
熬夜整理的C/C++萬(wàn)字總結(jié)(一)

一. C語(yǔ)言概述
歡迎大家來(lái)到c語(yǔ)言的世界,c語(yǔ)言是一種強(qiáng)大的專(zhuān)業(yè)化的編程語(yǔ)言。
1.1 C語(yǔ)言的起源
貝爾實(shí)驗(yàn)室的Dennis Ritchie在1972年開(kāi)發(fā)了C,當(dāng)時(shí)他正與ken Thompson一起設(shè)計(jì)UNIX操作系統(tǒng),然而,C并不是完全由Ritchie構(gòu)想出來(lái)的。它來(lái)自Thompson的B語(yǔ)言。
1.2 使用C語(yǔ)言的理由
在過(guò)去的幾十年中,c語(yǔ)言已成為最流行和最重要的編程語(yǔ)言之一。它之所以得到發(fā)展,是因?yàn)槿藗儑L試使用它后都喜歡它。過(guò)去很多年中,許多人從c語(yǔ)言轉(zhuǎn)而使用更強(qiáng)大的c++語(yǔ)言,但c有其自身的優(yōu)勢(shì),仍然是一種重要的語(yǔ)言,而且它還是學(xué)習(xí)c++的必經(jīng)之路。
高效性。c語(yǔ)言是一種高效的語(yǔ)言。c表現(xiàn)出通常只有匯編語(yǔ)言才具有的精細(xì)的控制能力(匯編語(yǔ)言是特定cpu設(shè)計(jì)所采用的一組內(nèi)部制定的助記符。不同的cpu類(lèi)型使用不同的匯編語(yǔ)言)。如果愿意,您可以細(xì)調(diào)程序以獲得最大的速度或最大的內(nèi)存使用率。 可移植性。c語(yǔ)言是一種可移植的語(yǔ)言。意味著,在一個(gè)系統(tǒng)上編寫(xiě)的c程序經(jīng)過(guò)很少改動(dòng)或不經(jīng)過(guò)修改就可以在其他的系統(tǒng)上運(yùn)行。 強(qiáng)大的功能和靈活性。c強(qiáng)大而又靈活。比如強(qiáng)大靈活的UNIX操作系統(tǒng)便是用c編寫(xiě)的。其他的語(yǔ)言(Perl、Python、BASIC、Pascal)的許多編譯器和解釋器也都是用c編寫(xiě)的。結(jié)果是當(dāng)你在一臺(tái)Unix機(jī)器上使用Python時(shí),最終由一個(gè)c程序負(fù)責(zé)生成最后的可執(zhí)行程序。
1.3 C語(yǔ)言標(biāo)準(zhǔn)
1.3.1 K&R C
起初,C語(yǔ)言沒(méi)有官方標(biāo)準(zhǔn)。1978年由美國(guó)電話(huà)電報(bào)公司(AT&T)貝爾實(shí)驗(yàn)室正式發(fā)表了C語(yǔ)言。布萊恩?柯林漢(Brian Kernighan) 和 丹尼斯?里奇(Dennis Ritchie) 出版了一本書(shū),名叫《The C Programming Language》。這本書(shū)被 C語(yǔ)言開(kāi)發(fā)者們稱(chēng)為K&R,很多年來(lái)被當(dāng)作 C語(yǔ)言的非正式的標(biāo)準(zhǔn)說(shuō)明。人們稱(chēng)這個(gè)版本的 C語(yǔ)言為K&R C。
K&R C主要介紹了以下特色:結(jié)構(gòu)體(struct)類(lèi)型;長(zhǎng)整數(shù)(long int)類(lèi)型;無(wú)符號(hào)整數(shù)(unsigned int)類(lèi)型;把運(yùn)算符=+和=-改為+=和-=。因?yàn)?+和=-會(huì)使得編譯器不知道使用者要處理i = -10還是i =- 10,使得處理上產(chǎn)生混淆。
即使在后來(lái)ANSI C標(biāo)準(zhǔn)被提出的許多年后,K&R C仍然是許多編譯器的最準(zhǔn)要求,許多老舊的編譯器仍然運(yùn)行K&R C的標(biāo)準(zhǔn)。
1.3.2 ANSI C/C89標(biāo)準(zhǔn)
1970到80年代,C語(yǔ)言被廣泛應(yīng)用,從大型主機(jī)到小型微機(jī),也衍生了C語(yǔ)言的很多不同版本。1983年,美國(guó)國(guó)家標(biāo)準(zhǔn)協(xié)會(huì)(ANSI)成立了一個(gè)委員會(huì)X3J11,來(lái)制定 C語(yǔ)言標(biāo)準(zhǔn)。
1989年,美國(guó)國(guó)家標(biāo)準(zhǔn)協(xié)會(huì)(ANSI)通過(guò)了C語(yǔ)言標(biāo)準(zhǔn),被稱(chēng)為ANSI X3.159-1989 "Programming Language C"。因?yàn)檫@個(gè)標(biāo)準(zhǔn)是1989年通過(guò)的,所以一般簡(jiǎn)稱(chēng)C89標(biāo)準(zhǔn)。有些人也簡(jiǎn)稱(chēng)ANSI C,因?yàn)檫@個(gè)標(biāo)準(zhǔn)是美國(guó)國(guó)家標(biāo)準(zhǔn)協(xié)會(huì)(ANSI)發(fā)布的。
