
Elasticsearch 生產(chǎn)環(huán)境集群部署最佳實(shí)踐
在生產(chǎn)環(huán)境搭建或維護(hù) Elasticsearch 集群和個(gè)人搭建集群的小打小鬧有非常大的不同。
本文的最佳實(shí)踐基于每天增量數(shù)億+ 的線上環(huán)境。
少啰嗦,上干貨。
1、內(nèi)存
Elasticsearch 和 Lucene 都是 Java 語言編寫,這意味著我們必須注意堆內(nèi)存的設(shè)置。
Elasticsearch 可用的堆越多,它可用于過濾器(filter)和其他緩存的內(nèi)存也就越多,更進(jìn)一步講可以提高查詢性能。
但請注意,過多的堆可能會(huì)使垃圾回收暫停時(shí)間過長。請勿將堆內(nèi)存的最大值設(shè)置為 JVM 用于壓縮對象指針(壓縮的 oops)的臨界值之上,確切的臨界值有所不同,但不要超過 32 GB。
推薦:干貨 | 吃透Elasticsearch 堆內(nèi)存
常見內(nèi)存配置坑 1:堆內(nèi)存設(shè)置過大
舉例:Elasticsearch 宿主機(jī):64 GB 內(nèi)存,堆內(nèi)存恨不得設(shè)置為 64 GB。
但,這忽略了堆的另一部分內(nèi)存使用大戶:OS 文件緩存。
Lucene 旨在利用底層操作系統(tǒng)來緩存內(nèi)存中的數(shù)據(jù)結(jié)構(gòu)。Lucene 段存儲(chǔ)在單獨(dú)的文件中。
由于段是不可變的(immutable),因此這些文件永遠(yuǎn)不會(huì)更改。這使它們非常易于緩存,并且底層操作系統(tǒng)很樂意將熱段駐留在內(nèi)存中,以加快訪問速度。
這些段包括倒排索引(用于全文搜索)和doc values 正排索引(用于聚合)。Lucene 的性能取決于與 OS 文件緩存的交互。
如果你將所有可用內(nèi)存分配給 Elasticsearch 的堆,則 OS 文件緩存將不會(huì)剩下任何可用空間。這會(huì)嚴(yán)重影響性能。
官方標(biāo)準(zhǔn)建議是:將 50% 的可用內(nèi)存(不超過 32 GB,一般建議最大設(shè)置為:31 GB)分配給 Elasticsearch 堆,而其余 50% 留給 Lucene 緩存。
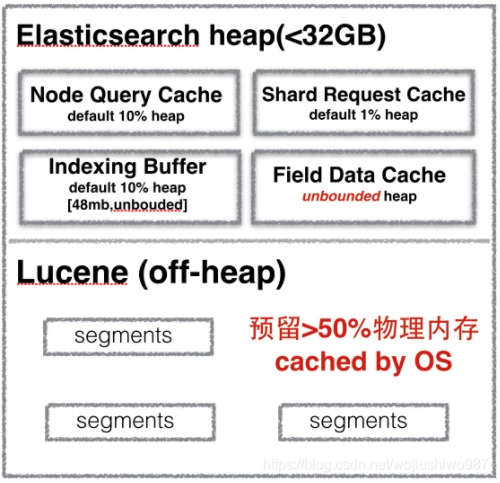
圖片來自網(wǎng)絡(luò)
可以通過以下方式配置 Elasticsearch 堆:
方式一:堆內(nèi)存配置文件 jvm.options
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms16g
-Xmx16g
方式二:啟動(dòng)參數(shù)設(shè)置
ES_JAVA_OPTS="-Xms10g -Xmx10g" ./bin/elasticsearch
2、CPU
運(yùn)行復(fù)雜的緩存查詢、密集寫入數(shù)據(jù)都需要大量的CPU,因此選擇正確的查詢類型以及漸進(jìn)的寫入策略至關(guān)重要。
