
實時用戶畫像實踐經(jīng)驗
一、前言
?1、通過提供實時的業(yè)務(wù)指標(biāo),解決業(yè)務(wù)對熱點、潛力的把控,助力生產(chǎn)、消費,提升優(yōu)質(zhì)創(chuàng)作量及內(nèi)容消費能力。
?2、提供實時的復(fù)雜計算的外顯指標(biāo),加強用戶體驗,解決業(yè)務(wù)側(cè)通過后端腳本計算的高維護成本和復(fù)雜性,節(jié)約成本,提升人效。
實時算法特征
?1、以實時數(shù)據(jù)為基礎(chǔ),提供多樣的實時算法特征,與算法團隊共同提升 DAU、留存、用戶付費等核心指標(biāo)。用戶畫像
?1、用戶篩選,做到多維、多類型的定向篩選,并接入營銷、廣告、 運營平臺等系統(tǒng),提高業(yè)務(wù)效率,降低人員成本。
?1、用戶分析,做到多角度用戶分析,定向用戶分析報告 0 成本,助力業(yè)務(wù)部門快速把握核心客戶市場。
本文就知乎平臺的數(shù)據(jù)賦能團隊,基于以上三個方向的目標(biāo),就這四個問題,來逐一介紹這方面的技術(shù)實踐經(jīng)驗和心得體會:
?1、如何通過實時數(shù)據(jù)驅(qū)動業(yè)務(wù)發(fā)展?
?2、如何從 0 -> 1 搭建實時數(shù)據(jù)中心?
?3、如何搭建一套高效快速的用戶畫像系統(tǒng)來解決歷史系統(tǒng)的多種問題?
?4、如何快速高效的開發(fā)業(yè)務(wù)功能和保證業(yè)務(wù)質(zhì)量?
1.1 名詞解釋

1.2 實時數(shù)據(jù)與用戶畫像與各業(yè)務(wù)的結(jié)合
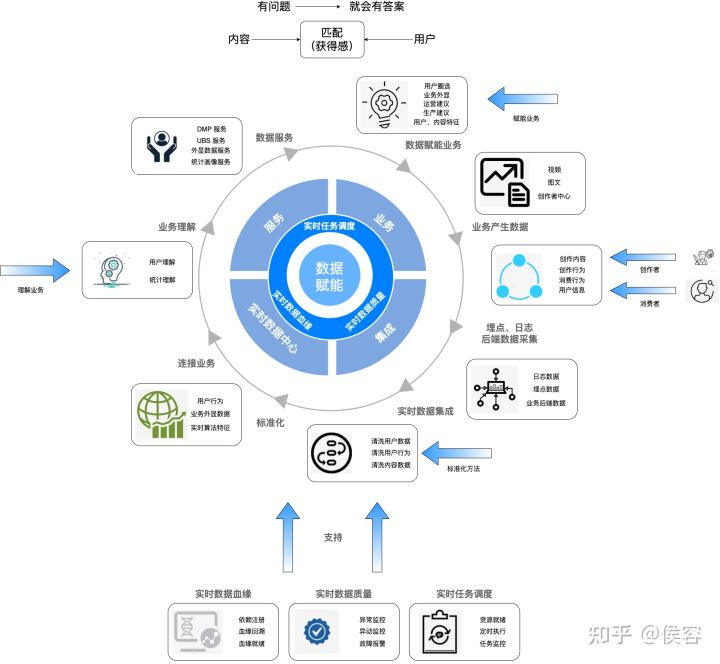
二、面臨的挑戰(zhàn)和痛點
?1、如何通過實效性發(fā)現(xiàn)業(yè)務(wù)價值?
??1.1、搭建熱點、潛力等緊隨時間的指標(biāo)和相關(guān)的排行榜,直接支持業(yè)務(wù)發(fā)展。
?2、如何讓用戶畫像的篩選和分析能力最大化?
??2.1、要全面覆蓋多維度用戶篩選的多種需求。
??2.2、多角度、多方式覆蓋用戶分析。
2)數(shù)據(jù)實效性
?1、推薦頁首屏瀏覽 6 條內(nèi)容,如何在第二刷的時候就立即感知到最新的用戶行為?
??1.1、通過 UBS 建設(shè)提升實效性(下面介紹)。
?2、在推薦算法中,非常實時的特征推薦算法效果要比天級別更新特征的算法效果好很多,如何保證 10 分鐘內(nèi)算法受到特征變更?
??2.1、通過實時數(shù)據(jù)系統(tǒng)與 Palo 配合共同建設(shè),提升到 10 分鐘內(nèi)更新(下面介紹)。
3)接口實時性
?1、熱點運營場景,期望用戶畫像服務(wù)能在秒級別快速篩選出大量人群,用戶后續(xù)的推送等運營場景,如何解決?
??1.1、通過用戶畫像系統(tǒng)與 Palo 配合共同建設(shè),提升人群篩選的速度(下面介紹)。
4)復(fù)雜性
?1、實時數(shù)據(jù)幾乎沒有 count、sum 需求。幾乎都是復(fù)雜去重和多數(shù)據(jù)聯(lián)合計算的情況。
??1.1、以播放量為例。在啟播、暫停、完播、心跳等多個條件下,會同時有多個點,要進行去重。同時基于視頻回答、視頻的關(guān)系和雙作者聯(lián)合創(chuàng)作的關(guān)系,需要疊加,同時保證在父子內(nèi)容異常狀態(tài)的情況下過濾其中部分播放行為。
?2、人群分析業(yè)務(wù),期望多角度、各維度進行人群關(guān)聯(lián)計算,同時基于全部用戶特征針對當(dāng)前人群和對比人群進行 TGI 計算,篩選出顯著特征,如何解決?
??2.1、通過用戶畫像系統(tǒng)與 Palo 配合共同建設(shè),解決復(fù)雜的人群分析(下面介紹)。
?3、業(yè)務(wù)數(shù)據(jù)中有增 / 刪 / 改邏輯,如何實時同步?
??3.1、實時數(shù)據(jù)集成系統(tǒng)與 Palo 配合共同建設(shè),解決增 / 刪 / 改邏輯(下面介紹)。
?4、明細數(shù)據(jù)異常發(fā)現(xiàn)滯后,異常發(fā)現(xiàn)后,需要針對性修正構(gòu)建方式,及回溯數(shù)據(jù)修復(fù),如何解決?
