如何部署一個(gè)生產(chǎn)級別的 Kubernetes 應(yīng)用
 本文我們用一個(gè) Wordpress 示例來盡可能將前面的知識點(diǎn)串聯(lián)起來,我們需要達(dá)到的目的是讓 Wordpress 應(yīng)用具有高可用、滾動(dòng)更新的過程中不能中斷服務(wù)、數(shù)據(jù)要持久化不能丟失、當(dāng)應(yīng)用負(fù)載太高的時(shí)候能夠自動(dòng)進(jìn)行擴(kuò)容、當(dāng)然還有 HTTPS 訪問等等,這些是我們的應(yīng)用部署到線上環(huán)境基本上要具備的一些能力,接下來我們就來一步一步完成這些需求。
本文我們用一個(gè) Wordpress 示例來盡可能將前面的知識點(diǎn)串聯(lián)起來,我們需要達(dá)到的目的是讓 Wordpress 應(yīng)用具有高可用、滾動(dòng)更新的過程中不能中斷服務(wù)、數(shù)據(jù)要持久化不能丟失、當(dāng)應(yīng)用負(fù)載太高的時(shí)候能夠自動(dòng)進(jìn)行擴(kuò)容、當(dāng)然還有 HTTPS 訪問等等,這些是我們的應(yīng)用部署到線上環(huán)境基本上要具備的一些能力,接下來我們就來一步一步完成這些需求。
原理
首先要部署 Wordpress 應(yīng)用,我們肯定需要知道 Wordpress 是如何運(yùn)行起來的,Wordpress 是一個(gè)基于 PHP 和 MySQL 的流行的開源內(nèi)容管理系統(tǒng),擁有豐富的插件和模板系統(tǒng)。到這里我們應(yīng)該就清楚應(yīng)該如何去運(yùn)行 Wordpress 了,一個(gè)能夠解析 PHP 的程序,和 MySQL 數(shù)據(jù)庫就可以了,我們要想在 Kubernetes 系統(tǒng)中來運(yùn)行,肯定需要使用到 Docker 鏡像了,對于 Wordpress 應(yīng)用程序本身官方提供了鏡像 https://hub.docker.com/_/wordpress,也給出了說明如何運(yùn)行,可以通過一系列環(huán)境變量去指定 MySQL 數(shù)據(jù)庫的配置,只需要將這些參數(shù)配置上直接運(yùn)行即可。我們知道 Wordpress 應(yīng)用本身會頻繁的和 MySQL 數(shù)據(jù)庫進(jìn)行交互,這種情況下如果將二者用容器部署在同一個(gè) Pod 下面是不是要高效很多,因?yàn)橐粋€(gè) Pod 下面的所有容器是共享同一個(gè) network namespace 的,下面我們就來部署我們的應(yīng)用,將我們的應(yīng)用都部署到 kube-example 這個(gè)命名空間下面,所以首先創(chuàng)建一個(gè)命名空間:(namespace.yaml)
apiVersion: v1
kind: Namespace
metadata:
name: kube-example
然后編寫部署到 Kubernetes 下面的資源清單:(deployment.yaml)
apiVersion: apps/v1
kind: Deployment
metadata:
name: wordpress
namespace: kube-example
labels:
app: wordpress
spec:
selector:
matchLabels:
app: wordpress
template:
metadata:
labels:
app: wordpress
spec:
containers:
- name: wordpress
image: wordpress:5.3.2-apache
ports:
- containerPort: 80
name: wdport
env:
- name: WORDPRESS_DB_HOST
value: localhost:3306
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
value: wordpress
- name: mysql
image: mysql:5.7
imagePullPolicy: IfNotPresent
args: # 新版本鏡像有更新,需要使用下面的認(rèn)證插件環(huán)境變量配置才會生效
- --default_authentication_plugin=mysql_native_password
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_unicode_ci
ports:
- containerPort: 3306
name: dbport
env:
- name: MYSQL_ROOT_PASSWORD
value: rootPassW0rd
- name: MYSQL_DATABASE
value: wordpress
- name: MYSQL_USER
value: wordpress
- name: MYSQL_PASSWORD
value: wordpress
由于我們這里 MySQL 和 Wordpress 在同一個(gè) Pod 下面,所以在 Wordpress 中我們指定數(shù)據(jù)庫地址的時(shí)候是用的 localhost:3306,因?yàn)檫@兩個(gè)容器已經(jīng)共享同一個(gè) network namespace 了,這點(diǎn)很重要,然后如果我們要想把這個(gè)服務(wù)暴露給外部用戶還得創(chuàng)建一個(gè) Service 或者 Ingress 對象,這里我們一步一步來,暫時(shí)先創(chuàng)建一個(gè) NodePort 類型的 Service:(service.yaml)
apiVersion: v1
kind: Service
metadata:
name: wordpress
namespace: kube-example
spec:
selector:
app: wordpress
type: NodePort
ports:
- name: web
port: 80
targetPort: wdport
因?yàn)橹恍枰┞?Wordpress 這個(gè)應(yīng)用,所以只匹配了一個(gè)名為 wdport 的端口,現(xiàn)在我們來創(chuàng)建上面的幾個(gè)資源對象:
$ kubectl apply -f namespace.yaml
$ kubectl apply -f deployment.yaml
$ kubectl apply -f service.yaml
接下來就是等待拉取鏡像,啟動(dòng) Pod:
$ kubectl get pods -n kube-example
NAME READY STATUS RESTARTS AGE
wordpress-77dcdb64c6-zdlb8 2/2 Running 0 12m
$ kubectl get svc -n kube-example
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
wordpress NodePort 10.106.237.157 <none> 80:30892/TCP 2m2s
當(dāng) Pod 啟動(dòng)完成后,我們就可以通過上面的 http://<任意節(jié)點(diǎn)IP>:30892 這個(gè) NodePort 端口來訪問應(yīng)用了。我們仔細(xì)想一想這一種方式有什么問題?首先一個(gè) Pod 中的所有容器并沒有啟動(dòng)的先后順序,所以很有可能當(dāng) wordpress 這個(gè)容器啟動(dòng)起來去連接 mysql 這個(gè)容器的時(shí)候,mysql 還沒有啟動(dòng)起來;另外一個(gè)問題是現(xiàn)在我們的應(yīng)用是不是只有一個(gè)副本?會有單點(diǎn)問題,應(yīng)用的性能也是一個(gè)問題,由于 Wordpress 應(yīng)用本身是無狀態(tài)應(yīng)用,所以這種情況下一般我們只需要多部署幾個(gè)副本即可,比如這里我們在 Deployment 的 YAML 文件中加上 replicas:3 這個(gè)屬性,這個(gè)時(shí)候有一個(gè)什么問題呢?由于 MySQL 是有狀態(tài)應(yīng)用,每一個(gè) Pod 里面的數(shù)據(jù)庫的數(shù)據(jù)都是獨(dú)立的,他們并沒有共享,也就是說這3個(gè) Pod 相當(dāng)于是獨(dú)立的3個(gè) Wordpress 實(shí)例,所以應(yīng)該怎么辦呢?拆分,把 Wordpress 和 MySQL 這兩個(gè)容器部署成獨(dú)立的 Pod 就可以了,這樣我們只需要對 Wordpress 應(yīng)用增加副本,而數(shù)據(jù)庫 MySQL 還是一個(gè)實(shí)例,所有的應(yīng)用都連接到這一個(gè)數(shù)據(jù)庫上面,是不是就可以解決這個(gè)問題了。
