
ElasticSearch 如何使用 ik 進(jìn)行中文分詞?
本篇文章則著重分析 ElasticSearch 在全文搜索前如何使用 ik 進(jìn)行分詞,讓大家對(duì) ElasticSearch 的全文搜索和 ik 中文分詞原理有一個(gè)全面且深入的了解。
全文搜索和精確匹配
ElasticSearch 支持對(duì)文本類型數(shù)據(jù)進(jìn)行全文搜索和精確搜索,但是必須提前為其設(shè)置對(duì)應(yīng)的類型:
keyword 類型,存儲(chǔ)時(shí)不會(huì)做分詞處理,支持精確查詢和分詞匹配查詢;
text 類型,存儲(chǔ)時(shí)會(huì)進(jìn)行分詞處理,也支持精確查詢和分詞匹配查詢。
比如,創(chuàng)建名為 article 的索引(Index),并為其兩個(gè)字段(Filed)配置映射(Mapping),文章內(nèi)容設(shè)置為 text 類型,而文章標(biāo)題設(shè)置為 keyword 類型。
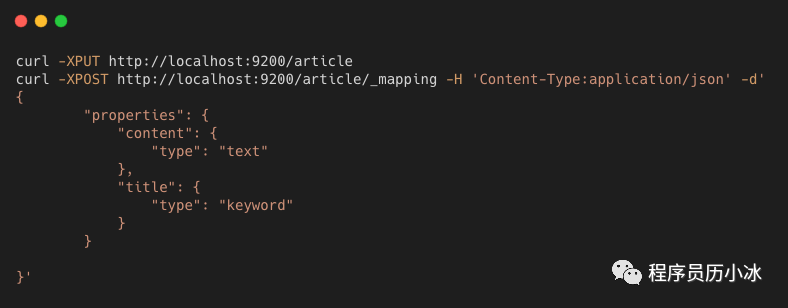
Elasticsearch 在進(jìn)行存儲(chǔ)時(shí),會(huì)對(duì)文章內(nèi)容字段進(jìn)行分詞,獲取并保存分詞后的詞元(tokens);對(duì)文章標(biāo)題則是不進(jìn)行分詞處理,直接保存原值。
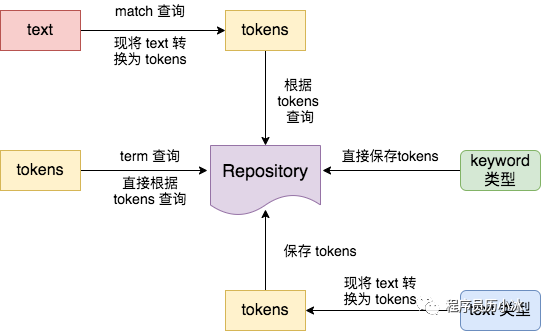
上圖的右半邊展示了 keyword 和 text 兩種類型的不同存儲(chǔ)處理過程。而左半邊則展示了 ElasticSearch 相對(duì)應(yīng)的兩種查詢方式:
term 查詢,也就是精確查詢,不進(jìn)行分詞,而是直接根據(jù)輸入詞進(jìn)行查詢;
match 查詢,也就是分詞匹配查詢,先對(duì)輸入詞進(jìn)行分詞,然后逐個(gè)對(duì)分詞后的詞元進(jìn)行查詢。
舉個(gè)例子,有兩篇文章,一篇的標(biāo)題和內(nèi)容都是“程序員”,另外一篇的標(biāo)題和內(nèi)容都是“程序”,那么二者在 ElasticSearch 中的倒排索引存儲(chǔ)如下所示(假設(shè)使用特殊分詞器)。
