗試教會(huì)機(jī)器處理自然語言。1950年代,Alan Turing提出了著名的圖靈測(cè)試,該測(cè)試旨在評(píng)估機(jī)器是否能以一種與人類無法區(qū)分的方式進(jìn)行對(duì)話。然而,由于當(dāng)時(shí)計(jì)算機(jī)性能和知識(shí)表示的限制,早期語言模型往往表現(xiàn)欠佳。20世紀(jì)70年代末至80年代初,隨著計(jì)算機(jī)計(jì)算能力的提升,基于統(tǒng)計(jì)的語言模型開始受到關(guān)注。N-gram模型、隱馬爾可夫模型等應(yīng)運(yùn)而生,通過分析大量文本語料庫中的統(tǒng)計(jì)信息,使得計(jì)算機(jī)更加懂得語言的結(jié)構(gòu)和規(guī)律。當(dāng)時(shí)的模型雖然在一定程度上提升了自然語言處理的準(zhǔn)確性,但仍然存在缺點(diǎn),如對(duì)上下文的限制、處理長文本耗時(shí)較長等問題。
隨著深度學(xué)習(xí)技術(shù)的發(fā)展,神經(jīng)網(wǎng)絡(luò)模型改變了自然語言處理的格局并提出了多個(gè)序列到序列(Sequence-to-Sequence)的基礎(chǔ)模型架構(gòu),比如Transformer模型。憑借其強(qiáng)大的學(xué)習(xí)能力、并行計(jì)算的優(yōu)勢(shì)以及對(duì)長文本處理的能力,Transformer成為了現(xiàn)代大語言模型的基礎(chǔ)架構(gòu)。2020年,OpenAI發(fā)布了第一個(gè)大語言模型GPT-3[1](Generative Pre-trained Transformer),引起了業(yè)界的廣泛關(guān)注。GPT系列模型通過大規(guī)模無監(jiān)督學(xué)習(xí),在海量的文本數(shù)據(jù)中自動(dòng)學(xué)習(xí)語言的特征和規(guī)律,從而可以生成和理解自然語言。這使得高效大語言模型不僅能夠應(yīng)對(duì)對(duì)話和翻譯等傳統(tǒng)任務(wù),還可以創(chuàng)造性地生成新的文本內(nèi)容,成為了多個(gè)領(lǐng)域的助手。然而,基于Transformer的大語言模型帶來的挑戰(zhàn)也不容忽視。其龐大的參數(shù)量和計(jì)算資源需求使得訓(xùn)練和部署成本變得極高;同時(shí),模型的數(shù)據(jù)和計(jì)算復(fù)雜度也帶來了隱私和安全的風(fēng)險(xiǎn)。為此,研究者們?cè)谀P蛢?yōu)化、壓縮、加密和隱私保護(hù)等方向進(jìn)行了探索,以尋求更加高效和可信的解決方案。
2
高效的序列建模
高效的序列建模可以分為四大主要路線:
-
稀疏Transformer(Sparse Trasnformer); -
線性Transformer(Linear Transformer); -
長卷積(Long Convolution); -
循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)。
在以下的章節(jié)中,我們將回顧這些路線并介紹代表性方法,以及在大規(guī)模自然語言模型中應(yīng)用中的難點(diǎn)。下圖顯示了高效序列建模的發(fā)展時(shí)間線。
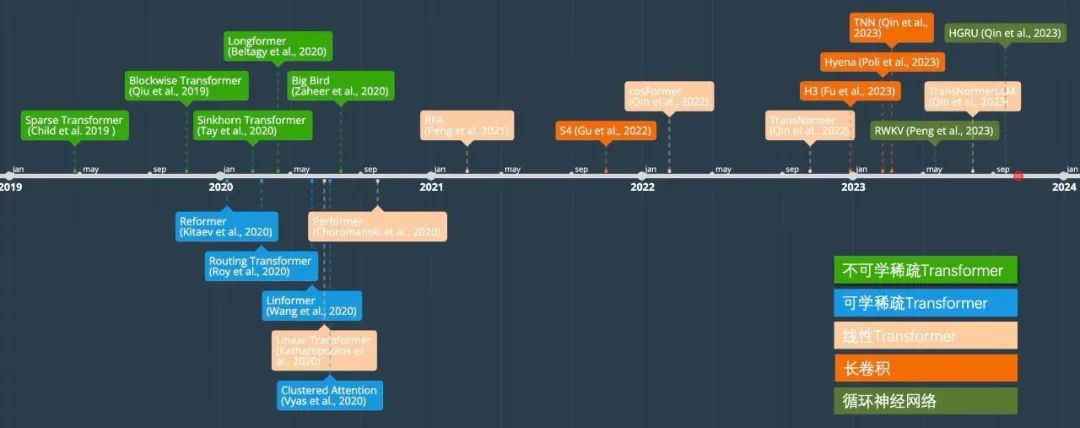
稀疏Transformer
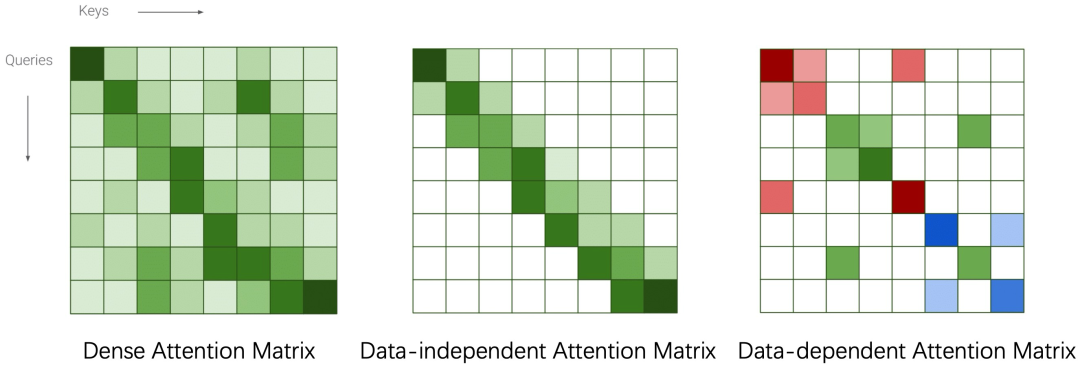
稀疏Transformer的核心思想是通過一些方式將稠密的注意力矩陣變稀疏從而減少理論復(fù)雜度。根據(jù)稀疏方式的不同分為Data-independent Pattern和Data-dependent Pattern。前者包括Blockwise Transformer[2]、Sparse Transformer[3]、Longformer[4]和Big Bird[5]。后者則包括Linformer[6]、Reformer[7]、Routing Transformer[8]、Clustered Attention[9]、Sinkhorn Transformer[10]。值得注意的是稀疏Transformer的實(shí)際效率與顯存占用與具體實(shí)現(xiàn)方式相關(guān),在很多情況下相比于標(biāo)準(zhǔn)Transformer在速度上有提升但是顯存占用不一定符合理論分析。在LLM模型中,GPT3采用的是Sparse Transformer。由于稀疏Transformer的效果必然會(huì)比標(biāo)準(zhǔn)Transformer差,在之后的研究中逐漸被拋棄。
