
Presto 原理 | 一文理解 Presto 兩種 JOIN 算法實(shí)現(xiàn)
JOIN 的實(shí)現(xiàn)
幾乎所有的數(shù)據(jù)庫(kù)引擎一次只 JOIN 兩個(gè)表。即使在 SQL 查詢中有兩個(gè)以上的表要聯(lián)接,數(shù)據(jù)庫(kù)也會(huì)聯(lián)接前兩個(gè)表并將輸出與第三個(gè)表聯(lián)接起來,然后對(duì)其余表繼續(xù)這樣做。數(shù)據(jù)庫(kù)工程師將連接操作中涉及的這兩個(gè)表稱為構(gòu)建表(Build Table)和探測(cè)表(Probe Table)。
Build Table
構(gòu)建表是用于創(chuàng)建內(nèi)存索引的表。通常,在讀取探測(cè)表之前必須完整讀取構(gòu)建表。
Probe Table
一旦構(gòu)建表被讀取并存儲(chǔ)在內(nèi)存中,探測(cè)表就會(huì)被逐行讀取。從探測(cè)表讀取的每一行都將根據(jù) join criteria 與構(gòu)建表進(jìn)行連接。
如果想及時(shí)了解Spark、Hadoop或者HBase相關(guān)的文章,歡迎關(guān)注微信公眾號(hào):過往記憶大數(shù)據(jù)
Presto 使用優(yōu)化后的邏輯計(jì)劃中的右表作為構(gòu)建表,將邏輯計(jì)劃中的左表作為探測(cè)表。請(qǐng)注意,邏輯計(jì)劃中的表不必與它們?cè)?SQL 查詢中的順序相同。Presto 有一些基于成本的優(yōu)化器,它們可以重新排序連接以將最小的表(即構(gòu)建表)保留在右側(cè),以便它可以放入內(nèi)存中。如果連接重新排序優(yōu)化器被禁用或連接器特定的統(tǒng)計(jì)信息(例如 Hive 統(tǒng)計(jì)信息)被禁用,則 Presto 將不會(huì)對(duì)連接查詢重新排序。在這種情況下,建議將最小的表保留在連接的右側(cè),以便 Presto 可以將其用作構(gòu)建表。
JOIN 算法
數(shù)據(jù)庫(kù)根據(jù)數(shù)據(jù)類型和連接類型使用不同的算法來連接兩個(gè)表。例如,SQL Server 使用 Nested Loop 算法、Merge Join 算法、Hash Join 算法和 Adaptive Join 算法。在撰寫本文時(shí),開源的 Presto SQL 引擎采用 Nested Loop 算法和 Hash Join 算法來支持 Presto 中所有不同聯(lián)接類型。本節(jié)簡(jiǎn)要說明Nested Loop 算法和 Hash Join 算法,并討論其他算法在 Presto 中的適用性以提高性能。
Nested Loop Algorithm
顧名思義,嵌套循環(huán)算法使用嵌套循環(huán)連接兩個(gè)表。下面使用一個(gè)數(shù)組連接示例來解釋嵌套循環(huán)連接算法。假設(shè)你有兩個(gè)整數(shù)數(shù)組,并要求你打印這些數(shù)組的笛卡爾積,你會(huì)如何解決這個(gè)問題?下面給出了一種簡(jiǎn)單的方法來打印兩個(gè)數(shù)組的笛卡爾積。
public class IteblogNestedLoop {public static void main(String[] args) {// Construct two arraysint[] tableA = {1, 2, 3, 4, 5, 6};int[] tableB = {10, 20, 30, 40};// Nested loop to print the Cartesian product of two arraysfor (int x : tableA) {for (int y : tableB) {System.out.println(x + ", " + y);}}}}
