
使用 EFKLK 搭建 Kubernetes 日志收集工具棧
前面大家介紹了 Kubernetes 集群中的幾種日志收集方案,Kubernetes 中比較流行的日志收集解決方案是 Elasticsearch、Fluentd 和 Kibana(EFK)技術(shù)棧,也是官方現(xiàn)在比較推薦的一種方案。
Elasticsearch 是一個(gè)實(shí)時(shí)的、分布式的可擴(kuò)展的搜索引擎,允許進(jìn)行全文、結(jié)構(gòu)化搜索,它通常用于索引和搜索大量日志數(shù)據(jù),也可用于搜索許多不同類型的文檔。
Elasticsearch 通常與 Kibana 一起部署,Kibana 是 Elasticsearch 的一個(gè)功能強(qiáng)大的數(shù)據(jù)可視化 Dashboard,Kibana 允許你通過 web 界面來瀏覽 Elasticsearch 日志數(shù)據(jù)。
Fluentd是一個(gè)流行的開源數(shù)據(jù)收集器,我們將在 Kubernetes 集群節(jié)點(diǎn)上安裝 Fluentd,通過獲取容器日志文件、過濾和轉(zhuǎn)換日志數(shù)據(jù),然后將數(shù)據(jù)傳遞到 Elasticsearch 集群,在該集群中對其進(jìn)行索引和存儲(chǔ)。
我們先來配置啟動(dòng)一個(gè)可擴(kuò)展的 Elasticsearch 集群,然后在 Kubernetes 集群中創(chuàng)建一個(gè) Kibana 應(yīng)用,最后通過 DaemonSet 來運(yùn)行 Fluentd,以便它在每個(gè) Kubernetes 工作節(jié)點(diǎn)上都可以運(yùn)行一個(gè) Pod。
如果你了解 EFK 的基本原理,只是為了測試可以直接使用 Kubernetes 官方提供的 addon 插件的資源清單,地址:https://github.com/kubernetes/kubernetes/blob/master/cluster/addons/fluentd-elasticsearch/,直接安裝即可。
1安裝 Elasticsearch 集群
在創(chuàng)建 Elasticsearch 集群之前,我們先創(chuàng)建一個(gè)命名空間,我們將在其中安裝所有日志相關(guān)的資源對象。
kubectl create ns logging
環(huán)境準(zhǔn)備
ElasticSearch 安裝有最低安裝要求,如果安裝后 Pod 無法正常啟動(dòng),請檢查是否符合最低要求的配置,要求如下:

這里我們要安裝的 ES 集群環(huán)境信息如下所示:

這里我們使用一個(gè) NFS 類型的 StorageClass 來做持久化存儲(chǔ),當(dāng)然如果你是線上環(huán)境建議使用 Local PV 或者 Ceph RBD 之類的存儲(chǔ)來持久化 Elasticsearch 的數(shù)據(jù)。
此外由于 ElasticSearch 7.x 版本默認(rèn)安裝了 X-Pack 插件,并且部分功能免費(fèi),需要我們配置一些安全證書文件。
1、生成證書文件
# 運(yùn)行容器生成證書
$ docker run --name elastic-certs -i -w /app elasticsearch:7.12.0 /bin/sh -c \
"elasticsearch-certutil ca --out /app/elastic-stack-ca.p12 --pass '' && \
elasticsearch-certutil cert --name security-master --dns \
security-master --ca /app/elastic-stack-ca.p12 --pass '' --ca-pass '' --out /app/elastic-certificates.p12"
# 從容器中將生成的證書拷貝出來
$ docker cp elastic-certs:/app/elastic-certificates.p12 .
# 刪除容器
$ docker rm -f elastic-certs
# 將 pcks12 中的信息分離出來,寫入文件
$ openssl pkcs12 -nodes -passin pass:'' -in elastic-certificates.p12 -out elastic-certificate.pem
2、添加證書到 Kubernetes
# 添加證書
$ kubectl create secret -n logging generic elastic-certs --from-file=elastic-certificates.p12
# 設(shè)置集群用戶名密碼
$ kubectl create secret -n logging generic elastic-auth --from-literal=username=elastic --from-literal=password=ydzsio321
安裝 ES 集群
首先添加 ELastic 的 Helm 倉庫:
helm repo add elastic https://helm.elastic.co
helm repo update
ElaticSearch 安裝需要安裝三次,分別安裝 Master、Data、Client 節(jié)點(diǎn),Master 節(jié)點(diǎn)負(fù)責(zé)集群間的管理工作;Data 節(jié)點(diǎn)負(fù)責(zé)存儲(chǔ)數(shù)據(jù);Client 節(jié)點(diǎn)負(fù)責(zé)代理 ElasticSearch Cluster 集群,負(fù)載均衡。
首先使用 helm pull 拉取 Chart 并解壓:
helm pull elastic/elasticsearch --untar --version 7.12.0
cd elasticsearch
在 Chart 目錄下面創(chuàng)建用于 Master 節(jié)點(diǎn)安裝配置的 values 文件:
# values-master.yaml
## 設(shè)置集群名稱
clusterName: "elasticsearch"
## 設(shè)置節(jié)點(diǎn)名稱
nodeGroup: "master"
## 設(shè)置角色
roles:
master: "true"
ingest: "false"
data: "false"
# ============鏡像配置============
## 指定鏡像與鏡像版本
image: "elasticsearch"
imageTag: "7.12.0"
## 副本數(shù)
replicas: 3
# ============資源配置============
## JVM 配置參數(shù)
esJavaOpts: "-Xmx1g -Xms1g"
## 部署資源配置(生成環(huán)境一定要設(shè)置大些)
resources:
requests:
cpu: "2000m"
memory: "2Gi"
limits:
cpu: "2000m"
memory: "2Gi"
## 數(shù)據(jù)持久卷配置
persistence:
enabled: true
## 存儲(chǔ)數(shù)據(jù)大小配置
volumeClaimTemplate:
storageClassName: nfs-storage
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 5Gi
# ============安全配置============
## 設(shè)置協(xié)議,可配置為 http、https
protocol: http
## 證書掛載配置,這里我們掛入上面創(chuàng)建的證書
secretMounts:
- name: elastic-certs
secretName: elastic-certs
path: /usr/share/elasticsearch/config/certs
## 允許您在/usr/share/elasticsearch/config/中添加任何自定義配置文件,例如 elasticsearch.yml
## ElasticSearch 7.x 默認(rèn)安裝了 x-pack 插件,部分功能免費(fèi),這里我們配置下
## 下面注掉的部分為配置 https 證書,配置此部分還需要配置 helm 參數(shù) protocol 值改為 https
esConfig:
elasticsearch.yml: |
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
# xpack.security.http.ssl.enabled: true
# xpack.security.http.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
# xpack.security.http.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
## 環(huán)境變量配置,這里引入上面設(shè)置的用戶名、密碼 secret 文件
extraEnvs:
- name: ELASTIC_USERNAME
valueFrom:
secretKeyRef:
name: elastic-auth
key: username
- name: ELASTIC_PASSWORD
valueFrom:
secretKeyRef:
name: elastic-auth
key: password
# ============調(diào)度配置============
## 設(shè)置調(diào)度策略
## - hard:只有當(dāng)有足夠的節(jié)點(diǎn)時(shí) Pod 才會(huì)被調(diào)度,并且它們永遠(yuǎn)不會(huì)出現(xiàn)在同一個(gè)節(jié)點(diǎn)上
## - soft:盡最大努力調(diào)度
antiAffinity: "soft"
tolerations:
- operator: "Exists" ##容忍全部污點(diǎn)
然后創(chuàng)建用于 Data 節(jié)點(diǎn)安裝的 values 文件:
# values-data.yaml
# ============設(shè)置集群名稱============
## 設(shè)置集群名稱
clusterName: "elasticsearch"
