
前端成長進(jìn)階指北(網(wǎng)絡(luò)篇)
點擊上方 三分鐘學(xué)前端,關(guān)注公眾號
回復(fù)交流,加入前端編程面試算法每日一題群
嗨!各位早上好,三分鐘學(xué)前端來一波第一季度回顧與總結(jié),今天主講 網(wǎng)絡(luò) 篇 ,且已整理成了 pdf ,文末免費(fèi)獲取
下面進(jìn)入正文吧??
分別介紹下 http 和 tcp 協(xié)議,它們之間的區(qū)別與聯(lián)系
TCP 協(xié)議對應(yīng)于傳輸層,而 HTTP 協(xié)議對應(yīng)于應(yīng)用層,從本質(zhì)上來說,二者沒有可比性:
HTTP 對應(yīng)于應(yīng)用層,TCP 協(xié)議對應(yīng)于傳輸層 HTTP 協(xié)議是在 TCP 協(xié)議之上建立的,HTTP 在發(fā)起請求時通過 TCP 協(xié)議建立起連接服務(wù)器的通道,請求結(jié)束后,立即斷開 TCP 連接 HTTP 是無狀態(tài)的短連接,而 TCP 是有狀態(tài)的長連接 TCP是傳輸層協(xié)議,定義的是數(shù)據(jù)傳輸和連接方式的規(guī)范,HTTP是應(yīng)用層協(xié)議,定義的是傳輸數(shù)據(jù)的內(nèi)容的規(guī)范
一文走進(jìn) HTTP 與 TCP 協(xié)議,它們的區(qū)別與聯(lián)系
HTTP/2對比HTTP/1.1,特性是什么?是如何解決隊頭阻塞與壓縮頭部的?
自從 1997 年 HTTP/1.1 發(fā)布以來,我們已經(jīng)使用 HTTP/1.x 相當(dāng)長一段時間了,但近幾年內(nèi)容的爆炸式成長使得 HTTP/1.1 越來越無法滿足現(xiàn)代網(wǎng)絡(luò)的需求了,HTTP/1.1 協(xié)議的性能缺陷:
高延遲:頁面訪問速度下降 明文傳輸:不安全 無狀態(tài):頭部巨大切重復(fù) 不支持服務(wù)器推送 HTTP/1.x 為了性能考慮,會引入雪碧圖、將小圖內(nèi)聯(lián)、使用多個域名等等的方式,但還是有一些關(guān)鍵點無法優(yōu)化,例如HTTP頭部巨大且重復(fù)、明文傳輸不安全、服務(wù)器不能主動推送等,要改變這些必須重新設(shè)計 HTTP 協(xié)議,于是 HTTP/2 就出來了!
2015 年,HTTP/2 發(fā)布。HTTP/2 是現(xiàn)行 HTTP 協(xié)議(HTTP/1.x)的替代,但它不是重寫,HTTP 方法 / 狀態(tài)碼 / 語義都與 HTTP/1.x 一樣。HTTP/2 基于 SPDY,專注于性能,最大的目標(biāo)是在用戶和網(wǎng)站間只用一個連接(connec-tion)。
二進(jìn)制傳輸 Header 壓縮(HPACK) 多路復(fù)用 服務(wù)端 Push 提高安全性 HTTP/2 遺留問題:
HTTP/2 也存在隊頭阻塞問題,比如丟包。 慢啟動
HTTP/2對比HTTP/1.1,新特性是什么?是如何解決隊頭阻塞與壓縮頭部的?
說一下HTTP/3新特性,為什么選擇使用UDP協(xié)議?
HTTP/2 使用二進(jìn)制傳輸、Header 壓縮(HPACK)、多路復(fù)用等,相較于 HTTP/1.1 大幅提高了數(shù)據(jù)傳輸效率,但它仍然存在著以下幾個致命問題(主要由底層支撐的 TCP 協(xié)議造成):
建立連接時間長 隊頭阻塞問題相較于 HTTP/1.1 更嚴(yán)重 而修改 TCP 協(xié)議已經(jīng)是一件不可能完成的任務(wù),所以Google 就更起爐灶搞了一個基于 UDP 協(xié)議的 QUIC 協(xié)議:
基于 TCP 開發(fā)的設(shè)備和協(xié)議非常多,兼容困難 TCP 協(xié)議棧是 Linux 內(nèi)部的重要部分,修改和升級成本很大 UDP 本身是無連接的、沒有建鏈和拆鏈成本 UDP 的數(shù)據(jù)包無隊頭阻塞問題 UDP 改造成本小 QUIC 雖然基于 UDP,但是在原本的基礎(chǔ)上新增了很多功能,比如多路復(fù)用、0-RTT、使用 TLS1.3 加密、流量控制、有序交付、重傳等等功能
說一下 HTTP/3 新特性,為什么選擇使用 UDP 協(xié)議?
