
保姆級別的 PromQL 教程
注")
這篇文章介紹如何使用 PromQL 查詢 Prometheus 里面的數(shù)據(jù)。包括如何使用函數(shù),理解這些函數(shù),Metrics 的邏輯等等,因為看了很多教程試圖學習 PromQL,發(fā)現(xiàn)這些教程都直說有哪些函數(shù)、語法是什么,看完之后還是很難理解。比如 [1m] 是什么意思?為什么有的函數(shù)需要有的函數(shù)不需要?它對 Grafana 上面展示的數(shù)據(jù)有什么影響?rate 和 irate 的區(qū)別是什么?sum 和 rate 要先用哪個后用哪個?經(jīng)過照葫蘆畫瓢地寫了很多 PromQL 來設(shè)置監(jiān)控和告警規(guī)則,我漸漸對 PromQL 的邏輯有了一些理解。這篇文章從頭開始,通過介紹 PromQL 里面的邏輯,來理解這些函數(shù)的作用。本文不會一一回答上面這些問題,但是我的這些問題都是由于之前對 PromQL 里面的邏輯和概念不了解,相信讀完本文之后,這些問題的答案就顯得不言而喻了。
本文不會深入講解 Prometheus 的數(shù)據(jù)存儲原理,Prometheus 對 metrics 的抓取原理等問題;也不會深入介紹 PromQL 中每一個 API 的實現(xiàn)。只會著重于介紹如何寫 PromQL 的原理,和它的設(shè)計邏輯。但是相信如果理解了本文這些概念,可以更透徹地理解和閱讀 Prometheus 官方的文檔。
Metric 類型
Prometheus 里面其實只有兩種數(shù)據(jù)類型。Gauge 和 Counter。
Gauge
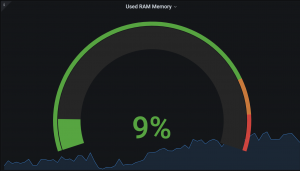
Gauge 是比較符合直覺的。它就是表示一個當前的“狀態(tài)”,比如內(nèi)存當前是多少,CPU 當前的使用率是多少。
Counter
Counter 有一些不符合直覺。我想了很久才理解(可能我有點鉆牛角尖了)。Counter 是一個永遠只遞增的 Metric 類型。
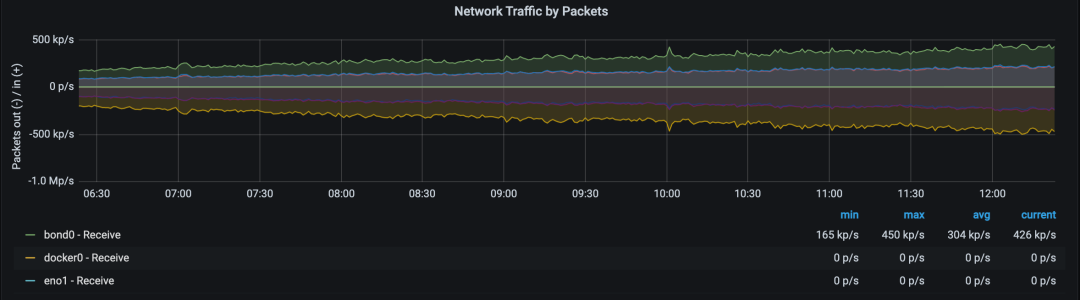
典型的 Counter 舉例:服務器服務的請求數(shù),服務器收到了多少包(上圖)。這個數(shù)字是只增不減的,用 Counter 最合適了。因為每一個時間點的總請求數(shù)都會包含之前時間點的請求數(shù),所以可以理解成它是一個“有狀態(tài)的”(非官方說法,我這么說只是為了方便讀者理解)。使用 Counter 記錄每一個時間點的“總數(shù)”,然后除以時間,就可以得到 QPS,packets/s 等數(shù)據(jù)。
為什么需要 Counter 呢?先來回顧一下 Gauge,你可以將 Gauge 理解為“無狀態(tài)的”,即類型是 Gauge 的 metric 不需要關(guān)心歷史的值,只需要記錄當前的值是多少就可以了。比如當前的內(nèi)存值,當前的 CPU 使用率。當然,如果你想要查詢歷史的值,依然是可以查到的。只不過對于每一個時間點的“內(nèi)存使用量”這個 Gauge,不包含歷史的數(shù)據(jù)。那么可否用 Gauge 來代替 Counter 呢?