高可用
現(xiàn)在我們將 Pod 中的兩個(gè)容器進(jìn)行拆分,將 Wordpress 和 MySQL 分別部署,然后 Wordpress 用多個(gè)副本進(jìn)行部署就可以實(shí)現(xiàn)應(yīng)用的高可用了,由于 MySQL 是有狀態(tài)應(yīng)用,一般來說需要用 StatefulSet 來進(jìn)行管理,但是我們這里部署的 MySQL 并不是集群模式,而是單副本的,所以用 Deployment 也是沒有問題的,當(dāng)然如果要真正用于生產(chǎn)環(huán)境還是需要集群模式的(MySQL 集群模式可以使用 Operator 部署或者直接使用外部鏈接):(mysql.yaml)
apiVersion: v1
kind: Service
metadata:
name: wordpress-mysql
namespace: kube-example
labels:
app: wordpress
spec:
ports:
- port: 3306
targetPort: dbport
selector:
app: wordpress
tier: mysql
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: wordpress-mysql
namespace: kube-example
labels:
app: wordpress
tier: mysql
spec:
selector:
matchLabels:
app: wordpress
tier: mysql
template:
metadata:
labels:
app: wordpress
tier: mysql
spec:
containers:
- name: mysql
image: mysql:5.7
imagePullPolicy: IfNotPresent
args: # 新版本鏡像有更新,需要使用下面的認(rèn)證插件環(huán)境變量配置才會生效
- --default_authentication_plugin=mysql_native_password
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_unicode_ci
ports:
- containerPort: 3306
name: dbport
env:
- name: MYSQL_ROOT_PASSWORD
value: rootPassW0rd
- name: MYSQL_DATABASE
value: wordpress
- name: MYSQL_USER
value: wordpress
- name: MYSQL_PASSWORD
value: wordpress
我們這里給 MySQL 應(yīng)用添加了一個(gè) Service 對象,是因?yàn)?Wordpress 應(yīng)用需要來連接數(shù)據(jù)庫,之前在同一個(gè) Pod 中用 localhost 即可,現(xiàn)在需要通過 Service 的 DNS 形式的域名進(jìn)行連接。直接創(chuàng)建上面資源對象:
$ kubectl apply -f mysql.yaml
service/wordpress-mysql created
deployment.apps/wordpress-mysql created
接下來創(chuàng)建獨(dú)立的 Wordpress 服務(wù),對應(yīng)的資源對象如下:(wordpress.yaml)
apiVersion: v1
kind: Service
metadata:
name: wordpress
namespace: kube-example
labels:
app: wordpress
spec:
selector:
app: wordpress
tier: frontend
type: NodePort
ports:
- name: web
port: 80
targetPort: wdport
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: wordpress
namespace: kube-example
labels:
app: wordpress
tier: frontend
spec:
replicas: 3
selector:
matchLabels:
app: wordpress
tier: frontend
template:
metadata:
labels:
app: wordpress
tier: frontend
spec:
containers:
- name: wordpress
image: wordpress:5.3.2-apache
ports:
- containerPort: 80
name: wdport
env:
- name: WORDPRESS_DB_HOST
value: wordpress-mysql:3306
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
value: wordpress
注意這里的環(huán)境變量 WORDPRESS_DB_HOST 的值將之前的 localhost 地址更改成了上面 MySQL 服務(wù)的 DNS 地址,完整的域名應(yīng)該是 wordpress-mysql.kube-example.svc.cluster.local:3306,由于這兩個(gè)應(yīng)該都處于同一個(gè)命名空間,所以直接簡寫成 wordpress-mysql:3306 也是可以的。創(chuàng)建上面資源對象:
$ kubectl apply -f wordpress.yaml
service/wordpress created
deployment.apps/wordpress created
$ kubectl get pods -l app=wordpress -n kube-example
NAME READY STATUS RESTARTS AGE
wordpress-6554f9f96c-24rl7 0/1 ContainerCreating 0 6m12s
wordpress-6554f9f96c-4qm5c 1/1 Running 0 6m12s
wordpress-6554f9f96c-wsjhh 0/1 ContainerCreating 0 6m12s
wordpress-mysql-8bbc78ddc-l4c28 1/1 Running 0 13m
可以看到都已經(jīng)是 Running 狀態(tài)了,然后我們需要怎么來驗(yàn)證呢?是不是我們能想到的就是去訪問下我們的 Wordpress 服務(wù)就可以了,我們這里還是使用的一個(gè) NodePort 類型的 Service 來暴露服務(wù):
$ kubectl get svc -l app=wordpress -n kube-example
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
wordpress NodePort 10.96.154.86 <none> 80:30012/TCP 8m15s
wordpress-mysql ClusterIP 10.107.5.168 <none> 3306/TCP 15m
可以看到 wordpress 服務(wù)產(chǎn)生了一個(gè) 30012 的端口,現(xiàn)在我們就可以通過 http://<任意節(jié)點(diǎn)的NodeIP>:30012 訪問我們的應(yīng)用了,在瀏覽器中打開,如果看到 wordpress 跳轉(zhuǎn)到了安裝頁面,證明我們的安裝是正確的,如果沒有出現(xiàn)預(yù)期的效果,那么就需要去查看下 Pod 的日志來排查問題了,根據(jù)頁面提示,填上對應(yīng)的信息,點(diǎn)擊“安裝”即可,最終安裝成功后,我們就可以看到熟悉的首頁界面了:
穩(wěn)定性
現(xiàn)在 Wodpress 應(yīng)用已經(jīng)部署成功了,那么就萬事大吉了嗎?如果我們的網(wǎng)站訪問量突然變大了怎么辦,如果我們要更新我們的鏡像該怎么辦?所以要保證我們的網(wǎng)站能夠非常穩(wěn)定的提供服務(wù),我們做得還不夠,我們可以通過做些什么事情來提高網(wǎng)站的穩(wěn)定性呢?
