
線程池如何監(jiān)控,才能幫助開發(fā)者快速定位線上錯(cuò)誤?
大部分情況下,線程池的運(yùn)行情況對(duì)于使用者來說是個(gè)黑盒
運(yùn)行情況不可知,會(huì)導(dǎo)致 生產(chǎn)出現(xiàn)事故問題排查困難,以及線程池參數(shù)難以定義
文章圍繞線程池監(jiān)控展開,討論 線程池如何監(jiān)控、監(jiān)控的指標(biāo)以及監(jiān)控?cái)?shù)據(jù)的存儲(chǔ)展示
01
如何監(jiān)控運(yùn)行數(shù)據(jù)
設(shè)想一下,如果想監(jiān)控線程池的運(yùn)行數(shù)據(jù),你會(huì)怎么操作?這里提供兩種常規(guī)思路
線程池運(yùn)行時(shí)埋點(diǎn),每一次運(yùn)行任務(wù)都進(jìn)行統(tǒng)計(jì) 定時(shí)獲取線程池的運(yùn)行數(shù)據(jù)
這里我推薦第二種,因?yàn)榫€程池的監(jiān)控 API 會(huì)通過 獲取主鎖來控制結(jié)果的相對(duì)準(zhǔn)確性,性能相對(duì)較差,后面會(huì)詳細(xì)說明
為什么叫相對(duì)準(zhǔn)確?因?yàn)槿蝿?wù)和線程的狀態(tài)在計(jì)算過程中可能會(huì)動(dòng)態(tài)變化,只能給到一個(gè)近似值,保證不了絕對(duì)準(zhǔn)確
模擬下定時(shí)采集線程池運(yùn)行時(shí)數(shù)據(jù)的代碼
private?ScheduledThreadPoolExecutor?collectVesselExecutor;
String?collectVesselTaskName?=?"client.scheduled.collect.data";
collectVesselExecutor?=?new?ScheduledThreadPoolExecutor(
????????new?Integer(1),
????????ThreadFactoryBuilder.builder().daemon(true).prefix(collectVesselTaskName).build()
);
//?延遲?initialDelay?后循環(huán)調(diào)用.?scheduleWithFixedDelay?每次執(zhí)行時(shí)間為上一次任務(wù)結(jié)束時(shí),?向后推一個(gè)時(shí)間間隔
collectVesselExecutor.scheduleWithFixedDelay(
????????()?->?runTimeGatherTask(),
????????properties.getInitialDelay(),
????????properties.getCollectInterval(),
????????TimeUnit.MILLISECONDS
);
一般線程池分為兩種方式創(chuàng)建,Spring Bean 和非 Spring Bean,假設(shè)創(chuàng)建的線程池是 Spring 管理的
我們只需要在 Spring 容器啟動(dòng)成功后,延遲一段時(shí)間后開始采集運(yùn)行數(shù)據(jù)就 OK 了
不論線程池是否由 Spring 管理,采集的方式大致相同。一種從 Spring 容器取,一種是創(chuàng)建好線程池后放到一個(gè)自定義容器
02
監(jiān)控的指標(biāo)有哪些?
說一下目前 Hippo4J 定義的線程池監(jiān)控指標(biāo),包括不限于。大家有業(yè)務(wù)中使用到的監(jiān)控指標(biāo)都可以討論下
線程池當(dāng)前負(fù)載:當(dāng)前線程數(shù) / 最大線程數(shù)線程池峰值負(fù)載:當(dāng)前線程數(shù) / 最大線程數(shù),線程池運(yùn)行期間最大的負(fù)載核心線程數(shù):線程池的核心線程數(shù)最大線程數(shù):線程池限制同時(shí)存在的線程數(shù)當(dāng)前線程數(shù):當(dāng)前線程池的線程數(shù)活躍線程數(shù):執(zhí)行任務(wù)的線程的大致數(shù)目最大出現(xiàn)線程數(shù):線程池中運(yùn)行以來同時(shí)存在的最大線程數(shù)阻塞隊(duì)列:線程池暫存任務(wù)的容器隊(duì)列容量:隊(duì)列中允許元素的最大數(shù)量隊(duì)列元素:隊(duì)列中已存放的元素?cái)?shù)量隊(duì)列剩余容量:隊(duì)列中還可以存放的元素?cái)?shù)量線程池任務(wù)完成總量:已完成執(zhí)行的任務(wù)的大致總數(shù)拒絕策略執(zhí)行次數(shù):運(yùn)行時(shí)拋出的拒絕次數(shù)總數(shù)
這些指標(biāo)可以幫助我們解決大多數(shù)因?yàn)榫€程池而導(dǎo)致的問題排查。但是,事情往往不能盡善盡美