??4.1、通過選擇 Lambda 架構(gòu)作為數(shù)據(jù)架構(gòu)解決(下面介紹)。
三、實踐及經(jīng)驗分享
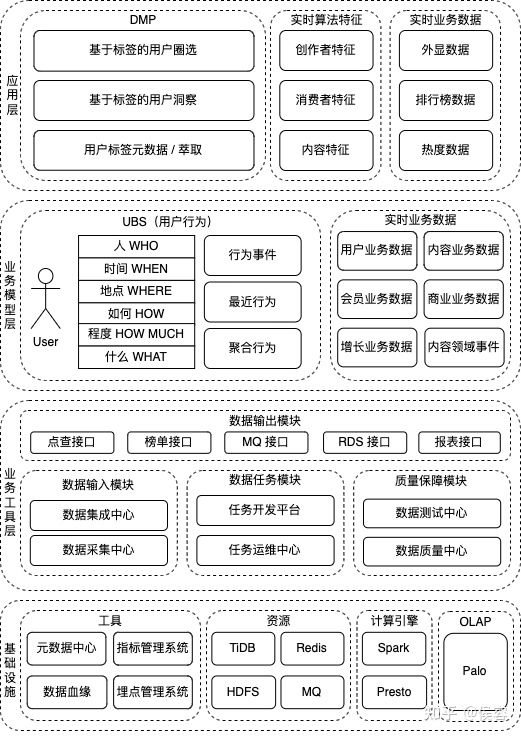
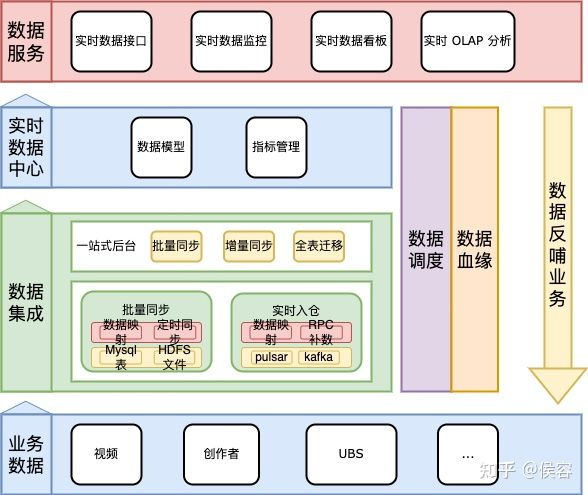
3.1 整體業(yè)務(wù)架構(gòu)
業(yè)務(wù)模型層:支持應(yīng)用層建設(shè)和一定的實時分析能力,同時也作為業(yè)務(wù)某一個流程的功能模塊接入使用,為外部業(yè)務(wù)和自身應(yīng)用層建設(shè),與業(yè)務(wù)共擔(dān)目標(biāo),為業(yè)務(wù)賦能。
業(yè)務(wù)工具層:支持應(yīng)用層和業(yè)務(wù)模型層的開發(fā),提供通用的工具,面向降低應(yīng)用層和業(yè)務(wù)模型層的建設(shè)成本,提升整體建設(shè)的工程效能,保證業(yè)務(wù)穩(wěn)定和數(shù)據(jù)質(zhì)量準(zhǔn)確。
基礎(chǔ)設(shè)施:技術(shù)中臺提供的基礎(chǔ)設(shè)施和云服務(wù),提供穩(wěn)定可用的基礎(chǔ)功能,保證上層建筑的穩(wěn)定性。
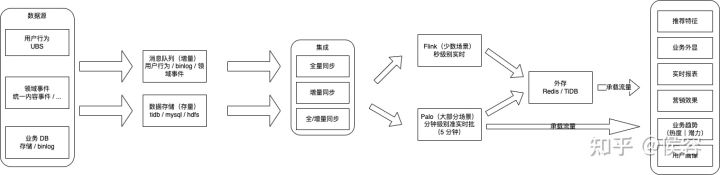
3.2 實時數(shù)據(jù)的數(shù)據(jù)架構(gòu)選型
3.3 應(yīng)用層建設(shè)經(jīng)驗分享
3.3.1 實時數(shù)據(jù)系統(tǒng)
實時數(shù)據(jù)系統(tǒng)主要有兩個大方向:實時業(yè)務(wù)數(shù)據(jù)和實時算法特征。
?1、通過提供實時的業(yè)務(wù)指標(biāo),解決業(yè)務(wù)對熱點、潛力的把控,助力生產(chǎn)、消費,提 升優(yōu)質(zhì)創(chuàng)作量及內(nèi)容消費能力。
?2、提供實時的復(fù)雜計算的外顯指標(biāo),加強用戶體驗,解決業(yè)務(wù)側(cè)通過后端腳本計算的高維護成本和復(fù)雜性,節(jié)約成本,提升人效。
實時算法特征。
?1、以實時數(shù)據(jù)為基礎(chǔ),提供多樣的實時算法特征,與推薦算法團隊共同提升 DAU、留存、用戶付費等核心指標(biāo)。
面臨的困難
?1、依賴數(shù)據(jù)源多,計算規(guī)則復(fù)雜。以我們的播放量計算為例:
??1.1、行為有多條,需要針對行為進行去重。
??1.2、過濾和加和規(guī)則很多,需要依賴多個數(shù)據(jù)源的不同數(shù)據(jù)結(jié)果進行計算。
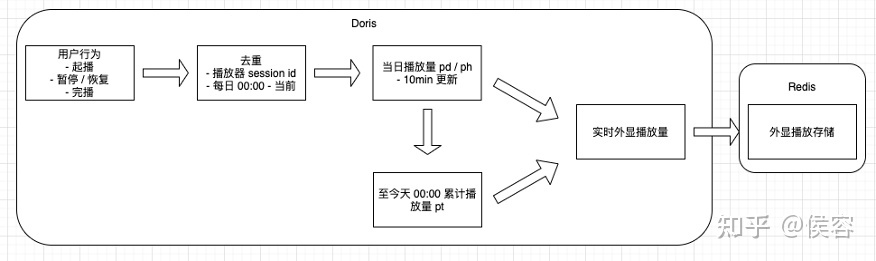
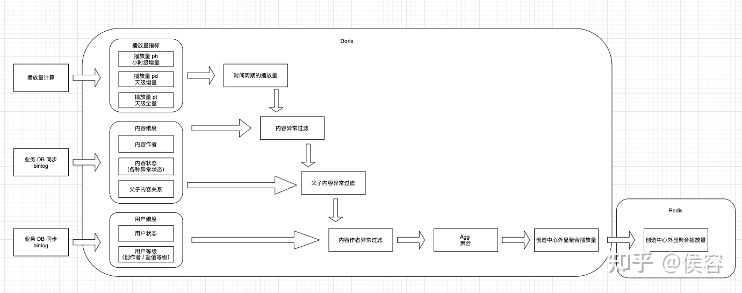