## 設(shè)置節(jié)點(diǎn)名稱
nodeGroup: "data"
## 設(shè)置角色
roles:
master: "false"
ingest: "true"
data: "true"
# ============鏡像配置============
## 指定鏡像與鏡像版本
image: "elasticsearch"
imageTag: "7.12.0"
## 副本數(shù)(建議設(shè)置為3,我這里資源不足只用了1個(gè)副本)
replicas: 1
# ============資源配置============
## JVM 配置參數(shù)
esJavaOpts: "-Xmx1g -Xms1g"
## 部署資源配置(生成環(huán)境一定要設(shè)置大些)
resources:
requests:
cpu: "1000m"
memory: "2Gi"
limits:
cpu: "1000m"
memory: "2Gi"
## 數(shù)據(jù)持久卷配置
persistence:
enabled: true
## 存儲(chǔ)數(shù)據(jù)大小配置
volumeClaimTemplate:
storageClassName: nfs-storage
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi
# ============安全配置============
## 設(shè)置協(xié)議,可配置為 http、https
protocol: http
## 證書掛載配置,這里我們掛入上面創(chuàng)建的證書
secretMounts:
- name: elastic-certs
secretName: elastic-certs
path: /usr/share/elasticsearch/config/certs
## 允許您在/usr/share/elasticsearch/config/中添加任何自定義配置文件,例如 elasticsearch.yml
## ElasticSearch 7.x 默認(rèn)安裝了 x-pack 插件,部分功能免費(fèi),這里我們配置下
## 下面注掉的部分為配置 https 證書,配置此部分還需要配置 helm 參數(shù) protocol 值改為 https
esConfig:
elasticsearch.yml: |
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
# xpack.security.http.ssl.enabled: true
# xpack.security.http.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
# xpack.security.http.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
## 環(huán)境變量配置,這里引入上面設(shè)置的用戶名、密碼 secret 文件
extraEnvs:
- name: ELASTIC_USERNAME
valueFrom:
secretKeyRef:
name: elastic-auth
key: username
- name: ELASTIC_PASSWORD
valueFrom:
secretKeyRef:
name: elastic-auth
key: password
# ============調(diào)度配置============
## 設(shè)置調(diào)度策略
## - hard:只有當(dāng)有足夠的節(jié)點(diǎn)時(shí) Pod 才會(huì)被調(diào)度,并且它們永遠(yuǎn)不會(huì)出現(xiàn)在同一個(gè)節(jié)點(diǎn)上
## - soft:盡最大努力調(diào)度
antiAffinity: "soft"
## 容忍配置
tolerations:
- operator: "Exists" ##容忍全部污點(diǎn)
最后一個(gè)是用于創(chuàng)建 Client 節(jié)點(diǎn)的 values 文件:
# values-client.yaml
# ============設(shè)置集群名稱============
## 設(shè)置集群名稱
clusterName: "elasticsearch"
## 設(shè)置節(jié)點(diǎn)名稱
nodeGroup: "client"
## 設(shè)置角色
roles:
master: "false"
ingest: "false"
data: "false"
# ============鏡像配置============
## 指定鏡像與鏡像版本
image: "elasticsearch"
imageTag: "7.12.0"
## 副本數(shù)
replicas: 1
# ============資源配置============
## JVM 配置參數(shù)
esJavaOpts: "-Xmx1g -Xms1g"
## 部署資源配置(生成環(huán)境一定要設(shè)置大些)
resources:
requests:
cpu: "1000m"
memory: "2Gi"
limits:
cpu: "1000m"
memory: "2Gi"
## 數(shù)據(jù)持久卷配置
persistence:
enabled: false
# ============安全配置============
## 設(shè)置協(xié)議,可配置為 http、https
protocol: http
## 證書掛載配置,這里我們掛入上面創(chuàng)建的證書
secretMounts:
- name: elastic-certs
secretName: elastic-certs
path: /usr/share/elasticsearch/config/certs
## 允許您在/usr/share/elasticsearch/config/中添加任何自定義配置文件,例如 elasticsearch.yml
## ElasticSearch 7.x 默認(rèn)安裝了 x-pack 插件,部分功能免費(fèi),這里我們配置下
## 下面注掉的部分為配置 https 證書,配置此部分還需要配置 helm 參數(shù) protocol 值改為 https
esConfig:
elasticsearch.yml: |
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
# xpack.security.http.ssl.enabled: true
# xpack.security.http.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
# xpack.security.http.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
## 環(huán)境變量配置,這里引入上面設(shè)置的用戶名、密碼 secret 文件
extraEnvs:
- name: ELASTIC_USERNAME
valueFrom:
secretKeyRef:
name: elastic-auth
key: username
- name: ELASTIC_PASSWORD
valueFrom:
secretKeyRef:
name: elastic-auth
key: password
# ============Service 配置============
service:
type: NodePort
nodePort: "30200"
現(xiàn)在用上面的 values 文件來安裝:
# 安裝 master 節(jié)點(diǎn)
helm install es-master -f values-master.yaml --namespace logging .
# 安裝 data 節(jié)點(diǎn)
helm install es-data -f values-data.yaml --namespace logging .
# 安裝 client 節(jié)點(diǎn)
helm install es-client -f values-client.yaml --namespace logging .安裝 Kibana
Elasticsearch 集群安裝完成后接下來配置安裝 Kibana
使用 helm pull 命令拉取 Kibana Chart 包并解壓:
helm pull elastic/kibana --untar --version 7.12.0
cd kibana
創(chuàng)建用于安裝 Kibana 的 values 文件:
# values-prod.yaml
## 指定鏡像與鏡像版本
image: "kibana"
imageTag: "7.12.0"
## 配置 ElasticSearch 地址
elasticsearchHosts: "http://elasticsearch-client:9200"
# ============環(huán)境變量配置============
## 環(huán)境變量配置,這里引入上面設(shè)置的用戶名、密碼 secret 文件
extraEnvs:
- name: "ELASTICSEARCH_USERNAME"
valueFrom:
secretKeyRef:
name: elastic-auth
key: username
- name: "ELASTICSEARCH_PASSWORD"
valueFrom:
secretKeyRef:
name: elastic-auth
key: password
# ============資源配置============
resources:
requests:
cpu: "500m"
memory: "1Gi"
limits:
cpu: "500m"
memory: "1Gi"
# ============配置 Kibana 參數(shù)============
## kibana 配置中添加語言配置,設(shè)置 kibana 為中文
kibanaConfig:
kibana.yml: |
i18n.locale: "zh-CN"
# ============Service 配置============
service:
type: NodePort
nodePort: "30601"
使用上面的配置直接安裝即可:
helm install kibana -f values-prod.yaml --namespace logging .
