
電商風(fēng)控賽事亞軍方案分享!
本次 Apache Flink 極客挑戰(zhàn)賽暨 AAIG CUP——電商推薦“抱大腿”攻擊識別 賽題以電商推薦反作弊為背景,要求選手在少樣本、半監(jiān)督、隱私保護(hù)的場景下搭建風(fēng)控模型來實(shí)時(shí)預(yù)測用戶點(diǎn)擊商品的行為是否惡意,實(shí)現(xiàn)對惡意流量的實(shí)時(shí)識別。下面分享一下我們隊(duì)伍對本次比賽的理解和詳細(xì)方案。
代碼開源地址:
https://github.com/rickyxume/TianChi_RecSys_AntiSpam
實(shí)踐背景
1.1 思路簡述
本賽題屬于結(jié)構(gòu)化數(shù)據(jù)二分類任務(wù),雖然是風(fēng)控競賽,但思考方向不局限于欺詐檢測或異常檢測,還可以參考推薦系統(tǒng)里的CTR預(yù)估、交互序列建模和圖建模等方向,可能會有更多啟發(fā)。Apache Flink 極客挑戰(zhàn)賽畢竟是個算法和工程并重的比賽,所涉及到的技術(shù)點(diǎn)也主要是在算法和工程兩個方面。
算法上涉及數(shù)據(jù)增廣、降噪、類別不平衡、半監(jiān)督學(xué)習(xí)、增量訓(xùn)練、模型剪枝、壓縮和加速等。
工程上涉及寫 FlinkSQL 在線特征工程、Flink 性能調(diào)優(yōu)、Ai Flow 工作流定義、Occlum 搭建TEE、Analytics Zoo Cluster Serving 分布式推理調(diào)用、模型pb文件凍結(jié)和 Docker 的使用等。
1.2 賽題理解
電商風(fēng)控業(yè)務(wù)背景
眾所周知,電商平臺會基于用戶點(diǎn)擊商品的行為來做個性化推薦,而一些不懷好意的商家可能想要推銷自己的低質(zhì)量商品,就在黑產(chǎn)市場買一個提高商品流量曝光的服務(wù),具體操作就是雇傭一批黑產(chǎn)用戶(可能是機(jī)器,也可能是肉雞)去協(xié)同點(diǎn)擊目標(biāo)商品(即商家想要提升曝光度的商品)和爆款商品來提高電商平臺推薦系統(tǒng)中兩商品間的I2I關(guān)聯(lián)分,用大白話來說就是“蹭流量”,通過這種方式干擾推薦系統(tǒng)來給惡意商家的商品更多曝光,極易誤導(dǎo)消費(fèi)者以爆款心理購買到劣質(zhì)商品,影響平臺治理,有損用戶利益,所以需要風(fēng)控系統(tǒng)去實(shí)時(shí)識別用戶行為來過濾惡意流量。
惡意點(diǎn)擊判定邏輯
理解打標(biāo)簽的邏輯對于理解賽題數(shù)據(jù)至關(guān)重要。
對于本賽題中的數(shù)據(jù)標(biāo)簽,僅當(dāng) user 和 item 滿足均為惡意的條件,即惡意用戶點(diǎn)擊惡意商家的商品時(shí),該點(diǎn)擊行為才是惡意的,也就是圖例中間三條紅線才是惡意點(diǎn)擊(label = 1),而其余情況,包括圖中剩下的三條藍(lán)線,都不算惡意點(diǎn)擊(label = 0)。

評估指標(biāo)及風(fēng)控要求
本賽題對風(fēng)控系統(tǒng)的安全和性能都有較高要求,需要在保證模型和數(shù)據(jù)安全的前提下,及時(shí)并準(zhǔn)確地?cái)r截惡意流量,實(shí)現(xiàn)實(shí)時(shí)風(fēng)控。
環(huán)境要求:Occlum HW 模式(即在TEE下運(yùn)行) 技術(shù)組件要求:必須使用 AI Flow 定義整個工作流,預(yù)測過程必須使用 Flink 作為實(shí)時(shí)計(jì)算引擎,其核心預(yù)測過程使用 Cluster Serving 完成。 時(shí)間限制:第一階段訓(xùn)練推理時(shí)間不限,第二階段訓(xùn)練推理限時(shí)15min,總時(shí)長不超過2h。 評估指標(biāo):,即兩階段F1得分與延遲符合要求(500ms以內(nèi))的數(shù)據(jù)占比的乘積之和
1.3 數(shù)據(jù)理解
數(shù)據(jù)描述
賽方提供匿名處理后的結(jié)構(gòu)化數(shù)據(jù),以供選手程序用于離線訓(xùn)練和在線推理,包含uuid、用戶訪問商品時(shí)間、用戶id、商品id、商品及用戶屬性特征和標(biāo)簽,各字段描述如下:
| 字段 | 含義 |
|---|---|
| uuid | 數(shù)據(jù)集中唯一確認(rèn)每條數(shù)據(jù)的id。 |
| visit_time | 該條行為數(shù)據(jù)的發(fā)生時(shí)間。實(shí)時(shí)預(yù)測過程中提供的數(shù)據(jù)的該值基本是單調(diào)遞增的。 |
| user_id | 該條數(shù)據(jù)對應(yīng)的用戶的id |
| item_id | 該條數(shù)據(jù)對應(yīng)的商品的id |
| features | 該數(shù)據(jù)的特征,復(fù)賽中,包含152個用空格分隔的浮點(diǎn)數(shù)。其中,第1 ~ 72個數(shù)字代表商品的特征,第73 ~ 152個數(shù)字代表用戶的特征。 |
| label | 值為0、1或-1,1代表該數(shù)據(jù)為惡意行為數(shù)據(jù),0為正常,-1則表示數(shù)據(jù)未標(biāo)注。 |
數(shù)據(jù)量及業(yè)務(wù)場景模擬
為模擬實(shí)際業(yè)務(wù)中的模型迭代場景,工作流分為兩個階段。
第一階段可以使用100w條數(shù)據(jù),其中10w條有標(biāo)簽用于離線訓(xùn)練,5w條測試數(shù)據(jù)用于實(shí)時(shí)推理;
第二階段可以使用第一階段所有數(shù)據(jù)以及100w條新增數(shù)據(jù),其中1w條有標(biāo)簽,5w條測試數(shù)據(jù)。
1.4 數(shù)據(jù)分析
特征相關(guān)性分析
首先,對給定的152維匿名的商品和用戶的屬性特征做拆分,其中商品特征為前72維,用戶特征為后80維,分別對其按字母前綴和序號逐個命名,做特征相關(guān)性可視化分析。
系數(shù)矩陣熱力圖")
可以發(fā)現(xiàn),特征相關(guān)系數(shù)矩陣熱力圖中有很多深色方塊,表明其存在多重共線性特征,特征冗余較多,商品特征熱力圖的顏色大體上更深,說明商品特征與行為標(biāo)簽更相關(guān)(側(cè)面表明商品可以表征商家),而在用戶特征中(觀察右圖中空白處)存在三列全部值都一樣的無效特征(u77、u78、u79)。
數(shù)據(jù)分布差異分析
選取前面得到的與目標(biāo)相關(guān)性較高的12個特征,分別繪制其在第一階段的訓(xùn)練集、測試集和全部數(shù)據(jù)上的密度分布曲線,圖中紅色的曲線是測試集的,可以明顯發(fā)現(xiàn)分布差異。
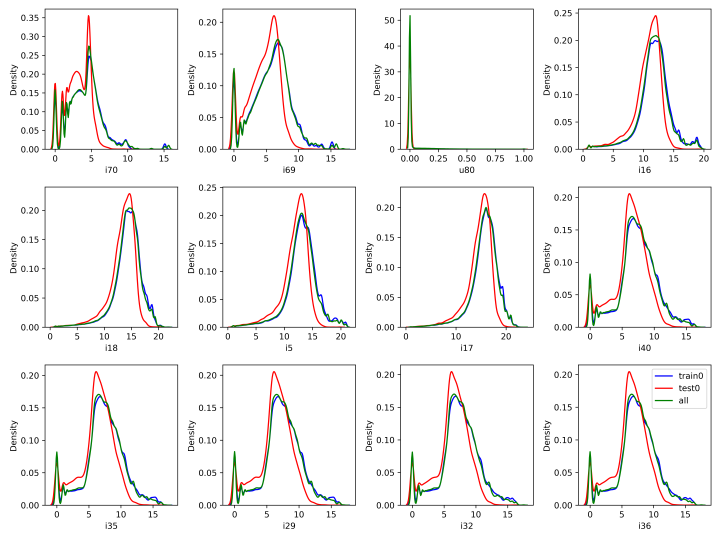 ? 目標(biāo)相關(guān)性top12特征在各集合上的數(shù)據(jù)密度分布曲線
? 目標(biāo)相關(guān)性top12特征在各集合上的數(shù)據(jù)密度分布曲線進(jìn)一步地,我們簡單使用 CatBoost 模型去區(qū)分訓(xùn)練集和測試集,在訓(xùn)練集和測試集中隨機(jī)采樣部分?jǐn)?shù)據(jù),逐個去除特征重要性高的特征,反復(fù)試驗(yàn)做對抗驗(yàn)證。
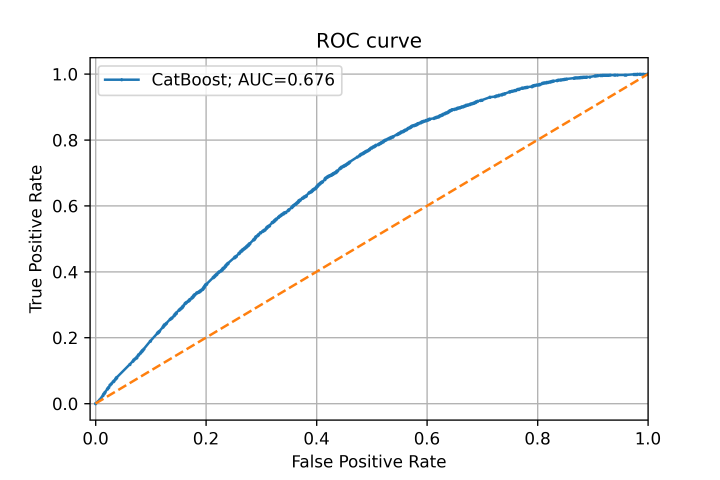 對抗驗(yàn)證模型ROC曲線與基線對比圖
對抗驗(yàn)證模型ROC曲線與基線對比圖我們發(fā)現(xiàn),逐個去除u80、i69、i70、i72、i5、i16、i71、i17、i18、i62、i61、i58、i57、i43、i64、i31、i32、i36、i39等較多特征之后,模型仍然有一定的區(qū)分能力,說明存在較多分布差異大的特征。
另外,我們通過對用戶冷啟動的分析發(fā)現(xiàn),在線下已知的所有數(shù)據(jù)中,存在約28%的重復(fù)樣本,重復(fù)樣本較多,訓(xùn)練集與測試集中都出現(xiàn)的老用戶數(shù)和總用戶數(shù)之比僅為 769/351744 ,也就是說,只有不到0.22%的用戶是老用戶,測試集幾乎全是新用戶。由此可以判斷出數(shù)據(jù)樣本量過小以至于樣本構(gòu)成十分不穩(wěn)定。
