
PyTorch下的可視化工具(網(wǎng)絡(luò)結(jié)構(gòu)/訓(xùn)練過程可視化)
點擊上方“視學(xué)算法”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達
導(dǎo)讀
?本文大致想說一下pytorch下的網(wǎng)絡(luò)結(jié)構(gòu)可視化和訓(xùn)練過程可視化。
一、網(wǎng)絡(luò)結(jié)構(gòu)的可視化
我們訓(xùn)練神經(jīng)網(wǎng)絡(luò)時,除了隨著step或者epoch觀察損失函數(shù)的走勢,從而建立對目前網(wǎng)絡(luò)優(yōu)化的基本認知外,也可以通過一些額外的可視化庫來可視化我們的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)圖。這將更加地高效地向讀者展現(xiàn)目前的網(wǎng)絡(luò)結(jié)構(gòu)。
為了可視化神經(jīng)網(wǎng)絡(luò),我們先建立一個簡單的卷積層神經(jīng)網(wǎng)絡(luò):
?import?torch
?import?torch.nn?as?nn
?
?class?ConvNet(nn.Module):
?????def?__init__(self):
?????????super(ConvNet,?self).__init__()
?
?????????self.conv1?=?nn.Sequential(
?????????????nn.Conv2d(1,?16,?3,?1,?1),
?????????????nn.ReLU(),
?????????????nn.AvgPool2d(2,?2)
?????????)
?
?????????self.conv2?=?nn.Sequential(
?????????????nn.Conv2d(16,?32,?3,?1,?1),
?????????????nn.ReLU(),
?????????????nn.MaxPool2d(2,?2)
?????????)
?
?????????self.fc?=?nn.Sequential(
?????????????nn.Linear(32?*?7?*?7,?128),
?????????????nn.ReLU(),
?????????????nn.Linear(128,?64),
?????????????nn.ReLU()
?????????)
?
?????????self.out?=?nn.Linear(64,?10)
?
?????def?forward(self,?x):
?????????x?=?self.conv1(x)
?????????x?=?self.conv2(x)
?????????x?=?x.view(x.size(0),?-1)
?????????x?=?self.fc(x)
?????????output?=?self.out(x)
?????????return?output
輸出網(wǎng)絡(luò)結(jié)構(gòu):
?MyConvNet?=?ConvNet()
?print(MyConvNet)
輸出結(jié)果:
?ConvNet(
???(conv1):?Sequential(
?????(0):?Conv2d(1,?16,?kernel_size=(3,?3),?stride=(1,?1),?padding=(1,?1))
?????(1):?ReLU()
?????(2):?AvgPool2d(kernel_size=2,?stride=2,?padding=0)
???)
???(conv2):?Sequential(
?????(0):?Conv2d(16,?32,?kernel_size=(3,?3),?stride=(1,?1),?padding=(1,?1))
?????(1):?ReLU()
?????(2):?MaxPool2d(kernel_size=2,?stride=2,?padding=0,?dilation=1,?ceil_mode=False)
???)
???(fc):?Sequential(
?????(0):?Linear(in_features=1568,?out_features=128,?bias=True)
?????(1):?ReLU()
?????(2):?Linear(in_features=128,?out_features=64,?bias=True)
?????(3):?ReLU()
???)
???(out):?Linear(in_features=64,?out_features=10,?bias=True)
?)
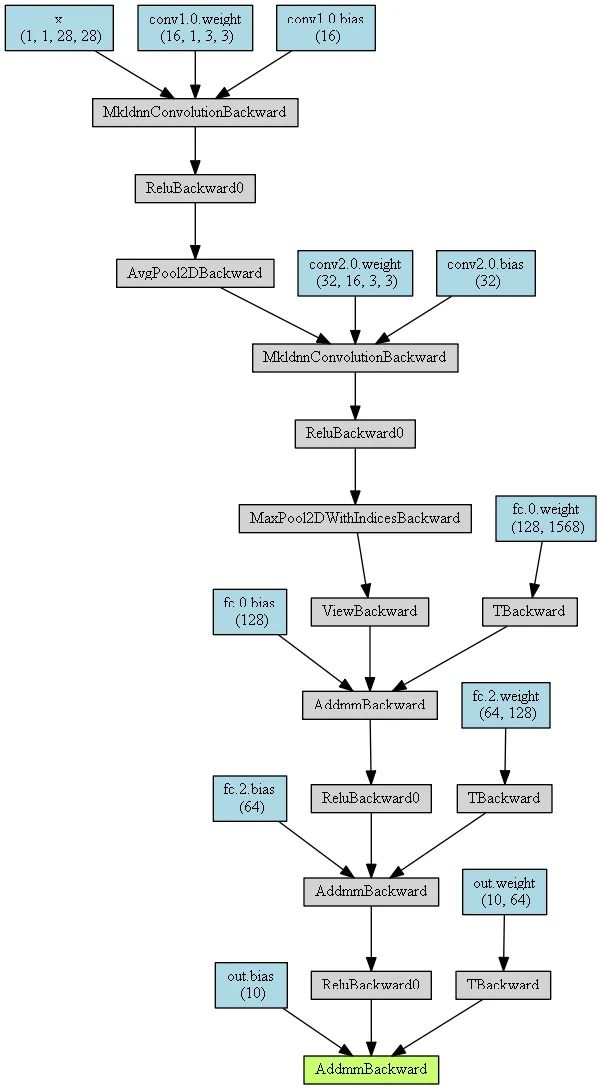
有了基本的神經(jīng)網(wǎng)絡(luò)后,我們分別通過HiddenLayer和PyTorchViz庫來可視化上述的卷積層神經(jīng)網(wǎng)絡(luò)。
需要說明的是,這兩個庫都是基于Graphviz開發(fā)的,因此倘若你的電腦上沒有安裝并且沒有添加環(huán)境變量,請自行安裝Graphviz工具,安裝教程
1.1 通過HiddenLayer可視化網(wǎng)絡(luò)
首先當然是安裝庫啦,打開cmd,輸入:
?pip?install?hiddenlayer
繪制的基本程序如下:
?import?hiddenlayer?as?h
?vis_graph?=?h.build_graph(MyConvNet,?torch.zeros([1?,1,?28,?28]))???#?獲取繪制圖像的對象
?vis_graph.theme?=?h.graph.THEMES["blue"].copy()?????#?指定主題顏色
?vis_graph.save("./demo1.png")???#?保存圖像的路徑
效果如下:

1.2 通過PyTorchViz可視化網(wǎng)絡(luò)
先安裝庫:
?pip?install?torchviz
這里我們只使用可視化函數(shù)make_dot()來獲取繪圖對象,基本使用和HiddenLayer差不多,不同的地方在于PyTorch繪圖之前可以指定一個網(wǎng)絡(luò)的輸入值和預(yù)測值。
?from?torchviz?import?make_dot
?x?=?torch.randn(1,?1,?28,?28).requires_grad_(True)??#?定義一個網(wǎng)絡(luò)的輸入值
?y?=?MyConvNet(x)????#?獲取網(wǎng)絡(luò)的預(yù)測值
?