??2.1、以算法特征為例,用戶瀏覽某內(nèi)容后,針對后續(xù)關(guān)聯(lián)的一系列計算后,需要在一定時間內(nèi)產(chǎn)出計算結(jié)果(10min 未產(chǎn)出后續(xù)推薦效果會有波動,26min 該特征的效果會降為 0)
?3、調(diào)度過程中協(xié)調(diào)成本高
??3.1、需要調(diào)度系統(tǒng)中,同時能識別 kafka 流消費的進度和任務(wù)完成情況。
??3.2、需要嚴(yán)格拉齊多個依賴的消費進度,當(dāng)達到統(tǒng)一進度后,集中進行后續(xù)任務(wù)計算。
解決方案
搭建實時數(shù)據(jù)基座,建設(shè)相應(yīng)的數(shù)據(jù)模型,降低建設(shè)成本。
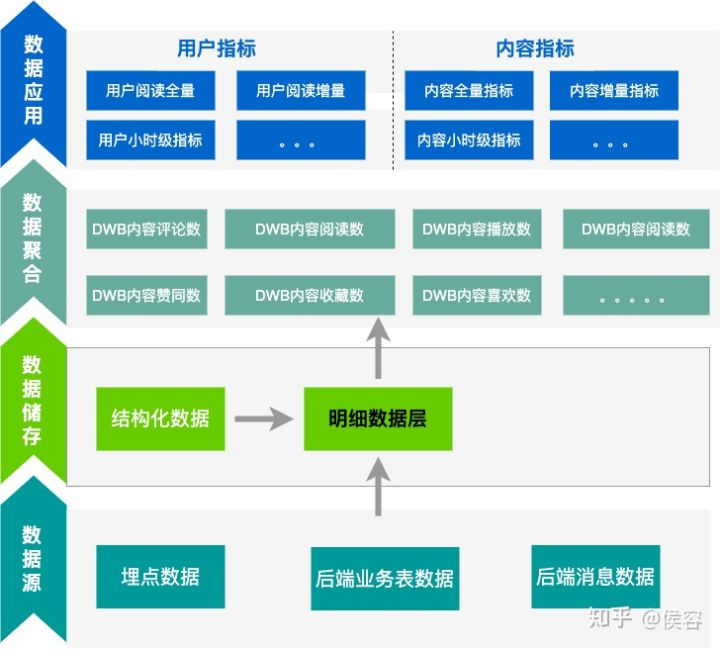
?1、通過建設(shè)實時數(shù)據(jù)集成和實時數(shù)據(jù)調(diào)度的能力,保障數(shù)據(jù)接入和數(shù)據(jù)模型建設(shè)的速度,降低接入時間,提升業(yè)務(wù)接入效率(具體見下方)
?2、通過建設(shè)實時數(shù)據(jù)質(zhì)量中心,保障數(shù)據(jù)質(zhì)量,降低發(fā)現(xiàn)數(shù)據(jù)質(zhì)量問題的時間,提升發(fā)現(xiàn)效率,保證業(yè)務(wù)交付結(jié)果(具體見下方)
時間敏感性高,加強監(jiān)控、與 Palo 集群共同提升吞吐效率和計算效率。
?1、搭建寫入延遲、計算延遲等監(jiān)控,快速發(fā)現(xiàn)問題。
?2、Palo 集群進行參數(shù)變更,調(diào)整批量寫入的數(shù)據(jù)量、時間和頻率等進行優(yōu)化。
??2.1、當(dāng)前我們的 Load 主要有 Broker Load 和 Routine Load。其中時效性要求高的是 Routine Load。我們針對性的進行了參數(shù)調(diào)整。
?3、Palo 增加了 Runtime Filter,通過 BloomFilter 提升 Join 性能。
??3.1、Palo 集群在 0.14 版本中加入了 Runtime Filter 的過濾,針對 Join 大量 key 被過濾的情況有明顯提升;
??3.2、該變更針對我們當(dāng)前的幾個業(yè)務(wù)調(diào)度性能,有明顯提升。時間從 40+s 提升至 10s 左右;
3.3.2 用戶畫像系統(tǒng) DMP
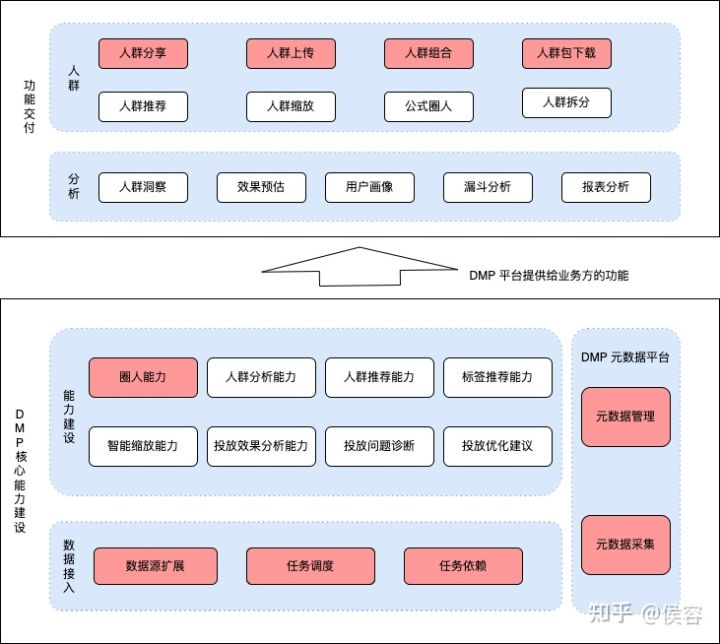
用戶畫像系統(tǒng)主要有兩大功能:用戶檢索和用戶分析。
?1、用戶檢索。重點在于快速完成人群包圈選同時在圈選條件變更過程中,需要快速計算出預(yù)計能圈的用戶有哪些?