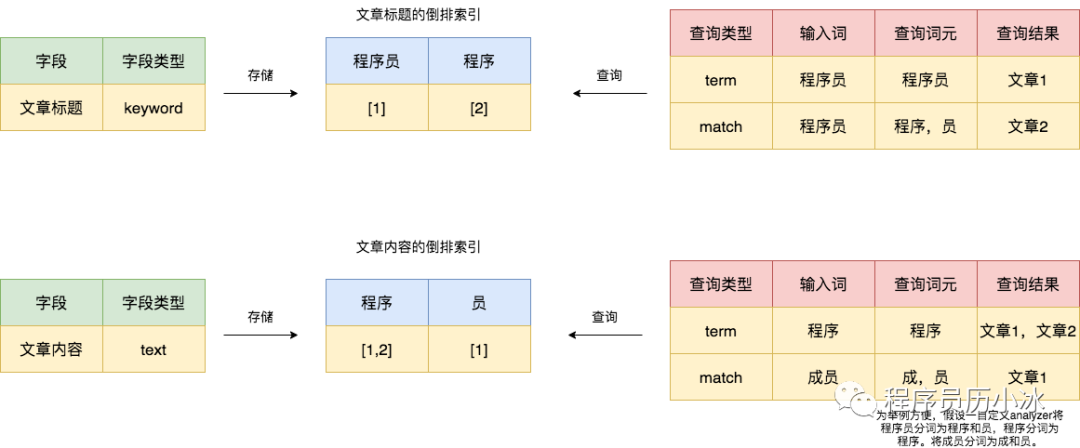
這時(shí),分別使用 term 和 match 查詢對(duì)兩個(gè)字段進(jìn)行查詢,就會(huì)得出如圖右側(cè)的結(jié)果。
Analyzer 處理過程
可見,keyword 與 text 類型, term 與 match 查詢方式之間不同就在于是否進(jìn)行了分詞。在 ElasticSearch 中將這個(gè)分詞的過程統(tǒng)稱了 Text analysis,也就是將字段從非結(jié)構(gòu)化字符串(text)轉(zhuǎn)化為結(jié)構(gòu)化字符串(keyword)的過程。
Text analysis 不僅僅只進(jìn)行分詞操作,而是包含如下流程:
使用字符過濾器(Character filters),對(duì)原始的文本進(jìn)行一些處理,例如去掉空白字符等;
使用分詞器(Tokenizer),對(duì)原始的文本進(jìn)行分詞處理,得到一些詞元(tokens);
使用詞元過濾器(Token filters),對(duì)上一步得到的詞元繼續(xù)進(jìn)行處理,例如改變詞元(小寫化),刪除詞元(刪除量詞)或增加詞元(增加同義詞),合并同義詞等。

ElasticSearch 中處理 Text analysis 的組件被稱為 Analyzer。相應(yīng)地,Analyzer 也由三部分組成,character filters、tokenizers 和 token filters。
Elasticsearch 內(nèi)置了 3 種字符過濾器、10 種分詞器和 31 種詞元過濾器。此外,還可以通過插件機(jī)制獲取第三方實(shí)現(xiàn)的相應(yīng)組件。開發(fā)者可以按照自身需求定制 Analyzer 的組成部分。
"analyzer": {"my_analyzer": {"type": "custom","char_filter": [ "html_strip"],"tokenizer": "standard","filter": [ "lowercase",]}}
按照上述配置,my_analyzer 分析器的功能大致如下:
字符過濾器是
html_strip,會(huì)去掉 HTML 標(biāo)記相關(guān)的字符;分詞器是 ElasticSearch 默認(rèn)的標(biāo)準(zhǔn)分詞器
standard;詞元過濾器是小寫化
lowercase處理器,將英語單詞小寫化。
一般來說,Analyzer 中最為重要的就是分詞器,分詞結(jié)果的好壞會(huì)直接影響到搜索的準(zhǔn)確度和滿意度。ElasticSearch 默認(rèn)的分詞器并不是處理中文分詞的最優(yōu)選擇,目前業(yè)界主要使用 ik 進(jìn)行中文分詞。
ik 分詞原理
ik 是目前較為主流的 ElasticSearch 開源中文分詞組件,它內(nèi)置了基礎(chǔ)的中文詞庫和分詞算法幫忙開發(fā)者快速構(gòu)建中文分詞和搜索功能,它還提供了擴(kuò)展詞庫字典和遠(yuǎn)程字典等功能,方便開發(fā)者擴(kuò)充網(wǎng)絡(luò)新詞或流行語。
ik 提供了三種內(nèi)置詞典,分別是:
main.dic:主詞典,包括日常的通用詞語,比如程序員和編程等;
quantifier.dic:量詞詞典,包括日常的量詞,比如米、公頃和小時(shí)等;
stopword.dic:停用詞,主要指英語的停用詞,比如 a、such、that 等。
此外,開發(fā)者可以通過配置擴(kuò)展詞庫字典和遠(yuǎn)程字典對(duì)上述詞典進(jìn)行擴(kuò)展。

ik 跟隨 ElasticSearch 啟動(dòng)時(shí),會(huì)將默認(rèn)詞典和擴(kuò)展詞典讀取并加載到內(nèi)存,并使用字典樹 tire tree (也叫前綴樹)數(shù)據(jù)結(jié)構(gòu)進(jìn)行存儲(chǔ),方便后續(xù)分詞時(shí)使用。
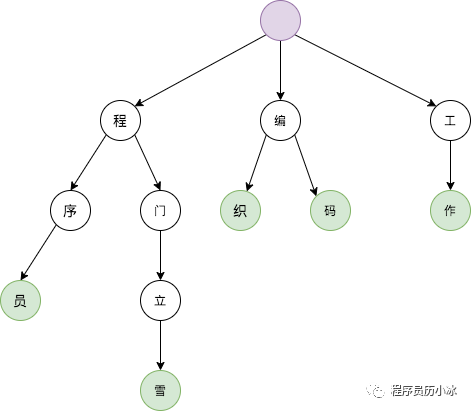
字典樹的典型結(jié)構(gòu)如上圖所示,每個(gè)節(jié)點(diǎn)是一個(gè)字,從根節(jié)點(diǎn)到葉節(jié)點(diǎn),路徑上經(jīng)過的字符連接起來,為該節(jié)點(diǎn)對(duì)應(yīng)的詞。所以上圖中的詞包括:程序員、程門立雪、編織、編碼和工作。