?MyConvNetVis?=?make_dot(y,?params=dict(list(MyConvNet.named_parameters())?+?[('x',?x)]))
?MyConvNetVis.format?=?"png"
?#?指定文件生成的文件夾
?MyConvNetVis.directory?=?"data"
?#?生成文件
?MyConvNetVis.view()
打開與上述代碼相同根目錄下的data文件夾,里面會有一個.gv文件和一個.png文件,其中的.gv文件是Graphviz工具生成圖片的腳本代碼,.png是.gv文件編譯生成的圖片,直接打開.png文件就行。
默認情況下,上述程序運行后會自動打開.png文件
生成圖片:
二、訓(xùn)練過程可視化
觀察我們的網(wǎng)絡(luò)的每一步的損失函數(shù)或準確率的變化可以有效地幫助我們判斷當前訓(xùn)練過程的優(yōu)劣。如果能將這些過程可視化,那么我們判斷的準確性和舒適性都會有所增加。
此處主要講通過可視化神器tensorboardX和剛剛用到的HiddenLayer來實現(xiàn)訓(xùn)練過程的可視化。
為了訓(xùn)練網(wǎng)絡(luò),我們先導(dǎo)入訓(xùn)練網(wǎng)絡(luò)需要的數(shù)據(jù),此處就導(dǎo)入MNIST數(shù)據(jù)集,并做訓(xùn)練前的一些基本的數(shù)據(jù)處理。
?import?torchvision
?import?torch.utils.data?as?Data
?#?準備訓(xùn)練用的MNIST數(shù)據(jù)集
?train_data?=?torchvision.datasets.MNIST(
?????root?=?"./data/MNIST",??#?提取數(shù)據(jù)的路徑
?????train=True,?#?使用MNIST內(nèi)的訓(xùn)練數(shù)據(jù)
?????transform=torchvision.transforms.ToTensor(),????#?轉(zhuǎn)換成torch.tensor
?????download=False???#?如果是第一次運行的話,置為True,表示下載數(shù)據(jù)集到root目錄
?)
?
?#?定義loader
?train_loader?=?Data.DataLoader(
?????dataset=train_data,
?????batch_size=128,
?????shuffle=True,
?????num_workers=0
?)
?
?test_data?=?torchvision.datasets.MNIST(
?????root="./data/MNIST",
?????train=False,????#?使用測試數(shù)據(jù)
?????download=False
?)
?
?#?將測試數(shù)據(jù)壓縮到0-1
?test_data_x?=?test_data.data.type(torch.FloatTensor)?/?255.0
?test_data_x?=?torch.unsqueeze(test_data_x,?dim=1)
?test_data_y?=?test_data.targets
?
?#?打印一下測試數(shù)據(jù)和訓(xùn)練數(shù)據(jù)的shape
?print("test_data_x.shape:",?test_data_x.shape)
?print("test_data_y.shape:",?test_data_y.shape)
?
?for?x,?y?in?train_loader:
?????print(x.shape)
?????print(y.shape)
?????break
結(jié)果:
?test_data_x.shape:?torch.Size([10000,?1,?28,?28])
?test_data_y.shape:?torch.Size([10000])
?torch.Size([128,?1,?28,?28])
?torch.Size([128])
2.1 通過tensorboardX可視化訓(xùn)練過程
tensorboard是谷歌開發(fā)的深度學(xué)習(xí)框架tensorflow的一套深度學(xué)習(xí)可視化神器,在pytorch團隊的努力下,他們開發(fā)出了tensorboardX來讓pytorch的玩家也能享受tensorboard的福利。
先安裝相關(guān)的庫:
?pip?install?tensorboardX
?pip?install?tensorboard
并將tensorboard.exe所在的文件夾路徑加入環(huán)境變量path中(比如我的tensorboard.exe的路徑為D:\Python376\Scripts\tensorboard.exe,那么就在path中加入D:\Python376\Scripts)
下面是tensorboardX的使用過程。基本使用為,先通過tensorboardX下的SummaryWriter類獲取一個日志編寫器對象。然后通過這個對象的一組方法往日志中添加事件,即生成相應(yīng)的圖片,最后啟動前端服務(wù)器,在localhost中就可以看到最終的結(jié)果了。
訓(xùn)練網(wǎng)絡(luò),并可視化網(wǎng)絡(luò)訓(xùn)練過程的代碼如下:
?from?tensorboardX?import?SummaryWriter
?logger?=?SummaryWriter(log_dir="data/log")
?
?#?獲取優(yōu)化器和損失函數(shù)
?optimizer?=?torch.optim.Adam(MyConvNet.parameters(),?lr=3e-4)
?loss_func?=?nn.CrossEntropyLoss()
?log_step_interval?=?100??????#?記錄的步數(shù)間隔
?
