
Rethinking “Batch” in BatchNorm
這篇很有趣且很有用,激動(dòng)的趕緊把文章看了一遍,不愧是FAIR,實(shí)驗(yàn)看的太爽了。
之前對(duì)于Norm的研究主要在于改變Norm的維度,然后衍生出了BatchNorm、GroupNorm、InstanceNorm和LayerNorm等方法,但是除了BN外的其他Norm含義是確定,而B(niǎo)N的batch卻可以有多種采樣方式,本文就是為了探討B(tài)N的batch使用不同的采樣方式會(huì)有什么影響,堪稱BatchNorm圣經(jīng),建議全文背誦(ps:GN也是吳育昕的作品)。
本文總共4大核心實(shí)驗(yàn),每個(gè)核心實(shí)驗(yàn)有多個(gè)子結(jié)論。
01
Motivation
BatchNorm現(xiàn)在已經(jīng)廣泛的應(yīng)用于CNN中。但是BN針對(duì)不同的場(chǎng)景使用時(shí)有許多細(xì)微的差異,如果選擇不當(dāng)會(huì)降低模型的性能。BatchNorm相對(duì)于其他算子來(lái)說(shuō),主要的不同在于BN是對(duì)batch數(shù)據(jù)進(jìn)行操作的。BN在batch數(shù)據(jù)中進(jìn)行統(tǒng)計(jì)量計(jì)算,而其他算子一般都是獨(dú)立處理單個(gè)樣本的。因此影響B(tài)N的輸出不僅僅取決于單個(gè)樣本的性質(zhì),還取決于batch的采樣方式。
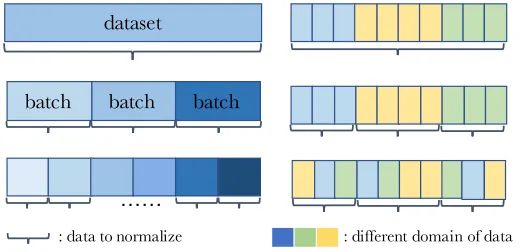
如圖所示,左右各舉例了三種batch采樣方式。其中左圖三種batch采樣方式分別為entire dataset、mini-batches和subset of mini-batches,右圖三種batch采樣方式分別為entire domain、each domain和mixture of each domain。
本文實(shí)驗(yàn)證明了使用BN時(shí)不考慮batch的采樣方式會(huì)在許多方面產(chǎn)生負(fù)面影響,合理使用batch采樣方式會(huì)改善模型性能。
02
A Review of BatchNorm
簡(jiǎn)單回顧一下BN的計(jì)算形式,這里以CNN中的BN為例。假設(shè)BN的輸入feature維度為
假設(shè)batch的大小為N,mini-batch X的維度為
推理的時(shí)候,
不同于默認(rèn)的BN設(shè)置,因?yàn)閎atch采樣方式主要影響的是統(tǒng)計(jì)量mean和std,本文將mean和std看成是一個(gè)逐通道分開(kāi)計(jì)算的仿射變換(可以等價(jià)為一個(gè)1x1的depth-wise layer)。
