本文轉(zhuǎn)載自機(jī)器之心 編輯:杜偉、陳萍
在本文中,來自曠視的研究者提出高性能檢測器 YOLOX,并對(duì) YOLO 系列進(jìn)行了經(jīng)驗(yàn)性改進(jìn),將 Anchor-free、數(shù)據(jù)增強(qiáng)等目標(biāo)檢測領(lǐng)域先進(jìn)技術(shù)引入 YOLO。獲得了超越 YOLOv3、YOLOv4 和 YOLOv5 的 AP,而且取得了極具競爭力的推理速度。
隨著目標(biāo)檢測技術(shù)的發(fā)展,YOLO 系列始終追尋可以實(shí)時(shí)應(yīng)用的最佳速度和準(zhǔn)確率權(quán)衡。學(xué)界人士不斷提取當(dāng)時(shí)最先進(jìn)的檢測技術(shù)(如 YOLOv2 的 anchor、YOLOv3 的殘差網(wǎng)絡(luò)),并對(duì)這些檢測技術(shù)進(jìn)行優(yōu)化以實(shí)現(xiàn)最佳性能。目前,YOLOv5 在速度和準(zhǔn)確率上有最好的權(quán)衡,在 COCO 數(shù)據(jù)集上以 13.7ms 的速度獲得 48.2% AP。
然而,過去兩年時(shí)間里,目標(biāo)檢測領(lǐng)域的主要進(jìn)展集中在無錨點(diǎn)(anchor-free)檢測器、先進(jìn)的標(biāo)簽分配策略以及端到端的(NMS-free)檢測器。但是,這些技術(shù)還沒有集成到 YOLO 系列模型中,YOLOv4 、 YOLOv5 仍然還是基于 anchor 的檢測器,使用手工分配策略進(jìn)行訓(xùn)練。近日,曠視的研究者將解耦頭、數(shù)據(jù)增強(qiáng)、無錨點(diǎn)以及標(biāo)簽分類等目標(biāo)檢測領(lǐng)域的優(yōu)秀進(jìn)展與 YOLO 進(jìn)行了巧妙地集成組合,提出了 YOLOX,不僅實(shí)現(xiàn)了超越 YOLOv3、YOLOv4 和 YOLOv5 的 AP,而且取得了極具競爭力的推理速度。
考慮到 YOLOv4、YOLOv5 在基于 anchor pipeline 中可能會(huì)出現(xiàn)一些過擬合,研究者選擇 YOLOv3 作為起點(diǎn)(將 YOLOv3-SPP 設(shè)置為默認(rèn)的 YOLOv3)。事實(shí)上,由于計(jì)算資源有限,以及在實(shí)際應(yīng)用中軟件支持不足,YOLOv3 仍然是業(yè)界應(yīng)用最廣泛的檢測器之一。