線性Transformer
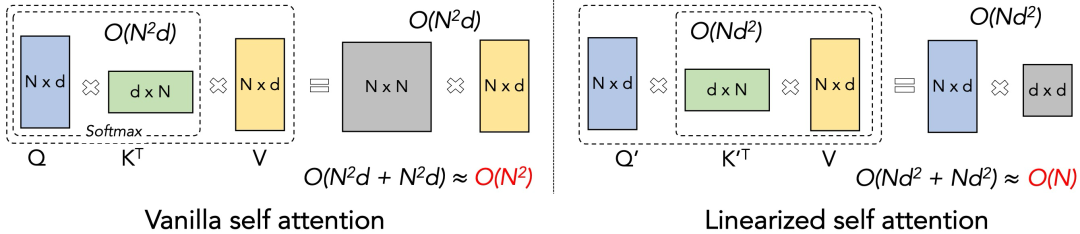
線性Transformer的核心思想是通過Kernel trick的方式,如上圖所示,將QKV的左乘變成右乘,從而將理論計(jì)算復(fù)雜度降為線性。由于SoftMax操作中的exp(<·,·>)運(yùn)算不滿足(Q·K)·V = Q·(K·V)的條件,在cosFormer[11]提出之前,主流解決方案是通過一些滿足條件的操作來近似SoftMax。例如RFA[12] 利用Rahimi & Recht 在2007年提出的Gaussian kernel的無偏估計(jì)來高效的近似SoftMax注意力。類似的方法還有Linear Transformer[13]、Performer[14]等。這些方案的主要缺陷在于它們都是對(duì)softmax的近似,所以效果的天花板即為標(biāo)準(zhǔn)Transformer。同時(shí),因?yàn)樗肓祟~外的計(jì)算,所以在d (feature維度)較大的情況下相比于transformer不會(huì)有太大的效率優(yōu)勢(shì)。實(shí)際上,在我們的實(shí)驗(yàn)中,大部分方法在實(shí)際場(chǎng)景下均比Transformer慢。同時(shí)由于這些方法對(duì)于超參和網(wǎng)絡(luò)初始化非常敏感,需要精細(xì)化的調(diào)參才能得到較好的結(jié)果,所以這些在benchmark (Long-Range Arena)的理想情況下效果不錯(cuò)的方法并沒有研究人員把它們應(yīng)用在LLM中。
然而,線性Transformer最大的優(yōu)勢(shì)在于恒定的推理速度,這樣在長序列的預(yù)測(cè)中相比于Transformer會(huì)有巨大的效率優(yōu)勢(shì)。如下圖所示,Ours為一種線性Transformer,在序列長度增加的情況下,保持了恒定的推理速度、顯存占用;同時(shí)標(biāo)準(zhǔn)的Transformer以及采用了KV Cache優(yōu)化的標(biāo)準(zhǔn)Transformer則在序列長度增加的情況下需要數(shù)倍至數(shù)十倍的時(shí)間和顯存。
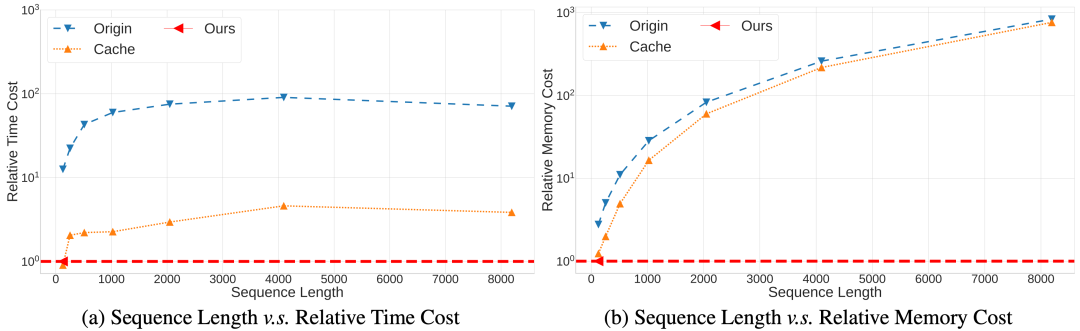
在這個(gè)優(yōu)勢(shì)下,線性Transformer作為一種有希望的高效序列建模的方向,得到了很多研究人員的關(guān)注,并期望可以在LLM下得到實(shí)際應(yīng)用。這項(xiàng)研究的轉(zhuǎn)機(jī)出現(xiàn)在cosFormer的提出。研究人員跳出了近似SoftMax的窠臼,采用簡單的ReLU激活函數(shù)配合cosine函數(shù)對(duì)鄰域加權(quán)即可得到類似于Transformer的效果。這種方案極大的簡化了線性Transformer的計(jì)算,讓實(shí)際速度超越標(biāo)準(zhǔn)Transformer成為了可能。同時(shí),由于這種方案無需近似SoftMax, 讓實(shí)際效果超越Transformer亦成為了可能。同年,Qin et al. 在EMNLP會(huì)議上提出了TransNormer[15],針對(duì)線性Transformer效果達(dá)不到標(biāo)準(zhǔn)Transformer給出了理論和實(shí)驗(yàn)證明,首次在小規(guī)模模型和數(shù)據(jù)集上超越了標(biāo)準(zhǔn)Transformer。次年,TransNormerLLM[16]集成了多個(gè)相對(duì)位置編碼以及深度的工程優(yōu)化,提出Lighting Attention的線性注意力架構(gòu),首次在效率與模型精度上全面超越標(biāo)準(zhǔn)Transformer,并在175B的超大規(guī)模參數(shù)和1.6T訓(xùn)練數(shù)據(jù)下做了初步驗(yàn)證,讓線性Transformer進(jìn)入LLM成為了可能。
長卷積
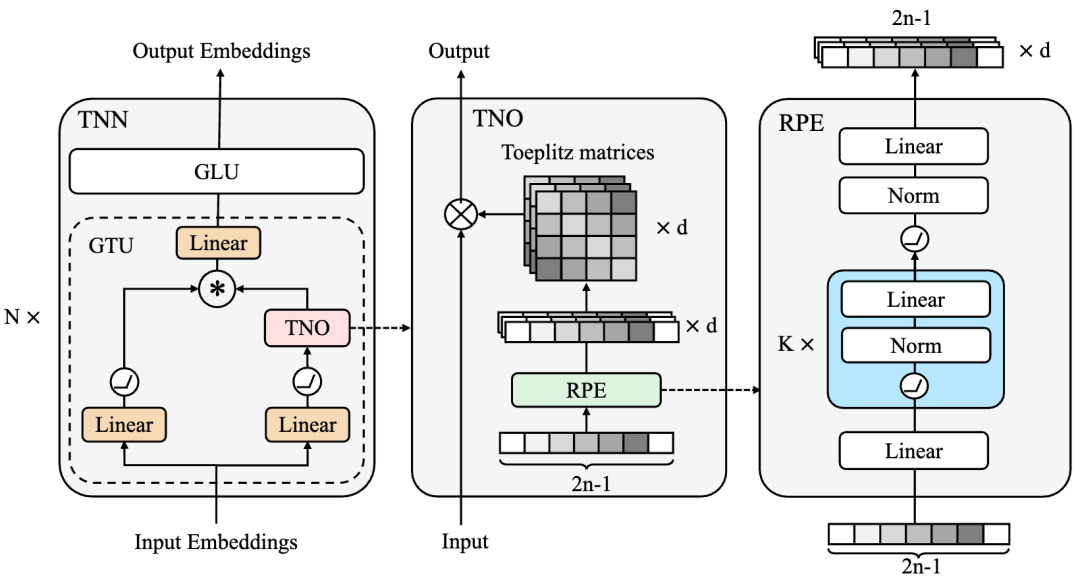