下面是安裝完成后的 ES 集群和 Kibana 資源:
[root@node2 ~]# kubectl get pods -n logging
NAME READY STATUS RESTARTS AGE
elasticsearch-client-0 1/1 Running 0 13m
elasticsearch-data-0 1/1 Running 0 17m
elasticsearch-master-0 1/1 Running 0 14m
elasticsearch-master-1 1/1 Running 0 16m
elasticsearch-master-2 1/1 Running 0 18m
kibana-kibana-66f97964b-pmqlq 1/1 Running 0 31s
[root@node2 ~]# kubectl get svc -n logging
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch-client NodePort 10.102.35.207 <none> 9200:30200/TCP,9300:30078/TCP 33m
elasticsearch-client-headless ClusterIP None <none> 9200/TCP,9300/TCP 33m
elasticsearch-data ClusterIP 10.97.179.233 <none> 9200/TCP,9300/TCP 37m
elasticsearch-data-headless ClusterIP None <none> 9200/TCP,9300/TCP 37m
elasticsearch-master ClusterIP 10.97.35.120 <none> 9200/TCP,9300/TCP 46m
elasticsearch-master-headless ClusterIP None <none> 9200/TCP,9300/TCP 46m
kibana-kibana NodePort 10.106.97.8 <none> 5601:30601/TCP 35s
上面我們安裝 Kibana 的時(shí)候指定了 30601 的 NodePort 端口,所以我們可以從任意節(jié)點(diǎn) http://IP:30601 來訪問 Kibana。
我們可以看到會(huì)跳轉(zhuǎn)到登錄頁面,讓我們輸出用戶名、密碼,這里我們輸入上面配置的用戶名 elastic、密碼 ydzsio321 進(jìn)行登錄。登錄成功后進(jìn)入如下所示的 Kibana 主頁:
2部署 Fluentd
Fluentd 是一個(gè)高效的日志聚合器,是用 Ruby 編寫的,并且可以很好地?cái)U(kuò)展。對于大部分企業(yè)來說,F(xiàn)luentd 足夠高效并且消耗的資源相對較少,另外一個(gè)工具Fluent-bit更輕量級(jí),占用資源更少,但是插件相對 Fluentd 來說不夠豐富,所以整體來說,F(xiàn)luentd 更加成熟,使用更加廣泛,所以我們這里也同樣使用 Fluentd 來作為日志收集工具。
工作原理
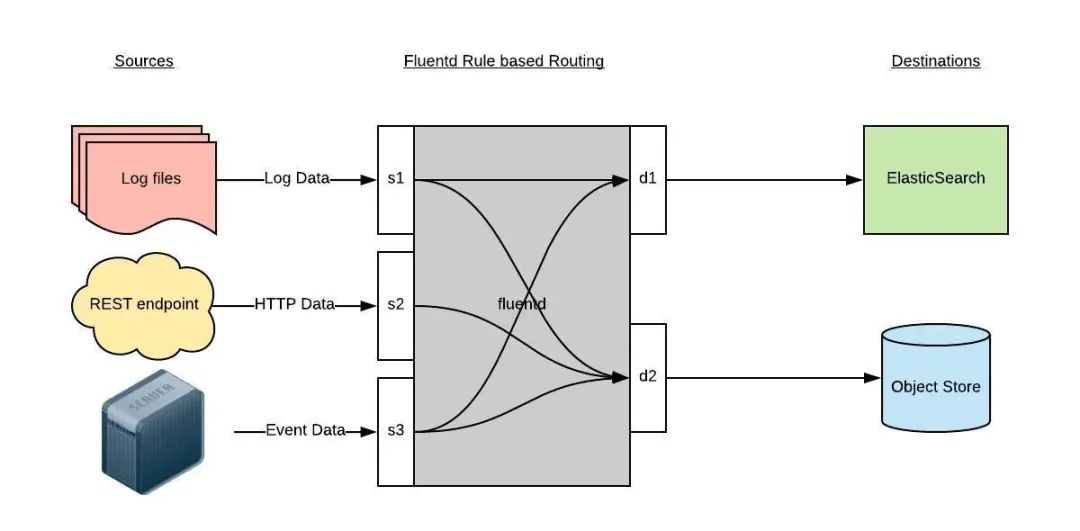
Fluentd 通過一組給定的數(shù)據(jù)源抓取日志數(shù)據(jù),處理后(轉(zhuǎn)換成結(jié)構(gòu)化的數(shù)據(jù)格式)將它們轉(zhuǎn)發(fā)給其他服務(wù),比如 Elasticsearch、對象存儲(chǔ)等等。Fluentd 支持超過 300 個(gè)日志存儲(chǔ)和分析服務(wù),所以在這方面是非常靈活的。主要運(yùn)行步驟如下:
首先 Fluentd 從多個(gè)日志源獲取數(shù)據(jù) 結(jié)構(gòu)化并且標(biāo)記這些數(shù)據(jù) 然后根據(jù)匹配的標(biāo)簽將數(shù)據(jù)發(fā)送到多個(gè)目標(biāo)服務(wù)去
配置
一般來說我們是通過一個(gè)配置文件來告訴 Fluentd 如何采集、處理數(shù)據(jù)的,下面簡單和大家介紹下 Fluentd 的配置方法。
日志源配置
比如我們這里為了收集 Kubernetes 節(jié)點(diǎn)上的所有容器日志,就需要做如下的日志源配置:
<source>
@id fluentd-containers.log
@type tail # Fluentd 內(nèi)置的輸入方式,其原理是不停地從源文件中獲取新的日志。
path /var/log/containers/*.log # 掛載的服務(wù)器Docker容器日志地址
pos_file /var/log/es-containers.log.pos
tag raw.kubernetes.* # 設(shè)置日志標(biāo)簽
read_from_head true
<parse> # 多行格式化成JSON
@type multi_format # 使用 multi-format-parser 解析器插件
<pattern>
format json # JSON 解析器
time_key time # 指定事件時(shí)間的時(shí)間字段
time_format %Y-%m-%dT%H:%M:%S.%NZ # 時(shí)間格式
</pattern>
<pattern>
format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/
time_format %Y-%m-%dT%H:%M:%S.%N%:z
</pattern>
</parse>
</source>
上面配置部分參數(shù)說明如下:
id:表示引用該日志源的唯一標(biāo)識(shí)符,該標(biāo)識(shí)可用于進(jìn)一步過濾和路由結(jié)構(gòu)化日志數(shù)據(jù) type:Fluentd 內(nèi)置的指令, tail表示 Fluentd 從上次讀取的位置通過 tail 不斷獲取數(shù)據(jù),另外一個(gè)是http表示通過一個(gè) GET 請求來收集數(shù)據(jù)。path: tail類型下的特定參數(shù),告訴 Fluentd 采集/var/log/containers目錄下的所有日志,這是 docker 在 Kubernetes 節(jié)點(diǎn)上用來存儲(chǔ)運(yùn)行容器 stdout 輸出日志數(shù)據(jù)的目錄。pos_file:檢查點(diǎn),如果 Fluentd 程序重新啟動(dòng)了,它將使用此文件中的位置來恢復(fù)日志數(shù)據(jù)收集。 tag:用來將日志源與目標(biāo)或者過濾器匹配的自定義字符串,F(xiàn)luentd 匹配源/目標(biāo)標(biāo)簽來路由日志數(shù)據(jù)。
路由配置
上面是日志源的配置,接下來看看如何將日志數(shù)據(jù)發(fā)送到 Elasticsearch:
<match **>
@id elasticsearch
@type elasticsearch
@log_level info
include_tag_key true
type_name fluentd
host "#{ENV['OUTPUT_HOST']}"