上面的代碼使用兩個(gè)循環(huán)來打印兩個(gè)數(shù)組的笛卡爾積。嵌套循環(huán)算法的時(shí)間復(fù)雜度為 O(n2),因?yàn)樗仨殞⑻綔y(cè)表中的每一行與構(gòu)建表中的每一行連接起來。由于需要每個(gè)組合,交叉連接操作的執(zhí)行時(shí)間復(fù)雜度不能超過 O(n2)。Presto 使用嵌套循環(huán)算法來執(zhí)行 cross join 操作,這就是為什么如果連接表非常大,cross join 需要很長(zhǎng)時(shí)間。由于 O(n2) 時(shí)間復(fù)雜度,不建議在沒有連接條件的情況下連接兩個(gè)大表。
Hash Join Algorithm
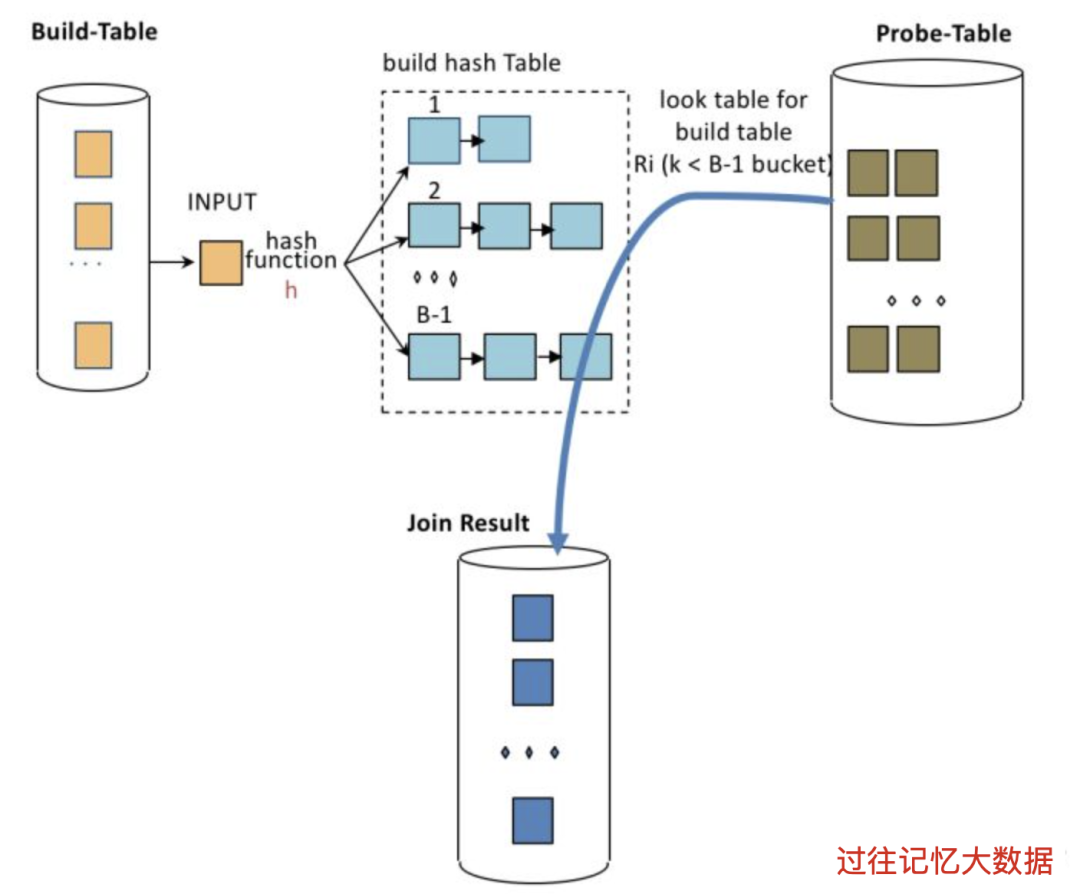
哈希連接算法為構(gòu)建表中的列生成哈希鍵,這些列是用于 JOIN 條件中的,比如 left.x = right.y AND left.z = right.w。每個(gè)這樣的相等條件稱為連接相等條件(join equi criteria)。盡管 equi criteria 術(shù)語(yǔ)在數(shù)據(jù)庫(kù)領(lǐng)域被廣泛使用,但它們也被稱為相等條件。為了使用哈希算法,讓我們考慮一個(gè)打印所有客戶及其訂單信息的問題。這個(gè)問題中使用的 Customer 和 Order 類定義如下。請(qǐng)注意,這兩個(gè)類都有一個(gè)共同的屬性:custKey。
class Order {String orderKey;String custKey;double totalPrice;public Order(String orderKey, String custKey, double totalPrice) {this.orderKey = orderKey;this.custKey = custKey;this.totalPrice = totalPrice;}@Overridepublic String toString() {return "Order: " + orderKey + ", " + custKey + ", " + totalPrice;}}class Customer {String custKey;String name;public Customer(String custKey, String name) {this.custKey = custKey;this.name = name;}@Overridepublic String toString() {return "Customer: " + name + ", " + custKey;}}
回到問題:我們?nèi)绾未蛴∷锌蛻艏捌溆唵危苛私馇短籽h(huán)算法后,可以簡(jiǎn)單地在循環(huán)內(nèi)應(yīng)用帶有 if 條件的嵌套循環(huán)算法,如下所示:
import java.util.*;public class IteblogHashJoin {public static void main(String[] args) {List<Customer> probe = List.of(new Customer("c_001", "Alice"),new Customer("c_002", "Bob"),new Customer("c_003", "David"));List<Order> build = List.of(new Order("o_01", "c_001", 100.0),new Order("o_01", "c_001", 100.0),new Order("o_02", "c_001", 150.0),new Order("o_03", "c_002", 90.0),new Order("o_04", "c_003", 120.0));// Nested loop joinfor (Customer customer : probe) {for (Order order : build) {if (Objects.equals(customer.custKey, order.custKey)) {System.out.println(customer + " -> " + order);}}}}}