Prometheus 是一個抓取的模型:服務器暴露一個 HTTP 服務,Prometheus 來訪問這個 HTTP 接口來獲取 metrics 的數(shù)據(jù)。如果使用 Gauge 來表示上面的 pk/s 數(shù)據(jù)的話,只能使用這種方案:使用這個 Metric 記錄自從上次抓取過后收到的 Packet 總數(shù)(或者直接記錄 Packet/s ,原理是一樣的)。每次 Prometheus 來抓取數(shù)據(jù)之后,就將這個值重置為 0. 這樣的實現(xiàn)就類似 Gauge 了。
這種實現(xiàn)的缺點有:
抓取數(shù)據(jù)本質(zhì)是 GET 操作,但是這個 GET 操作卻會修改數(shù)據(jù)(將 metric 重置為 0),所以會帶來很多隱患,比如一個服務每次只能由一個 Prometheus 來抓取,不能擴展;不能 cURL 這個 /metrics來進行 debug,因為會影響真實的數(shù)據(jù),等等。如果服務器發(fā)生了重啟,數(shù)據(jù)將會清零,會丟失數(shù)據(jù)(雖然 Counter 也沒有從本質(zhì)上解決這個問題)。
Counter 因為是一個只遞增的值,所以它可以判斷數(shù)字下降的問題,比如現(xiàn)在請求的 Count 數(shù)是 1000,然后下次 Prometheus 來抓取發(fā)現(xiàn)變成了 20,那么 Prometheus 就知道,真實的數(shù)據(jù)不可能是 20,因為請求數(shù)是不可能下降的。所以它會將這個點認為是 1020。
然后用 Counter 也可以解決多次讀的問題,服務器上的 /metrics,可以使用 cURL 和 grep 等工具實時查看,不會改變數(shù)據(jù)。Counter 有關(guān)的細節(jié)可以參考下 How does a Prometheus Counter work?[1]
其實 Prometheus 里面還有兩種數(shù)據(jù)類型,一種是 Histogram,另一種是 Summary.
但是這兩種類型本質(zhì)上都是 Counter。比如,如果你要統(tǒng)計一個服務處理請求的平均耗時,就可以用 Summary。在代碼中只用一種 Summary 類型[2],就可以暴露出收到的總請求數(shù),處理這些請求花費的總時間數(shù),兩個 Counter 類型的 metric。算是一個“語法糖”。
Histogram 是由多個 Counter 組成的一組(bucket)metrics,比如你要統(tǒng)計 P99 的信息,使用 Histogram 可以暴露出 10 個 bucket 分別存放不同耗時區(qū)間的請求數(shù),使用 histogram_quantile 函數(shù)就可以方便地計算出 P99(《P99 是如何計算的?[3]》). 本質(zhì)上也是一個“糖”。假如 Prometheus 沒有 Histogram 和 Summary 這兩種 Metric 類型,也是完全可以的,只不過我們在使用上就需要多做很多事情,麻煩一些。