有關(guān) HTTP 緩存的首部字段說一下
常見的HTTP 緩存首部字段有:
Expires:響應(yīng)頭,代表該資源的過期時間 Cache-Control:請求/響應(yīng)頭,緩存控制字段,精確控制緩存策略 If-Modified-Since:請求頭,資源最近修改時間,由瀏覽器告訴服務(wù)器 Last-Modified:響應(yīng)頭,資源最近修改時間,由服務(wù)器告訴瀏覽器 Etag:響應(yīng)頭,資源標(biāo)識,由服務(wù)器告訴瀏覽器 If-None-Match:請求頭,緩存資源標(biāo)識,由瀏覽器告訴服務(wù)器 其中, 強(qiáng)緩存 :
Expires(HTTP/1.0) Cache-Control(HTTP/1.1) 協(xié)商緩存:
Last-Modified 和 If-Modified-Since(HTTP/1.0) ETag 和 If-None-Match(HTTP/1.1)
了解 HTTP 緩存嗎?有關(guān) HTTP 緩存的首部字段說一下 ?
HTTP 常見的響應(yīng)碼,拒絕服務(wù)資源是哪個?
RFC 把狀態(tài)碼分成五類,分別是:
1××: 請求已被接受正被處理,表示目前是協(xié)議處理的中間狀態(tài),還需要后續(xù)的操作 2××: 請求成功處理,報文已經(jīng)收到并被正確處理 3××: 代表需要客戶端采取進(jìn)一步的操作才能完成請求,例如重定向,通常,這些狀態(tài)碼用來重定向,后續(xù)的請求地址(重定向目標(biāo))在本次響應(yīng)的Location域中指明 4××: 客戶端錯誤,請求報文有誤,服務(wù)器無法處理 5××: 服務(wù)器錯誤,服務(wù)器在處理請求時內(nèi)部發(fā)生了錯誤 容易爭論的點:
301、302 和 307區(qū)別(對 SEO 的影響) 401 和 404 的區(qū)別
HTTP 中的 keep-alive 有了解嗎?它和多路復(fù)用的區(qū)別
HTTP/1.x keep-alive 與 HTTP/2 多路復(fù)用區(qū)別:
HTTP/1.x 是基于文本的,只能整體去傳;HTTP/2 是基于二進(jìn)制流的,可以分解為獨(dú)立的幀,交錯發(fā)送 HTTP/1.x keep-alive 必須按照請求發(fā)送的順序返回響應(yīng);HTTP/2 多路復(fù)用不按序響應(yīng) HTTP/1.x keep-alive 為了解決隊頭阻塞,將同一個頁面的資源分散到不同域名下,開啟了多個 TCP 連接;HTTP/2 同域名下所有通信都在單個連接上完成 HTTP/1.x keep-alive 單個 TCP 連接在同一時刻只能處理一個請求(兩個請求的生命周期不能重疊);HTTP/2 單個 TCP 同一時刻可以發(fā)送多個請求和響應(yīng)
了解 HTTP/1.x 的 keep-alive 嗎?它與 HTTP/2 多路復(fù)用的區(qū)別是什么?
http header怎么判斷協(xié)議是不是 websocket
WebSocket 使用
ws或wss的統(tǒng)一資源標(biāo)志符,通過判斷 header 中是否包含Connection: Upgrade與Upgrade: websocket來判斷當(dāng)前是否需要升級到 websocket 協(xié)議,除此之外,它還包含Sec-WebSocket-Key、Sec-WebSocket-Version等header,當(dāng)服務(wù)器同意 WebSocket 連接時,返回響應(yīng)碼101,它的 API 很簡單。方法:
socket.send(data)socket.close([code], [reason])事件:
openmessageerrorclose
http header 怎么判斷協(xié)議是不是 websocket
GET 與 POST 區(qū)別是什么?
