
初學(xué)者怎么入門大語(yǔ)言模型(LLM)?
真的想入門大語(yǔ)言模型,只看這一個(gè)文章應(yīng)該是可以入門的。但是修行下去,還是要靠自己的了!
如果你把大語(yǔ)言模型/LLM 當(dāng)成一門技術(shù)來(lái)看,那就要看一下這門技術(shù)需要什么。
基本要求:
開發(fā)語(yǔ)言:Python, C/C++
開發(fā)框架:Numpy/Pytorch/Tensorflow/Keras/Onnx
數(shù)學(xué)知識(shí):線性代數(shù)、高數(shù)、概率、凸優(yōu)化
這些東西我們假定你都已經(jīng)會(huì)了,或者熟練使用了。
如果不熟,我建議你自己再學(xué)習(xí)一下。尤其是數(shù)學(xué)的幾個(gè)基本公式,是要學(xué)會(huì)的。我列一下吧。
數(shù)學(xué)核心內(nèi)容
「線性代數(shù)」:關(guān)鍵概念包括向量、矩陣、特征值和特征向量。重要的公式涉及矩陣乘法、行列式以及特征值方程Av=λv,其中 A是矩陣,v 是特征向量,λ是特征值。
「高數(shù)」:基本主題是微分和積分,重點(diǎn)是理解極限、導(dǎo)數(shù)和積分的概念。函數(shù) f(x) 在點(diǎn) x的導(dǎo)數(shù)由f′(x)=limh→0 f(x+h)?f(x) 給出,基本微積分定理將微分與積分聯(lián)系起來(lái)。
「概率」:關(guān)鍵點(diǎn)包括概率公理、條件概率、貝葉斯定理、隨機(jī)變量和分布。例如,貝葉斯定理由P(A∣B)=P(B∣A)P(A)/P(B)給出,它幫助在發(fā)生B 的情況下更新 A 的概率。
「凸優(yōu)化」:關(guān)注目標(biāo)函數(shù)為凸函數(shù)的問題。關(guān)鍵概念包括凸集、凸函數(shù)、梯度下降和拉格朗日乘數(shù)。梯度下降更新規(guī)則可以表示為 xn+1 =xn ?α?f(xn ),其中 α是學(xué)習(xí)率。
你可以看到這些相對(duì)經(jīng)常用到的數(shù)學(xué),其實(shí)沒有多難,只要你再看一下記住就好了。
開發(fā)框架
Numpy 主要是掌握各種數(shù)據(jù)的使用方法
Pytorch 與 Tensor、 Keras 就是完成各種網(wǎng)絡(luò)及訓(xùn)練的方法
你至少要能保證下面的代碼里的每一行代碼都能完全理解
import torch
from torch import nn, optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# Define a transformation to normalize the data
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
# Load the Fashion MNIST dataset
train_dataset = datasets.FashionMNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.FashionMNIST(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
# Define the neural network structure
class FashionMNISTNN(nn.Module):
def __init__(self):
super(FashionMNISTNN, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = FashionMNISTNN()
# Define the loss function and optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Function to train the model
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
# Compute prediction and loss
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
# Function for testing the model
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
# Train the model
epochs = 5
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_loader, model, loss_fn, optimizer)
test(test_loader, model, loss_fn)
print("Done!")
print("關(guān)注微信公眾號(hào):佑佑有話說(shuō)")
注意,是每一行代碼,都能完全理解!!!
Transformer基礎(chǔ)
做為 LLM 的基礎(chǔ)模型,你要想入門,那對(duì) Transformer 這個(gè)模型要了如指掌才成!
而 Transformer 的基本圖像就是下面這樣的:
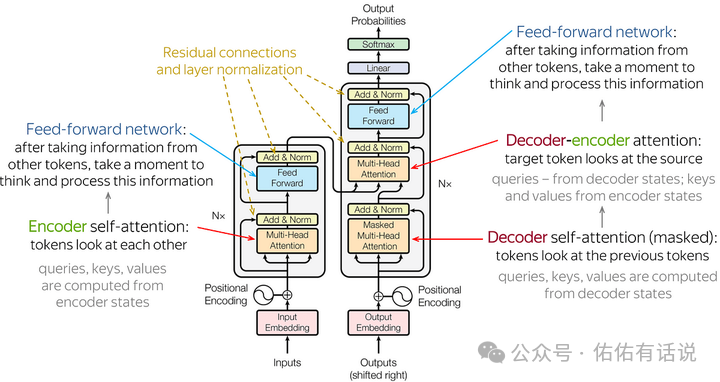
推薦自己手寫一個(gè) Transformer 模型,至少要寫一個(gè) Attention 的結(jié)構(gòu)。還要看懂下面這個(gè)圖。你就能體會(huì)到一個(gè)至簡(jiǎn)的模型是怎么遵循 Scaling Law的,AGI 可能就在這個(gè)簡(jiǎn)單的重復(fù)與變大中了!