在數(shù)據(jù)分析期間,我們還做了許多新特征的衍生和構(gòu)建,發(fā)現(xiàn)了一些能有效漲點(diǎn)的歷史統(tǒng)計(jì)特征和交叉特征,如歷史滑窗點(diǎn)擊次數(shù)和惡意點(diǎn)擊率、多次點(diǎn)擊的時(shí)間差和標(biāo)準(zhǔn)差、商品歷史獨(dú)立訪客數(shù)和熵等,考慮到 FlinkSQL 實(shí)現(xiàn)麻煩和延遲較高等問題,在特征挖掘方向的探索止步于此。
至此,經(jīng)過前面的數(shù)據(jù)分析可以發(fā)現(xiàn)存在三個問題:
數(shù)據(jù)數(shù)量上,有標(biāo)簽的數(shù)據(jù)量較少,重復(fù)樣本較多 數(shù)據(jù)質(zhì)量上,特征冗余較多,存在3個無效特征 測試集和訓(xùn)練集的數(shù)據(jù)分布差異大
后續(xù)思考方案可以對這些問題做針對性的優(yōu)化改進(jìn)。
調(diào)優(yōu)方案與權(quán)衡
根據(jù)對賽題和數(shù)據(jù)的深入理解,可以了解到風(fēng)控系統(tǒng)對算法和工程要求都很高,要快要準(zhǔn)又要安全,而本賽題的數(shù)據(jù)標(biāo)簽少、特征冗余多、數(shù)據(jù)分布差異又大,所以我們的總體調(diào)優(yōu)方案分成四部分,分別是對數(shù)據(jù)、算法、工程和策略的優(yōu)化。策略優(yōu)化在各個步驟之中體現(xiàn)。

2.1 數(shù)據(jù)優(yōu)化
第一大方向是數(shù)據(jù)優(yōu)化,包括用黑白名單做數(shù)據(jù)增廣和用特征切片做特征篩選,提高數(shù)據(jù)的數(shù)量和質(zhì)量。
2.1.1 數(shù)據(jù)增廣
受到風(fēng)控策略中對用戶分級分類建立黑白灰名單的啟發(fā),將黑白名單引入數(shù)據(jù)增廣策略之中。
根據(jù)前面對打標(biāo)簽邏輯的理解,可以將原先的單一點(diǎn)擊行為標(biāo)簽細(xì)化到用戶和商品(商家)上,針對已有標(biāo)簽的樣本,對其行為關(guān)聯(lián)的用戶和商品兩兩建立黑白名單,通過已知樣本的標(biāo)簽推理出未知樣本的標(biāo)簽。
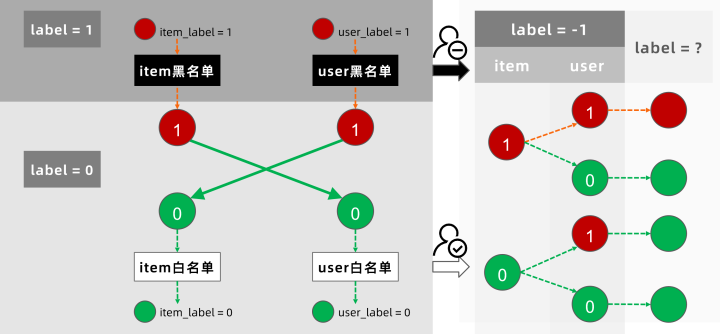 ? ?黑白名單策略示意圖
? ?黑白名單策略示意圖黑白名單策略如圖所示,具體步驟如下:
① 對于label=1的樣本,用戶和商品都是惡意的,將其標(biāo)記為1得到兩個黑名單;
② 對于label=0的樣本,結(jié)合黑名單中標(biāo)記過的id,只要用戶或商品其中一個標(biāo)簽是惡意的,那么另一個大概率是正常的,將其標(biāo)記為0,由此可又以得到兩個白名單;
③ 對于label=-1的樣本,通過黑白名單判斷(label = user_label * item_label)得到最終的行為標(biāo)簽。
根據(jù)黑白名單的方法我們可以將原先10w的標(biāo)簽數(shù)據(jù)擴(kuò)充到30w+,數(shù)據(jù)量增加了兩倍,可以緩解數(shù)據(jù)量少的問題。
2.1.2 特征篩選
考慮到賽方提供的數(shù)據(jù)都是匿名特征,可能是embedding或標(biāo)準(zhǔn)化后的數(shù)據(jù),所有特征對于深度神經(jīng)網(wǎng)絡(luò)來說可能都有用,所以我們并沒有篩掉很多特征,僅篩掉前面數(shù)據(jù)分析時(shí)發(fā)現(xiàn)的3個全部值都一樣的無效特征。
考慮到工程實(shí)現(xiàn)的簡潔性,直接在模型內(nèi)實(shí)現(xiàn)一個預(yù)處理層,輸入時(shí)以特征切片的形式把3個無效特征切掉,將剩余的有效特征合并,再傳入模型做后續(xù)計(jì)算,提高數(shù)據(jù)質(zhì)量的同時(shí)模型復(fù)雜度也隨之減小,還省去了寫FlinkSQL。
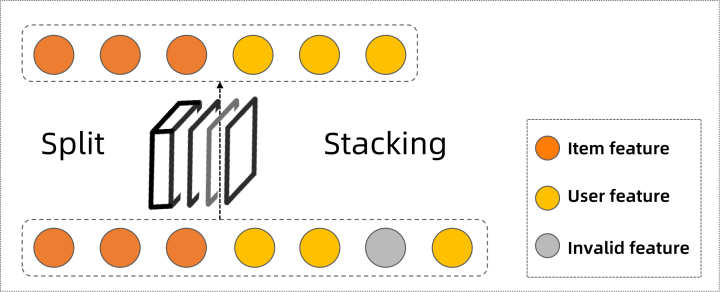
特征切片預(yù)處理層示意圖
class?SplitUI(Layer):
????#?忽略無效特征
????def?__init__(self,?**kwargs):
????????super(SplitUI,?self).__init__(**kwargs)
