本文中我們將使用深度學(xué)習(xí)方法 (LSTM) 執(zhí)行多元時(shí)間序列預(yù)測(cè)。
使用 LSTM 進(jìn)行端到端時(shí)間序列預(yù)測(cè)的完整代碼和詳細(xì)解釋。時(shí)間序列分析:時(shí)間序列表示基于時(shí)間順序的一系列數(shù)據(jù)。它可以是秒、分鐘、小時(shí)、天、周、月、年。未來的數(shù)據(jù)將取決于它以前的值。在現(xiàn)實(shí)世界的案例中,我們主要有兩種類型的時(shí)間序列分析:對(duì)于單變量時(shí)間序列數(shù)據(jù),我們將使用單列進(jìn)行預(yù)測(cè)。正如我們所見,只有一列,因此即將到來的未來值將僅取決于它之前的值。
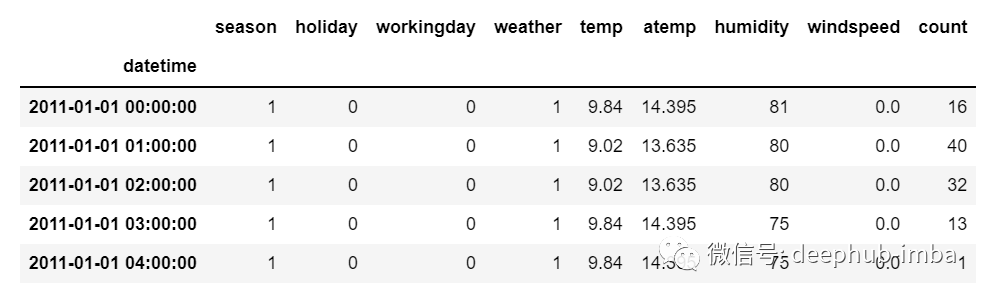
但是在多元時(shí)間序列數(shù)據(jù)的情況下,將有不同類型的特征值并且目標(biāo)數(shù)據(jù)將依賴于這些特征。正如在圖片中看到的,在多元變量中將有多個(gè)列來對(duì)目標(biāo)值進(jìn)行預(yù)測(cè)。(上圖中“count”為目標(biāo)值)
在上面的數(shù)據(jù)中,count不僅取決于它以前的值,還取決于其他特征。因此,要預(yù)測(cè)即將到來的count值,我們必須考慮包括目標(biāo)列在內(nèi)的所有列來對(duì)目標(biāo)值進(jìn)行預(yù)測(cè)。在執(zhí)行多元時(shí)間序列分析時(shí)必須記住一件事,我們需要使用多個(gè)特征預(yù)測(cè)當(dāng)前的目標(biāo),讓我們通過一個(gè)例子來理解:在訓(xùn)練時(shí),如果我們使用 5 列 [feature1, feature2, feature3, feature4, target] 來訓(xùn)練模型,我們需要為即將到來的預(yù)測(cè)日提供 4 列 [feature1, feature2, feature3, feature4]。本文中不打算詳細(xì)討論LSTM。所以只提供一些簡(jiǎn)單的描述,如果你對(duì)LSTM沒有太多的了解,可以參考我們以前發(fā)布的文章。LSTM基本上是一個(gè)循環(huán)神經(jīng)網(wǎng)絡(luò),能夠處理長(zhǎng)期依賴關(guān)系。假設(shè)你在看一部電影。所以當(dāng)電影中發(fā)生任何情況時(shí),你都已經(jīng)知道之前發(fā)生了什么,并且可以理解因?yàn)檫^去發(fā)生的事情所以才會(huì)有新的情況發(fā)生。RNN也是以同樣的方式工作,它們記住過去的信息并使用它來處理當(dāng)前的輸入。RNN的問題是,由于漸變消失,它們不能記住長(zhǎng)期依賴關(guān)系。因此為了避免長(zhǎng)期依賴問題設(shè)計(jì)了lstm。現(xiàn)在我們討論了時(shí)間序列預(yù)測(cè)和LSTM理論部分。讓我們開始編碼。讓我們首先導(dǎo)入進(jìn)行預(yù)測(cè)所需的庫:import numpy as npimport pandas as pdfrom matplotlib import pyplot as pltfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import LSTMfrom tensorflow.keras.layers import Dense, Dropoutfrom sklearn.preprocessing import MinMaxScalerfrom keras.wrappers.scikit_learn import KerasRegressorfrom sklearn.model_selection import GridSearchCV
