
重磅開源:超輕量3.5M中英文OCR模型,小小身材大大出乎意料
一、導讀
不得不說,2020年絕對是OCR開源界的豐收年,各種開源repo橫空出世,一次又一次的刷新開源界的baseline,小編今天再次給大家種個草,介紹今年OCR開源領(lǐng)域 “真.良心之作”百度飛槳PaddleOCR。
先看下飛槳文字識別套件PaddleOCR自今年年中開源以來,短短幾個月在GitHub上的表現(xiàn):
7月,8.6M超輕量模型發(fā)布,GitHub Trending 全球日榜榜單第一!
8月,開源CVPR2020頂會SOTA算法,再上GitHub趨勢榜單!
9月,GitHub Star數(shù)量已超過3.2K, 近期又帶來哪些重磅更新?
果然,看9月最新更新,PaddleOCR再次誠意滿滿為大家?guī)碚娓韶洠苯涌垂俜浇榻B:
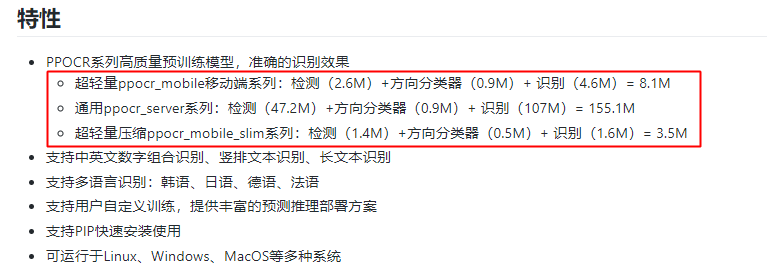
數(shù)量上,這次PaddleOCR一口氣發(fā)布了三個系列模型,滿足移動端、服務(wù)器端各種場景需求。而且,多語言也妥妥安排上了,全部訓練代碼和模型毫無保留開源。其中3.5M超輕量文字識別模型,堪稱目前業(yè)界開源的最輕量OCR模型了。
質(zhì)量上,如此輕量的模型,效果有保障嗎?不看廣告,直接看療效。
先看幾個常見的通用場景識別效果:



3.5M的模型能達到這個識別精度,絕對是良心之作了!
再看一個非正常顯示的圖片:

文字倒著也能識別,沒毛病(此處可以豎起大拇哥)。
想看更多效果?官方GitHub項目鏈接走起。
傳送門:
Github:https://github.com/PaddlePaddle/PaddleOCR
論文下載鏈接:
https://arxiv.org/abs/2009.09941
激動的心,顫抖的手,相信有OCR玩家要問:
有Demo可以動手玩一玩嗎?
二、快速體驗PaddleOCR的3.5M超輕量OCR模型
為了讓用戶快速上手,PaddleOCR也是做足了準備。
PC端快速嘗試:(打開網(wǎng)頁,選一張圖片,即可實時看到結(jié)果)
https://www.paddlepaddle.org.cn/hub/scene/ocr
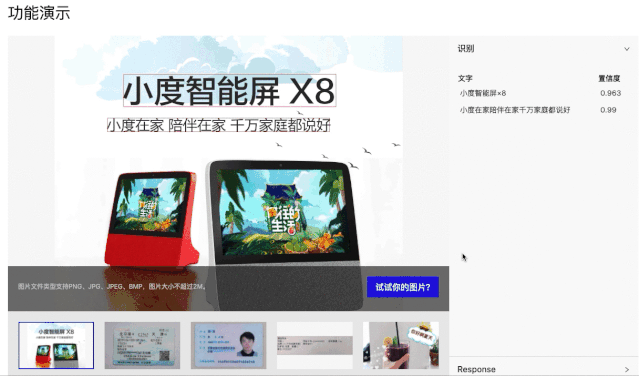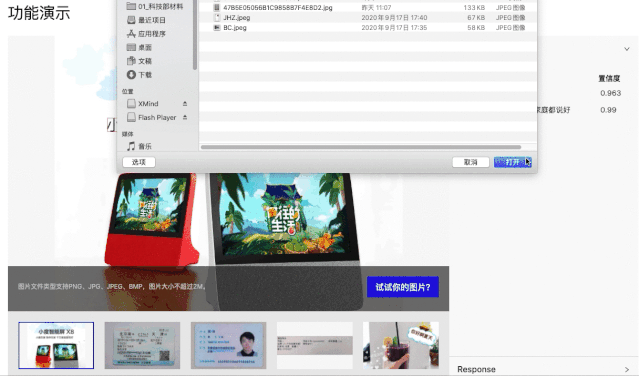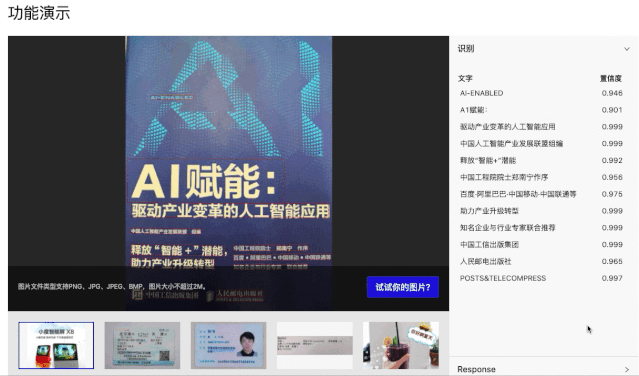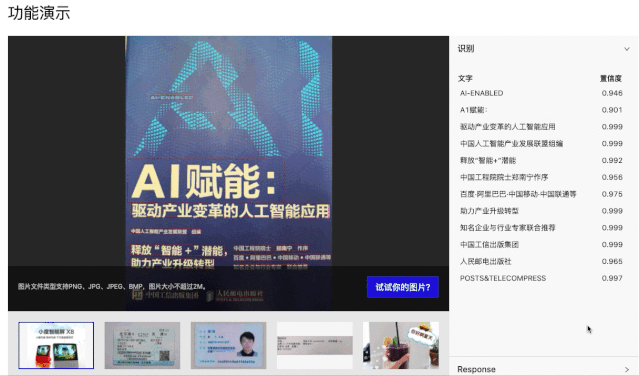
