
場(chǎng)景文字識(shí)別模型梳理
共 1412字,需瀏覽 3分鐘
·
2022-02-09 17:41
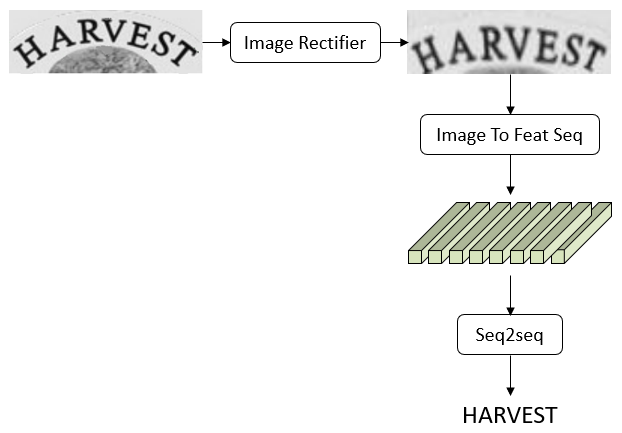
場(chǎng)景文字識(shí)別(scene text recognition),簡(jiǎn)稱為STR。最近對(duì)STR做了一下調(diào)研,相關(guān)論文可以記錄在scene text recognition papers中。當(dāng)前流行的各種方法經(jīng)過(guò)抽象和模塊化,可以得到文章開頭的pipeline圖和文章末尾的framework。
具體而言,STR可以分為三個(gè)模塊Image Rectifier、Image To Feature Sequence、Seq2seq。
Image Rectifier
這個(gè)模塊隱式地學(xué)習(xí)如何把文字圖像進(jìn)行矯正,使得模型對(duì)于彎曲和視角具備一定的魯棒性。該模塊輸入和輸出均為圖像。該模塊是可選項(xiàng),可要可不要。
Image To Feature Sequence
這個(gè)模塊將圖像映射為一個(gè)特征序列,即輸入為圖像,輸出為特征序列。該模塊可以使用CNNs、RNNs、self-attention等模塊。比如只使用CNNs;或者前半部分CNNs,后半部分RNNs;或者前半部分CNNs,后半部分self-attention;或者各種排列組合。
CNNs部分,可以只使用類似VGG、ResNet這樣的backbone,也可以在后面加一個(gè)類似于FPN這樣的neck對(duì)不同satage的特征進(jìn)行融合。
RNNs部分,一般使用LSTM或者GRU,可以只單向建模,也可以雙向建模。
self-attention部分,可以使用簡(jiǎn)單的non-local或者使用Transformer的encoder。
Seq2seq
這個(gè)模塊將特征序列轉(zhuǎn)換為文字序列,即輸入為特征序列,輸出為文字序列。
一般方法有CTC、RNN decoder、transformer decoder,基本上機(jī)器翻譯使用的方法這里都可以借用。
### 1. Image Rectifier
#### 1.1. STN + TPS
### 2. Image to Feature Sequence
#### 2.1. CNNs
##### 2.1.1. Backbone
###### 2.1.1.1. VGG
###### 2.1.1.2. ResNet
##### 2.1.2. Neck
###### 2.1.2.1. FPN
#### 2.2. RNNs (bidirectional or unidirectional)
##### 2.2.1. LSTM
##### 2.2.2. GRU
#### 2.3. self attention
##### 2.3.1. [non local](https://arxiv.org/abs/1711.07971)
##### 2.3.1. Transformer encoder
### 3. Seq2seq
#### 3.1. [CTC](https://www.cs.toronto.edu/~graves/icml_2006.pdf)
#### 3.2. RNNs
#### 3.2.1. vanilla
#### 3.2.2. equipped with attention module
#### 3.3. Transformer decoder
#### 3.4. [ACE](https://arxiv.org/abs/1904.08364)原文見我的個(gè)人博客場(chǎng)景文字識(shí)別模型方法梳理,排版會(huì)更好一些。
寫于2020-12-18。