如下圖 1 所示,通過將目標(biāo)檢測領(lǐng)域優(yōu)秀進(jìn)展與 YOLO 進(jìn)行組合,研究者在圖像分辨率為 640 × 640 的 COCO 數(shù)據(jù)集上將 YOLOv3 提升到 47.3% AP(YOLOX-DarkNet53),大大超過了目前 YOLOv3(44.3% AP,ultralytics version2)的最佳實(shí)踐。此外,當(dāng)將網(wǎng)絡(luò)切換到先進(jìn)的 YOLOv5 架構(gòu),該架構(gòu)采用先進(jìn)的 CSPNet 骨干以及一個(gè)額外的 PAN 頭,YOLOX-L 在 COCO 數(shù)據(jù)集、圖像分辨率為 640 × 640 獲得 50.0% AP,比 YOLOv5-L 高出 1.8% AP。研究者還在小尺寸上測試所設(shè)計(jì)的策略,YOLOX-Tiny 和 YOLOX-Nano(僅 0.91M 參數(shù)和 1.08G FLOPs)分別比對(duì)應(yīng)的 YOLOv4-Tiny 和 NanoDet3 高出 10% AP 和 1.8% AP。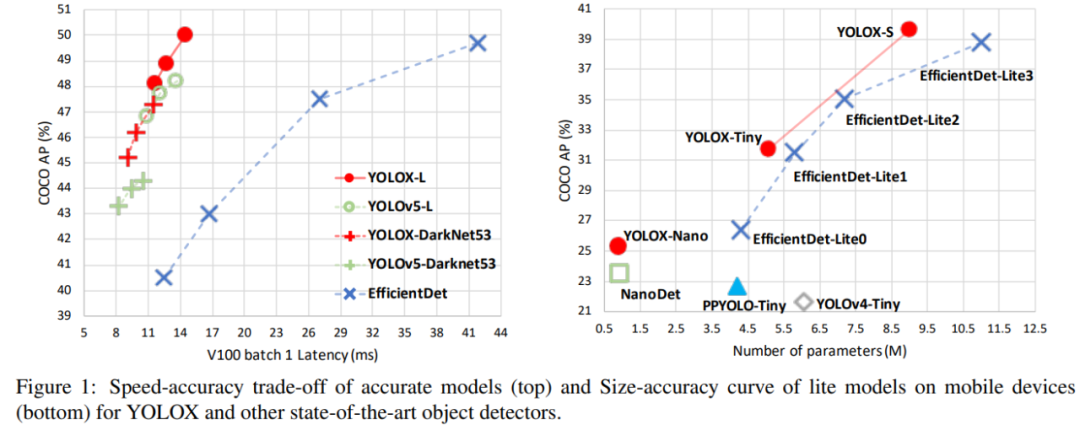
在 CVPR 2021 WAD 挑戰(zhàn)賽的 Streaming Perception Challenge 賽道上,曠視提出的基于 YOLOX 模型(YOLOX-L)的 2D 實(shí)時(shí)目標(biāo)檢測系統(tǒng)在 Argoverse-HD 數(shù)據(jù)集上實(shí)現(xiàn)了 41.1 的 streaming AP。此外,研究者在推理時(shí)用到了 TensorRT 優(yōu)化器,使得模型在高分辨輸入(即 1440×2304)時(shí)實(shí)現(xiàn)了 30 fps 的推理速度。
圖源:https://eval.ai/web/challenges/challenge-page/800/overview
研究者選擇將 YOLOv3+Darknet53 作為基線模型,并基于它詳細(xì)介紹了 YOLOX 的整個(gè)系統(tǒng)設(shè)計(jì)。從基線模型到最終模型,研究者的訓(xùn)練設(shè)置基本保持一致。他們在 COCO train2017 數(shù)據(jù)集上訓(xùn)練了 300 個(gè) epoch 的模型并進(jìn)行 5 個(gè) epoch 的 warmup,使用隨機(jī)梯度下降(SGD)來訓(xùn)練,學(xué)習(xí)率為 lr×BatchSize/64 ,初始學(xué)習(xí)率為 0.01,并使用了余弦(cosine)學(xué)習(xí)機(jī)制。