長卷積 (LongConv) 是近期提出一種序列建模方式,其核心思想是通過設(shè)計(jì)一個(gè)核長度為整個(gè)輸入序列長度的卷積神經(jīng)網(wǎng)絡(luò)來建模序列。這種方式的理論計(jì)算復(fù)雜度為 ,空間復(fù)雜度為 ,n為序列長度,d為特征維度。相比于線性Transformer的 計(jì)算和空間復(fù)雜度,長卷積在特征維度較大的LLM中會(huì)有一定的速度優(yōu)勢(shì)。目前基于長卷積的序列建模方法有TNN[17]、H3[18]、Hyena[19]、S4[20]等,值得注意的是,著名的開源項(xiàng)目RWKV也可以寫成長卷積的形式。其中TNN采用Toeplitz matrix來刻畫相對(duì)位置信息并將其作為長卷積的卷積核。S4則采用了一個(gè)全新的基于State Space Model (SSM)網(wǎng)絡(luò)層,將序列建模成一個(gè)連續(xù)的狀態(tài)空間的離散表示。
然而想要將這些方法推廣到LLM下仍然存在各種困難。例如,LLM訓(xùn)練對(duì)于模型的穩(wěn)定性要求非常高,然而S4因?yàn)镾SM的數(shù)學(xué)結(jié)構(gòu)復(fù)雜,在生成卷積核的時(shí)候需要非常細(xì)致的參數(shù)初始化才能得到較好的結(jié)果,這讓S4很難將參數(shù)量擴(kuò)增到千億規(guī)模。TNN雖然對(duì)參數(shù)不敏感,訓(xùn)練穩(wěn)定,并且在fp32下相對(duì)于Transformer有速度和精度的優(yōu)勢(shì),但是由于其引入了fft,在fp16或者bf16下,速度都很難超越通過Flash Attention優(yōu)化過的Transformer。如何將TNN做進(jìn)一步的IO優(yōu)化使其顯示出理論的計(jì)算復(fù)雜度優(yōu)勢(shì)是未來的研究方向之一。除此之外,長卷積的推理理論計(jì)算復(fù)雜度為O(nd log n),這讓這種方法的推理速度略慢于線性Transformer。最新的研究表明,長卷積都可以無損的在推理的時(shí)候轉(zhuǎn)化為RNN的模式,從而讓它們的推理速度與線性Transformer一致。從當(dāng)前的研究發(fā)現(xiàn)來看,長卷積是一個(gè)很有希望的,可以應(yīng)用在LLM中的結(jié)構(gòu),但是仍然需要大量的工程優(yōu)化使其達(dá)到理論速度。
循環(huán)神經(jīng)網(wǎng)絡(luò)
循環(huán)神經(jīng)網(wǎng)絡(luò) (RNN) 是一個(gè)歷史悠久的序列建模方式,其最大的優(yōu)勢(shì)在于恒定的推理速度:其推理速度僅跟隱狀態(tài)大小相關(guān)。由于RNN的序列特性,即當(dāng)前狀態(tài)基于上一個(gè)狀態(tài)的結(jié)果(如下圖所示),使得它無法像Transformer一樣做到完全并行化處理,并且對(duì)GPU處理不友好,從而在深度神經(jīng)網(wǎng)絡(luò)的年代逐步被Transformer給取代。
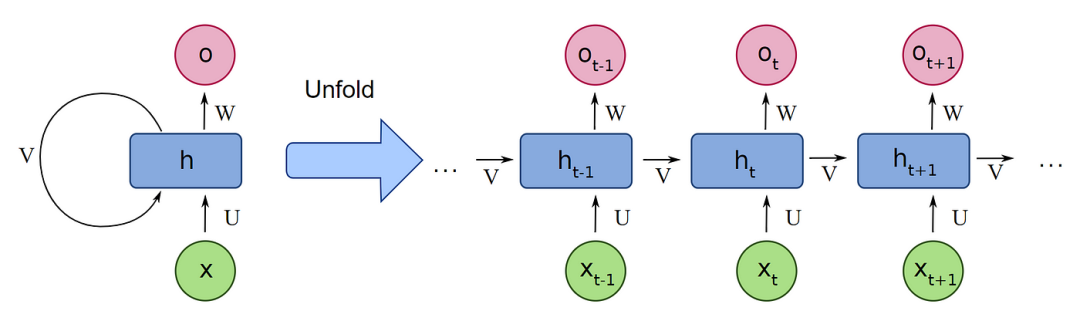
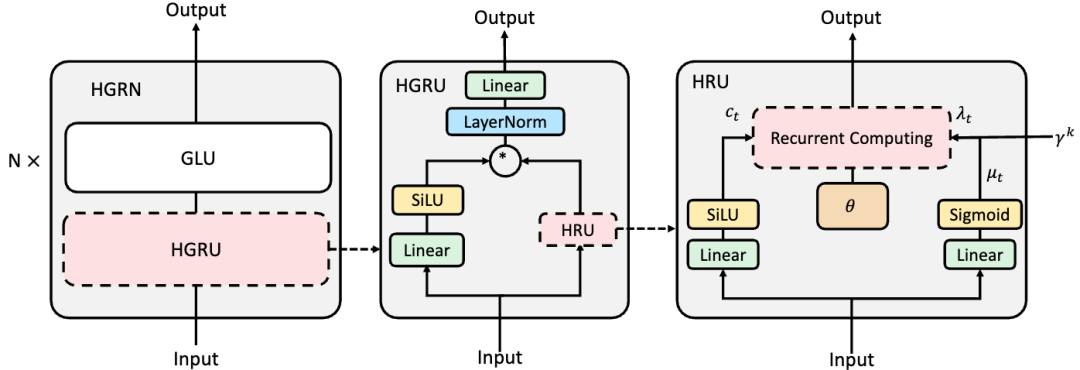
然而,最近的研究表明,RNN以及它們的變種可以被大幅簡化而不影響結(jié)果。Klaus et al.[21] 在2015年證明了LSTM結(jié)構(gòu)中存在大量多余的門控并強(qiáng)調(diào)了遺忘門的重要性。Eric et al.[22] 在ICLR 2018上證明了RNN中間層的非線性并不必須。Shuai et al.[23] 2018 則證明了RNN的循環(huán)權(quán)重矩陣需要是對(duì)角陣,這樣RNN不同狀態(tài)之間可以保證相互獨(dú)立。同年, Tao et al.[24] 在EMNLP會(huì)議上證明了在這種情況下,RNN的隱狀態(tài)更新可以表示為逐元素的向量積,從而做到完全并行化處理,至此RNN重新站上深度神經(jīng)網(wǎng)絡(luò)平臺(tái)。同時(shí),這種RNN被定義為線性RNN。上文提到的S4也可以寫成線性形式,另外一個(gè)比較出名的序列建模結(jié)構(gòu)RWKV也歸屬于這一類。當(dāng)前先進(jìn)的RNN架構(gòu)的問題在于1.絕大多數(shù)RNN在語言建模上仍然難以達(dá)到比肩Transformer的水平;2. 需要非常精細(xì)化的初始化以達(dá)到較好的收斂;3. 雖然RNN的理論計(jì)算復(fù)雜度為 ,空間復(fù)雜度為 (其中d為隱空間維度大小),為所有的方法中最小,但是在實(shí)際效率上仍然難以比肩經(jīng)過多年優(yōu)化之后的Transformer。值得注意的是,這一方法在近期的進(jìn)展迅速,其中Qin提出了如下圖所示的分層門控循環(huán)神經(jīng)網(wǎng)絡(luò) HGRN[25],首次在較大規(guī)模的網(wǎng)絡(luò)(10億參數(shù))和大規(guī)模語料(3000億token)上表現(xiàn)出了比Transformer更優(yōu)的結(jié)果,且不需要精細(xì)的初始化即可進(jìn)行穩(wěn)定的訓(xùn)練,為線性RNN成為LLM的基礎(chǔ)架構(gòu)鋪平了道路。