?2、用戶分析。重點在于多人群包的各個維度對比分析,通過分析結(jié)論找到最明顯的用戶特征(通過 TGI 值判斷)
面臨的困難
?1、數(shù)據(jù)規(guī)模大。我們當(dāng)前是 200+ 個標(biāo)簽,每個標(biāo)簽均有不同的枚舉值,總計有 300+ 萬的 tag。tag 對用戶的打標(biāo)量級在 900+ 億條記錄。由于標(biāo)簽每日更新導(dǎo)入量級十分大。
?2、篩選響應(yīng)時間要求高。針對簡單的篩選,要求在秒級別出結(jié)果,針對復(fù)雜的人群篩選,篩選后人群量大的情況,要求在 20s 內(nèi)完成人群包生成。
?3、人群包除了 long 類型的用戶 id 外,還需要有多種不同的設(shè)備 id 和設(shè)備 id md5 作為篩選結(jié)果。
?4、用戶分析場景下,針對 300+ 萬 tag 的多人群交叉 TGI 計算,需要在 10min 內(nèi)完成。
解決方案
DMP 業(yè)務(wù)架構(gòu)
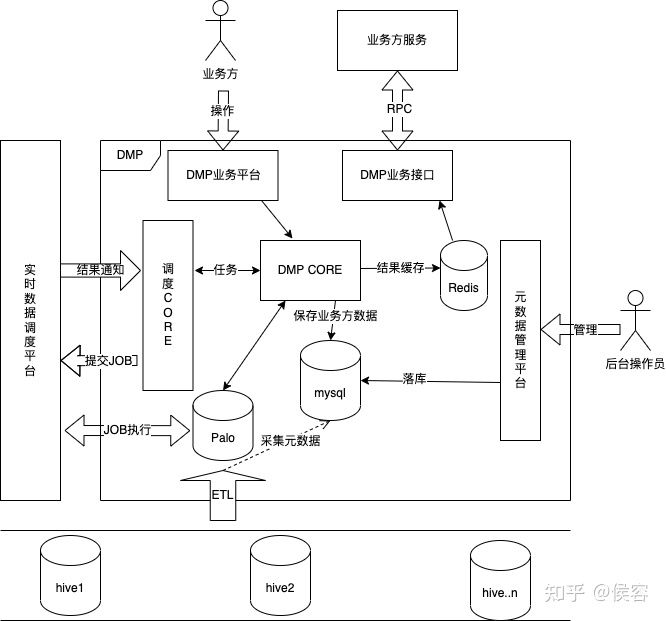
數(shù)據(jù)規(guī)模大,提升導(dǎo)入性能,分而治之。
?1、數(shù)據(jù)模型變更,拆分文件。
??Palo 的存儲是按照 Tablet 分散在集群上的。通過調(diào)整數(shù)據(jù)模型,確保分布均勻及每個文件盡可能的小。
?2、導(dǎo)入變更,拆分導(dǎo)入。
??由于每個 Broker Load 導(dǎo)入都是有性能瓶頸的,將 900+ 億行數(shù)據(jù),拆分為 1000+ 個 Broker Load 的導(dǎo)入任務(wù),確保每個導(dǎo)入總量都足夠小。
提升人群篩選和人群分析的計算速度,分而治之。
??1.1、將用戶每 0 ~ 100 萬拆分為一組。
??1.2、針對全部用戶的交并差,等價于對所有組用戶交并差后的并集。
??1.3、針對全部用戶的交并差的總數(shù),等價于對分組用戶交并差后的總數(shù)進行 sum。
?2、數(shù)據(jù)模型變更,拆分文件。
??2.1、設(shè)置 bitmap 的分組參數(shù),將分組設(shè)置為 colocate group。確保每個分組的交并差計算均在自己所在 BE 完成,無需 shuffle。
??2.1、將 bitmap 表的分桶拆分更多,通過更多文件同時計算加速結(jié)果。
?3、計算參數(shù)變更,提升并發(fā)。
??3.1、由于計算過程通過分治的手段,拆分為多個小任務(wù)。通過提升并行度 parallel_fragment_exec_instance_num 再進一步優(yōu)化計算速度。
效果
上線后,接入了知乎多個主要場景的業(yè)務(wù),支持多業(yè)務(wù)方的人群定向和分析能力。為業(yè)務(wù)帶來曝光量、轉(zhuǎn)化率等直接指標(biāo)的提升。
同時在工具性能上,有如下表現(xiàn):
?1、導(dǎo)入速度。當(dāng)前每日 900+ 億行數(shù)據(jù),在 3 小時內(nèi)完成導(dǎo)入。
?2、人群預(yù)估。人群預(yù)估基本可在 1s 內(nèi)完成,P95 985ms。
?3、人群圈選。人群圈選過程在 5s 內(nèi)完成,整體圈人在 2min 左右。(待提升中介紹)
?4、人群分析。人群分析過程在 5min 內(nèi)完成。
待提升
功能擴展
?1、缺乏定制的人群擴散能力。多業(yè)務(wù)場景對已有人群進行擴散有復(fù)雜且多樣的需求。
?2、缺乏用戶人群染色,無法再多個環(huán)節(jié)完成用戶效果的回收和進行后續(xù)的分析。
性能提升