w3school 給出的標(biāo)準(zhǔn)答案:
GET POST 后退按鈕/刷新 無害 數(shù)據(jù)會被重新提交(瀏覽器應(yīng)該告知用戶數(shù)據(jù)會被重新提交)。 書簽 可收藏為書簽 不可收藏為書簽 緩存 能被緩存 不能緩存 編碼類型 application/x-www-form-urlencoded application/x-www-form-urlencoded 或 multipart/form-data。為二進(jìn)制數(shù)據(jù)使用多重編碼。 歷史 參數(shù)保留在瀏覽器歷史中。 參數(shù)不會保存在瀏覽器歷史中。 對數(shù)據(jù)長度的限制 是的。當(dāng)發(fā)送數(shù)據(jù)時,GET 方法向 URL 添加數(shù)據(jù);URL 的長度是受限制的(URL 的最大長度是 2048 個字符)。 無限制。 對數(shù)據(jù)類型的限制 只允許 ASCII 字符。 沒有限制。也允許二進(jìn)制數(shù)據(jù)。 安全性 與 POST 相比,GET 的安全性較差,因為所發(fā)送的數(shù)據(jù)是 URL 的一部分。在發(fā)送密碼或其他敏感信息時絕不要使用 GET ! POST 比 GET 更安全,因為參數(shù)不會被保存在瀏覽器歷史或 web 服務(wù)器日志中。 可見性 數(shù)據(jù)在 URL 中對所有人都是可見的。 數(shù)據(jù)不會顯示在 URL 中。 從 HTTP 協(xié)議上看,GET 與 POST 的本質(zhì)區(qū)別有兩點:
請求行不同: GET:GET /uri HTTP/1.1 POST:POST /uri HTTP/1.1 對服務(wù)器資源的操作不同: GET:表示從服務(wù)器獲取資源 POST:向指定的服務(wù)器資源提交數(shù)據(jù)(通常導(dǎo)致狀態(tài)或服務(wù)器上的副作用的更改) 進(jìn)階:常見問題及解答:
POST 方法比 GET 方法安全? POST 方法會產(chǎn)生兩個 TCP 數(shù)據(jù)包?
你真的了解 GET 和 POST 嗎,它們的區(qū)別是什么?
session 和 cookie 的區(qū)別
安全性: Session 比 Cookie 安全,Session 是存儲在服務(wù)器端的,Cookie 是存儲在客戶端的。 存取值的類型不同:Cookie 只支持存字符串?dāng)?shù)據(jù),想要設(shè)置其他類型的數(shù)據(jù),需要將其轉(zhuǎn)換成字符串,Session 可以存任意數(shù)據(jù)類型。 有效期不同: Cookie 可設(shè)置為長時間保持,比如我們經(jīng)常使用的默認(rèn)登錄功能,Session 一般失效時間較短,客戶端關(guān)閉(默認(rèn)情況下)或者 Session 超時(一般30分鐘無操作)都會失效。 存儲大小不同: 單個 Cookie 保存的數(shù)據(jù)不能超過 4K,Session 可存儲數(shù)據(jù)遠(yuǎn)高于 Cookie,但是當(dāng)訪問量過多,會占用過多的服務(wù)器資源。
傻傻分不清之 Cookie、Session、Token、JWT
如果讓你去實現(xiàn)一個 CSRF 攻擊你會怎么做?
了解 CSRF 常見的攻擊方式,模擬攻擊就很簡單了,幾種常見的攻擊方式:
自動發(fā)起 GET 請求的 CSRF 自動發(fā)起 POST 請求的 CSRF 引誘用戶點擊鏈接的 CSRF 防護(hù)策略:
利用 Cookie 的 SameSite 屬性 利用同源策略 Token 認(rèn)證
除了CSRF,你還知道其它的攻擊方式嗎?