一個(gè)節(jié)點(diǎn)使用多個(gè)線程池來管理內(nèi)存消耗。與線程池關(guān)聯(lián)的隊(duì)列使待處理的請求得以保留(類似緩沖效果)而不是被丟棄。
由于 Elasticsearch會(huì)做動(dòng)態(tài)分配,除非有非常具體的要求,否則不建議更改線程池和隊(duì)列大小。
線程池和隊(duì)列的設(shè)置,參見:
Elasticsearch 線程池和隊(duì)列問題,請先看這一篇。
推薦閱讀:
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-threadpool.html
3、分片數(shù)
分片是 Elasticsearch 在集群內(nèi)分發(fā)數(shù)據(jù)的單位。集群發(fā)生故障再恢復(fù)平衡的速度取決于分片的大小、分片數(shù)量、網(wǎng)絡(luò)以及磁盤性能。
在 Elasticsearch 中,每個(gè)查詢在每個(gè)分片的單個(gè)線程中執(zhí)行。但是,可以并行處理多個(gè)分片。針對同一分片的多個(gè)查詢和聚合也可以并行處理。
這意味著在不涉及緩存的情況下,最小查詢延遲將取決于數(shù)據(jù)、查詢類型以及分片的大小三個(gè)因素。
3.1 設(shè)置很多小分片 VS 設(shè)置很少大分片?
查詢很多小分片,導(dǎo)致每個(gè)分片能做到快速響應(yīng),但是由于需要按順序排隊(duì)和處理結(jié)果匯集。因此不一定比查詢少量的大分片快。
如果存在多個(gè)并發(fā)查詢,那么擁有大量小分片也會(huì)降低查詢吞吐量。
所以,就有了下面的分片數(shù)如何設(shè)定的問題?
3.2 分片數(shù)設(shè)定
選擇正確數(shù)量的分片是一個(gè)復(fù)雜問題,因?yàn)樵诩阂?guī)劃階段以及在數(shù)據(jù)寫入開始之前,一般不能確切知道文檔數(shù)。
對于集群而言,分片數(shù)多了以后,索引和分片管理可能會(huì)使主節(jié)點(diǎn)超載,并可能會(huì)導(dǎo)致集群無響應(yīng),甚至導(dǎo)致集群宕機(jī)。
建議:為主節(jié)點(diǎn)(Master 節(jié)點(diǎn))分配足夠的資源以應(yīng)對分片數(shù)過多可能導(dǎo)致的問題。
必須強(qiáng)調(diào)的是:主分片數(shù)是在索引創(chuàng)建時(shí)定義的,不支持借助 update API 實(shí)現(xiàn)類副本數(shù)更新的動(dòng)態(tài)修改。創(chuàng)建索引后,更改主分片數(shù)的唯一方法是重新創(chuàng)建索引,然后將原來索引數(shù)據(jù) reindex 到新索引。
官方給出的合理的建議:每個(gè)分片數(shù)據(jù)大小:30GB-50GB。
推薦1:Elasticsearch究竟要設(shè)置多少分片數(shù)?
