
一文讀懂 AlphaTensor 論文
前言
這篇文章的主要內(nèi)容是,解讀 AlphaTensor 這篇論文的主要思想,如何通過強(qiáng)化學(xué)習(xí)來探索發(fā)現(xiàn)更高效的矩陣乘算法。
1、二進(jìn)制加法和乘法
這一節(jié)簡(jiǎn)單介紹一下計(jì)算機(jī)是怎么實(shí)現(xiàn)加法和乘法的。
以 2 + 5 和 2 * 5 為例。
我們知道數(shù)字在計(jì)算機(jī)中是以二進(jìn)制形式表示的。
整數(shù)2的二進(jìn)制表示為:0010
整數(shù)5的二進(jìn)制表示為:0101
1.1、二進(jìn)制加法
二進(jìn)制加法很簡(jiǎn)單,也就是兩個(gè)二進(jìn)制數(shù)按位相加,如下圖所示:

當(dāng)然具體到硬件實(shí)現(xiàn)其實(shí)是包含了異或運(yùn)算和與運(yùn)算,具體細(xì)節(jié)可以閱讀文末參考的資料。
1.2、二進(jìn)制乘法
二進(jìn)制乘法其實(shí)也是通過二進(jìn)制加法來實(shí)現(xiàn)的,如下圖所示:
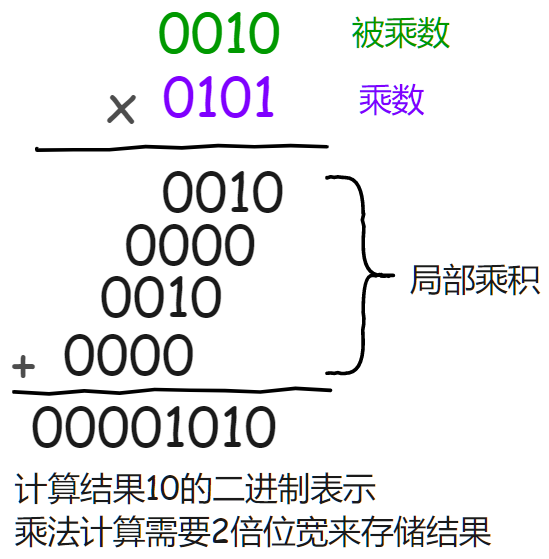
乘法在硬件上的實(shí)現(xiàn)本質(zhì)是移位相加。
對(duì)于二進(jìn)制數(shù)來說乘數(shù)和被乘數(shù)的每一位非0即1。
所以相當(dāng)于乘數(shù)中的每一位從低位到高位,分別和被乘數(shù)的每一位進(jìn)行與運(yùn)算并產(chǎn)生其相應(yīng)的局部乘積,再將這些局部乘積左移一位與上次的和相加。