我所了解的,除了 CSRF ,還有:
XSS 攻擊 SQL 注入攻擊 DDoS 攻擊 上傳文件漏洞 DNS 查詢攻擊 結(jié)合上篇 如果讓你去實現(xiàn)一個 CSRF 攻擊你會怎么做? ,總共介紹了六種 web 攻擊與防護(hù),其中最重要的是 CSRF 攻擊、 XSS 攻擊,其余只做了解即可。
為什么說 HTTPS 比 HTTP 安全呢
HTTP 協(xié)議使用起來非常的方便,但是它存在一個致命的缺點:
不安全。HTTPS并非是應(yīng)用層的一種新協(xié)議,其實是 HTTP+SSL/TLS 的簡稱HTTP 和 HTTPS 的區(qū)別:
HTTP 是超文本傳輸協(xié)議,信息是明文傳輸,HTTPS 則是具有安全性的TLS(SSL)加密傳輸協(xié)議 HTTP 和 HTTPS 使用的是完全不同的連接方式,用的端口也不一樣,前者是80,后者是443 HTTP 的連接很簡單,是無狀態(tài)的;HTTPS協(xié)議是由 HTTP+SSL/TLS 協(xié)議構(gòu)建的可進(jìn)行加密傳輸、身份認(rèn)證的網(wǎng)絡(luò)協(xié)議,比 HTTPS 協(xié)議安全。 針對抓包問題,HTTPS 可以防止用戶在不知情的情況下通信鏈路被監(jiān)聽,對于主動授信的抓包操作是不提供防護(hù)的,因為這個場景用戶是已經(jīng)對風(fēng)險知情。
DNS 協(xié)議是什么?完整查詢過程?為什么選擇使用 UDP 協(xié)議發(fā)起 DNS 查詢?
DNS(Domain Name System:域名系統(tǒng)),與 HTTP、FTP 和 SMTP 一樣,DNS 協(xié)議也是應(yīng)用層的協(xié)議,用于將用戶提供的主機(jī)名(域名)解析為 IP 地址
DNS完整查詢過程??:
首先搜索 瀏覽器的 DNS 緩存 ,緩存中維護(hù)一張域名與 IP 地址的對應(yīng)表 如果沒有命中??,則繼續(xù)搜索 操作系統(tǒng)的 DNS 緩存 如果依然沒有命中???♀?,則操作系統(tǒng)將域名發(fā)送至 本地域名服務(wù)器 ,本地域名服務(wù)器查詢自己的 DNS 緩存,查找成功則返回結(jié)果(注意:主機(jī)和本地域名服務(wù)器之間的查詢方式是 遞歸查詢 ) 若本地域名服務(wù)器的 DNS 緩存沒有命中???,則本地域名服務(wù)器向上級域名服務(wù)器進(jìn)行查詢,通過以下方式進(jìn)行 迭代查詢 (注意:本地域名服務(wù)器和其他域名服務(wù)器之間的查詢方式是迭代查詢,防止根域名服務(wù)器壓力過大):
首先本地域名服務(wù)器向根域名服務(wù)器發(fā)起請求,根域名服務(wù)器是最高層次的,它并不會直接指明這個域名對應(yīng)的 IP 地址,而是返回頂級域名服務(wù)器的地址,也就是說給本地域名服務(wù)器指明一條道路,讓他去這里尋找答案 本地域名服務(wù)器拿到這個頂級域名服務(wù)器的地址后,就向其發(fā)起請求,獲取權(quán)限域名服務(wù)器的地址 本地域名服務(wù)器根據(jù)權(quán)限域名服務(wù)器的地址向其發(fā)起請求,最終得到該域名對應(yīng)的 IP 地址
本地域名服務(wù)器 將得到的 IP 地址返回給操作系統(tǒng),同時自己將 IP 地址 緩存 起來?? 操作系統(tǒng) 將 IP 地址返回給瀏覽器,同時自己也將 IP 地址 緩存 起來?? 至此, 瀏覽器 就得到了域名對應(yīng)的 IP 地址,并將 IP 地址 緩存 起來?? 需要注意的是,DNS 使用了 UDP 協(xié)議來獲取域名對應(yīng)的 IP 地址,這個沒錯,但有些片面,準(zhǔn)確的來說,DNS 查詢在剛設(shè)計時主要使用 UDP 協(xié)議進(jìn)行通信,而 TCP 協(xié)議也是在 DNS 的演進(jìn)和發(fā)展中被加入到規(guī)范的:
DNS 在設(shè)計之初就在區(qū)域 傳輸中引入了 TCP 協(xié)議 , 在查詢中使用 UDP 協(xié)議 ,它同時占用了 UDP 和 TCP 的 53 端口 當(dāng) DNS 超過了 512 字節(jié)的限制,我們第一次在 DNS 協(xié)議中明確了 『當(dāng) DNS 查詢被截斷時,應(yīng)該使用 TCP 協(xié)議進(jìn)行重試』 這一規(guī)范; 隨后引入的 EDNS 機(jī)制允許我們使用 UDP 最多傳輸 4096 字節(jié)的數(shù)據(jù),但是由于 MTU 的限制導(dǎo)致的數(shù)據(jù)分片以及丟失,使得這一特性不夠可靠; 在最近的幾年,我們重新規(guī)定了 DNS 應(yīng)該同時支持 UDP 和 TCP 協(xié)議,TCP 協(xié)議也不再只是重試時的選擇;
DNS 協(xié)議是什么?完整查詢過程?為什么選擇使用 UDP 協(xié)議發(fā)起 DNS 查詢?