https://elastic.blog.csdn.net/article/details/78080602
推薦2:Elasticsearch之如何合理分配索引分片
https://qbox.io/blog/optimizing-elasticsearch-how-many-shards-per-index
4、副本
Elasticsearch 通過副本實(shí)現(xiàn)集群的高可用性,數(shù)據(jù)在數(shù)據(jù)節(jié)點(diǎn)之間復(fù)制,以實(shí)現(xiàn)主分片數(shù)據(jù)的備份,因此即便部分節(jié)點(diǎn)因異常下線也不會(huì)導(dǎo)致數(shù)據(jù)丟失。
默認(rèn)情況下,副本數(shù)為 1,但可以根據(jù)產(chǎn)品高可用要求將其增加。副本越多,數(shù)據(jù)的容災(zāi)性越高。
副本多的另一個(gè)優(yōu)點(diǎn)是,每個(gè)節(jié)點(diǎn)都擁有一個(gè)副本分片,有助于提升查詢性能。
銘毅提醒:
實(shí)際副本數(shù)增多提高查詢性能建議結(jié)合集群做下測試,我實(shí)測過效果不明顯。
副本數(shù)增多意味著磁盤存儲(chǔ)要加倍,也考驗(yàn)硬盤空間和磁盤預(yù)算。
建議:根據(jù)業(yè)務(wù)實(shí)際綜合考慮設(shè)置副本數(shù)。普通業(yè)務(wù)場景(非精準(zhǔn)高可用)副本設(shè)置為 1 足夠了。
5、冷熱集群架構(gòu)配置
根據(jù)產(chǎn)品業(yè)務(wù)數(shù)據(jù)特定和需求,我們可以將數(shù)據(jù)分為熱數(shù)據(jù)和冷數(shù)據(jù),這是冷熱集群架構(gòu)的前提。
訪問頻率更高的索引可以分配更多更高配(如:SSD)的數(shù)據(jù)節(jié)點(diǎn),而訪問頻率較低的索引可以分配低配(如:機(jī)械磁盤)數(shù)據(jù)節(jié)點(diǎn)。
冷熱集群架構(gòu)對于存儲(chǔ)諸如應(yīng)用程序日志或互聯(lián)網(wǎng)實(shí)時(shí)采集數(shù)據(jù)(基于時(shí)間序列數(shù)據(jù))特別有用。
數(shù)據(jù)遷移策略:通過運(yùn)行定時(shí)任務(wù)來實(shí)現(xiàn)定期將索引移動(dòng)到不同類型的節(jié)點(diǎn)。
具體實(shí)現(xiàn):curator 工具或借助 ILM 索引生命周期管理。
5.1 熱節(jié)點(diǎn)
熱節(jié)點(diǎn)是一種特定類型的數(shù)據(jù)節(jié)點(diǎn),關(guān)聯(lián)索引數(shù)據(jù)是:最近、最新、最熱數(shù)據(jù)。
因?yàn)檫@些熱節(jié)點(diǎn)數(shù)據(jù)通常傾向于最頻繁地查詢。熱數(shù)據(jù)的操作會(huì)占用大量 CPU 和 IO 資源,因此對應(yīng)服務(wù)器需要功能強(qiáng)大(高配)并附加 SSD 存儲(chǔ)支持。
針對集群規(guī)模大的場景,建議:至少運(yùn)行 3 個(gè)熱節(jié)點(diǎn)以實(shí)現(xiàn)高可用性。
當(dāng)然,這也和你實(shí)際業(yè)務(wù)寫入和查詢的數(shù)據(jù)量有關(guān)系,如果數(shù)據(jù)量非常大,可能會(huì)需要增加熱節(jié)點(diǎn)數(shù)目。
5.2 冷節(jié)點(diǎn)(或稱暖節(jié)點(diǎn))
冷節(jié)點(diǎn)是對標(biāo)熱節(jié)點(diǎn)的一種數(shù)據(jù)節(jié)點(diǎn),旨在處理大量不太經(jīng)常查詢的只讀索引數(shù)據(jù)。
由于這些索引是只讀的,因此冷節(jié)點(diǎn)傾向于使用普通機(jī)械磁盤而非 SSD 磁盤。
與熱節(jié)點(diǎn)對標(biāo),也建議:最少 3 個(gè)冷節(jié)點(diǎn)以實(shí)現(xiàn)高可用性。