03
Whole Population as aBatch
BN中統(tǒng)計(jì)量的計(jì)算默認(rèn)使用EMA方法,但是作者實(shí)驗(yàn)發(fā)現(xiàn)EMA會(huì)導(dǎo)致模型性能次優(yōu),然后提出了PreciseBN方法,近似將整個(gè)訓(xùn)練集統(tǒng)計(jì)量作為一個(gè)batch。
Inaccuracy of EMA
EMA是指數(shù)滑動(dòng)平均的縮寫(xiě),為了統(tǒng)計(jì)
EMA方法導(dǎo)致次優(yōu)解的原因有兩點(diǎn):
1.當(dāng)
2.當(dāng)
Towards Precise Population Statistics
為了得到整個(gè)訓(xùn)練集更加精確的統(tǒng)計(jì)量,PreciseBN采用了兩點(diǎn)小技巧:
1.將相同模型用于多個(gè)mini-batches來(lái)收集batch統(tǒng)計(jì)量
2.將多個(gè)batch收集的統(tǒng)計(jì)量聚合成一個(gè)population統(tǒng)計(jì)量
比如有N個(gè)樣本需要通過(guò)數(shù)量為的Bmini-batch進(jìn)行PreciseBN統(tǒng)計(jì)量計(jì)算,那么需要計(jì)算
相比于EMA,PreciseBN有兩點(diǎn)重要的屬性:
1.PreciseBN的統(tǒng)計(jì)量是通過(guò)相同模型計(jì)算得到的,而EMA是通過(guò)多個(gè)歷史模型計(jì)算得到的。
2.PreciseBN的所有樣本的權(quán)重是相同的,而EMA不同樣本的權(quán)重是不同的。
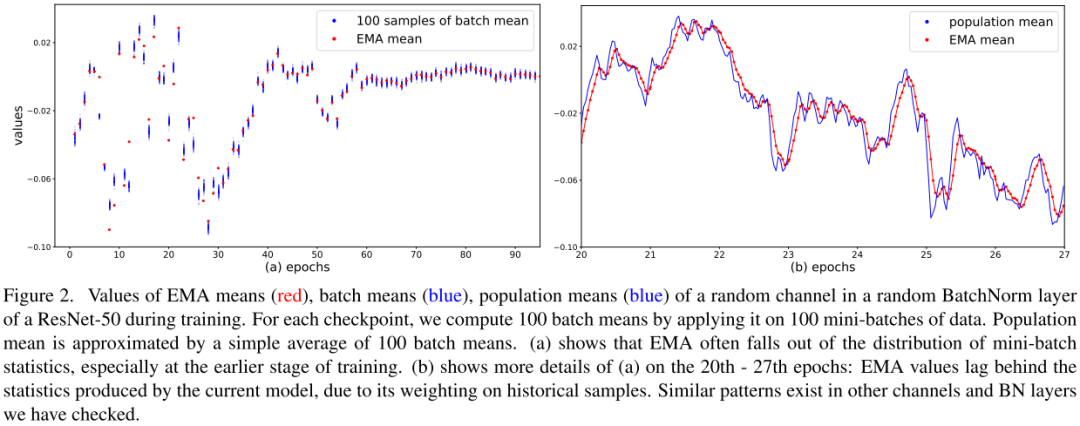
100 samples of batch mean意思是相同epoch下模型對(duì)100個(gè)隨機(jī)batch統(tǒng)計(jì)量的結(jié)果。如圖所示,在訓(xùn)練早期EMA的統(tǒng)計(jì)量不精確,會(huì)導(dǎo)致最終模型性能次優(yōu)。由于滑動(dòng)平均的計(jì)算方式導(dǎo)致EMA的統(tǒng)計(jì)量滯后于PrciseBN。
4個(gè)主要結(jié)論:
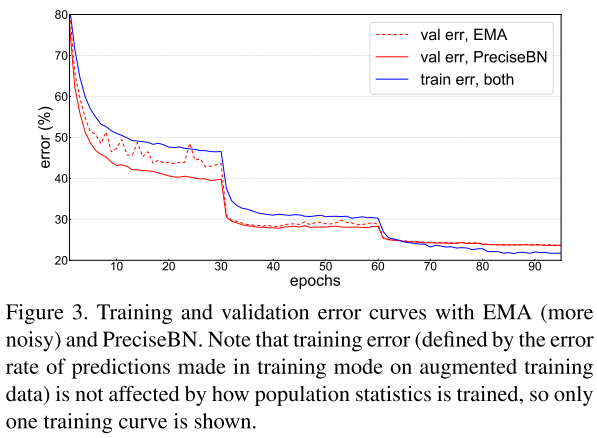
1.推理時(shí)使用PreciseBN會(huì)更加穩(wěn)定。
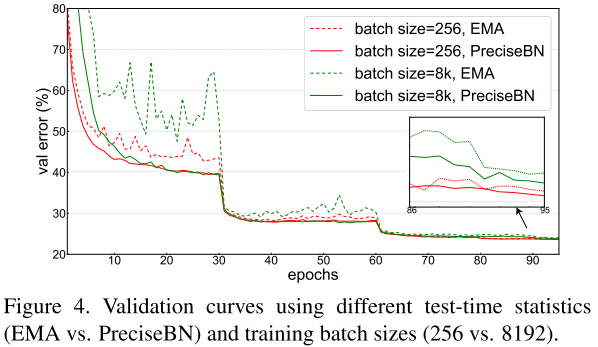
2.大batch訓(xùn)練對(duì)EMA影響更大。

3.PreciseBN只需要10^3~10^4個(gè)樣本可以得到近似最優(yōu)。

