
十幾億用戶中心系統(tǒng),ES+Redis+MySQL架構(gòu)輕松搞定

一、背景
二、ES高可用方案
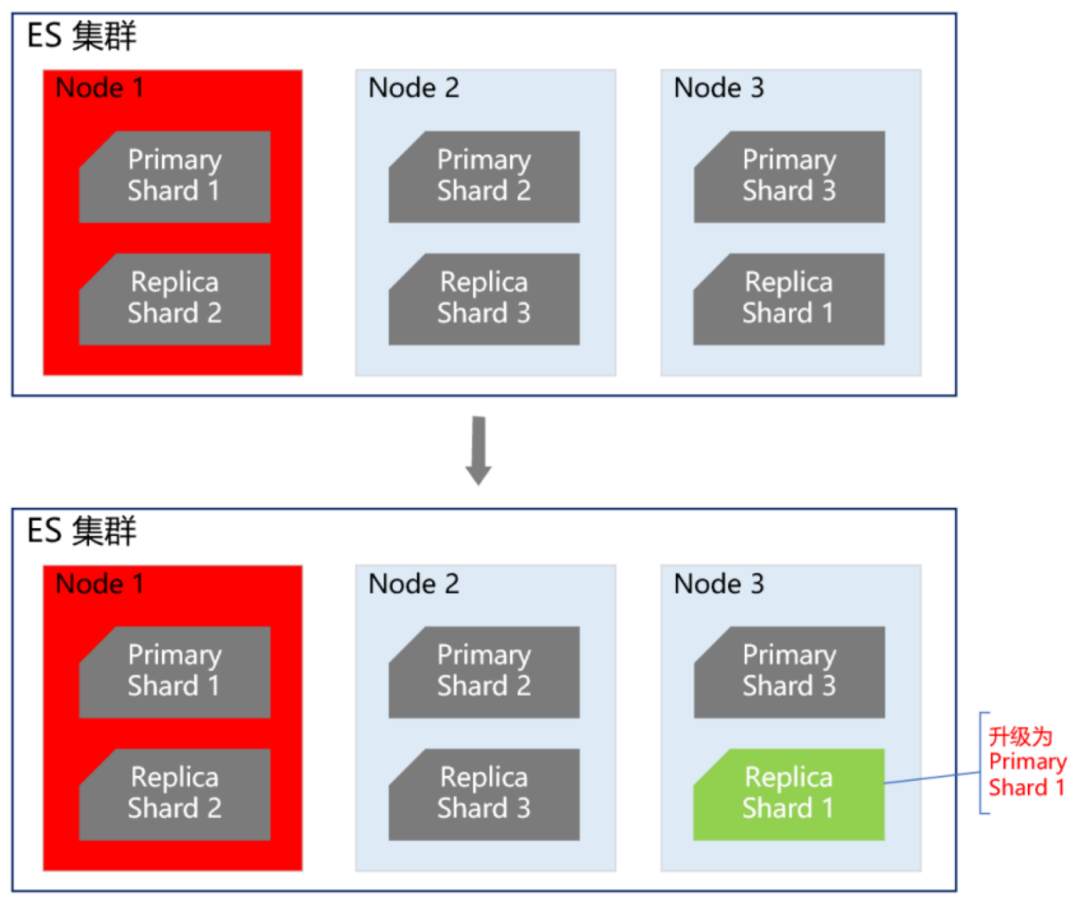
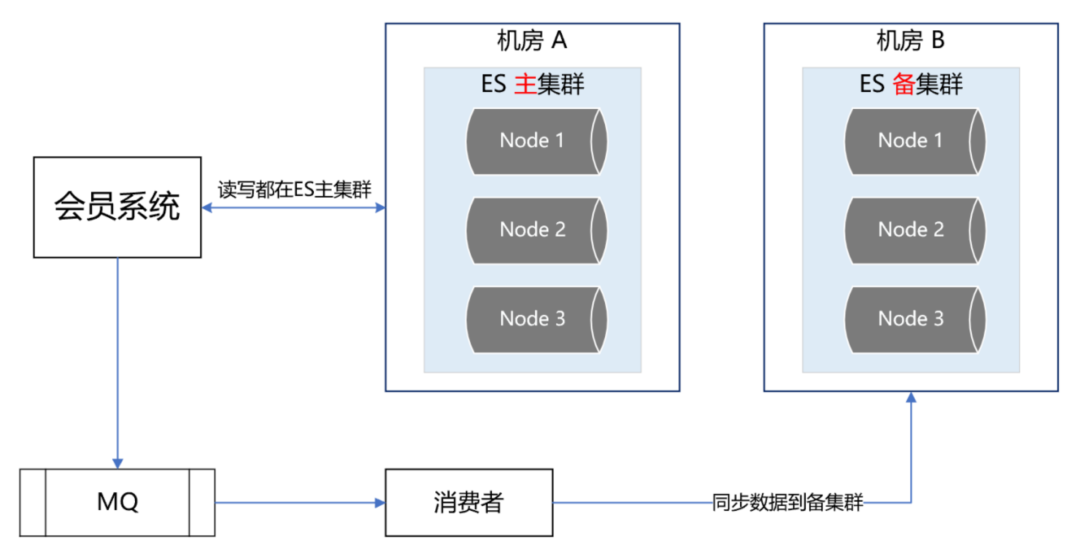
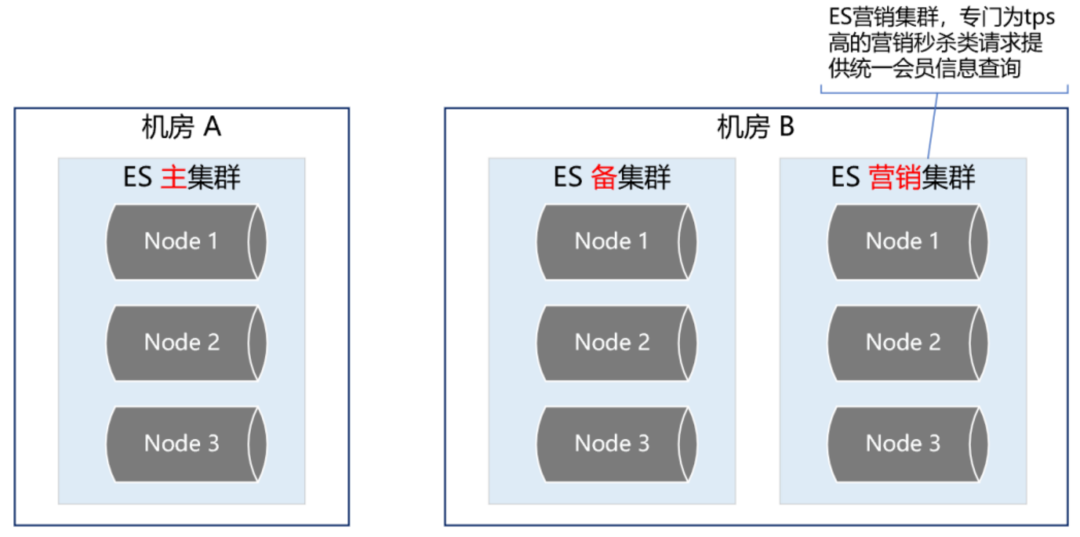
雙中心ES主備集群做到這一步,感覺應(yīng)該沒啥大問題了,但去年的一次恐怖流量沖擊讓我們改變了想法。那是一個(gè)節(jié)假日,某個(gè)業(yè)務(wù)上線了一個(gè)營(yíng)銷活動(dòng),在用戶的一次請(qǐng)求中,循環(huán)10多次調(diào)用了會(huì)員系統(tǒng),導(dǎo)致會(huì)員系統(tǒng)的tps暴漲,差點(diǎn)把ES集群打爆。這件事讓我們后怕不已,它讓我們意識(shí)到,一定要對(duì)調(diào)用方進(jìn)行優(yōu)先級(jí)分類,實(shí)施更精細(xì)的隔離、熔斷、降級(jí)、限流策略。首先,我們梳理了所有調(diào)用方,分出兩大類請(qǐng)求類型。第一類是跟用戶的下單主流程密切相關(guān)的請(qǐng)求,這類請(qǐng)求非常重要,應(yīng)該高優(yōu)先級(jí)保障。第二類是營(yíng)銷活動(dòng)相關(guān)的,這類請(qǐng)求有個(gè)特點(diǎn),他們的請(qǐng)求量很大,tps很高,但不影響下單主流程。基于此,我們又構(gòu)建了一個(gè)ES集群,專門用來應(yīng)對(duì)高tps的營(yíng)銷秒殺類請(qǐng)求,這樣就跟ES主集群隔離開來,不會(huì)因?yàn)槟硞€(gè)營(yíng)銷活動(dòng)的流量沖擊而影響用戶的下單主流程。如下圖所示:
講完了ES的雙中心主備集群高可用架構(gòu),接下來我們深入講解一下ES主集群的優(yōu)化工作。有一段時(shí)間,我們特別痛苦,就是每到飯點(diǎn),ES集群就開始報(bào)警,搞得每次吃飯都心慌慌的,生怕ES集群一個(gè)扛不住,就全公司炸鍋了。那為什么一到飯點(diǎn)就報(bào)警呢?因?yàn)榱髁勘容^大, 導(dǎo)致ES線程數(shù)飆高,cpu直往上竄,查詢耗時(shí)增加,并傳導(dǎo)給所有調(diào)用方,導(dǎo)致更大范圍的延時(shí)。那么如何解決這個(gè)問題呢?通過深入ES集群,我們發(fā)現(xiàn)了以下幾個(gè)問題:?