避免單點(diǎn)故障
為什么會有單點(diǎn)故障的問題呢?我們不是部署了多個(gè)副本的 Wordpress 應(yīng)用嗎?當(dāng)我們設(shè)置 replicas=1 的時(shí)候肯定會存在單點(diǎn)故障問題,如果大于 1 但是所有副本都調(diào)度到了同一個(gè)節(jié)點(diǎn)的是不是同樣就會存在單點(diǎn)問題了,這個(gè)節(jié)點(diǎn)掛了所有副本就都掛了,所以我們不僅需要設(shè)置多個(gè)副本數(shù)量,還需要讓這些副本調(diào)度到不同的節(jié)點(diǎn)上,來打散避免單點(diǎn)故障,這個(gè)利用 Pod 反親和性來實(shí)現(xiàn)了,我們可以加上如下所示的配置:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution: # 軟策略
- weight: 1
podAffinityTerm:
topologyKey: kubernetes.io/hostname
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- wordpress
這里的意思就是如果一個(gè)節(jié)點(diǎn)上面有 app=wordpress 這樣的 Pod 的話,那么我們的 Pod 就盡可能別調(diào)度到這個(gè)節(jié)點(diǎn)上面來,因?yàn)槲覀冞@里的節(jié)點(diǎn)并不多,所以我使用的是軟策略,因?yàn)槿绻褂糜膊呗缘脑挘绻麘?yīng)用副本數(shù)超過了節(jié)點(diǎn)數(shù)就必然會有 Pod 調(diào)度不成功,如果你線上節(jié)點(diǎn)非常多的話(節(jié)點(diǎn)數(shù)大于 Pod 副本數(shù)),建議使用硬策略,更新后我們可以查看下 3 個(gè)副本被分散在了不同的節(jié)點(diǎn)上。
使用 PDB
有些時(shí)候線上的某些節(jié)點(diǎn)需要做一些維護(hù)操作,比如要升級內(nèi)核,這個(gè)時(shí)候我們就需要將要維護(hù)的節(jié)點(diǎn)進(jìn)行驅(qū)逐操作,驅(qū)逐節(jié)點(diǎn)首先是將節(jié)點(diǎn)設(shè)置為不可調(diào)度,這樣可以避免有新的 Pod 調(diào)度上來,然后將該節(jié)點(diǎn)上的 Pod 全部刪除,ReplicaSet 控制器檢測到 Pod 數(shù)量減少了就會重新創(chuàng)建一個(gè)新的 Pod,調(diào)度到其他節(jié)點(diǎn)上面的,這個(gè)過程是先刪除,再創(chuàng)建,并非是滾動(dòng)更新,因此更新過程中,如果一個(gè)服務(wù)的所有副本都在被驅(qū)逐的節(jié)點(diǎn)上,則可能導(dǎo)致該服務(wù)不可用。
如果服務(wù)本身存在單點(diǎn)故障,所有副本都在同一個(gè)節(jié)點(diǎn),驅(qū)逐的時(shí)候肯定就會造成服務(wù)不可用了,這種情況我們使用上面的反親和性和多副本就可以解決這個(gè)問題。但是如果我們的服務(wù)本身就被打散在多個(gè)節(jié)點(diǎn)上,這些節(jié)點(diǎn)如果都被同時(shí)驅(qū)逐的話,那么這個(gè)服務(wù)的所有實(shí)例都會被同時(shí)刪除,這個(gè)時(shí)候也會造成服務(wù)不可用了,這種情況下我們可以通過配置 PDB(PodDisruptionBudget)對象來避免所有副本同時(shí)被刪除,比如我們可以設(shè)置在驅(qū)逐的時(shí)候 wordpress 應(yīng)用最多只有一個(gè)副本不可用,其實(shí)就相當(dāng)于逐個(gè)刪除并在其它節(jié)點(diǎn)上重建:(pdb.yaml)
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: wordpress-pdb
namespace: kube-example
spec:
maxUnavailable: 1
selector:
matchLabels:
app: wordpress
tier: frontend
直接創(chuàng)建這個(gè)資源對象即可:
$ kubectl apply -f pdb.yaml
poddisruptionbudget.policy/wordpress-pdb created
$ kubectl get pdb -n kube-example
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
wordpress-pdb N/A 1 1 10s
關(guān)于 PDB 的更多詳細(xì)信息可以查看官方文檔:https://kubernetes.io/docs/tasks/run-application/configure-pdb/。
健康檢查
我們的應(yīng)用現(xiàn)在還有一個(gè)非常重要的功能沒有提供,那就是健康檢查,我們知道健康檢查是提高應(yīng)用健壯性非常重要的手段,當(dāng)我們檢測到應(yīng)用不健康的時(shí)候我們希望可以自動(dòng)重啟容器,當(dāng)應(yīng)用還沒有準(zhǔn)備好的時(shí)候我們也希望暫時(shí)不要對外提供服務(wù),所以我們需要添加我們前面經(jīng)常提到的 liveness probe 和 rediness probe 兩個(gè)健康檢測探針,檢查探針的方式有很多,我們這里當(dāng)然可以認(rèn)為如果容器的 80 端口可以成功訪問那么就是健康的,對于一般的應(yīng)用提供一個(gè)健康檢查的 URL 會更好,這里我們添加一個(gè)如下所示的可讀性探針,為什么不添加存活性探針呢?這里其實(shí)是考慮到線上錯(cuò)誤排查的一個(gè)問題,如果當(dāng)我們的應(yīng)用出現(xiàn)了問題,然后就自動(dòng)重啟去掩蓋錯(cuò)誤的話,可能這個(gè)錯(cuò)誤就會被永遠(yuǎn)忽略掉了,所以其實(shí)這是一個(gè)折衷的做法,不使用存活性探針,而是結(jié)合監(jiān)控報(bào)警,保留錯(cuò)誤現(xiàn)場,方便錯(cuò)誤排查,但是可讀寫探針是一定需要添加的(最好使用 http 接口進(jìn)行檢查):
readinessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 5
periodSeconds: 5
增加上面的探針,每 5s 檢測一次應(yīng)用是否可讀,這樣只有當(dāng) readinessProbe 探針檢測成功后才表示準(zhǔn)備好接收流量了,這個(gè)時(shí)候才會更新 Service 的 Endpoints 對象。
服務(wù)質(zhì)量 QoS
QoS 是 Quality of Service 的縮寫,即服務(wù)質(zhì)量。為了實(shí)現(xiàn)資源被有效調(diào)度和分配的同時(shí)提高資源利用率,Kubernetes 針對不同服務(wù)質(zhì)量的預(yù)期,通過 QoS 來對 Pod 進(jìn)行服務(wù)質(zhì)量管理。對于一個(gè) Pod 來說,服務(wù)質(zhì)量體現(xiàn)在兩個(gè)具體的指標(biāo):CPU 和內(nèi)存。當(dāng)節(jié)點(diǎn)上內(nèi)存資源緊張時(shí),Kubernetes 會根據(jù)預(yù)先設(shè)置的不同 QoS 類別進(jìn)行相應(yīng)處理。