4.小batch會(huì)產(chǎn)生統(tǒng)計(jì)量積累錯(cuò)誤。
04
Batch in Training and Testing
BN在訓(xùn)練和測(cè)試中行為不一致:訓(xùn)練時(shí),BN的統(tǒng)計(jì)量來(lái)自mini-batch;測(cè)試時(shí),BN的統(tǒng)計(jì)量來(lái)自population。這部分主要探討了BN行為不一致對(duì)模型性能的影響,并且提出消除不一致的方法提升模型性能。
Effect of Normalization Batch Size
為了避免混淆,將SGD batch size或者total batch size定義為所有GPU上總的batch size大小,將normalization batch size定義為單個(gè)GPU上的batch size大小。
normalization batch size對(duì)training noise和train-test inconsistency有著直接影響:使用更大的batch,mini-batch統(tǒng)計(jì)量越接近population統(tǒng)計(jì)量,從而降低training noise和train-test inconsistency。
以下實(shí)驗(yàn)的SGD batch size固定使用1024大小。
為了便于分析,作者觀察了3種不同評(píng)估方法的錯(cuò)誤率:
1.在訓(xùn)練集上對(duì)mini-batch統(tǒng)計(jì)量進(jìn)行評(píng)估
2.在驗(yàn)證集上對(duì)mini-batch統(tǒng)計(jì)量進(jìn)行評(píng)估
3.在驗(yàn)證集上對(duì)population統(tǒng)計(jì)量進(jìn)行評(píng)估
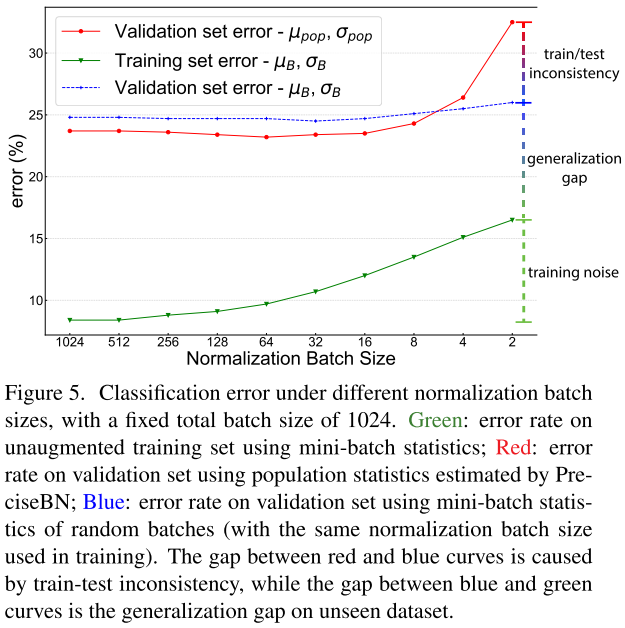
Training noise:當(dāng)normalization batch size非常小時(shí),單個(gè)樣本會(huì)受到同一個(gè)min-batch樣本的嚴(yán)重影響,導(dǎo)致訓(xùn)練精度較差,優(yōu)化困難。
Generalization gap:隨著normalization batch size的增加,mini-batch的驗(yàn)證集和訓(xùn)練集的之間的泛化誤差會(huì)增大,這可能是由于training noise和train-test inconsistency沒(méi)有正則化。
Train-test inconsistency:在小batch下,mini-batch統(tǒng)計(jì)量和population統(tǒng)計(jì)量的不一致是影響性能的主要因素。當(dāng)normalization batch size增大時(shí),細(xì)微的不一致可以提供正則化效果減少驗(yàn)證誤差。在mini-batch為32~128之間時(shí),正則化達(dá)到平衡,模型性能最優(yōu)。