講了這么說,希望讀者已經(jīng)明白 Counter 和 Gauge 了。因為我們接下來的查詢會一直跟這兩種 Metric 類型打交道。
Selectors
下面這張圖簡單地表示了 Metric 在 Prometheus 中的樣子,以給讀者一個概念。
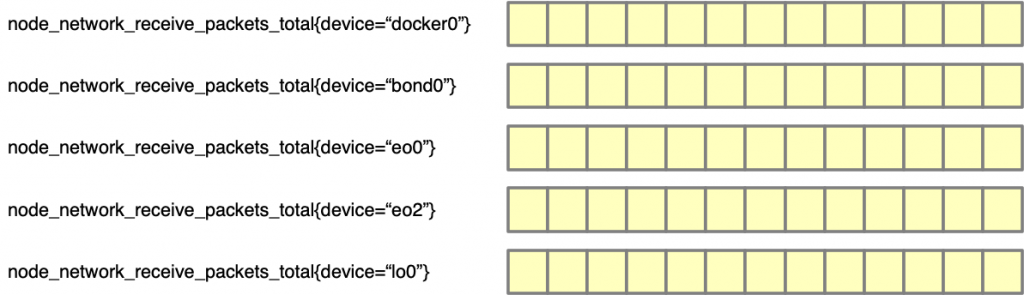
如果我們直接在 Grafana 中使用 node_network_receive_packets_total 來畫圖的話,就會得到 5 條線。

Metric 可以通過 label 來進行選擇,比如 node_network_receive_packets_total{device=”bond0″} 就會只查詢到 bond0 的數(shù)據(jù),繪制 bond0 這個 device 的曲線。也支持正則表達式,可以通過 node_network_receive_packets_total{device=~”en.*”} 繪制 en0 和 en2 的曲線。
其實,metric name 也是一個 “l(fā)abel”, 所以 node_network_receive_packets_total{device="bond0"} 本質(zhì)上是 {__name__="node_network_receive_packets_total", device="bond0"} 。但是因為 metric name 基本上是必用的 label,所以我們一般用第一種寫法, 這樣看起來更易懂。
PromQL 支持很復雜的 Selector,詳細的用法可以參考文檔[4]。指的一提的是,Prometheus 是圖靈完備 (Turing Complete)[5]的(Surprise!)。
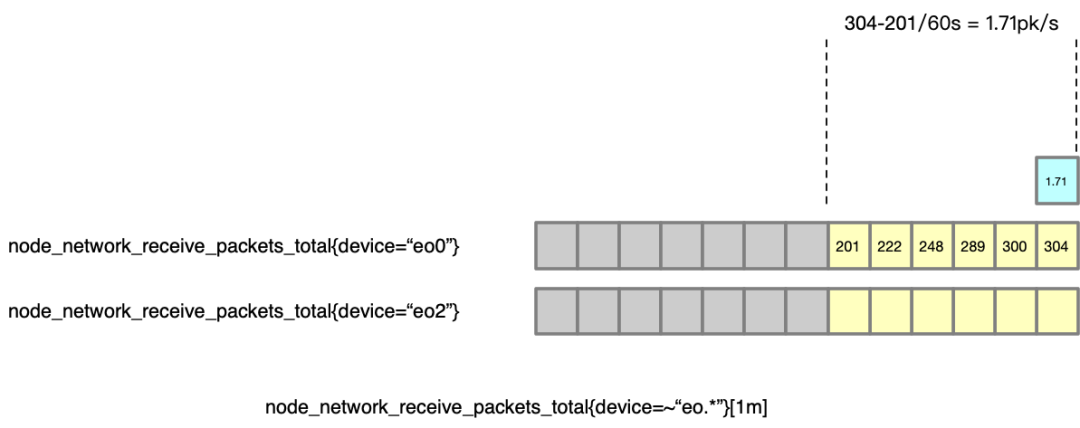
實際上,如果你使用下面的查詢語句,將會僅僅得到一個數(shù)字,而不是整個 metric 的歷史數(shù)據(jù)(node_network_receive_packets_total{device=~"en.*"} 得到的是下圖中黃色的部分。

這個就是 Instant Vector:只查詢到 metric 的在某個時間點(默認是當前時間)的值。
PromQL 語言的數(shù)據(jù)類型
為了避免讀者混淆,這里說明一下 Metric Type 和 PromQL 查詢語言中的數(shù)據(jù)類型的區(qū)別。很簡單,在寫 PromQL 的時候,無論是 Counter 還是 Gauge,對于函數(shù)來說都是一串數(shù)字,他們數(shù)據(jù)結(jié)構(gòu)上沒有區(qū)別。我們說的 Instant Vector 還是 Range Vector, 指的是 PromQL 函數(shù)的入?yún)⒑头祷刂档念愋汀?/p>
Instant Vector
Instant 是立即的意思,Instant Vector 顧名思義,就是當前的值。假如查詢的時間點是 t,那么查詢會返回距離 t 時間點最近的一個值。