QoS 主要分為 Guaranteed、Burstable 和 Best-Effort三類,優(yōu)先級從高到低。我們先分別來介紹下這三種服務(wù)類型的定義。
Guaranteed(有保證的)
屬于該級別的 Pod 有以下兩種:
Pod 中的所有容器都且僅設(shè)置了 CPU 和內(nèi)存的 limits Pod 中的所有容器都設(shè)置了 CPU 和內(nèi)存的 requests 和 limits ,且單個(gè)容器內(nèi)的 requests==limits(requests不等于0)
Pod 中的所有容器都且僅設(shè)置了 limits,如下所示:
containers:
- name: foo
resources:
limits:
cpu: 10m
memory: 1Gi
- name: bar
resources:
limits:
cpu: 100m
memory: 100Mi
Pod 中的所有容器都設(shè)置了 requests 和 limits,且單個(gè)容器內(nèi)的 requests==limits 的情況:
containers:
- name: foo
resources:
limits:
cpu: 10m
memory: 1Gi
requests:
cpu: 10m
memory: 1Gi
- name: bar
resources:
limits:
cpu: 100m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
容器 foo 和 bar 內(nèi) resources 的 requests 和 limits 均相等,該 Pod 的 QoS 級別屬于 Guaranteed。
Burstable(不穩(wěn)定的)
Pod 中只要有一個(gè)容器的 requests 和 limits 的設(shè)置不相同,那么該 Pod 的 QoS 即為 Burstable。如下所示容器 foo 指定了 resource,而容器 bar 未指定:
containers:
- name: foo
resources:
limits:
cpu: 10m
memory: 1Gi
requests:
cpu: 10m
memory: 1Gi
- name: bar
容器 foo 設(shè)置了內(nèi)存 limits,而容器 bar 設(shè)置了CPU limits:
containers:
- name: foo
resources:
limits:
memory: 1Gi
- name: bar
resources:
limits:
cpu: 100m
需要注意的是如果容器指定了 requests 而未指定 limits,則 limits 的值等于節(jié)點(diǎn)資源的最大值,如果容器指定了 limits 而未指定 requests,則 requests 的值等于 limits。
Best-Effort(盡最大努力)
如果 Pod 中所有容器的 resources 均未設(shè)置 requests 與 limits,該 Pod 的 QoS 即為 Best-Effort。如下所示容器 foo 和容器 bar 均未設(shè)置requests 和 limits:
containers:
- name: foo
resources:
- name: bar
resources:
資源回收策略
Kubernetes 通過 CGroup 給 Pod設(shè)置 QoS 級別,當(dāng)資源不足時(shí)會優(yōu)先 kill 掉優(yōu)先級低的 Pod,在實(shí)際使用過程中,通過 OOM 分?jǐn)?shù)值來實(shí)現(xiàn),OOM 分?jǐn)?shù)值范圍為 0-1000,OOM 分?jǐn)?shù)值根據(jù) OOM_ADJ參數(shù)計(jì)算得出。
對于 Guaranteed 級別的 Pod,OOM_ADJ 參數(shù)設(shè)置成了-998,對于 Best-Effort 級別的 Pod,OOM_ADJ 參數(shù)設(shè)置成了1000,對于 Burstable 級別的 Pod,OOM_ADJ 參數(shù)取值從 2 到 999。
QoS Pods 被 kill 掉的場景和順序如下所示:
Best-Effort Pods:系統(tǒng)用完了全部內(nèi)存時(shí),該類型 Pods 會最先被 kill 掉 Burstable Pods:系統(tǒng)用完了全部內(nèi)存,且沒有 Best-Effort 類型的容器可以被 kill 時(shí),該類型的 Pods 會被 kill 掉 Guaranteed Pods:系統(tǒng)用完了全部內(nèi)存,且沒有 Burstable 與 Best-Effort 類型的容器可以被 kill 時(shí),該類型的 pods 會被 kill 掉
所以如果資源充足,可將 QoS Pods 類型設(shè)置為 Guaranteed,用計(jì)算資源換業(yè)務(wù)性能和穩(wěn)定性,減少排查問題時(shí)間和成本。如果想更好的提高資源利用率,業(yè)務(wù)服務(wù)可以設(shè)置為 Guaranteed,而其他服務(wù)根據(jù)重要程度可分別設(shè)置為 Burstable 或 Best-Effort,這就要看具體的場景了。
比如我們這里如果想要盡可能提高 Wordpress 應(yīng)用的穩(wěn)定性,我們可以將其設(shè)置為 Guaranteed 類型的 Pod,我們現(xiàn)在沒有設(shè)置 resources 資源,所以現(xiàn)在是 Best-Effort 類型的 Pod。
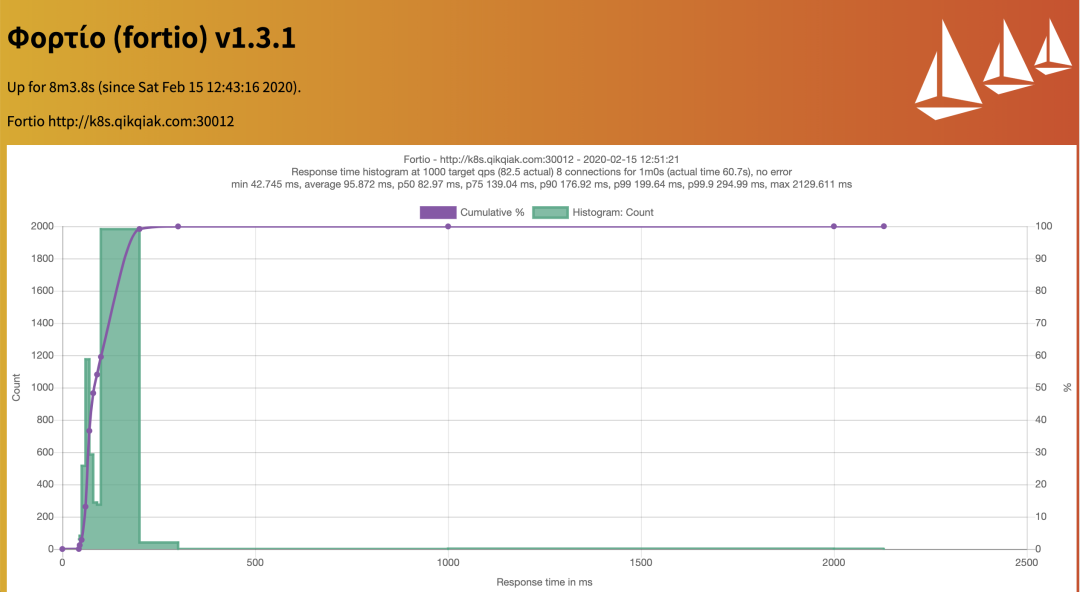
現(xiàn)在如果要想給應(yīng)用設(shè)置資源大小,就又有一個(gè)問題了,應(yīng)該如何設(shè)置合適的資源大小呢?其實(shí)這就需要我們對自己的應(yīng)用非常了解才行了,一般情況下我們可以先不設(shè)置資源,然后可以根據(jù)我們的應(yīng)用的并發(fā)和訪問量來進(jìn)行壓力測試,基本上可以大概計(jì)算出應(yīng)用的資源使用量,我們這里可以使用 Apache Bench(AB Test) 或者 Fortio(Istio 測試工具) 這樣的測試工具來測試,我們這里使用 Fortio 這個(gè)測試工具,比如每秒 1000 個(gè)請求和 8 個(gè)并發(fā)的連接的測試命令如下所示:
$ fortio load -a -c 8 -qps 1000 -t 60s "http://k8s.qikqiak.com:30012"
Starting at 1000 qps with 8 thread(s) [gomax 2] for 1m0s : 7500 calls each (total 60000)
Ended after 1m0.687224615s : 5005 calls. qps=82.472
Aggregated Sleep Time : count 5005 avg -27.128368 +/- 16 min -55.964246789 max -0.050576982 sum -135777.482
[......]