為了保持train和test的BN統(tǒng)計(jì)量一致,作者提出了兩種方法來(lái)解決不一致問(wèn)題,一種是推理的時(shí)候使用mini-batch統(tǒng)計(jì)量,另一種是訓(xùn)練的時(shí)候使用population batch統(tǒng)計(jì)量。
Use Mini-batch in Inference

作者在Mask R-CNN上進(jìn)行實(shí)驗(yàn),mini-batch的結(jié)果超過(guò)了population的結(jié)果,證明了在推理中使用mini-batch可以有效的緩解訓(xùn)練測(cè)試不一致。(ps:不使用norm效果略差,使用GN效果更好)
Use Population Batch in Training
為了在訓(xùn)練階段使用population統(tǒng)計(jì)量,作者采用FrozenBN的方法,F(xiàn)rozenBN使用population統(tǒng)計(jì)量。具體地,作者先選擇第80個(gè)epoch模型,然后將所有BN替換成FrozenBN,然后訓(xùn)練20個(gè)epoch。
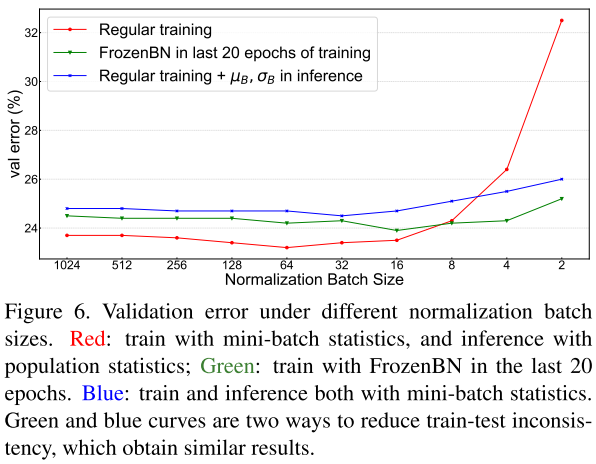
FrozenBN可以有效緩解訓(xùn)練測(cè)試不一致,即使在小normalization batch size,也能達(dá)到比較好的性能。但是隨著normalization batch size增大,作者提出的兩種緩解不一致的方法都不如常規(guī)BN的結(jié)果。
05
Batch from Different Domains
BN的訓(xùn)練過(guò)程可以看成是兩個(gè)獨(dú)立的階段:第一個(gè)階段是通過(guò)SGD學(xué)習(xí)features,第二個(gè)階段是由這些features得到population統(tǒng)計(jì)量。兩個(gè)階段分別稱為SGD training和population statistics training。
由于BN多了一個(gè)population統(tǒng)計(jì)階段,導(dǎo)致訓(xùn)練和測(cè)試之間的domain shift。當(dāng)數(shù)據(jù)來(lái)自多個(gè)doman時(shí),SGD training、population statistics training和testing三個(gè)步驟的domain gap都會(huì)對(duì)泛化性造成影響。