????def?call(self,?inputs):
????????#?按第二個維度對tensor進(jìn)行切片,返回一個list
????????in_dim?=?K.int_shape(inputs)[-1]
????????assert?in_dim?==?152
????????#?忽略掉149,150,151
????????return?[inputs[:,?:72],?inputs[:,?72:72+76],?inputs[:,?148+3:152]]
????def?compute_output_shape(self,?input_shape):
????????return?[(None,?72),?(None,?76),?(None,?1)]
2.2 算法優(yōu)化
第二大方向是算法優(yōu)化,包括模型結(jié)構(gòu)和訓(xùn)練策略的優(yōu)化,提高模型訓(xùn)練效率和泛化能力。
2.2.1 基線模型框架
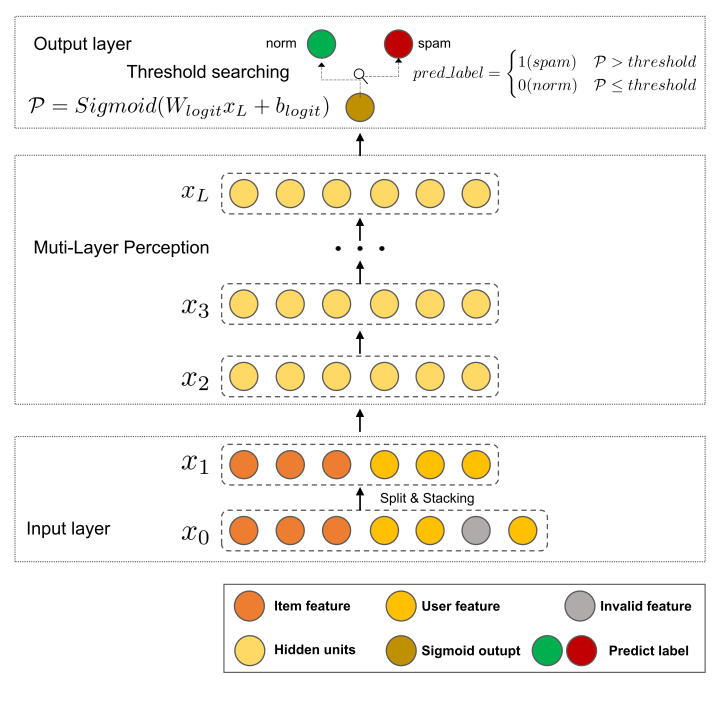
基線模型框架圖
暫時(shí)不管模型參數(shù)設(shè)置,我們先構(gòu)建一個基線模型的框架,類似漢堡的結(jié)構(gòu)。
輸入層就是前面說的預(yù)處理層,中間層是最樸素的MLP,最后一層是閾值層,閾值層里的閾值搜索和以往那些評估F1的競賽大體上一樣,就是多一步,搜完最佳閾值要加進(jìn)模型里。
本賽題中使用閾值搜索的具體步驟如下:
① 先訓(xùn)練并保存一個輸出為Sigmoid的模型;
② 讀取保存的模型,在驗(yàn)證集上做閾值搜索,找到最高F1所在的最佳閾值;
③ 將最佳閾值追加至模型最后一層把Sigmoid的輸出變成01標(biāo)簽。
④ 保存并凍結(jié)模型
中間的MLP雖然很快但缺點(diǎn)也很明顯,表達(dá)能力受限,所以我們考慮換用復(fù)雜一點(diǎn)的模型。
一開始也是直接套模型,魔改網(wǎng)絡(luò),雙塔結(jié)構(gòu)、加注意力、加專家網(wǎng)絡(luò)等等,曾經(jīng)嘗試過推薦系統(tǒng)里的CTR模型,比如說,Wide&Deep、AutoInt、DCN-Mix、deepFM等等,要么復(fù)雜度極高訓(xùn)練極慢,要么訓(xùn)練蠻快的但效果一般。直到復(fù)賽結(jié)束的前幾天我們也還在嘗試各種復(fù)雜模型,結(jié)果表明,不理解數(shù)據(jù)和模型就生搬硬套純屬浪費(fèi)時(shí)間。我們的問題可能在于沒有考慮到數(shù)據(jù)分布差異和特征冗余的情況,所以我們決定就在最簡單的MLP上不斷疊加buff,來緩解或解決這些問題。
2.2.2 模型結(jié)構(gòu)優(yōu)化
針對數(shù)據(jù)冗余問題,我們設(shè)計(jì)了一個簡單高效的深度白化殘差網(wǎng)絡(luò) DeepWRN (Deep Whitening Residual Networks),把基線模型框架里的MLP替換成了我們設(shè)計(jì)的 DeepWRN。
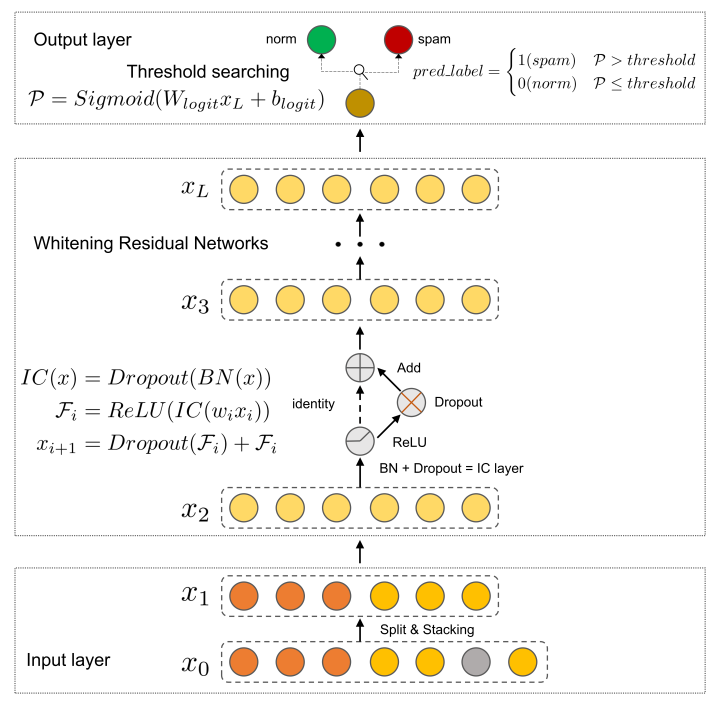 ? ?深度白化殘差網(wǎng)絡(luò)模型框架圖
? ?深度白化殘差網(wǎng)絡(luò)模型框架圖思路很簡單,用于降噪的“白化”可以消除數(shù)據(jù)冗余,類似集成學(xué)習(xí)的“殘差”可以提升模型性能。
實(shí)現(xiàn)也很簡單,深度白化殘差網(wǎng)絡(luò)在MLP基礎(chǔ)上僅需組合 BatchNorm、Dropout 和 Add 這三個簡單操作即可實(shí)現(xiàn)。簡單來說就是,把每一個BN層后面都加上Dropout,然后經(jīng)過ReLU激活再把Dropout后的值加到原先的輸入上。(其實(shí)殘差部分優(yōu)化空間很大,由于時(shí)間問題還沒有仔細(xì)實(shí)驗(yàn))
展示一下MLP改進(jìn)前后線上的得分情況,F(xiàn)1基本上有3個百分點(diǎn)的提升,總分提高了6.77%。
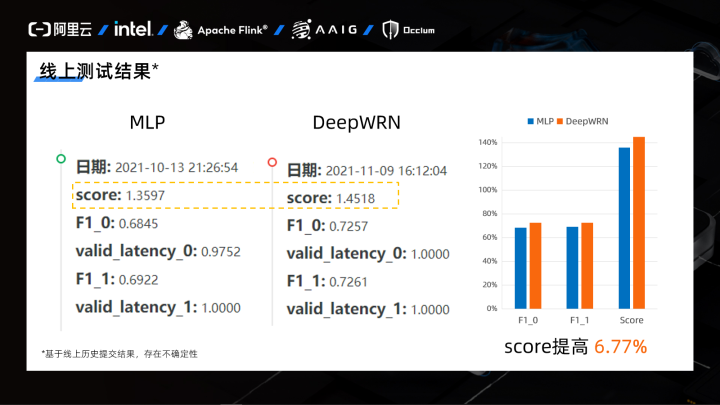 ? ?線上得分情況對比
? ?線上得分情況對比2.2.3 模型解釋
為什么簡單的MLP經(jīng)過改進(jìn)也可以有這么大的性能提升?