手機端App安裝體驗
PaddleOCR在百度大腦EasyEdge上開放了文字識別APP demo。安卓手機可直接掃碼下載:
iOS版本由于證書限制,需要登錄百度EasyEdge網(wǎng)頁掃碼體驗:https://ai.baidu.com/easyedge/app/openSource?from=paddlelite
效果如下:

通過PIP安裝包快速體驗PaddleOCR
# pip安裝pip install paddleocr# 快速使用from paddleocr import PaddleOCR, draw_ocr# Paddleocr目前支持中英文、英文、法語、德語、韓語、日語,可以通過修改lang參數(shù)進行切換,參數(shù)依次為`ch`, `en`, `french`, `german`, `korean`, `japan`。ocr = PaddleOCR(use_angle_cls=True, lang="ch")# 輸入待識別圖片路徑img_path = 'PaddleOCR/doc/imgs/11.jpg'# 輸出結(jié)果保存路徑result = ocr.ocr(img_path, cls=True)
更多內(nèi)容,可以進入https://github.com/PaddlePaddle/PaddleOCR 快速開始
三、多個開源repo測試對比
對于OCR方向的開發(fā)者而言,開源repo最吸引人的莫過于
①高質(zhì)量的預(yù)訓練模型
②簡單易上手的訓練代碼
③好用無坑的部署能力
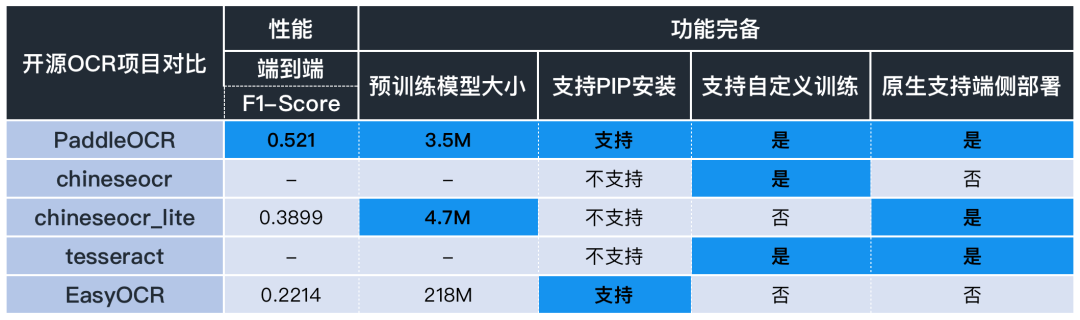 簡單對比一下目前主流OCR方向開源repo的核心能力:
簡單對比一下目前主流OCR方向開源repo的核心能力:
從性能指標來看:
針對OCR實際應(yīng)用場景,包括合同,車牌,銘牌,火車票,化驗單,表格,證書,街景文字,名片,數(shù)碼顯示屏等,收集的300張圖像,每張圖平均有17個文本框,PaddleOCR的F1-Score超過0.5,這個性能已經(jīng)很不錯了。
從功能完備來看:
預(yù)訓練模型大小:easyOCR目前暫無超輕量模型,chineseocr_lite最新的模型是4.7M左右,而PaddleOCR提供的3.5M無疑是目前業(yè)界已知最輕量的。
PIP安裝:目前僅PaddleOCR和easyOCR支持。
