
Linux內(nèi)核系統(tǒng)架構(gòu)介紹
28年前(1991年8月26日)Linus公開(kāi)Linux的代碼,開(kāi)啟了一個(gè)偉大的時(shí)代。這篇文章從進(jìn)程調(diào)度,內(nèi)存管理,設(shè)備驅(qū)動(dòng),文件系統(tǒng),網(wǎng)絡(luò)等方面講解Linux內(nèi)核系統(tǒng)架構(gòu)。Linux的系統(tǒng)架構(gòu)是一個(gè)經(jīng)典的設(shè)計(jì),它優(yōu)秀的分層和模塊化,融合了數(shù)量繁多的設(shè)備和不同的物理架構(gòu),讓世界各地的內(nèi)核開(kāi)發(fā)者能夠高效并行工作。先來(lái)看看Linus在多年前公開(kāi)Linux的郵件。
"Hello everybody out there using minix - I’m doing a (free) operating system (just a hobby, won’t be big and professional like gnu) for 386(486) AT clones. This has been brewing since april, and is starting to get ready. I’d like any feedback on things people like/dislike in minix, as my OS resembles it somewhat (same physical layout of the ?le-system (due to practical reasons) among other things).
I’ve currently ported bash(1.08) and gcc(1.40), and things seem to work. This implies that I’ll get something practical within a few months, and I’d like to know what features most people would want. Any suggestions are welcome, but I won’t promise I’ll implement them :-)
Linus ([email protected].?)"
事實(shí)上,從那一天開(kāi)始,Linux便是博采眾長(zhǎng),融合了非常多的優(yōu)秀設(shè)計(jì)。在了解操作系統(tǒng)的時(shí)候,我們至少需要知道:1. 操作系統(tǒng)是如何管理各種資源的?2. 軟硬件如何協(xié)同工作?3. 如何通過(guò)抽象化屏蔽差異 4. 軟硬件如何分工?這篇文章通過(guò)對(duì)內(nèi)核主要模塊的介紹,希望能為大家尋找這些問(wèn)題的答案起一個(gè)拋磚引玉的作用。實(shí)際上,建議每一個(gè)希望成為技術(shù)專家的人都讀一遍L(zhǎng)inux的源代碼。
先來(lái)看看Linux內(nèi)核一個(gè)高階架構(gòu)圖:
Linux系統(tǒng)架構(gòu)圖
架構(gòu)非常清晰,從硬件層,硬件抽象層,內(nèi)核基礎(chǔ)模塊(進(jìn)程調(diào)度,內(nèi)存管理,網(wǎng)絡(luò)協(xié)議棧等)到應(yīng)用層,這個(gè)基本上也是各類軟硬件結(jié)合的系統(tǒng)架構(gòu)的基礎(chǔ)設(shè)計(jì),例如物聯(lián)網(wǎng)系統(tǒng)(從單片機(jī),MCU等小型嵌入式系統(tǒng),到智能家居,智慧社區(qū)甚至智慧城市)在接入端設(shè)備的可參考架構(gòu)模型。
Linux最初是運(yùn)行在PC機(jī)上的,使用的x86架構(gòu)處理器相對(duì)來(lái)說(shuō)比較強(qiáng)大,各類指令和模式也比較齊全。例如我們看到的用戶態(tài)和內(nèi)核態(tài),在一般的小型嵌入式處理器上是沒(méi)有的,它的好處是通過(guò)將代碼和數(shù)據(jù)段(segment)給予不同的權(quán)限,保護(hù)內(nèi)核態(tài)的代碼和數(shù)據(jù)(包括硬件資源)必須通過(guò)類似系統(tǒng)調(diào)用(SysCall)的方式才能訪問(wèn),確保內(nèi)核的穩(wěn)定。
想象一下,如果需要你寫(xiě)一個(gè)操作系統(tǒng),有哪些因素需要考慮?
