Kafka 是MQ消息隊(duì)列作為最常用的中間件之一,其主要特性有:解耦、異步、限流/削峰。
Kafka 和傳統(tǒng)的消息系統(tǒng)(也稱作消息中間件)都具備系統(tǒng)解耦、冗余存儲(chǔ)、流量削峰、緩沖、異步通信、擴(kuò)展性、可恢復(fù)性等功能。與此同時(shí),Kafka 還提供了大多數(shù)消息系統(tǒng)難以實(shí)現(xiàn)的消息順序性保障及回溯消費(fèi)的功能。
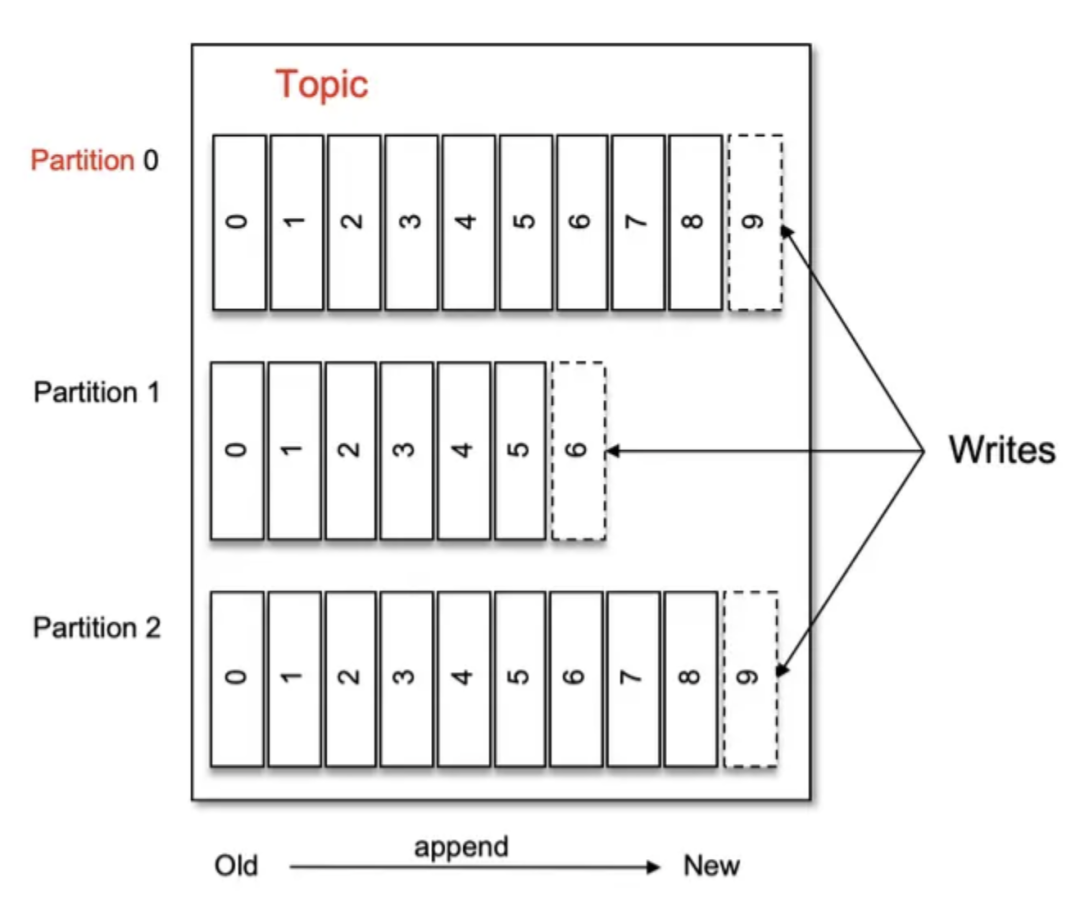
2.1 Topic與Partition
Topic(主題)是一個(gè)邏輯概念,在物理上并不存儲(chǔ)。主要用于描述一個(gè)類型的消息。例如我們有一個(gè)業(yè)務(wù)系統(tǒng)會(huì)發(fā)送一個(gè)描述用戶訂單狀態(tài)的消息,那么這一個(gè)類型里面所有的消息就是一個(gè)Topic,又比如這個(gè)業(yè)務(wù)系統(tǒng)同時(shí)還會(huì)發(fā)送描述會(huì)員余額的消息,那么這個(gè)就是一個(gè)新的消息類型,也就是一個(gè)新的Topic。
Partition(分區(qū))是一個(gè)物理概念,是實(shí)際存在于物理設(shè)備上的。一個(gè)Topic由多個(gè)Partition共同組成。Partition的存在是為了提高消息的性能與吞吐量,多個(gè)分區(qū)多個(gè)進(jìn)程消息處理速度肯定要比單分區(qū)快得多。
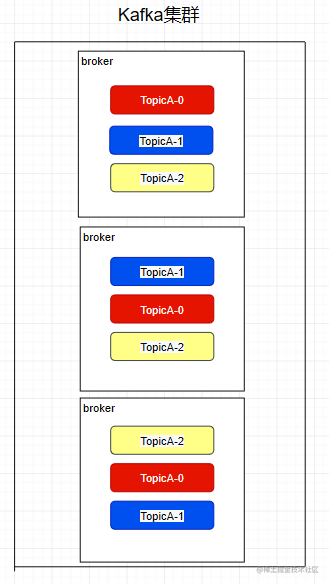
2.2 Broker與Partition
Broker作為分布式的實(shí)現(xiàn),其實(shí)可以直接簡單理解為一個(gè)Kafka進(jìn)程就是一個(gè)Broker。
我們之前提到Partition是物理存在的,其物理的存在的位置就在Broker中。同時(shí),為了服務(wù)具有一定的可靠性,每一個(gè)分區(qū)都有幾個(gè)副本,每個(gè)副本存在于不同的Broker中。
我們之前提到的Topic是邏輯概念即在于此,并沒有物理存在,圖中每個(gè)TopicA-x都是一個(gè)Partition,其中后面的數(shù)字代表了一個(gè)分區(qū)中的第幾個(gè)副本,每個(gè)Broker中都有不同的副本,目的就是當(dāng)有Broker宕機(jī)時(shí),其他的副本還存在保證系統(tǒng)的可用性。