從乘數(shù)的最低位開始:
若為1,則復(fù)制被乘數(shù),并左移一位與上一次的和相加;
若為0,則直接將0左移一位與上一次的和相加;
如此循環(huán)至乘數(shù)的最高位。
從二進(jìn)制乘法的實(shí)現(xiàn)也可以看出來,加法比乘法操作要快。
1.3、用加法替換乘法的簡(jiǎn)單例子
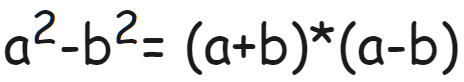
上面這個(gè)公式相信大家都很熟悉了,式子兩邊是等價(jià)的
左邊包含了2次乘法和1次加法(減法也可以看成加法)
右邊則包含了1次乘法和2次加法
可以看到通過數(shù)學(xué)上的等價(jià)變換,增加了加法的次數(shù)同時(shí)減少了乘法的次數(shù)。
2、矩陣乘算法
對(duì)于兩個(gè)大小分別為 Q x R 和 R x P 的矩陣相乘,通用的實(shí)現(xiàn)就需要 Q * P * R 次乘法操作(輸出矩陣大小 Q x P,總共 Q * P 個(gè)元素,每個(gè)元素計(jì)算需要 R 次乘法操作)。
根據(jù)前面 1.2內(nèi)容可知,乘法比加法慢,所以如果能減少的乘法次數(shù)就能有效加速矩陣乘的運(yùn)算。
2.1、通用矩陣乘算法
首先來看一下通用的矩陣乘算法:
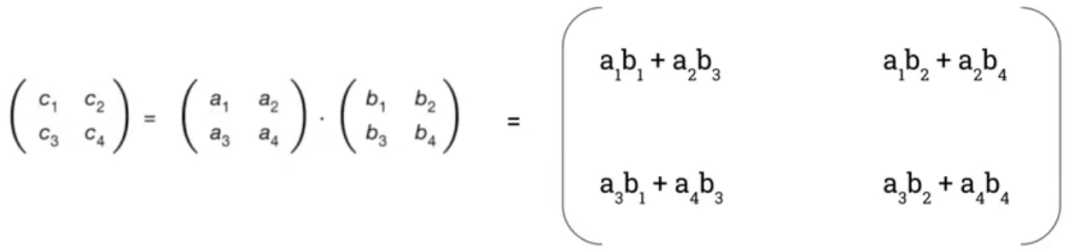
如上圖所示,兩個(gè)大小為2x2矩陣做乘法,總共需要8次乘法和4次加法。
2.2、Strassen 矩陣乘算法
