combine是聯(lián)合的意思,在Pandas中,combine()方法也是一種實(shí)現(xiàn)合并的方法,本文介紹combine()方法的用法。
一combine_first()實(shí)現(xiàn)合并
在介紹combine()方法前,先介紹比combine()更特殊的combine_first()方法。
combine_first(other): 對(duì)兩個(gè)DataFrame進(jìn)行聯(lián)合操作,實(shí)現(xiàn)合并的功能,other參數(shù)傳入被合并的DataFrame。
combine_first()方法根據(jù)DataFrame的行索引和列索引,對(duì)比兩個(gè)DataFrame中相同位置的數(shù)據(jù),優(yōu)先取非空的數(shù)據(jù)進(jìn)行合并。
如果調(diào)用combine_first()方法的df1中數(shù)據(jù)非空,則結(jié)果保留df1中的數(shù)據(jù),如果df1中的數(shù)據(jù)為空值且傳入combine_first()方法的df2中數(shù)據(jù)非空,則結(jié)果取df2中的數(shù)據(jù),如果df1和df2中的數(shù)據(jù)都為空值,則結(jié)果保留df1中的空值(空值有三種: np.nan、None 和 pd.NaT)。
即使兩個(gè)DataFrame的形狀不相同也不受影響,聯(lián)合時(shí)主要是根據(jù)索引來定位數(shù)據(jù)的位置。二combine()實(shí)現(xiàn)合并
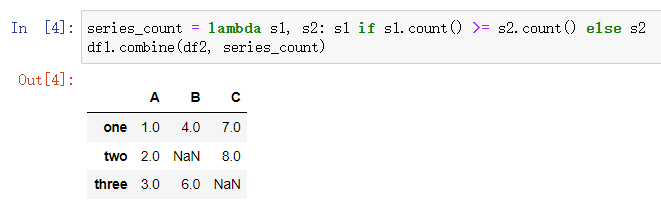
combine(other, func): 對(duì)兩個(gè)DataFrame進(jìn)行聯(lián)合操作,實(shí)現(xiàn)合并的功能。other參數(shù)傳入被合并的DataFrame,func參數(shù)傳入合并的規(guī)則函數(shù),兩個(gè)參數(shù)都是必傳參數(shù)。
func函數(shù)的入?yún)⑹莾蓚€(gè)Series,分別來自兩個(gè)DataFrame(將DataFrame按列遍歷),返回結(jié)果是一個(gè)合并之后的Series,在函數(shù)中實(shí)現(xiàn)合并的規(guī)則。
func可以是匿名函數(shù)、Python庫中定義好的函數(shù)、或自定義的函數(shù),要滿足兩個(gè)入?yún)⒁粋€(gè)返回值,且入?yún)⒑头祷刂凳菙?shù)組或Series。如上面的例子中,使用了匿名函數(shù),合并規(guī)則為返回兩個(gè)DataFrame中非空數(shù)據(jù)更多的列。原理如下圖。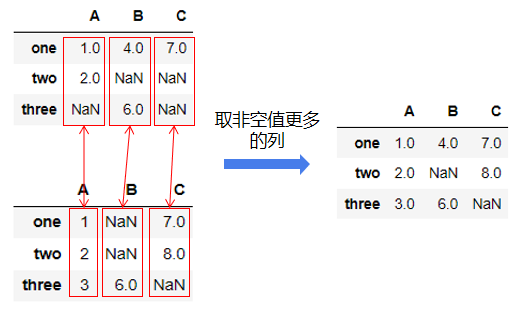
三調(diào)用已有函數(shù)和自定義函數(shù)
1. 調(diào)用numpy中的函數(shù)

fmax()是numpy中實(shí)現(xiàn)的函數(shù),用于比較兩個(gè)數(shù)組,返回一個(gè)新的數(shù)組。返回兩個(gè)數(shù)組中相同索引的最大值,如果其中一個(gè)數(shù)組的值為空則返回非空的值,如果兩個(gè)數(shù)組的值都為空則返回第一個(gè)數(shù)組的空值。
這個(gè)函數(shù)很適合用于combine()方法中,當(dāng)然還有很多現(xiàn)成的函數(shù)可以調(diào)用,按需調(diào)用即可。
2. 自定義實(shí)現(xiàn)combine_first()相同功能
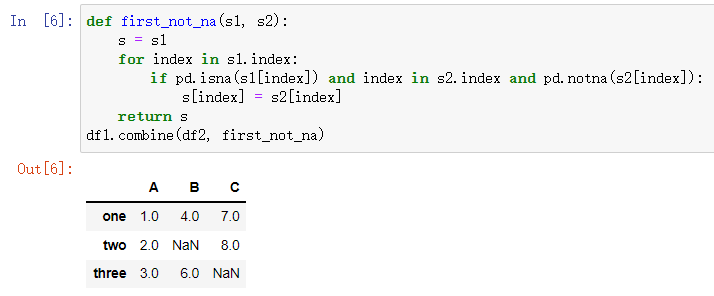
自定義一個(gè)函數(shù)first_not_na()在合并時(shí)優(yōu)先取非空的數(shù)據(jù),這個(gè)函數(shù)實(shí)現(xiàn)的功能與combine_first(other)方法相同。

