
0.2秒居然復制了100G文件?
點擊上方藍色字體,選擇“設為星標”
回復”學習資料“獲取學習寶典

文章轉自:OSC開源社區(qū)
cp 引發(fā)的思考
用 ls ?看一把文件,顯示文件確實是 100 G。
sh-4.4#?ls?-lh
-rw-r--r--?1?root?root?100G?Mar??6?12:22?test.txt
但是 copy 起來為什么會這么快呢?
sh-4.4#?time?cp?./test.txt?./test.txt.cp
real?0m0.107s
user?0m0.008s
sys?0m0.085s
①分析文件
我讓他先用 du 命令看一下,卻只有 2M ,根本不是 100G,這是怎么回事?
sh-4.4#?du?-sh?./test.txt
2.0M?./test.txt
再看 stat 命令顯示的信息:
sh-4.4#?stat?./test.txt
??File:?./test.txt
??Size:?107374182400?Blocks:?4096???????IO?Block:?4096???regular?file
Device:?78h/120d?Inode:?3148347?????Links:?1
Access:?(0644/-rw-r--r--)??Uid:?(????0/????root)???Gid:?(????0/????root)
Access:?2021-03-13?12:22:00.888871000?+0000
Modify:?2021-03-13?12:22:46.562243000?+0000
Change:?2021-03-13?12:22:46.562243000?+0000
?Birth:?-
