
手撕并發(fā)編程:十分鐘搞定Java內存模型

?? 導讀
隨著硬件技術的飛速發(fā)展,多核處理器已經成為計算設備的標配,這使得開發(fā)人員需要掌握并發(fā)編程的知識和技巧,以充分發(fā)揮多核處理器的潛力。然而并發(fā)編程并非易事,它涉及到許多復雜的概念和原理。為了更好地理解并發(fā)編程的內在機制,需要深入研究內存模型及其在并發(fā)編程中的應用。本文將主要以 Java 內存模型來探討并發(fā)編程中 BUG 的源頭和處理這些問題的底層實現(xiàn)原理,助你更好地把握并發(fā)編程的內在機制, 歡迎繼續(xù)閱讀。?? 目錄
1 并發(fā)編程問題-可見性和有序性 2 并發(fā)編程問題-原子性 3 內存模型與 happens-before 關系 4 內存模型綜述01
并發(fā)編程問題-可見性和有序性
private int a, b;private int x, y;public void test() {Thread t1 = new Thread(() -> {a = 1;x = b;});Thread t2 = new Thread(() -> {b = 2;y = a;});// ...start啟動線程,join等待線程assert x == 2;assert y == 1;}
首先我們先看一段代碼,這里定義了兩個共享變量 x 和 y,在兩個線程中分別對 x 和 y 賦值,當同時開啟兩個線程并等待線程執(zhí)行完成,最終結果是否是共享變量 x 等于2并且 y 等于1呢?答案是未可知,即共享變量 x 和 y 可能存在多種執(zhí)行結果。可以看到在并發(fā)編程中,常常會遇到一些與預期不符的結果,導致程序邏輯的失敗。這樣的異常問題,會讓開發(fā)人員感到困惑。但是如果細細探究這些問題的根源,發(fā)現(xiàn)是有跡可循的。
這個問題的原因主要是兩點:一是處理器和內存對共享變量的處理的速度差異。二是編譯優(yōu)化和處理器優(yōu)化造成代碼指令重排序。前者導致可見性問題,后者導致有序性問題。
1.1 處理器緩存導致的可見性問題
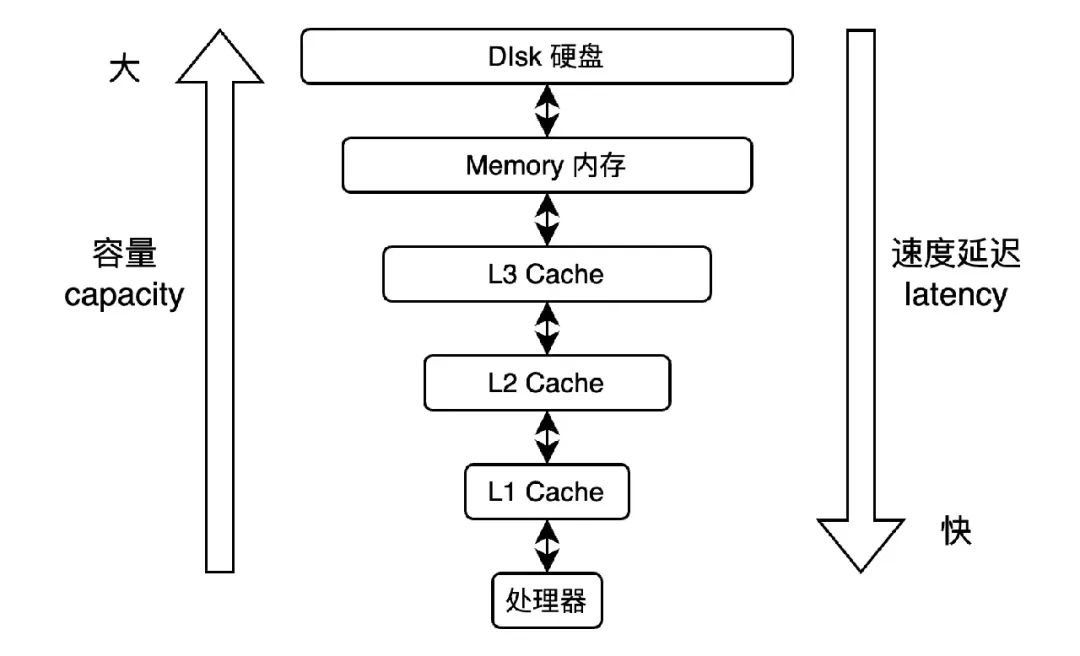
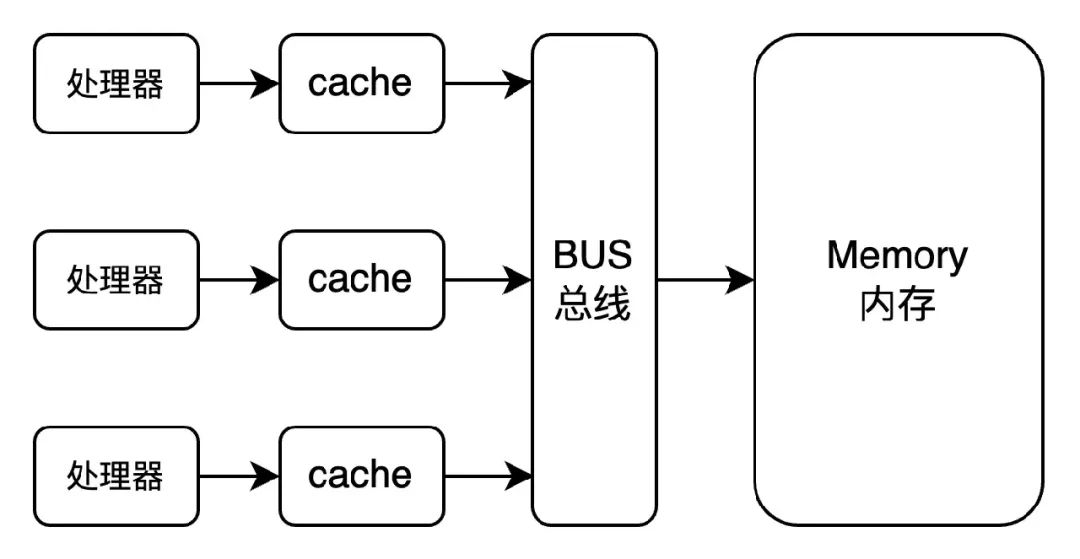
如上圖所示,由于處理器和內存的速度差距太大。為了提高處理速度,處理器不直接和內存進行通信,而是先將系統(tǒng)內存的數(shù)據讀到內部緩存 (L1,L2或其他) 后再進行操作。基于局部性原理,處理器在讀取內存數(shù)據時,是一塊塊地讀取,每一小塊數(shù)據也叫緩存行 (cache line) 。當處理器操作完數(shù)據,也不直接寫回內存,而且先寫入緩存中,并將當前緩存標記為臟 (dirty) 。等到當前緩存被替換時,才將數(shù)據寫回內存。這個過程叫寫回策略 (write-back) 。
