
Flink 解讀 | Apache Flink 1.16 功能解讀
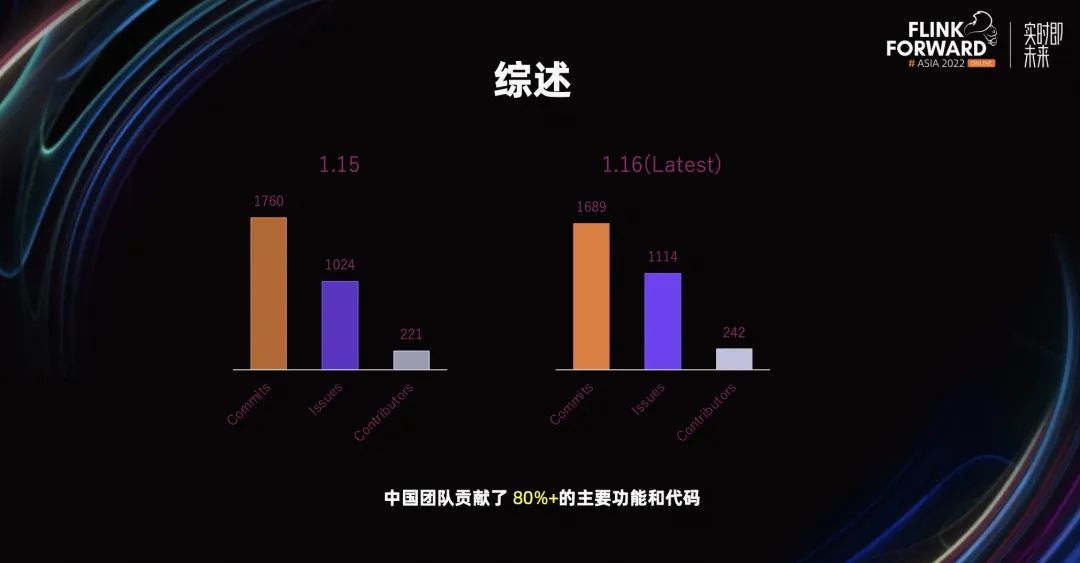
綜述
持續(xù)領(lǐng)先的流處理
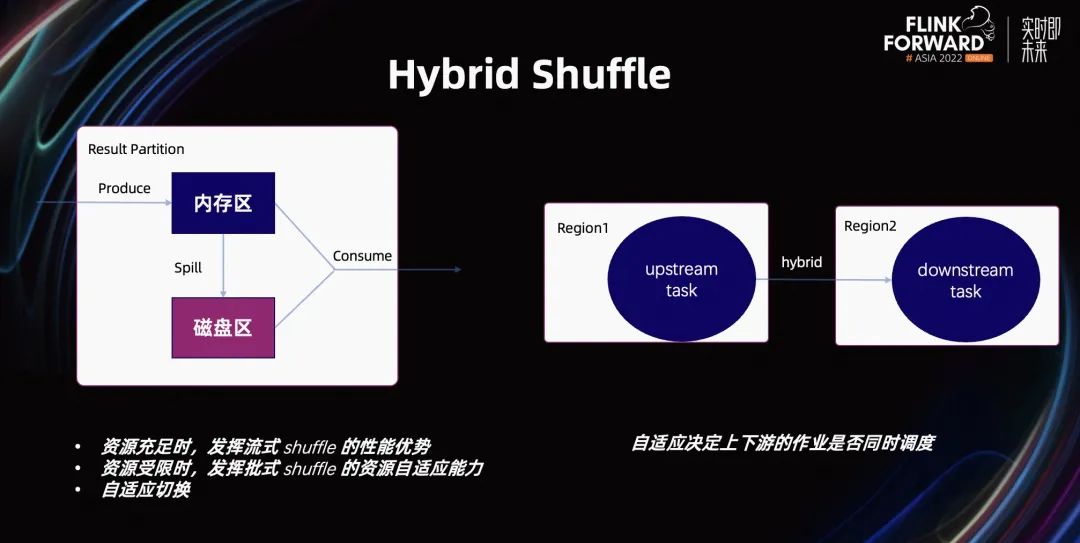
更穩(wěn)定易用高性能的批處理
蓬勃發(fā)展的生態(tài)
綜述

持續(xù)領(lǐng)先的流處理




我們?cè)?Flink 1.16 中,對(duì)維表部分的增強(qiáng)。
1. 我們引入了一種緩存機(jī)制,提升了維表的查詢性能。
2. 我們引入了一種異步查詢機(jī)制,提升了整個(gè)吞吐。
3. 我們引入一種重試機(jī)制,主要為了解決維表查詢時(shí),遇到的外部系統(tǒng)更新過慢,導(dǎo)致結(jié)果不正確,以及穩(wěn)定性問題。
通過上述改進(jìn),我們的維表查詢能力得到了極大提升。


