
模擬面試一(Java)
點擊關注,與你共同成長!

模擬面試一
常見linux命令
ls 查看當前目錄下文件和文件夾
cd 進入當前目錄
mkdir 創(chuàng)建文件夾
touch 創(chuàng)建文件
su 進入root權限
rm 刪除文件或文件夾
cp 復制文件
mv 移動文件
git使用
首先初始化倉庫:
git init - 初始化倉庫。
或者下載遠程代碼庫
git pull 下載遠程代碼并合并
其次添加文件
git add . - 添加文件到暫存區(qū)。
git commit - 將暫存區(qū)內容添加到倉庫中。
最后推向遠程代碼庫
git push 上傳遠程代碼并合并
重寫重載區(qū)別
重寫即子類重寫父類的方法,方法對應的形參和返回值類型都不能變。
重載即在一個類中,方法名相同,參數(shù)類型或數(shù)量不同。
springboot和spring區(qū)別
spring框架是一個基于DI和AOP模型設計的一系列應用組件,并且基于該組件,設計了MVC框架,配置文件較為繁瑣。
為了簡化設計流程,springboot橫空出世,利用springboot的默認方式,能很快開發(fā)出新的WEB應用。
redis整合到springboot
pom文件添加依賴項spring-boot-starter-data-redis
Springboot中application.properties添加redis服務器ip賬戶與密碼端口號
利用Autowired注入redisTemplate
利用redisTemplate進行相關操作
springboot怎么解析一個url
springboot starter集成了springmvc,因此解析url方式與springmvc一致。
客戶端發(fā)送url
核心控制器
Dispatcher Servlet接收該請求,通過映射器配置Handler mapping,將url映射的控制器controller返回給核心控制器。通過核心控制器找到適配器,調用實現(xiàn)對應接口的處理器,并將結果返回給適配器,
適配器將獲取的數(shù)據(jù)返回給
核心控制器核心控制器將獲取的數(shù)據(jù)傳遞給
視圖解析器,并獲取解析得到的結果核心控制器將結果返回給客戶端
tcp和udp區(qū)別
TCP作為面向流的協(xié)議,提供可靠的、面向連接的運輸服務,并且提供點對點通信
UDP作為面向報文的協(xié)議,不提供可靠交付,并且不需要連接,不僅僅對點對點,也支持多播和廣播
http和https區(qū)別
http所有傳輸?shù)膬热荻际?code style="font-size: 14px;overflow-wrap: break-word;padding: 2px 4px;border-radius: 4px;margin-right: 2px;margin-left: 2px;background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(239, 112, 96);">明文,并且客戶端和服務器端都無法驗證對方的身份。https具有安全性的ssl加密傳輸協(xié)議,加密采用對稱加密, https協(xié)議需要到ca申請證書,一般免費證書很少,需要交費。
簡述棧和隊列
棧是一種線性表,其限制只能在表尾進行插入或刪除操作。由于該特性又稱為后進先出的線性表。隊列是一種先進先出的線性表。其限制只能在線性表的一端進行插入,而在另一端刪除元素。
hashmap數(shù)據(jù)結構 鏈表轉紅黑樹
JDK8 之前底層實現(xiàn)是數(shù)組 + 鏈表,JDK8 改為數(shù)組 + 鏈表/紅黑樹。主要成員變量包括存儲數(shù)據(jù)的 table 數(shù)組、元素數(shù)量 size、加載因子 loadFactor。HashMap 中數(shù)據(jù)以鍵值對的形式存在,鍵對應的 hash 值用來計算數(shù)組下標,如果兩個元素 key 的 hash 值一樣,就會發(fā)生哈希沖突,被放到同一個鏈表上。
table 數(shù)組記錄 HashMap 的數(shù)據(jù),每個下標對應一條鏈表,所有哈希沖突的數(shù)據(jù)都會被存放到同一條鏈表,Node/Entry 節(jié)點包含四個成員變量:key、value、next 指針和 hash 值。在JDK8后鏈表超過8會轉化為紅黑樹。
mysql的操作 增刪改查
增:INSERT INTO 表名(字段名1,字段名2,…)VALUES(值1,值2,…)
刪:DELETE FROM 表名 [WHERE 條件表達式] TRUNCTE [TABLE ] 表名(刪除整張表數(shù)據(jù))
改:UPDATE 表名 SET 字段名1=值1,[ ,字段名2=值2,…] [ WHERE 條件表達式 ]
查:SELECT 字段名1,字段名2,… FROM 表名 [ WHERE 條件表達式 ]
mysql的查詢語法順序
where、group by、having、order by、limit
mysql索引數(shù)據(jù)結構 為什么快
mysql通常采用B+樹作為索引結構實現(xiàn)
B+樹也是是一種自平衡的多叉樹。其基本定義與B樹相同,不同點在于數(shù)據(jù)只出現(xiàn)在葉子節(jié)點,所有葉子節(jié)點增加了一個鏈指針,方便進行范圍查詢。
B+樹中間節(jié)點不存放數(shù)據(jù),所以同樣大小的磁盤頁上可以容納更多節(jié)點元素,訪問葉子節(jié)點上關聯(lián)的數(shù)據(jù)也具有更好的緩存命中率。并且數(shù)據(jù)順序排列并且相連,所以便于區(qū)間查找和搜索。