進(jìn)程管理:如何在多任務(wù)系統(tǒng)中按照調(diào)度算法分配CPU的時(shí)間片。
內(nèi)存管理:如何實(shí)現(xiàn)虛擬內(nèi)存和物理內(nèi)存的映射,分配和回收內(nèi)存。
文件系統(tǒng):如何將硬盤(pán)的扇區(qū)組織成文件系統(tǒng),實(shí)現(xiàn)文件的讀寫(xiě)等操作。
設(shè)備管理:如何尋址,訪問(wèn),讀,寫(xiě)設(shè)備配置信息和數(shù)據(jù)。
這些概念是操作系統(tǒng)的核心概念,由于篇幅原因,本文章主要從高階的角度來(lái)講,更多細(xì)節(jié)不在本文覆蓋。
進(jìn)程管理
進(jìn)程在不同的操作系統(tǒng)中有些稱為process,有些稱為task。操作系統(tǒng)中進(jìn)程數(shù)據(jù)結(jié)構(gòu)包含了很多元素,往往用鏈表連接。
進(jìn)程相關(guān)的內(nèi)容主要包括:虛擬地址空間,優(yōu)先級(jí),生命周期(阻塞,就緒,運(yùn)行等),占有的資源(例如信號(hào)量,文件等)。
CPU在每個(gè)系統(tǒng)滴答(Tick)中斷產(chǎn)生的時(shí)候檢查就緒隊(duì)列里面的進(jìn)程(遍歷鏈表中的進(jìn)程結(jié)構(gòu)體),如有符合調(diào)度算法的新進(jìn)程需要切換,保存當(dāng)前運(yùn)行的進(jìn)程的信息(包括棧信息等)后掛起當(dāng)前進(jìn)程,選擇新的進(jìn)程運(yùn)行,這就是進(jìn)程調(diào)度。
進(jìn)程的優(yōu)先級(jí)差異是CPU調(diào)度的基本依據(jù),調(diào)度的終極目標(biāo)是讓高優(yōu)先級(jí)的活動(dòng)能夠即時(shí)得到CPU的計(jì)算資源(即時(shí)響應(yīng)),低優(yōu)先級(jí)的任務(wù)也能公平分配到CPU資源。因?yàn)樾枰4孢M(jìn)程運(yùn)行的上下文(process context)等,進(jìn)程的切換本身是有成本的,調(diào)度算法在進(jìn)程切換頻率上也需要考慮效率。
在早期的Linux操作系統(tǒng)中,主要采用的是時(shí)間片輪轉(zhuǎn)算法(Round-Robin),內(nèi)核在就緒的進(jìn)程隊(duì)列中選擇高優(yōu)先級(jí)的進(jìn)程運(yùn)行,每次運(yùn)行相等的時(shí)間。該算法簡(jiǎn)單直觀,但仍然會(huì)導(dǎo)致某些低優(yōu)先級(jí)的進(jìn)程長(zhǎng)時(shí)間無(wú)法得到調(diào)度。為了提高調(diào)度的公平性,在Linux 2.6.23之后,引入了稱為完全公平調(diào)度器CFS(Completely Fair Scheduler)。
CPU在任何時(shí)間點(diǎn)只能運(yùn)行一個(gè)程序,用戶在使用優(yōu)酷APP看視頻時(shí),同時(shí)在微信中打字聊天,優(yōu)酷和微信是兩個(gè)不同的程序,為什么看起來(lái)像是在同時(shí)運(yùn)行?CFS的目標(biāo)就是讓所有的程序看起來(lái)都是以相同的速度在多個(gè)并行的CPU上運(yùn)行,即nr_running個(gè)運(yùn)行的進(jìn)程,每個(gè)進(jìn)程以1/nr_running的速度并發(fā)執(zhí)行,例如如有2個(gè)可運(yùn)行的任務(wù),那么每個(gè)以50%的CPU物理能力并發(fā)執(zhí)行。
CFS引入了"虛擬運(yùn)行時(shí)間"的概念,虛擬運(yùn)行時(shí)間用p->se.vruntime (nanosec-unit) 表示,通過(guò)它記錄和度量任務(wù)應(yīng)該獲得的"CPU時(shí)間"。在理想的調(diào)度情況下,任何時(shí)候所有的任務(wù)都應(yīng)該有相同的p->se.vruntime值(上面提到的以相同的速度運(yùn)行)。因?yàn)槊總€(gè)任務(wù)都是并發(fā)執(zhí)行的,沒(méi)有任務(wù)會(huì)超過(guò)理想狀態(tài)下應(yīng)該占有的CPU時(shí)間。CFS選擇需要運(yùn)行的任務(wù)的邏輯基于p->se.vruntime值,非常簡(jiǎn)單:它總是挑選p->se.vruntime值最小的任務(wù)運(yùn)行(最少被調(diào)度到的任務(wù))。