此外,多個(gè)副本Partition中會(huì)選取一個(gè)作為leader,其他的作為follower。我們的生產(chǎn)者在發(fā)送數(shù)據(jù)的時(shí)候,是直接發(fā)送到leader partition里面,然后follower partition會(huì)去leader那里自行同步數(shù)據(jù),消費(fèi)者消費(fèi)數(shù)據(jù)的時(shí)候,也是從leader那去消費(fèi)數(shù)據(jù)的。
副本處于不同的 broker 中,當(dāng) leader 副本出現(xiàn)故障時(shí),從 follower 副本中重新選舉新的 leader 副本對外提供服務(wù)。Kafka 通過多副本機(jī)制實(shí)現(xiàn)了故障的自動(dòng)轉(zhuǎn)移,當(dāng) Kafka 集群中某個(gè) broker 失效時(shí)仍然能保證服務(wù)可用。
2.3 生產(chǎn)者消費(fèi)者與ZooKeeper
產(chǎn)生消息的角色或系統(tǒng)稱之為生產(chǎn)者,例如上述某個(gè)業(yè)務(wù)系統(tǒng)產(chǎn)生了關(guān)于訂單狀態(tài)的相關(guān)消息,那么該業(yè)務(wù)系統(tǒng)即為生產(chǎn)者。
消費(fèi)者則是負(fù)責(zé)接收或者使用消息的角色或系統(tǒng)。
ZooKeeper 是 Kafka 用來負(fù)責(zé)集群元數(shù)據(jù)的管理、控制器 的選舉等操作的。Producer 將消息發(fā)送到 Broker,Broker 負(fù)責(zé)將收到的消息存儲(chǔ)到磁盤中,而 Consumer 負(fù)責(zé)從 Broker 訂閱并消費(fèi)消息。
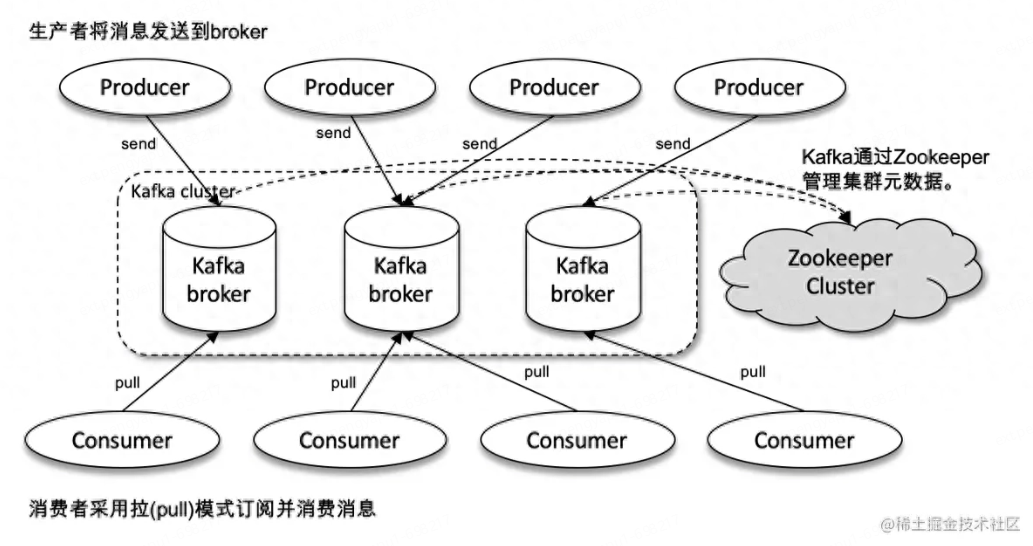
在每一個(gè)Broker在啟動(dòng)時(shí)都會(huì)像向ZK注冊信息,ZK會(huì)選取一個(gè)最早注冊的Broker作為Controller,后面Controller會(huì)與ZK進(jìn)行數(shù)據(jù)交互獲取元數(shù)據(jù)(即整個(gè)Kafka集群的信息,例如有那些Broker,每個(gè)Broker中有那些Partition等信息),然后其他Broker再與Controller交互進(jìn)而所有的Broker都能感知到整個(gè)集群的所有信息.