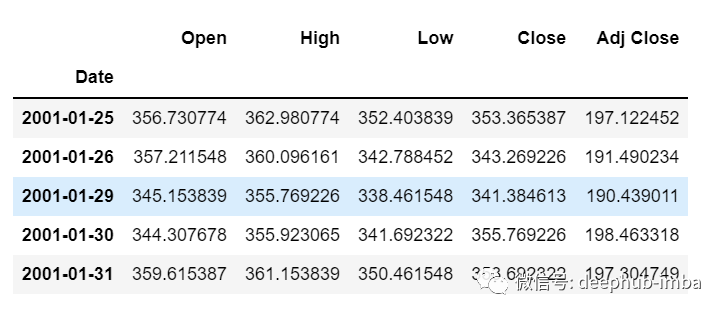
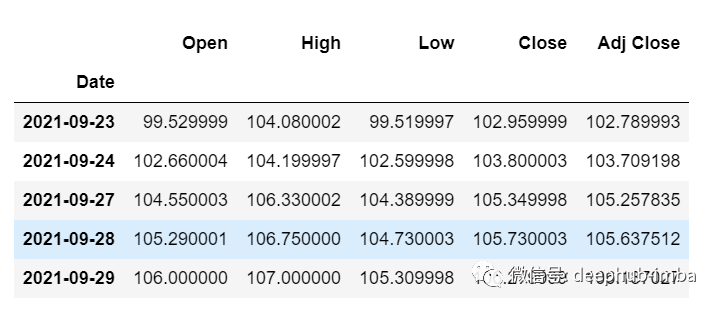
df=pd.read_csv("train.csv",parse_dates=["Date"],index_col=[0])df.head()
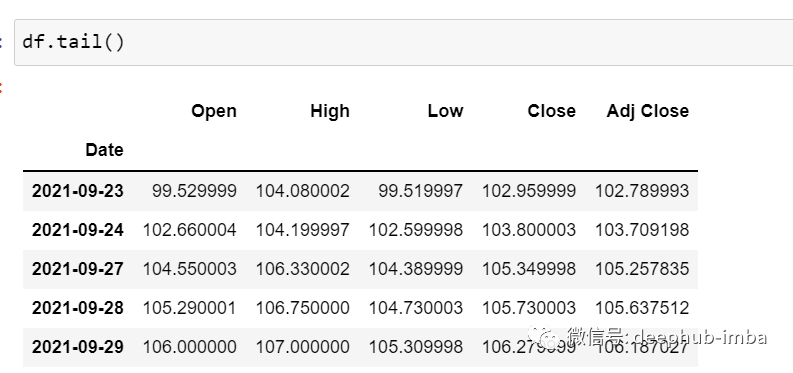
現(xiàn)在讓我們花點(diǎn)時(shí)間看看數(shù)據(jù):csv文件中包含了谷歌從2001-01-25到2021-09-29的股票數(shù)據(jù),數(shù)據(jù)是按照天數(shù)頻率的。
[如果您愿意,您可以將頻率轉(zhuǎn)換為“B”[工作日]或“D”,因?yàn)槲覀儾粫?huì)使用日期,我只是保持它的現(xiàn)狀。]這里我們?cè)噲D預(yù)測(cè)“Open”列的未來值,因此“Open”是這里的目標(biāo)列。現(xiàn)在讓我們進(jìn)行訓(xùn)練測(cè)試拆分。這里我們不能打亂數(shù)據(jù),因?yàn)樵跁r(shí)間序列中必須是順序的。test_split=round(len(df)*0.20)df_for_training=df[:-1041]df_for_testing=df[-1041:]print(df_for_training.shape)print(df_for_testing.shape)
(4162, 5)(1041, 5)
可以注意到數(shù)據(jù)范圍非常大,并且它們沒有在相同的范圍內(nèi)縮放,因此為了避免預(yù)測(cè)錯(cuò)誤,讓我們先使用MinMaxScaler縮放數(shù)據(jù)。(也可以使用StandardScaler)scaler = MinMaxScaler(feature_range=(0,1))df_for_training_scaled = scaler.fit_transform(df_for_training)df_for_testing_scaled=scaler.transform(df_for_testing)df_for_training_scaled
將數(shù)據(jù)拆分為X和Y,這是最重要的部分,正確閱讀每一個(gè)步驟。def createXY(dataset,n_past): dataX = [] dataY = [] for i in range(n_past, len(dataset)): dataX.append(dataset[i - n_past:i, 0:dataset.shape[1]]) dataY.append(dataset[i,0]) return np.array(dataX),np.array(dataY)
trainX,trainY=createXY(df_for_training_scaled,30)testX,testY=createXY(df_for_testing_scaled,30)