CFS使用了基于時(shí)間排序的紅黑樹(shù)來(lái)為將來(lái)任務(wù)的執(zhí)行排時(shí)間線。所有的任務(wù)按p->se.vruntime關(guān)鍵字排序。CFS從樹(shù)中選擇最左邊的任務(wù)執(zhí)行。隨著系統(tǒng)運(yùn)行,執(zhí)行過(guò)的任務(wù)會(huì)被放到樹(shù)的右邊,逐步地地讓每個(gè)任務(wù)都有機(jī)會(huì)成為最左邊的任務(wù),從而在一個(gè)可確定的時(shí)間內(nèi)獲得CPU資源。
總結(jié)來(lái)說(shuō),CFS首先運(yùn)行一個(gè)任務(wù),當(dāng)任務(wù)切換(或者Tick中斷發(fā)生的時(shí)候)時(shí),該任務(wù)使用的CPU時(shí)間會(huì)加到p->se.vruntime里,當(dāng)p->se.vruntime的值逐漸增大到別的任務(wù)變成了紅黑樹(shù)最左邊的任務(wù)時(shí)(同時(shí)在該任務(wù)和最左邊任務(wù)間增加一個(gè)小的粒度距離,防止過(guò)度切換任務(wù),影響性能),最左邊的任務(wù)被選中執(zhí)行,當(dāng)前的任務(wù)被搶占。
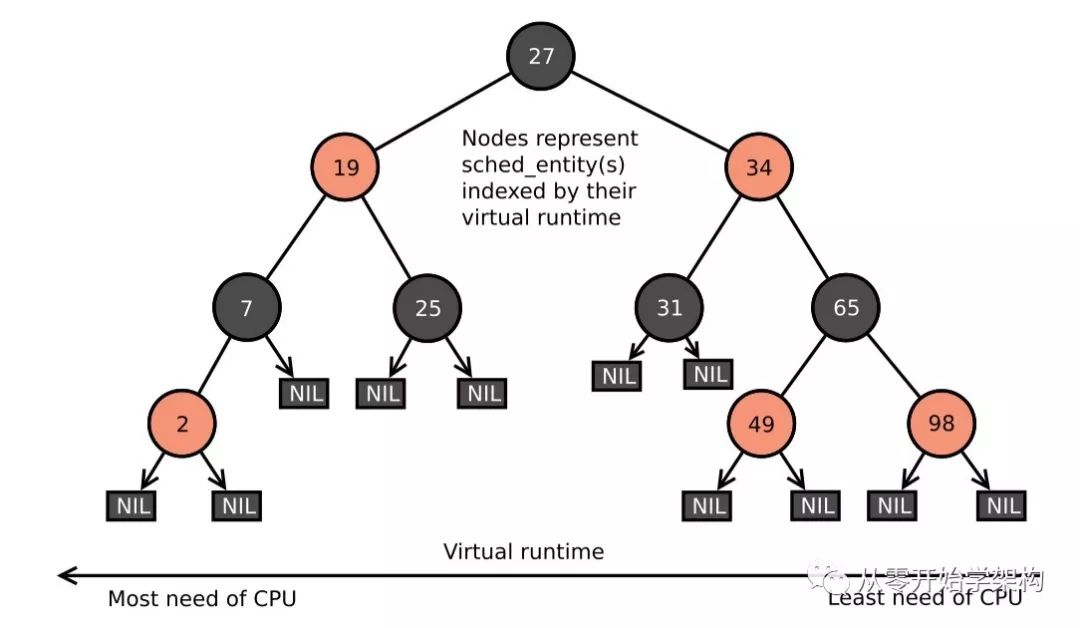
CFS紅黑樹(shù)
一般來(lái)說(shuō),調(diào)度器處理單個(gè)任務(wù),且盡可能為每個(gè)任務(wù)提供公平的CPU時(shí)間。某些時(shí)候,可能需要將任務(wù)分組,并為每個(gè)組提供公平的CPU時(shí)間。例如,系統(tǒng)可以為每個(gè)用戶分配平均的CPU時(shí)間后,再為每個(gè)用戶的每個(gè)任務(wù)分配平均的CPU時(shí)間。
內(nèi)存管理
內(nèi)存本身是一個(gè)外部存儲(chǔ)設(shè)備,系統(tǒng)需要對(duì)內(nèi)存區(qū)域?qū)ぶ罚业綄?duì)應(yīng)的內(nèi)存單元(memory cell),讀寫(xiě)其中的數(shù)據(jù)。
內(nèi)存區(qū)域通過(guò)指針尋址,CPU的字節(jié)長(zhǎng)度(32bit機(jī)器,64bit機(jī)器)決定了最大的可尋址地址空間。在32位機(jī)器上最大的尋址空間是4GBtyes。在64位機(jī)器上理論上有2^64Bytes。
最大的地址空間和實(shí)際系統(tǒng)有多少物理內(nèi)存無(wú)關(guān),所以稱為虛擬地址空間。對(duì)系統(tǒng)中所有的進(jìn)程來(lái)說(shuō),看起來(lái)每個(gè)進(jìn)程都獨(dú)立占有這個(gè)地址空間,且它無(wú)法感知其它進(jìn)程的內(nèi)存空間。事實(shí)上操作系統(tǒng)讓應(yīng)用程序無(wú)需關(guān)注其它應(yīng)用程序,看起來(lái)每個(gè)任務(wù)都是這個(gè)電腦上運(yùn)行的唯一進(jìn)程。
Linux將虛擬地址空間分為內(nèi)核空間和用戶空間。每個(gè)用戶進(jìn)程的虛擬空間范圍從0到TASK_SIZE。從TASK_SIZE到2^32或2^64的區(qū)域保留給內(nèi)核,不能被用戶進(jìn)程訪問(wèn)。TASK_SIZE可以配置,Linux系統(tǒng)默認(rèn)配置3:1,應(yīng)用程序使用3GB的空間,內(nèi)核使用1GB的空間,這個(gè)劃分并不依賴實(shí)際RAM的大小。在64位機(jī)器上,虛擬地址空間的范圍可以非常大,但實(shí)際上只使用其中42位或47位(2^42或2^47)。
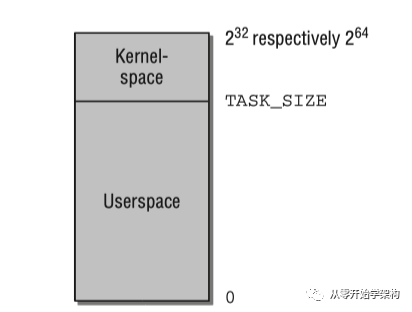
虛擬地址空間
絕大多數(shù)情況下,虛擬地址空間比實(shí)際系統(tǒng)可用的物理內(nèi)存(RAM)大,內(nèi)核和CPU必須考慮如何將實(shí)際可用的物理內(nèi)存映射到虛擬地址空間。
一個(gè)方法是通過(guò)頁(yè)表(Page Table)將虛擬地址映射到物理地址。虛擬地址與進(jìn)程使用的用戶&內(nèi)核地址相關(guān),物理地址用來(lái)尋址實(shí)際使用的RAM。