一、加載字典
ik 的 Dictionary 單例對(duì)象會(huì)在初始化時(shí),調(diào)用對(duì)應(yīng)的 load 函數(shù)讀取字典文件,構(gòu)造三個(gè)由 DictSegment 組成的字典樹,分別是 MainDict、QuantifierDict 和 StopWords。我們下面就來看一下其主詞典的加載和構(gòu)造過程。loadMainDict 函數(shù)較為簡單,它會(huì)首先創(chuàng)建一個(gè) DictSegment 對(duì)象作為字典樹的根節(jié)點(diǎn),然后分別去加載默認(rèn)主字典,擴(kuò)展主字典和遠(yuǎn)程主字典來填充字典樹。
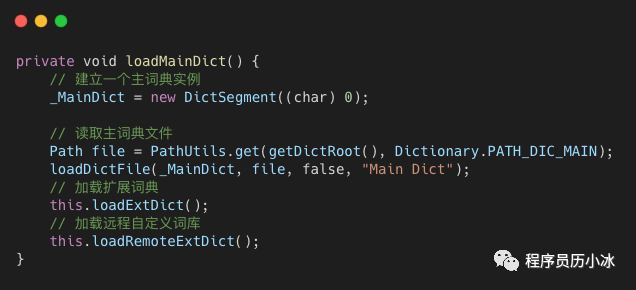
復(fù)制代碼
在 loadDictFile 函數(shù)執(zhí)行過程中,會(huì)從詞典文件讀取一行一行的詞,交給 DictSegment 的fillSegment 函數(shù)處理。
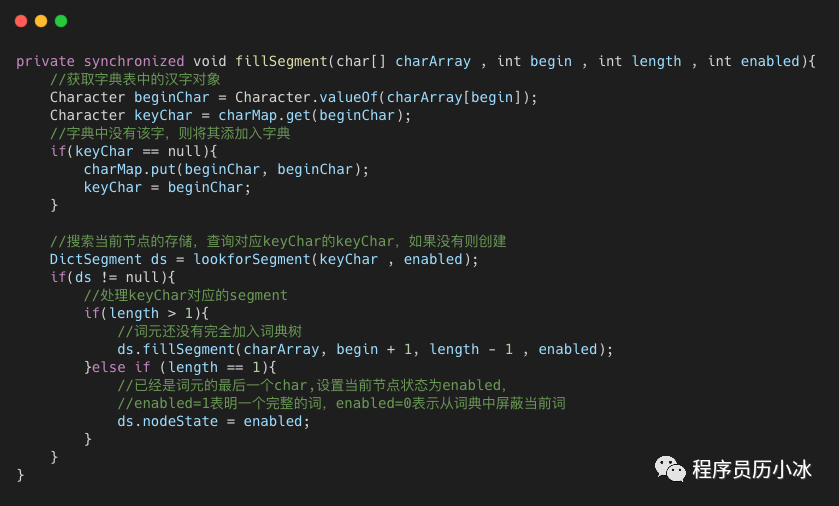
fillSegment 是構(gòu)建字典樹的核心函數(shù),具體實(shí)現(xiàn)如下所示,處理邏輯大致有如下幾個(gè)步驟:
一、按照索引,獲取詞中的一個(gè)字;
二、檢查當(dāng)前節(jié)點(diǎn)的子節(jié)點(diǎn)中是否有該字,如果沒有,則將其加入到
charMap中;三、調(diào)用
lookforSegment函數(shù)在字典樹中尋找代表該字的節(jié)點(diǎn),如果沒有則插入一個(gè)新的;四、遞歸調(diào)用
fillSegment函數(shù)處理下一個(gè)字。
ik 初始化過程大致如此,再進(jìn)一步詳細(xì)的邏輯大家可以直接去看源碼,中間都是中文注釋,相對(duì)來說較為容易閱讀。
二、分詞邏輯
ik 中實(shí)現(xiàn)了 ElasticSearch 相關(guān)的抽象類,來提供自身的分詞邏輯實(shí)現(xiàn):