1990年,國(guó)際標(biāo)準(zhǔn)化組織(ISO)和國(guó)際電工委員會(huì)(IEC)把C89標(biāo)準(zhǔn)定為C語(yǔ)言的國(guó)際標(biāo)準(zhǔn),命名為ISO/IEC 9899:1990 - Programming languages -- C[5] 。因?yàn)榇藰?biāo)準(zhǔn)是在1990年發(fā)布的,所以有些人把簡(jiǎn)稱(chēng)作C90標(biāo)準(zhǔn)。不過(guò)大多數(shù)人依然稱(chēng)之為C89標(biāo)準(zhǔn),因?yàn)榇藰?biāo)準(zhǔn)與ANSI C89標(biāo)準(zhǔn)完全等同。
1994年,國(guó)際標(biāo)準(zhǔn)化組織(ISO)和國(guó)際電工委員會(huì)(IEC)發(fā)布了C89標(biāo)準(zhǔn)修訂版,名叫ISO/IEC 9899:1990/Cor 1:1994[6] ,有些人簡(jiǎn)稱(chēng)為C94標(biāo)準(zhǔn)。
1995年,國(guó)際標(biāo)準(zhǔn)化組織(ISO)和國(guó)際電工委員會(huì)(IEC)再次發(fā)布了C89標(biāo)準(zhǔn)修訂版,名叫ISO/IEC 9899:1990/Amd 1:1995 - C Integrity[7] ,有些人簡(jiǎn)稱(chēng)為C95標(biāo)準(zhǔn)。
1.3.3 C99標(biāo)準(zhǔn)
1999年1月,國(guó)際標(biāo)準(zhǔn)化組織(ISO)和國(guó)際電工委員會(huì)(IEC)發(fā)布了C語(yǔ)言的新標(biāo)準(zhǔn),名叫ISO/IEC 9899:1999 - Programming languages -- C ,簡(jiǎn)稱(chēng)C99標(biāo)準(zhǔn)。這是C語(yǔ)言的第二個(gè)官方標(biāo)準(zhǔn)。
例如:
增加了新關(guān)鍵字 restrict,inline,_Complex,_Imaginary,_Bool 支持 long long,long double _Complex,float _Complex 這樣的類(lèi)型 支持了不定長(zhǎng)的數(shù)組。數(shù)組的長(zhǎng)度就可以用變量了。聲明類(lèi)型的時(shí)候呢,就用 int a[*] 這樣的寫(xiě)法。不過(guò)考慮到效率和實(shí)現(xiàn),這玩意并不是一個(gè)新類(lèi)型。
二、內(nèi)存分區(qū)
2.1 數(shù)據(jù)類(lèi)型
2.1.1 數(shù)據(jù)類(lèi)型概念
什么是數(shù)據(jù)類(lèi)型?為什么需要數(shù)據(jù)類(lèi)型? 數(shù)據(jù)類(lèi)型是為了更好進(jìn)行內(nèi)存的管理,讓編譯器能確定分配多少內(nèi)存。
我們現(xiàn)實(shí)生活中,狗是狗,鳥(niǎo)是鳥(niǎo)等等,每一種事物都有自己的類(lèi)型,那么程序中使用數(shù)據(jù)類(lèi)型也是來(lái)源于生活。
當(dāng)我們給狗分配內(nèi)存的時(shí)候,也就相當(dāng)于給狗建造狗窩,給鳥(niǎo)分配內(nèi)存的時(shí)候,也就是給鳥(niǎo)建造一個(gè)鳥(niǎo)窩,我們可以給他們各自建造一個(gè)別墅,但是會(huì)造成內(nèi)存的浪費(fèi),不能很好的利用內(nèi)存空間。
我們?cè)谙耄绻o鳥(niǎo)分配內(nèi)存,只需要鳥(niǎo)窩大小的空間就夠了,如果給狗分配內(nèi)存,那么也只需要狗窩大小的內(nèi)存,而不是給鳥(niǎo)和狗都分配一座別墅,造成內(nèi)存的浪費(fèi)。
當(dāng)我們定義一個(gè)變量,a = 10,編譯器如何分配內(nèi)存?計(jì)算機(jī)只是一個(gè)機(jī)器,它怎么知道用多少內(nèi)存可以放得下10?
所以說(shuō),數(shù)據(jù)類(lèi)型非常重要,它可以告訴編譯器分配多少內(nèi)存可以放得下我們的數(shù)據(jù)。
狗窩里面是狗,鳥(niǎo)窩里面是鳥(niǎo),如果沒(méi)有數(shù)據(jù)類(lèi)型,你怎么知道冰箱里放得是一頭大象!