ES負(fù)載不合理,熱點(diǎn)問題嚴(yán)重。ES主集群一共有幾十個(gè)節(jié)點(diǎn),有的節(jié)點(diǎn)上部署的shard數(shù)偏多,有的節(jié)點(diǎn)部署的shard數(shù)很少,導(dǎo)致某些服務(wù)器的負(fù)載很高,每到流量高峰期,就經(jīng)常預(yù)警。
ES線程池的大小設(shè)置得太高,導(dǎo)致cpu飆高。我們知道,設(shè)置ES的threadpool,一般將線程數(shù)設(shè)置為服務(wù)器的cpu核數(shù),即使ES的查詢壓力很大,需要增加線程數(shù),那最好也不要超過“cpu core * 3 / 2 + 1”。如果設(shè)置的線程數(shù)過多,會(huì)導(dǎo)致cpu在多個(gè)線程上下文之間頻繁來回切換,浪費(fèi)大量cpu資源。
shard分配的內(nèi)存太大,100g,導(dǎo)致查詢變慢。我們知道,ES的索引要合理分配shard數(shù),要控制一個(gè)shard的內(nèi)存大小在50g以內(nèi)。如果一個(gè)shard分配的內(nèi)存過大,會(huì)導(dǎo)致查詢變慢,耗時(shí)增加,嚴(yán)重拖累性能。
string類型的字段設(shè)置了雙字段,既是text,又是keyword,導(dǎo)致存儲(chǔ)容量增大了一倍。會(huì)員信息的查詢不需要關(guān)聯(lián)度打分,直接根據(jù)keyword查詢就行,所以完全可以將text字段去掉,這樣就能節(jié)省很大一部分存儲(chǔ)空間,提升性能。
ES查詢,使用filter,不使用query。因?yàn)閝uery會(huì)對(duì)搜索結(jié)果進(jìn)行相關(guān)度算分,比較耗cpu,而會(huì)員信息的查詢是不需要算分的,這部分的性能損耗完全可以避免。
節(jié)約ES算力,將ES的搜索結(jié)果排序放在會(huì)員系統(tǒng)的jvm內(nèi)存中進(jìn)行。
增加routing key。我們知道,一次ES查詢,會(huì)將請(qǐng)求分發(fā)給所有shard,等所有shard返回結(jié)果后再聚合數(shù)據(jù),最后將結(jié)果返回給調(diào)用方。如果我們事先已經(jīng)知道數(shù)據(jù)分布在哪些shard上,那么就可以減少大量不必要的請(qǐng)求,提升查詢性能。
經(jīng)過以上優(yōu)化,成果非常顯著,ES集群的cpu大幅下降,查詢性能大幅提升。ES集群的cpu使用率:?