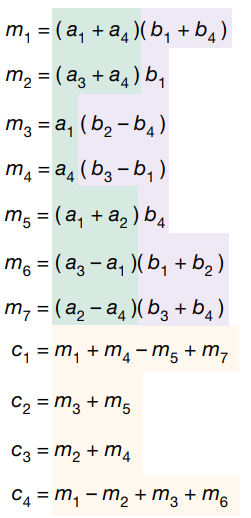
上圖所示即為 Strassen 矩陣乘算法,和通用矩陣乘算法不一樣的地方是,引入了7個(gè)中間變量 m,只有在計(jì)算這7個(gè)中間變量才會(huì)用到乘法。
簡(jiǎn)單用 c1 驗(yàn)證一下:
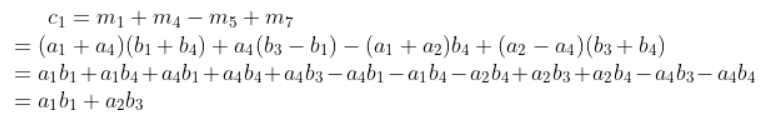
可以看到 Strassen 算法總共包含7次乘法和18次加法,通過數(shù)學(xué)上的等價(jià)變換減少了1次乘法同時(shí)增加了14次加法。
3、AlphaTensor 核心思想解讀
3.1、將矩陣乘表示為3維張量
首先來看下論文中的一張圖
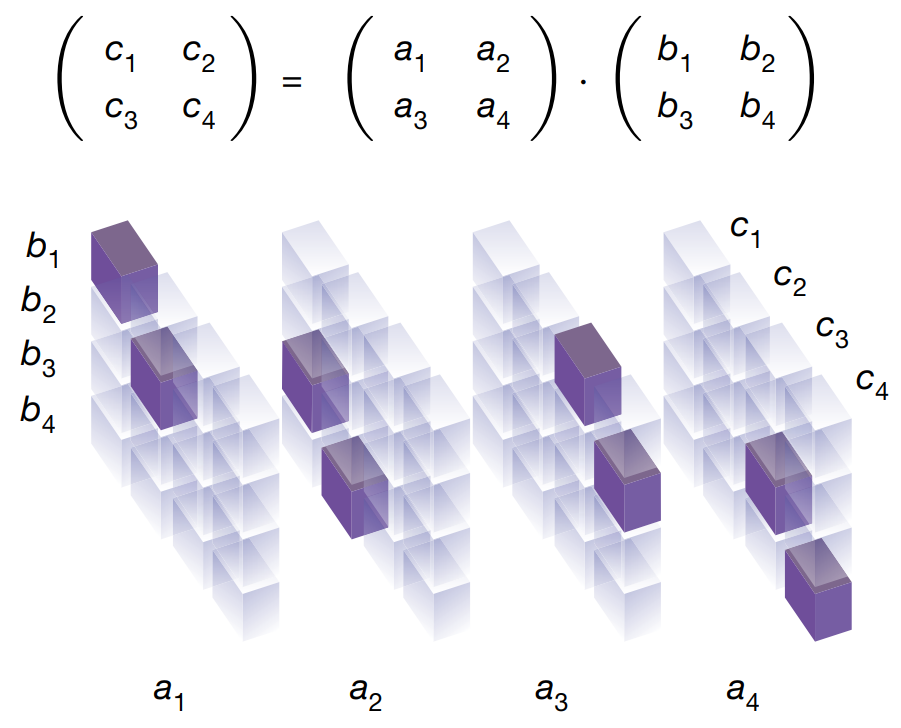
圖中下方是3維張量,每個(gè)立方體表示3維張量一個(gè)坐標(biāo)點(diǎn)。
其中張量每個(gè)位置的值只能是 0 或者 1,透明的立方體表示 0,紫色的立方體表示 1。
現(xiàn)在將圖簡(jiǎn)化一下,以[a,b,c]這樣的維度順序,將張量以維度a平攤開,這樣更容易理解:
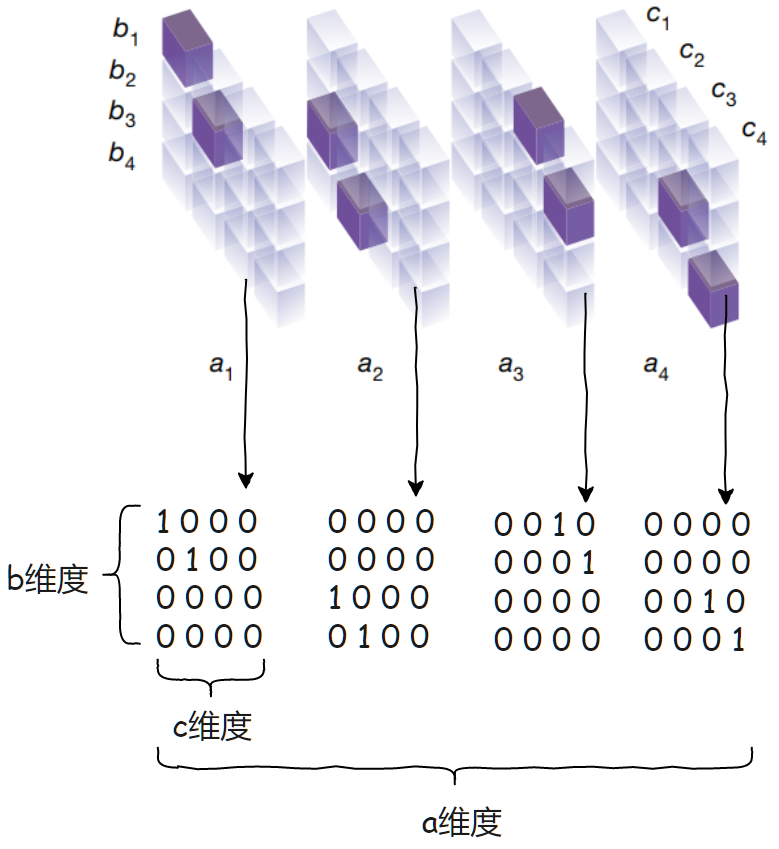
這個(gè)3維張量怎么理解呢?
比如對(duì)于 c1,我們知道 c1 的計(jì)算需要用到 a1,a2,b1,b3,對(duì)應(yīng)到3維張量就是:

而從上圖可知,對(duì)于兩個(gè) 2 x 2 的矩陣相乘,3維張量大小為 4 x 4 x 4。
一般的,對(duì)于兩個(gè) n x n 的矩陣相乘,3維張量大小為 n^2 x n^2 x n^2。
