
硬核圖解,再填猛將!
大家好,我是 Jack。
承諾的圖解 AI 算法系列教程,今天咱們繼續(xù)!
這個(gè)系列一直寫的比較隨性,想寫哪個(gè)算法就寫了哪個(gè),毫無章法。
好在,文章質(zhì)量都還不錯(cuò),雖然硬核了點(diǎn),但從各方面的反饋來看,還是有不少朋友喜歡看的。
今天,聊一聊人工智能,計(jì)算機(jī)視覺方向的重頭戲。
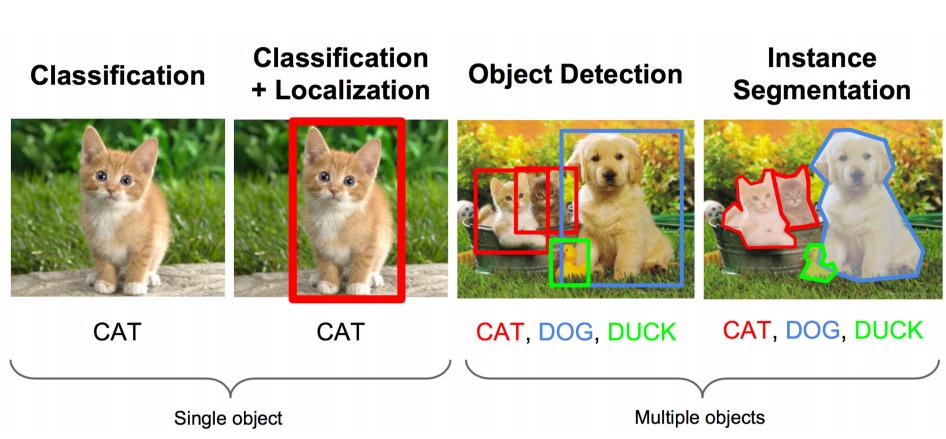
我們都知道,CV 領(lǐng)域最常規(guī)的三大任務(wù)是:圖像分類、目標(biāo)檢測、圖像分割。
圖像的分類和分割算法實(shí)戰(zhàn)教程,我在2019年就出過了,想看可以往前翻一翻。
目前,就差目標(biāo)檢測還沒寫過,雖遲但到,今天它來了!
目標(biāo)檢測
目標(biāo)檢測,應(yīng)用非常廣,是非常重要的技術(shù)儲(chǔ)備。
目標(biāo)檢測落地場景豐富,可用度非常高,人臉識(shí)別、智能安防系統(tǒng)、無人駕駛、無人機(jī)等各個(gè)領(lǐng)域,目標(biāo)檢測都是核心技術(shù)。
舉個(gè)例子,無人機(jī)領(lǐng)域,畫面中的車輛、行人等目標(biāo)的檢測。

軍事上,目標(biāo)的精準(zhǔn)打擊,也都有目標(biāo)檢測的身影。
生活上,我們也可以利用檢測做很多事情,隨手一拍。

目標(biāo)檢測檢測出物體,車輛、樹木,可能有些人會(huì)問,這個(gè)檢測出來有啥用?
那要是在此基礎(chǔ)上,再識(shí)別出這些是什么車、什么樹?
寶馬,奧迪,還是比亞迪?
楊樹,柳樹,還是白楊樹?