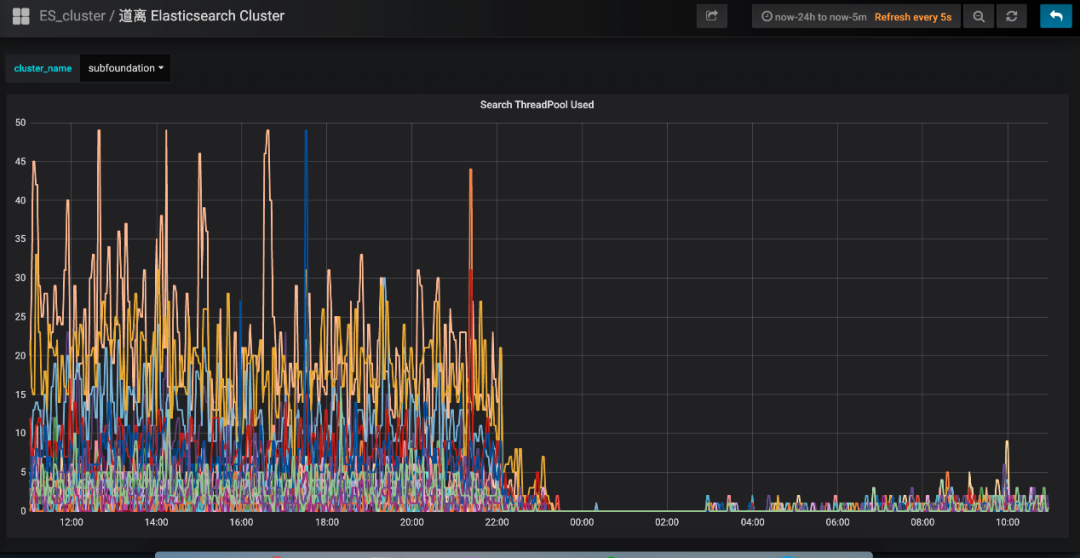
會(huì)員系統(tǒng)的接口耗時(shí):
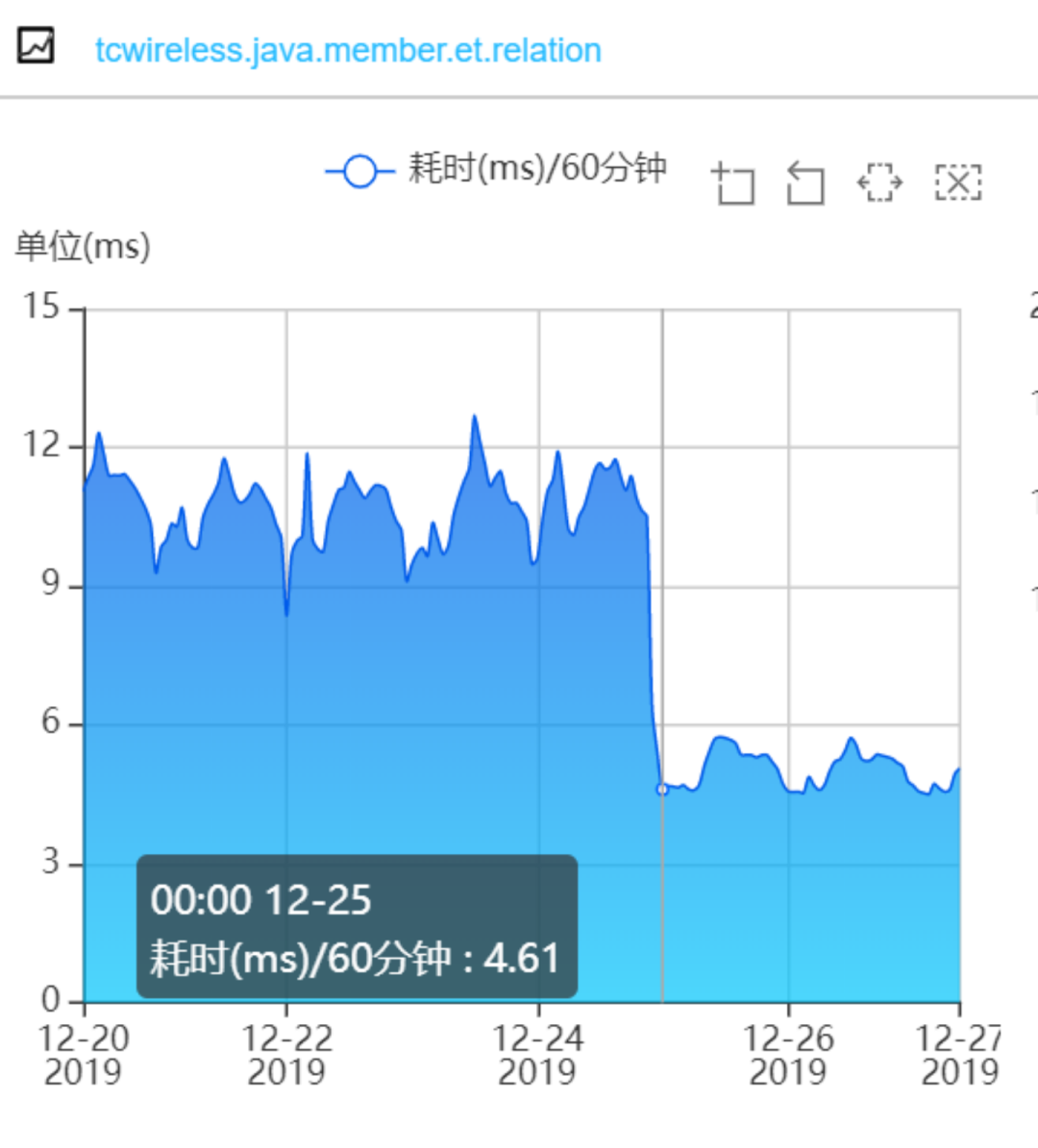
三、會(huì)員Redis緩存方案
一直以來,會(huì)員系統(tǒng)是不做緩存的,原因主要有兩個(gè):第一個(gè),前面講的ES集群性能很好,秒并發(fā)3萬多,99線耗時(shí)5毫秒左右,已經(jīng)足夠應(yīng)付各種棘手的場(chǎng)景。第二個(gè),有的業(yè)務(wù)對(duì)會(huì)員的綁定關(guān)系要求實(shí)時(shí)一致,而會(huì)員是一個(gè)發(fā)展了10多年的老系統(tǒng),是一個(gè)由好多接口、好多系統(tǒng)組成的分布式系統(tǒng)。所以,只要有一個(gè)接口沒有考慮到位,沒有及時(shí)去更新緩存,就會(huì)導(dǎo)致臟數(shù)據(jù),進(jìn)而引發(fā)一系列的問題,例如:用戶在APP上看不到微信訂單、APP和微信的會(huì)員等級(jí)、里程等沒合并、微信和APP無法交叉營(yíng)銷等等。那后來為什么又要做緩存呢?是因?yàn)榻衲隀C(jī)票的盲盒活動(dòng),它帶來的瞬時(shí)并發(fā)太高了。雖然會(huì)員系統(tǒng)安然無恙,但還是有點(diǎn)心有余悸,穩(wěn)妥起見,最終還是決定實(shí)施緩存方案。