數(shù)據(jù)類(lèi)型基本概念:
類(lèi)型是對(duì)數(shù)據(jù)的抽象; 類(lèi)型相同的數(shù)據(jù)具有相同的表示形式、存儲(chǔ)格式以及相關(guān)操作; 程序中所有的數(shù)據(jù)都必定屬于某種數(shù)據(jù)類(lèi)型; 數(shù)據(jù)類(lèi)型可以理解為創(chuàng)建變量的模具: 固定大小內(nèi)存的別名; 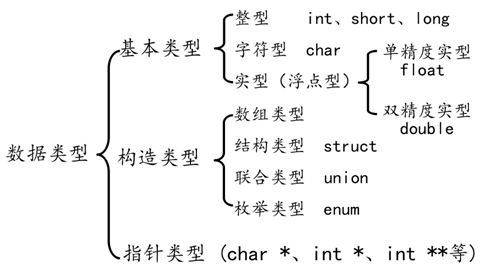
2.1.2 數(shù)據(jù)類(lèi)型別名
typedef unsigned int u32;
typedef struct _PERSON{
char name[64];
int age;
}Person;
void test(){
u32 val; //相當(dāng)于 unsigned int val;
Person person; //相當(dāng)于 struct PERSON person;
}
2.1.3 void數(shù)據(jù)類(lèi)型
void字面意思是”無(wú)類(lèi)型”,void* 無(wú)類(lèi)型指針,無(wú)類(lèi)型指針可以指向任何類(lèi)型的數(shù)據(jù)。
void定義變量是沒(méi)有任何意義的,當(dāng)你定義void a,編譯器會(huì)報(bào)錯(cuò)。
void真正用在以下兩個(gè)方面:
對(duì)函數(shù)返回的限定; 對(duì)函數(shù)參數(shù)的限定;
//1. void修飾函數(shù)參數(shù)和函數(shù)返回
void test01(void){
printf("hello world");
}
//2. 不能定義void類(lèi)型變量
void test02(){
void val; //報(bào)錯(cuò)
}
//3. void* 可以指向任何類(lèi)型的數(shù)據(jù),被稱(chēng)為萬(wàn)能指針
void test03(){
int a = 10;
void* p = NULL;
p = &a;
printf("a:%d\n",*(int*)p);
char c = 'a';
p = &c;
printf("c:%c\n",*(char*)p);
}
//4. void* 常用于數(shù)據(jù)類(lèi)型的封裝
void test04(){
//void * memcpy(void * _Dst, const void * _Src, size_t _Size);
}
2.1.4 sizeof 操作符
sizeof 是 c語(yǔ)言中的一個(gè)操作符,類(lèi)似于++、--等等。sizeof 能夠告訴我們編譯器為某一特定數(shù)據(jù)或者某一個(gè)類(lèi)型的數(shù)據(jù)在內(nèi)存中分配空間時(shí)分配的大小,大小以字節(jié)為單位。
基本語(yǔ)法:
sizeof(變量);
sizeof 變量;
sizeof(類(lèi)型);
sizeof 注意點(diǎn):
sizeof返回的占用空間大小是為這個(gè)變量開(kāi)辟的大小,而不只是它用到的空間。和現(xiàn)今住房的建筑面積和實(shí)用面積的概念差不多。所以對(duì)結(jié)構(gòu)體用的時(shí)候,大多情況下就得考慮字節(jié)對(duì)齊的問(wèn)題了; sizeof返回的數(shù)據(jù)結(jié)果類(lèi)型是unsigned int; 要注意數(shù)組名和指針變量的區(qū)別。通常情況下,我們總覺(jué)得數(shù)組名和指針變量差不多,但是在用sizeof的時(shí)候差別很大,對(duì)數(shù)組名用sizeof返回的是整個(gè)數(shù)組的大小,而對(duì)指針變量進(jìn)行操作的時(shí)候返回的則是指針變量本身所占得空間,在32位機(jī)的條件下一般都是4。而且當(dāng)數(shù)組名作為函數(shù)參數(shù)時(shí),在函數(shù)內(nèi)部,形參也就是個(gè)指針,所以不再返回?cái)?shù)組的大小;
//1. sizeof基本用法
void test01(){
int a = 10;
printf("len:%d\n", sizeof(a));
printf("len:%d\n", sizeof(int));
printf("len:%d\n", sizeof a);
}
//2. sizeof 結(jié)果類(lèi)型
void test02(){
unsigned int a = 10;
if (a - 11 < 0){
printf("結(jié)果小于0\n");
}
else{
printf("結(jié)果大于0\n");
}
int b = 5;