Size 為 107374182400(知識點:單位是字節(jié)),也就是 100G。
Blocks 這個指標顯示為 4096(知識點:一個 Block 的單位固定是 512 字節(jié),也就是一個扇區(qū)的大小),這里表示為 2M。
Size 表示的是文件大小,這個也是大多數人看到的大小。
Blocks 表示的是物理實際占用空間。
文件系統
現實的存取場景:例如你到火車站使用寄存服務,存行李的時候,是不是要登記一些個人信息?
對吧,至少自己名字要寫上。可能還會給你一個牌子,讓你掛手上,這個東西就是為了標示每一個唯一的行李。
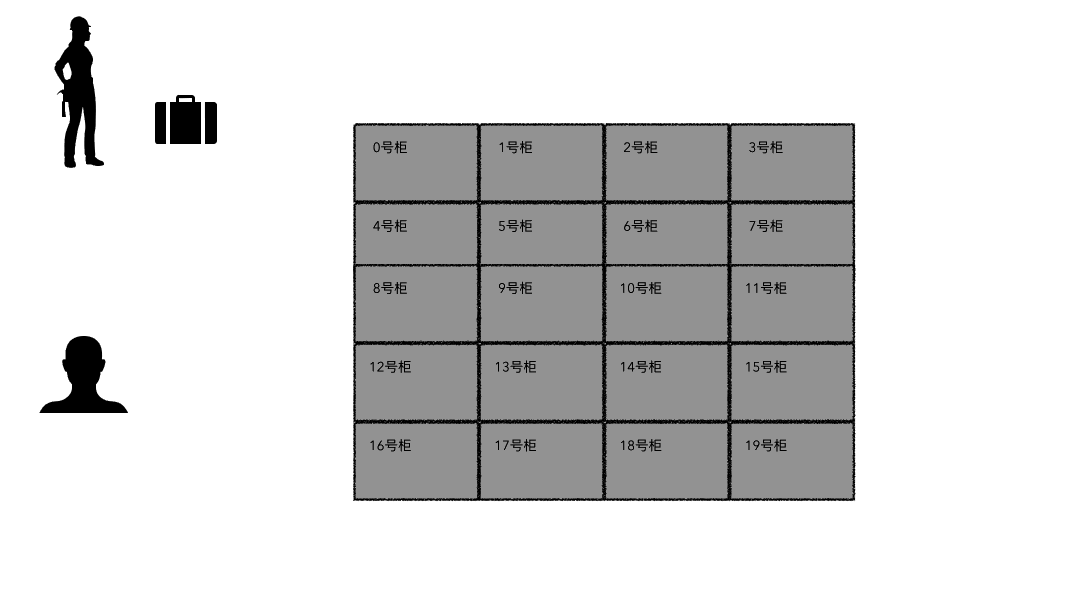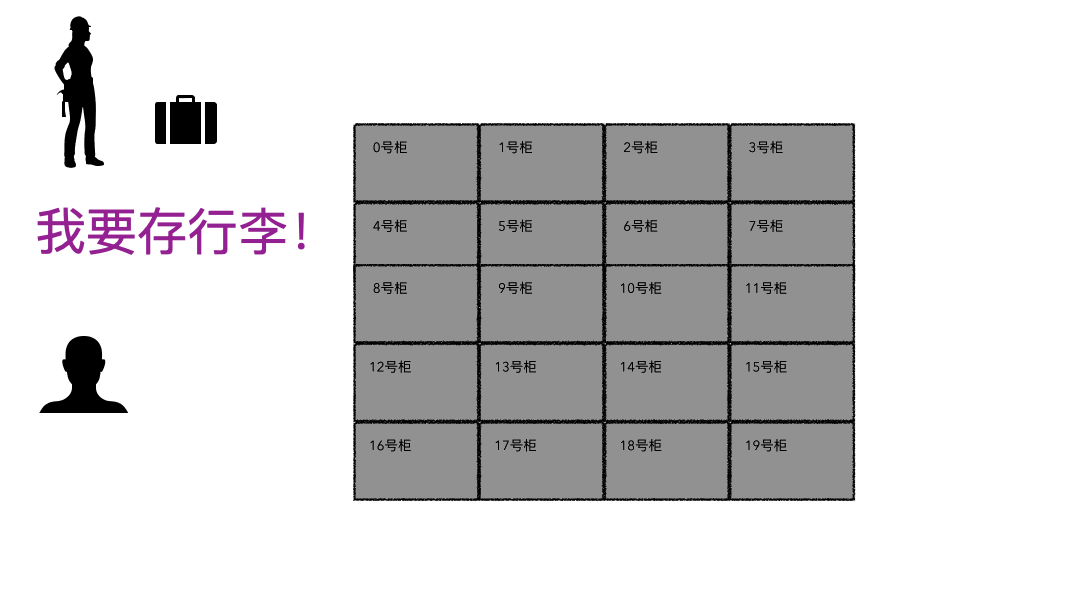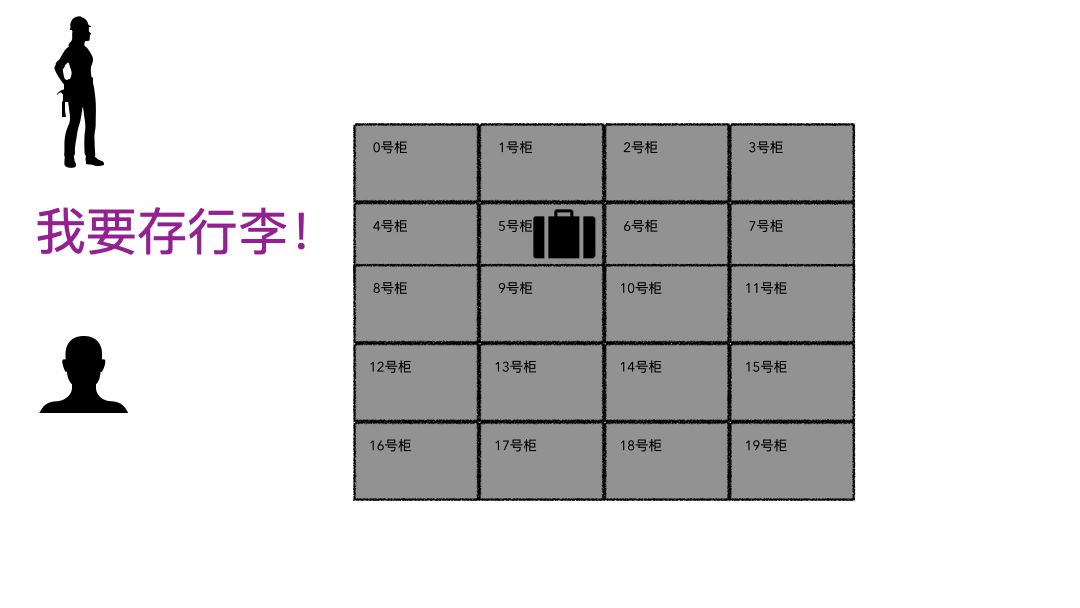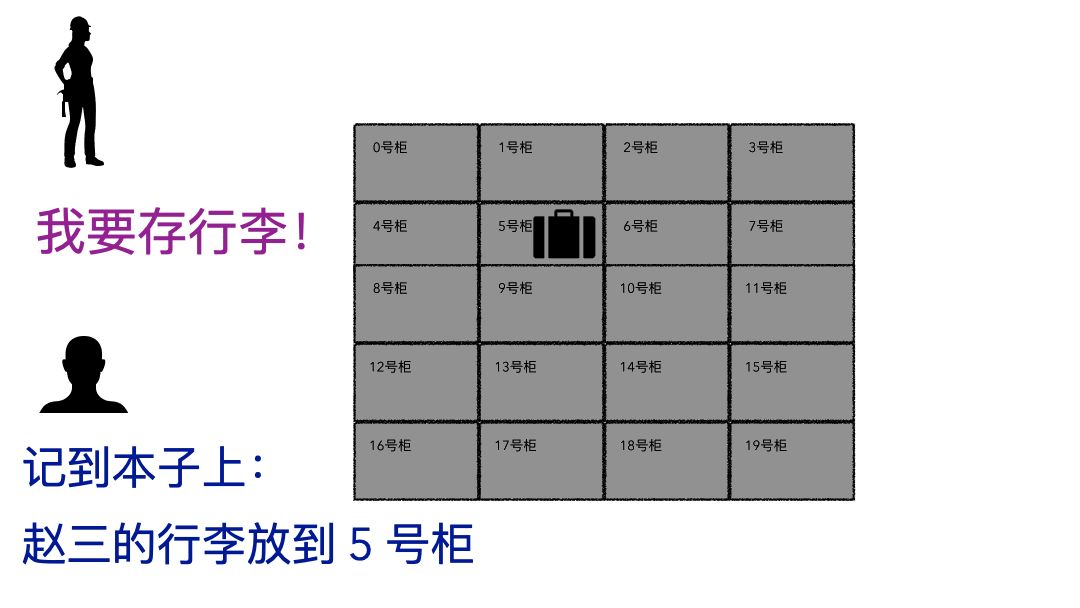