?for?epoch?in?range(5):
?????print("epoch:",?epoch)
?????#?每一輪都遍歷一遍數(shù)據(jù)加載器
?????for?step,?(x,?y)?in?enumerate(train_loader):
?????????#?前向計算->計算損失函數(shù)->(從損失函數(shù))反向傳播->更新網(wǎng)絡(luò)
?????????predict?=?MyConvNet(x)
?????????loss?=?loss_func(predict,?y)
?????????optimizer.zero_grad()???#?清空梯度(可以不寫)
?????????loss.backward()?????#?反向傳播計算梯度
?????????optimizer.step()????#?更新網(wǎng)絡(luò)
?????????global_iter_num?=?epoch?*?len(train_loader)?+?step?+?1??#?計算當前是從訓(xùn)練開始時的第幾步(全局迭代次數(shù))
?????????if?global_iter_num?%?log_step_interval?==?0:
?????????????#?控制臺輸出一下
?????????????print("global_step:{},?loss:{:.2}".format(global_iter_num,?loss.item()))
?????????????#?添加的第一條日志:損失函數(shù)-全局迭代次數(shù)
?????????????logger.add_scalar("train?loss",?loss.item()?,global_step=global_iter_num)
?????????????#?在測試集上預(yù)測并計算正確率
?????????????test_predict?=?MyConvNet(test_data_x)
?????????????_,?predict_idx?=?torch.max(test_predict,?1)?????#?計算softmax后的最大值的索引,即預(yù)測結(jié)果
?????????????acc?=?accuracy_score(test_data_y,?predict_idx)
?????????????#?添加第二條日志:正確率-全局迭代次數(shù)
?????????????logger.add_scalar("test?accuary",?acc.item(),?global_step=global_iter_num)
?????????????#?添加第三條日志:這個batch下的128張圖像
?????????????img?=?vutils.make_grid(x,?nrow=12)
?????????????logger.add_image("train?image?sample",?img,?global_step=global_iter_num)