3
高效大語言模型進(jìn)展
近年來,高效序列建模的算法層出不窮,但是可以落地到大語言模型上的鳳毛麟角。主要原因在于LLM的主流還是Transformer架構(gòu),并且是已經(jīng)優(yōu)化了多年的Transformer架構(gòu),甚至在硬件上都有進(jìn)一步的優(yōu)化,使得Transformer在效率和效果上都已經(jīng)接近算法的極限。相比之下,高效序列建模算法作為一個(gè)剛起步的算法,即使在理論計(jì)算復(fù)雜度上有優(yōu)勢(shì),在實(shí)際應(yīng)用中也很難做到效率或者效果上超過優(yōu)化后的Transformer。同時(shí),訓(xùn)練LLM是一個(gè)綜合實(shí)力的體現(xiàn),不但需要專業(yè)的數(shù)據(jù)處理團(tuán)隊(duì)來采集并處理大量的預(yù)訓(xùn)練語料,研究數(shù)據(jù)配比,也需要模型并行優(yōu)化工程師針對(duì)新推出的結(jié)構(gòu)進(jìn)行并行優(yōu)化。更重要的是,訓(xùn)練LLM需要投入大量的資金,高效序列建模的算法往往只在小規(guī)模上進(jìn)行了驗(yàn)證,它們是否在大規(guī)模參數(shù)和語料下保持一致的訓(xùn)練穩(wěn)定性和優(yōu)異性仍然是一個(gè)未知數(shù)。在這種情況下,采用萬無一失的Transformer架構(gòu)遠(yuǎn)比新架構(gòu)的風(fēng)險(xiǎn)低,導(dǎo)致在LLM競(jìng)爭激烈的當(dāng)前,Transformer仍為LLM的首選架構(gòu)。
在高效大語言模型的研發(fā)上,RWKV是第一個(gè)將參數(shù)量擴(kuò)充到140億的非Transformer架構(gòu)的模型,其在開放語料Pile上進(jìn)行了預(yù)訓(xùn)練,達(dá)到了和Transformer相當(dāng)?shù)乃疁?zhǔn)。近日,上海人工智能實(shí)驗(yàn)室提出TransNormerLLM,首次將線性Transformer的參數(shù)量擴(kuò)充到了1750億,并實(shí)現(xiàn)了模型并行速度優(yōu)化,在速度和精度上均超越了基于Flash attention的Transformer。其中訓(xùn)練速度比Flash attention Transformer快20%,困惑度 (ppl)比Flash attention Transformer低9%。在推理速度上,如下圖所示,由于TransNormerLLM的恒定的推理速度優(yōu)勢(shì),在長序列上有著數(shù)倍的效率提升,且序列越長,提升越明顯。
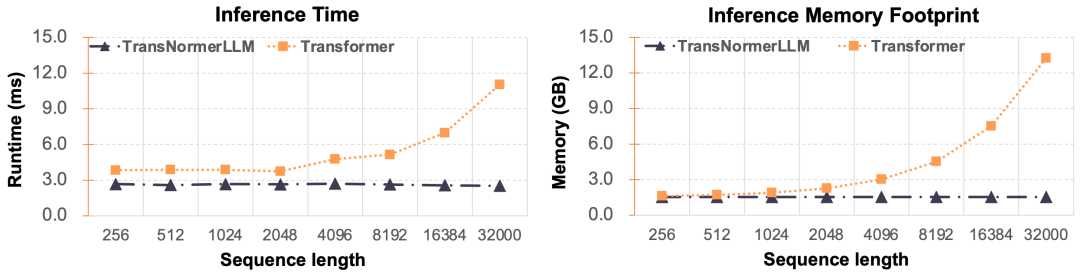
LLM的效率體現(xiàn)在訓(xùn)練效率和推理效率上。由于架構(gòu)的特性,TransNormerLLM在推理上對(duì)于Transformer有無可比擬的速度優(yōu)勢(shì),如此以來,在高效LLM的優(yōu)化中,我們只需要著重考慮訓(xùn)練效率的提升以及推理的穩(wěn)定性。根據(jù)優(yōu)化方向的不同,我們將影響的LLM的訓(xùn)練速度的因素分為三大塊:1. 網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)化,包括位置編碼的設(shè)計(jì)、門控機(jī)制、激活函數(shù)、張量歸一化的方式等;2. 算法工程優(yōu)化,包括attention算子的實(shí)現(xiàn)方式、歸一化函數(shù)的實(shí)現(xiàn)方式等;3. 分布式系統(tǒng)的優(yōu)化,包括張量并行、模型并行方式的實(shí)現(xiàn)等。通過上述方面的高度優(yōu)化,TransNormerLLM做到了在生產(chǎn)環(huán)境下的訓(xùn)練效率上超過了經(jīng)過Flash attention加持的Transformer架構(gòu)。同時(shí),我們提出了新的魯棒推理算法,從理論上證明了新算法可以極大的維持LLM的推理數(shù)值穩(wěn)定性。接下來,我們將介紹TransNormerLLM優(yōu)化的技術(shù)細(xì)節(jié)。