實(shí)驗(yàn)主要探究了兩種使用場(chǎng)景:第一種,模型在一個(gè)domain上進(jìn)行訓(xùn)練,然后在其他domain上進(jìn)行測(cè)試;第二種,模型在多個(gè)domain上進(jìn)行訓(xùn)練。
Domain to Compute Population Statistics
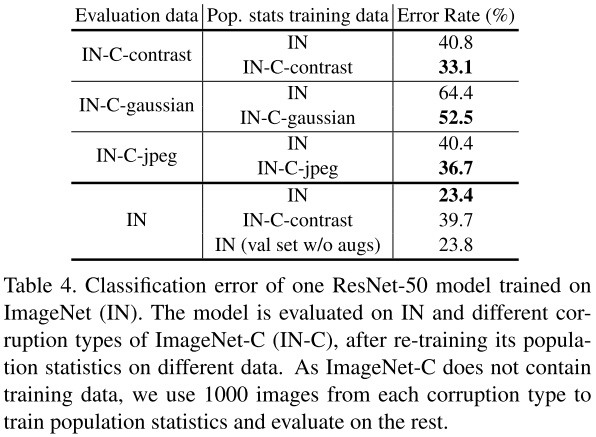
作者實(shí)驗(yàn)發(fā)現(xiàn),當(dāng)存在顯著的domain shift時(shí),模型使用評(píng)估domain的population統(tǒng)計(jì)量會(huì)得到更好的結(jié)果,可以緩解訓(xùn)練測(cè)試的不一致。
BatchNorm in Multi-Domain Training
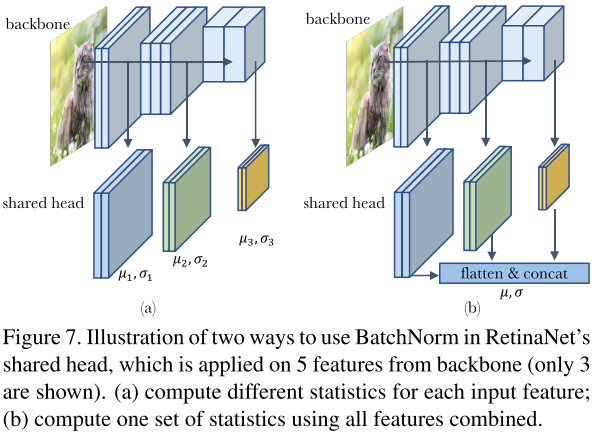
為了對(duì)多個(gè)domain的情況進(jìn)行實(shí)驗(yàn),作者將RetinaNet head中的BN統(tǒng)計(jì)量進(jìn)行實(shí)驗(yàn)設(shè)計(jì)。RetinaNet的head是5個(gè)feature層共享的,這意味著會(huì)接收來(lái)自5個(gè)不同分布或者domain的輸入進(jìn)行訓(xùn)練。
左圖的訓(xùn)練形式非常簡(jiǎn)單,head獨(dú)立作用于不同的feature層,都有自己獨(dú)立的統(tǒng)計(jì)量。右圖將所有輸入特征flatten然后concat在一起,統(tǒng)一進(jìn)行統(tǒng)計(jì)量計(jì)算。兩種不同計(jì)算統(tǒng)計(jì)量的方式稱為domain-specific statistics和shared statistics。

最終實(shí)驗(yàn)表明,SGD training、population statistics training和testing保持一致是非常重要的,并且全部使用domain-specific能取得最好的效果。(ps:不使用norm效果略差,使用GN效果更好)
06
Information Leakage within a Batch
BN在使用中還存在一種information leakage現(xiàn)象,因?yàn)锽N是對(duì)mini-batch的樣本計(jì)算統(tǒng)計(jì)量的,導(dǎo)致在樣本進(jìn)行獨(dú)立預(yù)測(cè)時(shí),會(huì)利用mini-batch內(nèi)其他樣本的統(tǒng)計(jì)信息。
Exploit Patterns in Mini-batches
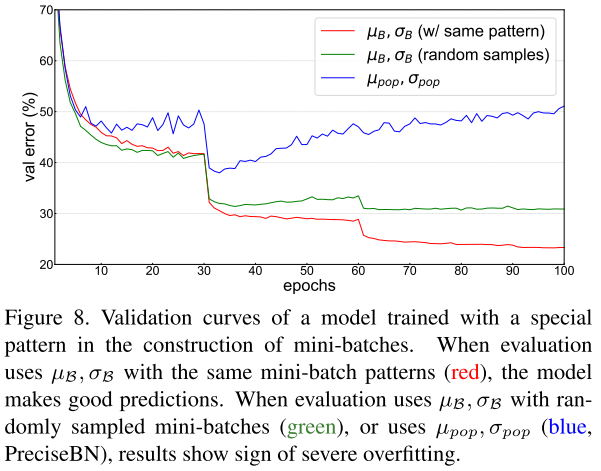