如下圖所示,進(jìn)程A和B的虛擬地址空間被分為大小相等的部分,稱為頁(yè)(page)。物理內(nèi)存同樣被分割為大小相等的頁(yè)(page frame)。
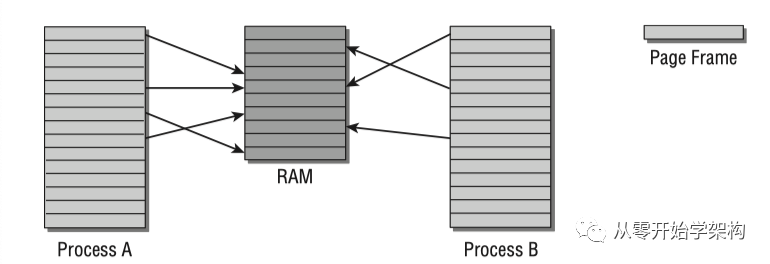
虛擬和物理地址空間映射
進(jìn)程A第1個(gè)內(nèi)存頁(yè)映射到物理內(nèi)存(RAM)的第4頁(yè);進(jìn)程B第1個(gè)內(nèi)存頁(yè)映射到物理內(nèi)存第5頁(yè)。進(jìn)程A第5個(gè)內(nèi)存頁(yè)和進(jìn)程B第1個(gè)內(nèi)存頁(yè)都映射到物理內(nèi)存的第5頁(yè)(內(nèi)核可決定哪些內(nèi)存空間被不同進(jìn)程共享)。
如圖所示,并不是每個(gè)虛擬地址空間的頁(yè)都與某個(gè)page frame關(guān)聯(lián),該頁(yè)可能并未使用或者數(shù)據(jù)還沒(méi)有被加載到物理內(nèi)存(暫時(shí)不需要),也可能因?yàn)槲锢韮?nèi)存頁(yè)被置換到了硬盤(pán)上,后續(xù)實(shí)際再需要的時(shí)候再被置換回內(nèi)存。
頁(yè)表(page table)將虛擬地址空間映射到物理地址空間。最簡(jiǎn)單的做法是用一個(gè)數(shù)組將虛擬頁(yè)和物理頁(yè)一一對(duì)應(yīng),但是這樣做可能需要消耗整個(gè)RAM本身來(lái)保存這個(gè)頁(yè)表,假設(shè)每個(gè)頁(yè)大小為4KB,虛擬地址空間大小為4GB,需要一個(gè)1百萬(wàn)個(gè)元素的數(shù)組來(lái)保存頁(yè)表。
因?yàn)樘摂M地址空間的絕大多數(shù)區(qū)域?qū)嶋H并沒(méi)有使用,這些頁(yè)實(shí)際并沒(méi)有和page frame關(guān)聯(lián),引入多級(jí)頁(yè)表(multilevel paging)能極大降低頁(yè)表使用的內(nèi)存,提高查詢效率。關(guān)于多級(jí)頁(yè)表的細(xì)節(jié)描述可以參考文后參考資料。
內(nèi)存映射(memory mapping)是一個(gè)重要的抽象方法,被運(yùn)用在內(nèi)核和用戶應(yīng)用程序等多個(gè)地方。映射是將來(lái)自某個(gè)數(shù)據(jù)源的數(shù)據(jù)(也可以是某個(gè)設(shè)備的I/O端口等)轉(zhuǎn)移到某個(gè)進(jìn)程的虛擬內(nèi)存空間。對(duì)映射的地址空間的操作可以使用處理普通內(nèi)存的方法(對(duì)地址內(nèi)容直接進(jìn)行讀寫(xiě))。任何對(duì)內(nèi)存的改動(dòng)會(huì)自動(dòng)轉(zhuǎn)移到原數(shù)據(jù)源,例如將某個(gè)文件的內(nèi)容映射到內(nèi)存中,只需要通過(guò)讀該內(nèi)存來(lái)獲取文件的內(nèi)容,通過(guò)將改動(dòng)寫(xiě)到該內(nèi)存來(lái)修改文件的內(nèi)容,內(nèi)核確保任何改動(dòng)都會(huì)自動(dòng)體現(xiàn)到文件里。
另外,在內(nèi)核中,實(shí)現(xiàn)設(shè)備驅(qū)動(dòng)時(shí),外設(shè)(外部設(shè)備)的輸入和輸出區(qū)域可以被映射到虛擬地址空間,讀寫(xiě)這些空間會(huì)被系統(tǒng)重定向到設(shè)備,從而對(duì)設(shè)備進(jìn)行操作,極大地簡(jiǎn)化了驅(qū)動(dòng)的實(shí)現(xiàn)。
內(nèi)核必須跟蹤哪些物理頁(yè)已經(jīng)被分配了,哪些還是空閑的,避免兩個(gè)進(jìn)程使用RAM中的同一個(gè)區(qū)域。內(nèi)存的分配和釋放是非常頻繁的任務(wù),內(nèi)核必須確保完成的速度盡量快,內(nèi)核只能分配整個(gè)page frame,它將內(nèi)存分為更小的部分的任務(wù)交給了用戶空間,用戶空間的程序庫(kù)可以將從內(nèi)核收到的page frame分成更小的區(qū)域后分配給進(jìn)程。
虛擬文件系統(tǒng)
Unix系統(tǒng)是建立在一些有見(jiàn)地的理念上的,一個(gè)非常重要的隱喻是:
Everything is a ?le.