同樣需要注意的是,若集群規(guī)模非常大,可能需要更多節(jié)點(diǎn)才能滿足性能要求。
甚至需要更多類型,如:熱節(jié)點(diǎn)、暖節(jié)點(diǎn)、冷節(jié)點(diǎn)等。
強(qiáng)調(diào)一下:CPU 和 內(nèi)存的分配最終需要你通過使用與生產(chǎn)環(huán)境中類似的環(huán)境借助 esrally 性能測試工具測試確定,而不是直接參考各種最佳實(shí)踐拍腦袋而定。
有關(guān)熱節(jié)點(diǎn)和熱節(jié)點(diǎn)的更多詳細(xì)信息,請參見:
https://www.elastic.co/blog/hot-warm-architecture-in-elasticsearch-5-x
6、節(jié)點(diǎn)角色劃分
Elasticsearch 節(jié)點(diǎn)核心可分為三類:主節(jié)點(diǎn)、數(shù)據(jù)節(jié)點(diǎn)、協(xié)調(diào)節(jié)點(diǎn)。
6.1 主節(jié)點(diǎn)
主節(jié)點(diǎn):如果主節(jié)點(diǎn)是僅是候選主節(jié)點(diǎn),不含數(shù)據(jù)節(jié)點(diǎn)角色,則它配置要求沒有那么高,因?yàn)樗淮鎯?chǔ)任何索引數(shù)據(jù)。
如前所述,如果分片非常多,建議主節(jié)點(diǎn)要提高硬件配置。
主節(jié)點(diǎn)職責(zé):存儲(chǔ)集群狀態(tài)信息、分片分配管理等。
同時(shí)注意,Elasticsearch 應(yīng)該有多個(gè)候選主節(jié)點(diǎn),以避免腦裂問題。
6.2 數(shù)據(jù)節(jié)點(diǎn)
數(shù)據(jù)節(jié)點(diǎn)職責(zé):CURD、搜索以及聚合相關(guān)的操作。
這些操作一般都是IO、內(nèi)存、CPU 密集型。
6.3 協(xié)調(diào)節(jié)點(diǎn)
協(xié)調(diào)節(jié)點(diǎn)職責(zé):類似負(fù)載平衡器,主要工作是:將搜索任務(wù)分發(fā)到相關(guān)的數(shù)據(jù)節(jié)點(diǎn),并收集所有結(jié)果,然后再將它們匯總并返回給客戶端應(yīng)用程序。
6.4 節(jié)點(diǎn)配置參考
下表參見官方博客 PPT
| 角色 | 描述 | 存儲(chǔ) | 內(nèi)存 | 計(jì)算 | 網(wǎng)絡(luò) |
|---|---|---|---|---|---|
| 數(shù)據(jù)節(jié)點(diǎn) | 存儲(chǔ)和檢索數(shù)據(jù) | 極高 | 高 | 高 | 中 |
| 主節(jié)點(diǎn) | 管理集群狀態(tài) | 低 | 低 | 低 | 低 |
| Ingest | 節(jié)點(diǎn) 轉(zhuǎn)換輸入數(shù)據(jù) | 低 | 中 | 高 | 中 |
| 機(jī)器學(xué)習(xí)節(jié)點(diǎn) | 機(jī)器學(xué)習(xí) | 低 | 極高 | 極高 | 中 |
| 協(xié)調(diào)節(jié)點(diǎn) | 請求轉(zhuǎn)發(fā)和合并檢索結(jié)果 | 低 | 中 | 中 | 中 |
6.5 不同節(jié)點(diǎn)角色配置如下
必須配置到:elasticsearch.yml 中。
主節(jié)點(diǎn)
node.master:true
node.data:false
數(shù)據(jù)節(jié)點(diǎn)
node.master:false
node.data:true
協(xié)調(diào)節(jié)點(diǎn)
node.master:false
node.data:false
7、故障排除提示
Elasticsearch 的性能在很大程度上取決于宿主機(jī)資源情況。
CPU、內(nèi)存使用率和磁盤 IO 是每個(gè)Elasticsearch節(jié)點(diǎn)的基本指標(biāo)。
建議你在CPU使用率激增時(shí)查看Java虛擬機(jī)(JVM)指標(biāo)。