2.4 消費(fèi)者組
目前大部分業(yè)務(wù)系統(tǒng)架構(gòu)都是分布式的,即一個(gè)應(yīng)用會(huì)部署多個(gè)節(jié)點(diǎn)。正常來說,一條消息只應(yīng)該被其中某一個(gè)節(jié)點(diǎn)消費(fèi)掉,而不應(yīng)該是所有被所有的消費(fèi)者同時(shí)消費(fèi)一遍。因此就產(chǎn)生了消費(fèi)者組的概念,在一個(gè)消費(fèi)者組中,一條消息只會(huì)被消費(fèi)者組中的一個(gè)消費(fèi)者所消費(fèi)。
從使用上來說,一般配置為一個(gè)應(yīng)用為一個(gè)消費(fèi)者組,或一個(gè)應(yīng)用中不同的環(huán)境也可以配置不用的消費(fèi)者組。例如生產(chǎn)環(huán)境的節(jié)點(diǎn)與預(yù)發(fā)環(huán)境的節(jié)點(diǎn)可以配置兩套消費(fèi)者組,這樣在有新的改動(dòng)部署在預(yù)發(fā)時(shí),即使本次改動(dòng)修改了消費(fèi)動(dòng)作的相關(guān)邏輯,也不會(huì)影響生產(chǎn)的數(shù)據(jù)。
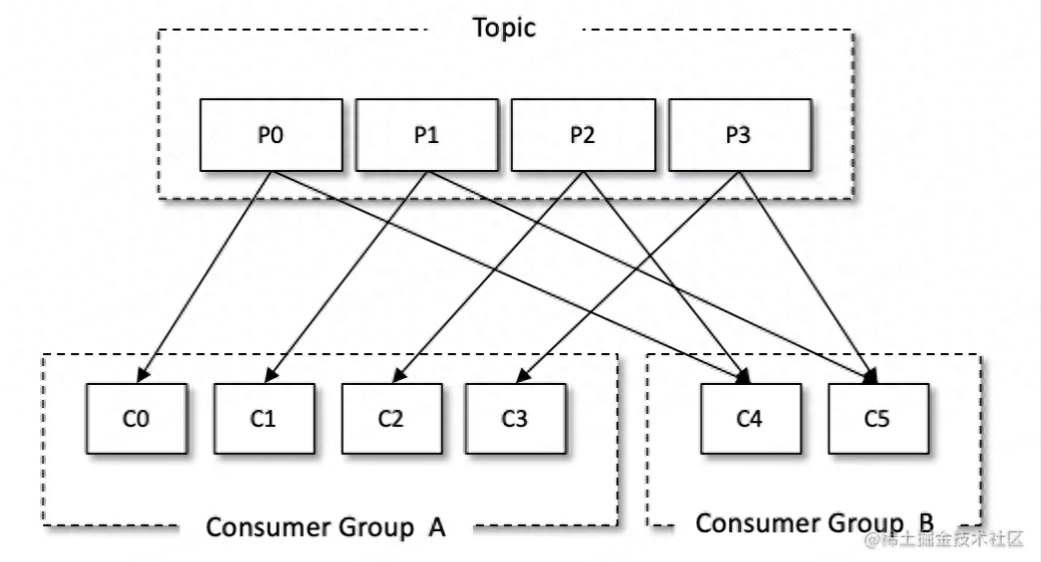
消費(fèi)者與消費(fèi)組這種模型可以讓整體的消費(fèi)能力具備橫向伸縮性,我們可以增加(或減少) 消費(fèi)者的個(gè)數(shù)來提高(或降低)整體的消費(fèi)能力。對于分區(qū)數(shù)固定的情況,一味地增加消費(fèi)者 并不會(huì)讓消費(fèi)能力一直得到提升,如果消費(fèi)者過多,出現(xiàn)了消費(fèi)者的個(gè)數(shù)大于分區(qū)個(gè)數(shù)的情況, 就會(huì)有消費(fèi)者分配不到任何分區(qū)。參考下圖(右下),一共有 8 個(gè)消費(fèi)者,7 個(gè)分區(qū),那么最后的消費(fèi) 者 C7 由于分配不到任何分區(qū)而無法消費(fèi)任何消息。
2.5 ISR、HW、LEO
Kafka通過ISR機(jī)制盡量保證消息不會(huì)丟失。
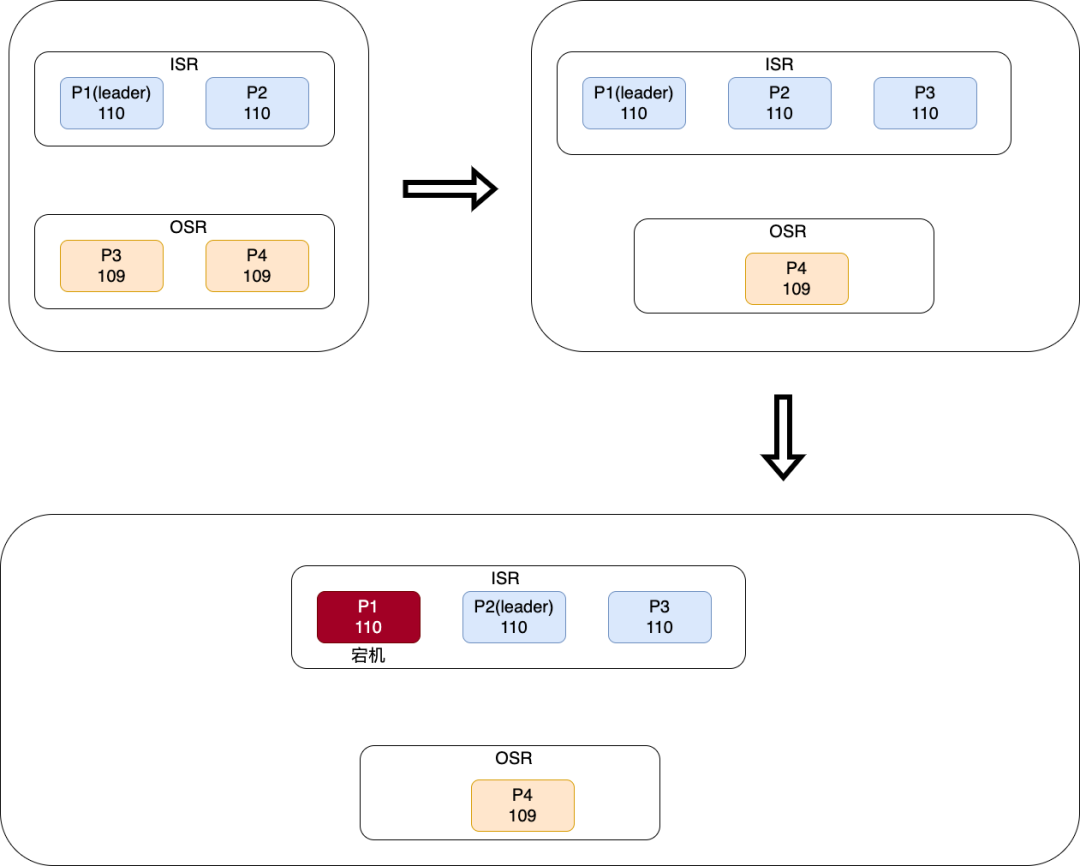
一個(gè)Partition中所有副本稱為AR (Assigned Replicas) ,所有與 leader 副本保持一定程度同步的副本(包括 leader 副本在內(nèi))組成 ISR (In-Sync Replicas)。我們上文提到,follower 副本只負(fù)責(zé)消息的同步,很多時(shí)候 follower 副本中的消息相對 leader 副本而言會(huì)有一定的滯后,而及時(shí)與leader副本保持?jǐn)?shù)據(jù)一致的就可以成為ISR成員。與 leader 副本同步滯后過多的副本(不包括 leader 副本)組成OSR (Out-of-Sync Replicas) ,由此可見,AR =ISR+OSR。在正常情況下,所有的 follower 副本都應(yīng)該與 leader 副本保持一定程度的同步,即 AR=ISR,OSR 集合為空。