當(dāng)前線程數(shù)、活躍線程數(shù)、最大出現(xiàn)線程數(shù)、線程池任務(wù)完成總量 的線程池 API 會(huì)先獲取到 mainLock,然后才開始計(jì)算
mainLock 是線程池的主鎖,線程執(zhí)行、線程銷毀和線程池停止等都會(huì)使用到這把鎖
final?ReentrantLock?mainLock?=?this.mainLock;
mainLock.lock();
try?{
????xxxxx
}?finally?{
????mainLock.unlock();
}
如果頻繁獲取這把鎖,會(huì)導(dǎo)致原有線程池任務(wù)執(zhí)行性能受到影響
所以,我們應(yīng)該避免頻繁獲取這幾項(xiàng)參數(shù),這也是不使用線程池任務(wù)執(zhí)行埋點(diǎn)最重要的原因
03
監(jiān)控?cái)?shù)據(jù)存儲(chǔ)
上面的線程池監(jiān)控指標(biāo)如果只能支持實(shí)時(shí)查看,并不能幫忙開發(fā)日常排查錯(cuò)誤
大部分場(chǎng)景下,生產(chǎn)上的問題發(fā)現(xiàn)會(huì)有延遲。比如 12:30 出現(xiàn)的問題,業(yè)務(wù)13:00 進(jìn)行的反饋
為了更好幫助開發(fā)排錯(cuò),我們需要將線程池的歷史運(yùn)行數(shù)據(jù)進(jìn)行存儲(chǔ)
說到線程池歷史運(yùn)行數(shù)據(jù)的存儲(chǔ),使用 時(shí)序數(shù)據(jù)庫(kù)(TSDB) 是最合適的
但大部分情況下,公司不會(huì)為了這一個(gè)需求搭建或者采購(gòu)時(shí)序數(shù)據(jù)庫(kù),那就可以使用折中方案,比如說 MySQL、ES 等
我們以 MySQL 為例,his_run_data?歷史運(yùn)行數(shù)據(jù)表,建表語(yǔ)句如下:
CREATE?TABLE?`his_run_data`?(
??`thread_pool_id`?varchar(56)?DEFAULT?NULL?COMMENT?'線程池ID',
??`instance_id`?varchar(256)?DEFAULT?NULL?COMMENT?'實(shí)例ID',
??`current_load`?bigint(20)?DEFAULT?NULL?COMMENT?'當(dāng)前負(fù)載',
??`peak_load`?bigint(20)?DEFAULT?NULL?COMMENT?'峰值負(fù)載',
??`pool_size`?bigint(20)?DEFAULT?NULL?COMMENT?'線程數(shù)',
??`active_size`?bigint(20)?DEFAULT?NULL?COMMENT?'活躍線程數(shù)',
??`queue_capacity`?bigint(20)?DEFAULT?NULL?COMMENT?'隊(duì)列容量',
??`queue_size`?bigint(20)?DEFAULT?NULL?COMMENT?'隊(duì)列元素',
??`queue_remaining_capacity`?bigint(20)?DEFAULT?NULL?COMMENT?'隊(duì)列剩余容量',
??`completed_task_count`?bigint(20)?DEFAULT?NULL?COMMENT?'已完成任務(wù)計(jì)數(shù)',
??`reject_count`?bigint(20)?DEFAULT?NULL?COMMENT?'拒絕次數(shù)',
??`timestamp`?bigint(20)?DEFAULT?NULL?COMMENT?'時(shí)間戳',
??`gmt_create`?datetime?DEFAULT?NULL?COMMENT?'創(chuàng)建時(shí)間',
??`gmt_modified`?datetime?DEFAULT?NULL?COMMENT?'修改時(shí)間',
??PRIMARY?KEY?(`id`),
??KEY?`idx_group_key`?(`tp_id`,`instance_id`)?USING?BTREE,
??KEY?`idx_timestamp`?(`timestamp`)?USING?BTREE
)?ENGINE=InnoDB?AUTO_INCREMENT=1?DEFAULT?CHARSET=utf8mb4?COMMENT='歷史運(yùn)行數(shù)據(jù)表';
可以看到,建表語(yǔ)句中有三個(gè)關(guān)鍵字段:
thread_pool_id:表示當(dāng)前數(shù)據(jù)的線程池標(biāo)識(shí)
instance_id:應(yīng)用可能集群部署,標(biāo)識(shí)集群下唯一的線程池
timestamp:記錄線程池運(yùn)行數(shù)據(jù)產(chǎn)生時(shí)的時(shí)間戳
有一個(gè)問題,線上的線程池是源源不斷產(chǎn)生運(yùn)行數(shù)據(jù)的,遲早不得把表的數(shù)據(jù)量推到上億?