?????????????#?添加第三條日志:網(wǎng)絡(luò)中的參數(shù)分布直方圖
?????????????for?name,?param?in?MyConvNet.named_parameters():
?????????????????logger.add_histogram(name,?param.data.numpy(),?global_step=global_iter_num)
?
運行完后,我們通過cmd來到與代碼同一級的目錄(如果你使用的是pycharm,可以通過pycharm中的終端)輸入指令tensorboard --logdir="./data/log",啟動服務(wù)器。
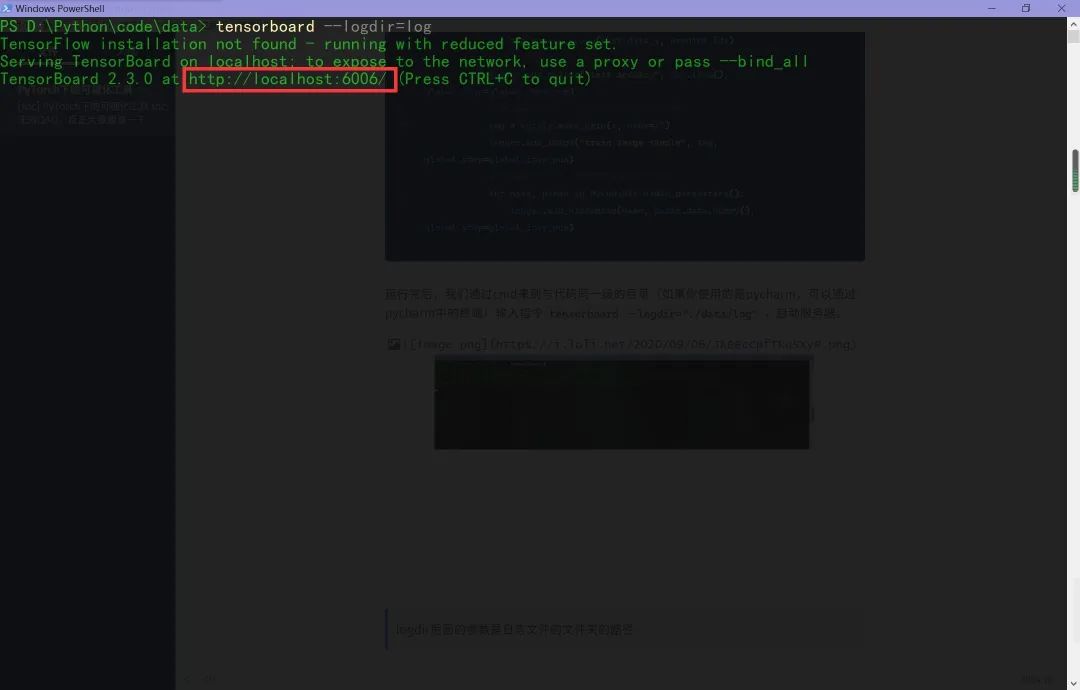
logdir后面的參數(shù)是日志文件的文件夾的路徑
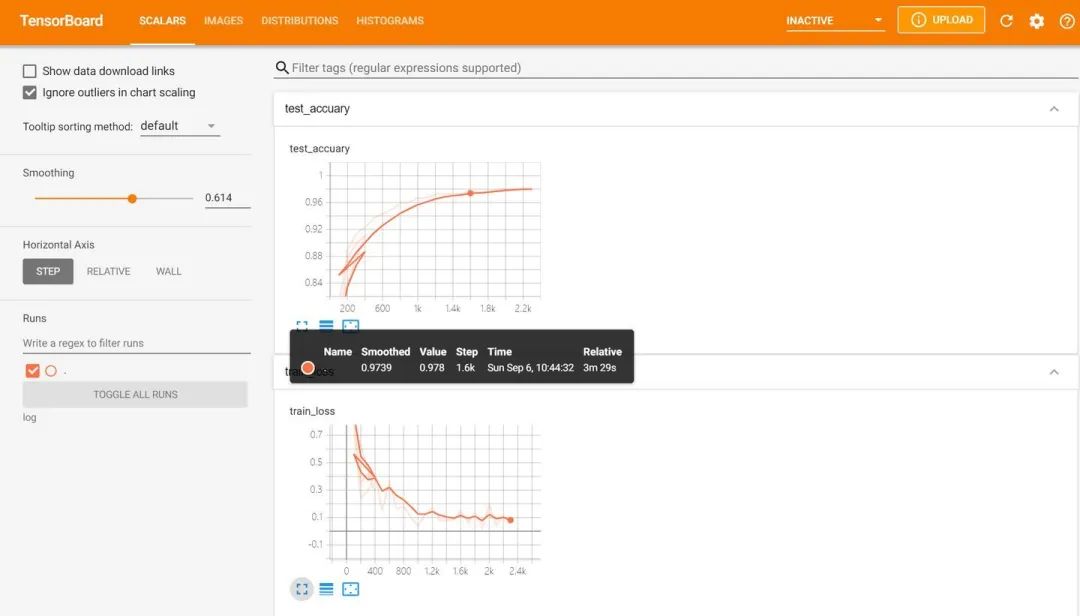
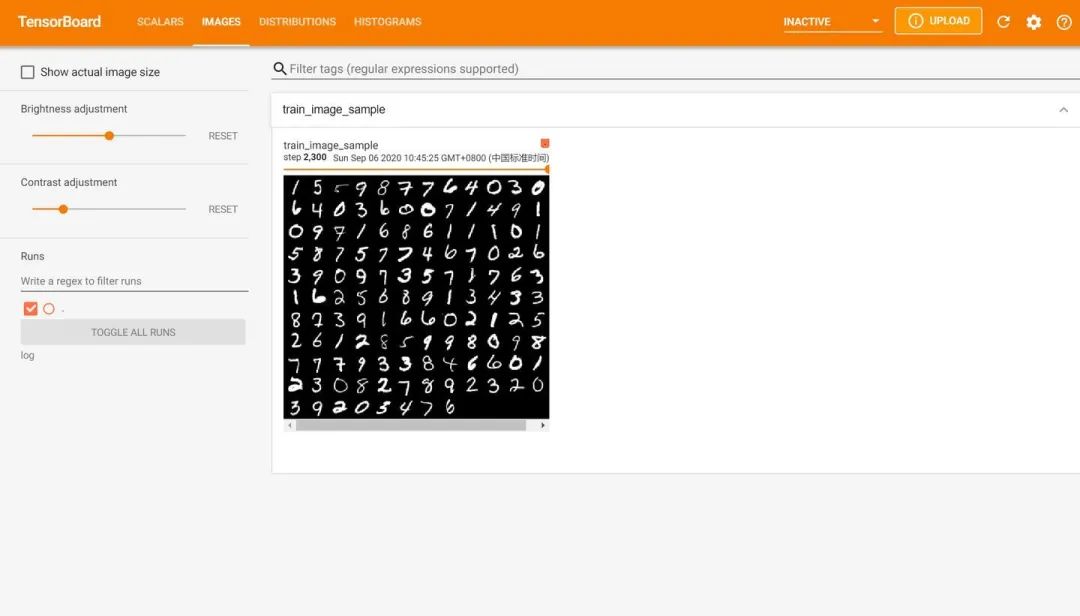
然后在谷歌瀏覽器中訪問紅框框中的url,便可得到可視化界面,點擊上面的頁面控件,可以查看我們通過add_scalar、add_image和add_histogram得到的圖像,而且各方面做得都很絲滑。
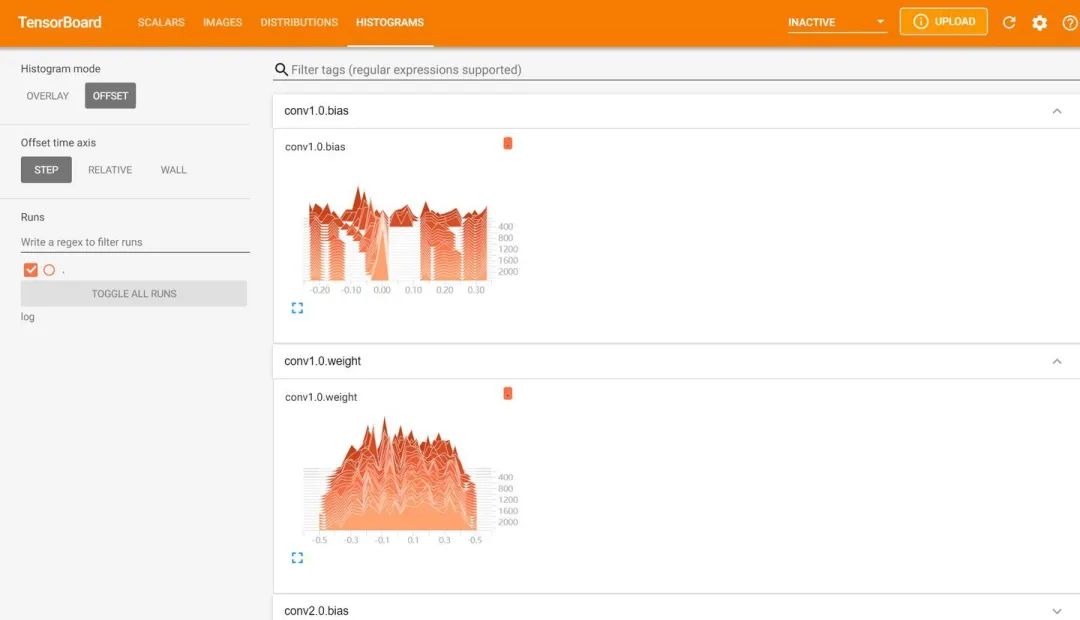
以下是筆者安裝使用tensorboard時遇到的一些錯誤。
好,作為一名沒有裝過TensorFlow的windows玩家,筆者下面開始踩坑。踩完后,直接把幾個可能的錯誤呈上。
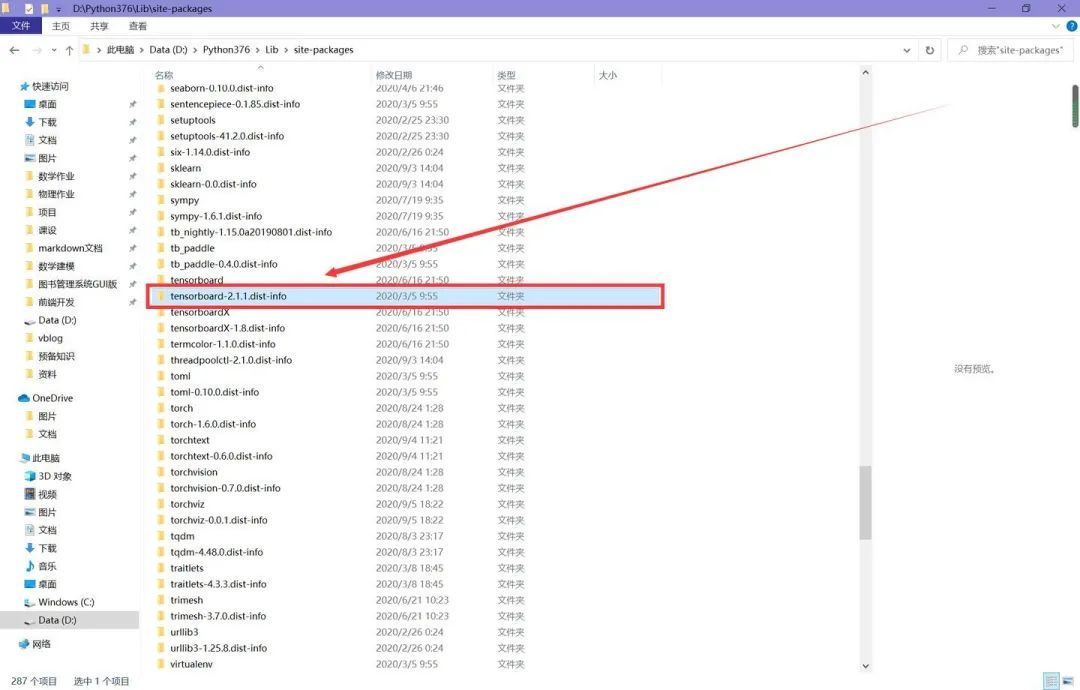
第一個錯誤,運行tensorboard --logdir="./data/log",遇到報錯,內(nèi)容為有重復(fù)的tensorboard的包。
解決方法:找到site-packages(如果你是像我一樣全局安裝的,那么找到解釋器那一級目錄的site-packages,如果是在項目虛擬環(huán)境中安裝的,那么找到項目中的site-packages),刪去下圖中紅框框標出來的文件夾。
第二個錯誤,在解決第一個錯誤后,再次運行命令,還是報錯,內(nèi)容為編碼出錯。由于筆者做過一點前端,在學(xué)習(xí)webpack項目時,曾經(jīng)被告知項目路徑不能含有中文,否則會有編碼錯誤,而剛才的報錯中涉及到了前端服務(wù)器的啟動,因此,筆者想到從文件名入手。
解決方法:確保命令涉及的文件路徑、所有程序涉及到文件不含中文。筆者是計算機名字含有中文,然后tensorboard的日志文件是以本地計算機名為后綴的,所以筆者將計算機名修改成了英文,重啟后再輸入指令就ok了。
2.2 HiddenLayer可視化訓(xùn)練過程
tensorboard的圖像很華麗,但是使用過程相較于其他的工具包較為繁瑣,所以小網(wǎng)絡(luò)一般沒必要使用tensorboard。
?import?hiddenlayer?as?hl
?import?time
?