leader副本會(huì)監(jiān)聽所有follower副本,當(dāng)其與leader副本數(shù)據(jù)一致時(shí)會(huì)將其加入ISR成員,當(dāng)與leader副本相差太多或宕機(jī)時(shí)會(huì)將其踢出ISR,也會(huì)在其追上leader副本后重新加入ISR。
當(dāng)leader副本宕機(jī)或不可用時(shí),只有ISR成員才能有機(jī)會(huì)被選擇為新的leader副本,這樣就能確保新的leader與已經(jīng)宕機(jī)的leader數(shù)據(jù)一致,而如果選擇OSR中的副本作為leader時(shí)會(huì)造成部分未同步的數(shù)據(jù)丟失。
上圖情況中,P1副本首先當(dāng)選了leader,且只有P2副本同步了P1的數(shù)據(jù),offset都為110,那么此時(shí)的ISR只有P1與P2,OSR有P3和P4。當(dāng)P3同步數(shù)據(jù)到110后,也會(huì)被leader加入到ISR中,若此時(shí)leader宕機(jī),則會(huì)從ISR中選出一個(gè)新的leader,并將P0踢出ISR中。
那么leader是如何感知到其他副本是否與自己數(shù)據(jù)一致呢?靠的就是HW與LEO機(jī)制。
LEO 是 Log End Offset 的縮寫,它標(biāo)識(shí)當(dāng)前日志文件中下一條待寫入消息的 offset,LEO 的大小相當(dāng)于當(dāng)前日志分區(qū)中最后一條消息的 offset 值加 1。分區(qū) ISR 集合中的每個(gè)副本都會(huì)維護(hù)自身的 LEO,而 ISR 集合中最小的 LEO 即為分區(qū)的 HW,HW 是 High Watermark 的縮寫,俗稱高水位,它標(biāo)識(shí)了一個(gè)特定的消息偏移量(offset),消費(fèi)者只能拉取到這個(gè) offset 之前的消息。
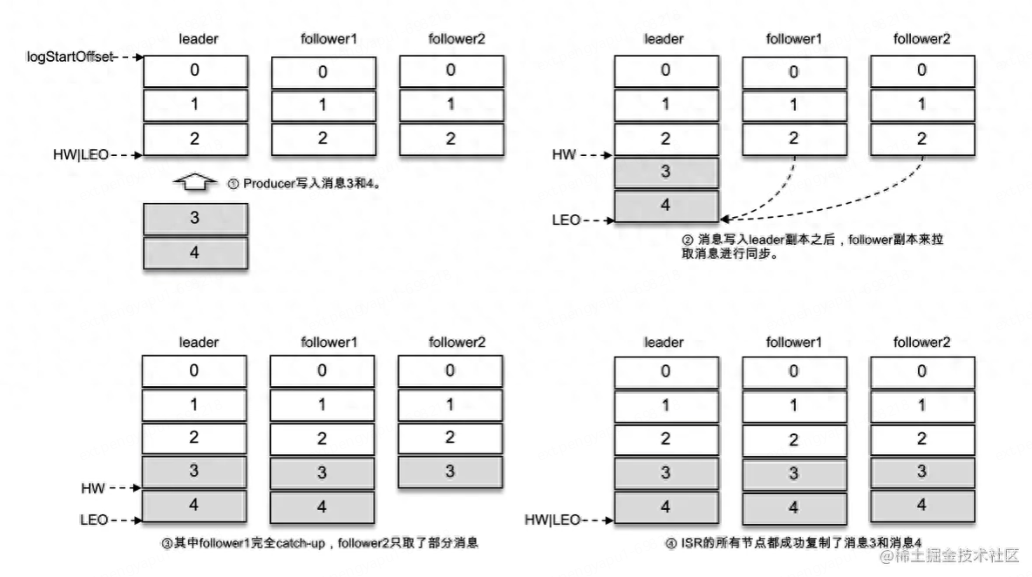
上圖中,因?yàn)樗懈北鞠⒍际且恢碌模运蠰EO都是3,HW也為3,當(dāng)有新的消息產(chǎn)生時(shí),即leader副本新插入了3/4兩條消息,此時(shí)leader的LEO為5,兩個(gè)follower的此時(shí)未同步消息,所以LEO仍未3,HW選擇最小的LEO是3.