常用的另一種數(shù)據(jù)類型是 Range Vector。
Range Vector
Range Vector 顧名思義,返回的是一個 range 的數(shù)據(jù)。
Range 的表示方法是 [1m],表示 1 分鐘的數(shù)據(jù)。也可以使用 [1h] 表示 1 小時,[1d] 表示 1 天。支持的所有的 duration 表示方法可以參考文檔[6]。
假如我們對 Prometheus 的采集配置是每 10s 采集一次,那么 1 分鐘內(nèi)就會有采集 6 次,就會有 6 個數(shù)據(jù)點。我們使用 node_network_receive_packets_total{device=~“.*”}[1m] 查詢的話,就可以得到以下的數(shù)據(jù):兩個 metric,最后的 6 個數(shù)據(jù)點。

Prometheus 大部分的函數(shù)要么接受的是 Instant Vector,要么接受的是 Range Vector。所以要看懂這些函數(shù)的文檔,就要理解這兩種類型。
在詳細解釋之前,請讀者思考一個問題:在 Grafana 中畫出來一個 Metric 的圖標,需要查詢結(jié)果是一個 Instant Vector,還是 Range Vector 呢?
答案是 Instant Vector (Surprise!)。
為什么呢?要畫出一段時間的 Chart,不應該需要一個 Range 的數(shù)據(jù)嗎?為什么是 Instant Vector?
答案是:Range Vector 基本上只是為了給函數(shù)用的,Grafana 繪圖只能接受 Instant Vector。Prometheus 的查詢 API 是以 HTTP 的形式提供的,Grafana 在渲染一個圖標的時候會向 Prometheus 去查詢數(shù)據(jù)。而這個查詢 API 主要有兩種:
第一種是 /query:查詢一個時間點的數(shù)據(jù),返回一個數(shù)據(jù)值,通過 ?time=1627111334 可以查詢指定時間的數(shù)據(jù)。
假如要繪制 1 個小時內(nèi)的 Chart 的話,Grafana 首先需要你在創(chuàng)建 Chart 的時候傳入一個 step 值,表示多久查一個數(shù)據(jù),這里假設(shè) step=1min 的話,我們對每分鐘需要查詢一次數(shù)據(jù)。那么 Grafana 會向 Prometheus 發(fā)送 60 次請求,查詢 60 個數(shù)據(jù)點,即 60 個 Instant Vector,然后繪制出來一張圖表。

當然,60 次請求太多了。所以就有了第二種 API query_range,接收的參數(shù)有 ?start=。但是這個 API 本質(zhì)上,是一個語法糖,在 Prometheus 內(nèi)部還是對 60 個點進行了分別計算,然后返回。當然了,會有一些優(yōu)化。
然后就有了下一個問題:為什么 Grafana 偏偏要繪制 Instant Vector,而不是 Range Vector 呢?