結(jié)構(gòu)優(yōu)化
-
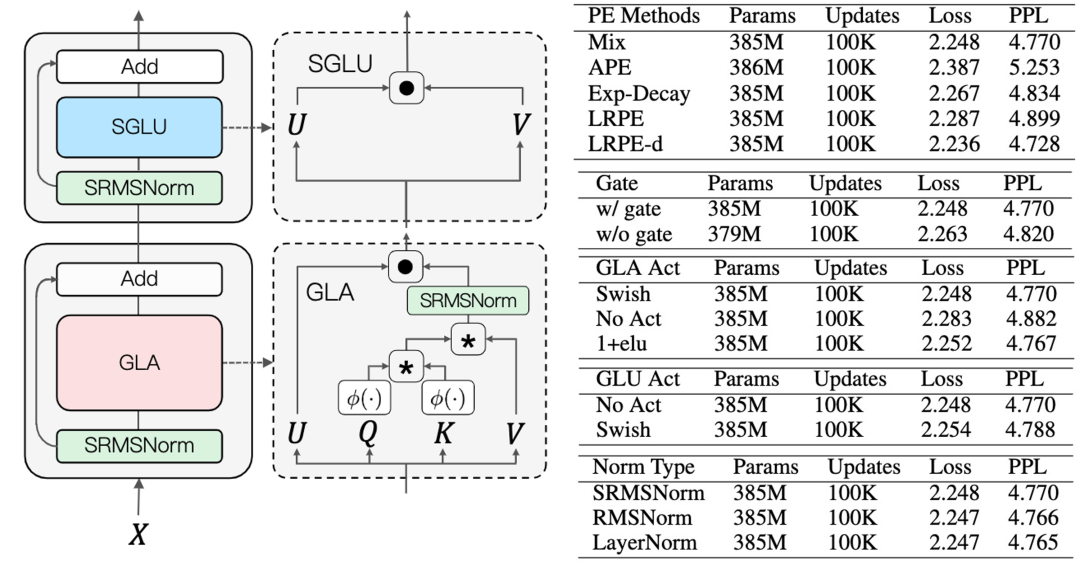
位置編碼:線性Transformer有注意力分散的先天缺陷。為了解決這個(gè)問題,原版TransNormer的解決方案是在網(wǎng)絡(luò)的前幾層采用稀疏注意力結(jié)構(gòu)中的對(duì)角注意力。但是由于采用的仍然是SoftMax注意力機(jī)制,這種方案對(duì)長序列不友好,同時(shí)也舍棄了Transformer中token的全局交互能力。在TransNormerLLM中,我們改進(jìn)了這個(gè)方案,采用我們?cè)赥MLR 2023上提出的LRPE位置編碼并結(jié)合指數(shù)衰減來達(dá)到同樣的目的,同時(shí)保留token的全局交互能力。相比于絕對(duì)位置編碼,我們發(fā)現(xiàn)采用上述的位置編碼可提升10%的模型效果(ppl)。同時(shí)經(jīng)過進(jìn)一步的實(shí)驗(yàn)我們發(fā)現(xiàn),只在網(wǎng)絡(luò)的第一層加入LRPE,剩余的層采用指數(shù)衰減可以加速模型20%并且沒有明顯的性能損失。因此,我們最終的模型即采用的上述位置編碼方案。 -
門控機(jī)制:我們引入了門控機(jī)制來提升模型的性能和訓(xùn)練的穩(wěn)定性。如下圖所示,我們分別在GLA (Gated Linear Attention)和GLU (Gated Linear Unit)中添加了門控機(jī)制。在GLA中,我們同時(shí)對(duì)比了多種門控激活函數(shù),相比于不添加激活函數(shù),采用Swish激活函數(shù)可以將性能提升3%。為了加速模型,我們將GLU中的激活函數(shù)取消,我們發(fā)現(xiàn)在GLU中不加激活函數(shù)對(duì)模型性能影響不大。 -
張量歸一化:為了解決線性Transformer中梯度無界導(dǎo)致訓(xùn)練收斂不佳的問題,TransNormer采用直接對(duì)于QKV的乘積做歸一化的方式來讓梯度收斂,其采用的歸一化方式為RMSNorm。在TransNormerLLM中,我們發(fā)現(xiàn)將RMSNorm中的可學(xué)權(quán)重參數(shù)去掉并不會(huì)影響結(jié)果,為了簡化模型,我們?nèi)サ袅诉@個(gè)權(quán)重參數(shù)并將這種歸一化方式稱為SRMSNorm (Simple RMSNorm)。 這樣,TransNormerLLM的最終結(jié)構(gòu)為下左圖所示。
算法優(yōu)化
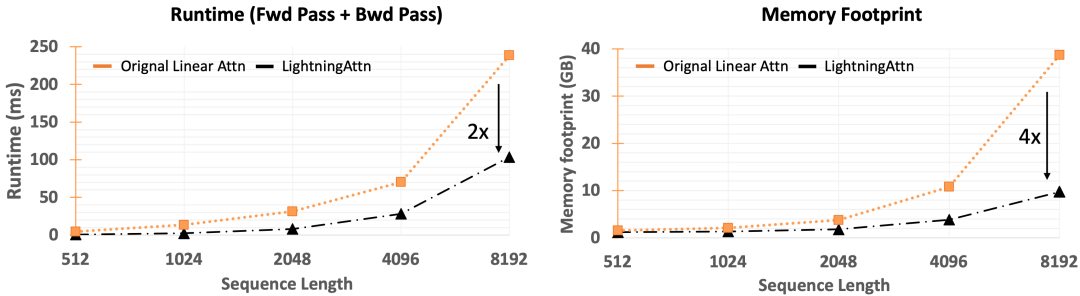
算法的性能與算法的工程優(yōu)化程度高度相關(guān),之前的高效序列建模的方法在生產(chǎn)環(huán)境中相比于Transformer無法顯示出其本身的效率優(yōu)勢(shì)的一大因素就是缺乏工程優(yōu)化。在TransNormerLLM中,我們針對(duì)線性Attention和歸一化函數(shù)做了細(xì)致的工程優(yōu)化:1. 我們提出了Lightning Attention并用Triton做了大量的IO優(yōu)化,實(shí)現(xiàn)了2倍的速度提升以及減少了3/4的顯存占用;2. 我們優(yōu)化了SRMSNorm的實(shí)現(xiàn)方式,實(shí)現(xiàn)了數(shù)十倍的效率提升。
-
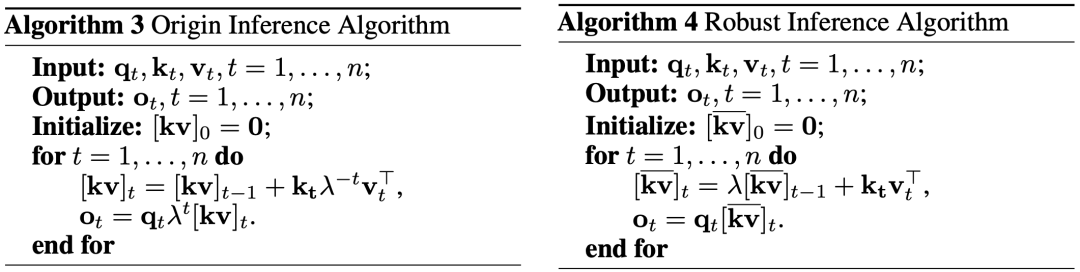
Lightning Attention 線性Attention的理論計(jì)算效率優(yōu)勢(shì)體現(xiàn)在QKV的右乘上,將理論計(jì)算復(fù)雜度從O(n^2d)降到了O(nd^2)。但是在語言模型中,右乘的運(yùn)算需要通過一系列的對(duì)并行不友好的循環(huán)來實(shí)現(xiàn),在實(shí)際的大規(guī)模并行運(yùn)算中,往往比左乘更慢。所以在我們的實(shí)現(xiàn)中,仍然采用左乘的形式。具體算法如下:

下圖顯示了經(jīng)過我們的工程優(yōu)化,當(dāng)前的Triton版Lightning attention比Pytorch版提升了2倍的速度和4倍的顯存優(yōu)勢(shì)。