下面分別講一下白化層和Dropout殘差結(jié)構(gòu)的設(shè)計(jì)思路、原理和作用。
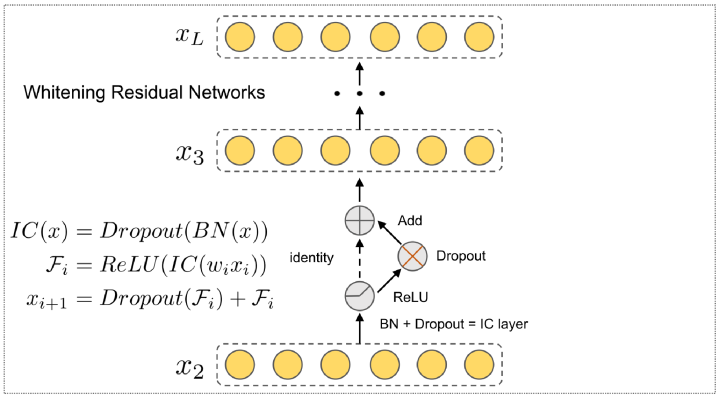 ? ?深度白化殘差網(wǎng)絡(luò)結(jié)構(gòu)
? ?深度白化殘差網(wǎng)絡(luò)結(jié)構(gòu)① 白化層(IC層)
由于前面數(shù)據(jù)分析時(shí)發(fā)現(xiàn)輸入的數(shù)據(jù)特征冗余較多,所以我們要考慮設(shè)計(jì)一個可以消除數(shù)據(jù)冗余的網(wǎng)絡(luò)結(jié)構(gòu),如果不是流計(jì)算,平時(shí)批處理一般都是直接用 PCA 做特征去相關(guān)性,但是考慮到線上環(huán)境比較難實(shí)現(xiàn)預(yù)處理,就思考能不能將這個操作內(nèi)置到模型中,查閱大量文獻(xiàn)后發(fā)現(xiàn) IC 層就可以實(shí)現(xiàn)這個功能。
白化層(IC層)中的 IC 源于獨(dú)立成分分析(Independent Component Analysis)[4] 中前兩個單詞首字母的縮寫。
獨(dú)立成分分析(ICA)起源于“雞尾酒會問題”,在嘈雜的雞尾酒會上,許多人在同時(shí)交談,可能還有背景音樂,但人耳卻能準(zhǔn)確而清晰的聽到對方的話語。這種可以從混合聲音中選擇自己感興趣的聲音而忽略其他聲音的現(xiàn)象稱為“雞尾酒會效應(yīng)”。ICA 就是從盲源分離技術(shù)發(fā)展而來的一種數(shù)據(jù)驅(qū)動的信號處理方法,是一種基于高階統(tǒng)計(jì)特性的分析方法。它利用統(tǒng)計(jì)原理,通過線性變換把數(shù)據(jù)或信號分離成統(tǒng)計(jì)獨(dú)立的非高斯的信號源的線性組合[5]。
簡而言之,ICA 就是用來降噪的。
要注意到的一點(diǎn)就是,ICA白化前需要做預(yù)處理,對輸入數(shù)據(jù)做標(biāo)準(zhǔn)化。在傳統(tǒng)用法里,ICA白化的計(jì)算量很大,但如今已經(jīng)出現(xiàn)了很多內(nèi)置在深度學(xué)習(xí)框架里被深度優(yōu)化過的操作,比如 BatchNorm 和 Dropout,計(jì)算量很小,能否用這些操作替代或近似ICA白化呢?有研究團(tuán)隊(duì)就發(fā)現(xiàn) BatchNorm+Dropout 可以實(shí)現(xiàn)近似 ICA 的效果[6]。本次比賽沒有完全照搬論文,代碼實(shí)現(xiàn)大概就是下面這樣。
deep?=?Dense(units,?use_bias=False)(deep)
deep?=?BatchNormalization()(deep)
deep?=?Dropout(deep_dropout_rate)(deep)
下面分別解釋一下 BatchNorm 和 Dropout 這兩個操作的用法。
① BatchNorm 使得輸入變量具有零均值和單位方差[7],這恰好就和白化前的標(biāo)準(zhǔn)化一樣,可以將其替換掉白化前的預(yù)處理操作。
② Dropout 以某個概率隨機(jī)失活部分神經(jīng)元[8]。對于 BatchNorm 后高斯分布下的數(shù)據(jù),獨(dú)立性和不相關(guān)性互為充要條件,去相關(guān)就等價(jià)于獨(dú)立,而 Dropout 可以消除特征間的相關(guān)性,使得輸入神經(jīng)元的數(shù)據(jù)是統(tǒng)計(jì)獨(dú)立的,學(xué)習(xí)這些特征的各神經(jīng)元在統(tǒng)計(jì)上也變得彼此獨(dú)立。
經(jīng)過以上分析,BatchNorm+Dropout組合后就得到的 IC層就可以近似 ICA 白化。
以一個神經(jīng)科學(xué)研究得出的結(jié)論作為理論基礎(chǔ),神經(jīng)網(wǎng)絡(luò)的表達(dá)能力隨獨(dú)立神經(jīng)元的數(shù)量增加而線性增加[9],由此可知,使用 IC層的神經(jīng)網(wǎng)絡(luò)的表達(dá)能力會隨著獨(dú)立神經(jīng)元的數(shù)量增多而提高。
與此同時(shí),BatchNorm 和 Dropout 都有緩解過擬合的作用,BatchNorm 還有加速收斂、防止梯度彌散等作用。
② Dropout 殘差結(jié)構(gòu)
這里的殘差沒有用標(biāo)準(zhǔn)的殘差結(jié)構(gòu),只是借鑒了殘差思想,說成是 Dropout Ensemble 也行,將通過IC層后的特征向量再次進(jìn)行一次 Dropout,和原來的輸入(恒等映射)進(jìn)行簡單的 Add 操作。
deep?=?ReLU()(deep)
deep_res?=?Dropout(deep_dropout_rate)(deep)
deep?=?add([deep_res,?deep])
當(dāng)時(shí)設(shè)計(jì)網(wǎng)絡(luò)時(shí)沒有考慮太多,只想著盡量保證模型復(fù)雜度和MLP一致的情況下提高模型泛化,其實(shí)后面實(shí)驗(yàn)時(shí)發(fā)現(xiàn),如果把IC層加進(jìn)標(biāo)準(zhǔn)的殘差單元里,雖然參數(shù)量會翻倍,但效果會好上不少。
