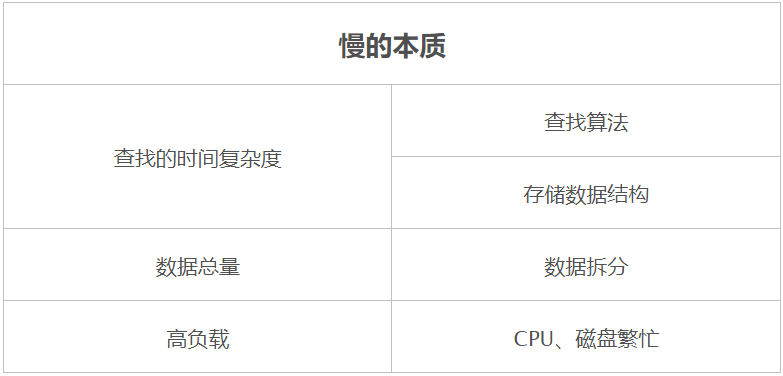
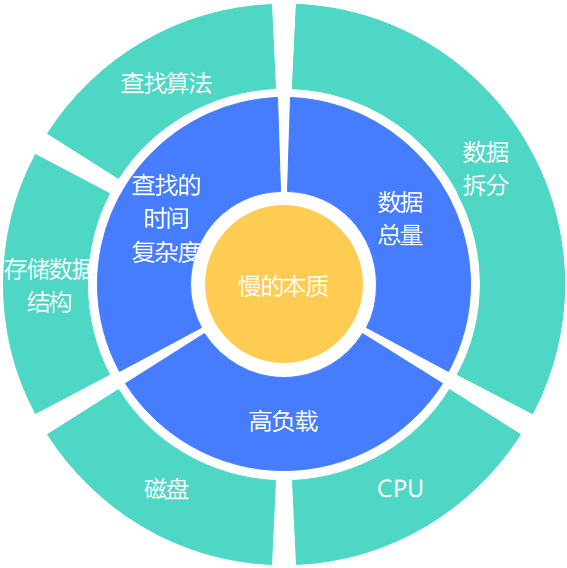
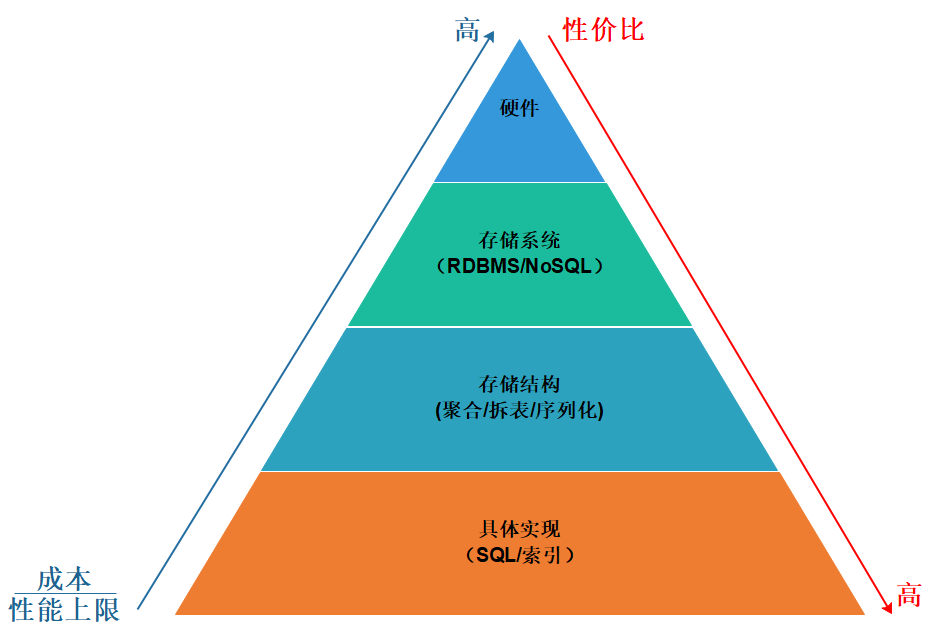
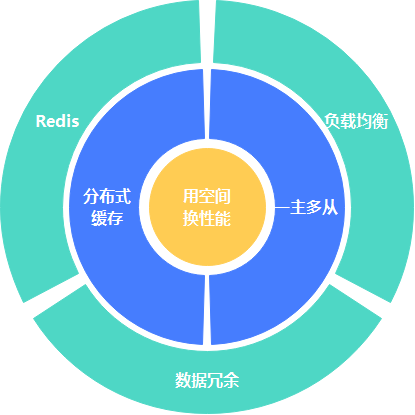
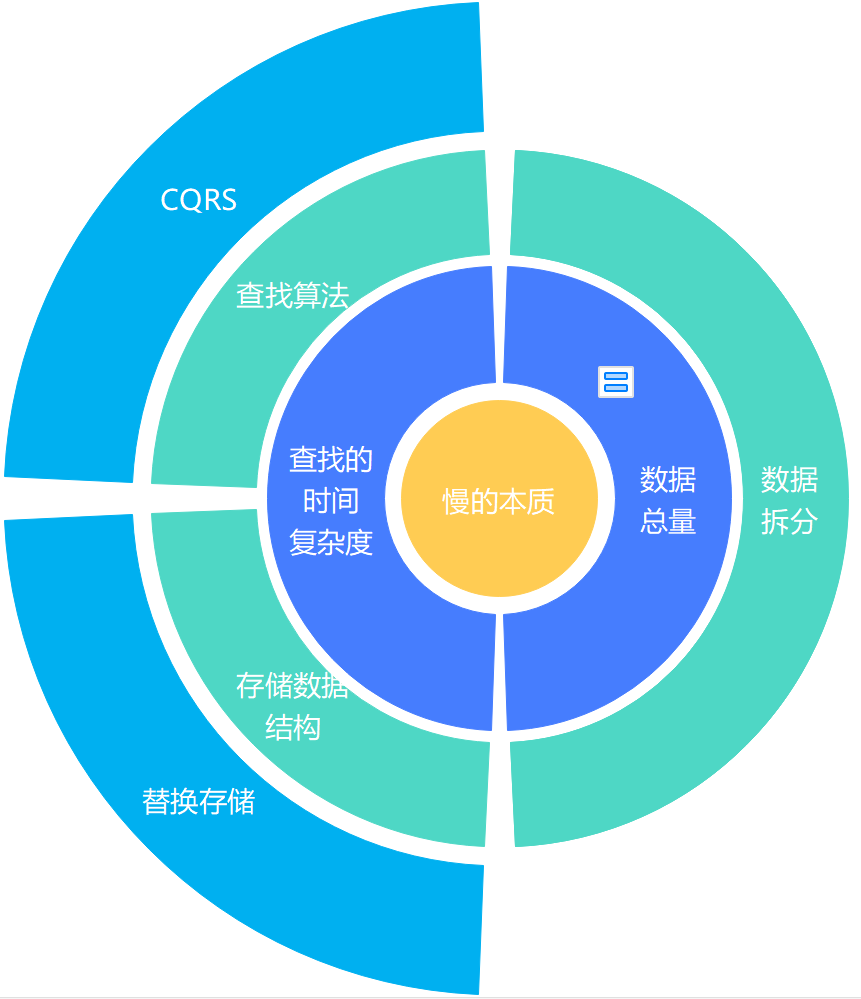
從上圖可見,自頂向下的一共有四層,分別是硬件、存儲(chǔ)系統(tǒng)、存儲(chǔ)結(jié)構(gòu)、具體實(shí)現(xiàn)。層與層之間是緊密聯(lián)系的,每一層的上層是該層的載體;因此越往頂層越能決定性能的上限,同時(shí)優(yōu)化的成本也相對會(huì)比較高,性價(jià)比也隨之越低。以最底層的具體實(shí)現(xiàn)為例,那么索引的優(yōu)化的成本應(yīng)該是最小的,可以說加了索引后無論是 CPU 消耗還是響應(yīng)時(shí)間都是立竿見影降低。