即系統(tǒng)幾乎所有的資源都可以看成是文件。為了支持不同的本地文件系統(tǒng),內(nèi)核在用戶進(jìn)程和文件系統(tǒng)實(shí)現(xiàn)間包含了一層虛擬文件系統(tǒng)(Virtual File System)。大多數(shù)的內(nèi)核提供的函數(shù)都能通過(guò)VFS(Virtual File System)定義的文件接口訪問(wèn)。例如內(nèi)核子系統(tǒng):字符和塊設(shè)備,管道,網(wǎng)絡(luò)Socket,交互輸入輸出終端等。
另外用于操作字符和塊設(shè)備的設(shè)備文件是在/dev目錄下的真實(shí)文件,當(dāng)讀寫(xiě)操作執(zhí)行的時(shí)候,其的內(nèi)容會(huì)被對(duì)應(yīng)的設(shè)備驅(qū)動(dòng)動(dòng)態(tài)創(chuàng)建。
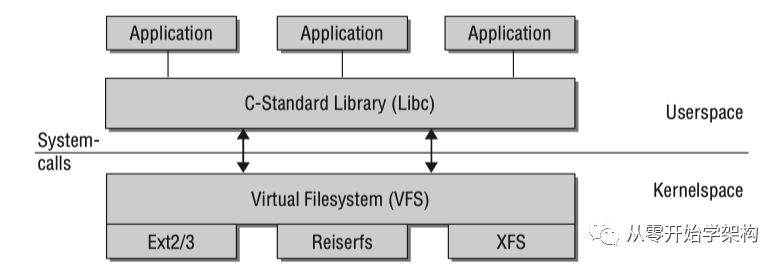
VFS系統(tǒng)
在虛擬文件系統(tǒng)中,inode用來(lái)表示文件和文件目錄(對(duì)于系統(tǒng)來(lái)說(shuō),目錄是一種特殊的文件)。inode的元素包含兩類:1. Metadata用于描述文件的狀態(tài),例如讀寫(xiě)權(quán)限。2. 用于保存文件內(nèi)容的數(shù)據(jù)段。
每個(gè)inode都有一個(gè)特別的號(hào)碼用于唯一識(shí)別,文件名和inode的關(guān)聯(lián)建立在該編號(hào)基礎(chǔ)上。以內(nèi)核查找/usr/bin/emacs為例,講解inodes如何組成文件系統(tǒng)的目錄結(jié)構(gòu)。從根inode開(kāi)始查找(即根目錄‘/’),該目錄使用一個(gè)inode表示,inode的數(shù)據(jù)段沒(méi)有普通的數(shù)據(jù),只包含了根目錄存的一些文件/目錄項(xiàng),這些項(xiàng)可以表示文件或其它目錄,每項(xiàng)包含兩個(gè)部分:1. 下一個(gè)數(shù)據(jù)項(xiàng)所在的inode編號(hào)? 2. 文件或目錄名
首先掃描根inode的數(shù)據(jù)區(qū)域直到找到一個(gè)名為‘usr’的項(xiàng),查找子目錄usr的inode。通過(guò)‘usr’ inode編號(hào)找到關(guān)聯(lián)的inode。重復(fù)以上步驟,查找名為‘bin’的數(shù)據(jù)項(xiàng),然后在其數(shù)據(jù)項(xiàng)的‘bin’對(duì)應(yīng)的inode中搜索名字‘emacs’的數(shù)據(jù)項(xiàng),最后返回的inode表示一個(gè)文件而不是一個(gè)目錄。最后一個(gè)inode的文件內(nèi)容不同于之前,前三個(gè)每個(gè)都表示了一個(gè)目錄,包含了它的子目錄和文件清單,和emacs文件關(guān)聯(lián)的inode在它的數(shù)據(jù)段保存了文件的實(shí)際內(nèi)容。
盡管在VFS查找某個(gè)文件的步驟和上面的描述一樣,但細(xì)節(jié)上還是有些差別。例如因?yàn)?/span>頻繁打開(kāi)文件是一個(gè)很慢的操作,引入緩存加速查找。
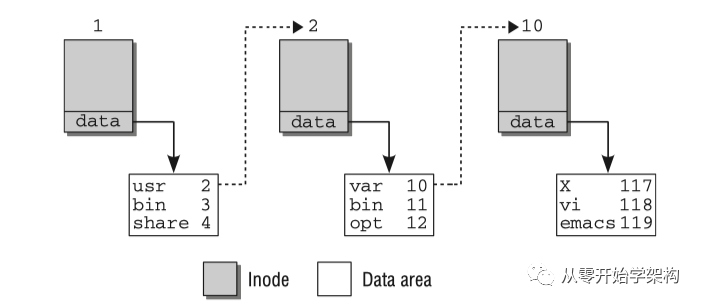
通過(guò)inode機(jī)制查找某個(gè)文件
設(shè)備驅(qū)動(dòng)
與外設(shè)通信往往指的是輸入(input)和輸出(output)操作,簡(jiǎn)稱I/O。實(shí)現(xiàn)外設(shè)的I/O內(nèi)核必須處理三個(gè)任務(wù):第一,必須針對(duì)不同的設(shè)備類型采用不同的方法來(lái)尋址硬件。第二,內(nèi)核必須為用戶應(yīng)用程序和系統(tǒng)工具提供操作不同設(shè)備的方法,且需要使用一個(gè)統(tǒng)一的機(jī)制來(lái)確保盡量有限的編程工作,和保證即使硬件方法不同應(yīng)用程序也能互相交互。第三,用戶空間需要知道在內(nèi)核中有哪些設(shè)備。
與外設(shè)通信的層級(jí)關(guān)系如下:
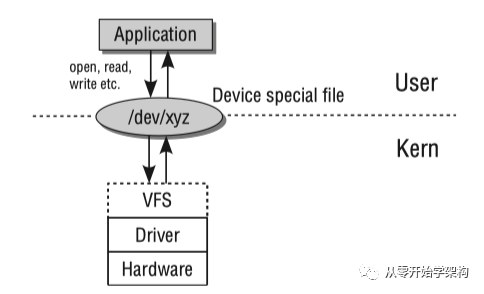
設(shè)備通信層級(jí)圖