再比如,什么品種的貓貓狗狗,什么品牌的衣帽鞋襪。
萬物皆可識(shí)別,只需隨手一拍。這就是很多做視覺的公司,都在做的重點(diǎn)方向。
這也是,目標(biāo)檢測+細(xì)分類的技術(shù)應(yīng)用的場景之一。先檢測出畫面中的目標(biāo),再將檢測出的目標(biāo)送入更細(xì)粒度的分類網(wǎng)絡(luò),識(shí)別出堪比人,甚至遠(yuǎn)超人的精細(xì)水平。
目標(biāo)檢測,專業(yè)一點(diǎn)的概念就是:解決“在哪里?是什么?”的問題,即定位出這個(gè)目標(biāo)的位置并且知道目標(biāo)物是什么。
基于深度學(xué)習(xí)的目標(biāo)檢測算法主要分為兩類:
- Two Stage:兩階段目標(biāo)檢測
- One Stage:端到端目標(biāo)檢測
Two Stage
Two Stage 是2013年到2015年的主流算法,后來逐漸發(fā)展為 One Stage 端到端的目標(biāo)檢測算法。
Two Stage 算法是先進(jìn)行區(qū)域生成,該區(qū)域稱之為 region proposal(簡稱RP,一個(gè)有可能包含待檢物體的預(yù)選框),再通過卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行樣本分類。
任務(wù)流程:特征提取 --> 生成RP --> 分類/定位回歸。
常見 Two Stage 目標(biāo)檢測算法有:R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN 和 R-FCN 等。
One Stage
不用 RP,直接在網(wǎng)絡(luò)中提取特征來預(yù)測物體分類和位置。
任務(wù)流程:特征提取–> 分類/定位回歸。
常見的 One Stage 目標(biāo)檢測算法有:YOLO 系列、SSD 系列、Anchor Free 系列等。
如今,比較常用、實(shí)用的目標(biāo)檢測算法都是 One Stage 的。