port "#{ENV['OUTPUT_PORT']}"
logstash_format true
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size "#{ENV['OUTPUT_BUFFER_CHUNK_LIMIT']}"
queue_limit_length "#{ENV['OUTPUT_BUFFER_QUEUE_LIMIT']}"
overflow_action block
</buffer>
</match>
match:標(biāo)識(shí)一個(gè)目標(biāo)標(biāo)簽,后面是一個(gè)匹配日志源的正則表達(dá)式,我們這里想要捕獲所有的日志并將它們發(fā)送給 Elasticsearch,所以需要配置成 **。id:目標(biāo)的一個(gè)唯一標(biāo)識(shí)符。 type:支持的輸出插件標(biāo)識(shí)符,我們這里要輸出到 Elasticsearch,所以配置成 elasticsearch,這是 Fluentd 的一個(gè)內(nèi)置插件。 log_level:指定要捕獲的日志級(jí)別,我們這里配置成 info,表示任何該級(jí)別或者該級(jí)別以上(INFO、WARNING、ERROR)的日志都將被路由到 Elsasticsearch。host/port:定義 Elasticsearch 的地址,也可以配置認(rèn)證信息,我們的 Elasticsearch 不需要認(rèn)證,所以這里直接指定 host 和 port 即可。 logstash_format:Elasticsearch 服務(wù)對日志數(shù)據(jù)構(gòu)建反向索引進(jìn)行搜索,將 logstash_format 設(shè)置為 true,F(xiàn)luentd 將會(huì)以 logstash 格式來轉(zhuǎn)發(fā)結(jié)構(gòu)化的日志數(shù)據(jù)。Buffer:Fluentd 允許在目標(biāo)不可用時(shí)進(jìn)行緩存,比如,如果網(wǎng)絡(luò)出現(xiàn)故障或者 Elasticsearch 不可用的時(shí)候。緩沖區(qū)配置也有助于降低磁盤的 IO。
過濾
由于 Kubernetes 集群中應(yīng)用太多,也還有很多歷史數(shù)據(jù),所以我們可以只將某些應(yīng)用的日志進(jìn)行收集,比如我們只采集具有 logging=true 這個(gè) Label 標(biāo)簽的 Pod 日志,這個(gè)時(shí)候就需要使用 filter,如下所示:
# 刪除無用的屬性
<filter kubernetes.**>
@type record_transformer
remove_keys $.docker.container_id,$.kubernetes.container_image_id,$.kubernetes.pod_id,$.kubernetes.namespace_id,$.kubernetes.master_url,$.kubernetes.labels.pod-template-hash
</filter>
# 只保留具有l(wèi)ogging=true標(biāo)簽的Pod日志
<filter kubernetes.**>
@id filter_log
@type grep
<regexp>
key $.kubernetes.labels.logging
pattern ^true$
</regexp>
</filter>
安裝
要收集 Kubernetes 集群的日志,直接用 DasemonSet 控制器來部署 Fluentd 應(yīng)用,這樣,它就可以從 Kubernetes 節(jié)點(diǎn)上采集日志,確保在集群中的每個(gè)節(jié)點(diǎn)上始終運(yùn)行一個(gè) Fluentd 容器。當(dāng)然可以直接使用 Helm 來進(jìn)行一鍵安裝,為了能夠了解更多實(shí)現(xiàn)細(xì)節(jié),我們這里還是采用手動(dòng)方法來進(jìn)行安裝。
首先,我們通過 ConfigMap 對象來指定 Fluentd 配置文件,新建 fluentd-configmap.yaml 文件,文件內(nèi)容如下:
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-conf
namespace: logging
data:
# 容器日志
containers.input.conf: |-
<source>
@id fluentd-containers.log
@type tail # Fluentd 內(nèi)置的輸入方式,其原理是不停地從源文件中獲取新的日志
path /var/log/containers/*.log # Docker 容器日志路徑
pos_file /var/log/es-containers.log.pos # 記錄讀取的位置
tag raw.kubernetes.* # 設(shè)置日志標(biāo)簽
read_from_head true # 從頭讀取
<parse> # 多行格式化成JSON
# 可以使用我們介紹過的 multiline 插件實(shí)現(xiàn)多行日志
@type multi_format # 使用 multi-format-parser 解析器插件
<pattern>
format json # JSON解析器
time_key time # 指定事件時(shí)間的時(shí)間字段
time_format %Y-%m-%dT%H:%M:%S.%NZ # 時(shí)間格式
</pattern>
<pattern>
format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/
time_format %Y-%m-%dT%H:%M:%S.%N%:z
</pattern>
</parse>
</source>
# 在日志輸出中檢測異常(多行日志),并將其作為一條日志轉(zhuǎn)發(fā)
# https://github.com/GoogleCloudPlatform/fluent-plugin-detect-exceptions
<match raw.kubernetes.**> # 匹配tag為raw.kubernetes.**日志信息
@id raw.kubernetes
@type detect_exceptions # 使用detect-exceptions插件處理異常棧信息
remove_tag_prefix raw # 移除 raw 前綴
message log
multiline_flush_interval 5
</match>
<filter **> # 拼接日志
@id filter_concat
@type concat # Fluentd Filter 插件,用于連接多個(gè)日志中分隔的多行日志
key message
multiline_end_regexp /\n$/ # 以換行符“\n”拼接
separator ""
</filter>
# 添加 Kubernetes metadata 數(shù)據(jù)
<filter kubernetes.**>
@id filter_kubernetes_metadata