delete和truncate區(qū)別
delete是數(shù)據(jù)操縱語言(DML),其按行刪除,支持where語句,執(zhí)行操作采用行鎖,執(zhí)行操作時會將該操作記錄在redo和undo中,因此支持回滾。
truncate是數(shù)據(jù)定義語言(DDL),其操作隱式提交,不支持回滾,不支持where,刪除時采用表級鎖進行刪除
請描述避免多線程競爭時有哪些手段?
不可變對象; 互斥鎖; ThreadLocal 對象; CAS;
六度人脈理論
1929年,匈牙利作家Frigyes Karinthy在短篇故事‘Chains’中首次提出的“六度人脈理論”,是指地球上所有的人都可以通過六層以內的熟人鏈和任何其他人聯(lián)系起來。我們定義A的‘一度好友’為A直接相識的好友,A的‘二度好友’為A一度好友的好友且與A不是一度好友,A的‘三度好友’為A二度好友的好友且與A不是一度好友、二度好友,以此類推。
在美團點評,小美、小團、小卓、小越、小誠、小信的好友關系見下圖。
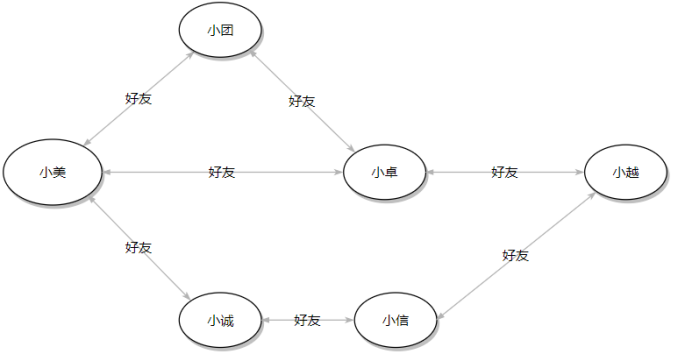
以‘小點’為起始點,廣度優(yōu)先遍歷,生成遍歷樹(無權圖可以生成最小生成樹),輸出層數(shù)為6的結點。
數(shù)據(jù)結構使用鄰接表,邊表節(jié)點由 一度好友 組成。
java 中,鄰接表可以用 linkedlist(邊表) 加 hashmap、ArrayList (頂點表)實現(xiàn)。
用鄰接表及廣度優(yōu)先算法
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class Graph {
//邊
public class EdgeNode{
int index; //存儲該頂點對應的下標
int weight; //存儲權重
}
ArrayList<String> pointList; //頂點數(shù)組
LinkedList<EdgeNode> edjList[]; //鄰接表
int pointNum; //頂點數(shù)
int edgeNum; //邊數(shù)
public Graph(int n){
pointList = new ArrayList<>(n);
edjList = new LinkedList[n];
for (int i = 0; i < n; i++) {
edjList[i] = new LinkedList<>();
}
pointNum = n;
}
//添加一條頂點
public void addPoint(String name){
if(pointList.size() >= pointNum){
System.out.println("point array full");
return ;
}
if(pointList.indexOf(name) != -1){
System.out.println("已經(jīng)存在"+name);
return ;
}
pointList.add(name);
}
public String getName(int index){
return pointList.get(index);
}
//添加一條邊
public void addEdge(String name1, String name2, int weight){
int i = pointList.indexOf(name1);
if(i == -1){
System.out.println("not find nam1="+name1);
return ;
}
int j = pointList.indexOf(name2);
if(j == -1){
System.out.println("not find name2="+name2);
return ;
}
EdgeNode edge = new EdgeNode();
edge.index = j;
edge.weight = weight;
edjList[i].add(edge);
edgeNum++;
//加入另一個邊 (無向邊 兩邊都加)
edge = new EdgeNode();
edge.index = i;
edge.weight = weight;
edjList[j].add(edge);
edgeNum++;
}
public void printAll(){
for (String s : pointList) {
}
for (int i=0;i<pointList.size();i++) {
System.out.print("節(jié)點"+pointList.get(i) +"邊為:");
for (EdgeNode edgeNode : edjList[i]) {
System.out.print(pointList.get(edgeNode.index)+" ");
}
System.out.println("");
}
}
/**
* 廣度遍歷
* @param name
*/
public void BSTTraverse(String name){
LinkedList<Integer> queue = new LinkedList();
//找到name
int i = pointList.indexOf(name);
if(i == -1){
System.out.println("not find name="+name);
return ;
}
int[] a = new int[pointNum];