?1、當(dāng)前 Palo 的行列轉(zhuǎn)換功能在建設(shè)中。在用戶畫像業(yè)務(wù)中,將用戶 id 更換為設(shè)備 id,人群縮減(將具體人群包縮減為一個比較小的人群包用于后續(xù)運營動作)過程是通過業(yè)務(wù)代碼實現(xiàn)的,降低了性能。
??1.1、后續(xù)結(jié)果由行列轉(zhuǎn)換后,用戶畫像結(jié)果處理流程中會將設(shè)備 id 獲取方式通過 join 維度表來實現(xiàn),人群縮減通過 order by rand limit 來實現(xiàn),會有比較明顯的性能提升。
?2、當(dāng)前 Palo 的讀取 bitmap 功能在建設(shè)中。業(yè)務(wù)代碼無法讀取到 bitmap,只能先通過 bitmap_to_string 方法讀取到轉(zhuǎn)換為文本的 bitmap,加大了傳輸量,降低了圈選性能。
??2.1、后續(xù)可以直接讀取 bitmap 后,業(yè)務(wù)邏輯中會替換為直接獲取 bitmap,會極大程度的減少數(shù)據(jù)傳輸量,同時業(yè)務(wù)邏輯可以針對性緩存,。
?3、針對人群預(yù)估邏輯,當(dāng)前是通過例如 bitmap_count(bitmap_and) 兩個函數(shù)完成的,后續(xù) Palo 會提供 bitmap_and_count 合并為一個函數(shù),替換后可提升計算效率。
3.4 工具層建設(shè)經(jīng)驗分享
3.4.1 數(shù)據(jù)集成
?1、在從離線數(shù)倉進行 broker load 的時候數(shù)據(jù)依賴丟失,上游數(shù)據(jù)錯誤無法評估受影響的范圍。
?2、需要編寫冗長的 etl 處理邏輯代碼,小的操作變更流程很長,需要全流程(至少 30 分鐘)的上線操作;此外每次部署操作還有可能遇到各種初始化 MQ 消費者的問題
?3、缺少運行狀態(tài)監(jiān)控,出現(xiàn)異常問題無法在分鐘甚至小時級別的時間發(fā)現(xiàn);
?4、在線導(dǎo)入僅支持 kafka json,上游的 pulsar、protobuf 數(shù)據(jù)仍需要代碼開發(fā)進行轉(zhuǎn)發(fā),導(dǎo)致每次接入數(shù)據(jù)都需要轉(zhuǎn)換函數(shù)的開發(fā)以及同樣全流程的上線操作;
?5、業(yè)務(wù)邏輯中,期望業(yè)務(wù)是什么樣,Palo 中的數(shù)據(jù)就是什么樣,讓業(yè)務(wù)無感知。這種全增量同步期望被包住,而不是做很多配置或開發(fā)很多代碼來實現(xiàn)。
解決方案
在建設(shè)實時數(shù)據(jù)模型的過程中。需要依賴眾多業(yè)務(wù)的數(shù)據(jù),同時需要針對數(shù)據(jù)逐層建設(shè)數(shù)據(jù)模型。摸索并搭建了實時數(shù)據(jù)集成系統(tǒng)和實時調(diào)度系統(tǒng),并下沉到工具層。
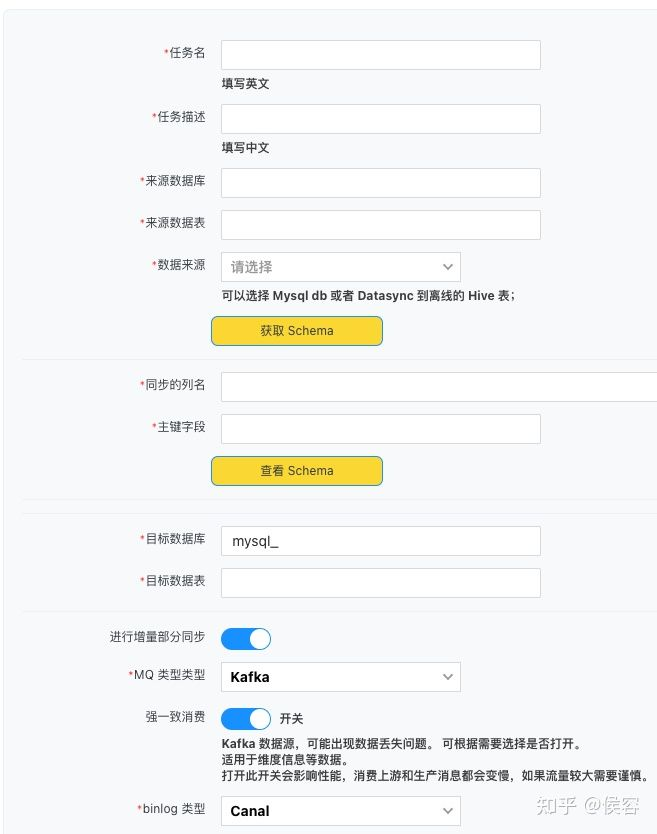
?1、實時數(shù)據(jù)集成。建設(shè)快速且自定義的配置,針對不同的數(shù)據(jù)源建設(shè)導(dǎo)入能力。
?2、與 Palo 的 Broker Load 和 Routine Load 進行配合,在此基礎(chǔ)上搭建針對業(yè)務(wù)的全增量同步。
?3、封裝集成能力對內(nèi)部暴露的接口,業(yè)務(wù)層無需理解中間過程,只選擇同步的數(shù)據(jù)庫和數(shù)據(jù)表即可進行實時同步。
同步配置

?2、中間鏈路多,缺乏報警,針對重要的鏈路,建設(shè)打點和報警成本高,需要 0.5 天左右。
??2.1、全量:原始數(shù)據(jù)庫 TiDB -> 中間部分(DataX)-> Palo