@type kubernetes_metadata
</filter>
# 修復(fù) ES 中的 JSON 字段
# 插件地址:https://github.com/repeatedly/fluent-plugin-multi-format-parser
<filter kubernetes.**>
@id filter_parser
@type parser # multi-format-parser多格式解析器插件
key_name log # 在要解析的日志中指定字段名稱
reserve_data true # 在解析結(jié)果中保留原始鍵值對
remove_key_name_field true # key_name 解析成功后刪除字段
<parse>
@type multi_format
<pattern>
format json
</pattern>
<pattern>
format none
</pattern>
</parse>
</filter>
# 刪除一些多余的屬性
<filter kubernetes.**>
@type record_transformer
remove_keys $.docker.container_id,$.kubernetes.container_image_id,$.kubernetes.pod_id,$.kubernetes.namespace_id,$.kubernetes.master_url,$.kubernetes.labels.pod-template-hash
</filter>
# 只保留具有l(wèi)ogging=true標(biāo)簽的Pod日志
<filter kubernetes.**>
@id filter_log
@type grep
<regexp>
key $.kubernetes.labels.logging
pattern ^true$
</regexp>
</filter>
###### 監(jiān)聽配置,一般用于日志聚合用 ######
forward.input.conf: |-
# 監(jiān)聽通過TCP發(fā)送的消息
<source>
@id forward
@type forward
</source>
output.conf: |-
<match **>
@id elasticsearch
@type elasticsearch
@log_level info
include_tag_key true
host elasticsearch-client
port 9200
user elastic # FLUENT_ELASTICSEARCH_USER | FLUENT_ELASTICSEARCH_PASSWORD
password ydzsio321
logstash_format true
logstash_prefix k8s
request_timeout 30s
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 8
overflow_action block
</buffer>
</match>
上面配置文件中我們只配置了 docker 容器日志目錄,收集到數(shù)據(jù)經(jīng)過處理后發(fā)送到 elasticsearch-client:9200 服務(wù)。
然后新建一個(gè) fluentd-daemonset.yaml 的文件,文件內(nèi)容如下:
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd-es
namespace: logging
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- "namespaces"
- "pods"
verbs:
- "get"
- "watch"
- "list"
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
subjects:
- kind: ServiceAccount
name: fluentd-es
namespace: logging
apiGroup: ""
roleRef:
kind: ClusterRole
name: fluentd-es
apiGroup: ""
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: logging
labels:
app: fluentd
kubernetes.io/cluster-service: "true"
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
kubernetes.io/cluster-service: "true"
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
serviceAccountName: fluentd-es
containers:
- name: fluentd
image: quay.io/fluentd_elasticsearch/fluentd:v3.2.0
volumeMounts:
- name: fluentconfig
mountPath: /etc/fluent/config.d
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: fluentconfig
configMap:
name: fluentd-conf
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
我們將上面創(chuàng)建的 fluentd-config 這個(gè) ConfigMap 對象通過 volumes 掛載到了 Fluentd 容器中,另外為了能夠靈活控制哪些節(jié)點(diǎn)的日志可以被收集,所以我們這里還添加了一個(gè) nodSelector 屬性:
nodeSelector:
beta.kubernetes.io/fluentd-ds-ready: "true"
意思就是要想采集節(jié)點(diǎn)的日志,那么我們就需要給節(jié)點(diǎn)打上上面的標(biāo)簽。
!!! info "提示"
如果你需要在其他節(jié)點(diǎn)上采集日志,則需要給對應(yīng)節(jié)點(diǎn)打上標(biāo)簽,使用如下命令:kubectl label nodes node名 beta.kubernetes.io/fluentd-ds-ready=true。
另外由于我們的集群使用的是 kubeadm 搭建的,默認(rèn)情況下 master 節(jié)點(diǎn)有污點(diǎn),所以如果要想也收集 master 節(jié)點(diǎn)的日志,則需要添加上容忍:
tolerations:
- operator: Exists
另外需要注意的地方是,如果更改了 docker 的根目錄,則在 volumes 和 volumeMount 里面都需要更改,保持一致。
分別創(chuàng)建上面的 ConfigMap 對象和 DaemonSet:
$ kubectl create -f fluentd-configmap.yaml
configmap "fluentd-conf" created