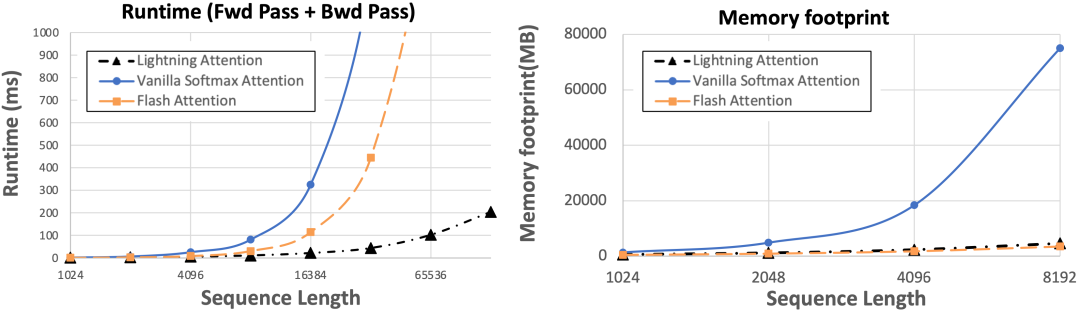
值得注意的是,我們也有右乘的實(shí)現(xiàn),解決了右乘并行運(yùn)算問題,將Lightning Attention做了進(jìn)一步的加速。如下圖所示,Lightning算法在常見的8k序列長度的時(shí)候已經(jīng)比Transformer下最先進(jìn)的Flash attention 2快了1倍,當(dāng)序列長度繼續(xù)增加的時(shí)候,Lightning attention的優(yōu)勢(shì)持續(xù)增大,在132k下達(dá)到了十倍以上的差異。
-
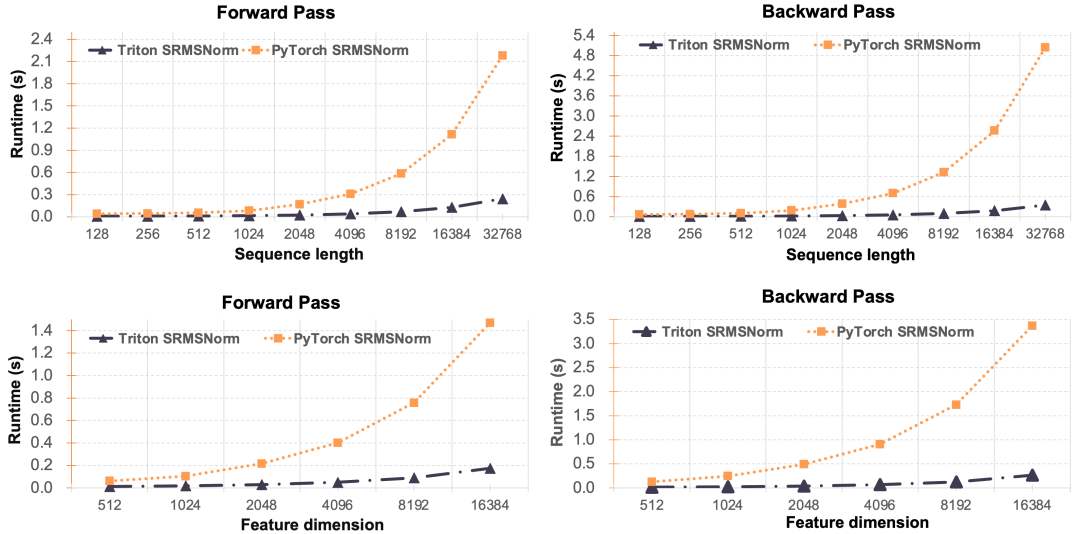
SRMSNorm 類似于Lightning Attention,我們同樣對(duì)于SRMSNorm做了工程優(yōu)化,如下圖所示,我們的Triton版SRMSNorm相比于Pytorch版實(shí)現(xiàn)的令人驚異的優(yōu)勢(shì)。
系統(tǒng)優(yōu)化
我們的TransNormerLLM模型采用Fully Sharded Data Parallel (FSDP)技術(shù)來在整個(gè)集群中分配參數(shù)、梯度和優(yōu)化器狀態(tài)。我們也采用了Activation Checkpointing技術(shù)來減少誤差反傳的顯存占用。另外,不同于之前的高效序列建模方法往往只能工作在fp32下或者只在fp32下才能顯示出效率優(yōu)勢(shì),我們的算法實(shí)現(xiàn)了Automatic Mixed Precision (AMP)來減少顯存開銷,并且在BFloat16下同樣顯示出了訓(xùn)練的高效性和穩(wěn)定性。除此之外,我們還針對(duì)TransNormerLLM做了模型并行。值得注意的是,由于Transformer跟TransNormer在網(wǎng)絡(luò)基礎(chǔ)架構(gòu)上的差異,我們無法沿用之前Transformer的模型并行方案,但是我們的模型并行很大程度上受到了Nvidia 的 MegatronLM 模型并行的啟發(fā)。在傳統(tǒng)Transformer架構(gòu)中,每一層都包括一個(gè)自注意力模塊和兩層多層感知器(MLP)模塊,使用時(shí)Megatron-LM在這兩個(gè)模塊上獨(dú)立使用模型并行。同樣,TransNormerLLM每一層也包含兩個(gè)模塊SGLU和GLA,我們分別對(duì)每個(gè)模塊執(zhí)行模型并行。下圖我們對(duì)比了不同的模型大小和速度,以及最大的訓(xùn)練序列長度。

推理優(yōu)化
線性Transformer的一大優(yōu)勢(shì)就是在推理的時(shí)候可以轉(zhuǎn)化為RNN的形式,讓推理速度跟序列長度無關(guān)。但是在實(shí)際中我們發(fā)現(xiàn),直接的轉(zhuǎn)化(下圖左)會(huì)造成數(shù)值精度不穩(wěn)定問題。為了解決這個(gè)問題,我們提出了一個(gè)新的魯棒推理算法(下圖右)來保證推理時(shí)候的數(shù)值穩(wěn)定性。
4
數(shù)據(jù)處理
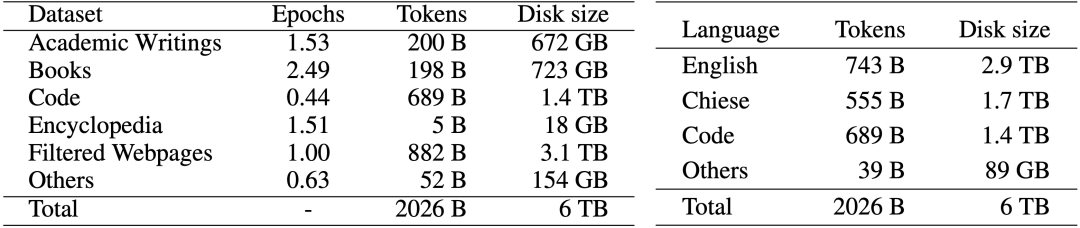
LLM的最終效果跟模型結(jié)構(gòu)和預(yù)訓(xùn)練數(shù)據(jù)相關(guān)。其中,預(yù)訓(xùn)練數(shù)據(jù)的質(zhì)量與數(shù)量對(duì)最終LLM的效果的影響遠(yuǎn)大與模型結(jié)構(gòu)。我們?cè)跇?biāo)準(zhǔn)學(xué)術(shù)數(shù)據(jù)集的評(píng)測(cè)中已經(jīng)展現(xiàn)出了當(dāng)前的模型結(jié)構(gòu)無論在效率還是效果上均優(yōu)于Transformer架構(gòu),為了訓(xùn)練高質(zhì)量的高效LLM模型,我們?nèi)匀恍枰哔|(zhì)量的預(yù)訓(xùn)練數(shù)據(jù)來訓(xùn)練LLM。由于當(dāng)前各個(gè)公司和研究機(jī)構(gòu)的LLM的預(yù)訓(xùn)練語料都處于非公開狀態(tài),我們獨(dú)立從互聯(lián)網(wǎng)上收集了大量可公開訪問的文本,總計(jì)超過 700TB。收集到的數(shù)據(jù)經(jīng)過我們?nèi)缦聢D所示的數(shù)據(jù)預(yù)處理程序進(jìn)行處理,留下 6TB 的清理語料庫,其中包含大約 2 萬億個(gè)token。