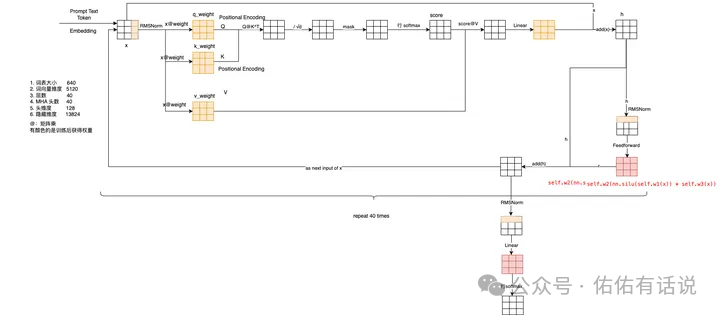
但是Transformer 這么簡(jiǎn)單的東西怎么就這么厲害了呢?整個(gè)大模型已經(jīng)發(fā)展兩三年了,如果你再不跟上,可能很快就淘汰了。
「只要你有想法,你就有結(jié)果!只要你投入,就會(huì)有成就!」
這些是個(gè)基礎(chǔ)了。但是對(duì)于 LLM 來(lái)講吧,如果你想自己繼續(xù)研究,那可能要接觸的就是下面這些東西了。
Prompt 工程
RAG 技術(shù)
Fine-Tune 技術(shù)
LLM Training From Scratch
LLM 部署及優(yōu)化技術(shù)
這幾項(xiàng)基本上是針對(duì)效果及成本的要求從低到高的順序,也是技術(shù)上從簡(jiǎn)單到難的順序列出來(lái)的。
「Prompt 工程」:涉及設(shè)計(jì)和完善給LLM的Prompt,來(lái)得到最準(zhǔn)確或最有用的Response。核心原則是通過(guò)精心設(shè)計(jì)的問題或陳述引導(dǎo)LLM生成所需的輸出。它需要理解LM的能力和限制,并且通常涉及反復(fù)試驗(yàn)以找到最有效的提示。基本技術(shù)就是三件事:
指令角色、精確表達(dá)、要求輸出格式。「RAG 技術(shù)(檢索增強(qiáng)生成)」:RAG 是一種方法,結(jié)合了檢索器模型來(lái)獲取相關(guān)文檔或數(shù)據(jù)和生成器模型來(lái)產(chǎn)生最終輸出。這種技術(shù)通過(guò)外部信息豐富LLM的響應(yīng),提高其準(zhǔn)確性和可靠性,特別是對(duì)于知識(shí)密集型任務(wù)。關(guān)鍵是有效整合檢索和生成過(guò)程,以利用現(xiàn)有知識(shí)和生成能力。
你需要了解的就是 LangChain「Fine-Tune 技術(shù)」:微調(diào)涉及在特定數(shù)據(jù)集或特定任務(wù)上輕微調(diào)整預(yù)訓(xùn)練模型參數(shù)以提高性能。這種方法允許利用大型預(yù)訓(xùn)練模型并將它們適應(yīng)于專門的要求,無(wú)需進(jìn)行大量重新訓(xùn)練。本質(zhì)是保持LM的一般能力,同時(shí)為特定用例進(jìn)行優(yōu)化。
沒啥好說(shuō)的了,自己準(zhǔn)備數(shù)據(jù)針對(duì)特定任務(wù)訓(xùn)練「LLM 從零開始訓(xùn)練」:從頭開始訓(xùn)練大型語(yǔ)言模型(LLM)意味著在不依賴現(xiàn)有預(yù)訓(xùn)練權(quán)重的情況下構(gòu)建模型。這個(gè)過(guò)程涉及收集大量數(shù)據(jù)集、設(shè)計(jì)模型架構(gòu),然后在高性能計(jì)算資源上長(zhǎng)時(shí)間訓(xùn)練模型。核心挑戰(zhàn)是需要大量的計(jì)算能力和數(shù)據(jù),以及有效管理訓(xùn)練過(guò)程的專業(yè)知識(shí)。
如果你沒有在一個(gè)頂級(jí)的公司或者研究團(tuán)隊(duì),想想就好了。「LLM 部署及優(yōu)化技術(shù)」:部署和優(yōu)化LLM涉及有效提供預(yù)測(cè)的策略,同時(shí)有效管理計(jì)算資源。這包括模型量化(減少數(shù)字的精度以節(jié)省內(nèi)存)、模型修剪(移除不那么重要的權(quán)重)和蒸餾(訓(xùn)練一個(gè)較小的模型來(lái)模仿一個(gè)較大的模型)。目標(biāo)是減少模型的大小和推理時(shí)間,而不會(huì)顯著影響其性能,使其適合生產(chǎn)環(huán)境。
入骨相思知不知
玲瓏骰子安紅豆


入我相思門,知我相思苦,長(zhǎng)相思兮長(zhǎng)相憶,短相思兮無(wú)窮極。