當(dāng)follower1同步完成leader的數(shù)據(jù)后,LEO未5,但follower2未同步,所以此時(shí)HW仍未3。此后follower2同步完成后,其LEO為5,所有副本的LEO都未5,此時(shí)HW選擇最小的為5。
通過這種機(jī)制,leader副本就能知道哪些副本是滿足ISR條件的(該副本LEO是否等于leader副本LEO)。
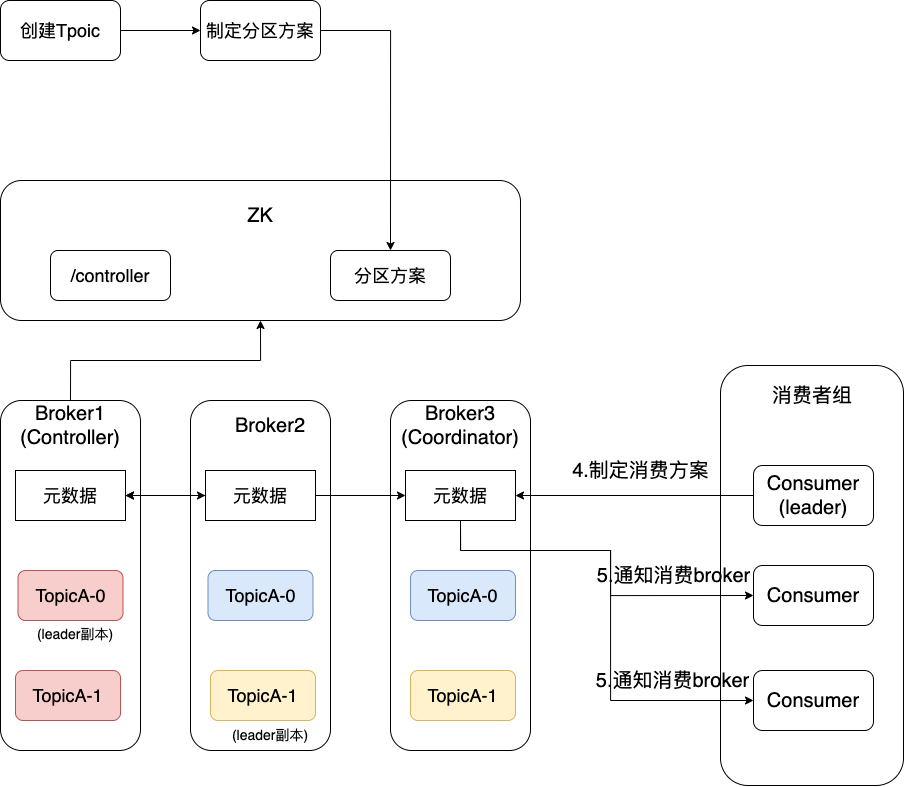
3.1 注冊信息
Kafka強(qiáng)依賴與ZooKeeper以維護(hù)整個(gè)集群的信息,因此在啟動(dòng)前應(yīng)該先啟動(dòng)ZooKeeper。
在ZK啟動(dòng)完成之后,所有的Broker(即所有的Kafka進(jìn)程)都會(huì)向ZK注冊信息,然后爭取/controller的監(jiān)聽權(quán),獲取到監(jiān)聽權(quán)的Broker稱為Controller,此后由Controller與ZK進(jìn)行信息交換,所有的Broker與Controller進(jìn)行消息交換。進(jìn)而保持整個(gè)Kafka集群的信息一致性。
3.2 創(chuàng)建主題
在所有的Broker注冊完畢后,需要注冊主題(Topic)以繼續(xù)后續(xù)流程。
其中某個(gè)客戶端接收到創(chuàng)建Topic請求后,會(huì)將請求中的分區(qū)方案(有幾個(gè)分區(qū)、幾個(gè)副本等)告訴ZK,ZK再將信息同步至Controller,此后所有的Broker與Controller交換完元數(shù)據(jù),至此所有的Broker都已經(jīng)知道該Topic的分區(qū)方案了,然后按照該分區(qū)方案創(chuàng)建自己的分區(qū)或副本即可。
以上就是某一個(gè)broker下面的某一個(gè)主題的分布情況
3.3 生產(chǎn)者發(fā)送數(shù)據(jù)
在創(chuàng)建完想要的Topic之后,生產(chǎn)者就可以開始發(fā)送數(shù)據(jù)。
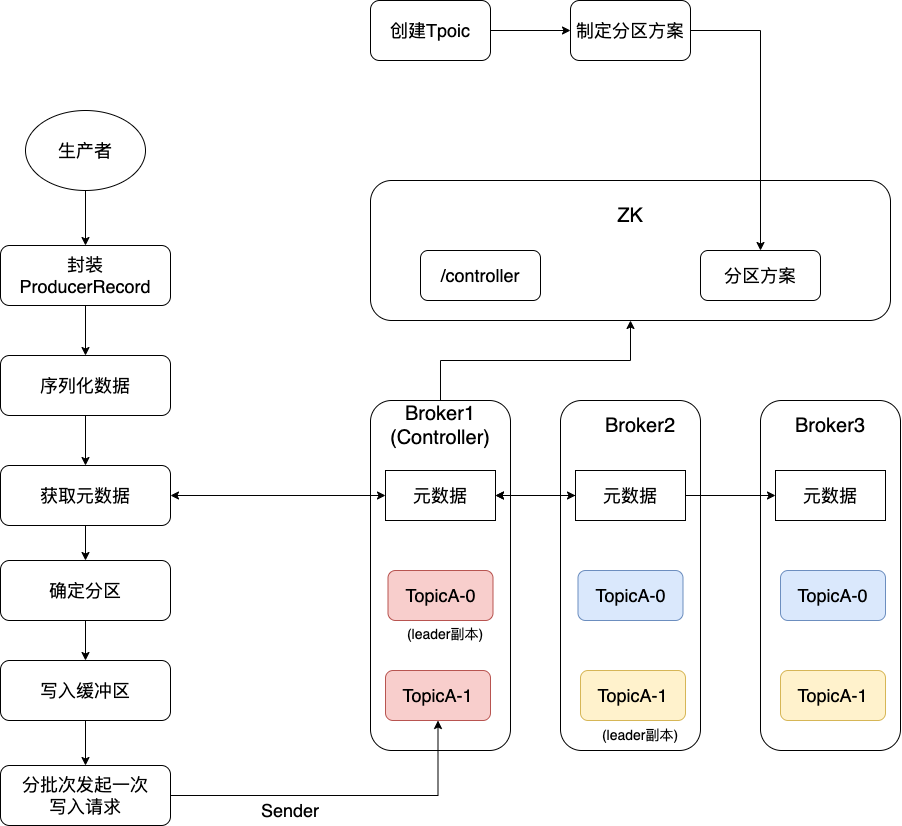
3.3.1 封裝ProducerRecord
首先生產(chǎn)者會(huì)將信息封裝成ProducerRecord
private final String topic;private final Integer partition;private final Headers headers;private final K key;private final V value;private final Long timestamp;
其中主要包好了要發(fā)送的Topic名稱,要發(fā)送至那個(gè)分區(qū),以及要發(fā)送的數(shù)據(jù)和key。
其他的都比較好理解,key的作用是如果key存在的話,就會(huì)對key進(jìn)行hash,然后根據(jù)不同的結(jié)果發(fā)送至不同的分區(qū),這樣當(dāng)有相同的key時(shí),所有相同的key都會(huì)發(fā)送到同一個(gè)分區(qū),我們之前也提到,所有的新消息都會(huì)被添加到分區(qū)的尾部,進(jìn)而保證了數(shù)據(jù)的順序性。
例如我們有個(gè)關(guān)于會(huì)員的業(yè)務(wù)系統(tǒng),其中生產(chǎn)者會(huì)產(chǎn)生關(guān)于某個(gè)會(huì)員積分的信息,消費(fèi)者拿到這個(gè)消息之后會(huì)實(shí)際對積分進(jìn)行操作。假如某個(gè)會(huì)員先獲得了100積分,然后又消費(fèi)了50積分。因此生產(chǎn)者會(huì)發(fā)送兩個(gè)MQ消息,但是假如沒有使用key的功能,這兩個(gè)消息被發(fā)送到了不同的分區(qū),因?yàn)槊總€(gè)分區(qū)的消費(fèi)水平不一樣(例如獲得積分的邏輯耗時(shí)比較長而某個(gè)分區(qū)又都是獲得積分的MQ),就有可能造成消費(fèi)50積分的MQ會(huì)先被消費(fèi)者收到。