if (sizeof(b) - 10 < 0){
printf("結(jié)果小于0\n");
}
else{
printf("結(jié)果大于0\n");
}
}
//3. sizeof 碰到數(shù)組
void TestArray(int arr[]){
printf("TestArray arr size:%d\n",sizeof(arr));
}
void test03(){
int arr[] = { 10, 20, 30, 40, 50 };
printf("array size: %d\n",sizeof(arr));
//數(shù)組名在某些情況下等價(jià)于指針
int* pArr = arr;
printf("arr[2]:%d\n",pArr[2]);
printf("array size: %d\n", sizeof(pArr));
//數(shù)組做函數(shù)函數(shù)參數(shù),將退化為指針,在函數(shù)內(nèi)部不再返回?cái)?shù)組大小
TestArray(arr);
}
2.1.5 數(shù)據(jù)類(lèi)型總結(jié)
數(shù)據(jù)類(lèi)型本質(zhì)是固定內(nèi)存大小的別名,是個(gè)模具,C語(yǔ)言規(guī)定:通過(guò)數(shù)據(jù)類(lèi)型定義變量; 數(shù)據(jù)類(lèi)型大小計(jì)算(sizeof); 可以給已存在的數(shù)據(jù)類(lèi)型起別名typedef; 數(shù)據(jù)類(lèi)型的封裝(void 萬(wàn)能類(lèi)型);
2.2 變量
2.1.1 變量的概念
既能讀又能寫(xiě)的內(nèi)存對(duì)象,稱(chēng)為變量;
若一旦初始化后不能修改的對(duì)象則稱(chēng)為常量。
變量定義形式: 類(lèi)型 標(biāo)識(shí)符, 標(biāo)識(shí)符, … , 標(biāo)識(shí)符
2.1.2 變量名的本質(zhì)
變量名的本質(zhì):一段連續(xù)內(nèi)存空間的別名; 程序通過(guò)變量來(lái)申請(qǐng)和命名內(nèi)存空間 int a = 0; 通過(guò)變量名訪(fǎng)問(wèn)內(nèi)存空間; 不是向變量名讀寫(xiě)數(shù)據(jù),而是向變量所代表的內(nèi)存空間中讀寫(xiě)數(shù)據(jù);
修改變量的兩種方式:
void test(){
int a = 10;
//1. 直接修改
a = 20;
printf("直接修改,a:%d\n",a);
//2. 間接修改
int* p = &a;
*p = 30;
printf("間接修改,a:%d\n", a);
}
2.3 程序的內(nèi)存分區(qū)模型
2.3.1 內(nèi)存分區(qū)
2.3.1.1 運(yùn)行之前
我們要想執(zhí)行我們編寫(xiě)的c程序,那么第一步需要對(duì)這個(gè)程序進(jìn)行編譯。1)預(yù)處理:宏定義展開(kāi)、頭文件展開(kāi)、條件編譯,這里并不會(huì)檢查語(yǔ)法
2)編譯:檢查語(yǔ)法,將預(yù)處理后文件編譯生成匯編文件
3)匯編:將匯編文件生成目標(biāo)文件(二進(jìn)制文件)
4)鏈接:將目標(biāo)文件鏈接為可執(zhí)行程序
? 代碼區(qū)
存放 CPU 執(zhí)行的機(jī)器指令。通常代碼區(qū)是可共享的(即另外的執(zhí)行程序可以調(diào)用它),使其可共享的目的是對(duì)于頻繁被執(zhí)行的程序,只需要在內(nèi)存中有一份代碼即可。代碼區(qū)通常是只讀的,使其只讀的原因是防止程序意外地修改了它的指t令。另外,代碼區(qū)還規(guī)劃了局部變量的相關(guān)信息。
? 全局初始化數(shù)據(jù)區(qū)/靜態(tài)數(shù)據(jù)區(qū)(data段)
該區(qū)包含了在程序中明確被初始化的全局變量、已經(jīng)初始化的靜態(tài)變量(包括全局靜態(tài)變量和t)和常量數(shù)據(jù)(如字符串常量)。
? 未初始化數(shù)據(jù)區(qū)(又叫 bss 區(qū))
存入的是全局未初始化變量和未初始化靜態(tài)變量。未初始化數(shù)據(jù)區(qū)的數(shù)據(jù)在程序開(kāi)始執(zhí)行之前被內(nèi)核初始化為 0 或者空(NULL)。
總體來(lái)講說(shuō),程序源代碼被編譯之后主要分成兩種段:程序指令(代碼區(qū))和程序數(shù)據(jù)(數(shù)據(jù)區(qū))。代碼段屬于程序指令,而數(shù)據(jù)域段和.bss段屬于程序數(shù)據(jù)。
那為什么把程序的指令和程序數(shù)據(jù)分開(kāi)呢?