同時為了提高效率,處理器使用寫緩存區(qū) (store buffer) 臨時保存向內存寫入的數(shù)據。寫緩沖區(qū)可以保證指令流水線的持續(xù)運行,同時合并寫緩沖區(qū)中對同一內存地址的多次寫,減少內存總線的占用。但是由于緩沖區(qū)的數(shù)據并非及時寫回內存,且寫緩沖區(qū)僅對自己的處理器可見,其他處理器無法感知當前共享變量已經變更。處理器的讀寫順序與內存實際操作的讀寫順序可能存在不一致。
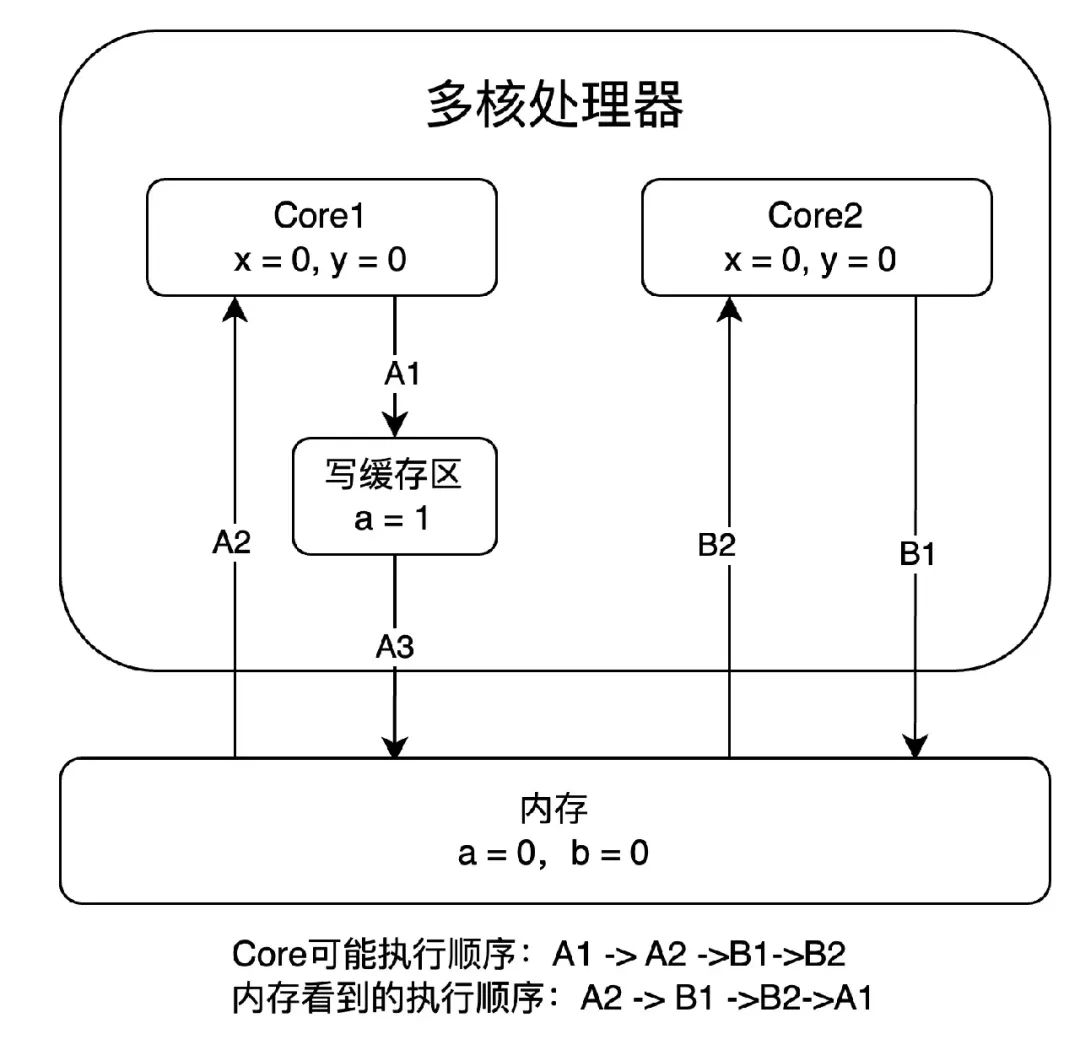
現(xiàn)在再回來看上面代碼,那么可以得到四種結果:
| 結果一: 假設處理器 A 對變量 a 賦值,但沒及時回寫內存。處理器 B 對變量 b 賦值,且及時回寫內存。處理器 A 從內存中讀到變量 b 最新值。那么這時結果是:x 等于2,y 等于0。 結果二: 假設處理器 A 對變量 a 賦值,且及時回寫內存。處理器 B 從內存中讀到變量 a 最新值。處理器 B 對變量 b 賦值,但沒及時回寫內存。那么這時結果是:x 等于0,y 等于1。 結果三: 假設處理器 A 和 B,都沒及時回寫變量 a 和 b 值到內存。那么這時結果是:x 等于0,y 等于0。 結果四: 假設處理器 A 和 B,都及時回寫變量 a 和 b 值到內存,且從內存中讀到變量 a 和 b 的最新值。那么這時結果是:x 等于2,y 等于1。 |
從上面可發(fā)現(xiàn)除了第四種情況,其他三種情況都存在對共享變量的操作不可見。所謂可見性,便是當一個線程對某個共享變量的操作,另外一個線程立即可見這個共享變量的變更。
而從上面推論可以發(fā)現(xiàn),要達到可見性,需要處理器及時回寫共享變量最新值到內存,也需要其他處理器及時從內存中讀取到共享變量最新值。
因此也可以說只要滿足上述兩個條件。那么就可以保證對共享變 量的操作,在并發(fā)情況下是線程安全的。在 Java 語言中,是通過 volatile 關鍵字實現(xiàn)。volatile 關鍵字并不是 Java 語言的特產,古老的 C 語言里也有,它最原始的意義就是禁用 CPU 緩存。
對如下共享變量:
// instance是volatile變量volatile Singlenton instance = new Singlenton();
轉換成匯編代碼,如下:
0x01a3de1d: movb 5 0 x 0, 0 x 1104800(% esi);0x01a3de24: lock addl $ 0 x 0,(% esp);
可以看到 volatile 修飾的共享變量會多出第二行匯編變量,并且多了一個 LOCK 指令。LOCK 前綴的指令在多核處理器會引發(fā)兩件事:
|
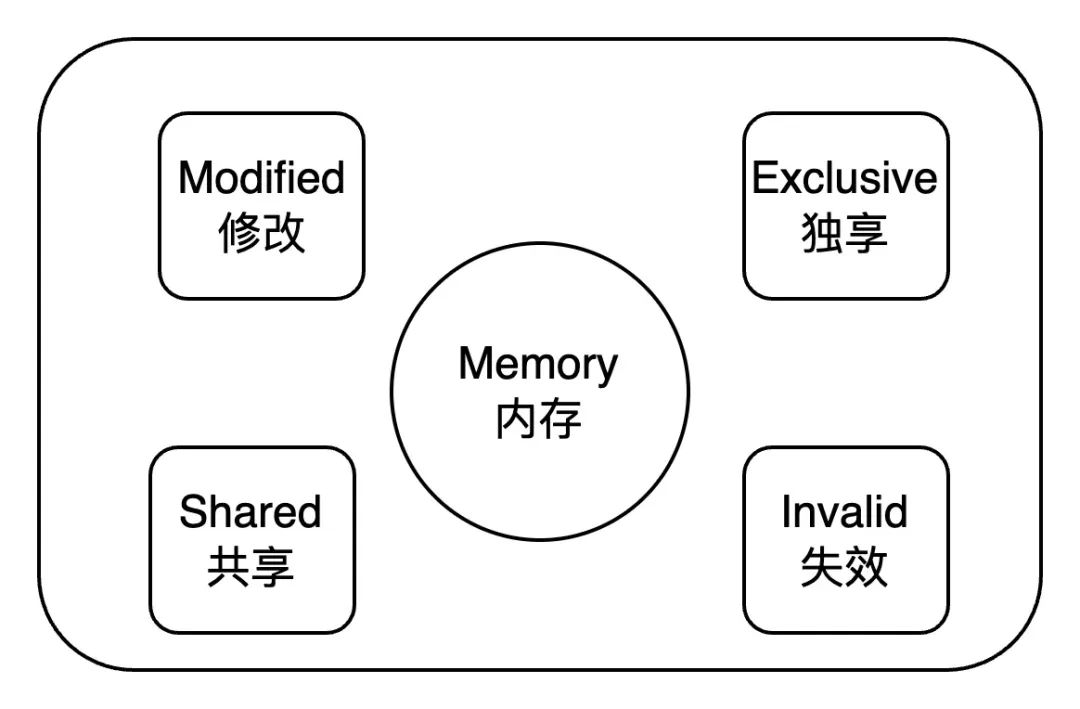