而假如此時(shí)會(huì)員積分為0的情況下再去消費(fèi)50積分明顯是不合理且邏輯錯(cuò)誤的,會(huì)造成業(yè)務(wù)系統(tǒng)異常。因此在生產(chǎn)者發(fā)送MQ時(shí)如果消息有順序性要求則一定要將key賦值,具體的可以是某些有唯一性標(biāo)識(shí)例如此處可以是會(huì)員ID。
3.3.2 序列化數(shù)據(jù)、獲取元數(shù)據(jù)、確定分區(qū)
首先生產(chǎn)側(cè)客戶端的序列化器會(huì)將要發(fā)送的ProducerRecord對象序列化成字節(jié)數(shù)組 ,然后發(fā)送到消費(fèi)端后消費(fèi)端的反序列化器會(huì)將字節(jié)數(shù)組再轉(zhuǎn)換成對應(yīng)的消費(fèi)對象。常用的序列化器有String、Doule、Long等等。
其次也可以自定義序列化器與反序列化器,例如可以將將字節(jié)數(shù)組進(jìn)行加密后再進(jìn)行傳輸,以此保證數(shù)據(jù)的安全性。
數(shù)據(jù)都準(zhǔn)備完成之后就可以開始獲取broker元數(shù)據(jù),例如host等,以方便后續(xù)確定要發(fā)送的位置。
確定要發(fā)送至那個(gè)分區(qū)有幾種情況:
-
如果ProducerRecord中指定了要發(fā)往那個(gè)分區(qū),則選擇用戶使用的分區(qū)
-
如果沒有指定分區(qū),則查看ProducerRecord中key是否為空,如果不為空則對key進(jìn)行計(jì)算以獲取使用那個(gè)分區(qū)
-
如果key也為空,則按照輪詢的方式發(fā)送至不同的分區(qū)
也可以通過自定義分區(qū)器的方式確定發(fā)送哪個(gè)分區(qū)。
3.3.3 寫入緩沖區(qū)、分批分送消息
生產(chǎn)者發(fā)送的MQ并不會(huì)直接通過網(wǎng)絡(luò)發(fā)送至broker,而是會(huì)先保存在生產(chǎn)者的緩沖區(qū)。
然后由生產(chǎn)者的Sender線程分批次將數(shù)據(jù)發(fā)送出去,分批次發(fā)送的原因是可以節(jié)省一定的網(wǎng)絡(luò)消耗與提升速度,因?yàn)橐淮伟l(fā)送一萬條與一萬次發(fā)送一條肯定效率不太一樣。
分批次發(fā)送主要有兩個(gè)參數(shù),批次量與等待時(shí)間。兩個(gè)參數(shù)主要是解決兩個(gè)問題,一個(gè)是防止一次發(fā)送的消息量過大,比如一次可能發(fā)送幾十mb的數(shù)據(jù)。另一個(gè)解決的問題是防止長時(shí)間沒有足夠消息產(chǎn)生而導(dǎo)致的消息一直不發(fā)送。因此當(dāng)上述兩個(gè)條件任意滿足其一就會(huì)觸發(fā)這一批次的發(fā)送。
Kafka的網(wǎng)絡(luò)模型用的是加強(qiáng)版的reactor網(wǎng)絡(luò)模型

首先客戶端發(fā)送請求全部會(huì)先發(fā)送給一個(gè)Acceptor,broker里面會(huì)存在3個(gè)線程(默認(rèn)是3個(gè)),這3個(gè)線程都是叫做processor,Acceptor不會(huì)對客戶端的請求做任何的處理,直接封裝成一個(gè)個(gè)socketChannel發(fā)送給這些processor形成一個(gè)隊(duì)列,發(fā)送的方式是輪詢,就是先給第一個(gè)processor發(fā)送,然后再給第二個(gè),第三個(gè),然后又回到第一個(gè)。消費(fèi)者線程去消費(fèi)這些socketChannel時(shí),會(huì)獲取一個(gè)個(gè)request請求,這些request請求中就會(huì)伴隨著數(shù)據(jù)。