權(quán)重衰減為 0.0005,SGD momentum 為 0.9。批大小默認(rèn)為 128(8 個(gè) GPU),其他批大小使用單個(gè) GPU 訓(xùn)練也運(yùn)行良好。輸入大小以 32 步長從 448 均勻過渡到 832。FPS 和延遲在單個(gè) Tesla V100 上使用 FP16-precision 和 batch=1 進(jìn)行測量。基線采用了 DarkNet53 骨干和 SPP 層的架構(gòu)(在一些論文中被稱作 YOLOv3-SPP)。與初始實(shí)現(xiàn)相比,研究者稍微改變了一些訓(xùn)練策略,添加了 EMA 權(quán)重更新、余弦學(xué)習(xí)機(jī)制、IoU 損失和 IoU 感知分支。他們使用 BCE 損失訓(xùn)練 cls 和 obj 分支,使用 IoU 損失訓(xùn)練 reg 分支。這些通用的訓(xùn)練技巧對(duì)于 YOLOX 的關(guān)鍵改進(jìn)呈正交,因此將它們應(yīng)用于基線上。此外,研究者還添加了 RandomHorizontalFlip、ColorJitter 和多尺度數(shù)據(jù)增強(qiáng),移除了 RandomResizedCrop 策略。通過這些增強(qiáng)技巧,YOLOv3 基線模型在 COCO val 數(shù)據(jù)集上實(shí)現(xiàn)了 38.5% 的 AP,具體如下表 2 所示: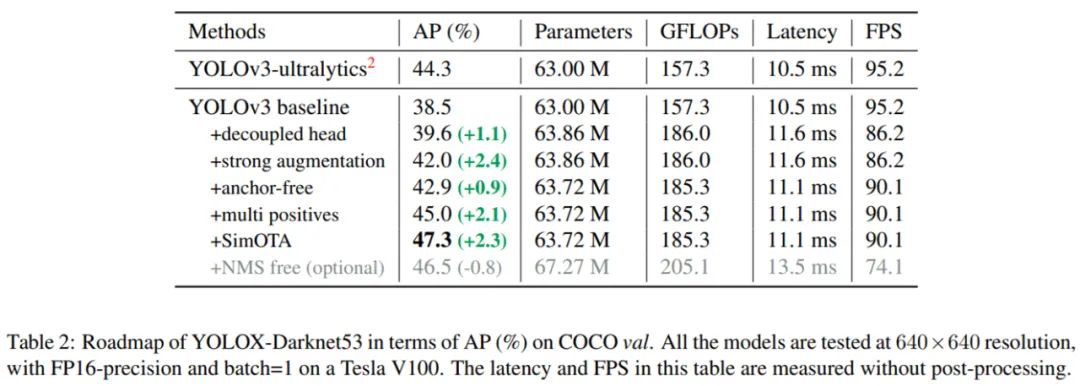
在目標(biāo)檢測中,分類與回歸任務(wù)之間的沖突是一個(gè)眾所周知的難題,因此用于分類和定位的解耦頭被廣泛用于大多數(shù)單階段和雙階段檢測器中。但是,隨著 YOLO 系列模型骨干和特征金字塔(如 FPN 和 PAN)持續(xù)進(jìn)化,它們的檢測頭依然處于耦合狀態(tài),YOLOv3 頭與本文提出的解耦頭之間的架構(gòu)差異如下圖 2 所示:
下圖 3 為使用 YOLOv3 頭和解耦頭時(shí)的檢測器訓(xùn)練曲線: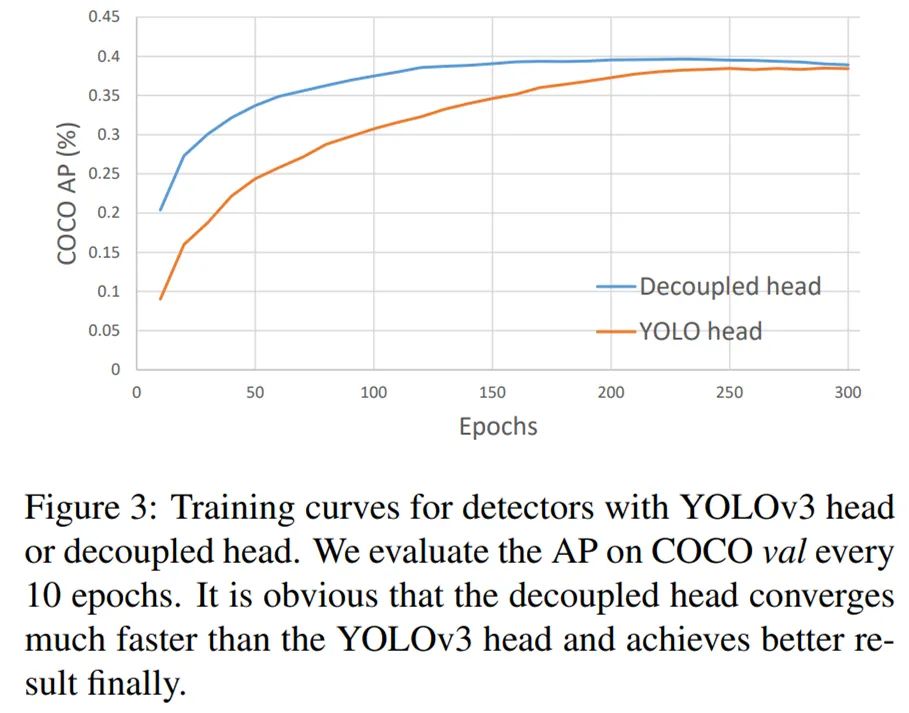
從下表 1 可以看到,使用耦合頭時(shí)端到端性能降低了 4.2% 的 AP,而使用解耦頭時(shí)僅僅降低了 0.8% AP。因此,研究者將 YOLO 檢測頭替換為一個(gè)輕量(lite)解耦頭,由此極大地提升了收斂速度。