更一般的,對(duì)于兩個(gè) n x m 和 m x p 的矩陣相乘,3維張量大小為 n*m x m*p x n*p。
然后論文中為了簡(jiǎn)化理解,都是以 n x n 矩陣乘來講解的,論文中以
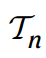
表示 n x n 矩陣乘的3維張量,下文中為了方便寫作以 Tn 來表示。
3.2、3維張量分解
然后論文中提出了一個(gè)假設(shè):
如果能將3維張量 Tn 分解為 R 個(gè)秩1的3維張量(R rank-one terms)的和的話,那么對(duì)于任意的 n x n 矩陣乘計(jì)算就只需要 R 次乘法。
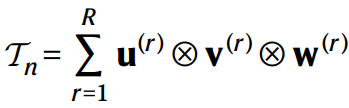
如上圖公式所示,就是表示的這個(gè)分解,其中的
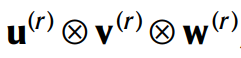
就表示的一個(gè)秩1的3維張量,是由 u^(r) 、 v^(r) 和 w^(r) 這3個(gè)一維向量做外積得到的。
這具體怎么什么理解呢?我們回去看一下 Strassen 矩陣乘算法:
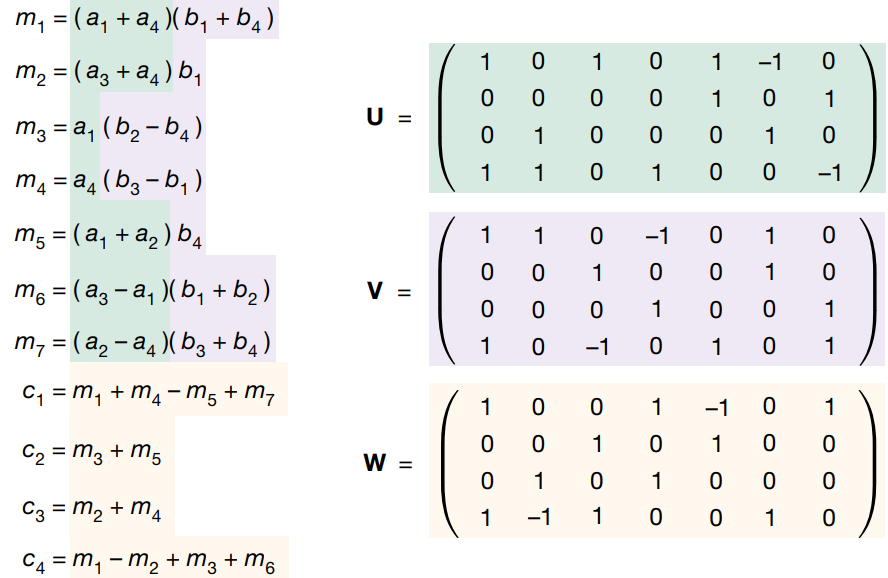
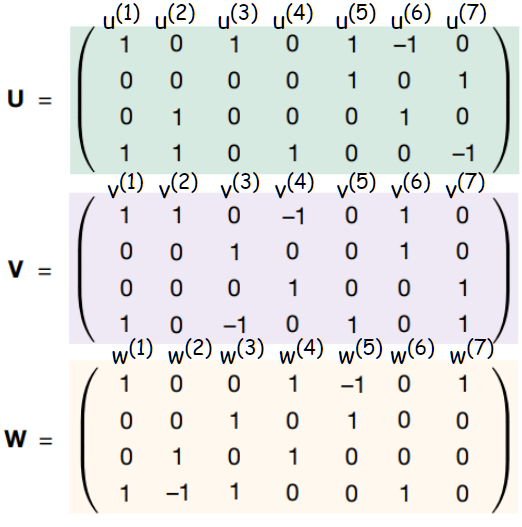
上圖左邊就是 Strassen 矩陣乘算法的計(jì)算過程,右邊的 U,V 和 W 3個(gè)矩陣,各自分別對(duì)應(yīng)左邊 U -> a, V -> b 和 W -> m。
具體又怎么理解這三個(gè)矩陣呢?
