
這4種Python更新Elasticsearch數(shù)據(jù)的方法你都會(huì)嗎?

大家好,我是菜鳥哥
今天總結(jié)一下通過 Python 更新 Elasticsearch 數(shù)據(jù)的幾個(gè)方法
Elasticsearch 是一個(gè)實(shí)時(shí)的分布式搜索分析引擎,它能讓你以前所未有的速度和規(guī)模,去探索你的數(shù)據(jù)。它被用作全文檢索、結(jié)構(gòu)化搜索、分析以及這三個(gè)功能的組合
全局更新
在 Elasticsearch 中,通過指定文檔的 _id, 使用 Elasticsearch 自帶的 index api 可以實(shí)現(xiàn)插入一條 document , 如果該 _id 已存在,將直接更新該 document
因此,通過 index API 來對(duì)已有的文檔實(shí)現(xiàn)更新,其實(shí)是進(jìn)行了一次 reindex 的操作如 ES 中已有數(shù)據(jù)如下

通過代碼將其更新:
es.index(index="test", doc_type="doc", id="dfebcXcBCWwWKoXwQ2Gk", body={
"name": "Python編程實(shí)戰(zhàn)",
"num": 5})
修改后結(jié)果

通過這種方法修改,因?yàn)槭?reindex 過程,所以當(dāng)數(shù)據(jù)量或者 document 很大的時(shí)候,效率非常的低
局部更新
update
Elasticsearch 中的 update API 支持根據(jù)用戶提供的腳本去實(shí)現(xiàn)更新
Update 更新操作允許 ES 獲得某個(gè)指定的文檔,可以通過腳本等操作對(duì)該文檔進(jìn)行更新。
可以把它看成是先刪除再索引的原子操作,只是省略了返回的過程,這樣即節(jié)省了來回傳輸?shù)木W(wǎng)絡(luò)流量,也避免了中間時(shí)間造成的文檔修改沖突。
在 Python 中可以直接通過包裝好的接口來更新
es.update(index="test", doc_type="doc", id="4Z6XcXcBChYTHL1ZdwjL", body={"doc": {"name": "Jerry"}})
注意 body 參數(shù),我們需要添加 doc 或者 script 變量來指定修改的內(nèi)容
增加字段:
es.update(index="test", doc_type="doc", id="4Z6XcXcBChYTHL1ZdwjL", body={"doc": {"name": "Jerry", "age": 25}})
運(yùn)行完之后,在 kibana 上查看結(jié)果
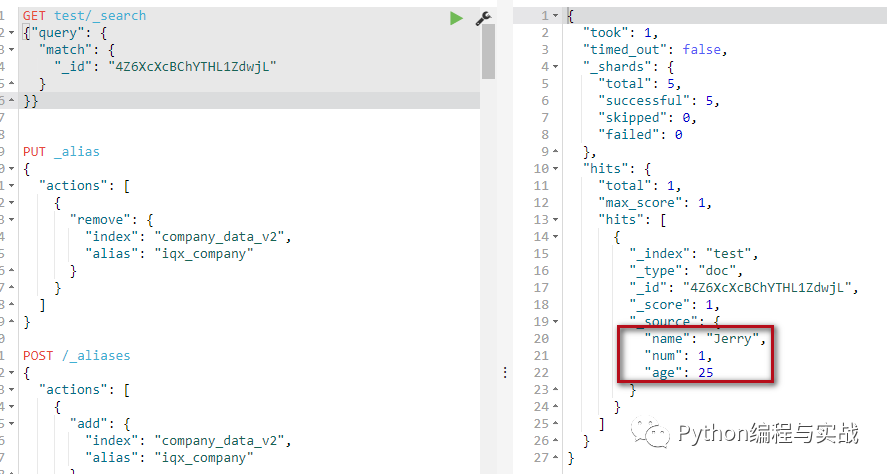
搜索更新
update_by_query
update_by_query,顧名思義,這種更新方式,即通過查詢?cè)俑隆?/p>
該方法的優(yōu)點(diǎn)是可以指定某些數(shù)據(jù),然后達(dá)到更新的目的
在 ES 中,我們通過 update_by_query 中的 query 和 script 來實(shí)現(xiàn)先查詢?cè)俑碌臋C(jī)制
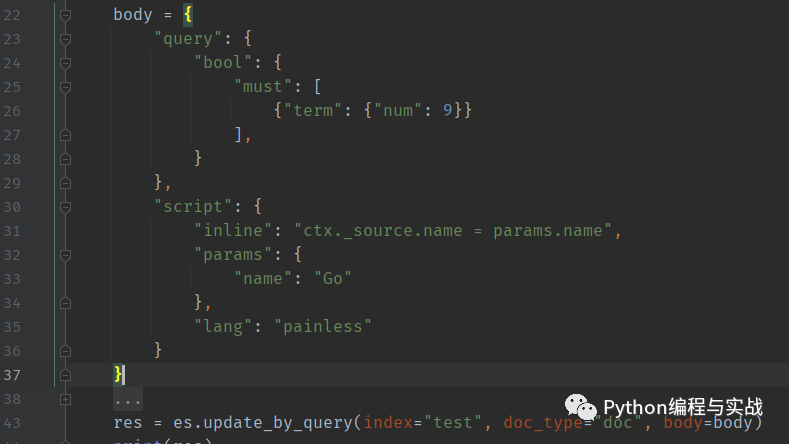