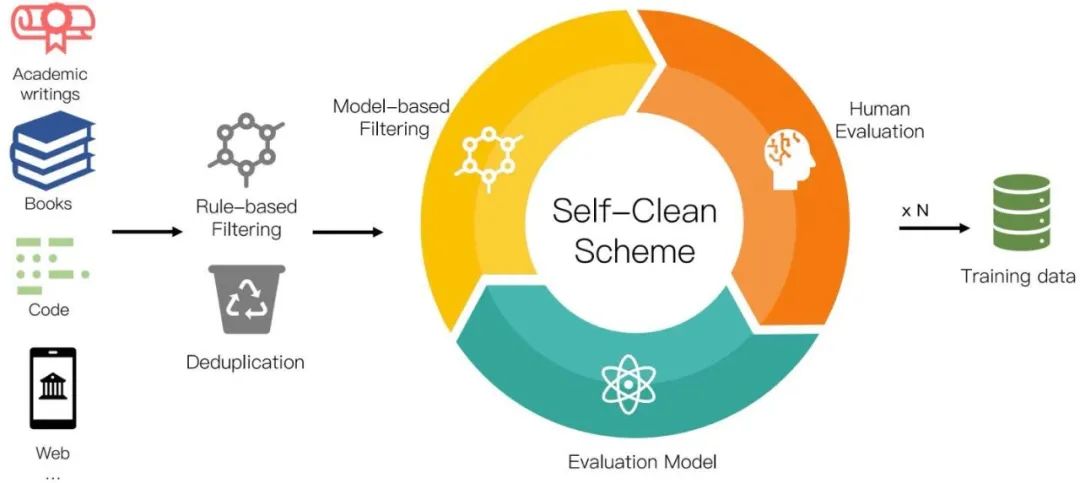
我們的數(shù)據(jù)預(yù)處理過程包括三個(gè)步驟:1). 基于規(guī)則的過濾,2). 重復(fù)數(shù)據(jù)刪除、和 3). 自清潔過濾。具體數(shù)據(jù)處理方法見論文。在添加到訓(xùn)練語料庫之前,清理后的語料庫需要由人類來評(píng)價(jià)。我們最終的數(shù)據(jù)分布如下圖所示:
5
Benchmark結(jié)果
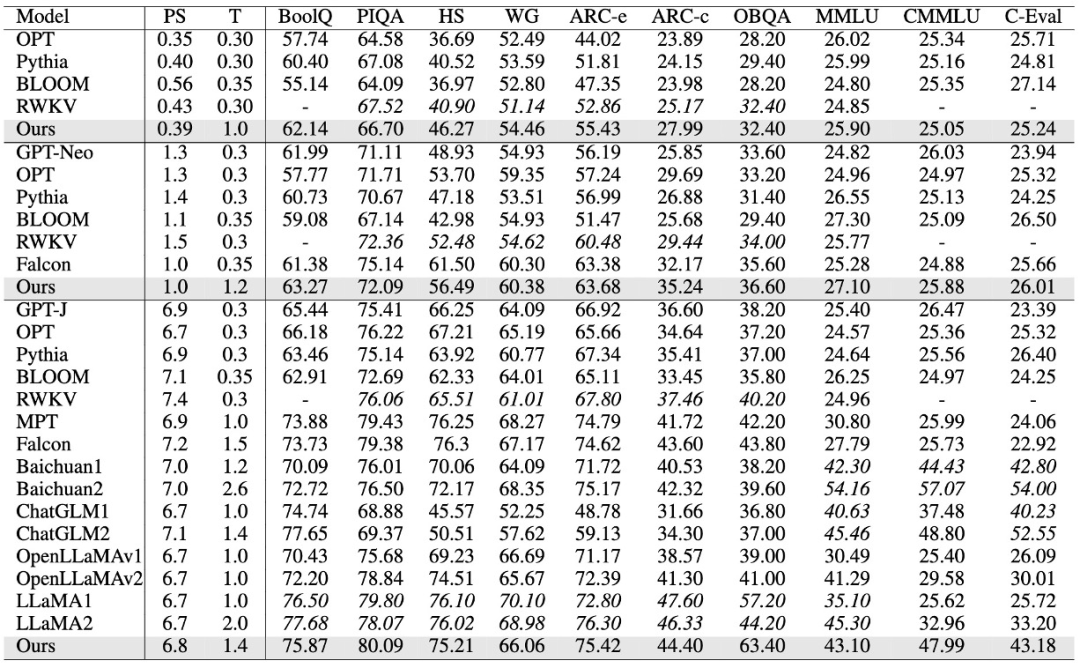
我們?cè)谧约旱念A(yù)訓(xùn)練數(shù)據(jù)集上訓(xùn)練了385M,1B,以及7B大小的模型,并在標(biāo)準(zhǔn)的LLM學(xué)術(shù)Benchmark上評(píng)測(cè)了我們的結(jié)果。針對(duì)常識(shí)性任務(wù),我們選取BoolQ, PIQA, SIQA, HellaSwag, WinoGrande, ARC easy and challenge, 和OpenBookQA Benchmarks。我們采用0-shot LM-Eval-Harness作為我們的評(píng)測(cè)方式。對(duì)于綜合任務(wù),我們選取5-shot 的MMLU,CMMLU和C-Eval Benchmark的結(jié)果作為我們的中英文評(píng)測(cè)結(jié)果。 如下表所示,我們的模型在385M,1B,7B均體現(xiàn)出了非常有競(jìng)爭力的結(jié)果。在英文上,我們的模型僅次于LLaMA2,ChatGLM2,和Baichuan2;在中文上,我們僅次于ChatGLM2和Baichuan2。其中PS表示模型大小,單位是Billion,T表示訓(xùn)練的token數(shù),單位是Trillion。HS表示HellaSwag,WG表示W(wǎng)inoGrande。值得注意的是,當(dāng)前我們的7B模型在預(yù)訓(xùn)練階段的序列長度為8K。在我們的Lightning Attention V2中,已經(jīng)實(shí)現(xiàn)了訓(xùn)練速度與序列長度無關(guān),所以未來的TransNormerLLM將可以采用硬件限制下的最大預(yù)訓(xùn)練長度,在無損速度的情況下進(jìn)行全量預(yù)訓(xùn)練。
6
高效大語言模型展望
無可否認(rèn),TransNormerLLM的提出和開源將是大語言模型發(fā)展歷程中的重要里程碑。而這一轉(zhuǎn)變,預(yù)示著我們正從標(biāo)準(zhǔn)Transformer架構(gòu)的優(yōu)化階段步入到高效大語言模型的優(yōu)化上。我們相信,在廣大研究者的共同努力下,高效大語言模型的技術(shù)將日臻成熟,應(yīng)用領(lǐng)域?qū)⒏訌V泛。這樣的變革,如同一場(chǎng)盛大的交響樂,我們期待著下一個(gè)音符的出現(xiàn),期待著高效大語言模型的下一個(gè)篇章。
7
相關(guān)資料
論文地址:
https://openreview.net/pdf?id=OROKjdAfjs
開源代碼:
https://github.com/OpenNLPLab/TransnormerLLM
開源模型:
https://huggingface.co/OpenNLPLab
參考文獻(xiàn):
Language Models are Few-Shot Learners: https://arxiv.org/abs/2005.14165
[2]Blockwise Self-Attention for Long Document Understanding: https://arxiv.org/abs/1911.02972
[3]Generating Long Sequences with Sparse Transformers: https://arxiv.org/abs/1904.10509
[4]Longformer: The Long-Document Transformer: https://arxiv.org/abs/2004.05150
[5]Big Bird: Transformers for Longer Sequences: https://arxiv.org/abs/2007.14062