具體地,這個(gè)輕量解耦頭包含一個(gè) 1 × 1 卷積層以減少通道維度,之后緊接著兩個(gè) 3 × 3 卷積層的并行分支,具體架構(gòu)參見上圖 2。研究者給出了在單個(gè) Tesla V100 上,使用 batch=1 時(shí)的推理時(shí)間。如上表 2 所示,輕量解耦頭可以帶來 1.1 ms 的推理延時(shí)。強(qiáng)(strong)數(shù)據(jù)增強(qiáng)策略研究者在增強(qiáng)策略中加入了 Mosaic 和 MixUp 以提升 YOLOX 的性能,他們在模型中采用 MixUp 和 Mosaic 實(shí)現(xiàn),并在最后 15 個(gè) epoch 的訓(xùn)練中關(guān)閉。如上表 2 所示,基線模型實(shí)現(xiàn)了 42.0% 的 AP。在使用強(qiáng)數(shù)據(jù)增強(qiáng)策略之后,研究者發(fā)現(xiàn) ImageNet 預(yù)訓(xùn)練不再具有更多增益,因此所有模型都從頭開始訓(xùn)練。YOLOv4 和 YOLOv5 都遵循 YOLOv3 的基于錨的初始 pipeline,然而錨機(jī)制存在許多已知的問題。過去兩年,無錨檢測器發(fā)展迅速。相關(guān)研究表明,無錨檢測器的性能可以媲美基于錨的檢測器。無錨點(diǎn)機(jī)制顯著減少了實(shí)現(xiàn)良好性能所需的啟發(fā)式調(diào)整和技巧(如 Anchor Clustering、Grid Sensitive)的設(shè)計(jì)參數(shù)數(shù)量,從而使得檢測器變得更簡單,尤其是在訓(xùn)練和解碼階段。將 YOLO 轉(zhuǎn)變?yōu)闊o錨點(diǎn)模式也非常簡單。研究者將每個(gè)位置的預(yù)測從 3 降至 1,并使它們直接預(yù)測四個(gè)值,即兩個(gè) offset 以及預(yù)測框的高寬值。他們將每個(gè)目標(biāo)的中心位置指令為正樣本,并預(yù)定義一個(gè)尺度范圍,以確定每個(gè)目標(biāo)的 FPN 水平。這種改進(jìn)減少了檢測器的參數(shù)量和 GFLOP,并使其速度更快,與此同時(shí)獲得了更好的性能,即 42.9% AP(具體如上表 2 所示)。為了確保與 YOLOv3 的分配規(guī)則一致,上述無錨點(diǎn)版本僅為每個(gè)目標(biāo)分配一個(gè)正樣本(中心位置),同時(shí)忽略了其他高質(zhì)量的預(yù)測。研究者將中心 3×3 區(qū)域分配為正樣本,并命名為「中心采樣」。如上表 2 示,檢測器的性能提升至 45.0% AP,已經(jīng)超越了當(dāng)前 SOTA ultralytics/yolov3 版本的 44.3%AP。