然而一個(gè)簡單的語句,無論如何優(yōu)化加索引也是有局限的,當(dāng)在具體實(shí)現(xiàn)這層沒有任何優(yōu)化空間的時(shí)候就得往上一層【存儲(chǔ)結(jié)構(gòu)】思考,思考是否從物理表設(shè)計(jì)的層面出發(fā)優(yōu)化(如分庫分表、壓縮數(shù)據(jù)量等),如果是文檔型數(shù)據(jù)庫得思考下文檔聚合的結(jié)果。如果在存儲(chǔ)結(jié)構(gòu)這層優(yōu)化得沒效果,得繼續(xù)往再上一次進(jìn)行考慮,是否關(guān)系型數(shù)據(jù)庫應(yīng)該不適合用在現(xiàn)在得業(yè)務(wù)場景?如果要換存儲(chǔ),那么得換怎樣得 NoSQL?所以咱們優(yōu)化的思路,出于性價(jià)比的優(yōu)先考慮具體實(shí)現(xiàn),實(shí)在沒有優(yōu)化空間了再往上一層考慮。當(dāng)然如果公司有錢,直接使用鈔能力,繞過了前面三層,這也是一種便捷的應(yīng)急處理方式。該篇文章不討論頂與底的兩個(gè)層面的優(yōu)化,主要從存儲(chǔ)結(jié)構(gòu)、存儲(chǔ)系統(tǒng)中間兩層的角度出發(fā)進(jìn)行探討。
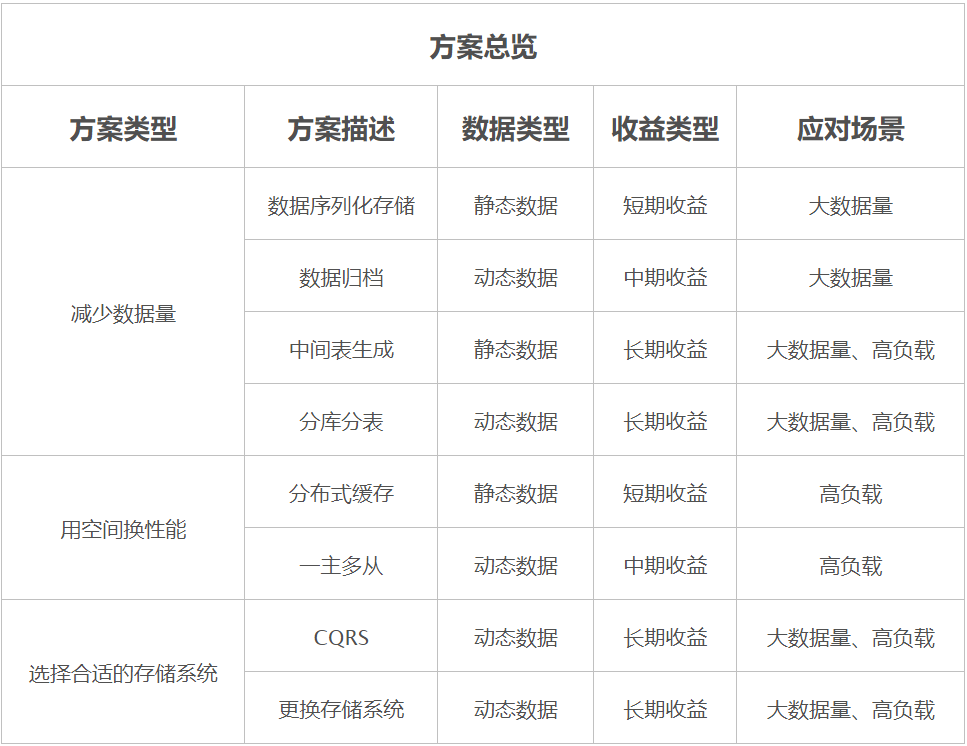
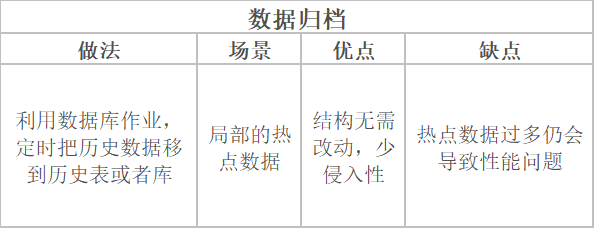
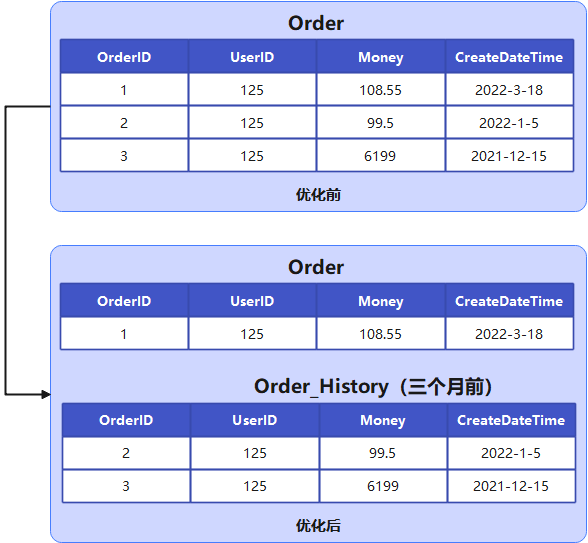
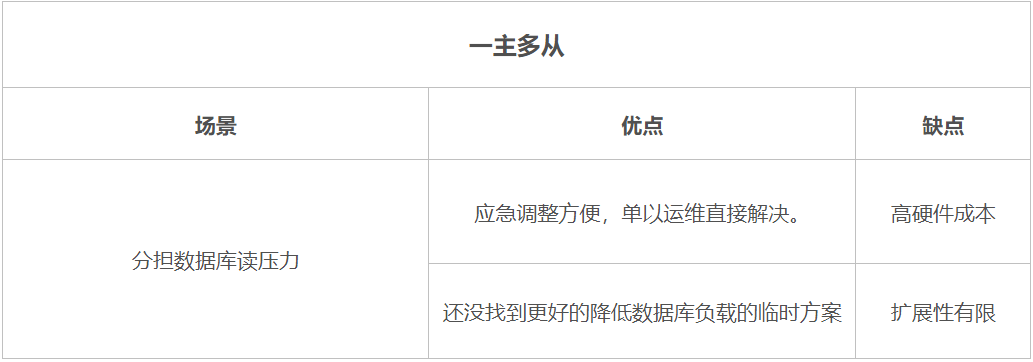
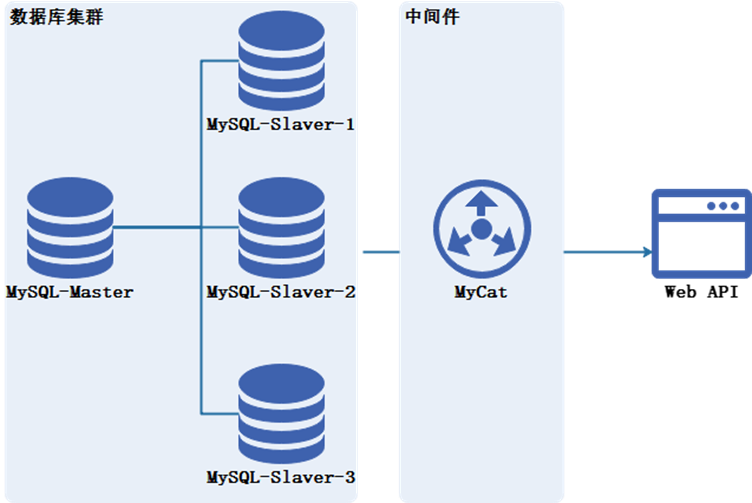