[6]Linformer: Self-attention with linear complexity: https://arxiv.org/abs/2006.04768
[7]Reformer: The efficient transformer: https://arxiv.org/abs/2001.04451
[8]Efficient content-based sparse attention with routing transformers: https://arxiv.org/abs/2003.05997
[9]Fast transformers with clustered attention: https://arxiv.org/abs/2007.04825
[10]Sparse sinkhorn attention: https://arxiv.org/abs/2002.11296
[11]cosformer: Rethinking softmax in attention: https://arxiv.org/abs/2202.08791
[12]Random feature attention: https://arxiv.org/abs/2103.02143
[13]Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention: https://arxiv.org/abs/2006.16236
[14]Rethinking attention with performers: https://arxiv.org/abs/2009.14794
[15]The devil in linear transformer: https://arxiv.org/abs/2210.10340
[16]Scaling TransNormer to 175 Billion Parameters: https://arxiv.org/abs/2307.14995
[17]Toeplitz Neural Network for Sequence Modeling: https://arxiv.org/abs/2305.04749
[18]Hungry Hungry Hippos: Towards Language Modeling with State Space Models: https://arxiv.org/abs/2212.14052
[19]Hyena Hierarchy: Towards Larger Convolutional Language Models: https://arxiv.org/abs/2302.10866
[20]Efficiently Modeling Long Sequences with Structured State Spaces: https://arxiv.org/abs/2111.00396
[21]LSTM: A Search Space Odyssey: https://arxiv.org/abs/1503.04069
[22]Parallelizing Linear Recurrent Neural Nets Over Sequence Length: https://arxiv.org/abs/1709.04057
[23]Independently Recurrent Neural Network (IndRNN): Building A Longer and Deeper RNN: https://arxiv.org/abs/1803.04831
[24]Simple Recurrent Units for Highly Parallelizable Recurrence: https://arxiv.org/abs/1709.02755
[25]Hierarchically Gated Recurrent Neural Network for Sequence Modeling: https://neurips.cc/virtual/2023/poster/71783
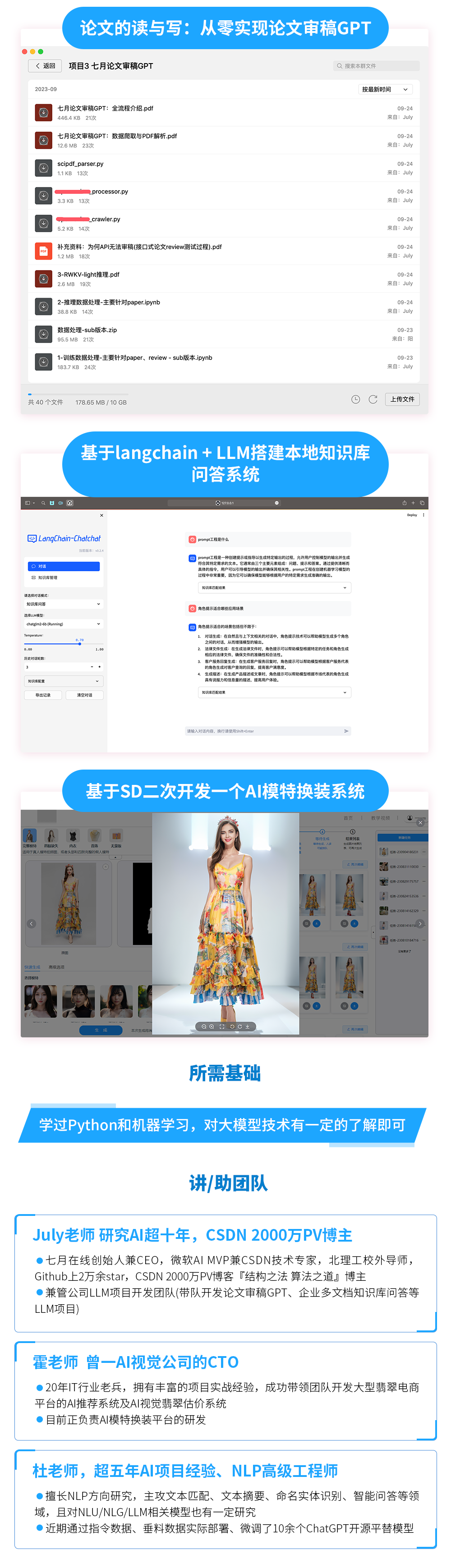
更多大模型內(nèi)容在「大模型項(xiàng)目開發(fā)線上營」
前20人報(bào)名,除了VIP年卡外,還多送兩個(gè)大模型小課:類ChatGPT微調(diào)實(shí)戰(zhàn)、LLM與langchain/知識(shí)圖譜/數(shù)據(jù)庫的實(shí)戰(zhàn),如已有這兩課,可以選同等價(jià)位別的課
↓↓↓掃碼搶購↓↓↓
課程咨詢可找蘇蘇老師VX:julyedukefu008或七月在線其他老師
點(diǎn)擊“閱讀原文”了解課程詳情~