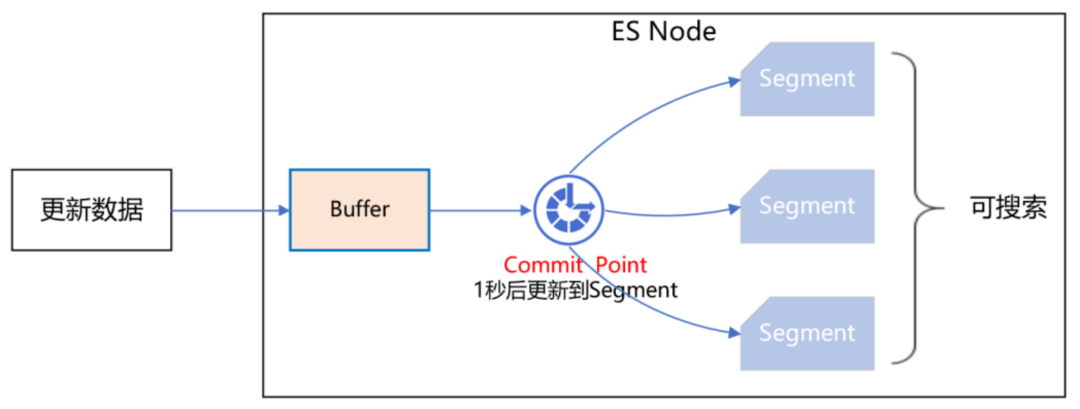
在做會(huì)員緩存方案的過程中,遇到一個(gè)ES引發(fā)的問題,該問題會(huì)導(dǎo)致緩存數(shù)據(jù)的不一致。我們知道,ES操作數(shù)據(jù)是近實(shí)時(shí)的,往ES新增一個(gè)Document,此時(shí)立即去查,是查不到的,需要等待1秒后才能查詢到。如下圖所示:
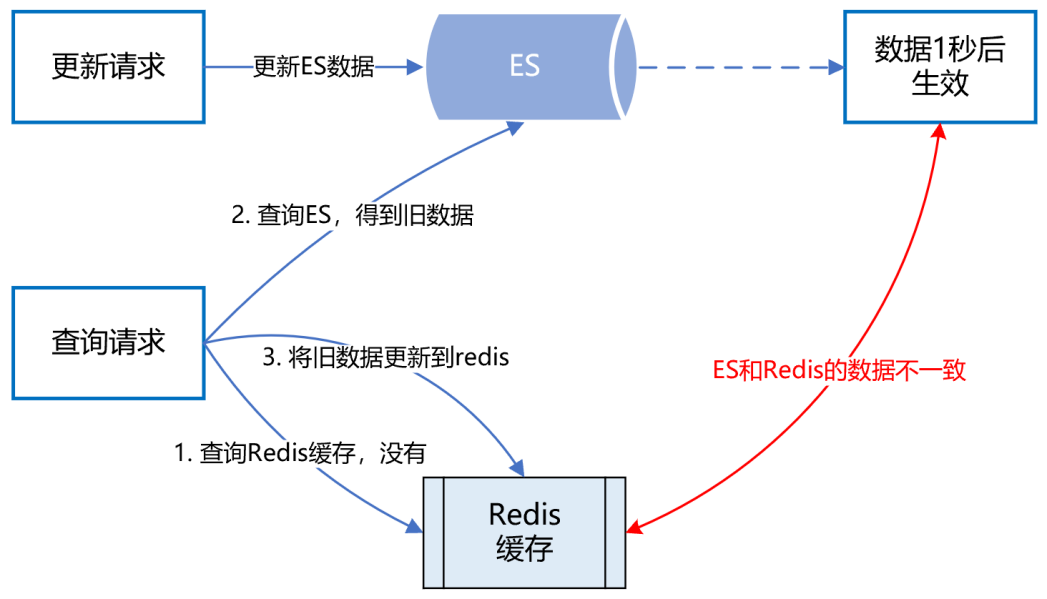
ES的近實(shí)時(shí)機(jī)制為什么會(huì)導(dǎo)致redis緩存數(shù)據(jù)不一致呢?具體來講,假設(shè)一個(gè)用戶注銷了自己的APP賬號(hào),此時(shí)需要更新ES,刪除APP賬號(hào)和微信賬號(hào)的綁定關(guān)系。而ES的數(shù)據(jù)更新是近實(shí)時(shí)的,也就是說,1秒后你才能查詢到更新后的數(shù)據(jù)。而就在這1秒內(nèi),有個(gè)請(qǐng)求來查詢?cè)撚脩舻臅?huì)員綁定關(guān)系,它先到redis緩存中查,發(fā)現(xiàn)沒有,然后到ES查,查到了,但查到的是更新前的舊數(shù)據(jù)。最后,該請(qǐng)求把查詢到的舊數(shù)據(jù)更新到redis緩存并返回。就這樣,1秒后,ES中該用戶的會(huì)員數(shù)據(jù)更新了,但redis緩存的數(shù)據(jù)還是舊數(shù)據(jù),導(dǎo)致了redis緩存跟ES的數(shù)據(jù)不一致。如下圖所示:
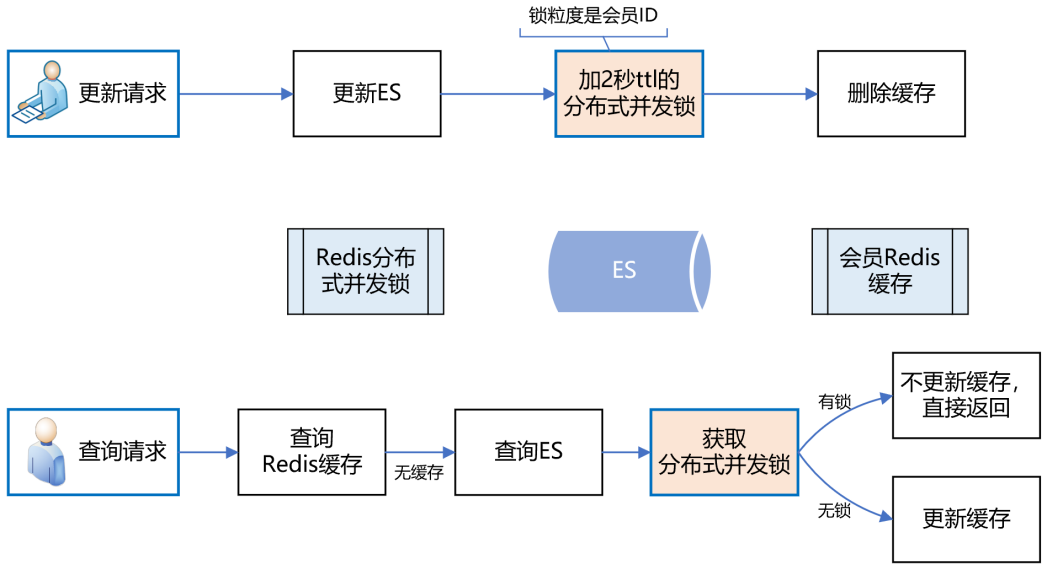
上述方案,乍一看似乎沒什么問題了,但仔細(xì)分析,還是有可能導(dǎo)致緩存數(shù)據(jù)的不一致。例如,在更新請(qǐng)求加分布式鎖之前,恰好有一個(gè)查詢請(qǐng)求獲取分布式鎖,而此時(shí)是沒有鎖的,所以它可以繼續(xù)更新緩存。但就在他更新緩存之前,線程block了,此時(shí)更新請(qǐng)求來了,加了分布式鎖,并刪除了緩存。當(dāng)更新請(qǐng)求完成操作后,查詢請(qǐng)求的線程活過來了,此時(shí)它再執(zhí)行更新緩存,就把臟數(shù)據(jù)寫到緩存中了。發(fā)現(xiàn)沒有?主要的問題癥結(jié)就在于“刪除緩存”和“更新緩存”發(fā)生了并發(fā)沖突,只要將它們互斥,就能解決問題。如下圖所示:
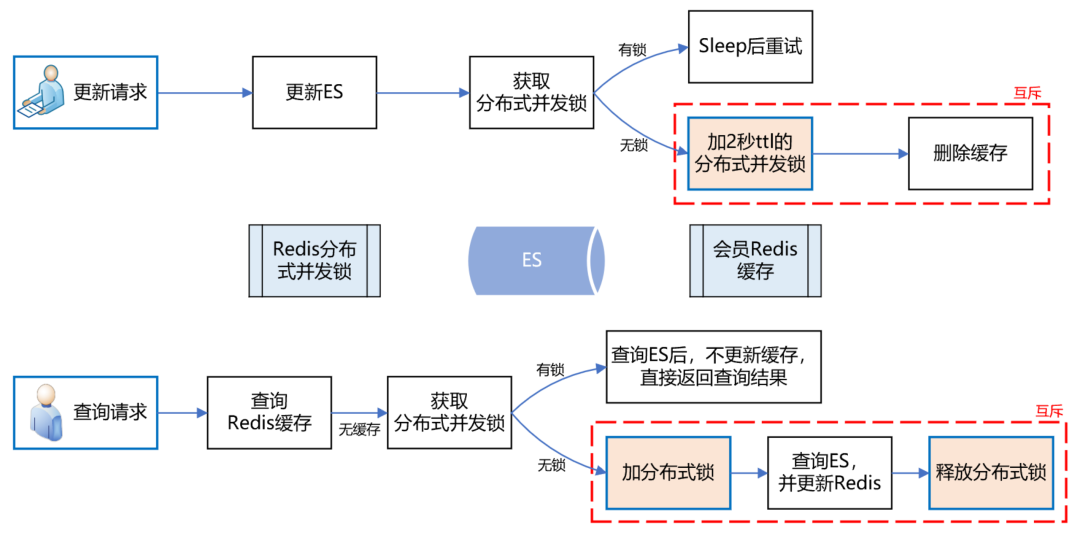
實(shí)施了緩存方案后,經(jīng)統(tǒng)計(jì),緩存命中率90%+,極大緩解了ES的壓力,會(huì)員系統(tǒng)整體性能得到了很大提升。
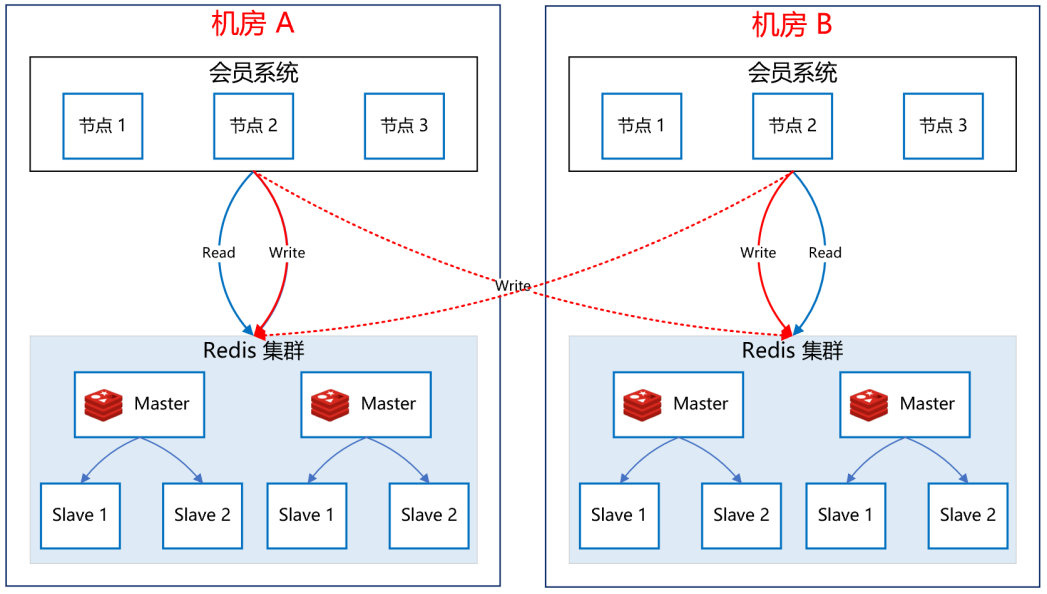
接下來,我們看一下如何保障Redis集群的高可用。如下圖所示:?