注意點(diǎn):別一次性遷移數(shù)量過多,建議低頻率多次限量遷移。像 MySQL 由于刪除數(shù)據(jù)后是不會(huì)釋放空間的,可以執(zhí)行命令 OPTIMIZE TABLE 釋放存儲(chǔ)空間,但是會(huì)鎖表,如果存儲(chǔ)空間還滿足,可以不執(zhí)行。建議優(yōu)先考慮該方案,主要通過數(shù)據(jù)庫作業(yè)把非熱點(diǎn)數(shù)據(jù)遷移到歷史表,如果需要查歷史數(shù)據(jù),可新增業(yè)務(wù)入口路由到對應(yīng)的歷史表(庫)。
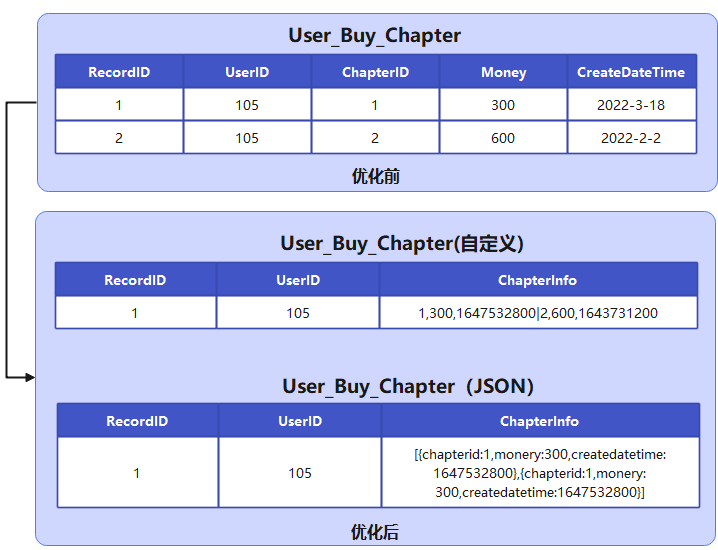
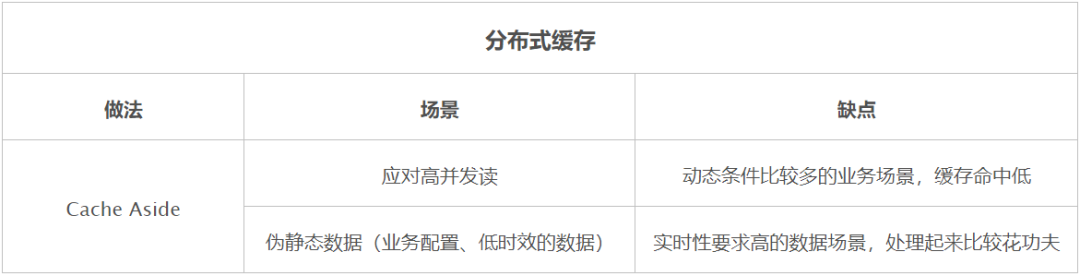
在數(shù)據(jù)庫以序列化存儲(chǔ)的方式,對于一些不需要結(jié)構(gòu)化存儲(chǔ)的業(yè)務(wù)來說是一種很好減少數(shù)據(jù)量的方式,特別是對于一些 M*N 的數(shù)據(jù)量的業(yè)務(wù)場景,如果以 M 作為主表優(yōu)化,那么就可以把數(shù)據(jù)量維持最多是 M 的量級。