IKAnalyzer繼承了Analyzer,用來提供中文分詞的分析器;IKTokenizer繼承了Tokenizer,用來提供中文分詞的分詞器,其incrementToken是 ElasticSearch 調(diào)用 ik 進(jìn)行分詞的入口函數(shù)。
incrementToken 函數(shù)會(huì)調(diào)用 IKSegmenter 的 next方法,來獲取分詞結(jié)果,它是 ik 分詞的核心方法。
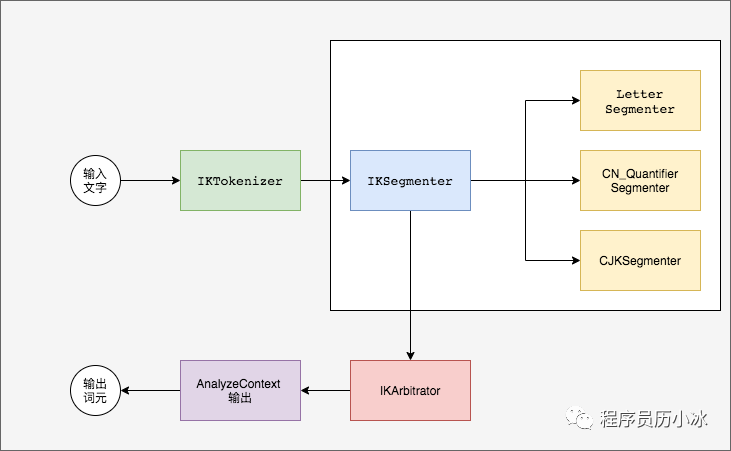
如上圖所示,IKSegmenter 中有三個(gè)分詞器,在進(jìn)行分詞時(shí)會(huì)遍歷詞中的所有字,然后將單字按照順序,讓三個(gè)分詞器進(jìn)行處理:
LetterSegmenter,英文分詞器比較簡單,就是把連續(xù)的英文字符進(jìn)行分詞;CN_QuantifierSegmenter,中文量詞分詞器,判斷當(dāng)前的字符是否是數(shù)詞和量詞,會(huì)把連起來的數(shù)詞和量詞分成一個(gè)詞;CJKSegmenter,核心分詞器,基于前文的字典樹進(jìn)行分詞。
我們只講解一下 CJKSegmenter 的實(shí)現(xiàn),其 analyze 函數(shù)大致分為兩個(gè)邏輯:
根據(jù)單字去字典樹中進(jìn)行查詢,如果單字是詞,則生成詞元;如果是詞前綴,則放入到臨時(shí)命中列表中;
然后根據(jù)單字和之前處理時(shí)保存的臨時(shí)命中列表數(shù)據(jù)一起去字典樹中查詢,如果命中,則生成詞元。
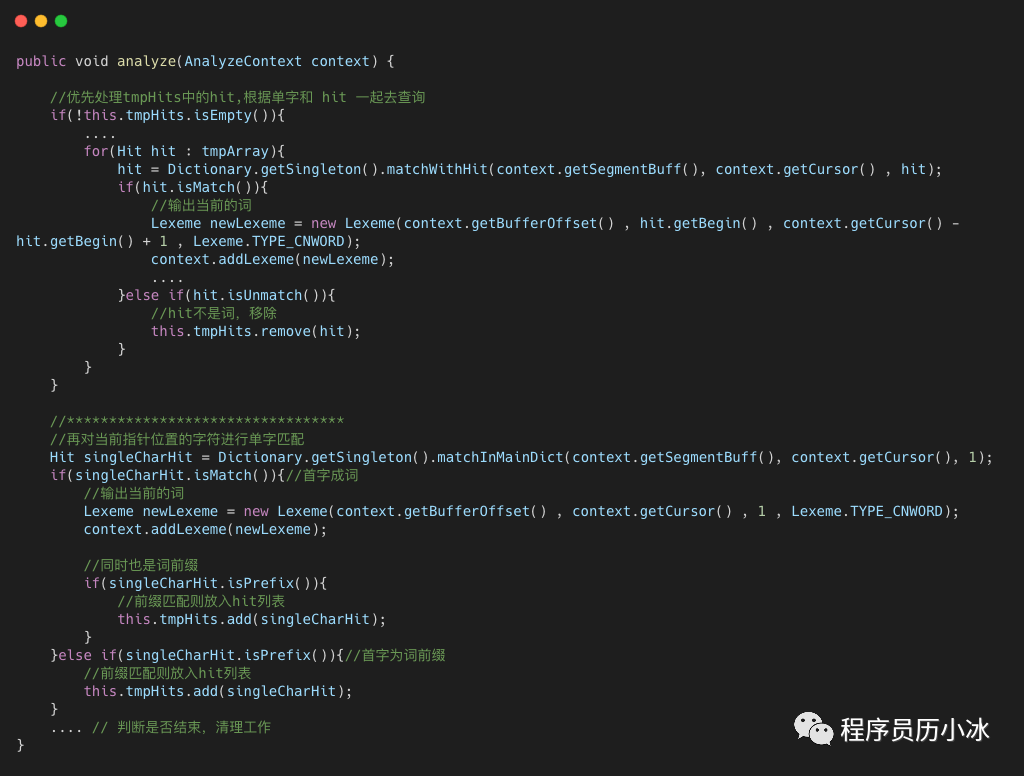
具體的代碼邏輯,如上所示。為了方便大家理解,舉個(gè)例子,比如輸入的詞是 編碼工作:
首先處理
編字;因?yàn)楫?dāng)前
tmpHits為空,直接進(jìn)行單字判斷;直接拿
編字去前文示意圖的字典樹查詢(詳見matchInMainDict函數(shù)),發(fā)現(xiàn)能夠命中,并且該字不是一個(gè)詞的結(jié)尾,所以將編和其在輸入詞中的位置生成Hit對(duì)象,存儲(chǔ)到tmpHits中。接著處理
碼字;因?yàn)?