程序被load到內(nèi)存中之后,可以將數(shù)據(jù)和代碼分別映射到兩個(gè)內(nèi)存區(qū)域。由于數(shù)據(jù)區(qū)域?qū)M(jìn)程來(lái)說(shuō)是可讀可寫(xiě)的,而指令區(qū)域?qū)Τ绦騺?lái)講說(shuō)是只讀的,所以分區(qū)之后呢,可以將程序指令區(qū)域和數(shù)據(jù)區(qū)域分別設(shè)置成可讀可寫(xiě)或只讀。這樣可以防止程序的指令有意或者無(wú)意被修改;
當(dāng)系統(tǒng)中運(yùn)行著多個(gè)同樣的程序的時(shí)候,這些程序執(zhí)行的指令都是一樣的,所以只需要內(nèi)存中保存一份程序的指令就可以了,只是每一個(gè)程序運(yùn)行中數(shù)據(jù)不一樣而已,這樣可以節(jié)省大量的內(nèi)存。比如說(shuō)之前的Windows Internet Explorer 7.0運(yùn)行起來(lái)之后, 它需要占用112 844KB的內(nèi)存,它的私有部分?jǐn)?shù)據(jù)有大概15 944KB,也就是說(shuō)有96 900KB空間是共享的,如果程序中運(yùn)行了幾百個(gè)這樣的進(jìn)程,可以想象共享的方法可以節(jié)省大量的內(nèi)存。
2.3.1.1 運(yùn)行之后
程序在加載到內(nèi)存前,代碼區(qū)和全局區(qū)(data和bss)的大小就是固定的,程序運(yùn)行期間不能改變。然后,運(yùn)行可執(zhí)行程序,操作系統(tǒng)把物理硬盤(pán)程序load(加載)到內(nèi)存,除了根據(jù)可執(zhí)行程序的信息分出代碼區(qū)(text)、數(shù)據(jù)區(qū)(data)和未初始化數(shù)據(jù)區(qū)(bss)之外,還額外增加了棧區(qū)、堆區(qū)。
? 代碼區(qū)(text segment)
加載的是可執(zhí)行文件代碼段,所有的可執(zhí)行代碼都加載到代碼區(qū),這塊內(nèi)存是不可以在運(yùn)行期間修改的。
? 未初始化數(shù)據(jù)區(qū)(BSS)
加載的是可執(zhí)行文件BSS段,位置可以分開(kāi)亦可以緊靠數(shù)據(jù)段,存儲(chǔ)于數(shù)據(jù)段的數(shù)據(jù)(全局未初始化,靜態(tài)未初始化數(shù)據(jù))的生存周期為整個(gè)程序運(yùn)行過(guò)程。
? 全局初始化數(shù)據(jù)區(qū)/靜態(tài)數(shù)據(jù)區(qū)(data segment)
加載的是可執(zhí)行文件數(shù)據(jù)段,存儲(chǔ)于數(shù)據(jù)段(全局初始化,靜態(tài)初始化數(shù)據(jù),文字常量(只讀))的數(shù)據(jù)的生存周期為整個(gè)程序運(yùn)行過(guò)程。
? 棧區(qū)(stack)
棧是一種先進(jìn)后出的內(nèi)存結(jié)構(gòu),由編譯器自動(dòng)分配釋放,存放函數(shù)的參數(shù)值、返回值、局部變量等。在程序運(yùn)行過(guò)程中實(shí)時(shí)加載和釋放,因此,局部變量的生存周期為申請(qǐng)到釋放該段棧空間。
? 堆區(qū)(heap)
堆是一個(gè)大容器,它的容量要遠(yuǎn)遠(yuǎn)大于棧,但沒(méi)有棧那樣先進(jìn)后出的順序。用于動(dòng)態(tài)內(nèi)存分配。堆在內(nèi)存中位于BSS區(qū)和棧區(qū)之間。一般由程序員分配和釋放,若程序員不釋放,程序結(jié)束時(shí)由操作系統(tǒng)回收。
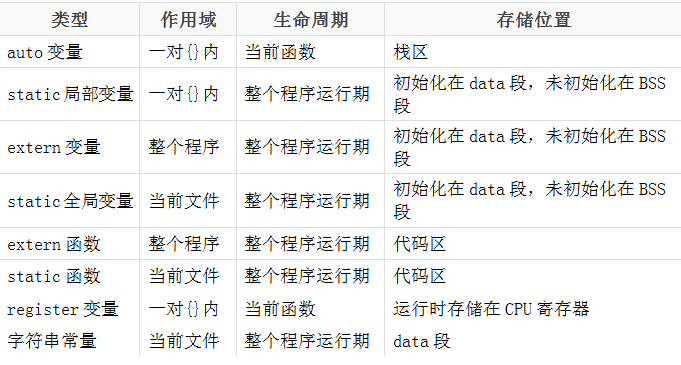
2.3.2 分區(qū)模型
2.3.2.1 棧區(qū)
由系統(tǒng)進(jìn)行內(nèi)存的管理。主要存放函數(shù)的參數(shù)以及局部變量。在函數(shù)完成執(zhí)行,系統(tǒng)自行釋放棧區(qū)內(nèi)存,不需要用戶(hù)管理。
#char* func(){
char p[] = "hello world!"; //在棧區(qū)存儲(chǔ) 亂碼
printf("%s\n", p);
return p;
}
void test(){
char* p = NULL;
p = func();
printf("%s\n",p);
}
2.3.2.2 堆區(qū)
由編程人員手動(dòng)申請(qǐng),手動(dòng)釋放,若不手動(dòng)釋放,程序結(jié)束后由系統(tǒng)回收,生命周期是整個(gè)程序運(yùn)行期間。使用malloc或者new進(jìn)行堆的申請(qǐng)。
char* func(){
char* str = malloc(100);
strcpy(str, "hello world!");
printf("%s\n",str);
return str;
}
void test01(){
char* p = NULL;
p = func();
printf("%s\n",p);