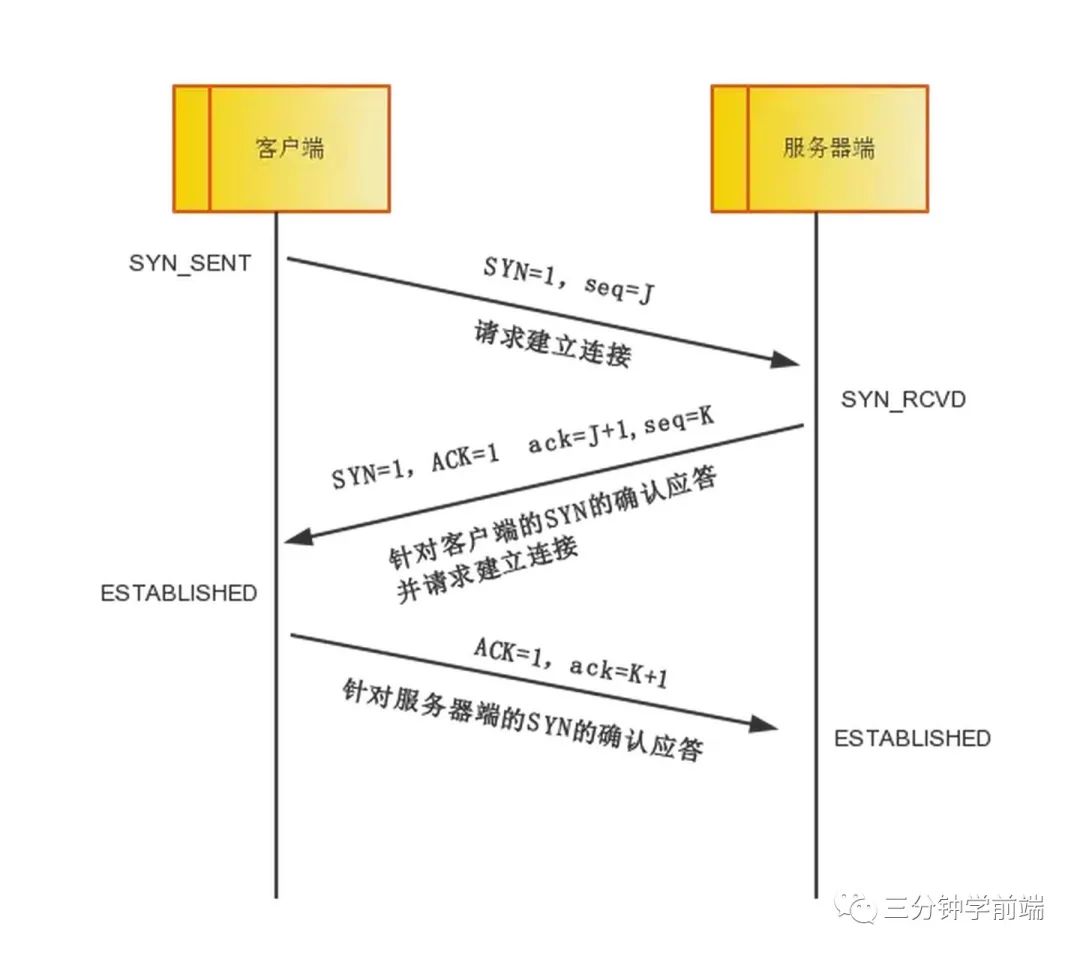
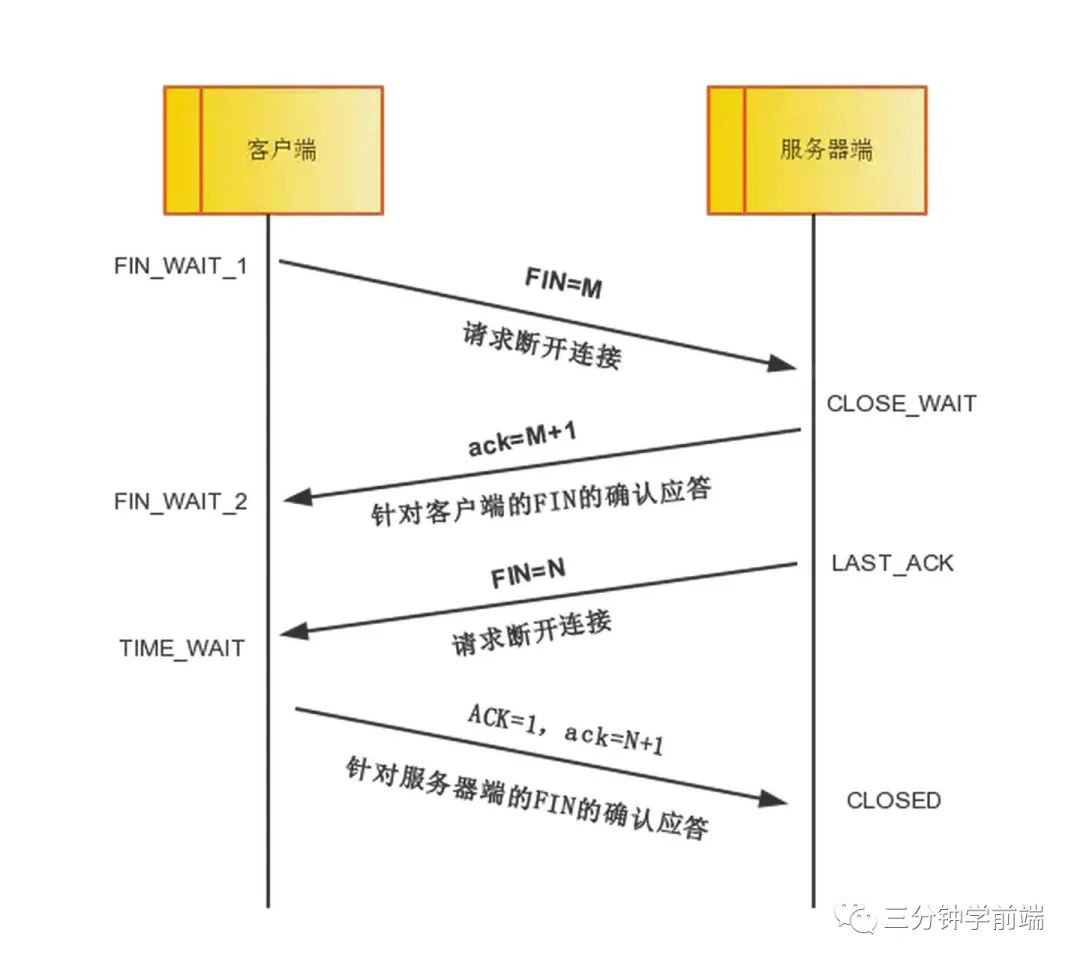
TCP 的三次握手和四次揮手,了解泛洪攻擊么
TCP 三次握手(連接過程)
TCP 四次揮手(斷開鏈接)
我們已經(jīng)知道,TCP 只有經(jīng)過三次握手才能連接,而 SYN 泛洪攻擊就是針對 TCP 握手過程進(jìn)行攻擊:
攻擊者發(fā)送大量的 SYN 包給服務(wù)器(第一次握手成功) 服務(wù)器回應(yīng)(SYN + ACK)包(第二次握手成功) 但是攻擊者不回應(yīng) ACK 包(第三次握手不進(jìn)行) 導(dǎo)致服務(wù)器存在大量的半開連接,這些半連接可以耗盡服務(wù)器資源,使被攻擊服務(wù)器無法再響應(yīng)正常 TCP 連接,從而達(dá)到攻擊的目的
關(guān)注「三分鐘學(xué)前端」
回復(fù)「網(wǎng)絡(luò)」,自動獲取三分鐘學(xué)前端網(wǎng)絡(luò)篇小書(90+頁)
回復(fù)「JS」,自動獲取三分鐘學(xué)前端 JS 篇小書(120+頁)
回復(fù)「算法」,自動獲取 github 2.9k+ 的前端算法小書
回復(fù)「面試」,自動獲取 github 23.2k+ 的前端面試小書
回復(fù)「簡歷」,自動獲取程序員系列的 120 套模版
最近開源了一個github倉庫:百問百答,在工作中很難做到對社群問題進(jìn)行立即解答,所以可以將問題提交至 https://github.com/Advanced-Frontend/Just-Now-QA ,我會在每晚花費(fèi) 1 個小時左右進(jìn)行處理,更多的是鼓勵與歡迎更多人一起參與探討與解答??