上述的操作是通過總線嗅探和總線仲裁來實現(xiàn)。而基于總線嗅探和總線仲裁,現(xiàn)代處理器逐漸形成了各種緩存一致性協(xié)議,例如 MESI 協(xié)議。
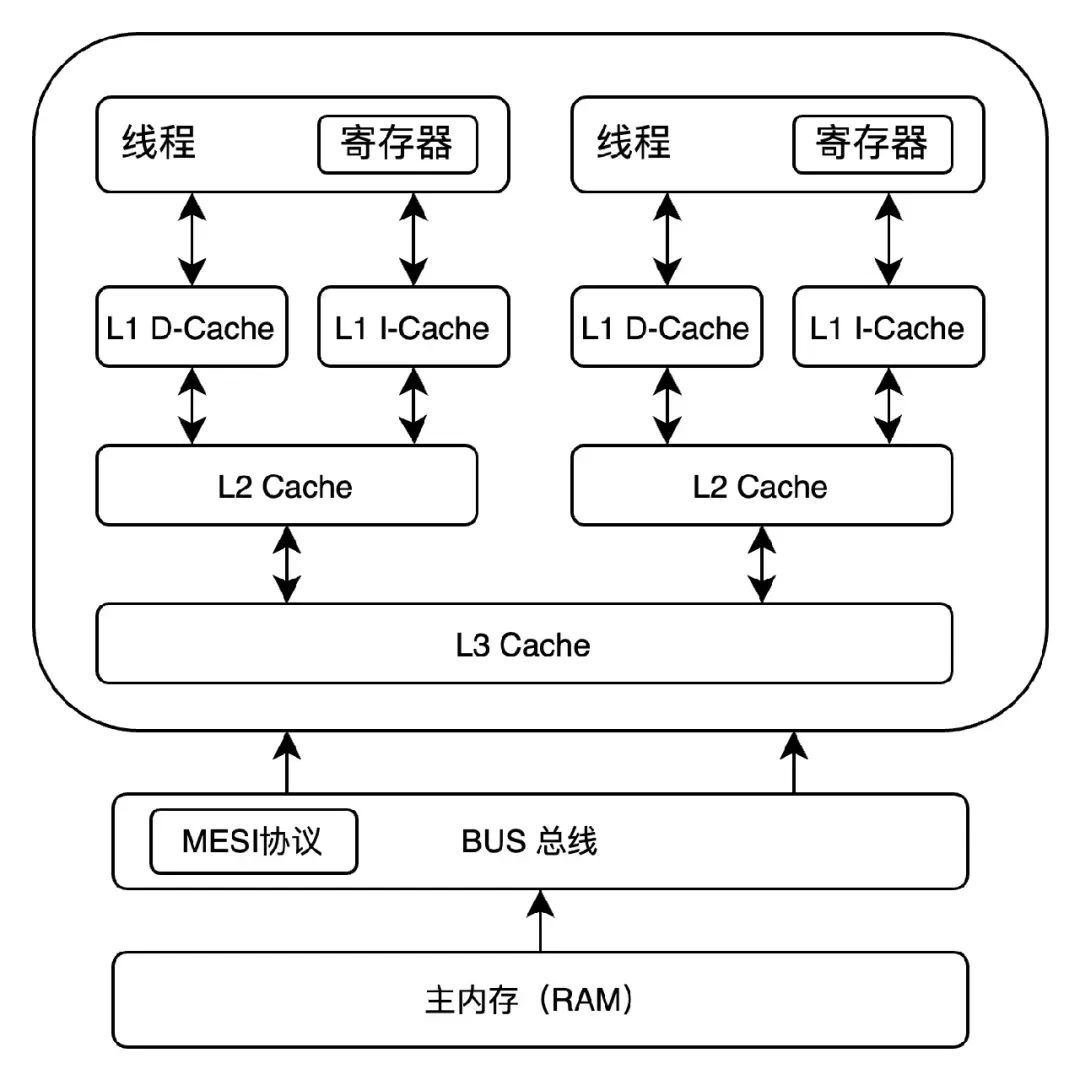
總之操作系統(tǒng)便是基于上述實現(xiàn),從底層來保證共享變量在并發(fā)情況下的線程安全。而對開發(fā)人員,只需要在恰當時候加上 volatile 關鍵字就可以。
除了 volatile,也可以使用 synchronized 關鍵字來保證可見性。關于 volatile 和 synchronized 的具體實現(xiàn),會在下篇文章詳細闡述。
1.2 編譯優(yōu)化導致的有序性問題
前面講到通過緩存一致性協(xié)議,來保障共享變量的可見性。那么是否還有其他情況,導致對共享變量操作不符合預期結果。可以看下面的代碼:
private int a, b;private int x, y;
public void test() {Thread t1 = new Thread(() -> {x = b;a = 1;});
Thread t2 = new Thread(() -> {y = a;b = 2;});// ...start啟動線程,join等待線程assert x == 2;assert y == 1;}
假設將線程 t1 的代碼塊從 a = 1;x = b;改成 x = b;a = 1; 。將線程 t2 的代碼塊從b = 2;y = a;改成 y = a;b = 2;。
對于線程 t1 和 t2 自己來說,代碼的重排序,不會影響當前線程執(zhí)行。但是在多線程并發(fā)執(zhí)行下,會出現(xiàn)如下情況: 假設處理器 A 先將變量 b=0 賦值給 x,再將變量 a 賦值1。 處理器 B 先將變量 a=0 賦值給 y,再將變量 b 賦值2。 那么這時結果是: x 等于0,y 等于0。
可見代碼的重排序也會影響到程序最終結果。
代碼和指令的重排序的主要原因有三個,分別為編譯器的重排序,處理器的亂序執(zhí)行,以及內存系統(tǒng)的重排序。后面兩點是處理器優(yōu)化。

重排序是指編譯器和處理器為了優(yōu)化程序性能而對指令序列進行重新排序的一種手段。重排序需要遵守兩點:
數(shù)據依賴性: 如果兩個操作之間存在數(shù)據依賴,那么編譯器和處理器不能調整它們的順序。
// 寫后讀a = 1;b = a;// 寫后寫a = 1;a = 2;// 讀后寫a = b;b = 1;
上面3種情況,編譯器和處理器不能調整它們的順序,否則將會造成程序語義的改變。
as-if-serial 語義: 即給程序一個順序執(zhí)行的假象。即經過重排序的執(zhí)行結果要與順序執(zhí)行的結果保持一致。
a = 1;b = 2;c = a * b;
如上對變量 a 的賦值和對變量 b 的賦值,不存在數(shù)據依賴關系。因此對變量 a 和 b 重排序不會影響變量 c 的結果。