}
void allocateSpace(char* p){
p = malloc(100);
strcpy(p, "hello world!");
printf("%s\n", p);
}
void test02(){
char* p = NULL;
allocateSpace(p);
printf("%s\n", p);
}

堆分配內(nèi)存API:
#include <stdlib.h>
void *calloc(size_t nmemb, size_t size);
功能:
在內(nèi)存動(dòng)態(tài)存儲(chǔ)區(qū)中分配nmemb塊長(zhǎng)度為size字節(jié)的連續(xù)區(qū)域。calloc自動(dòng)將分配的內(nèi)存 置0。
參數(shù):
nmemb:所需內(nèi)存單元數(shù)量 size:每個(gè)內(nèi)存單元的大小(單位:字節(jié))
返回值:
成功:分配空間的起始地址
失敗:NULL
#include <stdlib.h>
void *realloc(void *ptr, size_t size);
功能:
重新分配用malloc或者calloc函數(shù)在堆中分配內(nèi)存空間的大小。realloc不會(huì)自動(dòng)清理增加的內(nèi)存,需要手動(dòng)清理,如果指定的地址后面有連續(xù)的空間,那么就會(huì)在已有地址基礎(chǔ)上增加內(nèi)存,如果指定的地址后面沒(méi)有空間,那么realloc會(huì)重新分配新的連續(xù)內(nèi)存,把舊內(nèi)存的值拷貝到新內(nèi)存,同時(shí)釋放舊內(nèi)存。
參數(shù):
ptr:為之前用malloc或者calloc分配的內(nèi)存地址,如果此參數(shù)等于NULL,那么和realloc與malloc功能一致
size:為重新分配內(nèi)存的大小, 單位:字節(jié)
返回值:
成功:新分配的堆內(nèi)存地址
失敗:NULL
void test01(){
int* p1 = calloc(10,sizeof(int));
if (p1 == NULL){
return;
}
for (int i = 0; i < 10; i ++){
p1[i] = i + 1;
}
for (int i = 0; i < 10; i++){
printf("%d ",p1[i]);
}
printf("\n");
free(p1);
}
void test02(){
int* p1 = calloc(10, sizeof(int));
if (p1 == NULL){
return;
}
for (int i = 0; i < 10; i++){
p1[i] = i + 1;
}
int* p2 = realloc(p1, 15 * sizeof(int));
if (p2 == NULL){
return;
}
printf("%d\n", p1);
printf("%d\n", p2);
//打印
for (int i = 0; i < 15; i++){
printf("%d ", p2[i]);
}
printf("\n");
//重新賦值
for (int i = 0; i < 15; i++){
p2[i] = i + 1;
}
//再次打印
for (int i = 0; i < 15; i++){
printf("%d ", p2[i]);
}
printf("\n");
free(p2);
}
2.3.2.3 全局/靜態(tài)區(qū)
全局靜態(tài)區(qū)內(nèi)的變量在編譯階段已經(jīng)分配好內(nèi)存空間并初始化。這塊內(nèi)存在程序運(yùn)行期間一直存在,它主要存儲(chǔ)全局變量、靜態(tài)變量和常量。
注意:
(1)這里不區(qū)分初始化和未初始化的數(shù)據(jù)區(qū),是因?yàn)殪o態(tài)存儲(chǔ)區(qū)內(nèi)的變量若不顯示初始化,則編譯器會(huì)自動(dòng)以默認(rèn)的方式進(jìn)行初始化,即靜態(tài)存儲(chǔ)區(qū)內(nèi)不存在未初始化的變量。
(2)全局靜態(tài)存儲(chǔ)區(qū)內(nèi)的常量分為常變量和字符串常量,一經(jīng)初始化,不可修改。靜態(tài)存儲(chǔ)內(nèi)的常變量是全局變量,與局部常變量不同,區(qū)別在于局部常變量存放于棧,實(shí)際可間接通過(guò)指針或者引用進(jìn)行修改,而全局常變量存放于靜態(tài)常量區(qū)則不可以間接修改。
(3)字符串常量存儲(chǔ)在全局/靜態(tài)存儲(chǔ)區(qū)的常量區(qū)。
int v1 = 10;//全局/靜態(tài)區(qū)
const int v2 = 20; //常量,一旦初始化,不可修改
static int v3 = 20; //全局/靜態(tài)區(qū)
char *p1; //全局/靜態(tài)區(qū),編譯器默認(rèn)初始化為NULL
//那么全局static int 和 全局int變量有什么區(qū)別?