外部設(shè)備大多通過(guò)總線與CPU連接,系統(tǒng)往往不止一個(gè)總線,而是總線的集合。在很多PC設(shè)計(jì)中包含兩個(gè)通過(guò)一個(gè)bridge相連的PCI總線。某些總線例如USB不能當(dāng)作主總線使用,需要通過(guò)一個(gè)系統(tǒng)總線將數(shù)據(jù)傳遞給處理器。下圖顯示不同的總線是如何連接到系統(tǒng)的。

系統(tǒng)總線拓?fù)鋱D
系統(tǒng)與外設(shè)交互主要有以下方式:
I/O端口:使用I/O端口通信的情況下,內(nèi)核通過(guò)一個(gè)I/O控制器發(fā)送數(shù)據(jù),每個(gè)接收設(shè)備有唯一的端口號(hào),且將數(shù)據(jù)轉(zhuǎn)發(fā)給系統(tǒng)附著的硬件。有一個(gè)由處理器管理的單獨(dú)的虛擬地址空間用來(lái)管理所有的I/O地址。
I/O地址空間并不總是和普通的系統(tǒng)內(nèi)存關(guān)聯(lián),考慮到端口能夠映射到內(nèi)存中,這往往不好理解。
端口有不同的類型。一些是只讀的,一些是只寫(xiě)的,一般情況下它們是可以雙向操作的,數(shù)據(jù)能夠在處理器和外設(shè)間雙向交換。
在IA-32架構(gòu)體系中,端口的地址空間包含了2^16個(gè)不同的8位地址,這些地址可以通過(guò)從0x0到0xFFFFH間的數(shù)唯一識(shí)別。每個(gè)端口都有一個(gè)設(shè)備分配給它,或者空閑沒(méi)有使用,多個(gè)外設(shè)不能共享一個(gè)端口。很多情況下,交換數(shù)據(jù)使用8位是不夠用的,基于這個(gè)原因,可以將兩個(gè)連續(xù)的8位端口綁定為一個(gè)16位的端口。兩個(gè)連續(xù)的16位端口能夠被當(dāng)作一個(gè)32位的端口,處理器可以通過(guò)組裝語(yǔ)句來(lái)做輸入輸出操作。
不同處理器類型在實(shí)現(xiàn)操作端口時(shí)有所不同,內(nèi)核必須提供一個(gè)合適的抽象層,例如outb(寫(xiě)一個(gè)字節(jié)),outw(寫(xiě)一個(gè)字)和inb(讀一個(gè)字節(jié))這些命令可以用來(lái)操作端口。
I/O內(nèi)存映射:必須能夠像訪問(wèn)RAM內(nèi)存一樣尋址許多設(shè)備。因此處理器提供了將外設(shè)對(duì)應(yīng)的I/O端口映射到內(nèi)存中,這樣就能像操作普通內(nèi)存一樣操作設(shè)備了。例如顯卡使用這樣的機(jī)制,PCI也往往通過(guò)映射的I/O地址尋址。
為了實(shí)現(xiàn)內(nèi)存映射,I/O端口必須首先被映射到普通系統(tǒng)內(nèi)存中(使用處理器特有的函數(shù))。因?yàn)槠脚_(tái)間的實(shí)現(xiàn)方式差異比較大,所以內(nèi)核提供了一個(gè)抽象層來(lái)映射和去映射I/O區(qū)域。
除了如何訪問(wèn)外設(shè),什么時(shí)候系統(tǒng)會(huì)知道是否外設(shè)有數(shù)據(jù)可以訪問(wèn)?主要通過(guò)兩種方式:輪詢和中斷。
輪詢周期性地訪問(wèn)查詢?cè)O(shè)備是否有準(zhǔn)備好的數(shù)據(jù),如果有,便獲取數(shù)據(jù)。這種方法需要處理器在設(shè)備沒(méi)有數(shù)據(jù)的情況下也不斷去訪問(wèn)設(shè)備,浪費(fèi)了CPU時(shí)間片。
另一種方式是中斷,它的理念是外設(shè)把某件事情做完了后,主動(dòng)通知CPU,中斷的優(yōu)先級(jí)最高,會(huì)中斷CPU的當(dāng)前進(jìn)程運(yùn)行。每個(gè)CPU都提供了中斷線(可被不同的設(shè)備共享),每個(gè)中斷由唯一的中斷號(hào)識(shí)別,內(nèi)核為每個(gè)使用的中斷提供一個(gè)服務(wù)方法(ISR,Interrupt Service Routine,即中斷發(fā)生后,CPU調(diào)用的處理函數(shù)),中斷本身也可以設(shè)置優(yōu)先級(jí)。
中斷會(huì)掛起普通的系統(tǒng)工作。當(dāng)有數(shù)據(jù)已準(zhǔn)備好可以給內(nèi)核或者間接被一個(gè)應(yīng)用程序使用的時(shí)候,外設(shè)出發(fā)一個(gè)中斷。使用中斷確保系統(tǒng)只有在外設(shè)需要處理器介入的時(shí)候才會(huì)通知處理器,有效提高了效率。