因?yàn)閿?shù)據(jù)是有時(shí)效性的,過了一定時(shí)間之后,就沒有必要再占用實(shí)時(shí)的資源
針對(duì)上述問題提供兩種解決方案:
假設(shè)數(shù)據(jù)存儲(chǔ) 1 天,如果超出這個(gè)時(shí)間,直接刪除即可 同上所述,過期數(shù)據(jù)可以保留到備份表中,并刪除 his_run_data數(shù)據(jù)
可能有的小伙伴還會(huì)擔(dān)心,數(shù)據(jù)量太大會(huì)不會(huì)導(dǎo)致查詢時(shí)過慢?
我們可以算一下,假設(shè)有 100 個(gè)應(yīng)用,每個(gè)應(yīng)用部署 10 個(gè)節(jié)點(diǎn)
假設(shè)數(shù)據(jù)有效期為 1 小時(shí),那么可以產(chǎn)出的數(shù)據(jù)是 72 萬(wàn),一天也就是 1728 萬(wàn)
對(duì)于 MySQL 而言,幾千萬(wàn)數(shù)據(jù)量以下針對(duì)索引的查詢,都不會(huì)產(chǎn)生性能瓶頸
04
如何定義公共監(jiān)控?
抽象線程池存儲(chǔ)
上面說到,線程池的采集歷史運(yùn)行數(shù)據(jù)在各個(gè)應(yīng)用系統(tǒng)中,數(shù)據(jù)的存儲(chǔ)、定期刪除是否可以抽象出來,避免重復(fù)的工作
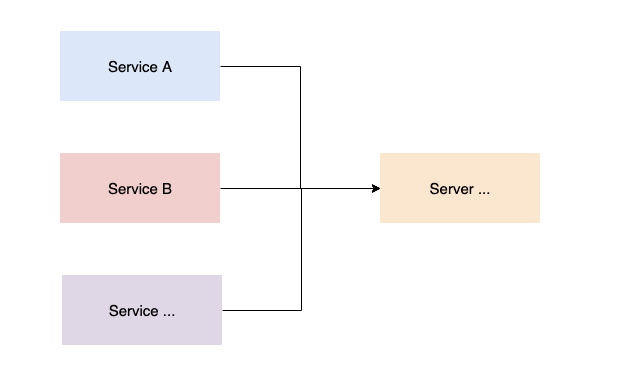
如果選擇抽象數(shù)據(jù)存儲(chǔ),客戶端節(jié)點(diǎn)與服務(wù)端之間的交互如下:
客戶端定時(shí)采集線程池歷史運(yùn)行數(shù)據(jù),將數(shù)據(jù)打包好發(fā)送服務(wù)端 服務(wù)端接收客戶端上報(bào)的數(shù)據(jù),進(jìn)行數(shù)據(jù)入庫(kù)持久化存儲(chǔ) 服務(wù)端定期刪除或存檔客戶端線程池歷史運(yùn)行數(shù)據(jù) 由服務(wù)端統(tǒng)一對(duì)外提供線程池運(yùn)行圖表的數(shù)據(jù)展示
這里有個(gè)小問題,客戶端如何打包發(fā)送給服務(wù)端?定時(shí)采集數(shù)據(jù)后直接上報(bào)是不是可行呢
不推薦采集、上報(bào)兩種行為放到一個(gè)流程中,好的設(shè)計(jì)應(yīng)該是要 分離開職責(zé);而且,如果在上報(bào)過程中網(wǎng)絡(luò)出現(xiàn)阻塞等等問題,會(huì)耽誤采集線程的下一次采集結(jié)果
我們可以使用多線程生產(chǎn)、消費(fèi)模型來做,相信大家初學(xué)多線程一定都學(xué)過這個(gè)設(shè)計(jì)
//?緩沖隊(duì)列
private?BlockingQueue?messageCollectVessel??=?new?ArrayBlockingQueue(bufferSize);
//?生產(chǎn)者
Message?message?=?collector.collectMessage();
boolean?offer?=?messageCollectVessel.offer(message);
if?(!offer)?{
????log.warn("Buffer?data?starts?stacking?data...");
}
//?消費(fèi)者
while?(true)?{
????try?{
????????Message?message?=?messageCollectVessel.take();
????????messageSender.send(message);
????}?catch?(Throwable?ex)?{
????????log.error("Consumption?buffer?container?task?failed.?Number?of?buffer?container?tasks?::?{}",?messageCollectVessel.size(),?ex);
????}
}
創(chuàng)建阻塞緩沖隊(duì)列,由定時(shí)線程池采集歷史運(yùn)行數(shù)據(jù),并放到緩沖隊(duì)列中;然后起一個(gè)線程,循環(huán)消費(fèi)即可
極端情況下緩沖隊(duì)列元素會(huì)出現(xiàn)堆積,最新采集的線程池?cái)?shù)據(jù)也就無(wú)法插入成功,為了不影響客戶端的運(yùn)行,僅做異常警告處理
使用最新抽象出來的客戶端、服務(wù)端交互流程,有以下幾個(gè)優(yōu)點(diǎn)
數(shù)據(jù)的存儲(chǔ)和查詢展示由服務(wù)端提供功能,減輕客戶端壓力和重復(fù)工作量 歷史運(yùn)行數(shù)據(jù)的刪除或備份操作由服務(wù)端統(tǒng)一執(zhí)行 不同的項(xiàng)目不需要為線程池歷史運(yùn)行數(shù)據(jù)分別創(chuàng)建表結(jié)構(gòu)存儲(chǔ) 形成交互規(guī)范,避免業(yè)務(wù)發(fā)散單獨(dú)開發(fā),中心化的設(shè)計(jì)更利于技術(shù)的迭代和管理
監(jiān)控圖表展示?