線程池里面默認(rèn)有8個(gè)線程,這些線程是用來處理request的,解析請求,如果request是寫請求,就寫到磁盤里。讀的話返回結(jié)果。processor會(huì)從response中讀取響應(yīng)數(shù)據(jù),然后再返回給客戶端。這就是Kafka的網(wǎng)絡(luò)三層架構(gòu)。
所以如果我們需要對kafka進(jìn)行增強(qiáng)調(diào)優(yōu),增加processor并增加線程池里面的處理線程,就可以達(dá)到效果。request和response那一塊部分其實(shí)就是起到了一個(gè)緩存的效果,是考慮到processor們生成請求太快,線程數(shù)不夠不能及時(shí)處理的問題。
3.4 消費(fèi)者消費(fèi)數(shù)據(jù)
消費(fèi)者消費(fèi)也主要分為兩個(gè)階段:
-
信息注冊階段,即整個(gè)消費(fèi)者組向集群注冊消費(fèi)信息等
-
信息消費(fèi)階段,開始信息消息,確保消息可靠性等
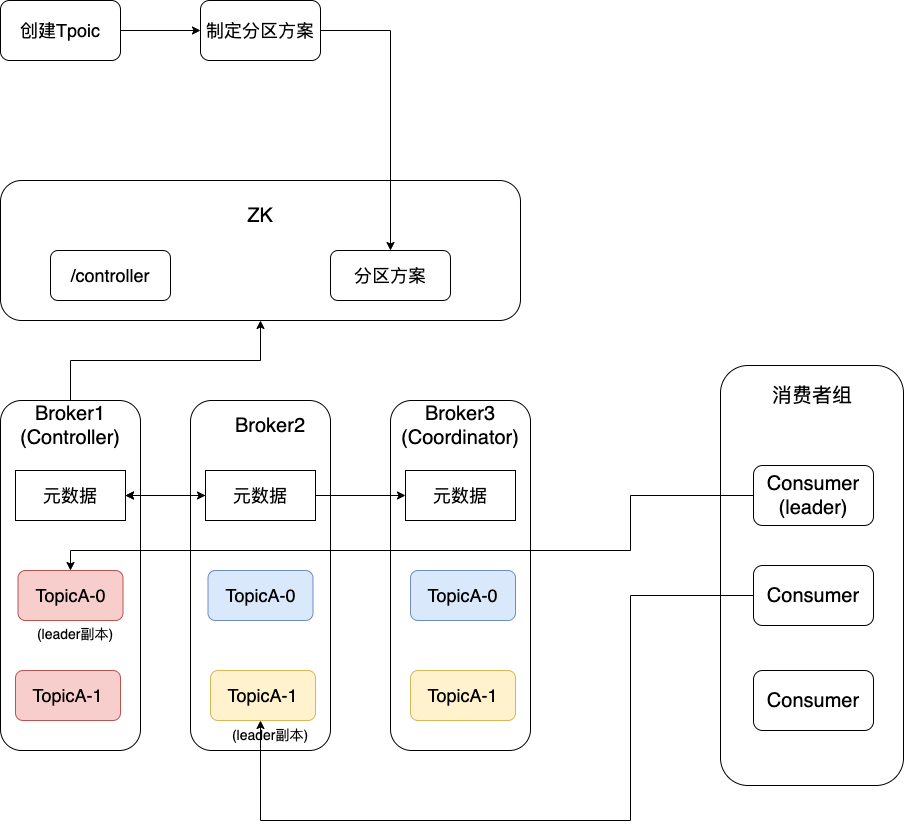
3.4.1 信息注冊
首先消費(fèi)者組內(nèi)所有消費(fèi)者都會(huì)向集群尋找自己的Coordinator(以消費(fèi)者組id做均衡)。找到Coordinator后,所有的Consumer都會(huì)向Coordinator發(fā)起join group加入消費(fèi)者組的請求,Coordinator會(huì)選擇一個(gè)最早發(fā)起請求的Consumer作為leader Consumer,其他的Consumer作為follower。
leader會(huì)根據(jù)要消費(fèi)的Topic及分區(qū)情況制定一個(gè)消費(fèi)方案,告知給Coordinator,Coordinator再將此消費(fèi)方案告知給各個(gè)follower。
自此,所有的Consumer都已經(jīng)知道自己要消費(fèi)那個(gè)分區(qū)了。
如上圖,每個(gè)消費(fèi)者都找了自己要消費(fèi)的分區(qū)情況
3.4.2 消費(fèi)信息
消費(fèi)信息主要包含了以下幾個(gè)步驟:
1)拉取消息
常用的消息隊(duì)列的消費(fèi)消息一般有兩種,推送或者拉取,Kafka在此處用的是拉取模式。
try { while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(100)); for (ConsumerRecord<String, String> record : records) { int updateCount = 1; if (map.containsKey(record.value())) { updateCount = (int) map.get(record.value() + 1); } map.put(record.value(), updateCount); } }}finally { consumer.close();}
通過設(shè)置定時(shí)時(shí)間,每隔多長時(shí)間拉取一次消息。
2)反序列化與消費(fèi)消息
在上面的代碼中,我們拿到的就是ConsumerRecord對象,但是實(shí)際上這個(gè)是消費(fèi)者客戶端幫我們做的反序列化的操作,將字節(jié)數(shù)組(byte[])反序列化成了對象。參考3.3.2我們也可以自定義反序列化器。
3)提交消息位移
例如當(dāng)消息隊(duì)列中有100條消息,消費(fèi)者第一次消費(fèi)了20條消息,那么第二次消費(fèi)的位置肯定是要從第21條消息開始消費(fèi),而記錄第21條消息的信息稱之為offset,offset為已經(jīng)消費(fèi)位置+1.