??2.2、增量:原始數(shù)據(jù)庫 TiDB -> TiCDC -> Canal Binlog Kafka -> ETL(填充數(shù)據(jù))-> Kafka -> Routine Load -> Palo
上線后
?1、僅需要 10min 的配置,數(shù)據(jù)集成包含模型,數(shù)據(jù)導(dǎo)入及中間 ETL 的轉(zhuǎn)化和額外數(shù)據(jù)補充以及 Routine Load 全部建好。業(yè)務(wù)層無需感知數(shù)據(jù)中間鏈路,僅需要描述我期望那個表被同步。
?2、上線后無需業(yè)務(wù)關(guān)心,完成第一步配置后,后續(xù)的監(jiān)控和報警以及一致性,集成全面解決。
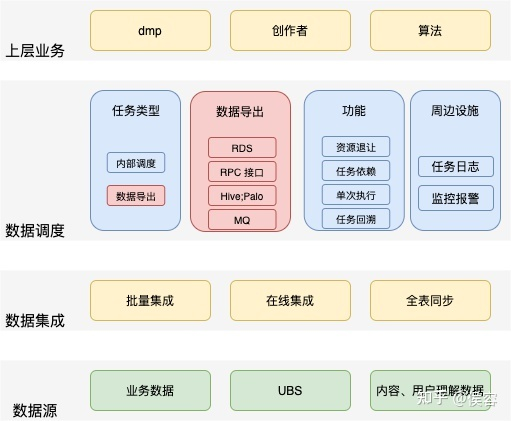
3.4.2 數(shù)據(jù)調(diào)度
?2、Palo 資源有限,但很多任務(wù)都是某些整點整分鐘的,一次性大量的計算任務(wù)造成集群崩潰;
?3、任務(wù)是否執(zhí)行成功,任務(wù)是否延遲,是否影響到業(yè)務(wù),無報警無反饋;
?4、導(dǎo)出存儲過程通用,重復(fù)代碼開發(fā),每次都需要 0.5 - 1 人天的時間開發(fā)寫入和業(yè)務(wù)接口。
解決方案
架構(gòu)圖
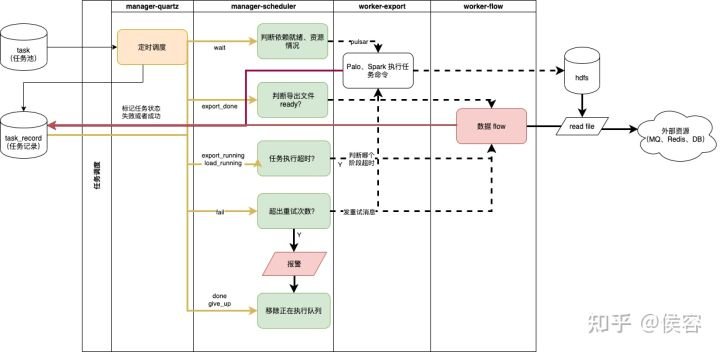
同步任務(wù)
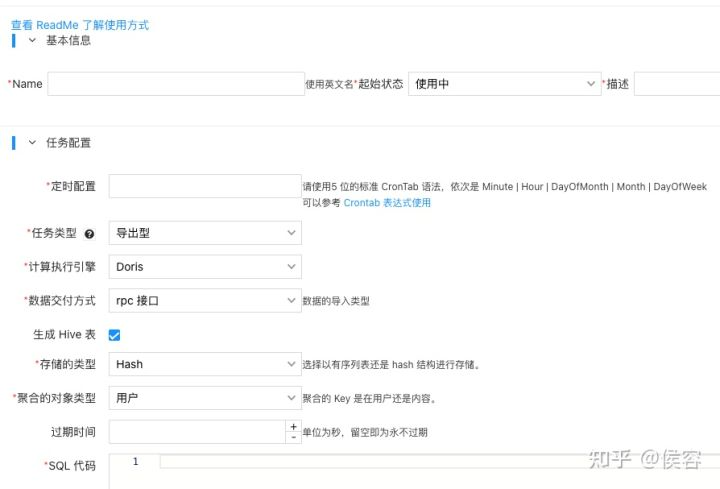
?2、通過退讓策略,監(jiān)控當(dāng)前 Palo 指標(biāo),在高負(fù)載情況下避免提交 SQL。避峰趨谷,完成資源最大利用。后續(xù)通過這種方案,一定程度的避免了瞬時跑高整體集群的問題。
?3、全鏈路監(jiān)控任務(wù)執(zhí)行情況,和延遲情況,一旦延遲報警,及時溝通解決和恢復(fù)業(yè)務(wù)。一旦任務(wù)延遲,監(jiān)控可非常快速的發(fā)現(xiàn)相關(guān)問題,多數(shù)情況能在業(yè)務(wù)可接受范圍內(nèi)完成恢復(fù)。
?4、上線后,原先需要 1 天的工程能力開發(fā)時間降低至 0。只需要在 Palo 中有一個可查詢的 SQL,經(jīng)過簡單配置即可完成一定時間交付給業(yè)務(wù)相關(guān)數(shù)據(jù)、排行榜的需求。
3.4.3 數(shù)據(jù)質(zhì)量
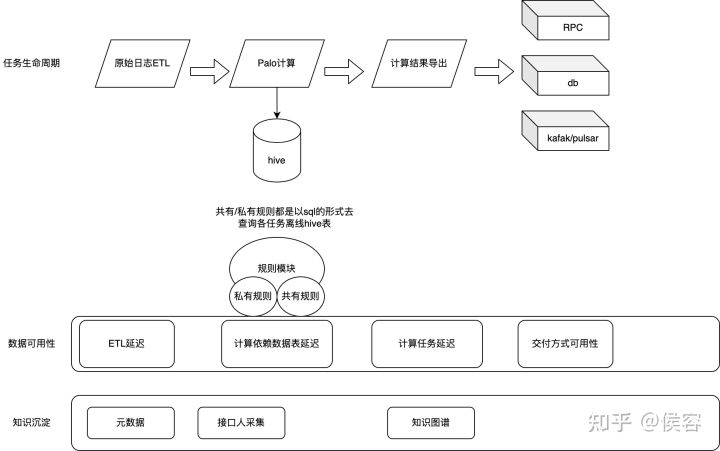
數(shù)據(jù),已經(jīng)成為互聯(lián)網(wǎng)企業(yè)非常依賴的重要資產(chǎn)。數(shù)據(jù)質(zhì)量的好壞直接關(guān)系到信息的精準(zhǔn)度,也影響到企業(yè)的生存和競爭力。Michael Hammer(《Reengineering the Corporation》一書的作者)曾說過,看起來不起眼的數(shù)據(jù)質(zhì)量問題,實際上是拆散業(yè)務(wù)流程的重要標(biāo)志。數(shù)據(jù)質(zhì)量管理是測度、提高和驗證質(zhì)量,以及整合組織數(shù)據(jù)的方法等一套處理準(zhǔn)則,而體量大、速度快和多樣性的特點,決定了大數(shù)據(jù)質(zhì)量所需的處理,有別于傳統(tǒng)信息治理計劃的質(zhì)量管理方式。
AI平臺、增長團隊、內(nèi)容平臺等已經(jīng)將部分或全部業(yè)務(wù)漸漸遷移到實時計算平臺,在接入數(shù)據(jù)更實時,更迅速的接入帶來的所享受的收益外,數(shù)據(jù)質(zhì)量更加變得重要。
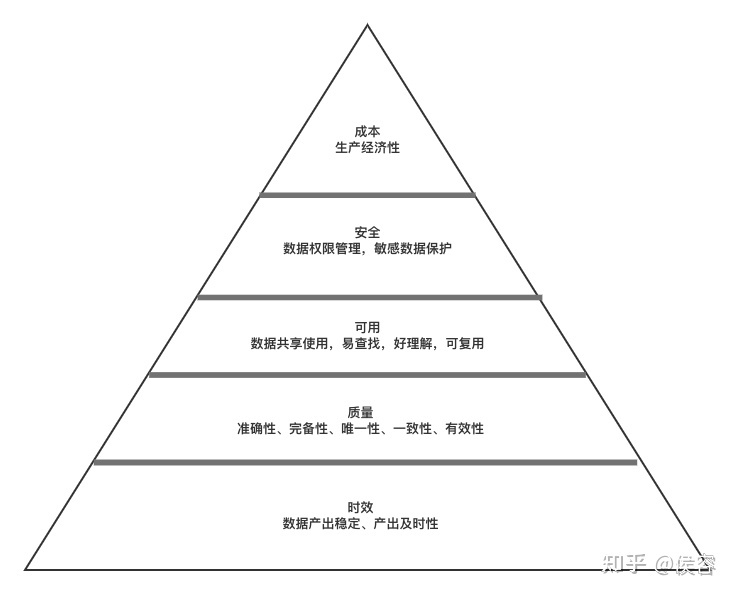