四、高可用會(huì)員主庫方案
上述講到,全平臺(tái)會(huì)員的綁定關(guān)系數(shù)據(jù)存在ES,而會(huì)員的注冊(cè)明細(xì)數(shù)據(jù)存在關(guān)系型數(shù)據(jù)庫。最早,會(huì)員使用的數(shù)據(jù)庫是SqlServer,直到有一天,DBA找到我們說,單臺(tái)SqlServer數(shù)據(jù)庫已經(jīng)存儲(chǔ)了十多億的會(huì)員數(shù)據(jù),服務(wù)器已達(dá)到物理極限,不能再擴(kuò)展了。按照現(xiàn)在的增長(zhǎng)趨勢(shì),過不了多久,整個(gè)SqlServer數(shù)據(jù)庫就崩了。你想想,那是一種什么樣的災(zāi)難場(chǎng)景:會(huì)員數(shù)據(jù)庫崩了,會(huì)員系統(tǒng)就崩了;會(huì)員系統(tǒng)崩了,全公司所有業(yè)務(wù)線就崩了。想想就不寒而栗,酸爽無比,為此我們立刻開啟了遷移DB的工作。
經(jīng)過調(diào)研,我們選擇了雙中心分庫分表的MySql集群方案,如下圖所示:
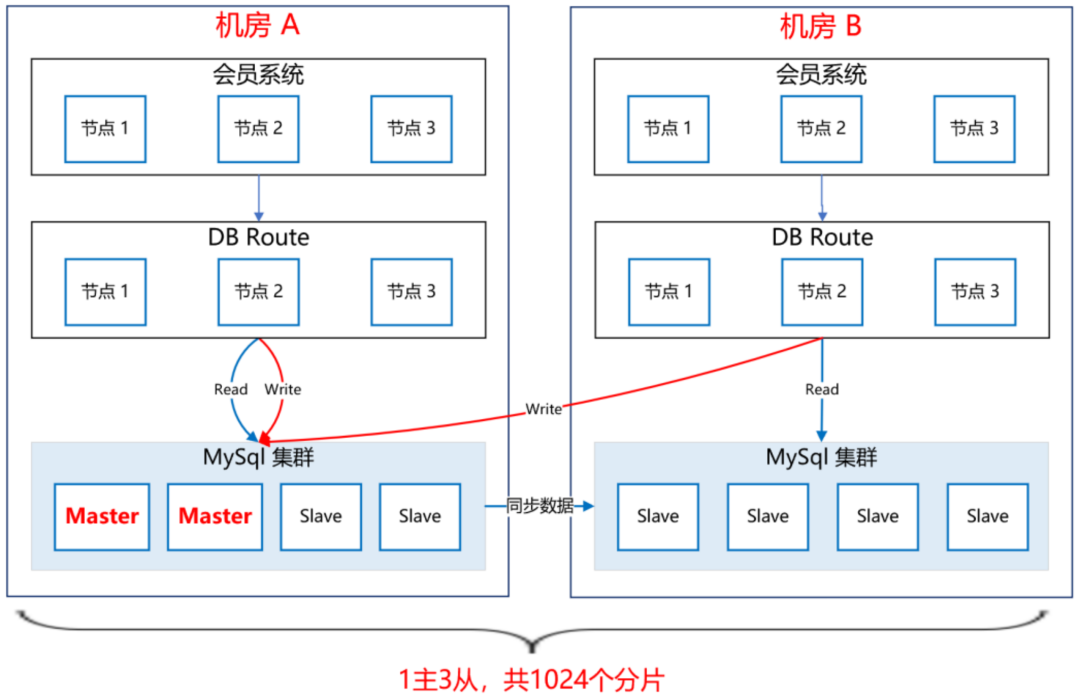
會(huì)員一共有十多億的數(shù)據(jù),我們把會(huì)員主庫分了1000多個(gè)分片,平分到每個(gè)分片大概百萬的量級(jí),足夠使用了。MySql集群采用1主3從的架構(gòu),主庫放在機(jī)房A,從庫放在機(jī)房B,兩個(gè)機(jī)房之間通過專線同步數(shù)據(jù),延遲在1毫秒內(nèi)。會(huì)員系統(tǒng)通過DBRoute讀寫數(shù)據(jù),寫數(shù)據(jù)都路由到master節(jié)點(diǎn)所在的機(jī)房A,讀數(shù)據(jù)都路由到本地機(jī)房,就近訪問,減少網(wǎng)絡(luò)延遲。這樣,采用雙中心的MySql集群架構(gòu),極大提高了可用性,即使機(jī)房A整體都崩了,還可以將機(jī)房B的Slave升級(jí)為Master,繼續(xù)提供服務(wù)。
雙中心MySql集群搭建好后,我們進(jìn)行了壓測(cè),測(cè)試下來,秒并發(fā)能達(dá)到2萬多,平均耗時(shí)在10毫秒內(nèi),性能達(dá)標(biāo)。
接下來的工作,就是把會(huì)員系統(tǒng)的底層存儲(chǔ)從SqlServer切到MySql上,這是個(gè)風(fēng)險(xiǎn)極高的工作,主要有以下幾個(gè)難點(diǎn):
基于以上痛點(diǎn),我們?cè)O(shè)計(jì)了“全量同步、增量同步、實(shí)時(shí)流量灰度切換”的技術(shù)方案。
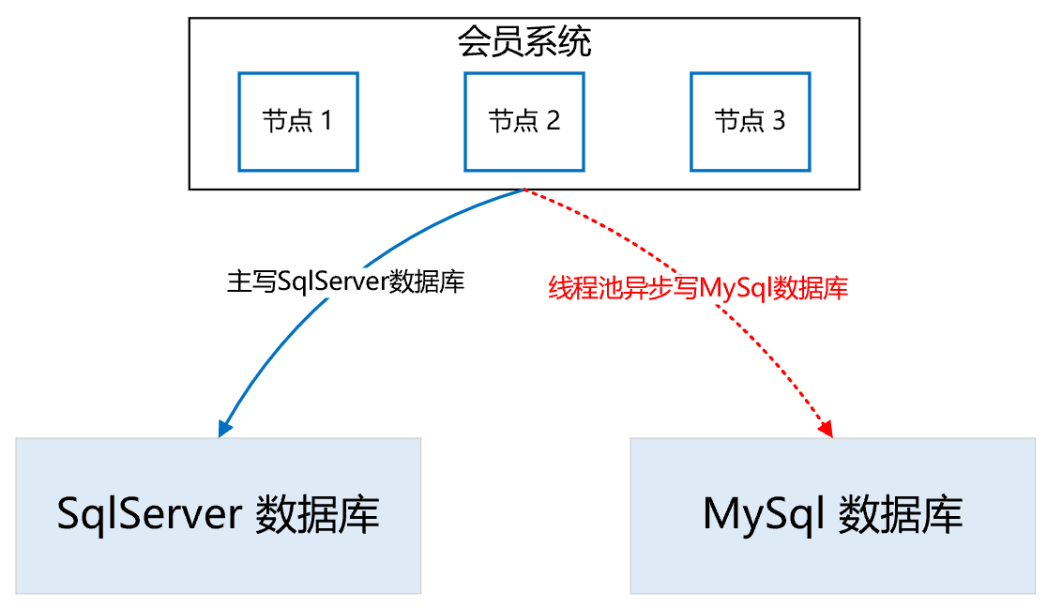