但數(shù)據依賴性和 as-if-serial 語義只保證單個處理器中執(zhí)行的指令序列和單個線程中執(zhí)行的操作,并不考慮多處理器和多線程之間的數(shù)據依賴情況。因此在多線程程序中,對存在數(shù)據依賴的操作重排序,可能會改變程序的執(zhí)行結果。因此要避免程序的錯誤的執(zhí)行,便是需要禁止這種編譯和處理器優(yōu)化導致的重排序。
這種方式叫做內存屏障 (memory barriers) 。內存屏障是一組處理器指令,用戶實現(xiàn)對內存操作的順序限制。以我們日常接觸的 X86_64 架構來說,讀讀 (loadload) 、讀寫 (loadstore) 以及寫寫 (storestore) 內存屏障是空操作 (no-op) ,只有寫讀 (storeload) 內存屏障會被替換成具體指令。
在 Java 語言中,內存屏障通過 volatile 關鍵字實現(xiàn),禁止被它修飾的變量發(fā)生指令重排序操作:
|
// 變量a,b通過volatile修飾private volatile int a, b;private int x, y;
public void test() {Thread t1 = new Thread(() -> {a = 1;// 編譯器插入storeload內存屏障指令// 1)禁止代碼和指令重排序// 2)強制刷新變量a的最新值到內存x = b;// 1)強制從內存中讀取變量b的最新值});
Thread t2 = new Thread(() -> {b = 2;// 編譯器插入storeload內存屏障指令// 1)禁止代碼和指令重排序// 2)強制刷新變量b的最新值到內存y = a;// 1)強制從內存中讀取變量a的最新值});// ...start啟動線程,join等待線程assert x == 2;assert y == 1;}
可以看到通過 volatile 修飾的變量通過 LOCK 指令和內存屏障,實現(xiàn)共享變量的可見性和避免代碼和指令的重排序,最終保障了程序在多線程情況下的正常執(zhí)行。
02
并發(fā)編程問題-原子性
private int count = 0;public void test() {List<Thread> ts = new ArrayList<>();for (int i = 0; i < 100; i++) {Thread t = new Thread(() -> {for (int j = 0; j < 10000; j++) {count += 1;}});ts.add(t);}// ...start啟動線程,join等待線程assert count == 100 * 10000;}
對于 Java 這樣的高級語言,一條語句最終會被轉換成多條 CPU 指令完成,例如上面代碼中的 count+=1,至少需要三條 CPU 指令:
| 指令1: 把變量 count 從內存加載到 CPU 的寄存器; 指令2: 在寄存器中執(zhí)行+1操作; 指令3: 將結果寫入內存(緩存機制導致可能寫入的是處理器緩存而不是內存)。 |
那么假設有兩個線程 A 和 B,同時執(zhí)行 count+=1,可能存在如下情況:
|
可以看到如果要 count 結果正確,要保證 count 讀取,操作,寫入三個過程不被中斷。這個過程,可以稱之為原子操作。原子 (atomic) 本意是“不能被進一步分割的最小粒子”,而原子操作 ( atomicoperation) 意為“不可被中斷的一個或一系列操作”。
處理器主要使用基于對緩存加鎖或總線加鎖的方式來實現(xiàn)原子操作:
總線加鎖: 通過 LOCK#信號鎖住總線 BUS,使當前處理器獨享內存空間。但是此時其他處理器都不能訪問內存其他地址,效率低。
緩存加鎖: 緩存一致性協(xié)議 (MESI) 。強制當前處理器緩存行失效,并從內存讀取其他處理器回寫的數(shù)據。當有些無法被緩存或跨域多個緩存行的數(shù)據,依然需要使用總線鎖。
對于以上兩個機制,處理器底層提供了很多指令來實現(xiàn),其中最重要的是 CMPXCHG 指令。但 CMPXCHG 只在單核處理器下有效,多核處理器依然要加上 LOCK 前綴 (LOCK CMPXCHG) 。利用 CMPXCHG 指令可以通過循環(huán) CAS 方式來實現(xiàn)原子操作。
判斷當前機器是否是多核處理器int mp = os::is MP();_asm {mov edx, destmov ecx, exchange valuemov eax, compare_value這里需要先進行判斷是否為多核處理器LOCK IF MP(mp)如果是多核處理器就會在這行指令前加Lock標記cmpxchg dword ptr [edx],ecx}
CAS 即 Compare and Swap。CAS 操作需要輸入兩個數(shù)值,一個舊值 (期望操作前的值) 和一個新值,在操作期間先比較舊值有沒有發(fā)生變化,如果沒有發(fā)生變化,才交換成新值,發(fā)生了變化則不交換。
Java 語言提供了大量的原子操作類,來實現(xiàn)對應的 CAS 操作。比如 AtomicBoolean,AtomicInteger,AtomicLong 等。
private AtomicInteger count = new AtomicInteger(0);public void test() {List<Thread> ts = new ArrayList<>();for (int i = 0; i < 100; i++) {Thread t = new Thread(() -> {for (int j = 0; j < 10000; j++) {count.incrementAndGet();}});ts.add(t);}// ...start啟動線程,join等待線程assert count.get() == 100 * 10000;}