通過(guò)總線控制設(shè)備:不是所有的設(shè)備都是直接通過(guò)I/O語(yǔ)句尋址操作的,很多情況下是通過(guò)某個(gè)總線系統(tǒng)。
不是所有的設(shè)備類型都能直接掛接在所有的總線系統(tǒng)上,例如硬盤(pán)掛到SCSI接口上,但顯卡不可以(顯卡可以掛到PCI總線上)。硬盤(pán)必須通過(guò)IDE間接掛到PCI總線上。
總線類型可分為系統(tǒng)總線和擴(kuò)展總線。硬件上的實(shí)現(xiàn)差別對(duì)內(nèi)核來(lái)說(shuō)并不重要,只有總線和它附著的外設(shè)如何被尋址才相關(guān)。對(duì)于系統(tǒng)總線來(lái)說(shuō),例如PCI總線,I/O語(yǔ)句和內(nèi)存映射用來(lái)與總線通信,也用于和它附著的設(shè)備通信。內(nèi)核還提供了一些命令供設(shè)備驅(qū)動(dòng)來(lái)調(diào)用總線函數(shù),例如訪問(wèn)可用的設(shè)備列表,使用統(tǒng)一的格式讀寫(xiě)配置信息。
擴(kuò)展總線例如USB,SCSI通過(guò)清晰定義的總線協(xié)議與附著的設(shè)備來(lái)交換數(shù)據(jù)和命令。內(nèi)核通過(guò)I/O語(yǔ)句或內(nèi)存映射來(lái)與總線通信,通過(guò)平臺(tái)無(wú)關(guān)的函數(shù)來(lái)使總線與附著的設(shè)備通信。
與總線附著的設(shè)備通信不一定需要通過(guò)在內(nèi)核空間的驅(qū)動(dòng)進(jìn)行,在某些情況下也可以通過(guò)用戶空間實(shí)現(xiàn)。一個(gè)主要的例子是SCSI Writer,通過(guò)cdrecord工具來(lái)尋址。這個(gè)工具產(chǎn)生所需要的SCSI命令,在內(nèi)核的幫助下通過(guò)SCSI總線將命令發(fā)送到對(duì)應(yīng)的設(shè)備,處理和回復(fù)設(shè)備產(chǎn)生或返回的信息。
塊設(shè)備(block)和字符設(shè)備(character)在3個(gè)方面顯著不同:
塊設(shè)備中的數(shù)據(jù)能夠在任何點(diǎn)操作,而字符設(shè)備不能也沒(méi)這個(gè)要求。
塊設(shè)備數(shù)據(jù)傳輸?shù)臅r(shí)候總是使用固定大小的塊。即使只請(qǐng)求一個(gè)字節(jié)的情況下,設(shè)備驅(qū)動(dòng)也總是從設(shè)備獲取一個(gè)完整的塊。相反,字符設(shè)備能夠返回單個(gè)字節(jié)。
讀寫(xiě)塊設(shè)備會(huì)使用緩存。讀操作方面,數(shù)據(jù)緩存在內(nèi)存中,能夠在需要的時(shí)候重新訪問(wèn)。寫(xiě)操作方面,也會(huì)被緩存,延時(shí)寫(xiě)入設(shè)備。使用緩存對(duì)于字符設(shè)備(例如鍵盤(pán))來(lái)說(shuō)不合理,每個(gè)讀請(qǐng)求都必須被可靠地交互到設(shè)備。
塊和扇區(qū)的概念:塊是一個(gè)指定大小的字節(jié)序列,用于保存在內(nèi)核和設(shè)備間傳輸?shù)臄?shù)據(jù),塊的大小可以被設(shè)置。扇區(qū)是固定大小的,能被設(shè)備傳輸?shù)淖钚〉臄?shù)據(jù)量。塊是一段連續(xù)的扇區(qū),塊大小是扇區(qū)的整數(shù)倍。
網(wǎng)絡(luò)
Linux的網(wǎng)絡(luò)子系統(tǒng)為互聯(lián)網(wǎng)的發(fā)展提供了堅(jiān)實(shí)的基礎(chǔ)。網(wǎng)絡(luò)模型基于ISO的OSI模型,如下圖右半部分。但在具體應(yīng)用中,往往會(huì)把相應(yīng)層級(jí)結(jié)合以簡(jiǎn)化模型,下圖左半部分為L(zhǎng)inux運(yùn)用的TCP/IP參考模型。(由于介紹Linux網(wǎng)絡(luò)部分的資料比較多,在本文中只對(duì)大的層級(jí)簡(jiǎn)單介紹,不展開(kāi)說(shuō)明。)
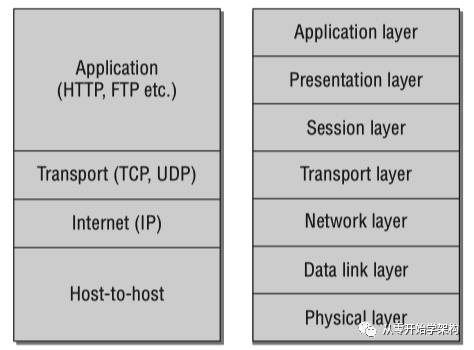
網(wǎng)絡(luò)模型