在上面的操作中:query 字段,表示我們要查詢的條件,根據(jù)該條件找到對(duì)應(yīng)的數(shù)據(jù)script 字段包含以下關(guān)鍵字:
source 是將要執(zhí)行的腳本內(nèi)容; lang 表示的是當(dāng)前腳本的語言*; param 則是腳本執(zhí)行的參數(shù);
參考詳情:https://www.elastic.co/guide/en/elasticsearch/reference/master/modules-scripting-painless.html
批量更新
在實(shí)際需求中,面對(duì)最多的還是批量更新
當(dāng)然你也可以通過 for 循環(huán)一條一條來更新,不過這種方法效率太低了。
尤其是面對(duì)數(shù)據(jù)量很大的時(shí)候,那真的是急死人..
好在 ES 有提供批量操作的接口 bulk
在 Python 中可以直接導(dǎo)入使用
from elasticsearch.helpers import bulk
那么在 bulk 中如何使用 update 呢?請(qǐng)看代碼
actions = []
for item in data_list:
_id = item.get("_id")
doc = item.get("doc")
index_action = {
'_op_type': 'update',
'_index': index_name,
'_type': "doc",
'_id': _id,
'doc': doc
}
actions.append(index_action)
if actions:
bulk(es, actions)
可以看到有個(gè) doc 的參數(shù),和上面介紹的 update 方法類似,doc中的值便是我們需要修改的字段內(nèi)容
_op_type 為操作類型為update,表明是更新的操作
以該種方式組合的 index_action 組成數(shù)組,通過 bulk 便能實(shí)現(xiàn)批量更新 !
以上便是通過 Python 更新 Elasticsearch 的幾種方法
個(gè)人推薦通過 update 接口或者 bulk 批量來做更新,你學(xué)廢了嗎?
我們的文章到此就結(jié)束啦,如果你喜歡今天的Python 實(shí)戰(zhàn)教程,請(qǐng)持續(xù)關(guān)注我們!
推薦閱讀:
入門: 最全的零基礎(chǔ)學(xué)Python的問題 | 零基礎(chǔ)學(xué)了8個(gè)月的Python | 實(shí)戰(zhàn)項(xiàng)目 |學(xué)Python就是這條捷徑
干貨:爬取豆瓣短評(píng),電影《后來的我們》 | 38年NBA最佳球員分析 | 從萬眾期待到口碑撲街!唐探3令人失望 | 笑看新倚天屠龍記 | 燈謎答題王 |用Python做個(gè)海量小姐姐素描圖 |
趣味:彈球游戲 | 九宮格 | 漂亮的花 | 兩百行Python《天天酷跑》游戲!
AI: 會(huì)做詩的機(jī)器人 | 給圖片上色 | 預(yù)測(cè)收入 | 碟中諜這么火,我用機(jī)器學(xué)習(xí)做個(gè)迷你推薦系統(tǒng)電影

年度爆款文案
2).學(xué)Python真香!我用100行代碼做了個(gè)網(wǎng)站,幫人PS旅行圖片,賺個(gè)雞腿吃
9).發(fā)現(xiàn)一個(gè)舔狗福利!這個(gè)Python爬蟲神器太爽了,自動(dòng)下載妹子圖片
點(diǎn)閱讀原文,領(lǐng)廖雪峰視頻資料!