Sockets used: 53 (for perfect keepalive, would be 8)
Code 200 : 5005 (100.0 %)
Response Header Sizes : count 5005 avg 292.17083 +/- 1.793 min 292 max 311 sum 1462315
Response Body/Total Sizes : count 5005 avg 27641.171 +/- 1.793 min 27641 max 27660 sum 138344060
Saved result to data/2020-02-15-125121_Fortio.json (graph link)
All done 5005 calls 95.872 ms avg, 82.5 qps
也可以通過瀏覽器查看到最終測試結(jié)果:
在測試期間我們可以用如下所示的命令查看應(yīng)用的資源使用情況:
$ kubectl top pods -l app=wordpress -n kube-example
NAME CPU(cores) MEMORY(bytes)
wordpress-5cc66f986b-2jv7h 569m 72Mi
wordpress-5cc66f986b-nf79l 997m 71Mi
wordpress-d4c885d5d-gtvhd 895m 87Mi
我們可以看到內(nèi)存基本上都是處于 100Mi 以內(nèi),而 CPU 消耗就非常大了,但是由于 CPU 是可壓縮資源,也就是說超過了限制應(yīng)用也不會掛掉的,只是會變慢而已。所以我們這里可以給 Wordpress 應(yīng)用添加如下所示的資源配置,如果你集群資源足夠的話可以適當(dāng)多分配一些資源:
resources:
limits:
cpu: 200m
memory: 100Mi
requests:
cpu: 200m
memory: 100Mi
滾動(dòng)更新
Deployment 控制器默認(rèn)的就是滾動(dòng)更新的更新策略,該策略可以在任何時(shí)間點(diǎn)更新應(yīng)用的時(shí)候保證某些實(shí)例依然可以正常運(yùn)行來防止應(yīng)用 down 掉,當(dāng)新部署的 Pod 啟動(dòng)并可以處理流量之后,才會去殺掉舊的 Pod。在使用過程中我們還可以指定 Kubernetes 在更新期間如何處理多個(gè)副本的切換方式,比如我們有一個(gè)3副本的應(yīng)用,在更新的過程中是否應(yīng)該立即創(chuàng)建這3個(gè)新的 Pod 并等待他們?nèi)繂?dòng),或者殺掉一個(gè)之外的所有舊的 Pod,或者還是要一個(gè)一個(gè)的 Pod 進(jìn)行替換?
如果我們從舊版本到新版本進(jìn)行滾動(dòng)更新,只是簡單的通過輸出顯示來判斷哪些 Pod 是存活并準(zhǔn)備就緒的,那么這個(gè)滾動(dòng)更新的行為看上去肯定就是有效的,但是往往實(shí)際情況就是從舊版本到新版本的切換的過程并不總是十分順暢的,應(yīng)用程序很有可能會丟棄掉某些客戶端的請求。比如我們在 Wordpress 應(yīng)用中添加上如下的滾動(dòng)更新策略,隨便更改以下 Pod Template 中的參數(shù),比如容器名更改為 blog:
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
然后更新應(yīng)用,同時(shí)用 Fortio 工具在滾動(dòng)更新過程中來測試應(yīng)用是否可用:
$ kubectl apply -f wordpress.yaml
$ fortio load -a -c 8 -qps 1000 -t 60s "http://k8s.qikqiak.com:30012"
Starting at 1000 qps with 8 thread(s) [gomax 2] for 1m0s : 7500 calls each (total 60000)
Ended after 1m0.006243654s : 5485 calls. qps=91.407
Aggregated Sleep Time : count 5485 avg -17.626081 +/- 15 min -54.753398956 max 0.000709054 sum -96679.0518
[...]
Code 200 : 5463 (99.6 %)
Code 502 : 20 (0.4 %)
Response Header Sizes : count 5485 avg 213.14166 +/- 13.53 min 0 max 214 sum 1169082
Response Body/Total Sizes : count 5485 avg 823.18651 +/- 44.41 min 0 max 826 sum 4515178
[...]