另外像訂單的地址信息,這種業(yè)務(wù)一般是不需要根據(jù)里面的字段檢索出來,也比較適合。這種方案我認(rèn)為屬于一種臨時(shí)性的優(yōu)化方案,無論是從序列化后丟失了部份字段的查詢能力,還是這方案的可優(yōu)化性都是有限的。
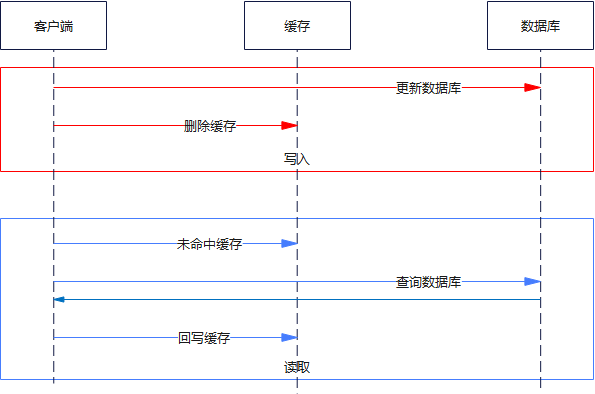
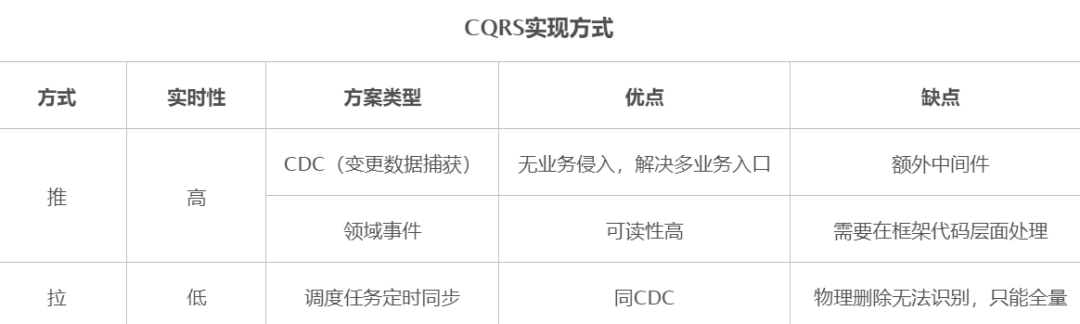
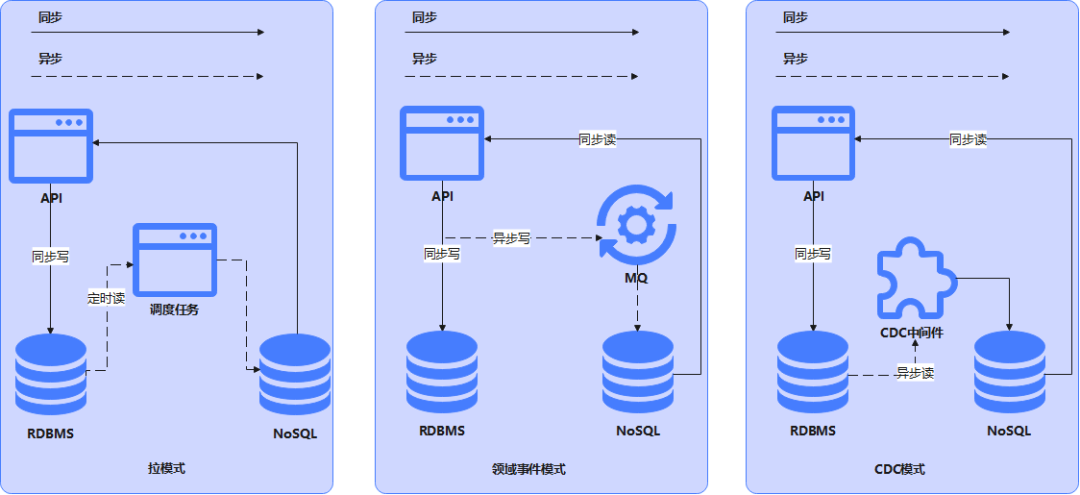
當(dāng)緩存沒有數(shù)據(jù),就得跑去數(shù)據(jù)庫查詢出來,這就是緩存穿透。假如某個(gè)時(shí)間臨界點(diǎn)數(shù)據(jù)是空的例如周排行榜,穿透過去的無論查找多少次數(shù)據(jù)庫仍然是空,而且該查詢消耗 CPU 相對比較高,并發(fā)一進(jìn)來因?yàn)槿鄙倭司彺鎸拥膶Ω卟l(fā)的應(yīng)對,這個(gè)時(shí)候就會(huì)因?yàn)椴l(fā)導(dǎo)致數(shù)據(jù)庫資源消耗過高,這就是緩存擊穿。數(shù)據(jù)庫資源消耗過高就會(huì)導(dǎo)致其他查詢超時(shí)等問題。該問題的解決方案也簡單,對于查詢到數(shù)據(jù)庫的空結(jié)果也緩存起來,但是給一個(gè)相對快過期的時(shí)間。有些同行可能又會(huì)問,這樣不就會(huì)造成了數(shù)據(jù)不一致了么?一般有數(shù)據(jù)同步的方案像分布式緩存、后續(xù)會(huì)說的一主多從、CQRS,只要存在數(shù)據(jù)同步這幾個(gè)字,那就意味著會(huì)存在數(shù)據(jù)一致性的問題,因此如果使用上述方案,對應(yīng)的業(yè)務(wù)場景應(yīng)允許容忍一定的數(shù)據(jù)不一致。