不同公司對(duì)于線程池的監(jiān)控不盡相同,出于各種考慮,會(huì)將監(jiān)控封裝成最符合自己業(yè)務(wù)場(chǎng)景的流程
Hippo4J 從最基本的指標(biāo)出發(fā),封裝出了最小代價(jià)的監(jiān)控體系,并提供可視化頁(yè)面的圖標(biāo)展示
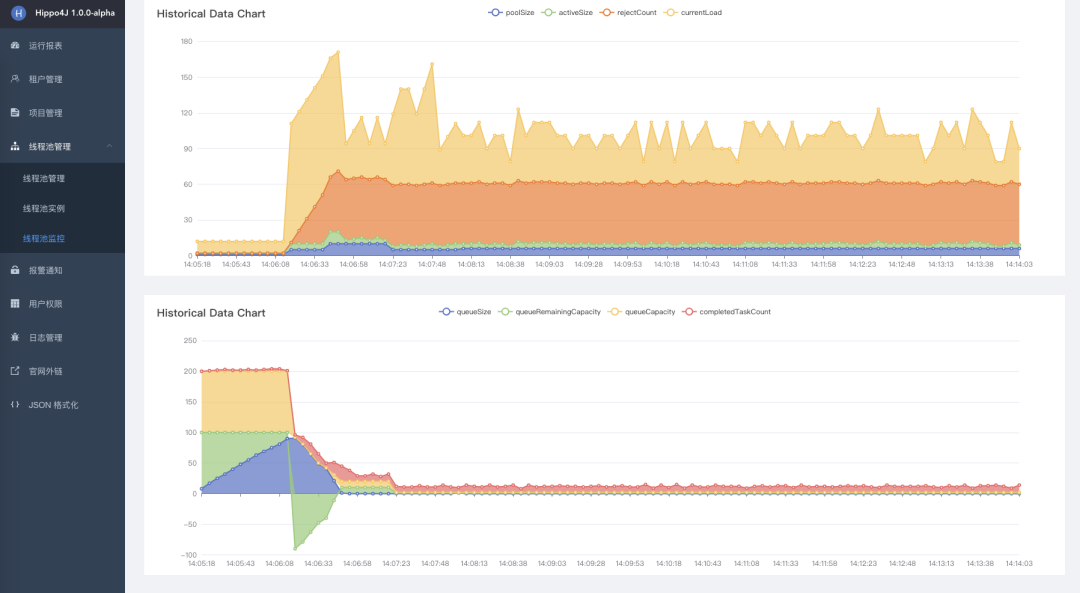
有興趣可以查看 Hippo4J 框架官網(wǎng)介紹
Site:https://www.hippox.cn
還有一個(gè)功能點(diǎn),考慮到很多公司搭建了一套監(jiān)控體系,其中以 Prometheus + Grafana 為主
后續(xù) Hippo4J 會(huì)接入 Prometheus,應(yīng)用內(nèi)部存儲(chǔ)線程池的運(yùn)行數(shù)據(jù),適配 Prometheus 采集存儲(chǔ),最終展示到 Grafana
05
總結(jié)回顧
線程池作為企業(yè)級(jí)應(yīng)用廣泛的技術(shù),對(duì)它的監(jiān)控是不可或缺的穩(wěn)定性保障之一
文章從線程池的監(jiān)控出發(fā),講解了如何監(jiān)控、監(jiān)控的指標(biāo)以及監(jiān)控?cái)?shù)據(jù)的存儲(chǔ),相信讀者們也各有收獲
看了上面的線程池監(jiān)控內(nèi)容,大家有什么想要補(bǔ)充的,在下方評(píng)論區(qū)留言
各位讀者所在的公司又是如何對(duì)線程池監(jiān)控,可以互相交流下心得