先進(jìn)標(biāo)簽分配(Advanced label assignment )是近年來目標(biāo)檢測領(lǐng)域中另一個(gè)重要進(jìn)展。該研究將其作為候選標(biāo)簽分配策略。但是在實(shí)踐中,該研究發(fā)現(xiàn)通過 Sinkhorn-Knopp 算法解決 OT 問題會(huì)帶來 25% 額外訓(xùn)練時(shí)間,這對(duì)于 300 epoch 來說代價(jià)非常高。因此,該研究將其簡化為動(dòng)態(tài) top-k 策略,命名為 SimOTA,以獲得近似解。SimOTA 不僅減少了訓(xùn)練時(shí)間,同時(shí)避免了 SinkhornKnopp 算法中額外超參數(shù)問題。如表 2 所示,SimOTA 將檢測器的 AP 從 45.0% 提高到 47.3%,比 SOTA ultralytics-YOLOv3 高出 3.0%。該研究參考 PSS 添加了兩個(gè)額外的卷基層、一對(duì)一的標(biāo)簽分配、stop gradient。這些使得檢測器能夠以端到端方式執(zhí)行,但會(huì)略微降低性能和推理速度,如表 2 所示。該研究將其作為一個(gè)可選模塊,但在最終的模型中并沒有涉及。在其他骨干網(wǎng)絡(luò)的實(shí)驗(yàn)結(jié)果除了 DarkNet53,該研究還在其他不同大小的骨干上測試了 YOLOX,結(jié)果表明 YOLOX 都實(shí)現(xiàn)了性能提升。為了公平的進(jìn)行比較,該研究采用 YOLOv5 骨干,包括改進(jìn)的 CSPNet、SiLU 激活函數(shù)、PAN 頭。此外,該研究還遵循擴(kuò)展規(guī)則來生成 YOLOXS、YOLOX-M、 YOLOX-L、YOLOX-X 模型。與 YOLOv5 在表 3 的結(jié)果相比,該模型在僅需非常少的額外推理耗時(shí),取得了 3.0%~1.0% 的性能提升。
該研究進(jìn)一步將模型縮小為 YOLOX-Tiny,并與 YOLOv4-Tiny 進(jìn)行比較。對(duì)于移動(dòng)端設(shè)備,研究者采用深度卷積構(gòu)建 YOLOX-Nano 模型,模型僅有 0.91M 參數(shù)量以及 1.08G FLOP。如表 4 所示,YOLOX 在更小的模型尺寸下表現(xiàn)良好。