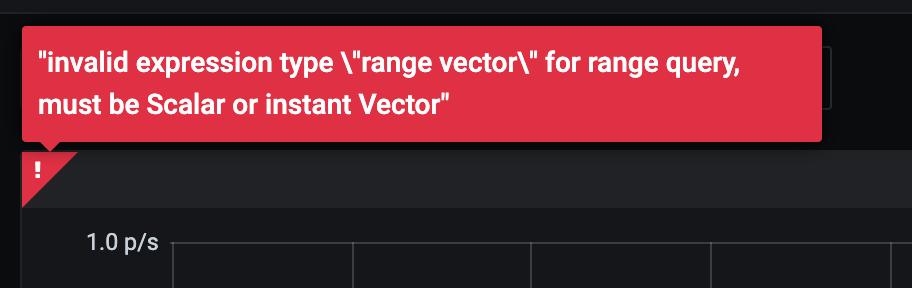
因為這里的 Range Vector 并不是一個“繪制的時間”,而是函數(shù)計算所需要的時間區(qū)間。看下面的例子就容易理解了。
來解釋一下這個查詢:
rate(node_network_receive_packets_total{device=~”en.*”}[1m])

node_network_receive_packets_total 是一個 Counter,為了計算每秒的 packet 數(shù)量,我們要計算每秒的數(shù)量,就要用到 rate 函數(shù)。
先來看一個時間點的計算,假如我們計算 t 時間點的每秒 packet 數(shù)量,rate 函數(shù)可以幫我們用這段時間([1m])的總 packet 數(shù)量,除以時間 [1m] ,就得到了一個“平均值”,以此作為曲線來繪制。
以這種方法就得到了一個點的數(shù)據(jù)。
然后我們對之前的每一個點,都以此法進行計算,就得到了一個 pk/s 的曲線(最長的那條是原始的數(shù)據(jù),黃色的表示 rate 對于每一個點的計算過程,藍色的框為最終的繪制的點)。
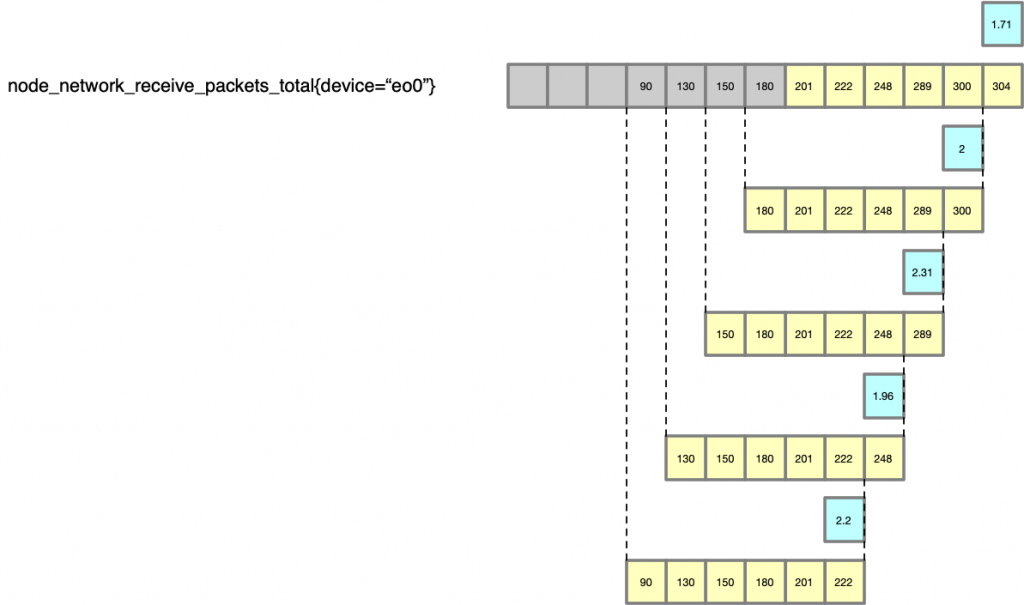
所以這個 PromQL 查詢最終得到的數(shù)據(jù)點是:… 2.2, 1.96, 2.31, 2, 1.71 (即藍色的點)。
這里有兩個選中的 metric,分別是 en0 和 en2,所以 rate 會分別計算兩條曲線,就得到了上面的 Chart,有兩條線。
rate, irate 和 increase
很多人都會糾結(jié) irate 和 rate 有什么區(qū)別。看到這里,其實就很好解釋了。
以下來自官方的文檔:
irate() irate(v range-vector) calculates the per-second instant rate of increase of the time series in the range vector. This is based on the last two data points.