N_past是我們?cè)陬A(yù)測(cè)下一個(gè)目標(biāo)值時(shí)將在過去查看的步驟數(shù)。這里使用30,意味著將使用過去的30個(gè)值(包括目標(biāo)列在內(nèi)的所有特性)來預(yù)測(cè)第31個(gè)目標(biāo)值。因此,在trainX中我們會(huì)有所有的特征值,而在trainY中我們只有目標(biāo)值。對(duì)于訓(xùn)練,dataset = df_for_training_scaled, n_past=30data_X.addend (df_for_training_scaled[i - n_past:i, 0:df_for_training.shape[1]])
從n_past開始的范圍是30,所以第一次數(shù)據(jù)范圍將是-[30 - 30,30,0:5] 相當(dāng)于 [0:30,0:5]因此在dataX列表中,df_for_training_scaled[0:30,0:5]數(shù)組將第一次出現(xiàn)。現(xiàn)在, dataY.append(df_for_training_scaled[i,0])i = 30,所以它將只取第30行開始的open(因?yàn)樵陬A(yù)測(cè)中,我們只需要open列,所以列范圍僅為0,表示open列)。第一次在dataY列表中存儲(chǔ)df_for_training_scaled[30,0]值。所以包含5列的前30行存儲(chǔ)在dataX中,只有open列的第31行存儲(chǔ)在dataY中。然后我們將dataX和dataY列表轉(zhuǎn)換為數(shù)組,它們以數(shù)組格式在LSTM中進(jìn)行訓(xùn)練。print("trainX Shape-- ",trainX.shape)print("trainY Shape-- ",trainY.shape)
(4132, 30, 5)(4132,)
print("testX Shape-- ",testX.shape)print("testY Shape-- ",testY.shape)
(1011, 30, 5)(1011,)
4132 是 trainX 中可用的數(shù)組總數(shù),每個(gè)數(shù)組共有 30 行和 5 列, 在每個(gè)數(shù)組的 trainY 中,我們都有下一個(gè)目標(biāo)值來訓(xùn)練模型。讓我們看一下包含來自 trainX 的 (30,5) 數(shù)據(jù)的數(shù)組之一 和 trainX 數(shù)組的 trainY 值:print("trainX[0]-- \n",trainX[0])print("trainY[0]-- ",trainY[0])
如果查看 trainX[1] 值,會(huì)發(fā)現(xiàn)到它與 trainX[0] 中的數(shù)據(jù)相同(第一列除外),因?yàn)槲覀儗⒖吹角?30 個(gè)來預(yù)測(cè)第 31 列,在第一次預(yù)測(cè)之后它會(huì)自動(dòng)移動(dòng) 到第 2 列并取下一個(gè) 30 值來預(yù)測(cè)下一個(gè)目標(biāo)值。
trainX — — →trainY
[0 : 30,0:5] → [30,0]
[1:31, 0:5] → [31,0]
[2:32,0:5] →[32,0]
像這樣,每個(gè)數(shù)據(jù)都將保存在 trainX 和 trainY 中。現(xiàn)在讓我們訓(xùn)練模型,我使用 girdsearchCV 進(jìn)行一些超參數(shù)調(diào)整以找到基礎(chǔ)模型。def build_model(optimizer): grid_model = Sequential() grid_model.add(LSTM(50,return_sequences=True,input_shape=(30,5))) grid_model.add(LSTM(50)) grid_model.add(Dropout(0.2)) grid_model.add(Dense(1))