盡管嵌套循環(huán)連接可以達(dá)到我們的要求,但它的效率很低,因?yàn)樗诮o定 n 個(gè)客戶和 n 個(gè)訂單的情況下迭代 n2 次。一個(gè)有效的解決方案可以使用一個(gè) Hashtable 來存儲(chǔ)所有訂單,使用相同的連接條件:custKey 作為哈希鍵。然后在遍歷 Customer 列表時(shí),可以生成 Customer 的散列值。獲取具有相同custKey 的訂單列表,如下所示:
import java.util.*;public class IteblogHashJoin {public static void main(String[] args) {List<Customer> probe = List.of(new Customer("c_001", "Alice"),new Customer("c_002", "Bob"),new Customer("c_003", "David"));List<Order> build = List.of(new Order("o_01", "c_001", 100.0),new Order("o_01", "c_001", 100.0),new Order("o_02", "c_001", 150.0),new Order("o_03", "c_002", 90.0),new Order("o_04", "c_003", 120.0));// Build the hash map indexMap<Integer, List<Order>> index = new Hashtable<>();for (Order order : build) {int hash = Objects.hash(order.custKey);index.putIfAbsent(hash, new LinkedList<>());index.get(hash).add(order);}// Hash Join algorithmfor (Customer customer : probe) {int hash = Objects.hash(customer.custKey);List<Order> orders = index.get(hash);if (orders != null) {for (Order order : orders) {if (Objects.equals(customer.custKey, order.custKey)) {System.out.println(customer + " -> " + order);}}}}}}
在上述算法中,使用單獨(dú)的 LinkedList 來避免哈希沖突,因?yàn)橥豢蛻粝露鄠€(gè)訂單的可能性很高。使用 equijoin criteria 里面列的哈希值用于將構(gòu)建表存儲(chǔ)在存儲(chǔ)桶中。然后將相同的散列算法應(yīng)用于探測(cè)表的 equijoin criteria 列以查找包含匹配項(xiàng)的桶。盡管 Hash Join 算法的最壞情況時(shí)間復(fù)雜度是 O(n2),但平均情況下預(yù)計(jì)為 O(n)。
上述問題可以定義為下面給出的 SQL 查詢,以將 Customer 表與 Orders 表連接起來。
SELECT *FROM iteblog.customer cLEFT JOIN iteblog.orders oON c.custkey=o.orderkey;