for (int j = 0; j < pointNum; j++) {
a[j] = 0;
}
a[i] = 1;
LinkedList<EdgeNode> list = edjList[i];
for (EdgeNode edgeNode : list) {
queue.addLast(edgeNode.index);
a[edgeNode.index] = 1;
}
while(queue.size() != 0){
//從queue中拿出一個節(jié)點
i = queue.removeFirst();
System.out.println("遍歷 " + pointList.get(i));
list = edjList[i];
for (EdgeNode edgeNode : list) {
if(a[edgeNode.index] != 1){
queue.addLast(edgeNode.index);
a[edgeNode.index] = 1;
}
}
}
}
public class Node{
int index;
int deep;
}
/**
* 根據(jù)深度獲取好友隊列
* @param name
* @param deep 獲取1度好友 則深度為2
* @return
* 采用廣度優(yōu)先算法
*/
public LinkedList<Node> getQueueByDeep(String name, int deep){
LinkedList<Node> queue = new LinkedList();
//找到name
int i = pointList.indexOf(name);
if(i == -1){
System.out.println("not find name="+name);
return null;
}
int[] a = new int[pointNum];
for (int j = 0; j < pointNum; j++) {
a[j] = 0;
}
Node node = new Node();
node.index = i;
node.deep = 1;
queue.addLast(node);
a[i] = 1;
while(queue.size() != 0){
//從queue中拿出一個節(jié)點
node = queue.getFirst();
if(node.deep == deep){
return queue;
}
queue.removeFirst();
//System.out.println("遍歷 " + pointList.get(node.index).data);
List<EdgeNode> list = edjList[node.index];
for (EdgeNode edgeNode : list) {
if(a[edgeNode.index] != 1){
Node temp = new Node();
temp.index = edgeNode.index;
temp.deep = node.deep+1;
queue.addLast(temp);
a[edgeNode.index] = 1;
System.out.println("deep="+temp.deep + pointList.get(edgeNode.index));
}
}
}
return null;
}
public static void main(String[] args) throws Exception{
Graph g = new Graph(7);
g.addPoint("小團");
g.addPoint("小美");
g.addPoint("小誠");
g.addPoint("小信");
g.addPoint("小卓");
g.addPoint("小越");
g.addPoint("小孩");
g.addEdge("小團", "小美", 1);
g.addEdge("小卓", "小美", 1);
g.addEdge("小誠", "小美", 1);
g.addEdge("小團", "小卓", 1);
g.addEdge("小誠", "小信", 1);
g.addEdge("小信", "小越", 1);
g.addEdge("小卓", "小越", 1);
g.addEdge("小信", "小孩", 1);
g.printAll();
g.BSTTraverse("小美");
int deep = 4;
LinkedList<Node> queue = g.getQueueByDeep("小美", 4);
if(queue == null){
System.out.println("沒有"+(deep-1)+"度好友");
}else{
for (Node node : queue) {
System.out.println(node.deep+"度好友為 "+ g.getName(node.index));
}
}
}
}
請簡述HTTP的5個常用Method及其含義,以及5個常用Status Code及其含義?HTTP與HTTPS的區(qū)別是什么,簡述一下HTTPS的實現(xiàn)原理。
get 從服務器端獲取資源
put 提交資源
post 更新資源
delete 刪除資源
connect 建立tunnel隧道
100 請求已收到,正等待后續(xù)資源
200 ok 成功
206 partial content 部分資源
301 永久重定向
400 bad request 客戶端請求語法錯誤
500 Not Implement 服務器內部錯誤
502 Bad Getaway 網(wǎng)關錯誤