對于kaiming大神的 ResNet[10]大家眾說紛紜,我們也不能很好的解釋其發(fā)揮效用的真實(shí)原因,下面是直覺上我們認(rèn)為 Dropout 殘差結(jié)構(gòu)發(fā)揮的作用:
在殘差單元內(nèi)使用 Dropout,進(jìn)一步提高各神經(jīng)元的獨(dú)立性,增強(qiáng)模型表達(dá)能力。 殘差相加的操作類似于模型內(nèi)的集成學(xué)習(xí)[11],可以提高模型魯棒性。 顯式修改網(wǎng)絡(luò)結(jié)構(gòu),加入殘差通路,讓網(wǎng)絡(luò)更容易學(xué)習(xí)到恒等映射[12],模型更容易訓(xùn)練,同時(shí)確保模型效果不會因網(wǎng)絡(luò)變深而越來越差。
最后,組合白化層和 Dropout 殘差結(jié)構(gòu)就得到了我們設(shè)計(jì)的深度白化殘差網(wǎng)絡(luò),實(shí)現(xiàn)簡單且性能強(qiáng)勁。

線下消融實(shí)驗(yàn)
因?yàn)楫?dāng)時(shí)我們提前發(fā)現(xiàn)了線上環(huán)境第一階段推理進(jìn)程不結(jié)束的問題,給官方反映了 issue ,這個被問題解決后又出現(xiàn)了新問題,恰好那時(shí)我們倆都比較忙,沒剩多少時(shí)間改了,所以直接不考慮第二階段了。
這里MLP的隱層設(shè)置為[256,128,32,8],可以發(fā)現(xiàn)在原始的4層MLP上增加IC層和Dropout殘差結(jié)構(gòu),在參數(shù)量和計(jì)算量幾乎沒變的情況下,分?jǐn)?shù)都有很大提升。
驗(yàn)")
2.2.4 訓(xùn)練策略優(yōu)化
因?yàn)閿?shù)據(jù)量比較少,針對類別不平衡問題,我們優(yōu)先考慮在損失函數(shù)上下功夫,對于時(shí)間限制等問題考慮使用更高效的訓(xùn)練方式和定制化的訓(xùn)練配置。
Focal loss + 自適應(yīng)學(xué)習(xí)率衰減
一開始嘗試過直接調(diào)交叉熵的 Class weight,也有一點(diǎn)效果,但是當(dāng)我們嘗試使用 Focal loss 后發(fā)現(xiàn),模型驗(yàn)證階段的 Precision 一下子就提了上來。也嘗試過 Combo loss,就是把各種 Loss 加在一起,發(fā)現(xiàn)調(diào)各個 Loss 的權(quán)重十分麻煩,所以后面一直都是用的固定參數(shù)的 Focal loss。
import?tensorflow.keras.backend?as?K
from?tensorflow.keras.losses?import?binary_crossentropy
def?FocalLoss(y_true,?y_pred,?alpha=0.75,?gamma=2.0):
????BCE?=?binary_crossentropy(y_true,?y_pred)
????BCE_EXP?=?K.exp(-BCE)
????focal_loss?=?K.mean(alpha?*?K.pow((1-BCE_EXP),?gamma)?*?BCE)
????return?focal_loss
自適應(yīng)學(xué)習(xí)率衰減就是callbacks里的這個ReduceLROnPlateau,監(jiān)控的指標(biāo)變化不大時(shí),到指定輪數(shù),調(diào)度器就會把學(xué)習(xí)率乘一個衰減系數(shù),這里是直接減半了。
from?tensorflow.keras.callbacks?import?ReduceLROnPlateau
ReduceLROnPlateau(monitor='val_loss',?factor=0.5,patience=6,?verbose=1,?mode='auto',epsilon=1e-6,?cooldown=1,?min_lr=1e-7)
在模型訓(xùn)練前期,使用較大學(xué)習(xí)率可以加速模型收斂,在后期,使用小學(xué)習(xí)率在小批量訓(xùn)練情況下容易發(fā)揮 Focal loss 的作用,明顯提高模型精確度。Focal loss使得網(wǎng)絡(luò)不會被大量的負(fù)例帶偏,自適應(yīng)學(xué)習(xí)率衰減可以保證訓(xùn)練時(shí)長合適,不會一直在一個鞍點(diǎn)打轉(zhuǎn),訓(xùn)練更高效。
交叉訓(xùn)練
數(shù)據(jù)集去重后打亂并對半劃分,訓(xùn)練集和驗(yàn)證集交叉使用,第一次訓(xùn)練結(jié)束后,加載最佳模型,使用驗(yàn)證集再繼續(xù)訓(xùn)練。
說實(shí)話,這個比較玄學(xué)...我們的理解是,這種訓(xùn)練方式可以充分利用已有標(biāo)簽數(shù)據(jù),數(shù)據(jù)利用最大化的同時(shí)防止模型過擬合,提高模型泛化能力。具體用法可以看 Github。
自定義回調(diào)函數(shù)
實(shí)現(xiàn)了自定義保存 checkpoint 的開始輪數(shù)、停止訓(xùn)練的最大輪數(shù)和最長時(shí)間等功能,結(jié)合合適的自適應(yīng)學(xué)習(xí)率早停可以省下更多時(shí)間,確保線上訓(xùn)練不超時(shí)。具體實(shí)現(xiàn)可以看 Github。
2.3 工程優(yōu)化
第三大方向是工程優(yōu)化,包括推理前 Warm-up 和工程簡化,保證安全的同時(shí)盡量降低推理延遲。