作者實(shí)驗(yàn)發(fā)現(xiàn),當(dāng)使用random采樣的mini-batch統(tǒng)計(jì)量時(shí),驗(yàn)證誤差會(huì)增加,當(dāng)使用population統(tǒng)計(jì)量時(shí),驗(yàn)證誤差會(huì)隨著epoch的增加逐漸增大,驗(yàn)證了BN信息泄露問(wèn)題的存在。
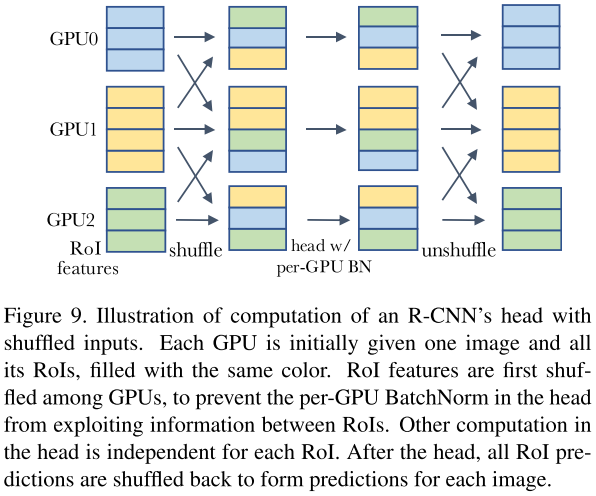
為了處理信息泄露問(wèn)題,之前常見(jiàn)的作法是使用SyncBN,來(lái)弱化mini-batch內(nèi)樣本之間的相關(guān)性。另一種解決方法是在進(jìn)入head之前在GPU之間隨機(jī)打亂RoI features,這給每個(gè)GPU分配了一個(gè)隨機(jī)的樣本子集來(lái)進(jìn)行歸一化,同時(shí)也削弱了min-batch樣本之間的相關(guān)性,如上圖所示。
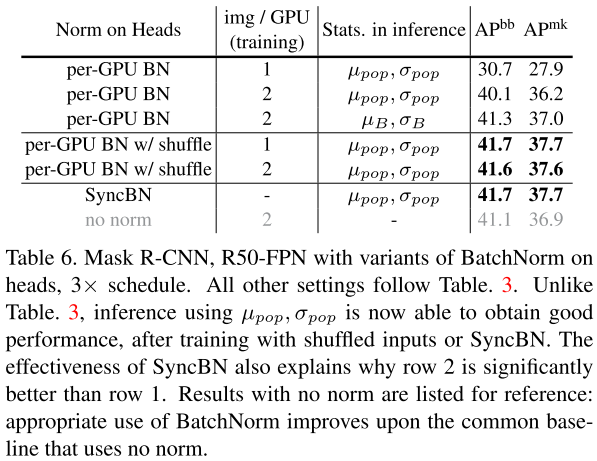
實(shí)驗(yàn)結(jié)果表明,shuffling和SyncBN都能有效地處理信息泄漏,使得head在測(cè)試時(shí)能夠很好地泛化。在速度方面,我們注意到shuffling需要更少的跨gpu同步,但是shuffling每次傳輸?shù)臄?shù)據(jù)比SyncBN多。因此,shuffling和SyncBN的相對(duì)效率跟具體模型架構(gòu)相關(guān)。
Cheating in Contrastive Learning
在對(duì)比學(xué)習(xí)和度量學(xué)習(xí)時(shí),訓(xùn)練目標(biāo)通常是在mini-batch下進(jìn)行比較的,這種情況下BN也會(huì)造成信息泄露,導(dǎo)致模型在訓(xùn)練期間作弊,之前的研究提出了很多不同方法來(lái)針對(duì)性解決對(duì)比學(xué)習(xí)和度量學(xué)習(xí)的信息泄露問(wèn)題。
07
總結(jié)
本文從多個(gè)角度探討了BN的batch使用不同的采樣方式會(huì)有什么影響,并且做了非常詳盡的對(duì)比試驗(yàn),堪稱BatchNorm圣經(jīng),建議全文背誦。
另外,看完后最大的感觸是,BN不會(huì)用就別用,GN yyds。
Reference
[1] Rethinking “Batch” in BatchNorm
長(zhǎng)按掃描下方二維碼添加小助手。
可以一起討論遇到的問(wèn)題
聲明:轉(zhuǎn)載請(qǐng)說(shuō)明出處
掃描下方二維碼關(guān)注【集智書(shū)童】公眾號(hào),獲取更多實(shí)踐項(xiàng)目源碼和論文解讀,非常期待你我的相遇,讓我們以夢(mèng)為馬,砥礪前行!