$ kubectl create -f fluentd-daemonset.yaml
serviceaccount "fluentd-es" created
clusterrole.rbac.authorization.k8s.io "fluentd-es" created
clusterrolebinding.rbac.authorization.k8s.io "fluentd-es" created
daemonset.apps "fluentd" created
創(chuàng)建完成后,查看對應(yīng)的 Pods 列表,檢查是否部署成功:
$ kubectl get pods -n logging
NAME READY STATUS RESTARTS AGE
elasticsearch-client-0 1/1 Running 0 64m
elasticsearch-data-0 1/1 Running 0 65m
elasticsearch-master-0 1/1 Running 0 73m
fluentd-5rqbq 1/1 Running 0 60m
fluentd-l6mgf 1/1 Running 0 60m
fluentd-xmfpg 1/1 Running 0 60m
kibana-kibana-66f97964b-mdspc 1/1 Running 0 63m
Fluentd 啟動(dòng)成功后,這個(gè)時(shí)候就可以發(fā)送日志到 ES 了,但是我們這里是過濾了只采集具有 logging=true 標(biāo)簽的 Pod 日志,所以現(xiàn)在還沒有任何數(shù)據(jù)會(huì)被采集。
下面我們部署一個(gè)簡單的測試應(yīng)用, 新建 counter.yaml 文件,文件內(nèi)容如下:
apiVersion: v1
kind: Pod
metadata:
name: counter
labels:
logging: "true" # 一定要具有該標(biāo)簽才會(huì)被采集
spec:
containers:
- name: count
image: busybox
args:
[
/bin/sh,
-c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done',
]
該 Pod 只是簡單將日志信息打印到 stdout,所以正常來說 Fluentd 會(huì)收集到這個(gè)日志數(shù)據(jù),在 Kibana 中也就可以找到對應(yīng)的日志數(shù)據(jù)了,使用 kubectl 工具創(chuàng)建該 Pod:
$ kubectl create -f counter.yaml
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
counter 1/1 Running 0 9h
Pod 創(chuàng)建并運(yùn)行后,回到 Kibana Dashboard 頁面,點(diǎn)擊左側(cè)最下面的 Management -> Stack Management,進(jìn)入管理頁面,點(diǎn)擊左側(cè) Kibana 下面的 索引模式,點(diǎn)擊 創(chuàng)建索引模式 開始導(dǎo)入索引數(shù)據(jù):
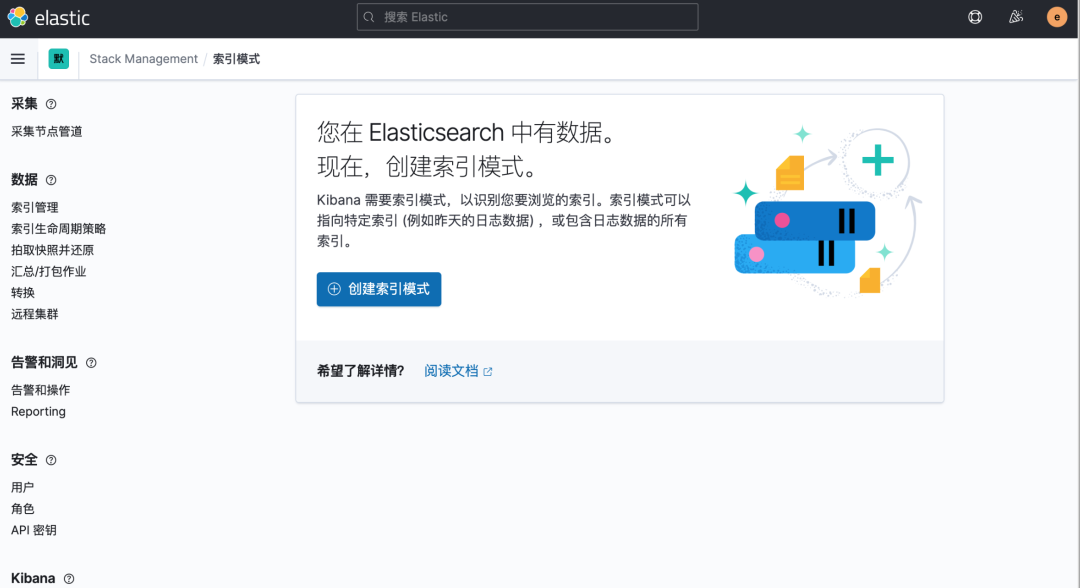
在這里可以配置我們需要的 Elasticsearch 索引,前面 Fluentd 配置文件中我們采集的日志使用的是 logstash 格式,定義了一個(gè) k8s 的前綴,所以這里只需要在文本框中輸入 k8s-* 即可匹配到 Elasticsearch 集群中采集的 Kubernetes 集群日志數(shù)據(jù),然后點(diǎn)擊下一步,進(jìn)入以下頁面:
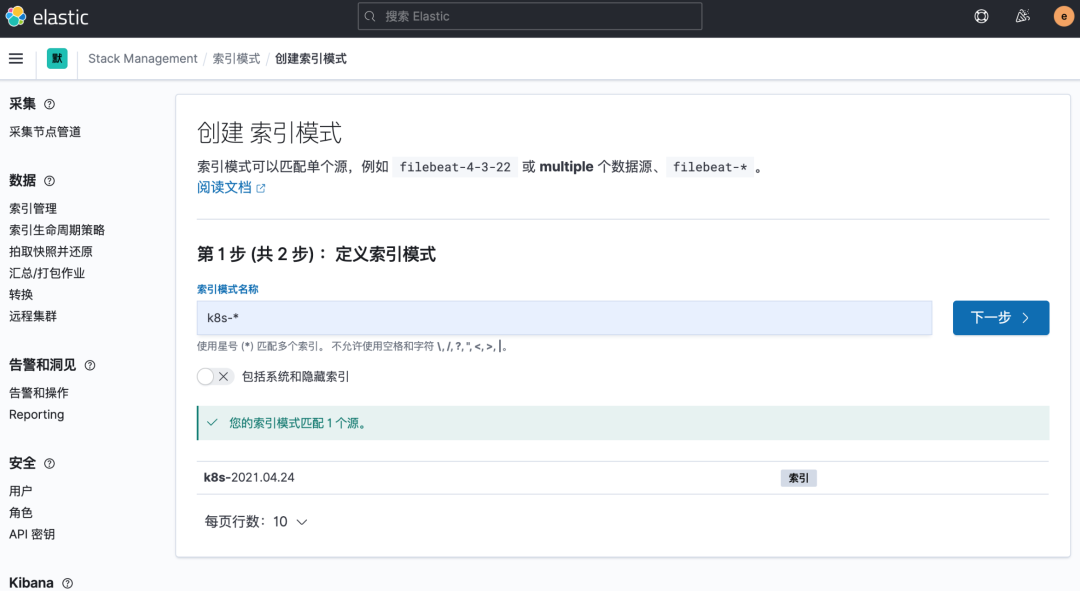
在該頁面中配置使用哪個(gè)字段按時(shí)間過濾日志數(shù)據(jù),在下拉列表中,選擇@timestamp字段,然后點(diǎn)擊 創(chuàng)建索引模式,創(chuàng)建完成后,點(diǎn)擊左側(cè)導(dǎo)航菜單中的 Discover,然后就可以看到一些直方圖和最近采集到的日志數(shù)據(jù)了:
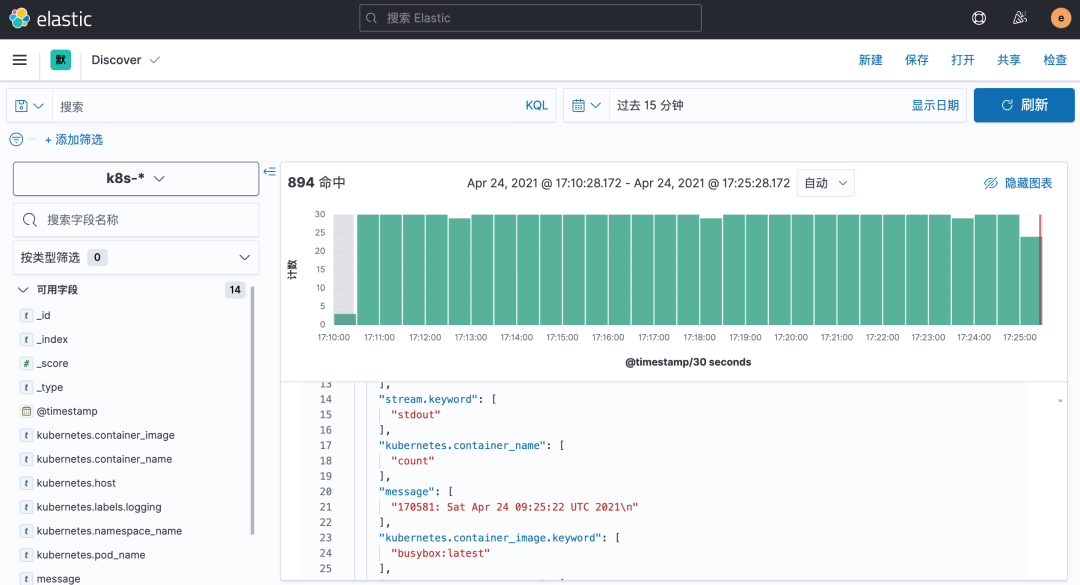
現(xiàn)在的數(shù)據(jù)就是上面 Counter 應(yīng)用的日志,如果還有其他的應(yīng)用,我們也可以篩選過濾:
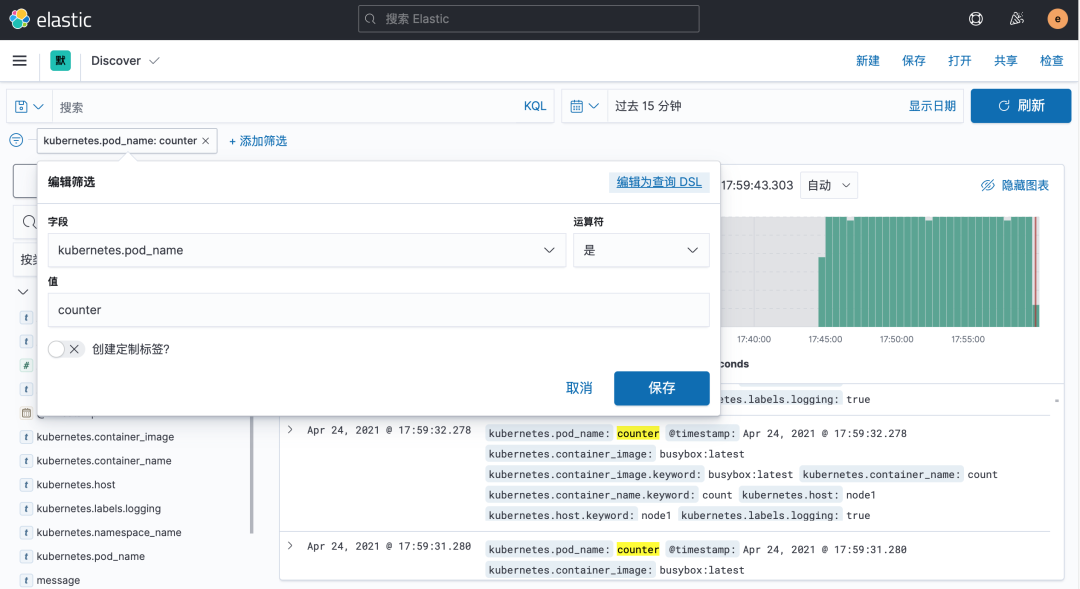
我們也可以通過其他元數(shù)據(jù)來過濾日志數(shù)據(jù),比如您可以單擊任何日志條目以查看其他元數(shù)據(jù),如容器名稱,Kubernetes 節(jié)點(diǎn),命名空間等。
3安裝 Kafka
對于大規(guī)模集群來說,日志數(shù)據(jù)量是非常巨大的,如果直接通過 Fluentd 將日志打入 Elasticsearch,對 ES 來說壓力是非常巨大的,我們可以在中間加一層消息中間件來緩解 ES 的壓力,一般情況下我們會(huì)使用 Kafka,然后可以直接使用 kafka-connect-elasticsearch 這樣的工具將數(shù)據(jù)直接打入 ES,也可以在加一層 Logstash 去消費(fèi) Kafka 的數(shù)據(jù),然后通過 Logstash 把數(shù)據(jù)存入 ES,這里我們來使用 Logstash 這種模式來對日志收集進(jìn)行優(yōu)化。
首先在 Kubernetes 集群中安裝 Kafka,同樣這里使用 Helm 進(jìn)行安裝:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm repo update
首先使用 helm pull 拉取 Chart 并解壓:
helm pull bitnami/kafka --untar --version 12.17.5
cd kafka
這里面我們指定使用一個(gè) StorageClass 來提供持久化存儲(chǔ),在 Chart 目錄下面創(chuàng)建用于安裝的 values 文件:
# values-prod.yaml
## Persistence parameters
##
persistence:
enabled: true
storageClass: "nfs-storage"
accessModes:
- ReadWriteOnce
size: 5Gi
## Mount point for persistence
mountPath: /bitnami/kafka
# 配置zk volumes
zookeeper:
enabled: true
persistence:
enabled: true
storageClass: "nfs-storage"
accessModes:
- ReadWriteOnce
size: 8Gi
直接使用上面的 values 文件安裝 kafka:
$ helm install kafka -f values-prod.yaml --namespace logging .
Release "kafka" does not exist. Installing it now.
