
Elasticsearch 警惕使用 wildcard 檢索!然后呢?
1、wildcard 檢索定義
wildcard 檢索可以定義為:支持通配符的模糊檢索。
類似 Mysql 中的 like 模糊匹配,如下所示:

Elasticsearch 中的 wildcard 使用方式如下:
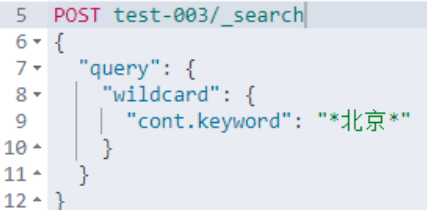
通配符運算符是匹配一個或多個字符的占位符。
通配符支持兩種:
? : 支持模糊匹配單個字符。舉例:Ma?s 僅能匹配:Mars, Mass, 和 Maps。 : 支持模糊匹配零個或者多個字符。舉例:Ma*s 能匹配:Mars, Matches 和 Massachusetts等。
2、全局視野——wildcard 檢索所處位置
全局認知非常重要,檢索核心類型大致(非嚴謹、精確)分為:精準匹配檢索(Term-level queries)和基于分詞的全文匹配檢索(Full text queries)。
全文匹配檢索細分如下:

精準匹配檢索細分如下:
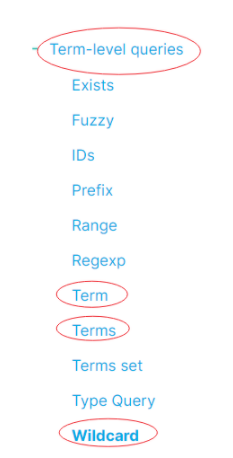
也就是:wildcard 是和Term、Terms檢索平級的檢索。
3、wildcard 檢索適用場景
適用于:召回率要求高的業(yè)務場景。
基于分詞的全文檢索,可能會導致明明存在,但是檢索不到。可能的原因如下:
原因1:基礎詞庫不完備; 原因2:分詞粒度不精確。
舉個例子一看就明白了:
前置說明:
1、純屬舉例,不涉及針對具體人。 2、Ik 詞典main.dic 非原生,做了互聯(lián)網(wǎng)詞庫的擴展,但詞庫中依然沒有“劉強東”三個字。 3、如果你在本地測試結果和文章不一致,極大可能是詞典不一樣導致的。
PUT test-004
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
}
}
}
POST test-004/_bulk
{"index":{"_id":1}}
{"title":"英文官網(wǎng)承認劉強東一度被捕的原因是涉嫌XX"}
{"index":{"_id":2}}
{"title":"別提了朋友哥哥劉強東窗事發(fā)了"}
{"index":{"_id":3}}
{"title":"劉強東施效顰,沒想到竟然收獲了流量"}
{"index":{"_id":4}}
{"title":"劉強東是誰?我不認識"}
POST test-004/_search
{
"query": {
"match_phrase": {
"title": "劉強東"
}
}
}
用的短語檢索 match_phrase,搜索結果如下:

原因說明,analyzer API 能說明一切。
POST test-004/_analyze
{
"text": [
"京東英文官網(wǎng)承認劉強東一度被捕的原因是涉嫌XX"
],
"analyzer": "ik_max_word"
}
分詞結果如下:

面對如上召回情況,部分不追求精準率只追求召回率的業(yè)務場景,可能會需要文檔_id = 1、2、3、4 全部都要召回。
這時候,如果不改變分詞的情況下,可能的解決方案之一就是:wildcard 檢索實現(xiàn)。
POST test-004/_search
{
"query": {
"wildcard": {
"title.keyword": "*劉強東*"
}
}
}
如上的方式,文檔1、2、3、4全部召回。
相當于在原有DSL的基礎上,只改動檢索方式和字段名稱就搞定了產(chǎn)品經(jīng)理的提高召回率的需求。
貌似,可以交差大吉了。實則,有非常大的隱患。
4、wildcard 可能的風險
官方文檔是這么說的:

中文含義是:避免以*或?開頭的模式。這會增加查找匹配項所需的迭代次數(shù)并降低搜索性能。
wildcard 到底有多慢?如下示例可見一斑:
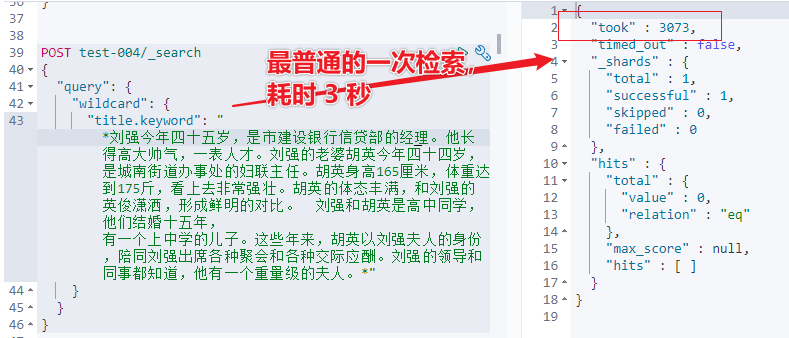
wildcard 檢索字段指定的字符數(shù)多了以后,會報錯如下:

在 wood 大叔 2017年的文章中,曾經(jīng)指出如下的核心點:
4.1 出現(xiàn)問題
用戶輸入的字符串長度沒有做限制,導致首尾通配符中間可能是很長的一個字符串。后果就是對應的wildcard Query執(zhí)行非常慢,非常消耗CPU。
4.2 根本原因
為了加速通配符和正則表達式的匹配速度,Lucene4.0開始會將輸入的字符串模式構建成一個DFA (Deterministic Finite Automaton),帶有通配符的pattern構造出來的DFA可能會很復雜,開銷很大。
源碼及細節(jié)推薦閱讀:
https://elasticsearch.cn/article/171
https://elasticsearch.cn/article/186
5、wildcard 實戰(zhàn)中的悲劇
如下,采用原汁原味的技術群交流內(nèi)容,更具有說服力。
更能警示大家:慎用 Wildcard!
5.1 悲劇1:一味的滿足產(chǎn)品經(jīng)理的需求,wildcard 不考慮性能的亂用。

5.2 悲劇2:wildcard 參數(shù)傳了一篇文章進來,導致集群宕機!

5.3 悲劇3:wildcard 搜索一百個漢字,導致CPU利用率 100%!
注意是:不同100個字組合,一直搜。

5.4 悲劇4:客戶現(xiàn)場演示,集群宕機!
根因:bool 組合了近 100 組+ wildcard 不同關鍵詞的檢索。
6、wildcard 可能的替代方案
在尋求解決方案的時候,我們要先問一下:為什么大家喜歡用 wildcard 實現(xiàn)模糊檢索?
得到的答復往往是:順手,類似Mysql like 查詢,短、平、快的達到了產(chǎn)品經(jīng)理的要求,滿足了項目需求。
但,這忽略了性能問題以及可能帶來的災難后果。
所以,解決方案應該從根源上入手,以尋求徹底解決。
6.1 替代方案一:寫入時分詞優(yōu)化,使用 Ngram 分詞。
更細粒度分詞,更有利于數(shù)據(jù)的召回!
PUT test-005
{
"settings": {
"index.max_ngram_diff": 10,
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "ngram",
"min_gram": 3,
"max_gram": 10,
"token_chars": [
"letter",
"digit"
]
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "my_analyzer",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
}
}
}
POST test-005/_bulk
{"index":{"_id":1}}
{"title":"英文官網(wǎng)承認劉強東一度被捕的原因是涉嫌性侵"}
{"index":{"_id":2}}
{"title":"別提了朋友哥哥劉強東窗事發(fā)了"}
{"index":{"_id":3}}
{"title":"劉強東施效顰,沒想到竟然收獲了流量"}
{"index":{"_id":4}}
{"title":"劉強東是誰?我不認識"}
POST test-005/_search
{
"query": {
"match_phrase": {
"title": "劉強東"
}
}
}
Ngram 實現(xiàn)推薦:
Elasticsearch能檢索出來,但不能正確高亮怎么辦?
6.2 替代方案二:7.9 + 以上的版本,使用 wildcard 數(shù)據(jù)類型。
wildcard 類型出現(xiàn)的目的:一方面避免了某些場景下分詞查詢不準確的問題,另一方面也解決了通配符和正則檢索的效率問題。
注意:新上的數(shù)據(jù)類型 wildcard,而非 wildcard 檢索。
使用方法參見:
https://www.elastic.co/guide/en/elasticsearch/reference/master/keyword.html#wildcard-field-type。
6.3 禁用方案:禁止使用wildcard 模糊檢索
特殊業(yè)務場景需要禁止:wildcard 檢索。
實現(xiàn)如下:
PUT _cluster/settings
{
"transient": {
"search.allow_expensive_queries": false
}
}
需要強調(diào)的是:
"search.allow_expensive_queries" 是 7.7+ 版本才有的功能,早期版本會報錯。
7、小結
由于技術慣性,我們習慣于相同或者相通技術的技術遷移,比如:mysql like 查詢遷移到 Elasticsearch 中的 wildcard 模糊檢索。但遷移的時候一定要注意:不同技術點的實現(xiàn)差異,同時要多關注技術點不能可能導致的性能問題。
即便 2017年 wood 大叔就發(fā)了兩篇文章讓大家警惕 wildcard 模糊檢索可能帶來的性能問題。但四年后的今天,仍然很多公司的實戰(zhàn)業(yè)務中還未考慮性能及后果的前提下,樂此不疲的用著 wildcard 檢索!
所以,本文算是 wood 大叔的 wildcard 警示文章接力,希望更多人看到。
參考:
https://t.zsxq.com/Y3zv7Eq
https://t.zsxq.com/bm62zZf
推薦:
中國最大的 Elastic 非官方公眾號
點擊查看“閱讀原文”,更短時間更快習得更多干貨。和全球 1000 位+ Elastic 愛好者(含中國 50%+ Elastic 認證工程師)一起每日精進 ELK 技能!