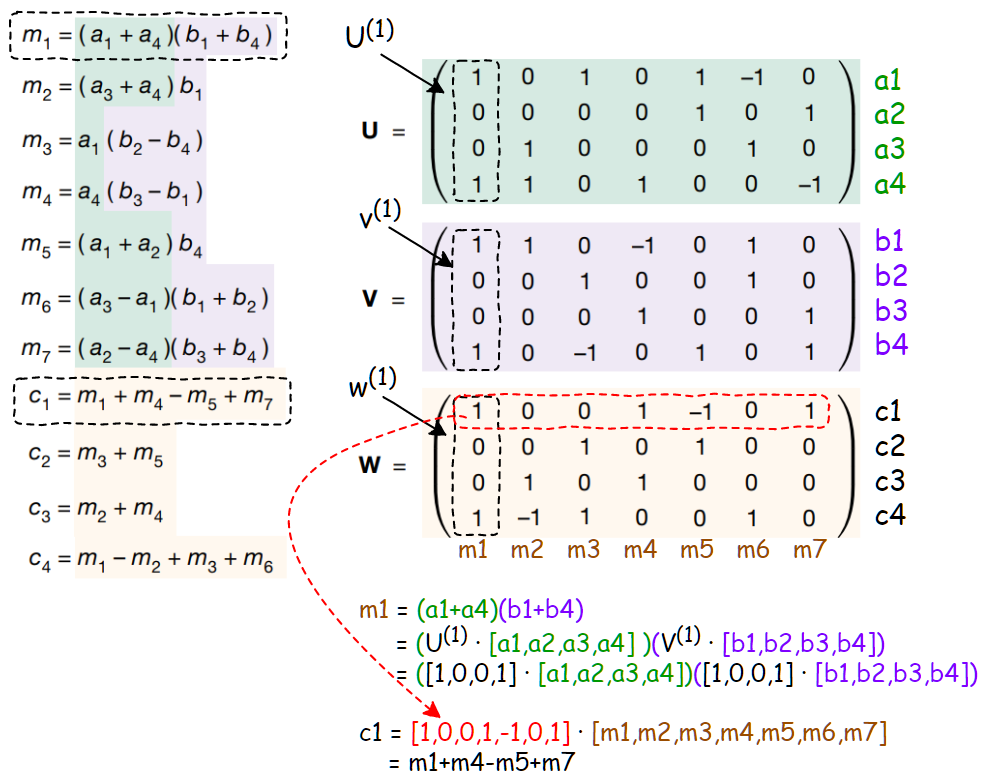
我們?cè)趫D上加一些標(biāo)注來解釋,其中 U , V 和 W 矩陣每一列從左到右按順序,就對(duì)應(yīng)上文提到的,u^(r) 、 v^(r) 和 w^(r) 這3個(gè)一維向量。
然后矩陣 U 每一列和 [a1,a2,a3,a4] 做內(nèi)積,矩陣 V 每一列和 [b1,b2,b3,b4] 做內(nèi)積,然后內(nèi)積結(jié)果相乘就得到 [m1,m2,m3,m4,m5,m6,m7]了。
最后矩陣 W 每一行和 [m1,m2,m3,m4,m5,m6,m7] 做內(nèi)積就得到 [c1,c2,c3,c4]。
接著再看一下的 U,V 和 W 這三個(gè)矩陣第一列的外積結(jié)果
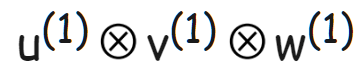
如下圖所示:
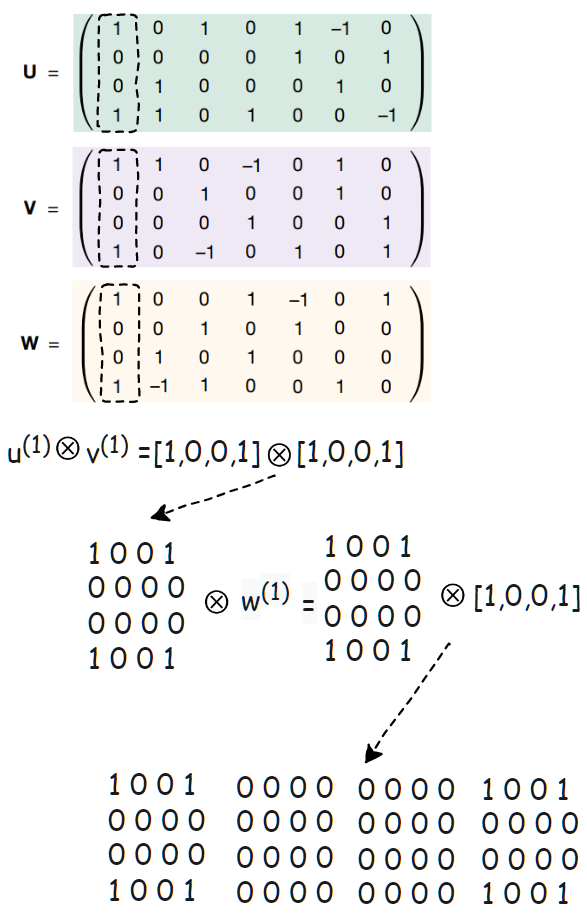
可以看到 U,V 和 W 三個(gè)矩陣每一列對(duì)應(yīng)的外積的結(jié)果就是一個(gè)3維張量,那么這些3維張量全部加起來就會(huì)得到 Tn 么?下面我們來驗(yàn)證一下:

可以看到這些外積的結(jié)果全部加起來就恰好等于 Tn:
所以也就證實(shí)了開頭的假設(shè):
如果能將表示矩陣乘的3維張量 Tn 分解為 R 個(gè)秩1的3維張量(R rank-one terms)的和,那么對(duì)于任意的 n x n 矩陣乘計(jì)算就只需要 R 次乘法。
因此也就很自然的可以想到,如果能找到更優(yōu)的張量分解,也就是讓 R 更小的話,那么就相當(dāng)于找到乘法次數(shù)更小的矩陣乘算法了。
通過強(qiáng)化學(xué)習(xí)探索更優(yōu)的3維張量分解
將探索3維張量分解過程變成游戲
論文中是采用了強(qiáng)化學(xué)習(xí)這個(gè)框架,來探索對(duì)3維張量Tn的更優(yōu)的分解。強(qiáng)化學(xué)習(xí)的環(huán)境是一個(gè)單玩家的游戲(a single-player game, TensorGame)。