在之前版本的客戶端,offset數(shù)據(jù)被存在zk中,每次都需要請求zk獲取數(shù)據(jù),而zk并不適合作為高并發(fā)的請求。因此在現(xiàn)在的版本中,kafka通過建立一個(gè)Topic來記錄所有消費(fèi)者消費(fèi)的offset,這個(gè)Topic是__consumer_offsets。每一個(gè)消費(fèi)者在消費(fèi)數(shù)據(jù)之前(即pol()方法中),都會(huì)把上一次消費(fèi)數(shù)據(jù)中最大的offset提交到該Topic中,即此時(shí)是作為生產(chǎn)者的身份投遞信息。
kafka中有幾種offset提交模式,默認(rèn)的是自動(dòng)提交:
enable.auto.commit設(shè)置為true時(shí),每隔 auto.commit.interval.ms時(shí)間會(huì)自動(dòng)提交已經(jīng)已經(jīng)拉取到的消息中最大的offset。
但是默認(rèn)的自動(dòng)提交也會(huì)帶來重復(fù)消費(fèi)與消息丟失的問題:
-
重復(fù)消費(fèi)。例如從offset為21開始拉取數(shù)據(jù),拉取到了40,但是當(dāng)消費(fèi)者處理到第30條數(shù)據(jù)的時(shí)候系統(tǒng)宕機(jī)了,那么此時(shí)已經(jīng)提交的offset仍為21,當(dāng)節(jié)點(diǎn)重新連接時(shí),仍會(huì)從21消費(fèi),那么此時(shí)21-30的數(shù)據(jù)就會(huì)被重新消費(fèi)。還有一種情況是再均衡時(shí),例如有新節(jié)點(diǎn)加入也會(huì)引發(fā)類似的問題。
-
public static void main(String[] args) { while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(3000)); records.forEach((ConsumerRecord<String, String> record) -> { System.out.println("revice: key ===" + record.key() + " value ====" + record.value() + " topic ===" + record.topic()); }); try { consumer.commitSync(); } catch (CommitFailedException e) { e.printStackTrace(); } }}
手動(dòng)同步提交可以在任何時(shí)候提交offset,例如可以每消費(fèi)一條進(jìn)行一次提交。提交失敗之后會(huì)拋出異常,可以在異常中做出補(bǔ)償機(jī)制,例如事務(wù)回滾等操作。
但是因?yàn)槭謩?dòng)同步提交是阻塞性質(zhì)的,所以不建議太高的頻率進(jìn)行提交。
異步提交有三種方式,區(qū)別在于有沒有回調(diào)的方式。
@Testpublic void asynCommit1(){ while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(3000)); records.forEach((ConsumerRecord<String, String> record) -> { System.out.println("revice: key ===" + record.key() + " value ====" + record.value() + " topic ===" + record.topic()); }); consumer.commitAsync(); }}
@Testpublic void asynCommit2(){ while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(3000)); records.forEach((ConsumerRecord<String, String> record) -> { System.out.println("revice: key ===" + record.key() + " value ====" + record.value() + " topic ===" + record.topic()); }); consumer.commitAsync(new OffsetCommitCallback(){ @Override public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) { if (exception!=null){ System.out.println(String.format("提交失敗:%s", offsets.toString())); } } }); }}
@Testpublic void asynCommit3(){ while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(3000)); records.forEach((ConsumerRecord<String, String> record) -> { System.out.println("revice: key ===" + record.key() + " value ====" + record.value() + " topic ===" + record.topic()); }); consumer.commitAsync((offsets, exception) ->{ if (exception!=null){ System.out.println(String.format("提交失敗:%s", offsets.toString())); } }); }}
異步提交 commitAsync() 與同步提交 commitSync() 最大的區(qū)別在于異步提交不會(huì)進(jìn)行重試,同步提交會(huì)一直進(jìn)行自動(dòng)重試,當(dāng)然也可以通過再發(fā)生異常時(shí)繼續(xù)提交的方式來完成此功能。
可以使用同步+異步的形式保證數(shù)據(jù)能夠準(zhǔn)確提交:
while (true) { ConsumerRecords records = consumer.poll(100); for (ConsumerRecord record : records) { log.trace("Kafka消費(fèi)信息ConsumerRecord={}",record.toString()); } try { consumer.commitAsync(); } catch (CommitFailedException e) { log.error("commitAsync failed", e) } finally{ try { consumer.commitSync(); } catch (CommitFailedException e) { log.error("commitAsync failed", e) } finally{ consumer.close(); } }}
4.1 異常重試
我們系統(tǒng)之前遇到過消費(fèi)者在消費(fèi)消息時(shí),短時(shí)間內(nèi)連續(xù)報(bào)錯(cuò)。根據(jù)現(xiàn)象以為是系統(tǒng)出現(xiàn)問題,后續(xù)發(fā)現(xiàn)所有報(bào)錯(cuò)都是同一條消息,排查后發(fā)現(xiàn)是處理消息過程中存在未捕獲的異常,導(dǎo)致消息重試,相同的問題引發(fā)了連續(xù)報(bào)錯(cuò)。
JMQ在消費(fèi)過程中如果有未捕獲的異常會(huì)認(rèn)為消息消費(fèi)失敗,會(huì)首先在本地重試兩次后放入重試隊(duì)列中,進(jìn)入重試隊(duì)列的消息,會(huì)有過期邏輯,當(dāng)超過重試時(shí)間或者超過最大重試次數(shù)后(默認(rèn)3天過期),消息將會(huì)被丟棄。因此在處理消息時(shí)需要考慮如果出現(xiàn)異常后的處理場景,選擇是重試還是忽略還是記錄數(shù)據(jù)后告警。
因此我們在消費(fèi)消息的過程中,尤其是采用pull模式,一定要根據(jù)業(yè)務(wù)場景注意異常的捕獲。否則小則影響本條消息,大則本批次后續(xù)所有消息都可能丟失。
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(60L));for (ConsumerRecord<String, String> record : records) { try { } catch (Exception e) { log.error("Bdp監(jiān)聽任務(wù)執(zhí)行失敗, taskName:{}", taskName, e); }}
4.2 本地重試與服務(wù)端重試
系統(tǒng)還遇到過在JMQ服務(wù)端配置了消費(fèi)失敗重試的邏輯,例如重試多少次間隔多久,但是在消費(fèi)失敗之后,發(fā)現(xiàn)重試的邏輯并沒有按照配置的邏輯走。聯(lián)系運(yùn)維幫忙排查后發(fā)現(xiàn):
根據(jù)4.1我們知道消費(fèi)失敗后,會(huì)首先在本地重試,本地重試失敗后會(huì)放入重試隊(duì)列,則此時(shí)進(jìn)入服務(wù)端重試,兩套重試需要兩套配置,本地的重試配置在本地的配置文件中。
<jmq:consumer id="apiConsumer" transport="jmq.apilog.transport"> <jmq:listener topic="${jmq.topic.apilog}" listener="apiLogMessageListener" retryDelay="1000" maxRetrys="3"/></jmq:consumer>
注:本篇文章圖片部分來源于網(wǎng)絡(luò)
-end-