從前,一般講解目標(biāo)檢測都是從兩階段的 R-CNN 系列開始,但說實(shí)話,有些老了,一階段的 YOLO 從 v1 都發(fā)展到 v5 了。
但并不代表 Faster R-CNN 這些就沒有學(xué)的必要,目標(biāo)檢測的基礎(chǔ),還是很有必要學(xué)習(xí)一番的,并且不少公司其實(shí)還在用這些算法。
現(xiàn)在,一般公司面試,都愛問 YOLO 系列的算法,YOLO v4、YOLO v5 這些。
今天,先來個(gè)比較基礎(chǔ)的,我們從 YOLO v1 談起。
YOLO v1
YOLO 的名字還是很霸氣的:You Only Look Once。
YOLO 之父是 Joseph Redmon,v1 - v3 是他的作品,篇篇頂會(huì),性能也是,開源口碑非常好。

可惜,發(fā)布完 v3 就退圈了,后續(xù)的 v4 - v5 ,都是其他團(tuán)隊(duì)接手了。
在講解 YOLO v1 之前,重申一下我們的任務(wù):在一張圖片中找出物體,并給出它的類別和位置。

YOLO v1 的核心思想是:采用利用整張圖作為網(wǎng)絡(luò)的輸入,直接在輸出層回歸 bounding box 的位置和 bounding box 所屬的類別。
為了照顧新人,這里解釋下 bounding box ,即檢測框,就是目標(biāo)外圍帶顏色的框框,一般簡稱 bbox。
YOLO v1 的實(shí)現(xiàn),是將一幅圖像分成 SxS 個(gè)網(wǎng)格(grid cell)。
哪個(gè)目標(biāo)物體的中心落在這個(gè)網(wǎng)格中,則這個(gè)網(wǎng)格負(fù)責(zé)預(yù)測這個(gè)目標(biāo)。

論文中,是將圖像分為 7x7 的網(wǎng)格,即上文中的 S=7。如上圖所示,紅色的點(diǎn),就是負(fù)責(zé)檢測狗的。
網(wǎng)絡(luò)結(jié)構(gòu)
YOLO v1目標(biāo)檢測一共三個(gè)步驟:

- resize圖片尺寸
- 輸入網(wǎng)絡(luò),出結(jié)果