首先,為了保證數(shù)據(jù)的無縫切換,采用實(shí)時(shí)雙寫的方案。因?yàn)闃I(yè)務(wù)邏輯的復(fù)雜,以及SqlServer和MySql的技術(shù)差異性,在雙寫mysql的過程中,不一定會(huì)寫成功,而一旦寫失敗,就會(huì)導(dǎo)致SqlServer和MySql的數(shù)據(jù)不一致,這是絕不允許的。所以,我們采取的策略是,在試運(yùn)行期間,主寫SqlServer,然后通過線程池異步寫MySql,如果寫失敗了,重試三次,如果依然失敗,則記日志,然后人工排查原因,解決后,繼續(xù)雙寫,直到運(yùn)行一段時(shí)間,沒有雙寫失敗的情況。通過上述策略,可以確保在絕大部分情況下,雙寫操作的正確性和穩(wěn)定性,即使在試運(yùn)行期間出現(xiàn)了SqlServer和MySql的數(shù)據(jù)不一致的情況,也可以基于SqlServer再次全量構(gòu)建出MySql的數(shù)據(jù),因?yàn)槲覀冊(cè)谠O(shè)計(jì)雙寫策略時(shí),會(huì)確保SqlServer一定能寫成功,也就是說,SqlServer中的數(shù)據(jù)是全量最完整、最正確的。如下圖所示:
所以,整體的實(shí)施流程如下:

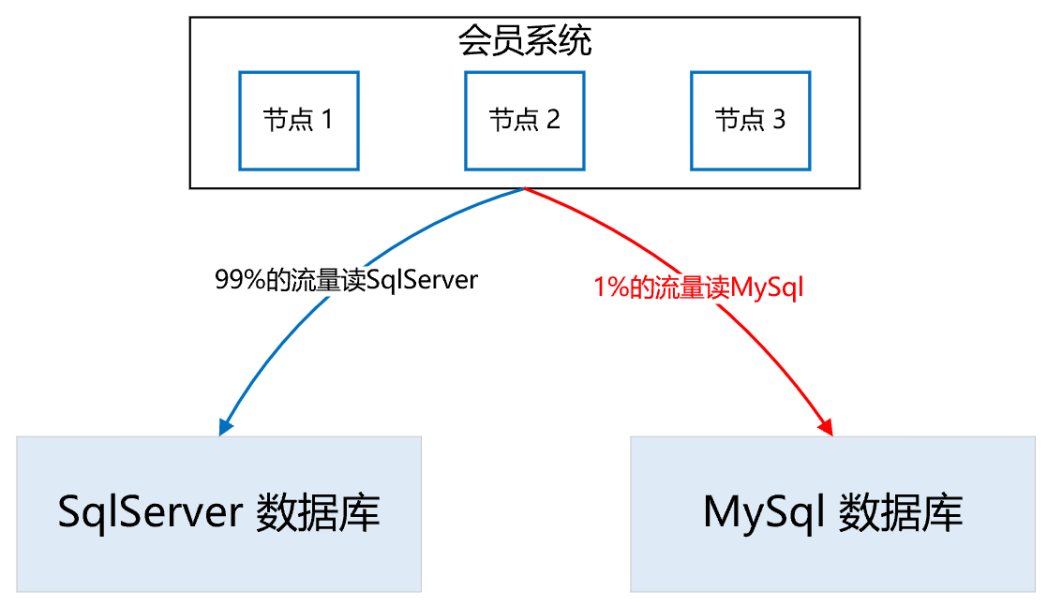
首先,在一個(gè)夜黑風(fēng)高的深夜,流量最小的時(shí)候,完成SqlServer到MySql數(shù)據(jù)庫的全量數(shù)據(jù)同步。接著,開啟雙寫,此時(shí),如果有用戶注冊(cè),就會(huì)實(shí)時(shí)雙寫到兩個(gè)數(shù)據(jù)庫。那么,在全量同步和實(shí)時(shí)雙寫開啟之間,兩個(gè)數(shù)據(jù)庫還相差這段時(shí)間的數(shù)據(jù),所以需要再次增量同步,把數(shù)據(jù)補(bǔ)充完整,以防數(shù)據(jù)的不一致。剩下的時(shí)間,就是各種日志監(jiān)控,看雙寫是否有問題,看數(shù)據(jù)比對(duì)是否一致等等。這段時(shí)間是耗時(shí)最長(zhǎng)的,也是最容易發(fā)生問題的,如果有的問題比較嚴(yán)重,導(dǎo)致數(shù)據(jù)不一致了,就需要從頭再來,再次基于SqlServer全量構(gòu)建MySql數(shù)據(jù)庫,然后重新灰度流量,直到最后,100%的流量全部灰度到MySql,此時(shí)就大功告成了,下線灰度邏輯,所有讀寫都切到MySql集群。
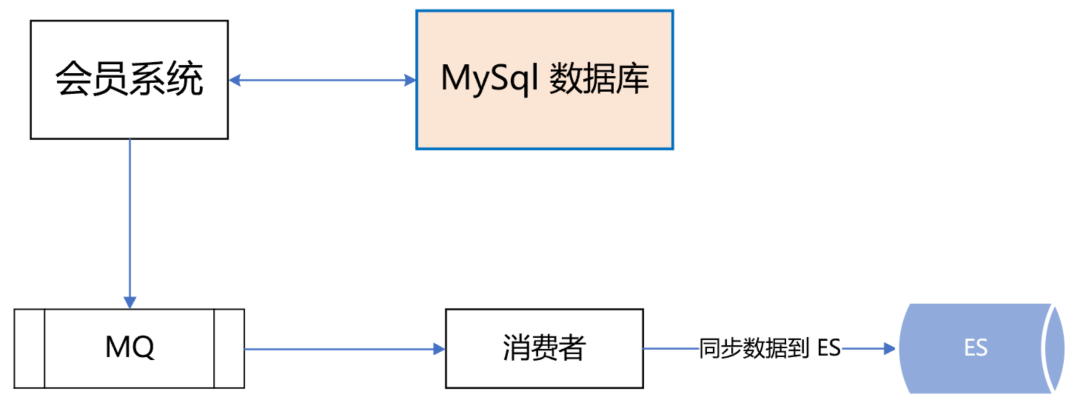
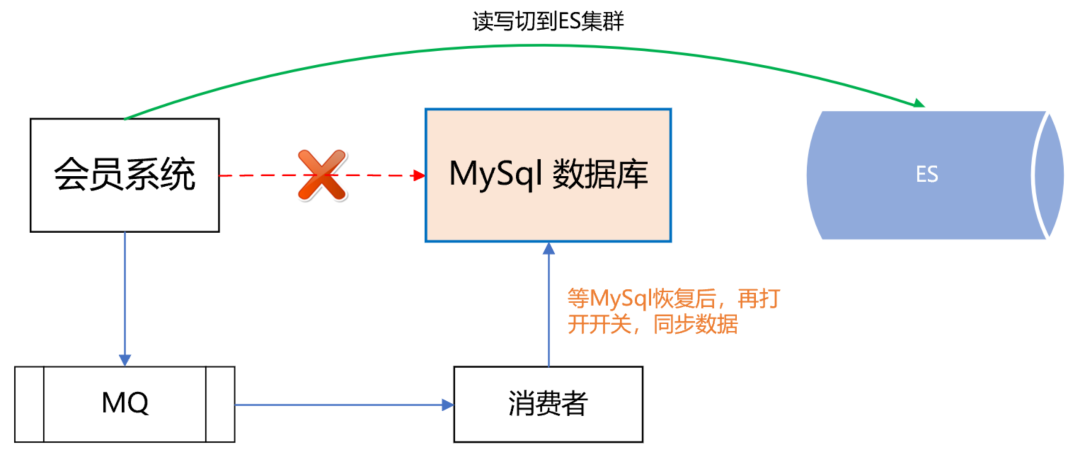
做到這一步,感覺會(huì)員主庫應(yīng)該沒問題了,可dal組件的一次嚴(yán)重故障改變了我們的想法。那次故障很恐怖,公司很多應(yīng)用連接不上數(shù)據(jù)庫了,創(chuàng)單量直線往下掉,這讓我們意識(shí)到,即使數(shù)據(jù)庫是好的,但dal組件異常,依然能讓會(huì)員系統(tǒng)掛掉。所以,我們?cè)俅萎悩?gòu)了會(huì)員主庫的數(shù)據(jù)源,雙寫數(shù)據(jù)到ES,如下所示:
五、異常會(huì)員關(guān)系治理
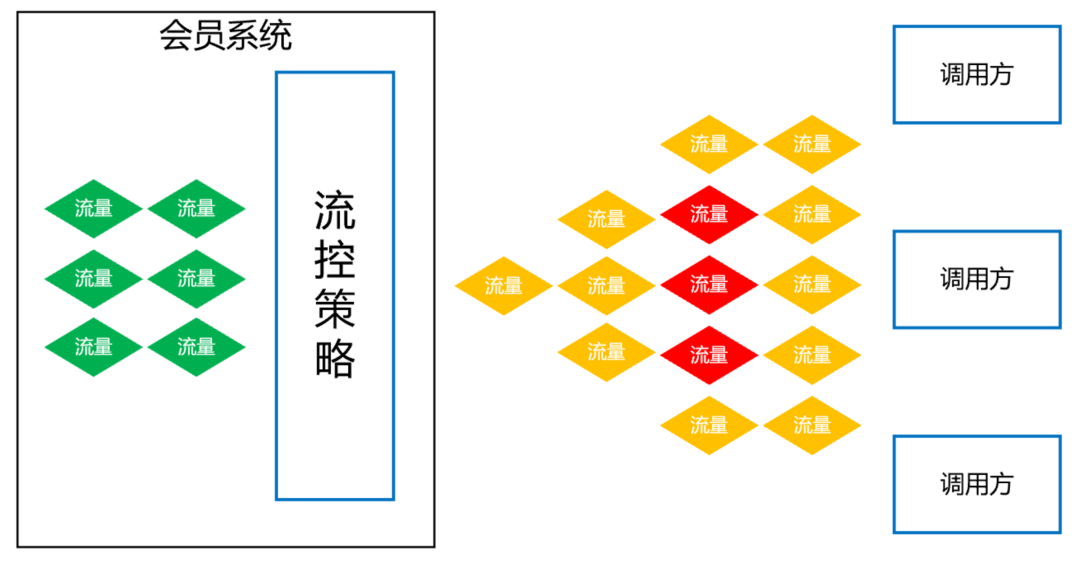
六、展望:更精細(xì)化的流控和降級(jí)策略
任何一個(gè)系統(tǒng),都不能保證百分之一百不出問題,所以我們要有面向失敗的設(shè)計(jì),那就是更精細(xì)化的流控和降級(jí)策略。
熱點(diǎn)控制。針對(duì)黑產(chǎn)刷單的場(chǎng)景,同一個(gè)會(huì)員id會(huì)有大量重復(fù)的請(qǐng)求,形成熱點(diǎn)賬號(hào),當(dāng)這些賬號(hào)的訪問超過設(shè)定閾值時(shí),實(shí)施限流策略。