fill_value: 先用fill_value填充DataFrame中的空值,再按傳入的函數(shù)進(jìn)行合并操作。
fill_value會(huì)填充DataFrame中所有列的空值,而且是在合并之前先填充。
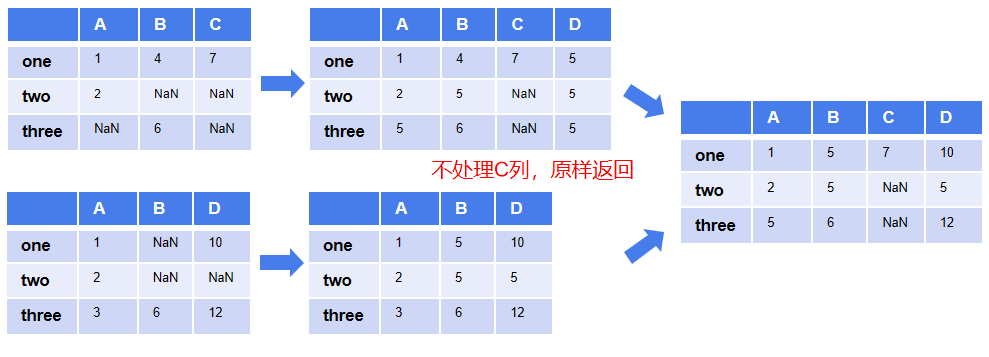
上面的例子中自定義了函數(shù)save_max(),合并時(shí)取同位置的最大值,原理如下圖。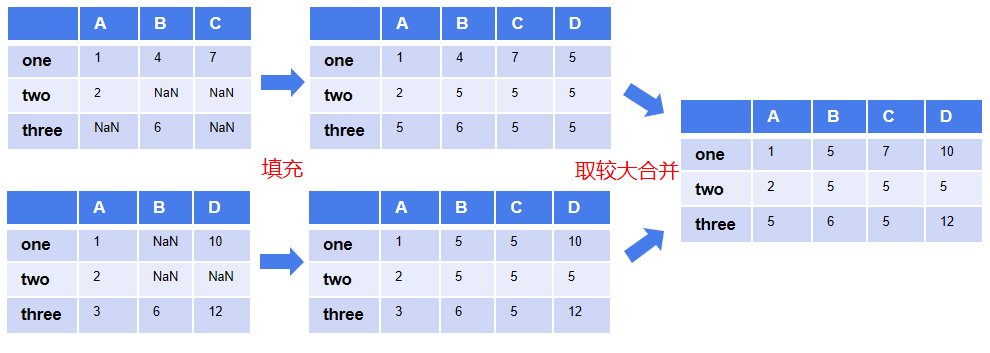
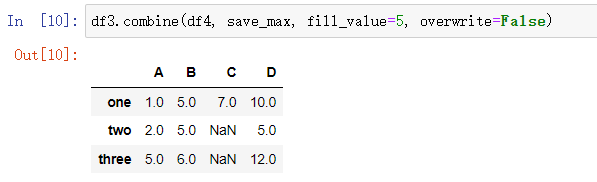
overwrite: 如果調(diào)用combine()方法的DataFrame中存在的列,在傳入combine()方法的DataFrame中不存在,則先在傳入的DataFrame中添加一列空值。overwrite參數(shù)默認(rèn)為True,如第四部分的例子中df4的填充原理如下。

如果將overwrite參數(shù)設(shè)置成False,則不會(huì)給傳入combine()方法的DataFrame添加不存在的列,并且合并時(shí)不會(huì)處理調(diào)用combine()方法的DataFrame中多出的列,多出的列直接原樣返回。原理如下圖。
同樣是合并操作,相對(duì)于前面文章介紹的concat()、merge()、join()三個(gè)方法,combine()方法可以自定義合并的規(guī)則。當(dāng)需要合并兩個(gè)相似的數(shù)據(jù)集,且兩個(gè)數(shù)據(jù)集里的數(shù)據(jù)各有一部分是目標(biāo)數(shù)據(jù)時(shí),很適合使用combine()方法。
例如其中一個(gè)DataFrame中的數(shù)據(jù)比另一個(gè)DataFrame中的數(shù)據(jù)多,但第一個(gè)DataFrame中的部分?jǐn)?shù)據(jù)質(zhì)量(準(zhǔn)確性、缺失值數(shù)量等)不如第二個(gè)DataFrame中的高,就可以使用combine()方法。
以上就是Pandas聯(lián)合方法combine()的介紹,如果需要本文代碼,可以點(diǎn)擊下方名片關(guān)注公眾號(hào)“Python碎片”,然后在后臺(tái)回復(fù)“pandas15”關(guān)鍵字獲取完整代碼。想學(xué)習(xí)更多Python知識(shí),立即點(diǎn)擊關(guān)注。> 參考文檔:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.combine.html