自定義訓練:實際業(yè)務(wù)場景中,預(yù)訓練模型往往不能滿足需求,對于自定義訓練和模型Finetuning,目前只有PaddleOCR支持。
部署方面:easyOCR模型較大不適合端側(cè)部署,Chineseocr_lite和PaddleOCR都具備端側(cè)部署能力。
開發(fā)者可以根據(jù)自己的實際需求,選擇適合自己的開源方案。
對于PaddleOCR 3.5MB的超輕量模型,是如何做到的,repo中也給出了解釋。
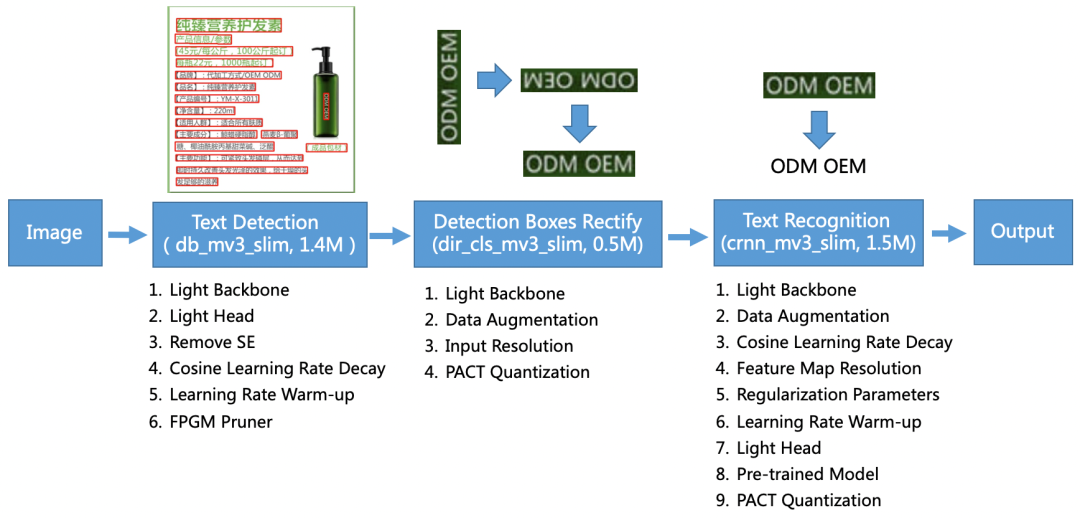
3.5M超輕量模型應(yīng)用了一套超輕量OCR系統(tǒng)PP-OCR,主要由DB文本檢測、檢測框矯正和CRNN文本識別三部分組成。該系統(tǒng)從骨干網(wǎng)絡(luò)選擇和調(diào)整、預(yù)測頭部的設(shè)計、數(shù)據(jù)增強、學習率變換策略、正則化參數(shù)選擇、預(yù)訓練模型使用以及模型自動裁剪量化8個方面,采用19個有效策略,對各個模塊的模型進行效果調(diào)優(yōu)和瘦身,最終得到整體大小為3.5M的超輕量中英文OCR模型和2M的英文數(shù)字OCR模型。
更多細節(jié)請參考文末PP-OCR技術(shù)文章。
其中,飛槳模型壓縮庫PaddleSlim為PaddleOCR超輕量化模型的實現(xiàn)提供了核心的技術(shù)支撐。PaddleSlim集成了模型剪枝、量化(包括量化訓練和離線量化)、蒸餾和神經(jīng)網(wǎng)絡(luò)搜索等多種業(yè)界常用且領(lǐng)先的模型壓縮功能。通過PaddleSlim對PP-OCR中檢測、檢測框矯正和識別模型的壓縮,從超輕量模型8.1M的壓縮到3.5M,模型大小降低了56.79%,其中檢測模型速度提升21%,而且整體模型精度還有一定提升。

四、更多驚喜等著你
除了3.5M超輕量OCR模型,PaddleOCR還隱藏哪些驚喜,一睹為快:
1、本次開源的超輕量英文數(shù)字識別模型,不得不說,考慮的真周到,英文場景用起來更溜。

2、多語言支持,中、英、德、法、韓、日,據(jù)了解還在持續(xù)迭代更新并擴充中,歡迎體驗。
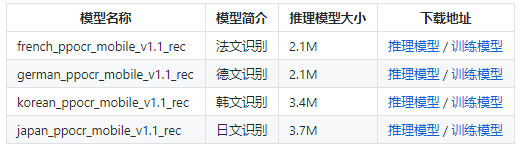
PaddleOCR也提供了多語言的識別模型配置文件如下圖所示: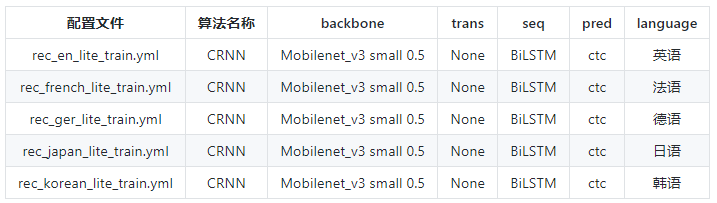