模型大小與數(shù)據(jù)增強(qiáng)在實(shí)驗(yàn)中,所有模型都保持了幾乎相同的學(xué)習(xí)進(jìn)度和優(yōu)化參數(shù)。然而,研究發(fā)現(xiàn)適當(dāng)?shù)臄?shù)據(jù)增強(qiáng)策略因模型大小而異。如表 5 所示,YOLOX-L 采用 MixUp 能提高 0.9%AP,對(duì)于諸如 YOLOX-Nano 這種小型模型來說,最好是弱化增強(qiáng)。具體來說,當(dāng)訓(xùn)練諸如 YOLOX-S、 YOLOX-Tiny、YOLOX-Nano 這種小模型時(shí),需要去除混合增強(qiáng)并弱化 mosaic(將擴(kuò)展范圍從 [0.1, 2.0] 降到 [0.5, 1.5])。這種改進(jìn)將 YOLOX-Nano 的 AP 從 24.0% 提高到 25.3%。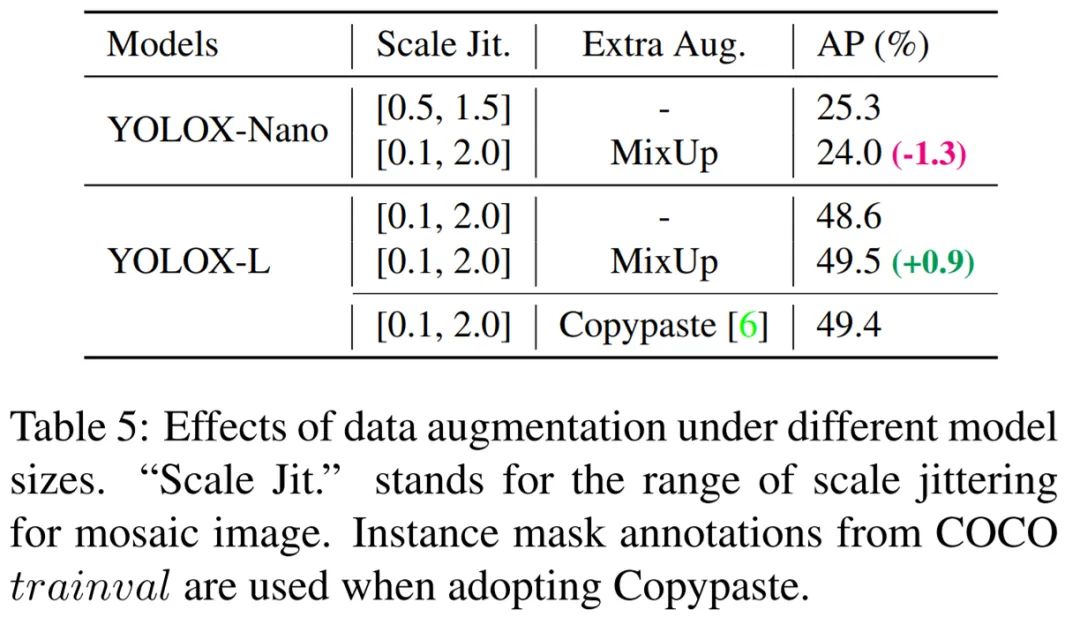
下表 6 為 YOLOX 與 SOTA 檢測器的對(duì)比結(jié)果。在 COCO 2017 test-dev 數(shù)據(jù)集上進(jìn)行了不同物體檢測器的速度和準(zhǔn)確率比較。研究者選擇在 300 epoch 上訓(xùn)練所有模型并進(jìn)行了公平比較。由結(jié)果可得,與 YOLOv3、YOLOv4、YOLOv5 系列進(jìn)行比較,該研究所提出的 YOLOX 取得了最佳性能,獲得 51.2%AP,高于其他模型,同時(shí)具有極具競爭力的推理速度。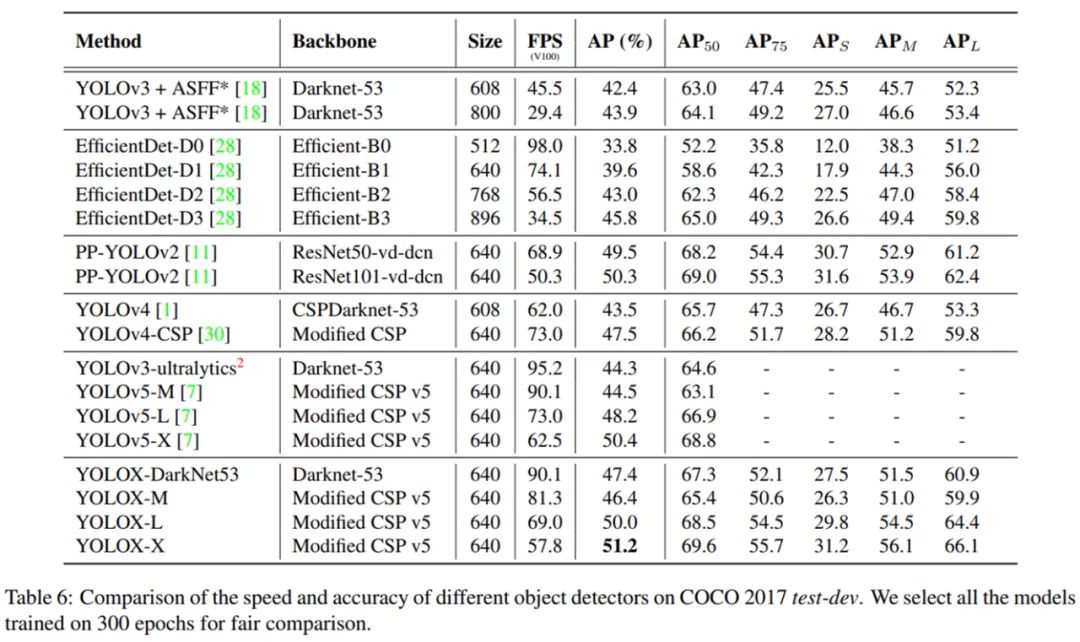
猜您喜歡:
等你著陸!【GAN生成對(duì)抗網(wǎng)絡(luò)】知識(shí)星球!
CVPR 2021 | GAN的說話人驅(qū)動(dòng)、3D人臉論文匯總
CVPR 2021 | 圖像轉(zhuǎn)換 今如何?幾篇GAN論文
【CVPR 2021】通過GAN提升人臉識(shí)別的遺留難題
CVPR 2021生成對(duì)抗網(wǎng)絡(luò)GAN部分論文匯總
經(jīng)典GAN不得不讀:StyleGAN
最新最全20篇!基于 StyleGAN 改進(jìn)或應(yīng)用相關(guān)論文
超100篇!CVPR 2020最全GAN論文梳理匯總!
附下載 | 《Python進(jìn)階》中文版
附下載 | 經(jīng)典《Think Python》中文版
附下載 | 《Pytorch模型訓(xùn)練實(shí)用教程》
附下載 | 最新2020李沐《動(dòng)手學(xué)深度學(xué)習(xí)》
附下載 | 《可解釋的機(jī)器學(xué)習(xí)》中文版
附下載 |《TensorFlow 2.0 深度學(xué)習(xí)算法實(shí)戰(zhàn)》
附下載 | 超100篇!CVPR 2020最全GAN論文梳理匯總!
附下載 |《計(jì)算機(jī)視覺中的數(shù)學(xué)方法》分享