工程分析
因?yàn)樵谂判邪裰邪l(fā)現(xiàn)好多人雖然第一階段延遲分沒有滿分,但是第二階段居然一直是滿分,所以我們嘗試探究其中的原因,debug 過程中發(fā)現(xiàn),在復(fù)賽基礎(chǔ)鏡像版本中,Cluster serving 在進(jìn)行第一次推理的時(shí)候,CPU的內(nèi)核級進(jìn)程占用會非常高,在htop中會體現(xiàn)出半紅半綠的情況,其中,紅色表示內(nèi)核級進(jìn)程,綠色表示用戶級。
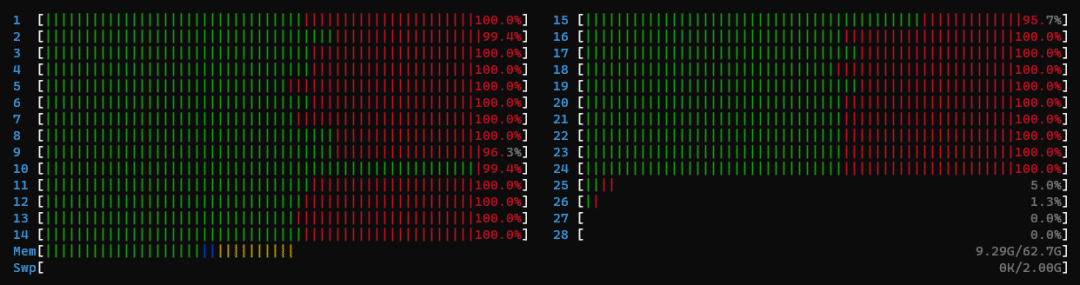 第一階段進(jìn)程占用
第一階段進(jìn)程占用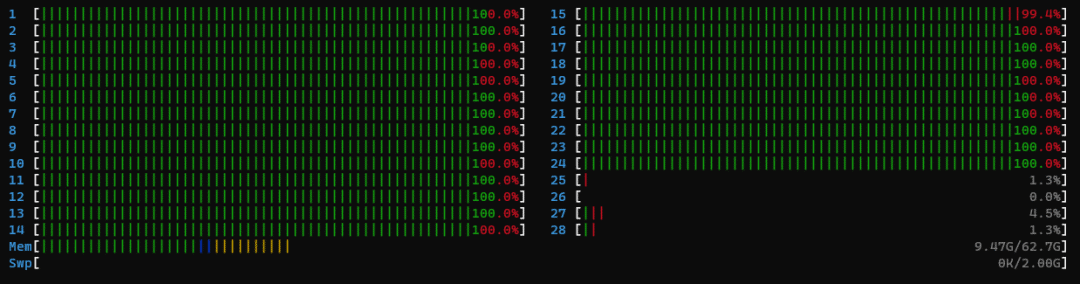
第二階段進(jìn)程占用
第一階段,kernel級的進(jìn)程占用率大概是一半,然而在第二次推理的時(shí)候,綠色條會占滿,幾乎都是用戶級進(jìn)程。對比兩個階段的推理延遲我們發(fā)現(xiàn),第二階段的推理延遲比第一階段低非常多。所以我們懷疑基礎(chǔ)版本鏡像中的第一階段的 Cluster serving 只用了CPU一半的算力(綠色部分),另一半的內(nèi)核級進(jìn)程(紅色部分)在處理其他任務(wù)。
經(jīng)過上面的分析,可以明確的一點(diǎn)就是,如果在第一階段前再加一個“第零階段”,也就是 Warm-up,可以讓工作流在進(jìn)入第一階段推理時(shí)用戶級進(jìn)程占用處于“滿血”狀態(tài),最大化 Cluster serving 的性能。
推理前 Warm-up
由于要保證數(shù)據(jù)安全,我們不能提前讀取賽方提供的數(shù)據(jù),于是我們通過構(gòu)造2w條隨機(jī)數(shù)據(jù)來模擬數(shù)據(jù)流,提前觸發(fā)推理模型部署,預(yù)熱 Flink 的推理進(jìn)程以實(shí)現(xiàn)線上推理能夠發(fā)揮出CPU的性能極致。
至于為什么是2w條而不是2k條,我們也是將延遲可視化后發(fā)現(xiàn)的,如果只用很少的數(shù)據(jù)去預(yù)熱,第一階段正式推理時(shí)會有一部分?jǐn)?shù)據(jù)超時(shí),而用2w條就好很多,線下實(shí)驗(yàn)了幾次之后才決定使用2w條數(shù)據(jù)預(yù)熱,可以保證第一階段不會出現(xiàn)延遲超時(shí)。
用盡量更少的數(shù)據(jù),花更少的時(shí)間去預(yù)熱。
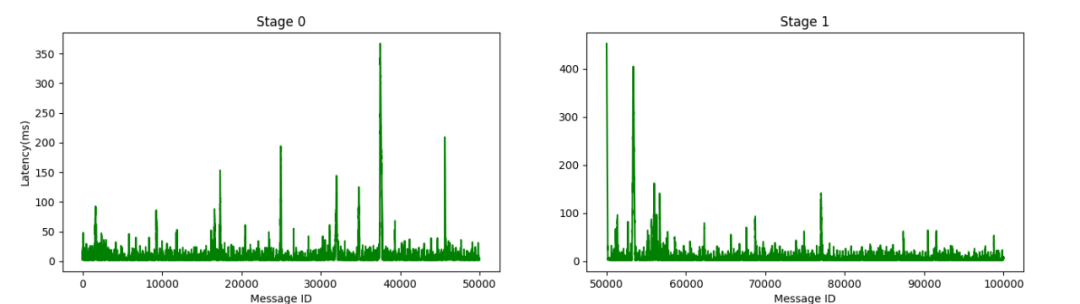
充分預(yù)熱后的兩個階段延遲情況
具體做法就是直接把官方提供的 workflow_utils.py 復(fù)制一份命名為 warmup_util.py,改一改里面的 push_kafka 函數(shù),在 run_bash.sh 里加上一行去調(diào)用它。預(yù)熱時(shí)push速度比第一階段稍慢,以防止 Flink 消費(fèi)不掉 Kafka 生產(chǎn)的消息,一直都壓不下去,具體實(shí)現(xiàn)可以看 Github。
/opt/python-occlum/bin/python3.7?warmup_util.py?--server?localhost:9092?--input_topic?tianchi_input_${time}?--output_topic?tianchi_output_${time}
工程簡化
工程簡化,其實(shí)就是棄用在線特征工程。因?yàn)樵趯?FlinkSQL 做滑窗統(tǒng)計(jì)特征時(shí)發(fā)現(xiàn),雖然新特征能有效漲點(diǎn),但 Warm-up 后居然延遲分不能拿滿,可能由于 Flink 水位線機(jī)制的存在或者其他什么原因,暫時(shí)還沒有深挖。經(jīng)多次嘗試后,我們決定在數(shù)據(jù)和工程上做權(quán)衡,簡化工程,降低難度,避免FlinkSQL在實(shí)時(shí)數(shù)據(jù)流上做特征工程時(shí)帶來的延遲影響。
流量壓力測試

我們使用DeepWRN在線下用比線上稍差的測評環(huán)境(線上環(huán)境的第三代 Intel? CPU是有深度學(xué)習(xí)算子加速優(yōu)化的),做了多次壓力測試實(shí)驗(yàn),通過調(diào)整 Kafka 發(fā)送數(shù)據(jù)流的間隔來模擬不同大小的流量,表格中第一行是線上的測評結(jié)果,其余的是線下的測評結(jié)果,多次結(jié)果取平均后繪制成柱狀圖。
線下非 Occlum 環(huán)境下,當(dāng) Kafka 發(fā)送數(shù)據(jù)的時(shí)間間隔為4ms時(shí),預(yù)熱后可以保證平均延遲僅3ms,而當(dāng)發(fā)送時(shí)間間隔降到原來的20倍時(shí),仍然可以全部通過。線上 Occlum 環(huán)境下,實(shí)測也全部通過,平均延遲僅14ms。說明我們的模型足夠簡單,預(yù)熱策略也足夠好,可以承受更大的流量。
2.4 總工作流

經(jīng)過上面各種策略一套下來,總的工作流就是:
在第一階段訓(xùn)練前,通過黑白名單擴(kuò)充數(shù)據(jù),然后去重,交叉訓(xùn)練,得到并保存最佳模型,搜索最佳閾值后更新模型,然后凍結(jié)成pb文件供 Cluster Serving 調(diào)用;