?#?記錄訓(xùn)練過程的指標
?history?=?hl.History()
?#?使用canvas進行可視化
?canvas?=?hl.Canvas()
?
?#?獲取優(yōu)化器和損失函數(shù)
?optimizer?=?torch.optim.Adam(MyConvNet.parameters(),?lr=3e-4)
?loss_func?=?nn.CrossEntropyLoss()
?log_step_interval?=?100??????#?記錄的步數(shù)間隔
?
?for?epoch?in?range(5):
?????print("epoch:",?epoch)
?????#?每一輪都遍歷一遍數(shù)據(jù)加載器
?????for?step,?(x,?y)?in?enumerate(train_loader):
?????????#?前向計算->計算損失函數(shù)->(從損失函數(shù))反向傳播->更新網(wǎng)絡(luò)
?????????predict?=?MyConvNet(x)
?????????loss?=?loss_func(predict,?y)
?????????optimizer.zero_grad()???#?清空梯度(可以不寫)
?????????loss.backward()?????#?反向傳播計算梯度
?????????optimizer.step()????#?更新網(wǎng)絡(luò)
?????????global_iter_num?=?epoch?*?len(train_loader)?+?step?+?1??#?計算當前是從訓(xùn)練開始時的第幾步(全局迭代次數(shù))
?????????if?global_iter_num?%?log_step_interval?==?0:
?????????????#?控制臺輸出一下
?????????????print("global_step:{},?loss:{:.2}".format(global_iter_num,?loss.item()))
?????????????#?在測試集上預(yù)測并計算正確率
?????????????test_predict?=?MyConvNet(test_data_x)
?????????????_,?predict_idx?=?torch.max(test_predict,?1)??#?計算softmax后的最大值的索引,即預(yù)測結(jié)果
?????????????acc?=?accuracy_score(test_data_y,?predict_idx)
?
?????????????#?以epoch和step為索引,創(chuàng)建日志字典
?????????????history.log((epoch,?step),
?????????????????????????train_loss=loss,
?????????????????????????test_acc=acc,
?????????????????????????hidden_weight=MyConvNet.fc[2].weight)
?
?????????????#?可視化
?????????????with?canvas:
?????????????????canvas.draw_plot(history["train_loss"])
?????????????????canvas.draw_plot(history["test_acc"])
?????????????????canvas.draw_image(history["hidden_weight"])
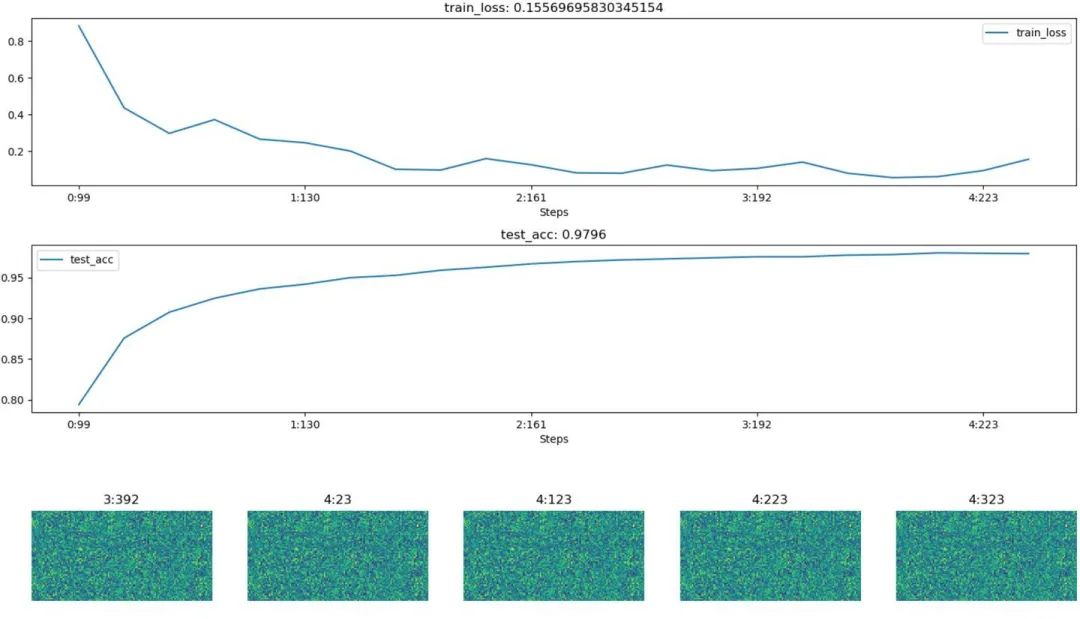
不同于tensorboard,hiddenlayer會在程序運行的過程中動態(tài)生成圖像,而不是模型訓(xùn)練完后
下面為模型訓(xùn)練的某一時刻的截圖:
三、使用Visdom進行可視化
Visdom是Facebook為pytorch開發(fā)的一塊可視化工具。類似于tensorboard,visdom也是通過在本地啟動前端服務(wù)器來實現(xiàn)可視化的,而在具體操作上,visdom又類似于matplotlib.pyplot。所以使用起來很靈活。
首先先安裝visdom庫,然后補坑。由于啟動前端服務(wù)器需要大量依賴項,所以在第一次啟動時可能會很慢(需要下載前端三板斧的依賴項),解決方法請見這里。
先導(dǎo)入需要的第三方庫:
?from?visdom?import?Visdom
?from?sklearn.datasets?import??load_iris
?import?torch
?import?numpy?as?np
?from?PIL?import?Image
matplotlib里,用戶繪圖可以通過plt這個對象來繪圖,在visdom中,同樣需要一個繪圖對象,我們通過vis = Visdom()來獲取。具體繪制時,由于我們會一次畫好幾張圖,所以visdom要求用戶在繪制時指定當前繪制圖像的窗口名字(也就是win這個參數(shù));除此之外,為了到時候顯示的分塊,用戶還需要指定繪圖環(huán)境env,這個參數(shù)相同的圖像,最后會顯示在同一張頁面上。
繪制線圖(相當于matplotlib中的plt.plot)
?#?繪制圖像需要的數(shù)據(jù)
?iris_x,?iris_y?=?load_iris(return_X_y=True)
?