- NMS
第一步,resize 很好理解,屬于深度學(xué)習(xí)的常規(guī)操作,就是為了將不同尺寸的圖片適配到統(tǒng)一的網(wǎng)絡(luò)結(jié)構(gòu)中,需要 resize 到相同的尺寸。
論文提出的這個(gè)網(wǎng)絡(luò)結(jié)構(gòu),輸入層的尺寸是 448x448,因此在將圖片送入網(wǎng)絡(luò)前,需要將圖片 resize 到 448x448。
我們直接看下網(wǎng)絡(luò)結(jié)構(gòu),精髓都在這里:
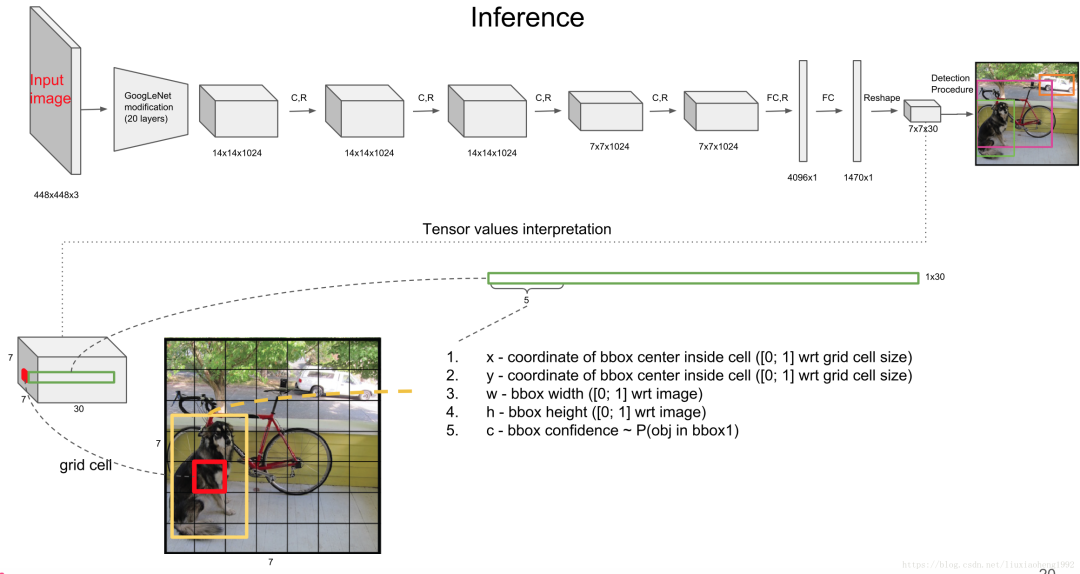
這里設(shè)計(jì)得很巧妙,可以看到網(wǎng)絡(luò)的最終輸出是 7×7×30。還是以這個(gè)狗為例,7x7 很好理解,圖像分為 7x7 個(gè)區(qū)域進(jìn)行預(yù)測。
最終輸出 tensor 的前五個(gè)數(shù)值,分別是 bbox 的 x,y,w,h,c,即 bbox 的中心坐標(biāo) x,y,bbox 的寬高 w,h,bbox 的置信度。
置信度就是算法的自信心得分,越高表示越堅(jiān)信這個(gè)檢測的目標(biāo)沒錯(cuò)。
而一個(gè)中心點(diǎn),會(huì)檢測 2 個(gè) bbox ,這個(gè)操作可以減少漏檢,因?yàn)榭梢赃m應(yīng)不同形狀的 bbox,進(jìn)而提高bbox 的準(zhǔn)確率。
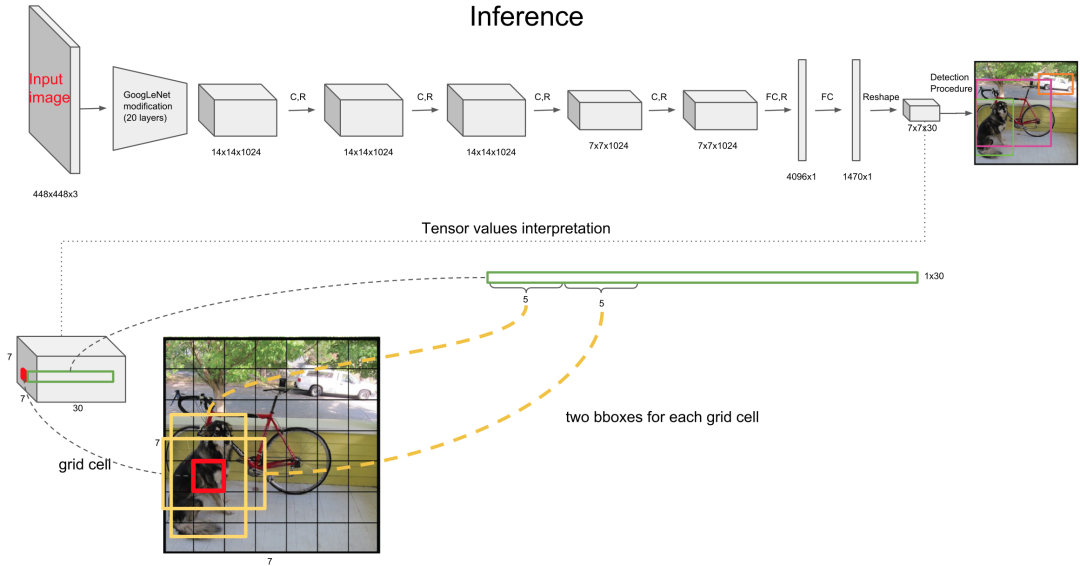
2 個(gè) bbox 都會(huì)保留,最后通過 NMS 選擇出最佳的 bbox,這個(gè)操作最后再講。
而后面的 20 個(gè),就是類別的概率,YOLO v1 是在 VOC 數(shù)據(jù)集上訓(xùn)練的,因此一共 20 個(gè)類。
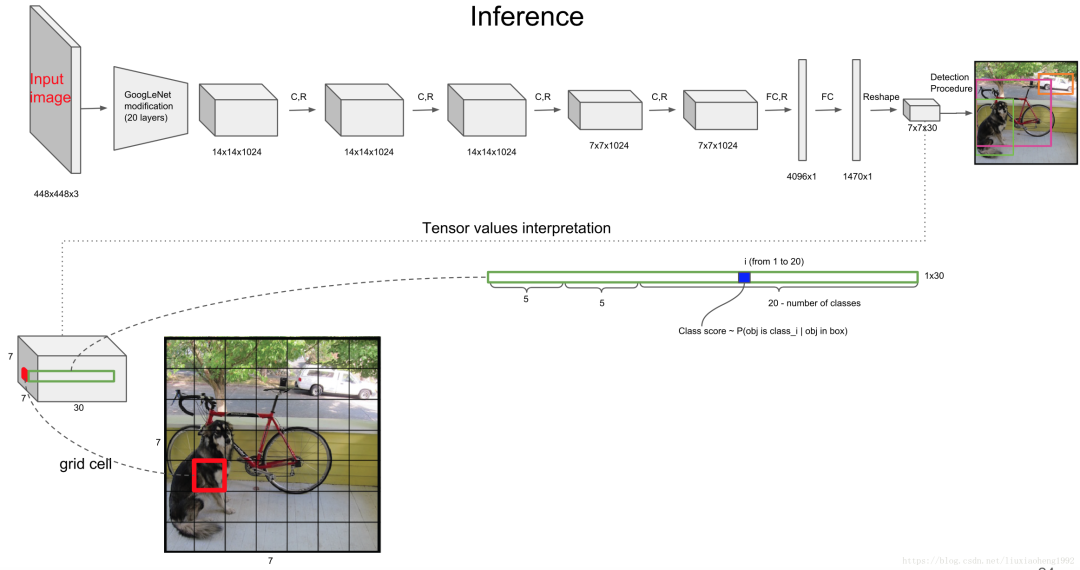
因此,tensor 總共加起來就是 7×7×(2×5+20),寫成公式就是:SxSx(Bx5+C)。