在第一階段推理前,用自己構(gòu)造的隨機(jī)數(shù)據(jù)通過 Kafka 來模擬數(shù)據(jù)流提前觸發(fā) Flink,對 Cluster Serving 進(jìn)行預(yù)熱,之后再進(jìn)入第一階段做正式推理;
第二階段也是重復(fù)第一階段的操作,更新黑白名單,限時(shí)繼續(xù)訓(xùn)練并推理,因?yàn)闀簳r(shí)沒解決第二階段的問題,所以不預(yù)熱,直接推理。
總結(jié)、思考與改進(jìn)
新點(diǎn)、實(shí)用性、安全性")
曾經(jīng)嘗試但棄用的思路
前面一直在關(guān)注讓模型更快更小更容易落地,但實(shí)際上我們嘗試過很多思路,結(jié)果都不太好才妥協(xié)到現(xiàn)在的方案。
一個是特征工程+偽標(biāo)簽的思路。
初賽時(shí),完全按照傳統(tǒng)數(shù)據(jù)挖掘題來做,針對業(yè)務(wù)背景和數(shù)據(jù)特點(diǎn)做了細(xì)致的特征工程,第一次接觸 Flink,然后發(fā)現(xiàn) FlinkSQL 不懂實(shí)現(xiàn),就放棄了,復(fù)賽時(shí)不想浪費(fèi)之前仔細(xì)挖掘的特征,打算回收再利用。
先是特征工程后訓(xùn)練樹模型,給無標(biāo)簽樣本根據(jù)置信度打上偽標(biāo)簽,再做有監(jiān)督學(xué)習(xí),由于線上用的是CPU,訓(xùn)練時(shí)間太長了,而且 Occlum 會莫名卡住,接著就考慮用深度學(xué)習(xí)模型給它自己打標(biāo)簽,感覺效果不太好,又浪費(fèi)時(shí)間,就戰(zhàn)略性放棄了。
再就是去學(xué)了下 FlinkSQL,考慮做一些簡單的滑窗特征,結(jié)果在線下沒開 Occlum 的情況下,Warm-up 之后延遲還是很大,就又戰(zhàn)略性放棄了。
另一個是表征學(xué)習(xí)的思路。
對歷史交互序列做 Embedding 或者構(gòu)建二部圖做 Embedding,但為了避免線上 Occlum 環(huán)境引入 bug,用的一直是 TF1,得到 Embedding 要一段時(shí)間,構(gòu)建 vlookup 表會特別久,模型參數(shù)量會劇增,存在模型參數(shù)量過大而加載十分緩慢的問題,就棄用了。(可能是我們embedding的打開方式不對?)
最后答辯發(fā)現(xiàn)大家的模型其實(shí)差不多都是MLP,應(yīng)該是嘗試過各種模型卻發(fā)現(xiàn)都沒有MLP效果好才這樣做的,中途我們嘗試過推薦系統(tǒng)里的CTR模型還有一些異常檢測的模型,一些最近比較火的對比學(xué)習(xí)、半監(jiān)督學(xué)習(xí)、多任務(wù)學(xué)習(xí)用TF1實(shí)現(xiàn)比較麻煩,時(shí)間也比較緊就沒用,總之很多模型的效果都一般,甚至不如MLP,由于復(fù)賽沒剩幾天時(shí)間了就放棄探索,與其套用各種fancy的網(wǎng)絡(luò)結(jié)構(gòu),不如直接在MLP上慢慢疊buff。
改進(jìn)方向
競賽后續(xù):
嘗試用GNN之類的半監(jiān)督圖算法 圖建模實(shí)現(xiàn)反欺詐圖算法(如 FRAUDAR[13]、RICD[14] 等),離線擴(kuò)充數(shù)據(jù)再做有監(jiān)督學(xué)習(xí) BTW,RICD[14]就是本次賽題出處的論文,有點(diǎn)像標(biāo)簽傳播,可以再仔細(xì)看一下。
真實(shí)業(yè)務(wù):
可以考慮做更細(xì)致的數(shù)據(jù)埋點(diǎn)和特征挖掘提高數(shù)據(jù)質(zhì)量 引入聯(lián)邦學(xué)習(xí)、知識圖譜等技術(shù)擴(kuò)充數(shù)據(jù)樣本或特征 Flink AI Flow 和 Occlum 配適圖深度學(xué)習(xí)框架或圖計(jì)算框架,優(yōu)化大規(guī)模圖的實(shí)時(shí)構(gòu)建和處理流程
一些感想
和隊(duì)友合得來真的很重要,雖然我倆時(shí)間上都有沖突,各種DDL,一邊是實(shí)驗(yàn)室導(dǎo)師的連環(huán)push,一邊是秋招接連不斷的筆試面試,但是,不到最后一天DDL戰(zhàn)士絕不認(rèn)輸!工程和算法互補(bǔ)完成最后逆襲。
深刻理解數(shù)據(jù)和模型原理真的很重要,如果一開始就選定合適的最終模型,后面就可以直接調(diào)參上分了,不至于像這次這樣一頓亂套各種模型,最后一天的下午才開始調(diào)參。
想當(dāng)算法工程師,工程能力必不可少,算法再吊炸天,工程上遇到問題不會debug,代碼都提交不上,前面全是白費(fèi),很多人估計(jì)在工程這一步給拒之門外,是困難也是機(jī)遇,其他人退縮的同時(shí)也讓給了我們更多的機(jī)會。
碎碎念
從9月到12月,慢慢爬到 rank 2/4537,能茍到這個成績還蠻意外的,其實(shí)自己那時(shí)候還是一個剛接觸競賽沒多久的風(fēng)控小白(其實(shí)想著考研來著嗚嗚嗚我這個菜雞),一切只因 Datawhale 開源分享的 baseline 進(jìn)的坑,后面抱著學(xué)習(xí)的心態(tài)邊秋招邊打比賽,最終拿到了反欺詐方向的offer,也拿到了這個風(fēng)控比賽的亞軍,十分感謝這段時(shí)間里給力隊(duì)友的無縫協(xié)作、老師的支持幫助和工作人員的無私解答。