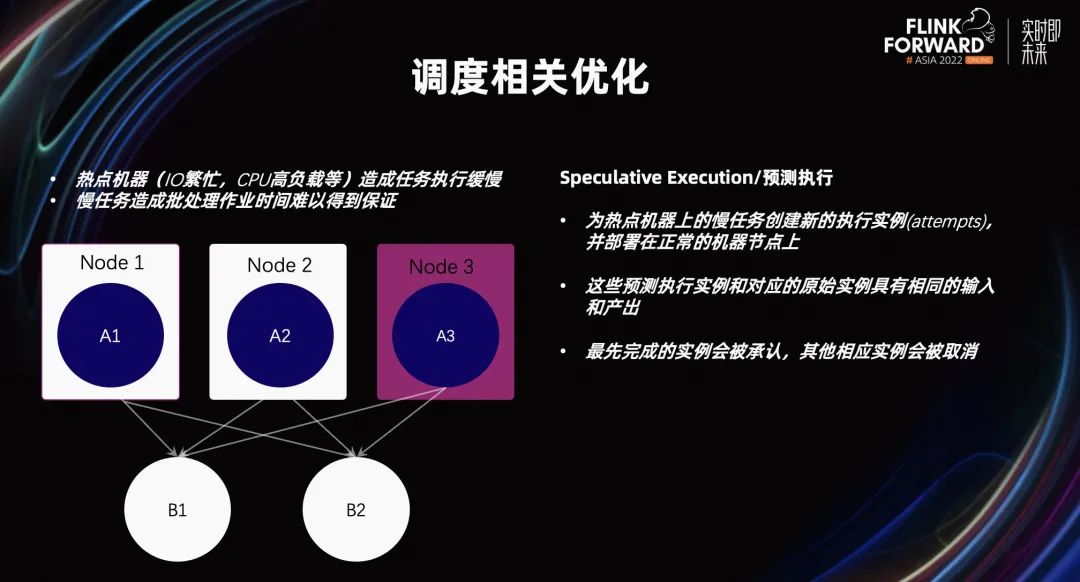
更穩(wěn)定易用高性能的批處理
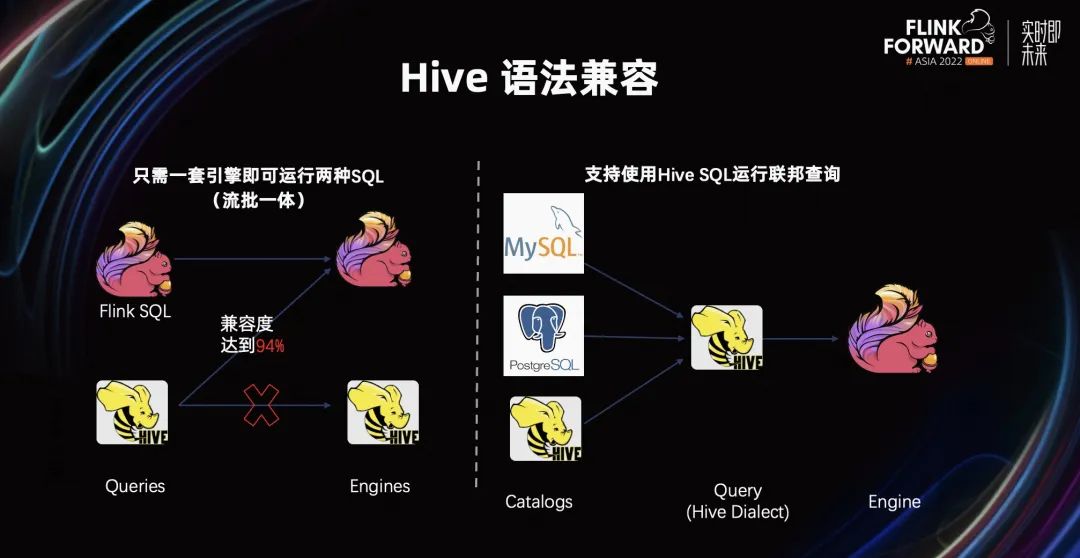
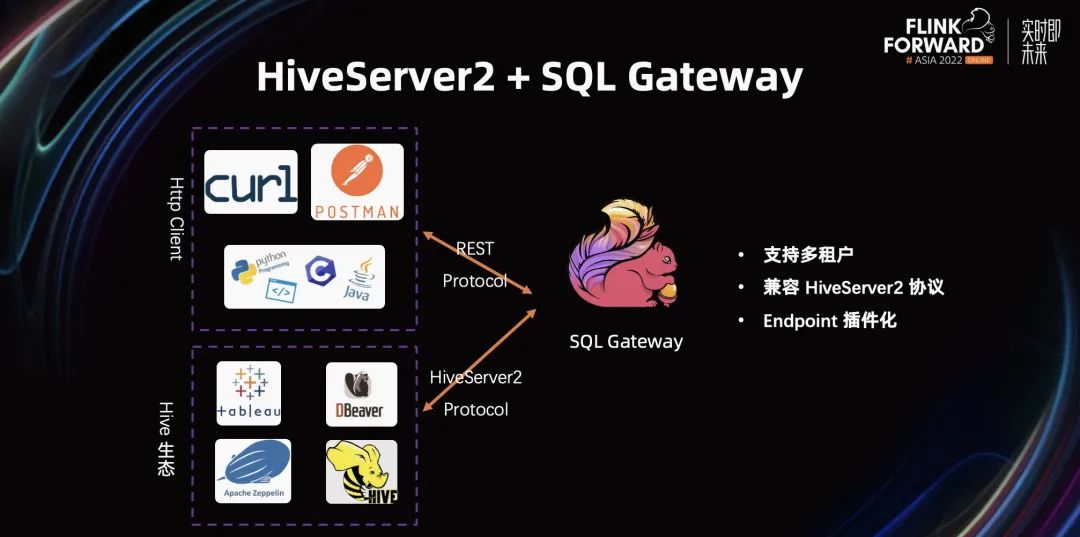





蓬勃發(fā)展的生態(tài)




往期精選





 點(diǎn)擊「閱讀原文」,查看原文視頻&演講 PPT
點(diǎn)擊「閱讀原文」,查看原文視頻&演講 PPT評(píng)論
圖片
表情