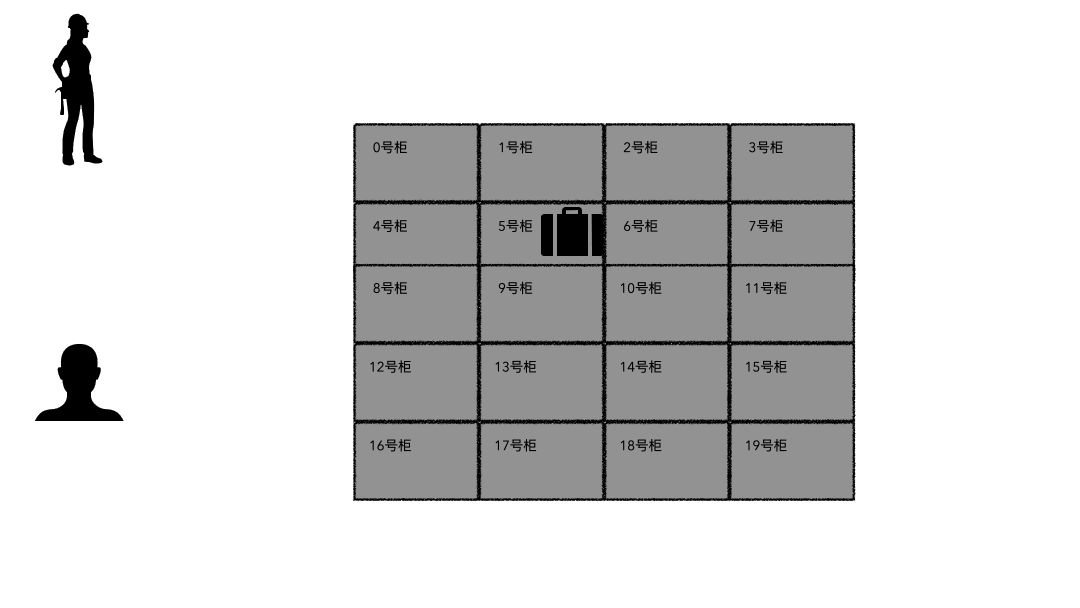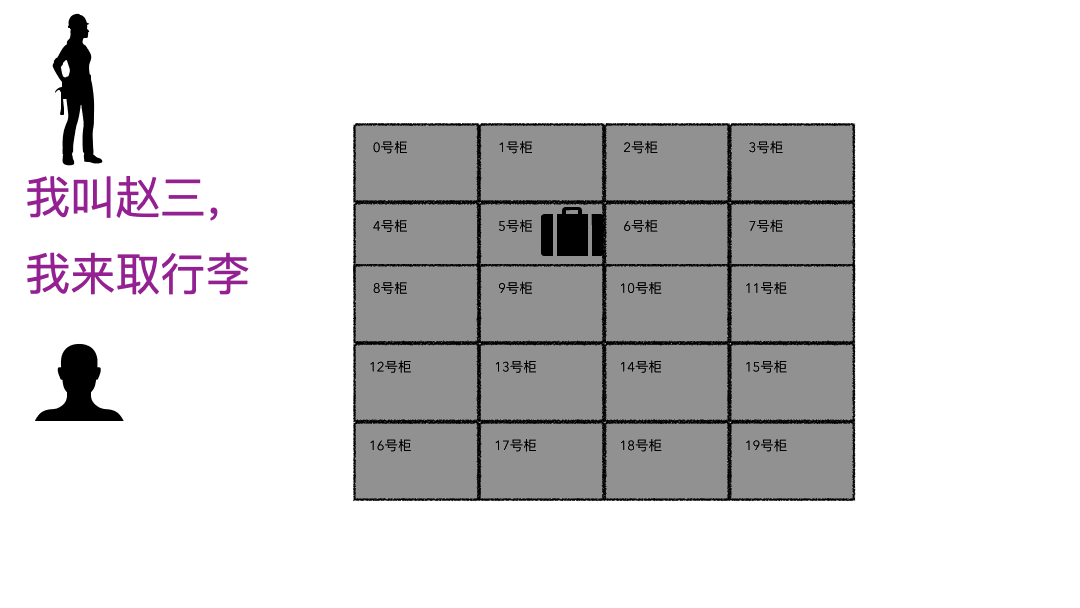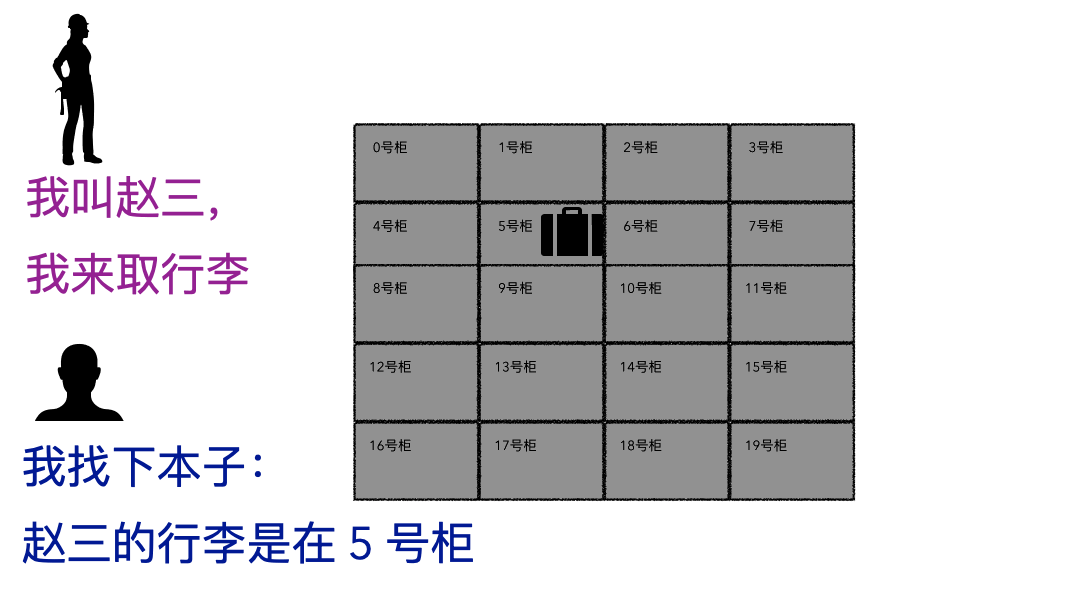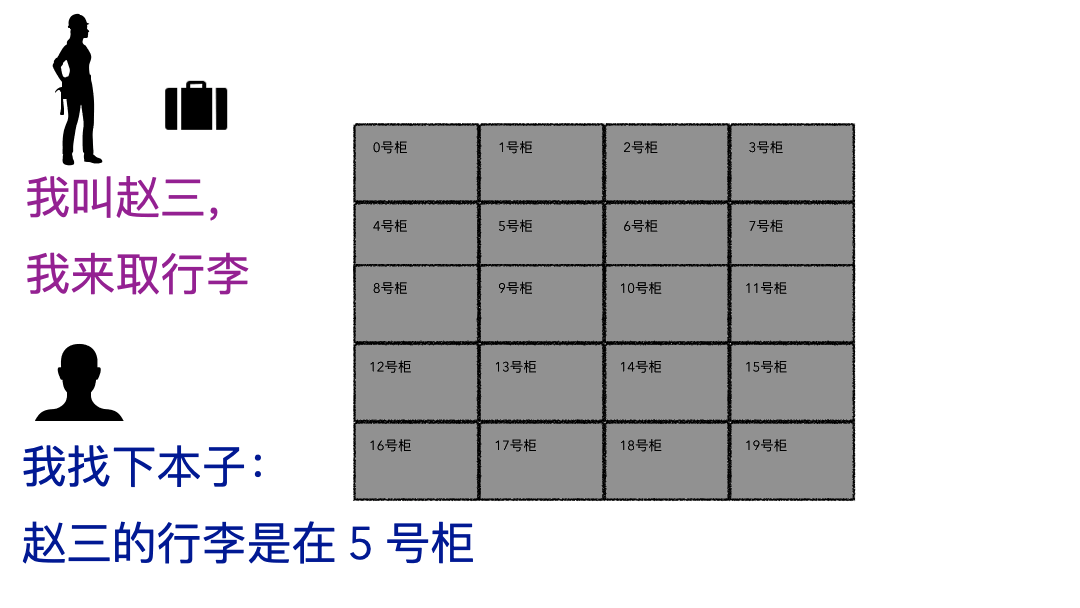
取行李的時候,要報自己名字,有牌子的給他牌子,然后工作人員才能去特定的位置找到你的行李。
①文件系統
登記名字就是在文件系統記錄文件名
生成的牌子就是元數據索引
你的行李就是文件
寄存室就是磁盤(容納東西的物理空間)
管理員整套運行機制就是文件系統
②空間管理
直觀的一個想法,我把進來的數據就完整的放進去。