?#?獲取繪圖對象,相當于plt
?vis?=?Visdom()
?
?#?添加折線圖
?x?=?torch.linspace(-6,?6,?100).view([-1,?1])
?sigmoid?=?torch.nn.Sigmoid()
?sigmoid_y?=?sigmoid(x)
?tanh?=?torch.nn.Tanh()
?tanh_y?=?tanh(x)
?relu?=?torch.nn.ReLU()
?relu_y?=?relu(x)
?#?連接三個張量
?plot_x?=?torch.cat([x,?x,?x],?dim=1)
?plot_y?=?torch.cat([sigmoid_y,?tanh_y,?relu_y],?dim=1)
?#?繪制線性圖
?vis.line(X=plot_x,?Y=plot_y,?win="line?plot",?env="main",
??????????opts={
??????????????"dash"?:?np.array(["solid",?"dash",?"dashdot"]),
??????????????"legend"?:?["Sigmoid",?"Tanh",?"ReLU"]
??????????})
繪制散點圖:
?#?繪制2D和3D散點圖
?#?參數(shù)Y用來指定點的分布,win指定圖像的窗口名稱,env指定圖像所在的環(huán)境,opts通過字典來指定一些樣式
?vis.scatter(iris_x[?:?,?0?:?2],?Y=iris_y+1,?win="windows1",?env="main")
?vis.scatter(iris_x[?:?,?0?:?3],?Y=iris_y+1,?win="3D?scatter",?env="main",
?????????????opts={
?????????????????"markersize"?:?4,???#?點的大小
?????????????????"xlabel"?:?"特征1",
?????????????????"ylabel"?:?"特征2"
?????????????})
繪制莖葉圖:
?#?添加莖葉圖
?x?=?torch.linspace(-6,?6,?100).view([-1,?1])
?y1?=?torch.sin(x)
?y2?=?torch.cos(x)
?
?#?連接張量
?plot_x?=?torch.cat([x,?x],?dim=1)
?plot_y?=?torch.cat([y1,?y2],?dim=1)
?#?繪制莖葉圖
?vis.stem(X=plot_x,?Y=plot_y,?win="stem?plot",?env="main",
??????????opts={
??????????????"legend"?:?["sin",?"cos"],
??????????????"title"?:?"莖葉圖"
??????????})
繪制熱力圖:
?#?計算鳶尾花數(shù)據(jù)集特征向量的相關(guān)系數(shù)矩陣
?iris_corr?=?torch.from_numpy(np.corrcoef(iris_x,?rowvar=False))
?#?繪制熱力圖
?vis.heatmap(iris_corr,?win="heatmap",?env="main",
?????????????opts={
?????????????????"rownames"?:?["x1",?"x2",?"x3",?"x4"],
?????????????????"columnnames"?:?["x1",?"x2",?"x3",?"x4"],
?????????????????"title"?:?"熱力圖"
?????????????})
可視化圖片,這里我們使用自定義的env名MyPlotEnv
?#?可視化圖片
?img_Image?=?Image.open("./example.jpg")
?img_array?=?np.array(img_Image.convert("L"),?dtype=np.float32)
?img_tensor?=?torch.from_numpy(img_array)
?print(img_tensor.shape)
?
?#?這次env自定義
?vis.image(img_tensor,?win="one?image",?env="MyPlotEnv",
???????????opts={
???????????????"title"?:?"一張圖像"
???????????})
可視化文本,同樣在MyPlotEnv中繪制:
?#?可視化文本
?text?=?"hello?world"
?vis.text(text=text,?win="text?plot",?env="MyPlotEnv",
??????????opts={
??????????????"title"?:?"可視化文本"
??????????})
?