tmpHits不為空,所以拿著編對(duì)應(yīng)的Hit對(duì)象和碼字去字典樹中查詢(詳見matchWithHit函數(shù)), 發(fā)現(xiàn)命中了編碼一詞,所以將這個(gè)詞作為輸出詞元之一,存入AnalyzeContext;但是因?yàn)?碼已經(jīng)是葉節(jié)點(diǎn),并沒有子節(jié)點(diǎn),表示不是其他詞的前綴,所以將對(duì)應(yīng)的Hit對(duì)象刪除掉;接著拿單字
碼去字典樹中查詢,看單字是否成詞,或者構(gòu)成詞的前綴。依次類推,將所有字處理完。
三、消除歧義和結(jié)果輸出
通過上述步驟,有時(shí)候會(huì)生成很多分詞結(jié)果集合,比如說,程序員愛編程 會(huì)被分成 程序員、程序、員、愛 和 編程 五個(gè)結(jié)果。這也是 ik 的 ik_max_word 模式的輸出結(jié)果。但是有些場景,開發(fā)者希望只有 程序員、愛 和 編程 三個(gè)分詞結(jié)果,這時(shí)就需要使用 ik 的 ik_smart 模式,也就是進(jìn)行消除歧義處理。
ik 使用 IKArbitrator 進(jìn)行消除歧義處理,主要使用組合遍歷的方式進(jìn)行處理。從上一階段的分詞結(jié)果中取出不相交的分詞集合,所謂相交,就是其在文本中出現(xiàn)的位置是否重合。比如 程序員、程序 和 員 三個(gè)分詞結(jié)果是相交的,但是 愛 和 編程 是不相交的。所以分歧處理時(shí)會(huì)將 程序員、程序 和 員 作為一個(gè)集合,愛 作為一個(gè)集合,編碼 作為一個(gè)集合,分別進(jìn)行處理,將集合中按照規(guī)則優(yōu)先級(jí)最高的分詞結(jié)果集選出來,具體規(guī)則如下所示:
有效文本長度長優(yōu)先;
詞元個(gè)數(shù)少優(yōu)先;
路徑跨度大優(yōu)先;
位置越靠后的優(yōu)先,因?yàn)楦鶕?jù)統(tǒng)計(jì)學(xué)結(jié)論,逆向切分概率高于正向切分;
詞長越平均優(yōu)先;
詞元位置權(quán)重大優(yōu)先。
根據(jù)上述規(guī)則,在第一個(gè)集合中,程序員 明顯要比 程序 和 員 要更符合規(guī)則,所以消除歧義的結(jié)果就是輸出 程序員,而不是 程序 和 員。
最后,對(duì)于輸入字來說,有些位置可能并不在輸出結(jié)果中,所以會(huì)以單字的方式作為詞元直接輸出(詳見AnalyzeContext 的 outputToResult 函數(shù))。比如 程序員是職業(yè),是 字是不會(huì)被分詞出來的,但是在最終輸出結(jié)果時(shí),要將其作為單字輸出。
后記
ElasticSearch 和 ik 組合是目前較為主流的中文搜索技術(shù)方案,理解其搜索和分詞的基礎(chǔ)流程和原理,有利于開發(fā)者更快地構(gòu)建中文搜索功能,或基于自身需求,特殊定制搜索分詞策略。