一致性: 多源數(shù)據(jù)的數(shù)據(jù)模型不一致,例如:命名不一致、數(shù)據(jù)結(jié)構(gòu)不一致、約束規(guī)則不一致。數(shù)據(jù)實體不一致,例如:數(shù)據(jù)編碼不一致、命名及含義不一致、分類層次不一致、生命周期不一致……相同的數(shù)據(jù)有多個副本的情況下的數(shù)據(jù)不一致、數(shù)據(jù)內(nèi)容沖突的問題;
準(zhǔn)確性: 準(zhǔn)確性也叫可靠性,是用于分析和識別哪些是不準(zhǔn)確的或無效的數(shù)據(jù),不可靠的數(shù)據(jù)可能會導(dǎo)致嚴(yán)重的問題,會造成有缺陷的方法和糟糕的決策;
唯一性: 用于識別和度量重復(fù)數(shù)據(jù)、冗余數(shù)據(jù)。重復(fù)數(shù)據(jù)是導(dǎo)致業(yè)務(wù)無法協(xié)同、流程無法追溯的重要因素,也是數(shù)據(jù)治理需要解決的最基本的數(shù)據(jù)問題;
關(guān)聯(lián)性: 數(shù)據(jù)關(guān)聯(lián)性問題是指存在數(shù)據(jù)關(guān)聯(lián)的數(shù)據(jù)關(guān)系缺失或錯誤,例如:函數(shù)關(guān)系、相關(guān)系數(shù)、主外鍵關(guān)系、索引關(guān)系等。存在數(shù)據(jù)關(guān)聯(lián)性問題,會直接影響數(shù)據(jù)分析的結(jié)果,進而影響管理決策;
真實性: 數(shù)據(jù)必須真實準(zhǔn)確的反映客觀的實體存在或真實的業(yè)務(wù),真實可靠的原始統(tǒng)計數(shù)據(jù)是企業(yè)統(tǒng)計工作的靈魂,是一切管理工作的基礎(chǔ),是經(jīng)營者進行正確經(jīng)營決策必不可少的第一手資料;
及時性: 數(shù)據(jù)的及時性是指能否在需要的時候獲到數(shù)據(jù),數(shù)據(jù)的及時性與企業(yè)的數(shù)據(jù)處理速度及效率有直接的關(guān)系,是影響業(yè)務(wù)處理和管理效率的關(guān)鍵指標(biāo)。
解決方案
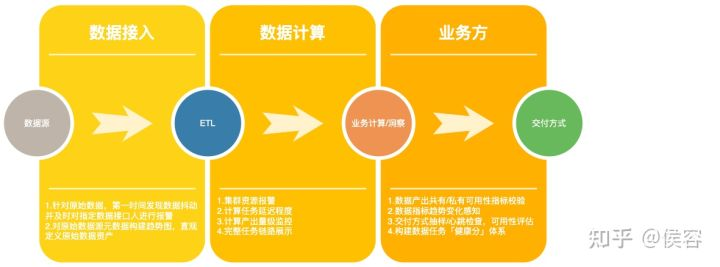
全流程的數(shù)據(jù)鏈路和各級質(zhì)量保證方法
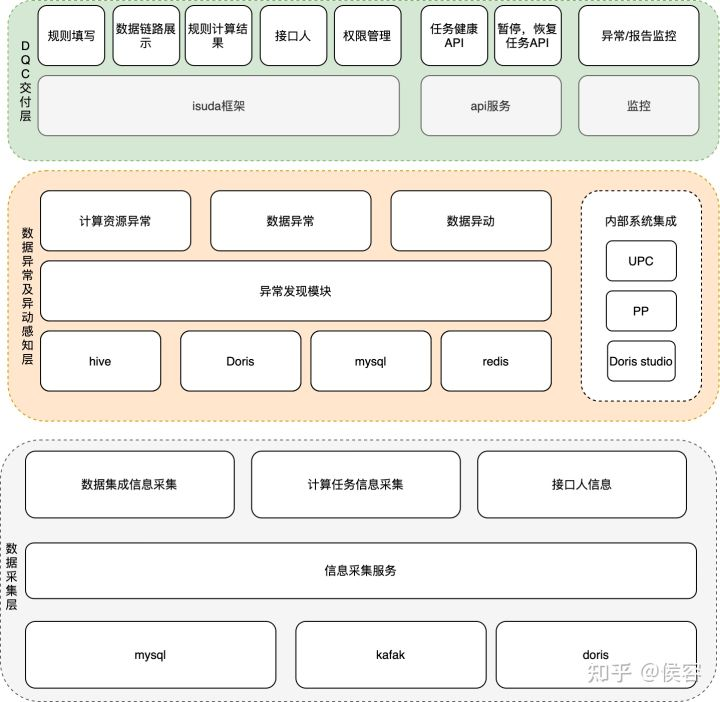
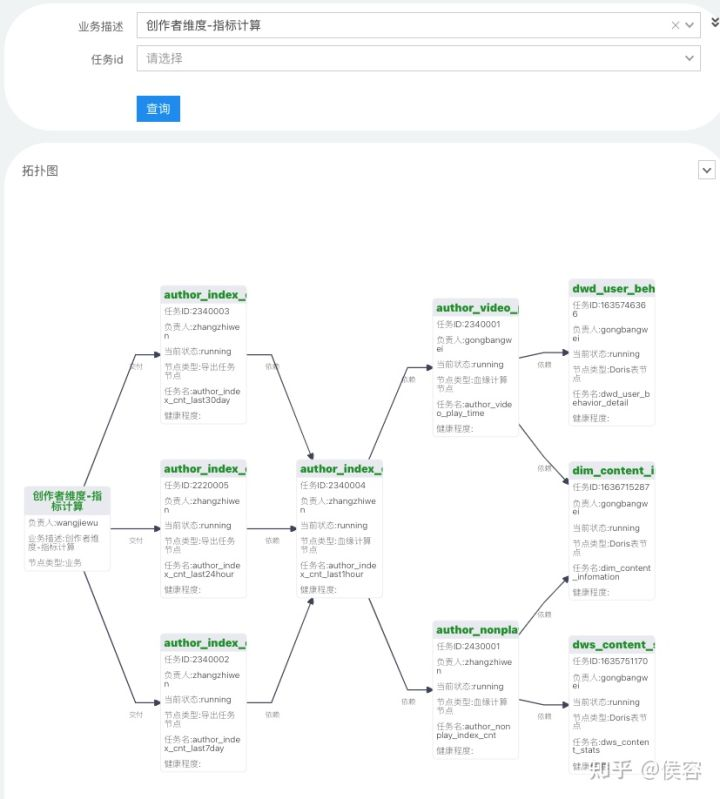
某業(yè)務(wù)健康情況監(jiān)控
以通過 DQC 監(jiān)控的某一個業(yè)務(wù)的健康情況,該業(yè)務(wù)由多個導(dǎo)出任務(wù)和中間計算任務(wù)及部分?jǐn)?shù)據(jù)源組成,當(dāng)前情況是一切正常。期間如果出現(xiàn)某節(jié)點任意異常后,都可及時發(fā)現(xiàn)。

上線前
?1、早期無類似 DQC 系統(tǒng)保證的前提下,我們很多問題都是天級別甚至上線后,才發(fā)現(xiàn)存在數(shù)據(jù)異常,出現(xiàn)過 3 次問題,造成的返工和交付不靠譜的情況,對業(yè)務(wù)影響巨大。
?2、早期開發(fā)中,在開發(fā)過程需要不斷針對各種細節(jié)規(guī)則進行比對,總會花費一定時間逐層校驗,成本巨大。
上線后
?1、在上線 1 個月內(nèi),通過 DQC 系統(tǒng)規(guī)則,當(dāng)前已發(fā)現(xiàn)了 14 個錯異常,在 1 - 2h 左右發(fā)現(xiàn),立即修復(fù)。對業(yè)務(wù)的影響降低到最小。