CAS 雖然很高效地解決了原子操作,但是 CAS 也存在一些問題,比如 ABA 問題,循環(huán)時間長開銷大,只能保障一個共享變量的原子操作。關于如上問題解決和 Atomic 包介紹,會在下篇文章詳細闡述。
03
內存模型與 happens-before 關系
前面說到處理器提供了一些特殊指令比如 LOCK,CMPXCHG,內存屏障等來保障多線程情況下的程序邏輯正常執(zhí)行。但這依然存在幾個問題:
|
因此高級語言會提供一種抽象的內存模型,用于描述多線程環(huán)境下的內存訪問行為。 無需關心底層硬件和操作系統(tǒng)的具體實現(xiàn)細節(jié),就可以編寫出高效、可移植的并發(fā)程序。對于 Java 語言,這種內存模型便是 Java 內存模型 (Java Memory Model,簡稱 JMM) 。
Java 內存模型主要特性是提供了 volatile、synchronized、final 等同步原語,用于實現(xiàn)原子性、可見性和有序性。另一個重要的概念便是 happens-before 關系,用來描述并發(fā)編程中操作之間的偏序關系。除了 Java 語言,包括 golang,c++,rust 等高級語言也實現(xiàn)了自己的 happens-before 關系。
Java 內存模型的 happens-before 關系是用來描述兩個線程操作的內存可見性。需注意這里的可見性,并不代表 A 線程的執(zhí)行順序一定早于 B 線程, 而是 A 線程對某個共享變量的操作對 B 線程可見。即A線程對變量 a 進行寫操作,B 線程讀取到是變量 a 的變更值。
Java內存模型定義了主內存 (main memory) ,本地內存 (local memory) ,共享變量等抽象關系,來決定共享變量在多線程之間通信同步方式,即前面所說兩個線程操作的內存可見性。其中本地內存,涵蓋了緩存,寫緩沖區(qū),寄存器以及其他硬件和編譯器優(yōu)化等概念。
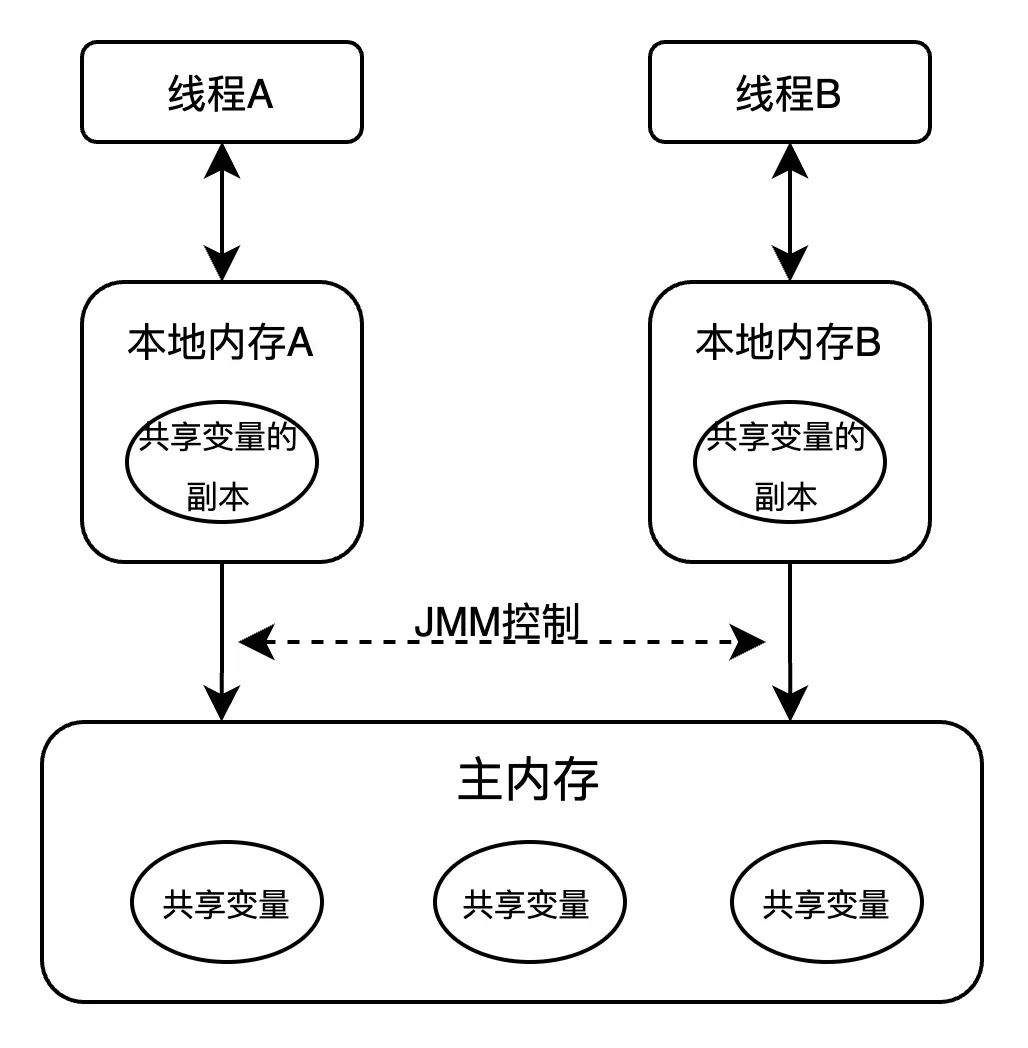
如圖所示,如果線程 A 與線程 B 之間要通信的話,必須要經歷下面2個步驟:
|
盡管定義這樣的數(shù)據通信方式,但實際程序的數(shù)據依賴操作是復雜多變的。為了進一步抽象這種線程間的數(shù)據同步方式,Java 內存模型定義了下述線程間的 happens-before 關系:
| 程序順序規(guī)則: 單線程內,每個操作 happens-before 于該線程中的任意后續(xù)操作。 監(jiān)視器鎖規(guī)則: 解鎖操作 happens-before 之后對同一把鎖的加鎖操作。 volatile 變量規(guī)則: volatile 字段的寫操作 happens-before 之后對同一字段的讀操作。 傳遞性規(guī)則: 如果 A happens-before B,且 B happens-before C,那么 A happens-before C。 start()規(guī)則: 如果線程 A 執(zhí)行操作 ThreadB.start(),那么 A 線程的 ThreadB.start()操作 happens-before 于線程 B 中的任意操作。 join()規(guī)則:如果線程 A 執(zhí)行操作 ThreadB.join()并成功返回,那么線程 B 中的任意操作 happens-before 線程 A 從 ThreadB.join()操作成功返回。 |
與開發(fā)人員密切相關的是1、2、3、4四個規(guī)則。其中規(guī)則1滿足了 as-if-serial 語義,即 Java 內存模型允許代碼和指令重排序,只要不影響程序執(zhí)行結果。規(guī)則2和3是通過 synchronized、volatile 關鍵字實現(xiàn)。結合規(guī)則1、2、3來看看規(guī)則4的具體使用,可以看到如下的代碼,程序最終執(zhí)行且得到正確結果:
// x, y, z被volatile關鍵字修飾private volatile int x, y, z;public void test() {Thread a = new Thread(() -> {// 基于程序順序規(guī)則// 沒有數(shù)據依賴關系,可以重排序下面代碼int i = 0;x = 2;// 基于volatile變量規(guī)則// 編譯器插入storeload內存屏障指令// 1)禁止代碼和指令重排序// 2)強制刷新變量x的最新值到內存});Thread b = new Thread(() -> {int i = 0;// 存在數(shù)據依賴關系,無法重排序下面代碼// 強制從主內存中讀取變量x的最新值y = x;// 基于volatile變量規(guī)則// 編譯器插入storeload內存屏障指令// 1)禁止代碼和指令重排序// 2)強制刷新變量y的最新值到內存// 3)y = x;可能會被編譯優(yōu)化去除y = 3;// 編譯器插入storeload內存屏障指令// 1)禁止代碼和指令重排序// 2)強制刷新變量y的最新值到內存});Thread c = new Thread(() -> {// 基于程序順序規(guī)則// 沒有數(shù)據依賴關系,可以重排序下面代碼int i = 0;// 基于volatile變量規(guī)則// 強制從主內存中讀取變量x和y的最新值z = x * y;// 編譯器插入storeload內存屏障指令// 1)禁止代碼和指令重排序// 2)強制刷新變量z的最新值到內存});// ...start啟動線程,join等待線程assert z == 6;// 可以看到a線程對變量x變更,b線程對變量y變更,最終對線程c可見// 即滿足傳遞性規(guī)則}