7.1 堆內(nèi)存使用率高
高堆內(nèi)存使用率壓力以兩種方式影響集群性能:
7.1.1 堆內(nèi)存壓力上升到75%及更高
剩余可用內(nèi)存更少,并且集群現(xiàn)在還需要花費(fèi)一些 CPU 資源以通過垃圾回收來回收內(nèi)存。
在啟用垃圾收集時(shí),這些 CPU 周期不可用于處理用戶請求。結(jié)果,隨著系統(tǒng)變得越來越受資源約束,用戶請求的響應(yīng)時(shí)間增加。
7.1.2 堆內(nèi)存壓力繼續(xù)上升并達(dá)到接近100%
將使用更具侵略性的垃圾收集形式,這將反過來極大地影響集群響應(yīng)時(shí)間。
索引響應(yīng)時(shí)間度量標(biāo)準(zhǔn)表明,高堆內(nèi)存壓力會(huì)嚴(yán)重影響性能。
7.2 非堆內(nèi)存使用率增長
JVM 外非堆內(nèi)存的增長,吞噬了用于頁面緩存的內(nèi)存,并可能導(dǎo)致內(nèi)核級(jí)OOM。
7.3 監(jiān)控磁盤IO
由于Elasticsearch大量使用存儲(chǔ)設(shè)備,磁盤 IO 的監(jiān)視是所有其他優(yōu)化的基礎(chǔ),發(fā)現(xiàn)磁盤 IO 問題并對相關(guān)業(yè)務(wù)操作做調(diào)整可以避免潛在的問題。
應(yīng)根據(jù)引起磁盤 IO 的情況評(píng)估對策,常見優(yōu)化磁盤 IO 實(shí)戰(zhàn)策略如下:
優(yōu)化分片數(shù)量及其大小 段合并策略優(yōu)化 更換普通磁盤為SSD磁盤 添加更多節(jié)點(diǎn)
7.5 合理設(shè)置預(yù)警
對于依賴搜索的應(yīng)用程序,用戶體驗(yàn)與搜索請求的等待時(shí)間長短相關(guān)。
有許多因素會(huì)影響查詢性能,例如:
構(gòu)造查詢方式不合理 Elasticsearch 集群配置不合理 JVM 內(nèi)存和垃圾回收問題 磁盤 IO 等
查詢延遲是直接影響用戶體驗(yàn)的指標(biāo),因此請確保在其上放置一些預(yù)警操作。
舉例:線上實(shí)戰(zhàn)問題:

如何避免? 以下兩個(gè)核心配置供參考:
PUT _cluster/settings
{
"transient": {
"search.default_search_timeout": "50s",
"search.allow_expensive_queries": false
}
}
需要強(qiáng)調(diào)的是:"search.allow_expensive_queries" 是 7.7+ 版本才有的功能,早期版本會(huì)報(bào)錯(cuò)。
推薦閱讀:
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-wildcard-query.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-your-data.html
7.6 合理配置緩存
默認(rèn)情況下,Elasticsearch中的大多數(shù)過濾器都是高速緩存的。
這意味著在第一次執(zhí)行過濾查詢時(shí),Elasticsearch 將查找與過濾器匹配的文檔,并使用該信息構(gòu)建名為“bitset”的結(jié)構(gòu)。
存儲(chǔ)在 bitset 中的數(shù)據(jù)包含文檔標(biāo)識(shí)符以及給定文檔是否與過濾器匹配。
具有相同過濾器的查詢的后續(xù)執(zhí)行將重用存儲(chǔ)在bitset中的信息,從而通過節(jié)省 IO 操作和 CPU 周期來加快查詢的執(zhí)行速度。
建議在查詢中使用 filter 過濾器。
有關(guān)更多詳細(xì)信息,請參見:
7.7 合理設(shè)置刷新頻率
刷新頻率(refresh_interval)和段合并頻率與索引性能密切相關(guān),此外,它們還會(huì)影響整個(gè)集群的性能。
刷新頻率需要根據(jù)業(yè)務(wù)需要合理設(shè)置,尤其頻繁寫入的業(yè)務(wù)場景。