NAME: kafka
LAST DEPLOYED: Tue Apr 27 18:46:01 2021
NAMESPACE: logging
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
** Please be patient while the chart is being deployed **
Kafka can be accessed by consumers via port 9092 on the following DNS name from within your cluster:
kafka.logging.svc.cluster.local
Each Kafka broker can be accessed by producers via port 9092 on the following DNS name(s) from within your cluster:
kafka-0.kafka-headless.logging.svc.cluster.local:9092
To create a pod that you can use as a Kafka client run the following commands:
kubectl run kafka-client --restart='Never' --image docker.io/bitnami/kafka:2.8.0-debian-10-r0 --namespace logging --command -- sleep infinity
kubectl exec --tty -i kafka-client --namespace logging -- bash
PRODUCER:
kafka-console-producer.sh \
--broker-list kafka-0.kafka-headless.logging.svc.cluster.local:9092 \
--topic test
CONSUMER:
kafka-console-consumer.sh \
--bootstrap-server kafka.logging.svc.cluster.local:9092 \
--topic test \
--from-beginning
安裝完成后我們可以使用上面的提示來檢查 Kafka 是否正常運(yùn)行:
$ kubectl get pods -n logging -l app.kubernetes.io/instance=kafka
kafka-0 1/1 Running 0 7m58s
kafka-zookeeper-0 1/1 Running 0 7m58s
用下面的命令創(chuàng)建一個(gè) Kafka 的測試客戶端 Pod:
$ kubectl run kafka-client --restart='Never' --image docker.io/bitnami/kafka:2.8.0-debian-10-r0 --namespace logging --command -- sleep infinity
pod/kafka-client created
然后啟動(dòng)一個(gè)終端進(jìn)入容器內(nèi)部生產(chǎn)消息:
# 生產(chǎn)者
$ kubectl exec --tty -i kafka-client --namespace logging -- bash
I have no name!@kafka-client:/$ kafka-console-producer.sh --broker-list kafka-0.kafka-headless.logging.svc.cluster.local:9092 --topic test
>hello kafka on k8s
>
啟動(dòng)另外一個(gè)終端進(jìn)入容器內(nèi)部消費(fèi)消息:
# 消費(fèi)者
$ kubectl exec --tty -i kafka-client --namespace logging -- bash
I have no name!@kafka-client:/$ kafka-console-consumer.sh --bootstrap-server kafka.logging.svc.cluster.local:9092 --topic test --from-beginning
hello kafka on k8s
如果在消費(fèi)端看到了生產(chǎn)的消息數(shù)據(jù)證明我們的 Kafka 已經(jīng)運(yùn)行成功了。
4Fluentd 配置 Kafka
現(xiàn)在有了 Kafka,我們就可以將 Fluentd 的日志數(shù)據(jù)輸出到 Kafka 了,只需要將 Fluentd 配置中的 <match> 更改為使用 Kafka 插件即可,但是在 Fluentd 中輸出到 Kafka,需要使用到 fluent-plugin-kafka 插件,所以需要我們自定義下 Docker 鏡像,最簡單的做法就是在上面 Fluentd 鏡像的基礎(chǔ)上新增 kafka 插件即可,Dockerfile 文件如下所示:
FROM quay.io/fluentd_elasticsearch/fluentd:v3.2.0
RUN echo "source 'https://mirrors.tuna.tsinghua.edu.cn/rubygems/'" > Gemfile && gem install bundler
RUN gem install fluent-plugin-kafka -v 0.16.1 --no-document
使用上面的 Dockerfile 文件構(gòu)建一個(gè) Docker 鏡像即可,我這里構(gòu)建過后的鏡像名為 cnych/fluentd-kafka:v0.16.1。接下來替換 Fluentd 的 Configmap 對象中的 <match> 部分,如下所示:
# fluentd-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-conf
namespace: logging
data:
......
output.conf: |-
<match **>
@id kafka
@type kafka2
@log_level info
# list of seed brokers
brokers kafka-0.kafka-headless.logging.svc.cluster.local:9092
use_event_time true
# topic settings
topic_key k8slog
default_topic messages # 注意,kafka中消費(fèi)使用的是這個(gè)topic
# buffer settings
<buffer k8slog>
@type file
path /var/log/td-agent/buffer/td
flush_interval 3s
</buffer>
# data type settings
<format>
@type json
</format>
# producer settings
required_acks -1
compression_codec gzip
</match>
然后替換運(yùn)行的 Fluentd 鏡像:
# fluentd-daemonset.yaml
image: cnych/fluentd-kafka:v0.16.1
直接更新 Fluentd 的 Configmap 與 DaemonSet 資源對象即可:
kubectl apply -f fluentd-configmap.yaml
kubectl apply -f fluentd-daemonset.yaml
更新成功后我們可以使用上面的測試 Kafka 客戶端來驗(yàn)證是否有日志數(shù)據(jù):
$ kubectl exec --tty -i kafka-client --namespace logging -- bash
I have no name!@kafka-client:/$ kafka-console-consumer.sh --bootstrap-server kafka.logging.svc.cluster.local:9092 --topic messages --from-beginning
{"stream":"stdout","docker":{},"kubernetes":{"container_name":"count","namespace_name":"default","pod_name":"counter","container_image":"busybox:latest","host":"node1","labels":{"logging":"true"}},"message":"43883: Tue Apr 27 12:16:30 UTC 2021\n"}
......
5安裝 Logstash
雖然數(shù)據(jù)從 Kafka 到 Elasticsearch 的方式多種多樣,我們這里還是采用更加流行的 Logstash 方案,上面我們已經(jīng)將日志從 Fluentd 采集輸出到 Kafka 中去了,接下來我們使用 Logstash 來連接 Kafka 與 Elasticsearch 間的日志數(shù)據(jù)。
首先使用 helm pull 拉取 Chart 并解壓:
helm pull elastic/logstash --untar --version 7.12.0
cd logstash
同樣在 Chart 根目錄下面創(chuàng)建用于安裝的 Values 文件,如下所示:
# values-prod.yaml
fullnameOverride: logstash
persistence:
enabled: true
logstashConfig:
logstash.yml: |
http.host: 0.0.0.0
# 如果啟用了xpack,需要做如下配置
xpack.monitoring.enabled: true
xpack.monitoring.elasticsearch.hosts: ["http://elasticsearch-client:9200"]
xpack.monitoring.elasticsearch.username: "elastic"
xpack.monitoring.elasticsearch.password: "ydzsio321"
# 要注意下格式
logstashPipeline:
logstash.conf: |
input { kafka { bootstrap_servers => "kafka-0.kafka-headless.logging.svc.cluster.local:9092" codec => json consumer_threads => 3 topics => ["messages"] } }
filter {} # 過濾配置(比如可以刪除key、添加geoip等等)
output { elasticsearch { hosts => [ "elasticsearch-client:9200" ] user => "elastic" password => "ydzsio321" index => "logstash-k8s-%{+YYYY.MM.dd}" } stdout { codec => rubydebug } }
volumeClaimTemplate:
accessModes: ["ReadWriteOnce"]
storageClassName: nfs-storage
resources:
requests:
storage: 1Gi
其中最重要的就是通過 logstashPipeline 配置 logstash 數(shù)據(jù)流的處理配置,通過 input 指定日志源 kafka 的配置,通過 output 輸出到 Elasticsearch,同樣直接使用上面的 Values 文件安裝 logstash 即可:
$ helm upgrade --install logstash -f values-prod.yaml --namespace logging .
Release "logstash" does not exist. Installing it now.
NAME: logstash
LAST DEPLOYED: Tue Apr 27 20:22:45 2021
NAMESPACE: logging
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
1. Watch all cluster members come up.
$ kubectl get pods --namespace=logging -l app=logstash -w
安裝啟動(dòng)完成后可以查看 logstash 的日志:
$ logstash kubectl get pods --namespace=logging -l app=logstash
NAME READY STATUS RESTARTS AGE
logstash-0 1/1 Running 0 2m8s
$ kubectl logs -f logstash-0 -n logging
......