即,irate 是計算的最后兩個點之間的差值。可以用下圖來表示:
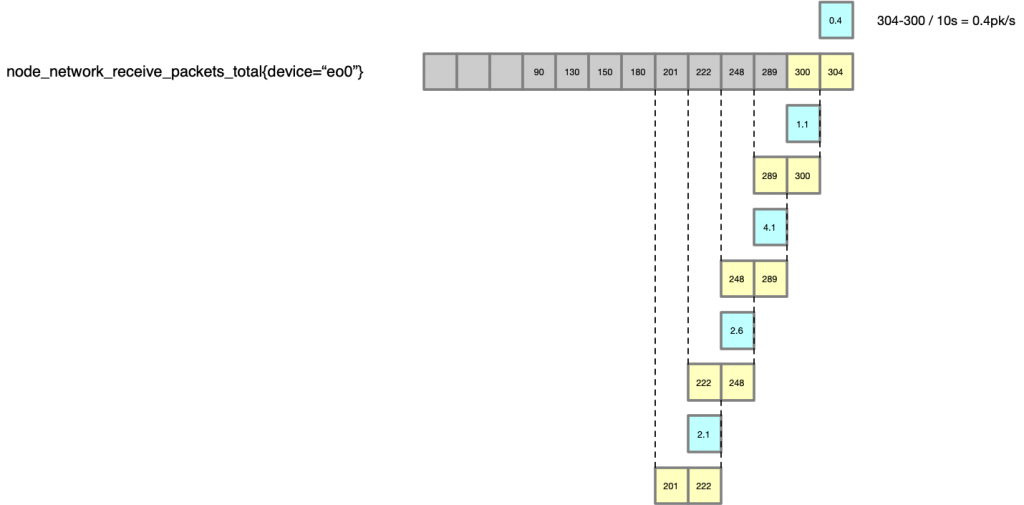
自然,因為只用最后兩個點的差值來計算,會比 rate 平均值的方法得到的結(jié)果,變化更加劇烈,更能反映當時的情況。那既然是使用最后兩個點計算,這里又為什么需要 [1m] 呢?這個 [1m] 不是用來計算的,是用來限制找 t-2 個點的時間的,比如,如果中間丟了很多數(shù)據(jù),那么顯然這個點的計算會很不準確,irate 在計算的時候會最多向前在 [1m] 找點,如果超過 [1m] 沒有找到數(shù)據(jù)點,這個點的計算就放棄了。
在現(xiàn)實中的例子,可以將上面查詢的 rate 改成 irate。
irate(node_network_receive_packets_total{device=~”en.*”}[1m])

對比與之前的圖,可以看到變化更加劇烈了。
那么,是不是我們總是使用 irate 比較好呢?也不是,比如 requests/s 這種,如果變化太劇烈,從面板上你只能看到一條劇烈抖動導致看不清數(shù)值的曲線,而具體值我們是不太關(guān)心的,我們可能更關(guān)心一天中的 QPS 變化情況;但是像是 CPU,network 這種資源的變化,使用 irate 更加有意義一些。
還有一個函數(shù)叫做 increase,它的計算方式是 end - start,沒有除。計算的是每分鐘的增量。比較好理解,這里就不畫圖了。
這三個函數(shù)接受的都是 Range Vector,返回的是 Instant Vector,比較常用。
另外需要注意的是,increase 和 rate 的 range 內(nèi)必須要有至少 4 個數(shù)據(jù)點。詳細的解釋可以見這里:What range should I use with rate()?[7]
介紹了這兩種類型,那么其他的 Prometheus 函數(shù)[8]應該都可以看文檔理解了。Prometheus 的文檔中會將函數(shù)這樣標注:
changes() For each input time series, changes(v range-vector) returns the number of times its value has changed within the provided time range as an instant vector.