7.8 啟動(dòng)慢查詢?nèi)罩?/span>
啟用慢查詢?nèi)罩居涗泴⒂兄谧R(shí)別哪些查詢慢,以及可以采取哪些措施來改進(jìn)它們,這對于通配符查詢特別有用。
推薦:
7.9 增大ulimit大小
增加ulimit大小以允許最大文件數(shù),這屬于非常常規(guī)的設(shè)置。
在 /etc/profile 下設(shè)置:
ulimit -n 65535
7.10 合理設(shè)置交互內(nèi)存
當(dāng)操作系統(tǒng)決定換出未使用的應(yīng)用程序內(nèi)存時(shí),ElasticSearch 性能可能會(huì)受到影響。
通過 elasticsearch.yml 下配置:
bootstrap.mlockall: true
7.11 禁用通配符模糊匹配刪除索引
禁止通過通配符查詢刪除所有索引。
為確保某人不會(huì)對所有索引(* 或 _all)發(fā)出 DELETE 操作,設(shè)置如下:
PUT /_cluster/settings
{
"persistent": {
"action.destructive_requires_name": true
}
}
此時(shí)如果我們再使用通配符刪除索引,舉例執(zhí)行如下操作:
DELETE join_*
會(huì)報(bào)錯(cuò)如下:
{
"error" : {
"root_cause" : [
{
"type" : "illegal_argument_exception",
"reason" : "Wildcard expressions or all indices are not allowed"
}
],
"type" : "illegal_argument_exception",
"reason" : "Wildcard expressions or all indices are not allowed"
},
"status" : 400
}
8、常用指標(biāo)監(jiān)視 API
8.1 集群健康狀態(tài) API
GET _cluster/health?pretty
8.2 索引信息 API
GET _cat/indices?pretty&v
8.3 節(jié)點(diǎn)狀態(tài) API
GET _nodes?pretty
8.4 主節(jié)點(diǎn)信息 API
GET _cat/master?pretty&v
8.5 分片分配、索引信息統(tǒng)計(jì) API
GET _stats?pretty
8.6 節(jié)點(diǎn)狀態(tài)信息統(tǒng)計(jì) API
統(tǒng)計(jì)節(jié)點(diǎn)的jvm,http,io統(tǒng)計(jì)信息。
GET _nodes/stats?pretty
大多數(shù)系統(tǒng)監(jiān)視工具(如kibana、cerebro 等)都支持 Elasticsearc h的指標(biāo)聚合。
建議使用此類工具持續(xù)監(jiān)控集群狀態(tài)信息。
9、小結(jié)
ElasticSearch 具有很好的默認(rèn)配置以供新手快速上手、入門。但是,一旦到了線上業(yè)務(wù)實(shí)戰(zhàn)環(huán)境,就必須花費(fèi)一些時(shí)間來調(diào)整設(shè)置以滿足實(shí)際業(yè)務(wù)功能要求以及性能指標(biāo)要求。
建議你參考本文建議并結(jié)合官方文檔修改相關(guān)配置,以使得集群整體部署最優(yōu)。
加微信:elastic6,一起探討部署最佳實(shí)踐。
參考
https://medium.com/@abhidrona/elasticsearch-deployment-best-practices-d6c1323b25d7
https://t.zsxq.com/UVbQbee
推薦:
中國最大的 Elastic 非官方公眾號(hào)
點(diǎn)擊查看“閱讀原文”,更短時(shí)間更快習(xí)得更多干貨。和全球 1000 位+ Elastic 愛好者(含中國 50%+ Elastic 認(rèn)證工程師)一起每日精進(jìn) ELK 技能!