對,思路完全正確。改進的方式就是切分,把空間按照一定粒度切分。每個小粒度的物理塊命名為 Block,每個 Block 一般是 4K 大小,用戶數據存到文件系統里來自然也是要切分,存儲到磁盤上各個角落。
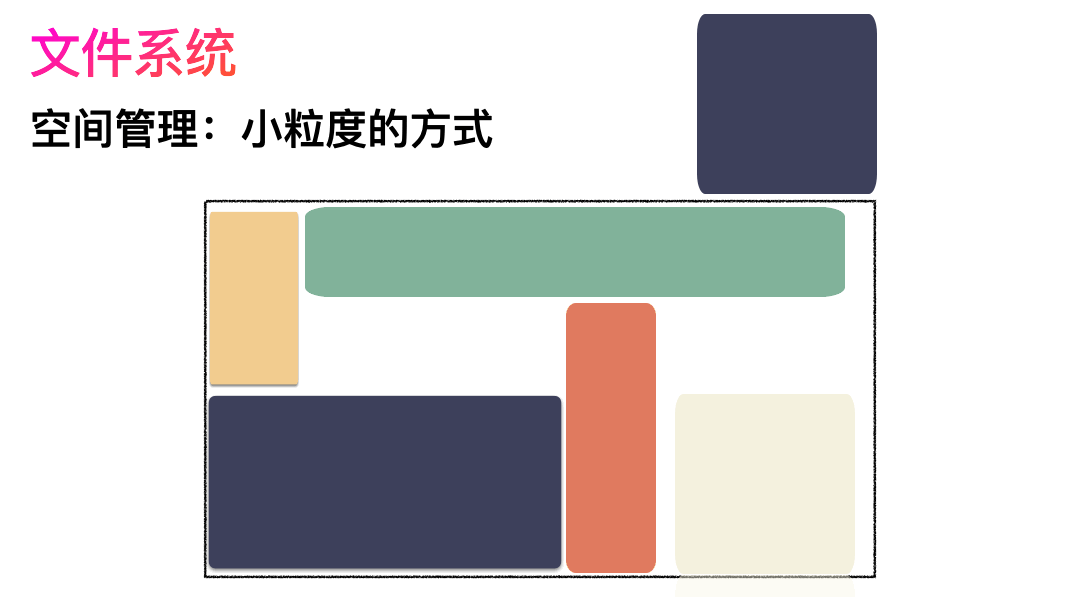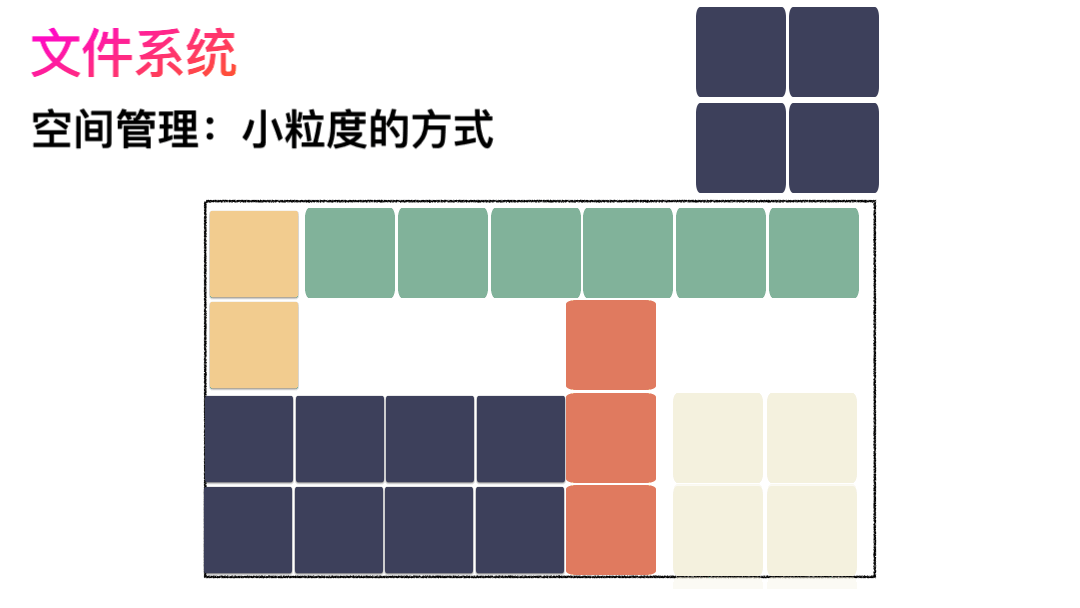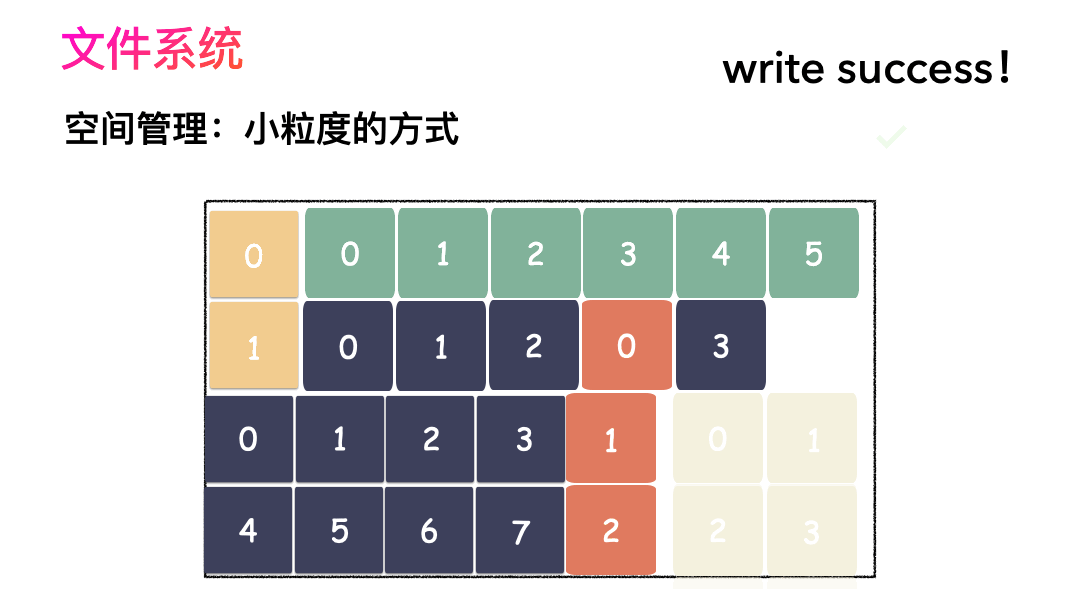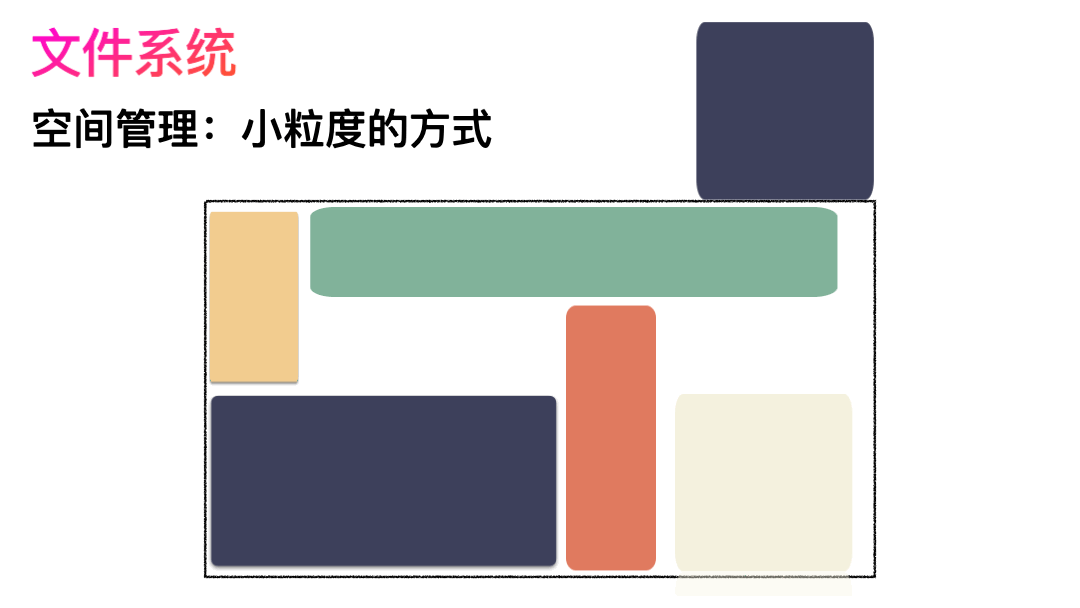
先寫數據:數據先按照 Block 粒度存儲到磁盤的各個位置。
再寫元數據:然后把 Block 所在的各個位置保存起來,即 inode(我用一本書來表示)。
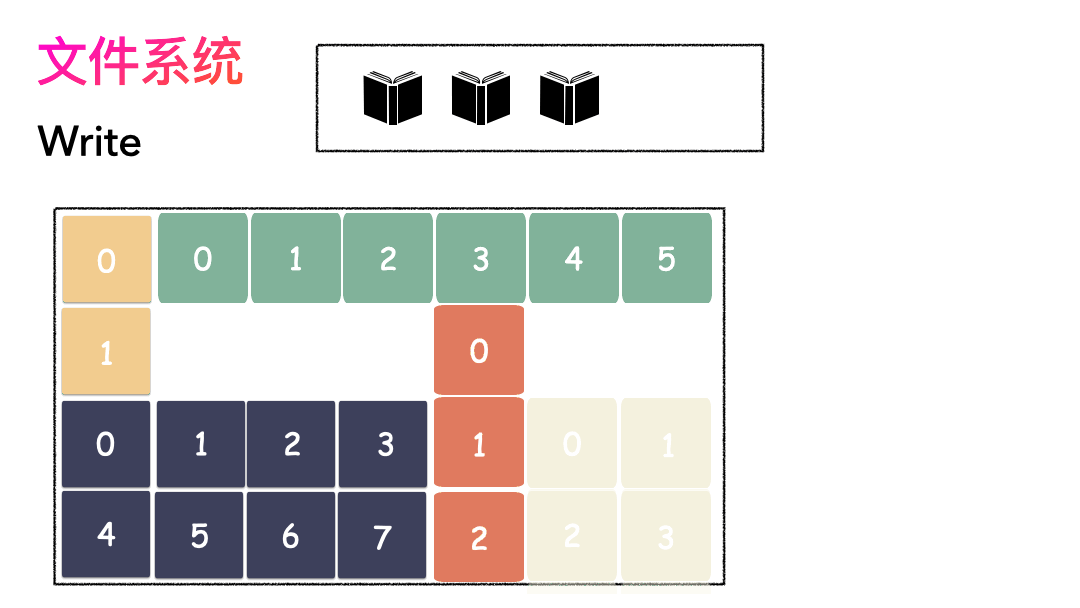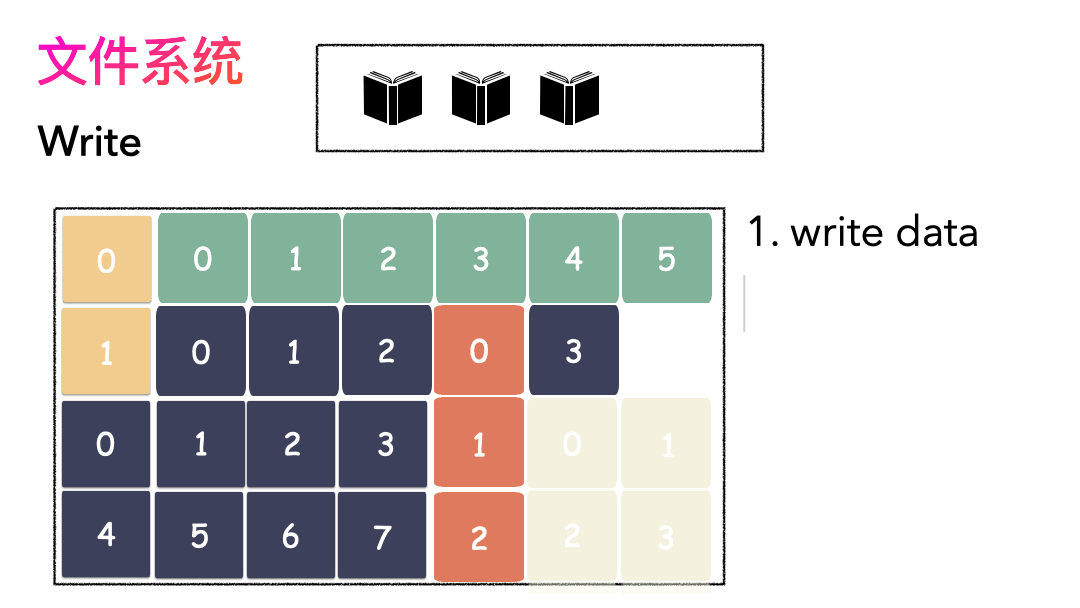