這里的問題,可以當(dāng)作回歸問題來解決的。所有的輸出包括坐標(biāo)和寬高都定義在0到1之間。
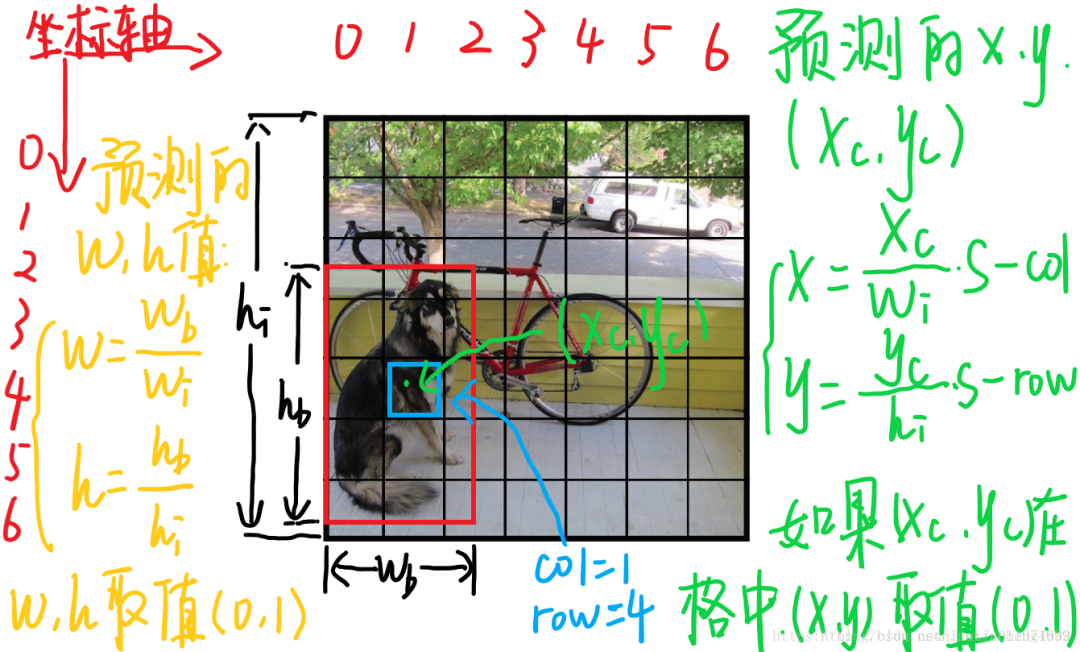
來看一下每個(gè)單元格預(yù)測的B個(gè)(x,y,w,h,confidence)的向量和C的條件概率中,每個(gè)參數(shù)的含義(假設(shè)圖片寬為高為,將圖片分為:
(x,y)是bbox的中心相對(duì)于單元格的offset
對(duì)于下圖中藍(lán)色框的那個(gè)單元格坐標(biāo)為,假設(shè)它預(yù)測的輸出是紅色框的bbox,設(shè)bbox的中心坐標(biāo)為,那么最終預(yù)測出來的是經(jīng)過歸一化處理的,表示的是中心相對(duì)于單元格的offset,計(jì)算公式如下:
(w,h)是bbox相對(duì)于整個(gè)圖片的比例
預(yù)測的 bbox 的寬高為 ,表示的是 bbox 的是相對(duì)于整張圖片的占比,計(jì)算公式如下:
confidence
這個(gè)置信度是由兩部分組成,一是格子內(nèi)是否有目標(biāo),二是bbox的準(zhǔn)確度。定義置信度為 Object 。
這里,如果格子內(nèi)有物體,則 Object ,此時(shí)置信度等于IoU。如果格子內(nèi)沒有物體,則 Object ,此時(shí)置信度為0。
C類的條件概率
條件概率定義為 Class Object ,表示該單元格存在物體且屬于第 i 類的概率。
在測試的時(shí)候每個(gè)單元格預(yù)測最終輸出的概率定義為:
NMS
經(jīng)過網(wǎng)絡(luò)處理后,將 的結(jié)果送入 NMS ,最后即可得到最終的輸出框結(jié)果。
NMS,即非極大值抑制,就是將一些冗余框去掉,示意圖如下:

NMS 別看簡單,面試常考題,比如動(dòng)手實(shí)現(xiàn)一個(gè) NMS 代碼之類的。
這個(gè)概念千萬不要懵懵懂懂,細(xì)節(jié)決定成敗。省著被嘲諷:NMS都不會(huì),做什么Detection!