運行上述代碼,再通過在終端中輸入python3 -m visdom.server啟動服務(wù)器,然后根據(jù)終端返回的URL,在谷歌瀏覽器中訪問這個URL,就可以看到圖像了。
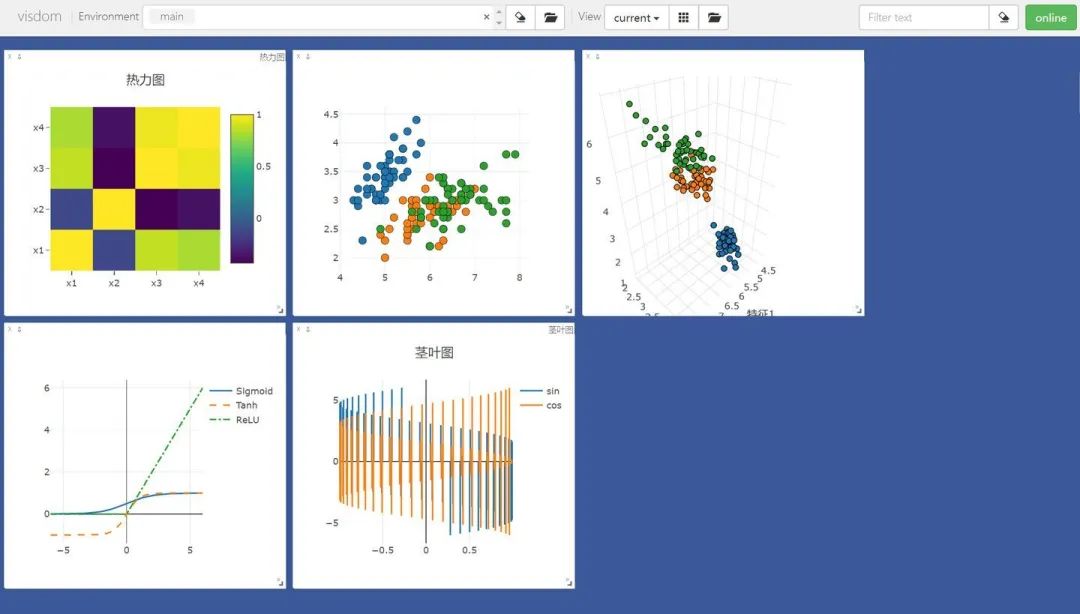
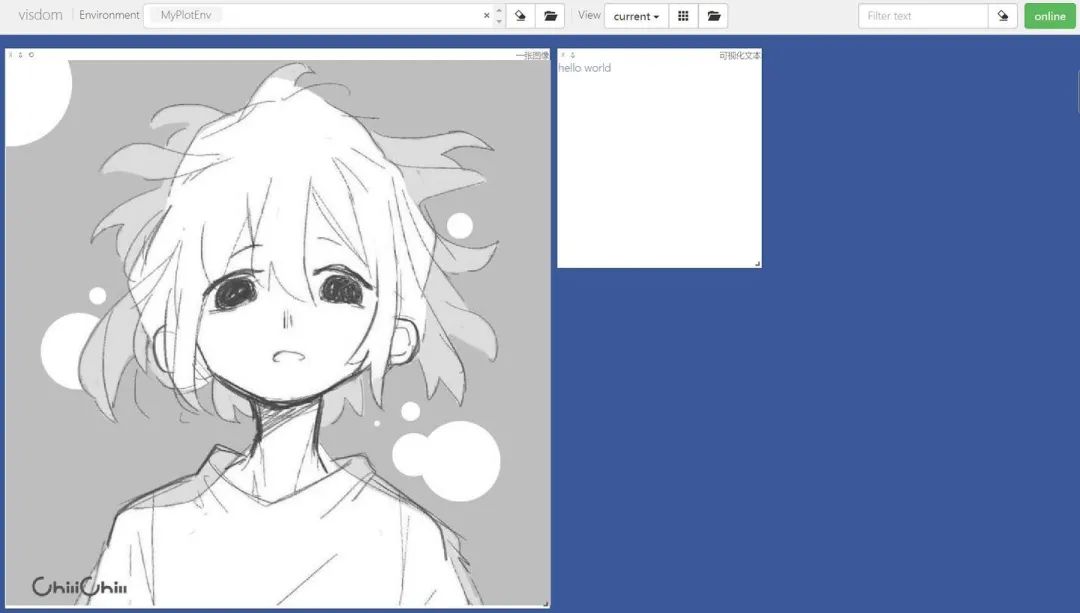
在Environment中輸入不同的env參數(shù)可以看到我們在不同環(huán)境下繪制的圖片。對于分類圖集特別有用。
在終端中按下Ctrl+C可以終止前端服務(wù)器。
進一步
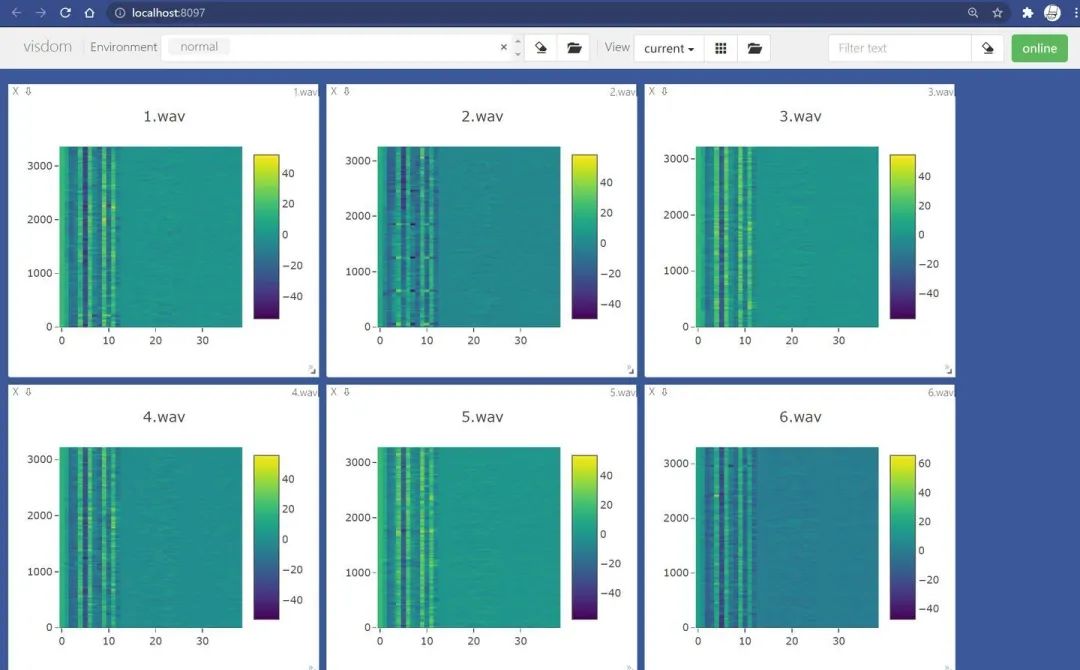
需要注意,如果你的前端服務(wù)器停掉了,那么所有的圖片都會丟失,因為此時的圖像的數(shù)據(jù)都是駐留在內(nèi)存中,而并沒有dump到本地磁盤。那么如何保存當前visdom中的可視化結(jié)果,并在將來復(fù)用呢?其實很簡單,比如我現(xiàn)在有一堆來之不易的Mel頻譜圖:
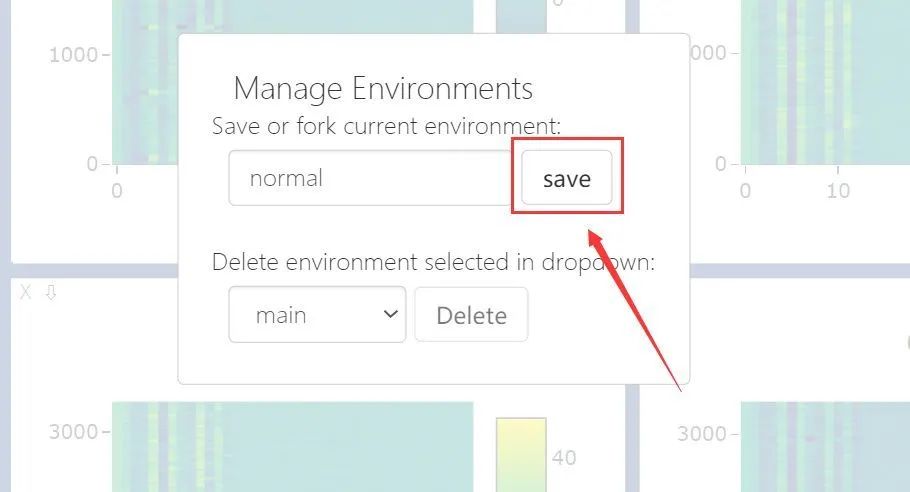
點擊Manage Views

點擊fork->save:(此處我只保存名為normal的env)
接著,在你的User目錄下(Windows是C:\Users\賬戶.visdom文件夾,Linux是在~.visdom文件夾下),可以看到保存好的env:
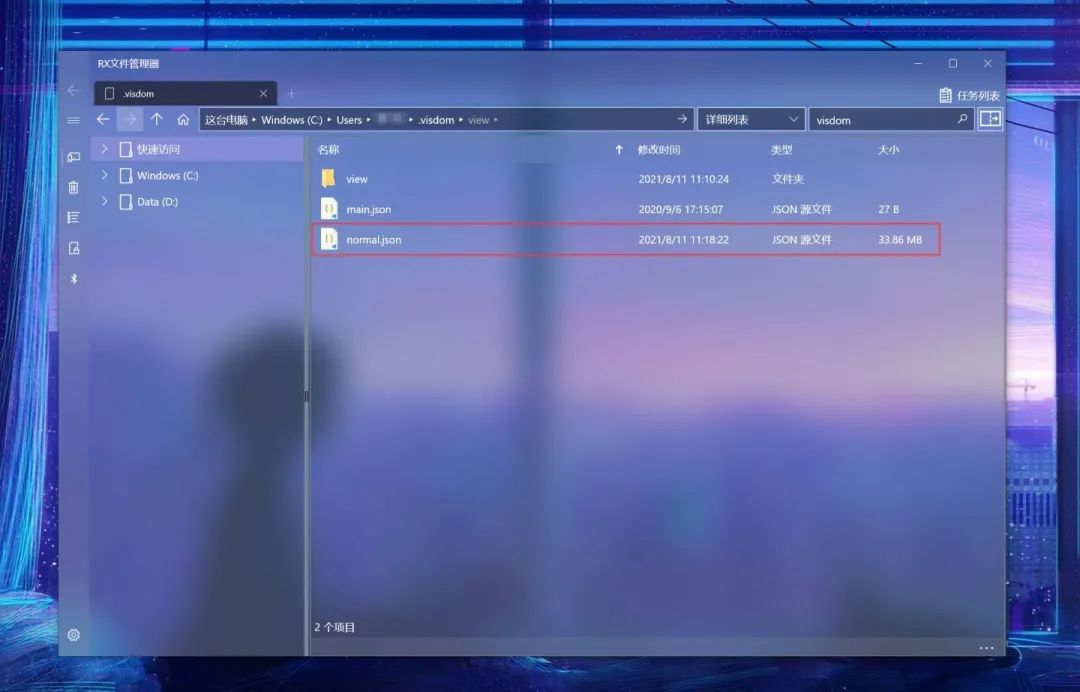
它是以json文件格式保存的,那么如果你保存完后再shut down當前的前端服務(wù)器,圖像數(shù)據(jù)便不會丟失。
好的,現(xiàn)在在保存完你珍貴的數(shù)據(jù)后,請關(guān)閉你的visdom前端服務(wù)器。然后再啟動它。
如何查看保存的數(shù)據(jù)呢?很簡答,下次打開visdom前端后,visdom會在.visdom文件夾下讀取所有的保存數(shù)據(jù)完成初始化,這意味著,你直接啟動visdom,其他什么也不用做就可以看到之前保存的數(shù)據(jù)啦!
那么如何服用保存的數(shù)據(jù)呢?既然你都知道了visdom保存的數(shù)據(jù)在哪里,那么直接通過python的json包來讀取這個數(shù)據(jù)文件,然后做解析就可以了,這是方法一,演示如下:
import?json
with?open(r"...\.visdom\normal.json",?"r",?encoding="utf-8")?as?f:
????dataset?:?dict?=?json.load(f)
jsons?:?dict?=?dataset["jsons"]??????#?這里存著你想要恢復(fù)的數(shù)據(jù)
reload?:?dict?=?dataset["reload"]????#?這里存著有關(guān)窗口尺寸的數(shù)據(jù)?
print(jsons.keys())?????#?查看所有的win
out:
dict_keys(['jsons',?'reload'])
dict_keys(['1.wav',?'2.wav',?'3.wav',?'4.wav',?'5.wav',?'6.wav',?'7.wav',?'8.wav',?'9.wav',?'10.wav',?'11.wav',?'12.wav',?'13.wav',?'14.wav'])
但這么做不是很優(yōu)雅,所以visdom封裝了第二種方法。你當然可以通過訪問文件夾.visdom來查看當前可用的env,但是也可以這么做:
from?visdom?import?Visdom
vis?=?Visdom()
print(vis.get_env_list())
out:
Setting?up?a?new?session...
['main',?'normal']
在獲取了可用的環(huán)境名后,你可以通過get_window_data方法來獲取指定env、指定win下的圖像數(shù)據(jù)。請注意,該方法返回str,故需要通過json來解析:
from?visdom?import?Visdom
import?json
vis?=?Visdom()
window?=?vis.get_window_data(win="1.wav",?env="normal")????
window?=?json.loads(window)?????????#?window?是?str,需要解析為字典
content?=?window["content"]
data?=?content["data"][0]
print(data.keys())
out:
Setting?up?a?new?session...
dict_keys(['z',?'x',?'y',?'zmin',?'zmax',?'type',?'colorscale'])
通過索引這些keys,相信想復(fù)用原本的圖像數(shù)據(jù)并不困難。
如果覺得有用,就請分享到朋友圈吧!

點個在看 paper不斷!