grid_model.compile(loss = 'mse',optimizer = optimizer) return grid_modelgrid_model = KerasRegressor(build_fn=build_model,verbose=1,validation_data=(testX,testY))
parameters = {'batch_size' : [16,20], 'epochs' : [8,10], 'optimizer' : ['adam','Adadelta'] }
grid_search = GridSearchCV(estimator = grid_model, param_grid = parameters, cv = 2)
如果你想為你的模型做更多的超參數(shù)調(diào)整,也可以添加更多的層。但是如果數(shù)據(jù)集非常大建議增加 LSTM 模型中的時(shí)期和單位。在第一個(gè) LSTM 層中看到輸入形狀為 (30,5)。它來自 trainX 形狀。(trainX.shape[1],trainX.shape[2]) → (30,5)
現(xiàn)在讓我們將模型擬合到 trainX 和 trainY 數(shù)據(jù)中。grid_search = grid_search.fit(trainX,trainY)
由于進(jìn)行了超參數(shù)搜索,所以這將需要一些時(shí)間來運(yùn)行。現(xiàn)在讓我們檢查模型的最佳參數(shù)。
grid_search.best_params_
{‘batch_size’: 20, ‘epochs’: 10, ‘optimizer’: ‘a(chǎn)dam’}
my_model=grid_search.best_estimator_.model
現(xiàn)在可以用測(cè)試數(shù)據(jù)集測(cè)試模型。prediction=my_model.predict(testX)print("prediction\n", prediction)print("\nPrediction Shape-",prediction.shape)
testY 和 prediction 的長(zhǎng)度是一樣的。現(xiàn)在可以將 testY 與預(yù)測(cè)進(jìn)行比較。
但是我們一開始就對(duì)數(shù)據(jù)進(jìn)行了縮放,所以首先我們必須做一些逆縮放過程。scaler.inverse_transform(prediction)
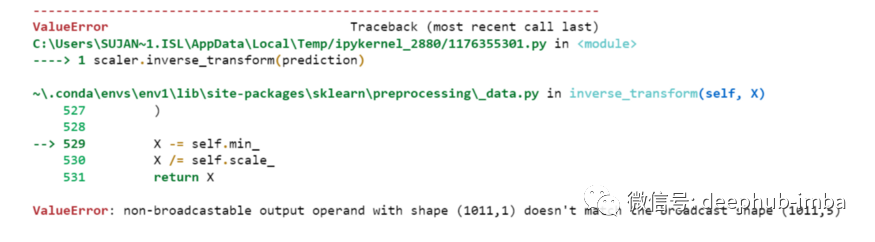
報(bào)錯(cuò)了,這是因?yàn)樵诳s放數(shù)據(jù)時(shí),我們每行有 5 列,現(xiàn)在我們只有 1 列是目標(biāo)列。
所以我們必須改變形狀來使用 inverse_transform:prediction_copies_array = np.repeat(prediction,5, axis=-1)

5 列值是相似的,它只是將單個(gè)預(yù)測(cè)列復(fù)制了 4 次。所以現(xiàn)在我們有 5 列相同的值 。
prediction_copies_array.shape(1011,5)
這樣就可以使用 inverse_transform 函數(shù)。pred=scaler.inverse_transform(np.reshape(prediction_copies_array,(len(prediction),5)))[:,0]