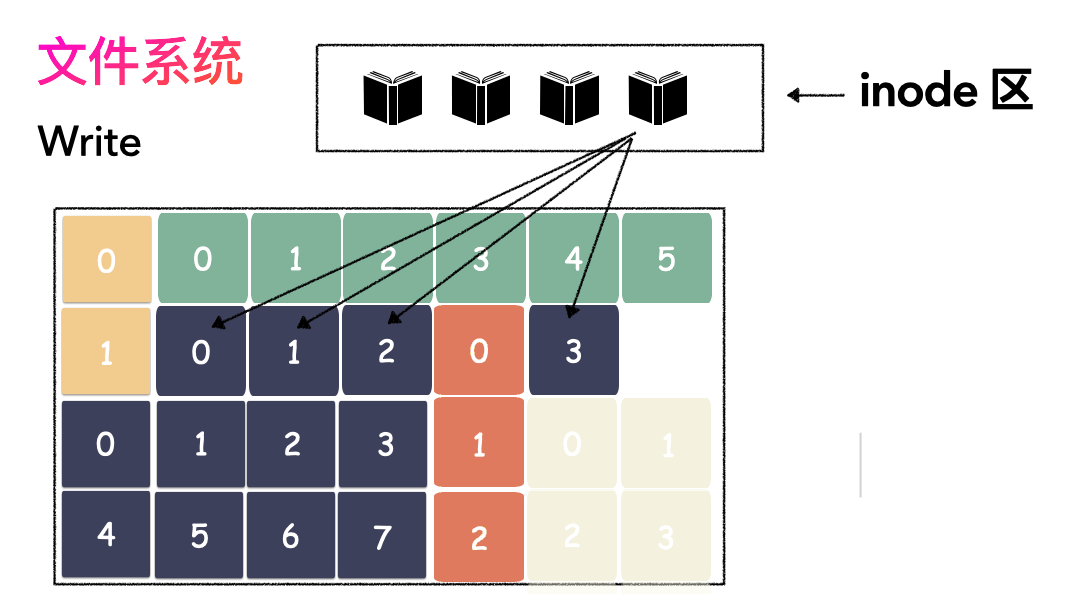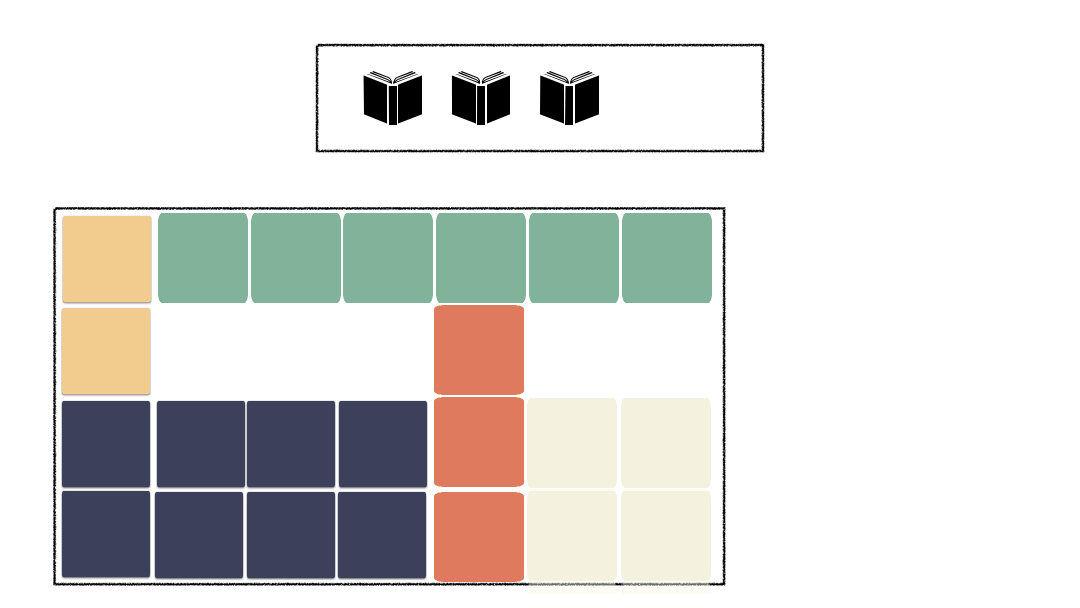
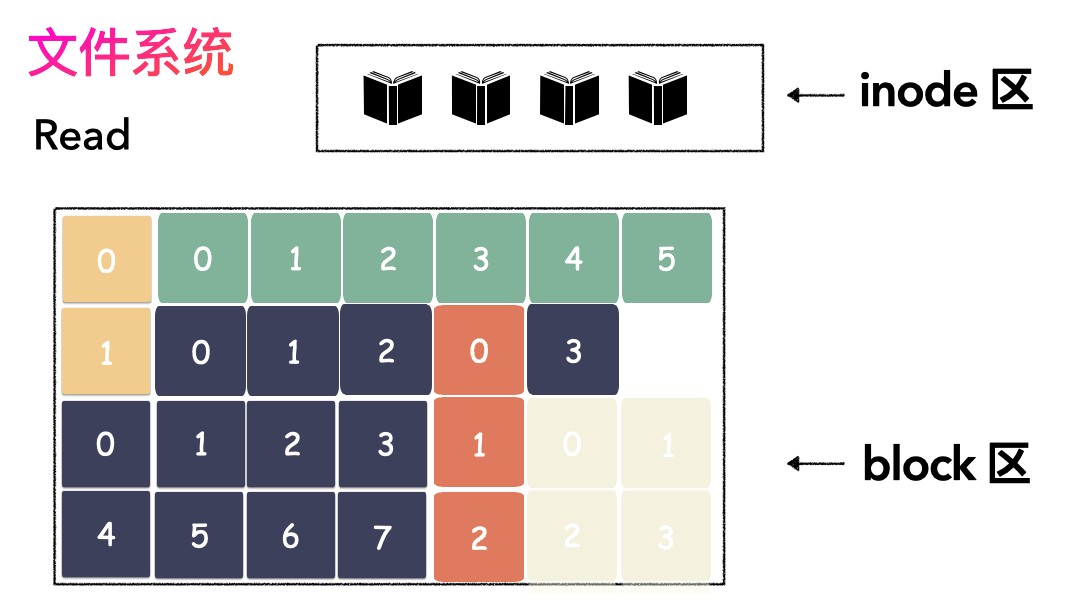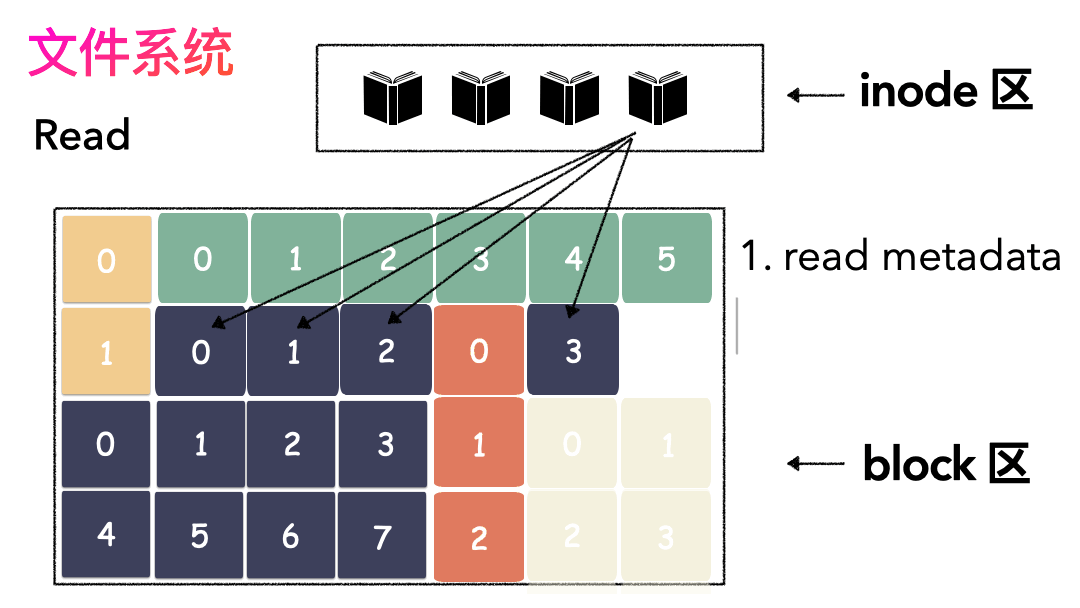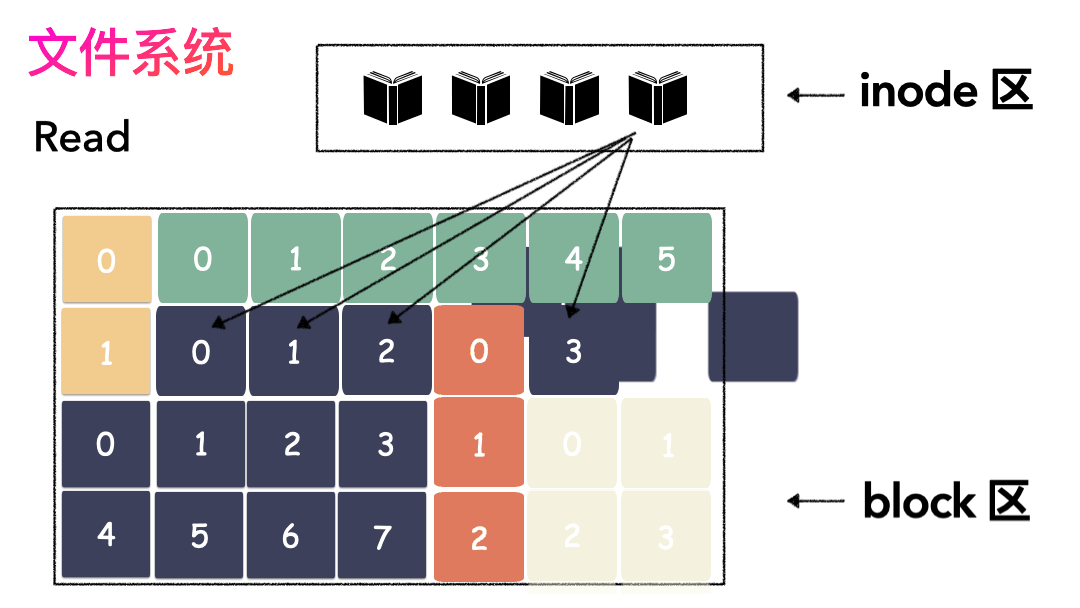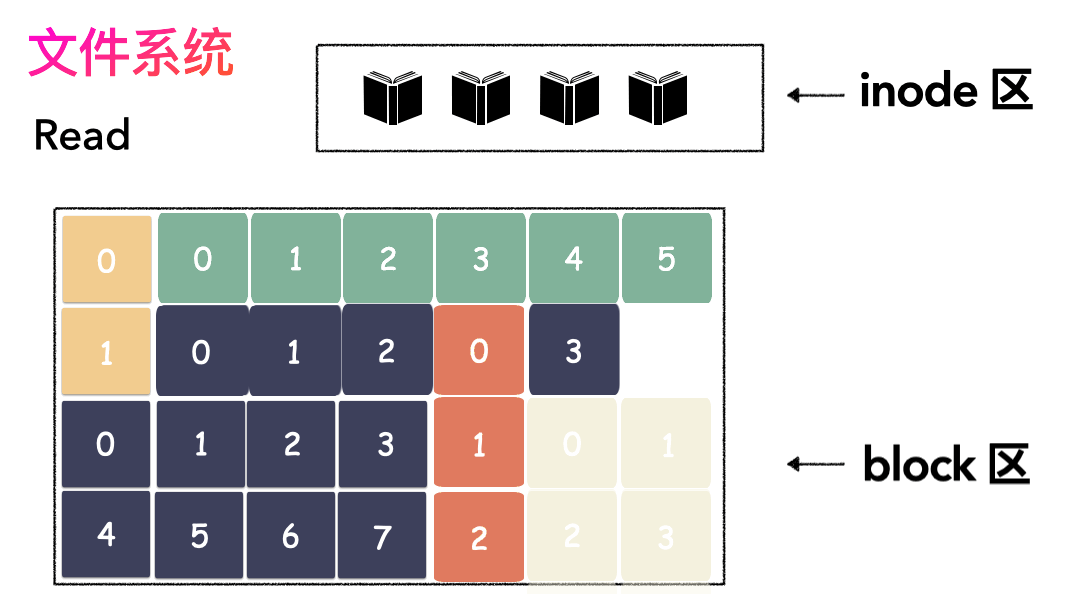
先讀 inode,找到各個 Block 的位置。
然后讀數據,構造一個完整的文件,給到用戶。
inode/block 概念
好,我們現在來看看 inode,直觀地感受一下:
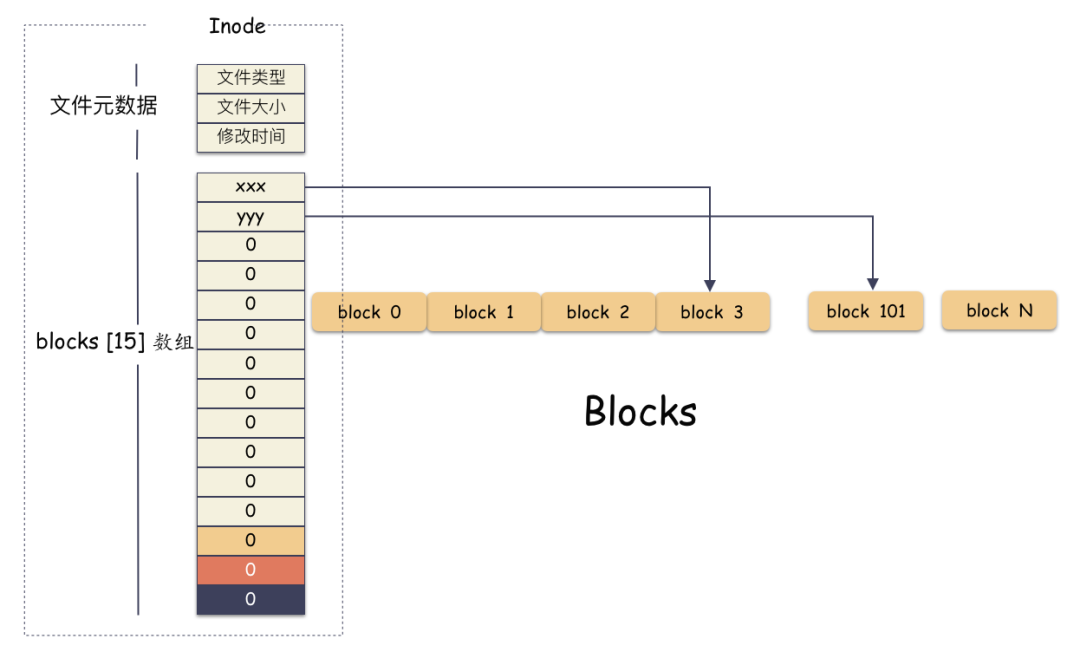