具有等連接條件的所有連接操作都使用Presto中的哈希連接算法執(zhí)行。然而,連接操作并不局限于等效連接標(biāo)準(zhǔn)。例如,如果列值大于或小于另一列的值,則可以連接兩個(gè)表,如下查詢所示:
所有具有 equijoin criteria 的連接操作都使用 Presto 中的哈希連接算法執(zhí)行。但是,連接操作不限于 equijoin criteria。例如,如果列值大于或小于另一列的值,則可以連接兩個(gè)表,如下面的查詢:
SELECT o.orderkey, l.linenumberFROM iteblog.orderkey oLEFT JOIN iteblog.lineitem lON o.orderdate < l.shipdate;
Hash Join 算法不適用于具有不等式約束的 join 條件。首先,很難提出一個(gè)完美的散列算法來保持輸入的不等式屬性(即給定 x > b 并不能保證 hash(a) > hash(b))。其次,即使我們提出了一個(gè)滿足不等式要求的散列函數(shù),我們也不能簡(jiǎn)單地連接一個(gè)桶中的所有值。要加入不相等的行,應(yīng)該匹配大于/小于給定列的每一行。因此,Presto 使用帶 filter 的嵌套循環(huán)算法而不是散列連接算法來執(zhí)行具有非等連接條件的連接。
盡管開源的 Presto SQL 僅使用 Nested Loop 算法和 Hash Join 算法進(jìn)行連接操作,但 Merge Join 是關(guān)系數(shù)據(jù)庫(kù)中使用的另一種眾所周知的算法,有一些大數(shù)據(jù)計(jì)算引擎也支持 Merge Join ,比如 Spark。以下部分介紹了 Merge Join 算法,并解釋了 Presto 社區(qū)為何不考慮添加對(duì) Merge Join 算法的支持。
Merge Join
Merge Join 算法來自著名的 Merge-Sort 算法。歸并排序算法有兩個(gè)階段:排序和合并。假設(shè)兩個(gè)數(shù)組已經(jīng)排序,它們可以以 O(n) 的時(shí)間復(fù)雜度合并。Presto 可以通過使用 equijoin criteria 中使用的列對(duì)構(gòu)建表和探測(cè)表進(jìn)行排序,然后通過執(zhí)行合并操作來實(shí)現(xiàn)該算法。忽略排序部分,merge join 算法的性能有望優(yōu)于上述算法,但 Presto 社區(qū)發(fā)現(xiàn)它需要在內(nèi)存中對(duì)兩個(gè)表進(jìn)行排序,這在大數(shù)據(jù)世界中很耗時(shí),考慮到有限的內(nèi)存,甚至可能是不可行的。但是,如果有機(jī)會(huì)在底層數(shù)據(jù)源中對(duì)數(shù)據(jù)進(jìn)行排序,則合并連接算法可能是一個(gè)更好的候選算法。
在我看來,如果構(gòu)建表足夠小可以容納在內(nèi)存中,那么對(duì)它進(jìn)行排序并使用二分搜索算法將探測(cè)表行與構(gòu)建表進(jìn)行比較不會(huì)是一個(gè)糟糕的選擇。它可以改進(jìn)具有不等式條件(例如大于或小于)的連接操作。Presto 還支持關(guān)系數(shù)據(jù)庫(kù),與大數(shù)據(jù)存儲(chǔ)相比,這些數(shù)據(jù)庫(kù)的數(shù)據(jù)量通常較少。如果連接來自關(guān)系數(shù)據(jù)庫(kù)的兩個(gè)表,或者來自關(guān)系數(shù)據(jù)庫(kù)的表與來自 Hadoop 文件存儲(chǔ)的表連接,則有機(jī)會(huì)要求底層關(guān)系數(shù)據(jù)庫(kù)返回排序結(jié)果。因此,我覺得即使在大數(shù)據(jù)領(lǐng)域,Merge Join 仍然是一個(gè)值得考慮的候選。