基于調(diào)用賬號(hào)的流控規(guī)則。這個(gè)策略主要是防止調(diào)用方的代碼bug導(dǎo)致的大流量。例如,調(diào)用方在一次用戶請(qǐng)求中,循環(huán)很多次來調(diào)用會(huì)員接口,導(dǎo)致會(huì)員系統(tǒng)流量暴增很多倍。所以,要針對(duì)每個(gè)調(diào)用賬號(hào)設(shè)置流控規(guī)則,當(dāng)超過閾值時(shí),實(shí)施限流策略。
全局流控規(guī)則。我們會(huì)員系統(tǒng)能抗下tps 3萬多的秒并發(fā)請(qǐng)求量,如果此時(shí),有個(gè)很恐怖的流量打過來,tps高達(dá)10萬,與其讓這波流量把會(huì)員數(shù)據(jù)庫、es全部打死,還不如把超過會(huì)員系統(tǒng)承受范圍之外的流量快速失敗,至少tps 3萬內(nèi)的會(huì)員請(qǐng)求能正常響應(yīng),不會(huì)讓整個(gè)會(huì)員系統(tǒng)全部崩潰。
基于平均響應(yīng)時(shí)間的降級(jí)。會(huì)員接口也有依賴其他接口,當(dāng)調(diào)用其他接口的平均響應(yīng)時(shí)間超過閾值,進(jìn)入準(zhǔn)降級(jí)狀態(tài)。如果接下來 1s 內(nèi)進(jìn)入的請(qǐng)求,它們的平均響應(yīng)時(shí)間都持續(xù)超過閾值,那么在接下的時(shí)間窗口內(nèi),自動(dòng)地熔斷。
基于異常數(shù)和異常比例的降級(jí)。當(dāng)會(huì)員接口依賴的其他接口發(fā)生異常,如果1分鐘內(nèi)的異常數(shù)超過閾值,或者每秒異常總數(shù)占通過量的比值超過閾值,進(jìn)入降級(jí)狀態(tài),在接下的時(shí)間窗口之內(nèi),自動(dòng)熔斷。
目前,我們最大的痛點(diǎn)是會(huì)員調(diào)用賬號(hào)的治理。公司內(nèi),想要調(diào)用會(huì)員接口,必須申請(qǐng)一個(gè)調(diào)用賬號(hào),我們會(huì)記錄該賬號(hào)的使用場(chǎng)景,并設(shè)置流控、降級(jí)策略的規(guī)則。但在實(shí)際使用的過程中,申請(qǐng)了該賬號(hào)的同事,可能異動(dòng)到其他部門了,此時(shí)他可能也會(huì)調(diào)用會(huì)員系統(tǒng),為了省事,他不會(huì)再次申請(qǐng)會(huì)員賬號(hào),而是直接沿用以前的賬號(hào)過來調(diào)用,這導(dǎo)致我們無法判斷一個(gè)會(huì)員賬號(hào)的具體使用場(chǎng)景是什么,也就無法實(shí)施更精細(xì)的流控和降級(jí)策略。所以,接下來,我們將會(huì)對(duì)所有調(diào)用賬號(hào)進(jìn)行一個(gè)個(gè)的梳理,這是個(gè)非常龐大且繁瑣的工作,但無路如何,硬著頭皮也要做好。
來源:DBAPlus
熱門推薦:
PS:如果覺得我的分享不錯(cuò),歡迎大家隨手點(diǎn)贊、轉(zhuǎn)發(fā)、在看。