void test(){
static int v4 = 20; //全局/靜態(tài)區(qū)
}
char* func(){
static char arr[] = "hello world!"; //在靜態(tài)區(qū)存儲(chǔ) 可讀可寫(xiě)
arr[2] = 'c';
char* p = "hello world!"; //全局/靜態(tài)區(qū)-字符串常量區(qū)
//p[2] = 'c'; //只讀,不可修改
printf("%d\n",arr);
printf("%d\n",p);
printf("%s\n", arr);
return arr;
}
void test(){
char* p = func();
printf("%s\n",p);
}
2.3.2.4 總結(jié)
在理解C/C++內(nèi)存分區(qū)時(shí),常會(huì)碰到如下術(shù)語(yǔ):數(shù)據(jù)區(qū),堆,棧,靜態(tài)區(qū),常量區(qū),全局區(qū),字符串常量區(qū),文字常量區(qū),代碼區(qū)等等,初學(xué)者被搞得云里霧里。在這里,嘗試捋清楚以上分區(qū)的關(guān)系。
數(shù)據(jù)區(qū)包括:堆,棧,全局/靜態(tài)存儲(chǔ)區(qū)。
全局/靜態(tài)存儲(chǔ)區(qū)包括:常量區(qū),全局區(qū)、靜態(tài)區(qū)。 常量區(qū)包括:字符串常量區(qū)、常變量區(qū)。 代碼區(qū):存放程序編譯后的二進(jìn)制代碼,不可尋址區(qū)。
可以說(shuō),C/C++內(nèi)存分區(qū)其實(shí)只有兩個(gè),即代碼區(qū)和數(shù)據(jù)區(qū)。
2.3.3 函數(shù)調(diào)用模型
2.3.3.1 函數(shù)調(diào)用流程
棧(stack)是現(xiàn)代計(jì)算機(jī)程序里最為重要的概念之一,幾乎每一個(gè)程序都使用了棧,沒(méi)有棧就沒(méi)有函數(shù),沒(méi)有局部變量,也就沒(méi)有我們?nèi)缃衲芤?jiàn)到的所有計(jì)算機(jī)的語(yǔ)言。在解釋為什么棧如此重要之前,我們先了解一下傳統(tǒng)的棧的定義:
在經(jīng)典的計(jì)算機(jī)科學(xué)中,棧被定義為一個(gè)特殊的容器,用戶(hù)可以將數(shù)據(jù)壓入棧中(入棧,push),也可以將壓入棧中的數(shù)據(jù)彈出(出棧,pop),但是棧容器必須遵循一條規(guī)則:先入棧的數(shù)據(jù)最后出棧(First In Last Out,FILO).
在經(jīng)典的操作系統(tǒng)中,棧總是向下增長(zhǎng)的。壓棧的操作使得棧頂?shù)牡刂窚p小,彈出操作使得棧頂?shù)刂吩龃蟆?/p>
棧在程序運(yùn)行中具有極其重要的地位。最重要的,棧保存一個(gè)函數(shù)調(diào)用所需要維護(hù)的信息,這通常被稱(chēng)為堆棧幀(Stack Frame)或者活動(dòng)記錄(Activate Record).一個(gè)函數(shù)調(diào)用過(guò)程所需要的信息一般包括以下幾個(gè)方面:
函數(shù)的返回地址; 函數(shù)的參數(shù); 臨時(shí)變量; 保存的上下文:包括在函數(shù)調(diào)用前后需要保持不變的寄存器。
我們從下面的代碼,分析以下函數(shù)的調(diào)用過(guò)程:
int func(int a,int b){
int t_a = a;
int t_b = b;
return t_a + t_b;
}
int main(){
int ret = 0;
ret = func(10, 20);
return EXIT_SUCCESS;
}
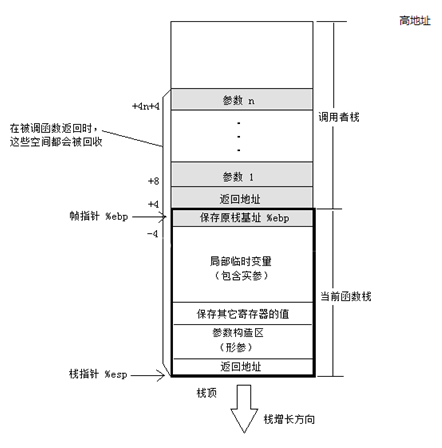
2.3.3.2 調(diào)用慣例