首先定義這個(gè)游戲進(jìn)行 t 步之后的狀態(tài)為 St:
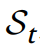
然后初始狀態(tài) S0 就設(shè)置為要分解的3維張量 Tn:
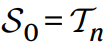
對(duì)于游戲中的每一步t,玩家(就是本論文提出的 AlphaTensor)會(huì)根據(jù)當(dāng)前的狀態(tài)選擇下一步的行動(dòng),也就是通過生成新的三個(gè)一維向量從而得到新的秩1張量:
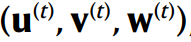
接著更新狀態(tài) St減去這個(gè)秩1張量:
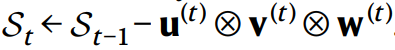
玩家的目標(biāo)就是,讓最終狀態(tài) St=0同時(shí)盡量的減少游戲的步數(shù)。
當(dāng)?shù)竭_(dá)最終狀態(tài) St=0 之后,也就找到了3維張量Tn的一個(gè)分解了:
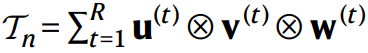
還有些細(xì)節(jié)是,對(duì)于玩家每一步的選擇都是給一個(gè) -1 的分?jǐn)?shù)獎(jiǎng)勵(lì),其實(shí)也很容易理解,也就是玩的步數(shù)越多,獎(jiǎng)勵(lì)越低,從而鼓勵(lì)玩家用更少的步數(shù)完成游戲。
而且對(duì)于一維向量的生成,也做了限制
就是生成這些一維向量的值,只限定在比如 [?2,??1,?0,?1,?2] 這5個(gè)離散值之內(nèi)。
AlphaTensor 簡(jiǎn)要解讀
論文中是怎么說的,在游戲過程中玩家 AlphaTensor 是通過一個(gè)深度神經(jīng)網(wǎng)絡(luò)來指導(dǎo)蒙特卡洛樹搜索(MonteCarlo tree search)。關(guān)于這個(gè)蒙特卡洛樹搜索,我不是很了解這里就不做解讀了,有興趣的讀者可以閱讀文末參考資料。
首先看下深渡神經(jīng)網(wǎng)絡(luò)部分:
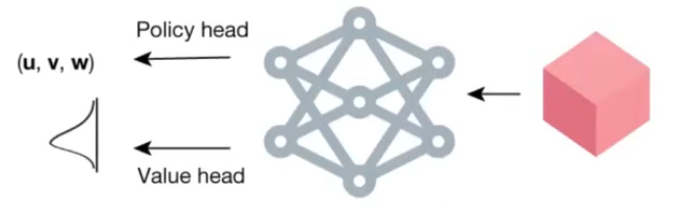
深度神經(jīng)網(wǎng)絡(luò)的輸入是當(dāng)前的狀態(tài) St也就是需要分解的張量(上圖中的最右邊的粉紅色立方體)。輸出包含兩個(gè)部分,分別是 Policy head 和 Value head。
其中 Policy head 的輸出是對(duì)于當(dāng)前狀態(tài)可以采取的潛在下一步行動(dòng),也就是一維向量(u(t),?v(t),?w(t)) 的候選分布,然后通過采樣得到下一步的行動(dòng)。
然后 Value head 應(yīng)該是對(duì)于給定的當(dāng)前的狀態(tài) St ,估計(jì)游戲完成之后的最終獎(jiǎng)勵(lì)分?jǐn)?shù)的分布。
接下來簡(jiǎn)要解讀一下整個(gè)游戲的流程,還有深度神經(jīng)網(wǎng)絡(luò)是如何訓(xùn)練的:
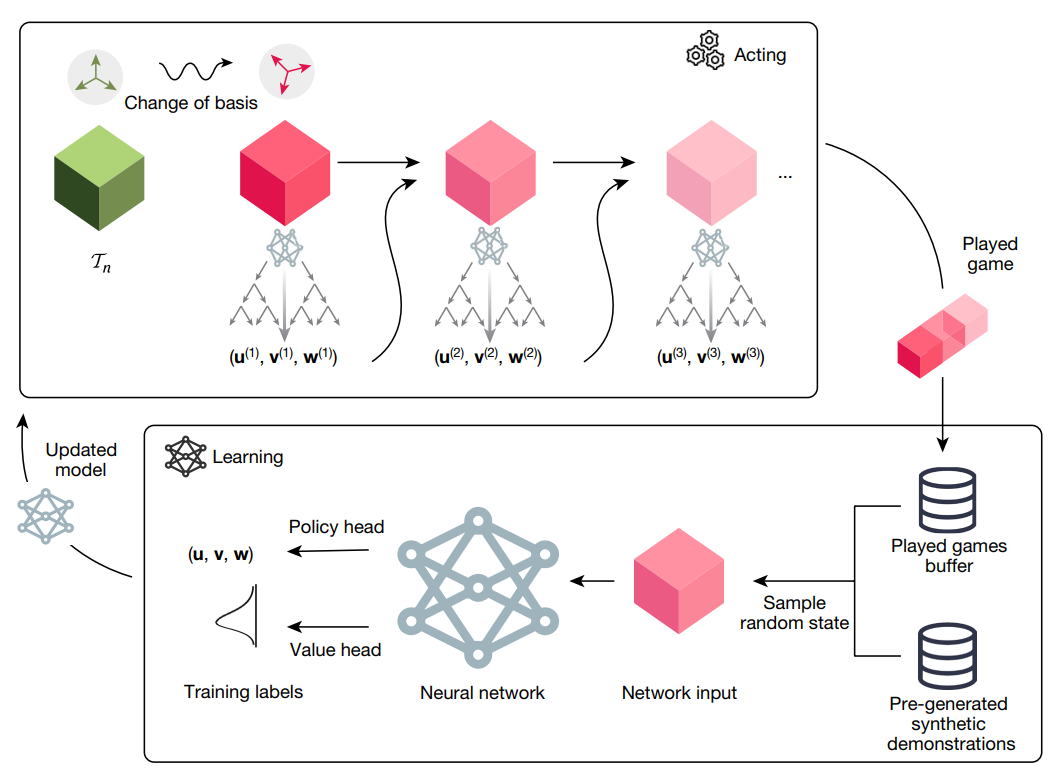
先看流程圖的上方 Acting 那個(gè)方框內(nèi),表示的是用訓(xùn)練好的網(wǎng)絡(luò)做推理玩游戲的過程。
可以看到最左邊綠色的立方體,也就是待分解的3維張量 Tn變換到粉紅色立方體,論文中提到是作了基的變換,但是這塊感覺如果不是去復(fù)現(xiàn)就不用了解的那么深入,而且我也沒去細(xì)看這塊就跳過吧。
然后從最初待分解的 Tn 開始,輸入到神經(jīng)網(wǎng)絡(luò),通過蒙特卡洛樹搜索得到秩1張量,然后減去該張量之后,繼續(xù)將相減的結(jié)果輸入到網(wǎng)路中,繼續(xù)這個(gè)過程直到張量相減的結(jié)果為0。
將游戲過程記錄下來,就是流程圖最右邊的 Played game。
然后流程圖下方的 Learning 方框表示的就是訓(xùn)練過程,訓(xùn)練數(shù)據(jù)有兩個(gè)部分,一個(gè)是已經(jīng)玩過的游戲記錄 Played games buffer 還有就是通過人工生成的數(shù)據(jù)。
人工怎么生成訓(xùn)練數(shù)據(jù)呢?