{
"docker" => {},
"stream" => "stdout",
"message" => "46921: Tue Apr 27 13:07:15 UTC 2021\n",
"kubernetes" => {
"host" => "node1",
"labels" => {
"logging" => "true"
},
"pod_name" => "counter",
"container_image" => "busybox:latest",
"container_name" => "count",
"namespace_name" => "default"
},
"@timestamp" => 2021-04-27T13:07:15.761Z,
"@version" => "1"
}
由于我們啟用了 debug 日志調(diào)試,所以我們可以在 logstash 的日志中看到我們采集的日志消息,到這里證明我們的日志數(shù)據(jù)就獲取成功了。
現(xiàn)在我們可以登錄到 Kibana 可以看到有如下所示的索引數(shù)據(jù)了:
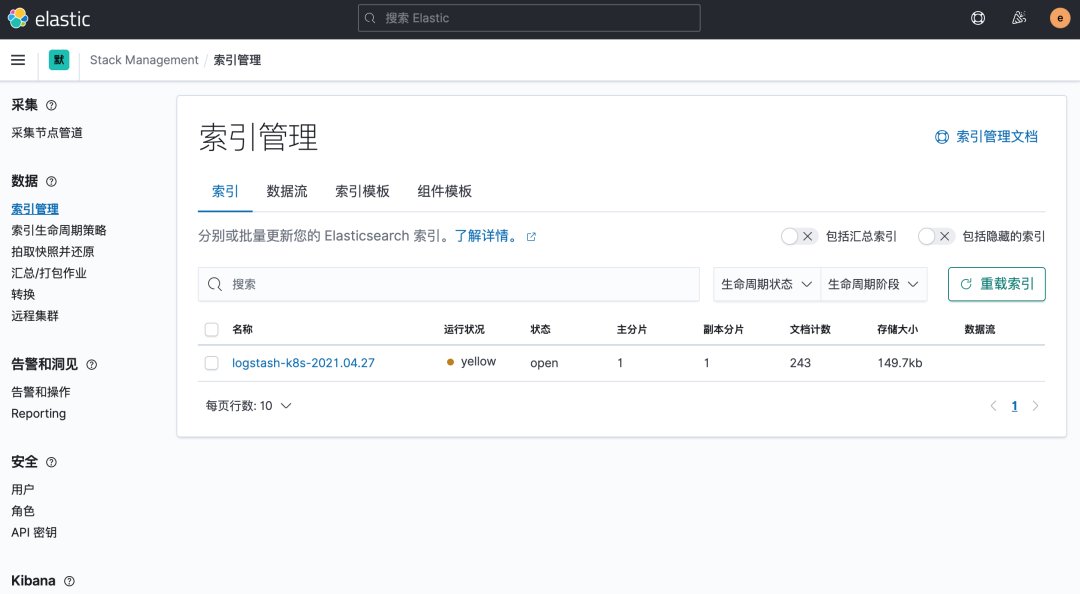
然后同樣創(chuàng)建索引模式,匹配上面的索引即可:
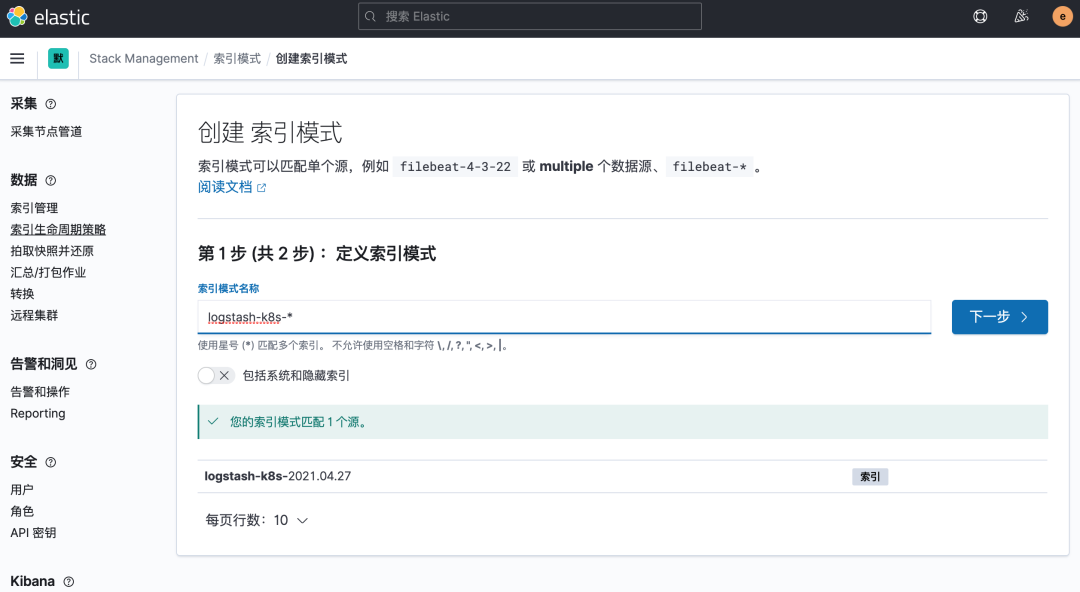
創(chuàng)建完成后就可以前往發(fā)現(xiàn)頁面過濾日志數(shù)據(jù)了:
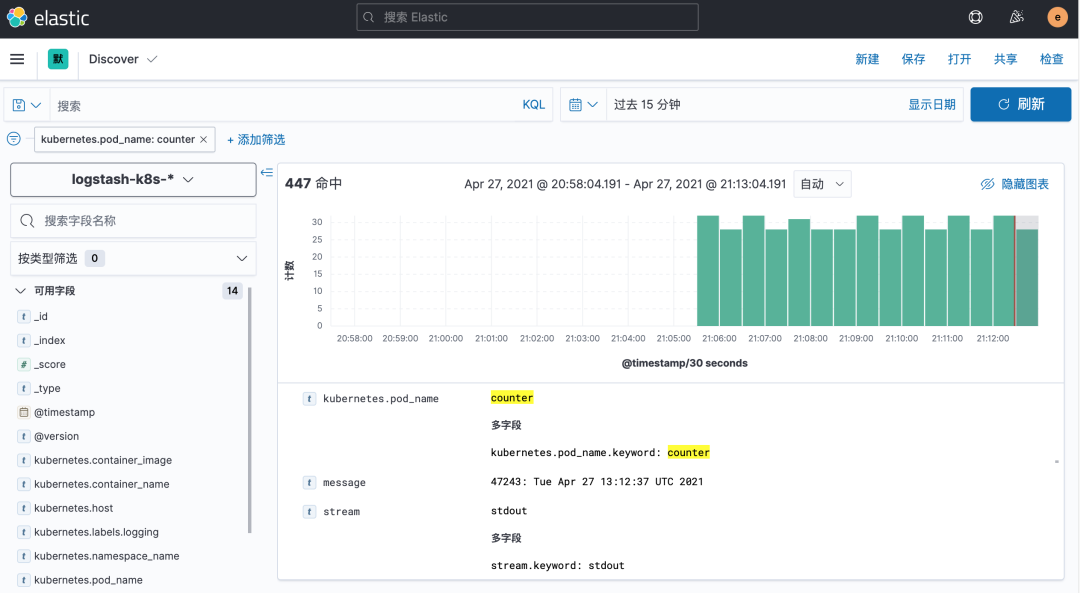
到這里我們就實(shí)現(xiàn)了一個(gè)使用 Fluentd+Kafka+Logstash+Elasticsearch+Kibana 的 Kubernetes 日志收集工具棧,這里我們完整的 Pod 信息如下所示:
$ kubectl get pods -n logging
NAME READY STATUS RESTARTS AGE
elasticsearch-client-0 1/1 Running 0 128m
elasticsearch-data-0 1/1 Running 0 128m
elasticsearch-master-0 1/1 Running 0 128m
fluentd-6k52h 1/1 Running 0 61m
fluentd-cw72c 1/1 Running 0 61m
fluentd-dn4hs 1/1 Running 0 61m
kafka-0 1/1 Running 3 134m
kafka-client 1/1 Running 0 125m
kafka-zookeeper-0 1/1 Running 0 134m
kibana-kibana-66f97964b-qqjgg 1/1 Running 0 128m
logstash-0 1/1 Running 0 13m
當(dāng)然在實(shí)際的工作項(xiàng)目中還需要我們根據(jù)實(shí)際的業(yè)務(wù)場景來進(jìn)行參數(shù)性能調(diào)優(yōu)以及高可用等設(shè)置,以達(dá)到系統(tǒng)的最優(yōu)性能。
本文為 《Kubernetes 進(jìn)階訓(xùn)練營》課程文檔,需要完整 YAML 文件的可以添加我微信
iEverything獲取。另外我們的平臺(tái)所有課程正在進(jìn)行51優(yōu)惠活動(dòng),可以點(diǎn)擊下面圖片了解詳情。