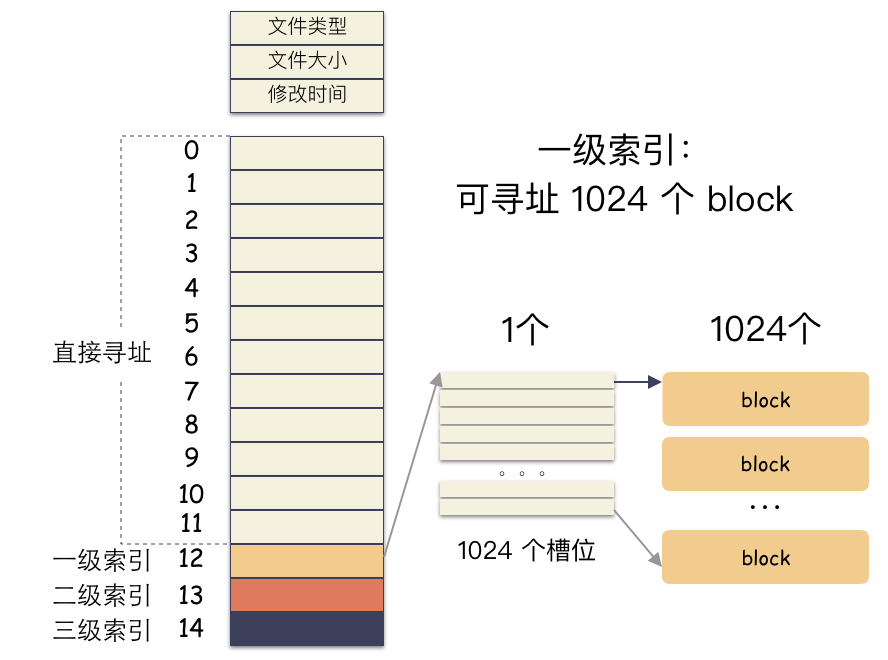
前 12 個槽位(也就是 0 - 11 )我們成為直接索引
第 13 個位置,我們稱為?1 級索引
第 14 個位置,我們稱為?2 級索引
第 15 個位置,我們稱為?3 級索引

一個 block ?4K,每個元素 4 字節(jié),也就是有 1024 個編號位置可以存儲。所以,一級索引能尋址 4M(1024 * 4K)空間 。
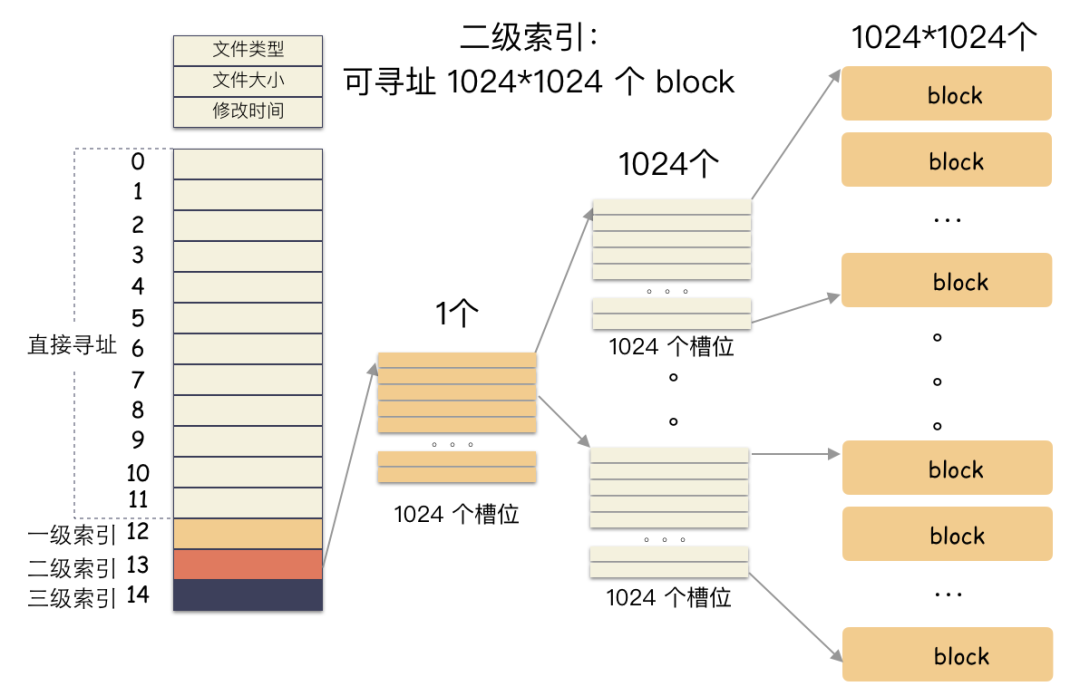
三級索引:三級索引是在二級索引的基礎上又多了一級,也就是說,有了 4G 的空間來存儲用戶數據的 block 編號。所以二級索引能尋址 4T (4G/4 * 4K) 的空間。

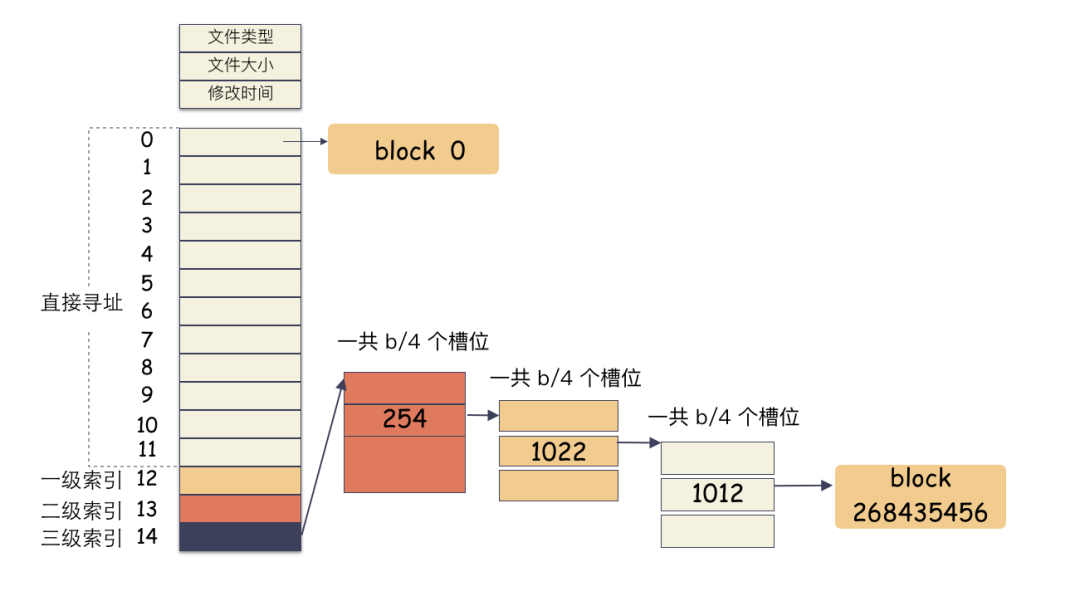
為什么 cp 那么快?接下來我們要寫入一個奇怪的文件,這個文件很大,但是真正的數據只有 8K:
在 [0,4K] 這位置有 4K 的數據
在 [1T , 1T+4K] 處也有 4K 數據
創(chuàng)建一個文件,這個時候分配一個 inode。
在 [ 0,4K ] 的位置寫入 4K 數據,這個時候只需要 一個 block,把這個編號寫到 block[0]?這個位置保存起來。
在 [ 1T,1T+4K ] 的位置寫入 4K 數據,這個時候需要分配一個 block,因為這個位置已經落到三級索引才能表現的空間了,所以需要還需要分配出 3 個索引塊。。
寫入完成,close 文件。
實際存儲如圖:
首先,最關鍵的是把磁盤空間切成離散的、定長的 block 來管理。
然后,通過 inode 能查找到所有離散的數據(保存了所有的索引)。
最后,實現索引塊和數據塊空間的后分配。
后記
后臺回復?學習資料?領取學習視頻