我們就知道,changes() 這個函數(shù)接受的是一個 range-vector, 所以要帶上類似于 [1m] 。不能傳入不帶類似 [1m] 的 metrics,類似于這樣的使用是不合法的:change(requests_count{server="server_a"},這樣就相當于傳入了一個 Instant Vector。
看到這里,你應該已經(jīng)成為一只在 Prometheus 里面自由翱翔的鳥兒了。接下來可以抱著文檔[9]去寫查詢了,但是在這之前,讓我再介紹一點非常重要的誤區(qū)。
使用函數(shù)的順序問題
在計算 P99 的時候,我們會使用下面的查詢:
histogram_quantile(0.9,
????sum?by?(le)
????(rate(http_request_duration_seconds_bucket[10m]))
)
首先,Histogram 是一個 Counter,所以我們要使用 rate 先處理,然后根據(jù) le 將 labels 使用 sum 合起來,最后使用 histogram_quantile 來計算。這三個函數(shù)的順序是不能調(diào)換的,必須是先 rate 再 sum,最后 histogram_quantile。
為什么呢?這個問題可以分成兩步來看:
rate 必須在 sum 之前。前面提到過 Prometheus 支持在 Counter 的數(shù)據(jù)有下降之后自動處理的,比如服務器重啟了,metric 重新從 0 開始。這個其實不是在存儲的時候做的,比如應用暴露的 metric 就是從 2033 變成 0 了,那么 Prometheus 就會忠實地存儲 0. 但是在計算 rate 的時候,就會識別出來這個下降。但是 sum 不會,所以如果先 sum 再 rate,曲線就會出現(xiàn)非常大的波動。詳細見這里[10]。
histogram_quantile 必須在最后。在《P99 是如何計算的?[11]》這篇文章中介紹了 P99 的原理。也就是說 histogram_quantile 計算的結(jié)果是近似值,去聚合(無論是 sum 還是 max 還是 avg)這個值都是沒有意義的。
引用鏈接
How does a Prometheus Counter work?: https://www.robustperception.io/how-does-a-prometheus-counter-work
[2]在代碼中只用一種 Summary 類型: https://github.com/prometheus/client_python#summary
[3]P99 是如何計算的?: https://www.kawabangga.com/posts/4284
[4]參考文檔: https://prometheus.io/docs/prometheus/latest/querying/basics/
[5]圖靈完備 (Turing Complete): https://www.robustperception.io/conways-life-in-prometheus
[6]參考文檔: https://prometheus.io/docs/prometheus/latest/querying/basics/#time-durations
[7]What range should I use with rate()?: https://www.robustperception.io/what-range-should-i-use-with-rate
[8]Prometheus 函數(shù): https://prometheus.io/docs/prometheus/latest/querying/functions/
[9]文檔: https://prometheus.io/docs/introduction/overview/
[10]這里: https://www.robustperception.io/rate-then-sum-never-sum-then-rate
[11]P99 是如何計算的?: https://www.kawabangga.com/posts/4284
原文鏈接:https://www.kawabangga.com/posts/4408


你可能還喜歡
點擊下方圖片即可閱讀


云原生是一種信仰???
關(guān)注公眾號
后臺回復?k8s?獲取史上最方便快捷的 Kubernetes 高可用部署工具,只需一條命令,連 ssh 都不需要!


點擊?"閱讀原文"?獲取更好的閱讀體驗!
發(fā)現(xiàn)朋友圈變“安靜”了嗎?