論文中提到,盡管張量分解是個(gè) NP-hard 的問題,給定一個(gè) Tn 要找其分解很難。但是我們可以反過來用秩1張量來構(gòu)造出一個(gè)待分解的張量嘛!簡(jiǎn)單來說就是采樣R個(gè)秩1張量,然后加起來就能的到分解的張量了。
因?yàn)閷?duì)于強(qiáng)化學(xué)習(xí)這塊我不是了解的并不深入,所以也就只能作粗淺的解讀。
實(shí)驗(yàn)結(jié)果
最后看一下實(shí)驗(yàn)結(jié)果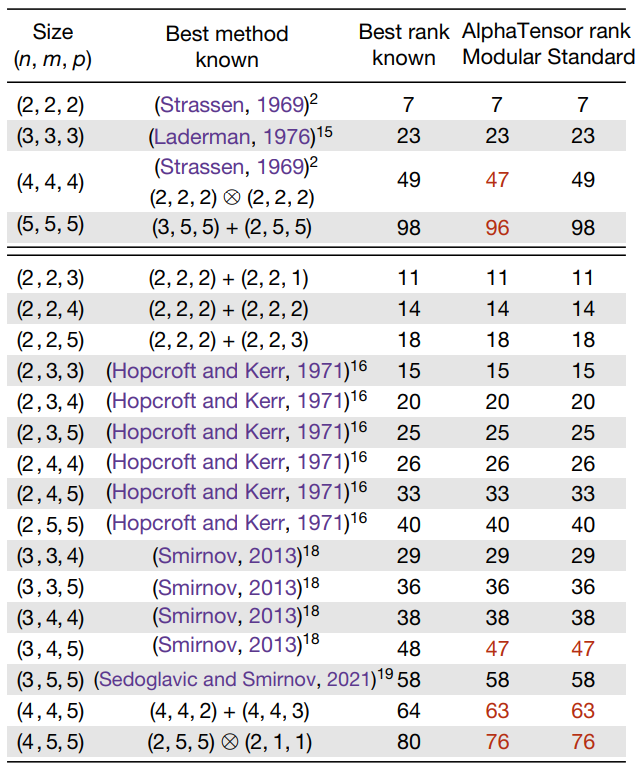
表格最左邊一列表示矩陣乘的規(guī)模,最右邊三列表示矩陣乘算法乘法次數(shù)。
第一列表示目前為止,數(shù)學(xué)家找到的最優(yōu)乘法次數(shù)。
第2和3列就是 AlphaTensor 找到的最優(yōu)乘法次數(shù)。
可以看到其中有5個(gè)規(guī)模,AlphaTensor 能找到更優(yōu)的乘法次數(shù)(標(biāo)紅的部分):
兩個(gè) 4 x 4 和 4 x 4 的矩陣乘,AlphaTensor 搜索出47次乘法;
兩個(gè) 5 x 5 和 5 x 5 的矩陣乘,AlphaTensor 搜索出96次乘法;
兩個(gè) 3 x 4 和 4 x 5 的矩陣乘,AlphaTensor 搜索出47次乘法;
兩個(gè) 4 x 4 和 4 x 5 的矩陣乘,AlphaTensor 搜索出63次乘法;
兩個(gè) 4 x 5 和 5 x 5 的矩陣乘,AlphaTensor 搜索出76次乘法;
參考資料
https://www.nature.com/articles/s41586-022-05172-4 https://www.youtube.com/watch?v=3N3Bl5AA5QU&ab_channel=YannicKilcher https://www.youtube.com/watch?v=gpYnDls4PdQ&ab_channel=HarvardMedicalAI%7CRajpurkarLab https://www.jobilize.com/course/section/hardware-for-addition-and-subtraction-by-openstax https://www.eet-china.com/mp/a94582.html https://baike.baidu.com/item/%E7%A1%AC%E4%BB%B6%E4%B9%98%E6%B3%95%E5%99%A8/4865151 https://blog.csdn.net/SunnyYoona/article/details/43570853 https://nikcheerla.github.io/deeplearningschool/2018/01/01/AlphaZero-Explained/ https://www.youtube.com/watch?v=hmQogtp6-fs&ab_channel=GauravSen https://www.youtube.com/watch?v=62nq4Zsn8vc&ab_channel=JoshVarty https://www.youtube.com/watch?v=J3I3WaJei_E&ab_channel=%E8%B5%B0%E6%AD%AA%E7%9A%84%E5%B7%A5%E7%A8%8B%E5%B8%ABJames