private int x, y, z;
public void test() {Thread a = new Thread(() -> {// synchronized,同步原語,程序邏輯將順序串行執(zhí)行synchronized (this){// 基于程序順序規(guī)則// 沒有數(shù)據依賴關系,可以重排序下面代碼int i = 0;x = 2;// 基于監(jiān)視器鎖規(guī)則// 強制刷新變量x的最新值到內存}});Thread b = new Thread(() -> {// synchronized,同步原語,程序邏輯將順序串行執(zhí)行synchronized (this) {int i = 0;// 存在數(shù)據依賴關系,無法重排序下面代碼// 強制從主內存中讀取變量x的最新值y = x;// 基于監(jiān)視器鎖規(guī)則// 1)強制刷新變量y的最新值到內存// 2)y = x;可能會被編譯優(yōu)化去除y = 3;// 強制刷新變量y的最新值到內存}});Thread c = new Thread(() -> {// synchronized,同步原語,程序邏輯將順序串行執(zhí)行synchronized (this) {// 基于程序順序規(guī)則// 沒有數(shù)據依賴關系,可以重排序下面代碼int i = 0;// 基于監(jiān)視器鎖規(guī)則// 強制從主內存中讀取變量x和y的最新值z = x * y;// 強制刷新變量z的最新值到內存}});// ...start啟動線程,join等待線程assert z == 6;// 可以看到a線程對變量x變更,b線程對變量y變更,最終對線程c可見// 即滿足傳遞性規(guī)則}
04
內存模型綜述
在本文中,我們對 Java 內存模型進行了全面的概述。Java 內存模型是 Java 虛擬機規(guī)范的一部分,為 Java 開發(fā)人員提供了一種抽象的內存模型,用于描述多線程環(huán)境下的內存訪問行為。
Java 內存模型關注并發(fā)編程中的原子性、可見性和有序性問題,并提供了一系列同步原語 (如 volatile、synchronized 等) 來實現(xiàn)這些原則。此外,還定義 happens-before 關系,用于描述操作之間的偏序關系,從而確保內存訪問的正確性和一致性。
Java 內存模型的主要優(yōu)勢在于它為并發(fā)編程提供了基礎,簡化了復雜性。屏蔽不同處理器差異性,在不同的處理器平臺之上呈現(xiàn)了一致的內存模型,并允許一定程度的性能優(yōu)化。這些優(yōu)勢使得 Java 開發(fā)人員可以更容易地編寫出正確、高效、可移植的并發(fā)程序。






第一時間看鵝廠技術