學(xué) NMS ,先要理解 IOU。
IOU 即Intersection over Union,也就是兩個(gè)box區(qū)域的交集比上并集,下面的示意圖就很好理解,用于確定兩個(gè)框的位置像素距離。
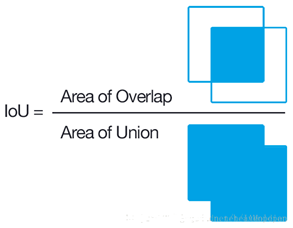
- 首先計(jì)算兩個(gè)box左上角點(diǎn)坐標(biāo)的最大值和右下角坐標(biāo)的最小值
- 然后計(jì)算交集面積
- 最后把交集面積除以對(duì)應(yīng)的并集面積
就這簡單,NMS 就是通過計(jì)算 IOU 來去除冗余框的,具體的實(shí)現(xiàn)思路如下。
以下圖為例,進(jìn)行說明:

就像上面的圖片一樣,定位一個(gè)車輛,最后算法就找出了一堆的方框,我們需要判別哪些矩形框是沒用的。
非極大值抑制的方法是:先假設(shè)有6個(gè)矩形框,根據(jù)分類器的類別分類概率做排序,假設(shè)從小到大屬于車輛的概率 分別為A、B、C、D、E、F。
(1)從最大概率矩形框F開始,分別判斷A~E與F的重疊度IOU是否大于某個(gè)設(shè)定的閾值;
(2)假設(shè)B、D與F的重疊度超過閾值,那么就扔掉B、D;并標(biāo)記第一個(gè)矩形框F,是我們保留下來的。
(3)從剩下的矩形框A、C、E中,選擇概率最大的E,然后判斷E與A、C的重疊度,重疊度大于一定的閾值,那么就扔掉;并標(biāo)記E是我們保留下來的第二個(gè)矩形框。
就這樣一直重復(fù),找到所有被保留下來的矩形框。
代碼實(shí)現(xiàn):
#?--------------------------------------------------------
#?Fast?R-CNN
#?Copyright?(c)?2015?Microsoft
#?Licensed?under?The?MIT?License?[see?LICENSE?for?details]
#?Written?by?Ross?Girshick
#?--------------------------------------------------------
import?numpy?as?np
def?py_cpu_nms(dets,?thresh):
????"""Pure?Python?NMS?baseline."""
????#x1、y1、x2、y2、以及score賦值
????x1?=?dets[:,?0]?????????????????????#?pred?bbox?top_x
????y1?=?dets[:,?1]?????????????????????#?pred?bbox?top_y
????x2?=?dets[:,?2]?????????????????????#?pred?bbox?bottom_x
????y2?=?dets[:,?3]?????????????????????#?pred?bbox?bottom_y
????scores?=?dets[:,?4]??????????????#?pred?bbox?cls?score
????#每一個(gè)檢測框的面積
????areas?=?(x2?-?x1?+?1)?*?(y2?-?y1?+?1)????#?pred?bbox?areas
????order?=?scores.argsort()[::-1]??????????????#?對(duì)pred?bbox按score做降序排序,對(duì)應(yīng)step-2
????#保留的結(jié)果框集合
????keep?=?[]????
????while?order.size?>?0:
????????i?=?order[0]??????????#?top-1?score?bbox
????????keep.append(i)???#保留該類剩余box中得分最高的一個(gè)
????????#得到相交區(qū)域,左上及右下
????????xx1?=?np.maximum(x1[i],?x1[order[1:]])???#?top-1?bbox(score最大)與order中剩余bbox計(jì)算NMS
????????yy1?=?np.maximum(y1[i],?y1[order[1:]])
????????xx2?=?np.minimum(x2[i],?x2[order[1:]])
????????yy2?=?np.minimum(y2[i],?y2[order[1:]])
????????