但是逆變換后的第一列是我們需要的,所以我們?cè)谧詈笫褂昧?→ [:,0]。現(xiàn)在將這個(gè) pred 值與 testY 進(jìn)行比較,但是 testY 也是按比例縮放的,也需要使用與上述相同的代碼進(jìn)行逆變換。original_copies_array = np.repeat(testY,5, axis=-1)original=scaler.inverse_transform(np.reshape(original_copies_array,(len(testY),5)))[:,0]
現(xiàn)在讓我們看一下預(yù)測(cè)值和原始值:print("Pred Values-- " ,pred)print("\nOriginal?Values--?"?,original)
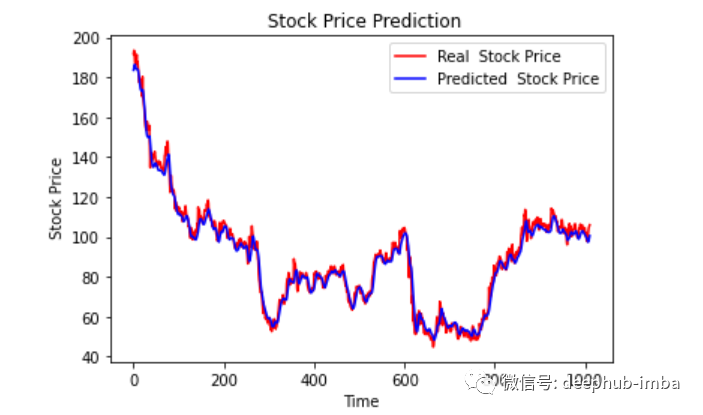
最后繪制一個(gè)圖來對(duì)比我們的 pred 和原始數(shù)據(jù)。
plt.plot(original, color = 'red', label = 'Real Stock Price')plt.plot(pred, color = 'blue', label = 'Predicted Stock Price')plt.title('Stock Price Prediction')plt.xlabel('Time')plt.ylabel('Google Stock Price')plt.legend()plt.show()
看樣子還不錯(cuò),到目前為止,我們訓(xùn)練了模型并用測(cè)試值檢查了該模型。現(xiàn)在讓我們預(yù)測(cè)一些未來值。
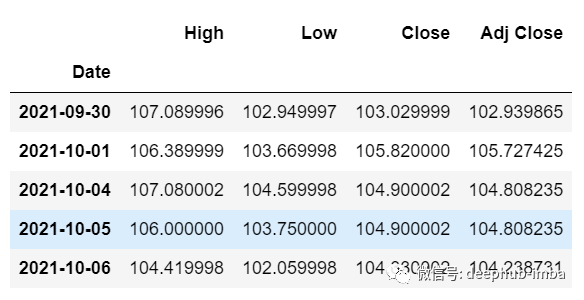
從主 df 數(shù)據(jù)集中獲取我們?cè)陂_始時(shí)加載的最后 30 個(gè)值[為什么是 30?因?yàn)檫@是我們想要的過去值的數(shù)量,來預(yù)測(cè)第 31 個(gè)值]df_30_days_past=df.iloc[-30:,:]df_30_days_past.tail()
可以看到有包括目標(biāo)列(“Open”)在內(nèi)的所有列。現(xiàn)在讓我們預(yù)測(cè)未來的 30 個(gè)值。
在多元時(shí)間序列預(yù)測(cè)中,需要通過使用不同的特征來預(yù)測(cè)單列,所以在進(jìn)行預(yù)測(cè)時(shí)我們需要使用特征值(目標(biāo)列除外)來進(jìn)行即將到來的預(yù)測(cè)。這里我們需要“High”、“Low”、“Close”、“Adj Close”列的即將到來的 30 個(gè)值來對(duì)“Open”列進(jìn)行預(yù)測(cè)。df_30_days_future=pd.read_csv("test.csv",parse_dates=["Date"],index_col=[0])df_30_days_future
剔除“Open”列后,使用模型進(jìn)行預(yù)測(cè)之前還需要做以下的操作:
縮放數(shù)據(jù),因?yàn)閯h除了‘Open’列,在縮放它之前,添加一個(gè)所有值都為“0”的Open列。縮放后,將未來數(shù)據(jù)中的“Open”列值替換為“nan”現(xiàn)在附加 30 天舊值和 30 天新值(其中最后 30 個(gè)“打開”值是 nan)df_30_days_future["Open"]=0df_30_days_future=df_30_days_future[["Open","High","Low","Close","Adj Close"]]old_scaled_array=scaler.transform(df_30_days_past)new_scaled_array=scaler.transform(df_30_days_future)new_scaled_df=pd.DataFrame(new_scaled_array)new_scaled_df.iloc[:,0]=np.nanfull_df=pd.concat([pd.DataFrame(old_scaled_array),new_scaled_df]).reset_index().drop(["index"],axis=1)
full_df ?形狀是 (60,5),最后第一列有 30 個(gè) nan 值。要進(jìn)行預(yù)測(cè)必須再次使用 for 循環(huán),我們?cè)诓鸱?trainX 和 trainY 中的數(shù)據(jù)時(shí)所做的。但是這次我們只有 X,沒有 Y 值。full_df_scaled_array=full_df.valuesall_data=[]time_step=30for i in range(time_step,len(full_df_scaled_array)): data_x=[] data_x.append( full_df_scaled_array[i-time_step :i , 0:full_df_scaled_array.shape[1]]) data_x=np.array(data_x) prediction=my_model.predict(data_x) all_data.append(prediction) full_df.iloc[i,0]=prediction
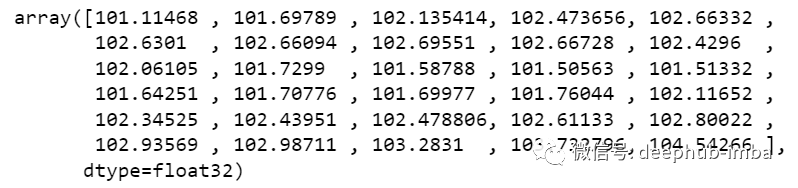
對(duì)于第一個(gè)預(yù)測(cè),有之前的 30 個(gè)值,當(dāng) for 循環(huán)第一次運(yùn)行時(shí)它會(huì)檢查前 30 個(gè)值并預(yù)測(cè)第 31 個(gè)“Open”數(shù)據(jù)。當(dāng)?shù)诙€(gè) for 循環(huán)將嘗試運(yùn)行時(shí),它將跳過第一行并嘗試獲取下 30 個(gè)值 [1:31] 。這里會(huì)報(bào)錯(cuò)錯(cuò)誤因?yàn)镺pen列最后一行是 “nan”,所以需要每次都用預(yù)測(cè)替換“nan”。最后還需要對(duì)預(yù)測(cè)進(jìn)行逆變換:new_array=np.array(all_data)new_array=new_array.reshape(-1,1)prediction_copies_array = np.repeat(new_array,5, axis=-1)y_pred_future_30_days = scaler.inverse_transform(np.reshape(prediction_copies_array,(len(new_array),5)))[:,0]print(y_pred_future_30_days)
這樣一個(gè)完整的流程就已經(jīng)跑通了。
https://github.com/sksujan58/Multivariate-time-series-forecasting-using-LSTM編輯:黃繼彥
校對(duì):林亦霖