從上面的輸出可以看出有部分請求處理失敗了(502),要弄清楚失敗的原因就需要弄明白當(dāng)應(yīng)用在滾動(dòng)更新期間重新路由流量時(shí),從舊的 Pod 實(shí)例到新的實(shí)例究竟會發(fā)生什么,首先讓我們先看看 Kubernetes 是如何管理工作負(fù)載連接的。
失敗原因
我們這里通過 NodePort 去訪問應(yīng)用,實(shí)際上也是通過每個(gè)節(jié)點(diǎn)上面的 kube-proxy 通過更新 iptables 規(guī)則來實(shí)現(xiàn)的。
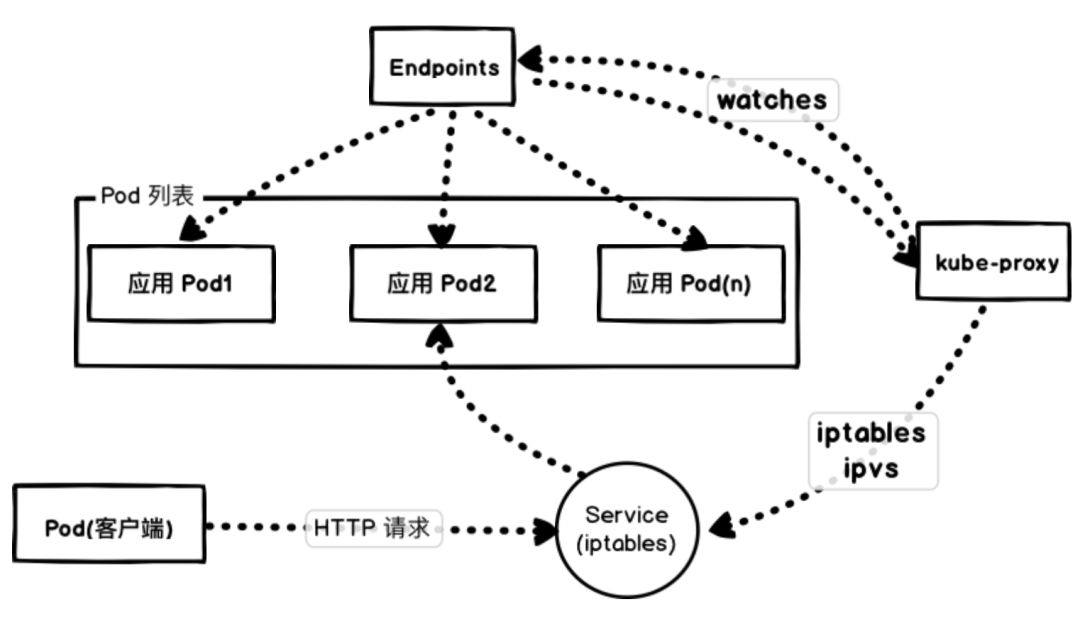
Kubernetes 會根據(jù) Pods 的狀態(tài)去更新 Endpoints 對象,這樣就可以保證 Endpoints 中包含的都是準(zhǔn)備好處理請求的 Pod。一旦新的 Pod 處于活動(dòng)狀態(tài)并準(zhǔn)備就緒后,Kubernetes 就將會停止就的 Pod,從而將 Pod 的狀態(tài)更新為 “Terminating”,然后從 Endpoints 對象中移除,并且發(fā)送一個(gè) SIGTERM 信號給 Pod 的主進(jìn)程。SIGTERM 信號就會讓容器以正常的方式關(guān)閉,并且不接受任何新的連接。Pod 從 Endpoints 對象中被移除后,前面的負(fù)載均衡器就會將流量路由到其他(新的)Pod 中去。因?yàn)樵谪?fù)載均衡器注意到變更并更新其配置之前,終止信號就會去停用 Pod,而這個(gè)重新配置過程又是異步發(fā)生的,并不能保證正確的順序,所以就可能導(dǎo)致很少的請求會被路由到已經(jīng)終止的 Pod 上去了,也就出現(xiàn)了上面我們說的情況。
零宕機(jī)
那么如何增強(qiáng)我們的應(yīng)用程序以實(shí)現(xiàn)真正的零宕機(jī)遷移更新呢?
首先,要實(shí)現(xiàn)這個(gè)目標(biāo)的先決條件是我們的容器要正確處理終止信號,在 SIGTERM 信號上實(shí)現(xiàn)優(yōu)雅關(guān)閉。下一步需要添加 readiness 可讀探針,來檢查我們的應(yīng)用程序是否已經(jīng)準(zhǔn)備好來處理流量了。為了解決 Pod 停止的時(shí)候不會阻塞并等到負(fù)載均衡器重新配置的問題,我們還需要使用 preStop 這個(gè)生命周期的鉤子,在容器終止之前調(diào)用該鉤子。
生命周期鉤子函數(shù)是同步的,所以必須在將最終停止信號發(fā)送到容器之前完成,在我們的示例中,我們使用該鉤子簡單的等待,然后 SIGTERM 信號將停止應(yīng)用程序進(jìn)程。同時(shí),Kubernetes 將從 Endpoints 對象中刪除該 Pod,所以該 Pod 將會從我們的負(fù)載均衡器中排除,基本上來說我們的生命周期鉤子函數(shù)等待的時(shí)間可以確保在應(yīng)用程序停止之前重新配置負(fù)載均衡器:
readinessProbe:
# ...
lifecycle:
preStop:
exec:
command: ["/bin/bash", "-c", "sleep 20"]
我們這里使用 preStop 設(shè)置了一個(gè) 20s 的寬限期,Pod 在真正銷毀前會先 sleep 等待 20s,這就相當(dāng)于留了時(shí)間給 Endpoints 控制器和 kube-proxy 更新去 Endpoints 對象和轉(zhuǎn)發(fā)規(guī)則,這段時(shí)間 Pod 雖然處于 Terminating 狀態(tài),即便在轉(zhuǎn)發(fā)規(guī)則更新完全之前有請求被轉(zhuǎn)發(fā)到這個(gè) Terminating 的 Pod,依然可以被正常處理,因?yàn)樗€在 sleep,沒有被真正銷毀。
現(xiàn)在,當(dāng)我們?nèi)ゲ榭礉L動(dòng)更新期間的 Pod 行為時(shí),我們將看到正在終止的 Pod 處于 Terminating 狀態(tài),但是在等待時(shí)間結(jié)束之前不會關(guān)閉的,如果我們使用 Fortio 重新測試下,則會看到零失敗請求的理想狀態(tài)。
HPA
現(xiàn)在應(yīng)用是固定的3個(gè)副本,但是往往在生產(chǎn)環(huán)境流量是不可控的,很有可能一次活動(dòng)就會有大量的流量,3個(gè)副本很有可能抗不住大量的用戶請求,這個(gè)時(shí)候我們就希望能夠自動(dòng)對 Pod 進(jìn)行伸縮,直接使用前面我們學(xué)習(xí)的 HPA 這個(gè)資源對象就可以滿足我們的需求了。
直接使用kubectl autoscale命令來創(chuàng)建一個(gè) HPA 對象
$ kubectl autoscale deployment wordpress --namespace kube-example --cpu-percent=20 --min=3 --max=6
horizontalpodautoscaler.autoscaling/hpa-demo autoscaled
$ kubectl get hpa -n kube-example
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
wordpress Deployment/wordpress <unknown>/20% 3 6 0 13s
此命令創(chuàng)建了一個(gè)關(guān)聯(lián)資源 wordpress 的 HPA,最小的 Pod 副本數(shù)為3,最大為6。HPA 會根據(jù)設(shè)定的 cpu 使用率(20%)動(dòng)態(tài)的增加或者減少 Pod 數(shù)量。同樣,使用上面的 Fortio 工具來進(jìn)行壓測一次,看下能否進(jìn)行自動(dòng)的擴(kuò)縮容:
$ fortio load -a -c 8 -qps 1000 -t 60s "http://k8s.qikqiak.com:30012"
在壓測的過程中我們可以看到 HPA 的狀態(tài)變化以及 Pod 數(shù)量也變成了6個(gè):
$ kubectl get hpa -n kube-example
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
wordpress Deployment/wordpress 98%/20% 3 6 6 2m40s
$ kubectl get pods -n kube-example
NAME READY STATUS RESTARTS AGE
wordpress-79d756cbc8-f6kfm 1/1 Running 0 21m
wordpress-79d756cbc8-kspch 1/1 Running 0 32s
wordpress-79d756cbc8-sf5rm 1/1 Running 0 32s
wordpress-79d756cbc8-tsjmf 1/1 Running 0 20m
wordpress-79d756cbc8-v9p7n 1/1 Running 0 32s
wordpress-79d756cbc8-z4wpp 1/1 Running 0 21m
wordpress-mysql-5756ccc8b-zqstp 1/1 Running 0 3d19h
當(dāng)壓測停止以后正常5分鐘后就會自動(dòng)進(jìn)行縮容,變成最小的3個(gè) Pod 副本。
安全性
安全性這個(gè)和具體的業(yè)務(wù)應(yīng)用有關(guān)系,比如我們這里的 Wordpress 也就是數(shù)據(jù)庫的密碼屬于比較私密的信息,我們可以使用 Kubernetes 中的 Secret 資源對象來存儲比較私密的信息:
$ kubectl create secret generic wordpress-db-pwd --from-literal=dbpwd=wordpress -n kube-example
secret/wordpress-db-pwd created
然后將 Deployment 資源對象中的數(shù)據(jù)庫密碼環(huán)境變量通過 Secret 對象讀取:
env:
- name: WORDPRESS_DB_HOST
value: wordpress-mysql:3306
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: wordpress-db-pwd
key: dbpwd
這樣我們就不會在 YAML 文件中看到明文的數(shù)據(jù)庫密碼了,當(dāng)然安全性都是相對的,Secret 資源對象也只是簡單的將密碼做了一次 Base64 編碼而已,對于一些特殊場景安全性要求非常高的應(yīng)用,就需要使用其他功能更加強(qiáng)大的密碼系統(tǒng)來進(jìn)行管理了,比如 Vault。
持久化
現(xiàn)在還有一個(gè)比較大的問題就是我們的數(shù)據(jù)還沒有做持久化,MySQL 數(shù)據(jù)庫沒有做,Wordpress 應(yīng)用本身也沒有做,這顯然不是一個(gè)合格的線上應(yīng)用。這里我們直接使用前面章節(jié)中創(chuàng)建的 rook-ceph-block 這個(gè) StorageClass 來創(chuàng)建我們的數(shù)據(jù)庫存儲后端:(pvc.yaml)
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pvc
namespace: kube-example
labels:
app: wordpress
spec:
storageClassName: rook-ceph-block
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
但是由于 Wordpress 應(yīng)用是多個(gè)副本,所以需要同時(shí)在多個(gè)節(jié)點(diǎn)進(jìn)行讀寫,也就是 accessModes 需要 ReadWriteMany 模式,而 Ceph RBD 模式是不支持 RWM 的,所以需要使用 CephFS,首先需要在 Ceph 中創(chuàng)建一個(gè) Filesystem,這里我們可以通過 Rook 的 CephFilesystem 資源對象創(chuàng)建,如下所示:
apiVersion: ceph.rook.io/v1
kind: CephFilesystem
metadata:
name: myfs
namespace: rook-ceph
spec:
metadataPool:
replicated:
size: 3
dataPools:
- replicated:
size: 3
metadataServer:
activeCount: 1
activeStandby: true
創(chuàng)建完成后還會生成一個(gè)名為 myfs-data0 的存儲池,也會自動(dòng)生成兩個(gè) MDS 的 Pod 服務(wù):
$ kubectl get pods -n rook-ceph |grep myfs
rook-ceph-mds-myfs-a-7948557994-44c4f 1/1 Running 0 11m
rook-ceph-mds-myfs-b-5976b868cc-gl86g 1/1 Running 0 11m
這個(gè)時(shí)候就可以創(chuàng)建我們的 StorageClass 對象了:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: csi-cephfs
provisioner: rook-ceph.cephfs.csi.ceph.com
parameters:
clusterID: rook-ceph
# 上面創(chuàng)建的 CephFS 文件系統(tǒng)名稱
fsName: myfs
# 自動(dòng)生成的
pool: myfs-data0
# Root path of an existing CephFS volume
# Required for provisionVolume: "false"
# rootPath: /absolute/path
# The secrets contain Ceph admin credentials. These are generated automatically by the operator
# in the same namespace as the cluster.
csi.storage.k8s.io/provisioner-secret-name: rook-csi-cephfs-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph
csi.storage.k8s.io/controller-expand-secret-name: rook-csi-cephfs-provisioner
csi.storage.k8s.io/controller-expand-secret-namespace: rook-ceph
csi.storage.k8s.io/node-stage-secret-name: rook-csi-cephfs-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph
reclaimPolicy: Retain
allowVolumeExpansion: true
mountOptions:
同樣直接創(chuàng)建上面的 StorageClass 資源對象即可,現(xiàn)在 Wordpress 的 PVC 對象使用我們這里的 csi-cephfs 這個(gè) StorageClass 對象:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: wordpress-pvc
namespace: kube-example
labels:
app: wordpress
spec:
storageClassName: csi-cephfs
accessModes:
- ReadWriteMany # 由于是多個(gè)Pod所以要用 RWM
resources:
requests:
storage: 2Gi
直接創(chuàng)建上面的資源對象:
$ kubectl get pvc -n kube-example
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mysql-pvc Bound pvc-93e0b186-da20-4e5e-8414-8cc73e00bf64 20Gi RWO rook-ceph-block 45m
wordpress-pvc Bound pvc-87675c58-407a-4b7e-be9d-0733f67c4835 2Gi RWX csi-cephfs 5s
在使用 CephFS 的過程中遇到了上面的 PVC 一直處于 Pending 狀態(tài),然后 describe 后發(fā)現(xiàn)有如下所示的錯(cuò)誤信息:
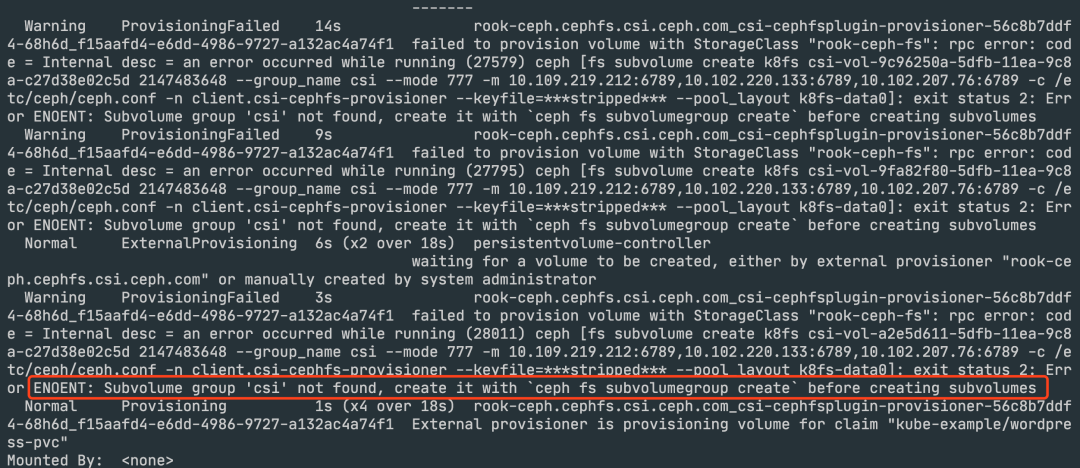
從錯(cuò)誤信息上面來看是在通過 StorageClass 去自動(dòng)創(chuàng)建 PV 的時(shí)候就出現(xiàn)了問題,所以我們需要去檢查 CSI 的 attach 階段:
$ kubectl get pods -n rook-ceph |grep csi-cephfsplugin-provisioner
csi-cephfsplugin-provisioner-56c8b7ddf4-4s7fd 4/4 Running 0 18m
csi-cephfsplugin-provisioner-56c8b7ddf4-55sg6 4/4 Running 0 39m
然后查看這兩個(gè) Pod 的日志發(fā)現(xiàn)都是類似于下面的錯(cuò)誤:
I0304 10:04:04.823171 1 leaderelection.go:246] failed to acquire lease rook-ceph/rook-ceph-cephfs-csi-ceph-com
I0304 10:04:14.344109 1 leaderelection.go:350] lock is held by csi-cephfsplugin-provisioner-56c8b7ddf4-rq4t6 and has not yet expired
因?yàn)槲覀冞@里有兩個(gè)副本的 Provisioner,正常應(yīng)該是有一個(gè)提供服務(wù),另外一個(gè)作為備用的,通過獲取到分布式鎖來表示當(dāng)前的 Pod 是否是 leader,這里兩個(gè) Pod 都沒獲取到,應(yīng)該就是出現(xiàn)了通信問題,然后將兩個(gè) Pod 都重建后,其中一個(gè) Pod 便獲取到了 lease 對象,然后 PVC 也成功綁定上了 PV。
可以看到上面的 PVC 已經(jīng)自動(dòng)綁定到 PV 上面去了,這個(gè)就是上面的 StorageClass 完成的工作。然后在 Wordpress 應(yīng)用上添加對 /var/www/html 目錄的掛載聲明:
volumeMounts:
- name: wordpress-data
mountPath: /var/www/html
volumes:
- name: wordpress-data
persistentVolumeClaim:
claimName: wordpress-pvc
在 MySQL 應(yīng)用上添加對 /var/lib/mysql 目錄的掛載聲明:
volumeMounts:
- name: mysql-data
mountPath: /var/lib/mysql
volumes:
- name: mysql-data
persistentVolumeClaim:
claimName: mysql-pvc
重新更新應(yīng)用即可,在更新的過程中發(fā)現(xiàn) MySQL 啟動(dòng)失敗了,報(bào)如下所示的錯(cuò)誤:
......
[ERROR] --initialize specified but the data directory has files in it. Aborting.
意思就是 /var/lib/mysql 目錄下面已經(jīng)有數(shù)據(jù)了,當(dāng)然可以清空該目錄然后重新創(chuàng)建即可,這里可能是 mysql:5.7 這個(gè)鏡像的 BUG,所以我們更改成 mysql:5.6 這個(gè)鏡像,去掉之前添加的一個(gè)認(rèn)證參數(shù):
containers:
- image: mysql:5.6
name: mysql
imagePullPolicy: IfNotPresent
args:
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_unicode_ci
重新更新就可以正常啟動(dòng)了。
Ingress
對于一個(gè)線上的應(yīng)用對外暴露服務(wù)用一個(gè)域名顯然是更加合適的,上面我們使用的 NodePort 類型的服務(wù)不適合用于線上生產(chǎn)環(huán)境,這里我們通過 Ingress 對象來暴露服務(wù),由于我們使用的是 Traefik2.1 這個(gè) Ingress 控制器,所以通過 IngressRoute 對象來暴露我們的服務(wù),此外為了安全我們還使用了 ACME 來自動(dòng)獲取 https 的證書,并且通過一個(gè)中間件將 http 強(qiáng)制跳轉(zhuǎn)到 https 服務(wù):(ingressroute.yaml)
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: wordpress-https
namespace: kube-example
spec:
entryPoints:
- websecure
routes:
- match: Host(`wordpress.qikqiak.com`)
kind: Rule
services:
- name: wordpress
port: 80
tls:
certResolver: ali
domains:
- main: "*.qikqiak.com"
---
apiVersion: traefik.containo.us/v1alpha1
kind: Middleware
metadata:
name: redirect-https
namespace: kube-example
spec:
redirectScheme:
scheme: https
---
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: wordpress-http
namespace: kube-example
spec:
entryPoints:
- web
routes:
- match: Host(`wordpress.qikqiak.com`)
kind: Rule
services:
- name: wordpress
port: 80
middlewares:
- name: redirect-https
直接創(chuàng)建上面的資源對象即可:
$ kubectl apply -f ingressroute.yaml
ingressroute.traefik.containo.us/wordpress-https created
middleware.traefik.containo.us/redirect-https created
ingressroute.traefik.containo.us/wordpress-http created
然后對域名 wordpress.qikqiak.com 加上對應(yīng)的 DNS 解析即可正常訪問了,這樣即使我們的數(shù)據(jù)庫或者 Wordpress 應(yīng)用掛掉了也不會丟失數(shù)據(jù)了,到這里就完成了我們一個(gè)生產(chǎn)級別應(yīng)用的部署,雖然應(yīng)用本身很簡單,但是如果真的要部署到生產(chǎn)環(huán)境我們需要關(guān)注的內(nèi)容就比較多了,當(dāng)然對于線上應(yīng)用除了上面我們提到的還有很多值得我們關(guān)注的地方,比如監(jiān)控報(bào)警、日志收集等方面都是我們關(guān)注的層面。