????????#計(jì)算相交的面積,不重疊時(shí)面積為0
????????w?=?np.maximum(0.0,?xx2?-?xx1?+?1)
????????h?=?np.maximum(0.0,?yy2?-?yy1?+?1)
????????inter?=?w?*?h
????????#計(jì)算IoU:重疊面積?/(面積1+面積2-重疊面積)
????????ovr?=?inter?/?(areas[i]?+?areas[order[1:]]?-?inter)
????????#保留IoU小于閾值的box
????????inds?=?np.where(ovr?<=?thresh)[0]?????#?這個(gè)操作可以對(duì)代碼斷點(diǎn)調(diào)試?yán)斫庀拢Y(jié)合step-3,我們希望剔除所有與當(dāng)前top-1?bbox?IoU?>?thresh的冗余bbox,那么保留下來的bbox,自然就是ovr?<=?thresh的非冗余bbox,其inds保留下來,作進(jìn)一步篩選
????????#因?yàn)閛vr數(shù)組的長度比order數(shù)組少一個(gè),所以這里要將所有下標(biāo)后移一位
????????order?=?order[inds?+?1]???#?保留有效bbox,就是這輪NMS未被抑制掉的幸運(yùn)兒,為什么?+ 1?因?yàn)閕nd =?0就是這輪NMS的top-1,剩余有效bbox在IoU計(jì)算中與top-1做的計(jì)算,inds對(duì)應(yīng)回原數(shù)組,自然要做?+1 的映射,接下來就是step-4的循環(huán)
????return?keep????#?最終NMS結(jié)果返回
if?__name__?==?'__main__':
????dets?=?np.array([[100,120,170,200,0.98],
?????????????????????[20,40,80,90,0.99],
?????????????????????[20,38,82,88,0.96],
?????????????????????[200,380,282,488,0.9],
?????????????????????[19,38,75,91,?0.8]])
????py_cpu_nms(dets,?0.5)
LOSS
從圖片 resize 到網(wǎng)絡(luò)結(jié)構(gòu),再到 NMS 都講完了,最后再說下算法的重中之重,損失函數(shù)。
損失函數(shù)是一個(gè)復(fù)合損失函數(shù),一共是 5 項(xiàng)相加:
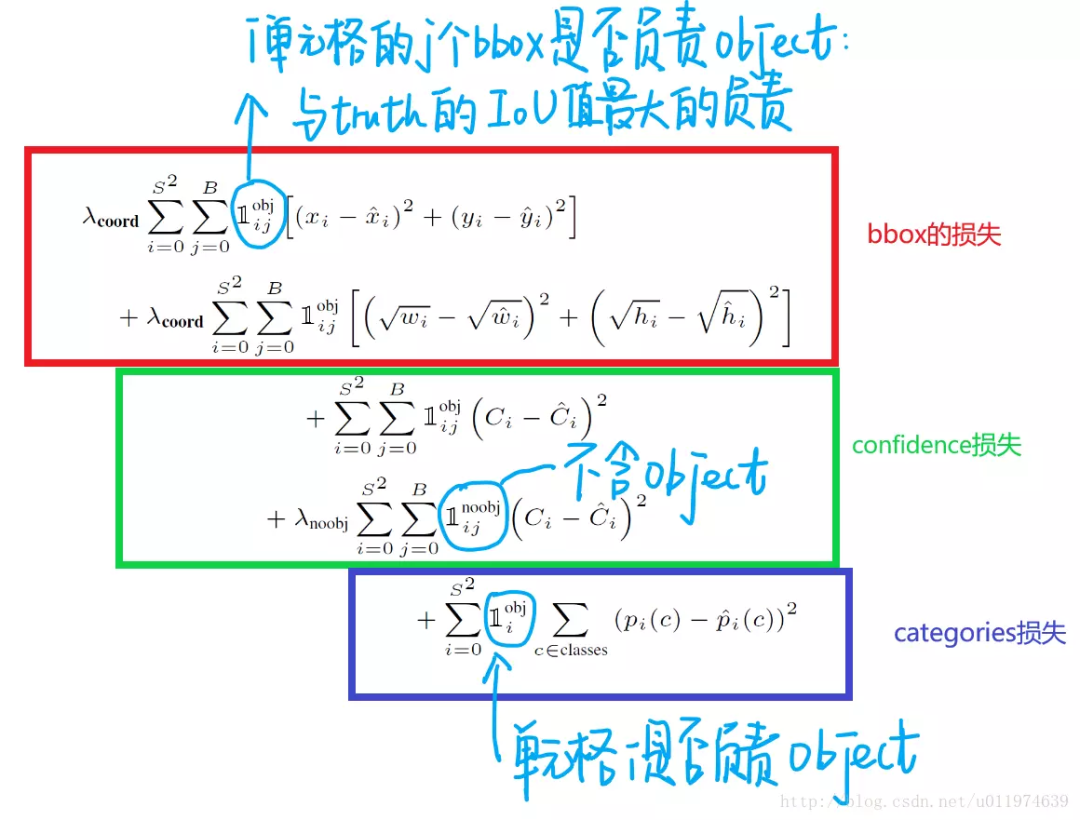
更詳細(xì)的注釋,可以看這張圖:

簡單解釋下:
所有的損失都是使用平方和誤差公式,暫時(shí)先不看公式中的 與 ,輸出的預(yù)測數(shù)值以及所造成的損失有:
- 預(yù)測框的中心點(diǎn) 。造成的損失是圖五中的第一行。其中 為控制函數(shù),在標(biāo)簽中包含物體的那些格點(diǎn)處,該值為 1 ;若格點(diǎn)不含有物體,該值為 0。也就是只對(duì)那些有真實(shí)物體所屬的格點(diǎn)進(jìn)行損失計(jì)算,若該格點(diǎn)不包含物體,那么預(yù)測數(shù)值不對(duì)損失函數(shù)造成影響。 數(shù)值與標(biāo)簽用簡單的平方和誤差。
- 預(yù)測框的寬高 。造成的損失是圖五的第二行。 的含義一樣,也是使得只有真實(shí)物體所屬的格點(diǎn)才會(huì)造成損失。這里對(duì) 在損失函數(shù)中的處理分別取了根號(hào),原因在于,如果不取根號(hào),損失函數(shù)往往更傾向于調(diào)整尺寸比較大的預(yù)測框。例如,20 個(gè)像素點(diǎn)的偏差,對(duì)于 800x600 的預(yù)測框幾乎沒有影響,此時(shí)的IOU數(shù)值還是很大,但是對(duì)于 30x40 的預(yù)測框影響就很大。取根號(hào)是為了盡可能的消除大尺寸框與小尺寸框之間的差異。
- 第三行與第四行,都是預(yù)測框的置信度C。當(dāng)該格點(diǎn)不含有物體時(shí),即 =1, 該置信度的標(biāo)簽為0;若含有物體時(shí),該置信度的標(biāo)簽為預(yù)測框與真實(shí)物體框的IOU數(shù)值(IOU計(jì)算公式為:兩個(gè)框交集的面積除以并集的面積)。
- 第五行為物體類別概率P,對(duì)應(yīng)的類別位置,該標(biāo)簽數(shù)值為1,其余位置為0,與分類網(wǎng)絡(luò)相同。
此時(shí)再來看 ? 與 ,YOLO 面臨的物體檢測問題,是一個(gè)典型的類別數(shù)目不均衡的問題。其中 49 個(gè)格點(diǎn),含有物體的格點(diǎn)往往只有 3、4 個(gè),其余全是不含有物體的格點(diǎn)。此時(shí)如果不采取點(diǎn)措施,那么物體檢測的mAP不會(huì)太高,因?yàn)槟P透鼉A向于不含有物體的格點(diǎn)。 與 的作用,就是讓含有物體的格點(diǎn),在損失函數(shù)中的權(quán)重更大,讓模型更加“重視”含有物體的格點(diǎn)所造成的損失。在論文中, 與 的取值分別為 5 與 0.5 。
最后
YOLO v1 的代碼實(shí)現(xiàn),有很多,Pytorch 和 Tensorflow 等各種版本都有,因?yàn)楫吘箤儆诔雒惴ā?/p>
Github 一搜,找個(gè) Star 高的即可。
本期硬核,歡迎轉(zhuǎn)發(fā)+再看,破200,周末加更 YOLO 系列!
我是 Jack,我們下期見~
 ·················END·················
·················END·················推薦閱讀
?? ?Python實(shí)現(xiàn)的導(dǎo)彈跟蹤算法,燃!?? ?看書vs視頻,我的一點(diǎn)小建議,共勉!????說實(shí)話,小時(shí)候我還挺有藝術(shù)細(xì)胞的