HTTP與HTTPS區(qū)別:
HTTPS是HTTP經(jīng)由加入SSL層來提高數(shù)據(jù)傳輸?shù)陌踩浴F渲蠸SL依靠證書來驗證服務器的身份,并對瀏覽器與服務器之間的 通信進行數(shù)據(jù)加密。HTTP不適合傳輸敏感信息。
HTTPs實現(xiàn)原理:
發(fā)起請求:客戶端通過TCP和服務器建立連接后,發(fā)出一個請求證書的消息給到服務器。
證書返回:服務器端在收到請求后回應客戶端并且返回證書。
給出一個布爾表達式的字符串,比如:true or false and false,表達式只包含true,false,and和or,現(xiàn)在要對這個表達式進行布爾求值,計算結果為真時輸出true、為假時輸出false,不合法的表達時輸出error(比如:true true)。表達式求值是注意and 的優(yōu)先級比 or 要高,比如:true or false and false,等價于 true or (false and false),計算結果是 true。
將字符串分割后分別壓棧,若遇到頂層為and時候進行彈出對比,最后保證棧中只有true、false、or字符串,再對棧中符號進行判斷
public static void main(String[] args) {
Scanner scanner=new Scanner(System.in);
String[] ss=scanner.nextLine().split(" ");
Stack<String> stack=new Stack<>();
for(int i=0;i<ss.length;i++){
String curr=ss[i];
//當前值為true或false時
if(curr.equals("true")||curr.equals("false")){
if(stack.isEmpty()){
stack.push(curr);
}else{
String top=stack.peek();
if(top.equals("true")||top.equals("false")){
System.out.println("error");
return;
}else{
if(top.equals("or")) stack.push(curr);
else{
stack.pop();
String pre=stack.pop();
if(curr.equals("false")||pre.equals("false")) stack.push("false");
else stack.push("true");
}
}
}
}
//當前值為and或or時
else{
if(stack.isEmpty()){
System.out.println("error");
return;
}else{
String top=stack.peek();
if(top.equals("and")||top.equals("or")){
System.out.println("error");
return;
}
stack.push(curr);
}
}
}
if(!stack.isEmpty()&&(stack.peek().equals("or")||stack.peek().equals("and"))){
System.out.println("error");
return;
}
while(!stack.isEmpty()){
String curr=stack.pop();
if(curr.equals("true")){
System.out.println("true");
break;
}
if(stack.isEmpty()) System.out.println("false");
}
}
給出兩個字符串,分別是模式串P和目標串T,判斷模式串和目標串是否匹配,匹配輸出 1,不匹配輸出 0。模式串中‘?’可以匹配目標串中的任何字符,模式串中的 ’*’可以匹配目標串中的任何長度的串,模式串的其它字符必須和目標串的字符匹配。例如P=a?b,T=acb,則P 和 T 匹配。
力扣44原題
import java.util.*;
public class Main{
public static void main(String[] args){
Scanner sc = new Scanner(System.in);
String p = sc.next();
String s = sc.next();
// System.out.println(s + " - " + p);
int m = s.length(), n = p.length();
boolean[][] dp = new boolean[m + 1][n + 1];
dp[0][0] = true;
for(int i = 1; i <= n; i++) dp[0][i] = dp[0][i - 1] && p.charAt(i - 1) == '*';
for(int i = 1; i <= m; i++){
for(int j = 1; j <= n; j++){
if(s.charAt(i - 1) == p.charAt(j - 1) || p.charAt(j - 1) == '?'){
dp[i][j] = dp[i - 1][j - 1];
}
if(p.charAt(j - 1) == '*'){
dp[i][j] = dp[i - 1][j] || dp[i][j - 1];
}
}
}
System.out.println((dp[m][n] ? 1 : 0));
}
}