用戶可以根據(jù)自己需求重新訓練,也可以在預(yù)訓練基礎(chǔ)上調(diào)優(yōu)。
3、文檔教程,絕對是開源界的一股清流,對于OCR方向,能想到的內(nèi)容,PaddleOCR應(yīng)該都覆蓋了吧。


其中的FAQ部分強烈推薦,面試OCR算法工程師崗位你應(yīng)該用的到。
五、支持自定義訓練,豐富部署能力
開發(fā)者如果想要使用自定義數(shù)據(jù)訓練超輕量模型,也可以從PaddleOCR提供的基礎(chǔ)算法庫中選擇適合自己的文本檢測、識別算法,進行自定義的訓練。自定義訓練的存在讓開發(fā)者可以使用自己的數(shù)據(jù)集打造更為契合自身需求的產(chǎn)品,極大程度滿足了不同開發(fā)者的需求。
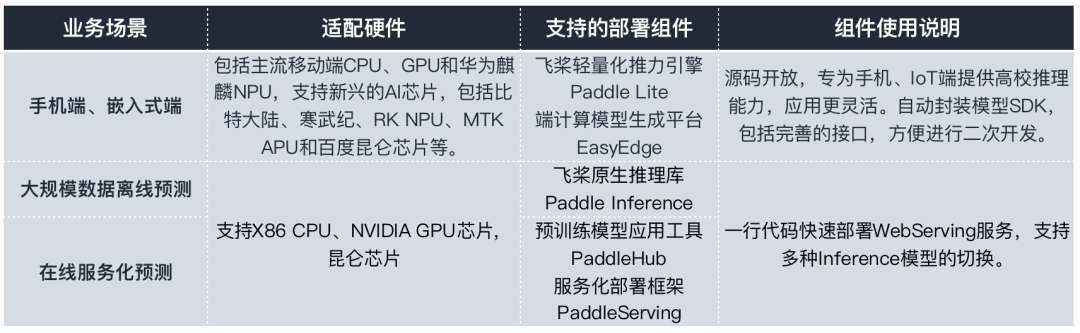
除了貼心的自定義訓練,滿足開發(fā)者產(chǎn)業(yè)級訓練的需求之外,百度PaddleOCR為了更好的方便開發(fā)者和企業(yè)應(yīng)用,打造了一系列的模型部署組件,可以支持開發(fā)者和企業(yè)在服務(wù)端、移動端、嵌入式硬件,云端服務(wù)化等多個不同的硬件平臺部署,最大化地滿足OCR文字識別領(lǐng)域的企業(yè)應(yīng)用。
六、招募活動預(yù)告
9月26日,飛槳將舉辦OCR方向的線下沙龍活動,歡迎北京OCR方向的開發(fā)者們,我們相聚中關(guān)村。
(掃描海報中的二維碼即可報名獲取直播鏈接或現(xiàn)場門票)
更多飛槳的相關(guān)內(nèi)容,請參閱以下內(nèi)容。
官網(wǎng)地址:https://www.paddlepaddle.org.cn
飛槳PaddleOCR項目地址:
GitHub: https://github.com/PaddlePaddle/PaddleOCR
Gitee: https://gitee.com/paddlepaddle/PaddleOCR
飛槳PaddleSlim項目地址:
GitHub: https://github.com/PaddlePaddle/PaddleSlim
Gitee: https://gitee.com/paddlepaddle/PaddleSlim
PP-OCR技術(shù)文章:
https://github.com/PaddlePaddle/PaddleOCR/raw/develop/doc/PPOCR.pdf