
學到一招!三行 Python 代碼輕松提取 PDF 表格數據!

來源丨網絡
大家好,我是菜鳥哥~
從 PDF 表格中獲取數據是一項痛苦的工作。不久前,一位開發(fā)者提供了一個名為 Camelot 的工具,使用三行代碼就能從 PDF 文件中提取表格數據。
項目地址:https://github.com/camelot-dev/camelot
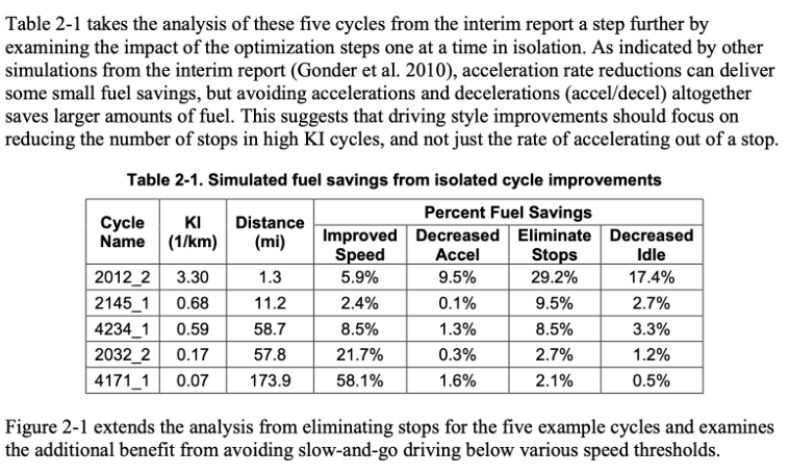
>>>?import?camelot
>>>?tables?=?camelot.read_pdf('foo.pdf')?#類似于Pandas打開CSV文件的形式
>>>?tables[0].df?#?get?a?pandas?DataFrame!
>>>?tables.export('foo.csv',?f='csv',?compress=True)?#?json,?excel,?html,?sqlite,可指定輸出格式
>>>?tables[0].to_csv('foo.csv')?#?to_json,?to_excel,?to_html,?to_sqlite,?導出數據為文件
>>>?tables
1>
>>>?tables[0]
7,?7)>?#?獲得輸出的格式
>>>?tables[0].parsing_report
{
????'accuracy':?99.02,
????'whitespace':?12.24,
????'order':?1,
????'page':?1
}
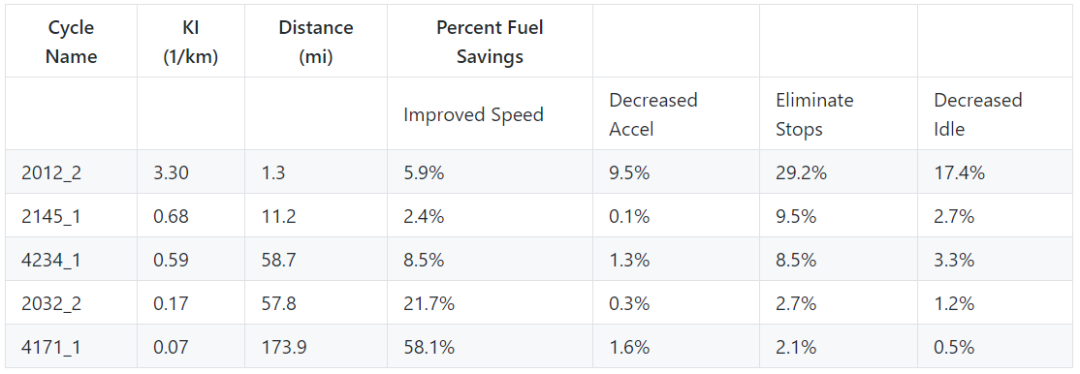
conda?install?-c?conda-forge?camelot-py
pip?install?camelot-py[cv]
git?clone?https://www.github.com/camelot-dev/camelot
cd?camelot
pip?install?".[cv]"這是我開發(fā)的機器人公眾號小號,目前增加了天氣查詢,955公司名單,關注時間查詢;后面還會增加圖片功能和每日送書抽獎送書活動,以及調戲功能,歡迎來體驗,捧場。
推薦閱讀:
入門:?最全的零基礎學Python的問題? |?零基礎學了8個月的Python??|?實戰(zhàn)項目?|學Python就是這條捷徑
干貨:爬取豆瓣短評,電影《后來的我們》?|?38年NBA最佳球員分析?|? ?從萬眾期待到口碑撲街!唐探3令人失望? |?笑看新倚天屠龍記?|?燈謎答題王?|用Python做個海量小姐姐素描圖?|碟中諜這么火,我用機器學習做個迷你推薦系統(tǒng)電影
趣味:彈球游戲? |?九宮格? |?漂亮的花?|?兩百行Python《天天酷跑》游戲!
AI:?會做詩的機器人?|?給圖片上色?|?預測收入?|?碟中諜這么火,我用機器學習做個迷你推薦系統(tǒng)電影
小工具:?Pdf轉Word,輕松搞定表格和水印!?|?一鍵把html網頁保存為pdf!|??再見PDF提取收費!?|?用90行代碼打造最強PDF轉換器,word、PPT、excel、markdown、html一鍵轉換?|?制作一款釘釘低價機票提示器!?|60行代碼做了一個語音壁紙切換器天天看小姐姐!|
年度爆款文案
點閱讀原文,看B站我的視頻!

評論
圖片
表情