?2、在系統(tǒng)上線后,在開發(fā)過程中,開發(fā)完相關(guān)數(shù)據(jù),如有異常,就產(chǎn)生了異常報警,大幅節(jié)省了人工發(fā)現(xiàn)的成本,因為修復(fù)時間早,在后續(xù)開發(fā)啟動前,就已經(jīng)修復(fù),極大程度降低開發(fā)過程中的返工成本。
四、總結(jié)與展望
4.1 收益總結(jié)
4.1.1 業(yè)務(wù)發(fā)展方面
??1.1、提供了基于時效性的熱點、潛力的把控。加速業(yè)務(wù)在生產(chǎn)、消費方面的使用,進而提升優(yōu)質(zhì)創(chuàng)作量及用戶對內(nèi)容消費能力。
??1.2、同時提供了提供實時的復(fù)雜計算的外顯指標(biāo),加強用戶體驗,下線了業(yè)務(wù)后端通過腳本計算指標(biāo)的方法,降低了業(yè)務(wù)的復(fù)雜性,節(jié)約了成本,提升人效。
?2、針對實時算法特征
??2.1、提供了基于創(chuàng)作者、內(nèi)容、消費者的實時算法特征,與算法團隊共同在多個項目中,針對 DAU、留存、用戶付費等核心指標(biāo)有了明顯的提升。
?3、針對用戶畫像
??3.1、完善和升級用戶篩選,做到多維、多類型的定向篩選,并接入了運營平臺、營銷平臺等系統(tǒng),提高了業(yè)務(wù)效率,降低了業(yè)務(wù)人員進行人群定向的成本。
??3.2、搭建和完善用戶分析,做到多角度用戶分析,定向用戶分析報告 0 成本,助力業(yè)務(wù)部門快速把握核心客戶市場。
4.1.2 工具建設(shè)方面
?2、搭建了集成、調(diào)度、質(zhì)量系統(tǒng)。通過工具的方式降低了業(yè)務(wù)發(fā)展和迭代的成本,讓業(yè)務(wù)快速發(fā)展,同時也保證了交付質(zhì)量提高了業(yè)務(wù)基線。
4.1.3 人員組織方面
搭建并完善了多層次團隊人員梯隊。根據(jù)針對不同方向的同學(xué),給予不同的 OKR 目標(biāo),做到跨層次方向隔離,同層次方向一致,同模塊目標(biāo)一致。共同為整體實時數(shù)據(jù)與用戶畫像服務(wù)建設(shè)而努力。
4.2 未來展望
?1、基于實時數(shù)據(jù)
??1.1、強化基礎(chǔ)能力工具層的建設(shè),持續(xù)降低基于實時數(shù)據(jù)方面的建設(shè)、交付成本。
??1.2、提升數(shù)據(jù)質(zhì)量工具覆蓋能力,為業(yè)務(wù)模型提供質(zhì)量保障,并提供基于實時數(shù)據(jù)的畫像質(zhì)量保障能力。
??1.3、基于當(dāng)前業(yè)務(wù)訴求,部分場景針對 5 分鐘級實時無法滿足,進一步探索秒級別復(fù)雜情況實時能力,并提供能力支持。
?2、基于用戶畫像
??2.1、加強并針對用戶畫像、用戶理解、用戶洞察 & 模型等進一步建設(shè)。通過與具體業(yè)務(wù)結(jié)合,建設(shè)貼合業(yè)務(wù)場景的用戶理解成果和相應(yīng)的分析能力,找到業(yè)務(wù)的留存點。
??2.2、進一步加強新的工具能力的建設(shè),通過建設(shè)用戶理解工具、用戶分析工具,降低產(chǎn)生理解及對業(yè)務(wù)分析的成本,提升業(yè)務(wù)效率,快速發(fā)現(xiàn)業(yè)務(wù)價值。
鏈接:
https://zhuanlan.zhihu.com/p/444879814?hmsr=joyk.com&utm_source=joyk.com&utm_medium=referral
推薦閱讀:
不是你需要中臺,而是一名合格的架構(gòu)師(附各大廠中臺建設(shè)PPT)
論數(shù)字化轉(zhuǎn)型——轉(zhuǎn)什么,如何轉(zhuǎn)?
企業(yè)10大管理流程圖,數(shù)字化轉(zhuǎn)型從業(yè)者必備!
評論
圖片
表情