Host-to-host層(Physical Layer和Data link layer,即物理層和數(shù)據(jù)鏈路層)負(fù)責(zé)將數(shù)據(jù)從一個(gè)計(jì)算機(jī)傳輸?shù)搅硪慌_(tái)計(jì)算機(jī)。這一層處理物理傳輸介質(zhì)的電氣和編解碼屬性,也將數(shù)據(jù)流拆分成固定大小的數(shù)據(jù)幀用于傳輸。如多個(gè)電腦共享一個(gè)傳輸路線,網(wǎng)絡(luò)適配器(網(wǎng)卡等)必須有一個(gè)唯一的ID(即MAC地址)來(lái)區(qū)分。從內(nèi)核的角度,這一層是通過(guò)網(wǎng)卡的設(shè)備驅(qū)動(dòng)實(shí)現(xiàn)的。
OSI模型的網(wǎng)絡(luò)層在TCP/IP模型中稱為網(wǎng)絡(luò)層,網(wǎng)絡(luò)層使網(wǎng)絡(luò)中的計(jì)算機(jī)之間能交換數(shù)據(jù),而這些計(jì)算機(jī)不一定是直接相連的。
如下圖,A和B之間物理上并沒(méi)有直接相連,所以也沒(méi)有直接的數(shù)據(jù)交換。網(wǎng)絡(luò)層的任務(wù)是為網(wǎng)絡(luò)中各機(jī)器之間通信找到路由。
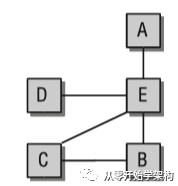
網(wǎng)絡(luò)連接的電腦
網(wǎng)絡(luò)層也負(fù)責(zé)將要傳輸?shù)陌殖芍付ǖ拇笮。?/span>因?yàn)榘趥鬏斅窂缴厦總€(gè)電腦支持的最大的數(shù)據(jù)包大小可能不一樣,在傳輸時(shí),數(shù)據(jù)流被分割成不同的包,在接收端再被組合。
網(wǎng)絡(luò)層為網(wǎng)絡(luò)中的電腦分配了唯一的網(wǎng)絡(luò)地址以便他們能互相通信(不同于硬件的MAC地址,因?yàn)榫W(wǎng)絡(luò)往往由子網(wǎng)絡(luò)組成)。在互聯(lián)網(wǎng)中,網(wǎng)絡(luò)層由IP網(wǎng)絡(luò)組成,有V4和V6版本。
傳輸層的任務(wù)是規(guī)范在兩個(gè)連接的電腦上運(yùn)行的應(yīng)用程序之間的數(shù)據(jù)傳輸。例如兩臺(tái)電腦上的客戶端和服務(wù)端程序,包括TCP或UDP連接,通過(guò)端口號(hào)來(lái)識(shí)別通信的應(yīng)用程序。例如端口號(hào)80用于web server,瀏覽器的客戶端必須將請(qǐng)求發(fā)送到這個(gè)端口來(lái)獲取需要的數(shù)據(jù)。而客戶端也需要有一個(gè)唯一的端口號(hào)以便web server能將回復(fù)發(fā)送給它。
這一層還負(fù)責(zé)為數(shù)據(jù)的傳輸提供一個(gè)可靠的連接(TCP情況下)。
TCP/IP模型中的應(yīng)用層在OSI模型中包含(session層,展現(xiàn)層,應(yīng)用層)。當(dāng)通信連接在兩個(gè)應(yīng)用之間建立起來(lái)后,這一層負(fù)責(zé)實(shí)際內(nèi)容的傳輸。例如web server與它的客戶端傳輸時(shí)的協(xié)議和數(shù)據(jù),不同與mail server與它的客戶端之間。
大多數(shù)的網(wǎng)絡(luò)協(xié)議在RFC(Request for Comments)中定義。
網(wǎng)絡(luò)實(shí)現(xiàn)分層模型:內(nèi)核對(duì)網(wǎng)絡(luò)層的實(shí)現(xiàn)類似TCP/IP參考模型。它是通過(guò)C代碼實(shí)現(xiàn)的,每個(gè)層只能和它的上下層通信,這樣的好處是可以將不同的協(xié)議和傳輸機(jī)制結(jié)合。如下圖所示:
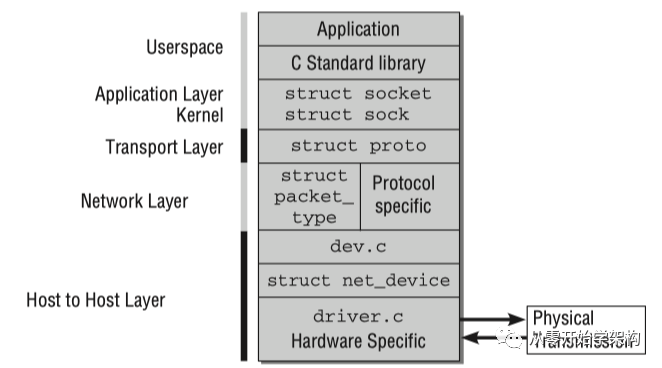
網(wǎng)絡(luò)實(shí)現(xiàn)分層圖
本文先介紹到這,對(duì)技術(shù)感興趣的朋友可以關(guān)注"從零開(kāi)始學(xué)架構(gòu)",后續(xù)也會(huì)繼續(xù)推出對(duì)各類架構(gòu)設(shè)計(jì)的介紹,希望和大家多多交流,也歡迎大家留言。
(The End)
參考資料:
《Professional Linux Kernel Architecture》
《Understanding Linux Kernel》
《Architecture of the Linux Kernel》

覺(jué)得本文有幫助,請(qǐng)點(diǎn)"在看"?