現(xiàn)在,我們大致了解了函數(shù)調(diào)用的過(guò)程,這期間有一個(gè)現(xiàn)象,那就是函數(shù)的調(diào)用者和被調(diào)用者對(duì)函數(shù)調(diào)用有著一致的理解,例如,它們雙方都一致的認(rèn)為函數(shù)的參數(shù)是按照某個(gè)固定的方式壓入棧中。如果不這樣的話(huà),函數(shù)將無(wú)法正確運(yùn)行。
如果函數(shù)調(diào)用方在傳遞參數(shù)的時(shí)候先壓入a參數(shù),再壓入b參數(shù),而被調(diào)用函數(shù)則認(rèn)為先壓入的是b,后壓入的是a,那么被調(diào)用函數(shù)在使用a,b值時(shí)候,就會(huì)顛倒。
因此,函數(shù)的調(diào)用方和被調(diào)用方對(duì)于函數(shù)是如何調(diào)用的必須有一個(gè)明確的約定,只有雙方都遵循同樣的約定,函數(shù)才能夠被正確的調(diào)用,這樣的約定被稱(chēng)為”調(diào)用慣例(Calling Convention)”.一個(gè)調(diào)用慣例一般包含以下幾個(gè)方面:
函數(shù)參數(shù)的傳遞順序和方式
函數(shù)的傳遞有很多種方式,最常見(jiàn)的是通過(guò)棧傳遞。函數(shù)的調(diào)用方將參數(shù)壓入棧中,函數(shù)自己再?gòu)臈V袑?shù)取出。對(duì)于有多個(gè)參數(shù)的函數(shù),調(diào)用慣例要規(guī)定函數(shù)調(diào)用方將參數(shù)壓棧的順序:從左向右,還是從右向左。有些調(diào)用慣例還允許使用寄存器傳遞參數(shù),以提高性能。
棧的維護(hù)方式
在函數(shù)將參數(shù)壓入棧中之后,函數(shù)體會(huì)被調(diào)用,此后需要將被壓入棧中的參數(shù)全部彈出,以使得棧在函數(shù)調(diào)用前后保持一致。這個(gè)彈出的工作可以由函數(shù)的調(diào)用方來(lái)完成,也可以由函數(shù)本身來(lái)完成。
為了在鏈接的時(shí)候?qū)φ{(diào)用慣例進(jìn)行區(qū)分,調(diào)用慣例要對(duì)函數(shù)本身的名字進(jìn)行修飾。不同的調(diào)用慣例有不同的名字修飾策略。
事實(shí)上,在c語(yǔ)言里,存在著多個(gè)調(diào)用慣例,而默認(rèn)的是cdecl.任何一個(gè)沒(méi)有顯示指定調(diào)用慣例的函數(shù)都是默認(rèn)是cdecl慣例。比如我們上面對(duì)于func函數(shù)的聲明,它的完整寫(xiě)法應(yīng)該是:
int _cdecl func(int a,int b);
注意: cdecl不是標(biāo)準(zhǔn)的關(guān)鍵字,在不同的編譯器里可能有不同的寫(xiě)法,例如gcc里就不存在_cdecl這樣的關(guān)鍵字,而是使用__attribute_((cdecl)).

2.3.3.2 函數(shù)變量傳遞分析

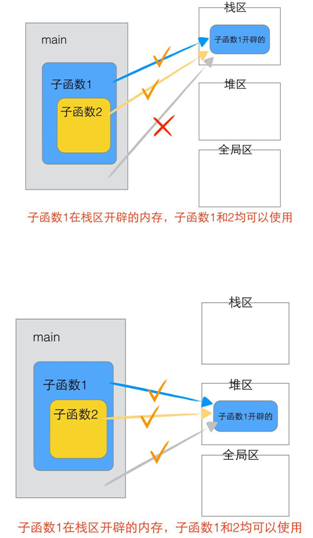
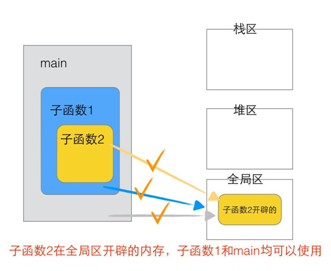
2.3.4 棧的生長(zhǎng)方向和內(nèi)存存放方向

//1. 棧的生長(zhǎng)方向
void test01(){
int a = 10;
int b = 20;
int c = 30;
int d = 40;
printf("a = %d\n", &a);
printf("b = %d\n", &b);
printf("c = %d\n", &c);
printf("d = %d\n", &d);
//a的地址大于b的地址,故而生長(zhǎng)方向向下
}
//2. 內(nèi)存生長(zhǎng)方向(小端模式)
void test02(){
//高位字節(jié) -> 地位字節(jié)
int num = 0xaabbccdd;
unsigned char* p = #
//從首地址開(kāi)始的第一個(gè)字節(jié)
printf("%x\n",*p);
printf("%x\n", *(p + 1));
printf("%x\n", *(p + 2));
printf("%x\n", *(p + 3));
}