
海量存儲(chǔ)、智能擴(kuò)容,這款數(shù)據(jù)庫架構(gòu)為何深受用戶喜愛?

點(diǎn)擊可觀看精彩演講視頻
一、騰訊云原生數(shù)據(jù)庫的前世今生
我們今天的分享主要由三部分組成,第一部分是我們做TDSQL-C這款產(chǎn)品的背景,即為什么做TDSQL-C、它的架構(gòu)和現(xiàn)狀如何。第二部分主要介紹TDSQL-C有哪些突破性的創(chuàng)新,以及從用戶視角來看我們主要做了哪些可以方便用戶的事。第三部分是TDSQL-C未來的RoadMap,偏技術(shù)。
首先看第一點(diǎn)。我們之前是做CDB的產(chǎn)品運(yùn)營研發(fā)相關(guān)工作,但在做的時(shí)候遇到了一些在傳統(tǒng)數(shù)據(jù)庫領(lǐng)域難以解決的問題:首先是存儲(chǔ)容量問題,當(dāng)單機(jī)磁盤容量達(dá)到一定程度時(shí),就會(huì)對業(yè)務(wù)帶來相應(yīng)的麻煩。第二個(gè)是擴(kuò)展性,熟悉數(shù)據(jù)庫運(yùn)維的朋友應(yīng)該知道,典型的場景是在業(yè)務(wù)有活動(dòng)的時(shí)候我們加機(jī)器,在業(yè)務(wù)活動(dòng)結(jié)束之后要減機(jī)器,它的過程一般是經(jīng)過備份、組件、實(shí)例,效率較差。第三是可用性,典型的就是災(zāi)備,從DBA的角度來看,災(zāi)備發(fā)生HA的時(shí)候,這個(gè)時(shí)間點(diǎn)是不可控的。第四是可靠性,因?yàn)閱螜C(jī)傳統(tǒng)的MySQL架構(gòu),它的一主一備,并且存儲(chǔ)是在本地存儲(chǔ),當(dāng)我們本地磁盤損壞的時(shí)候,它的數(shù)據(jù)可靠性會(huì)有問題,傳統(tǒng)的MySQL做數(shù)據(jù)備份以及數(shù)據(jù)恢復(fù),如果出現(xiàn)了大數(shù)延遲或者DDL這種問題的時(shí)候,這個(gè)時(shí)候如果再發(fā)生HA,那么此時(shí)數(shù)據(jù)庫服務(wù)實(shí)際上是不可用的。
基于在傳統(tǒng)數(shù)據(jù)庫領(lǐng)域運(yùn)維遇到的問題,再結(jié)合業(yè)內(nèi)的一些架構(gòu),我們自主研發(fā)了騰訊的一種存儲(chǔ)和分離的數(shù)據(jù)庫產(chǎn)品。
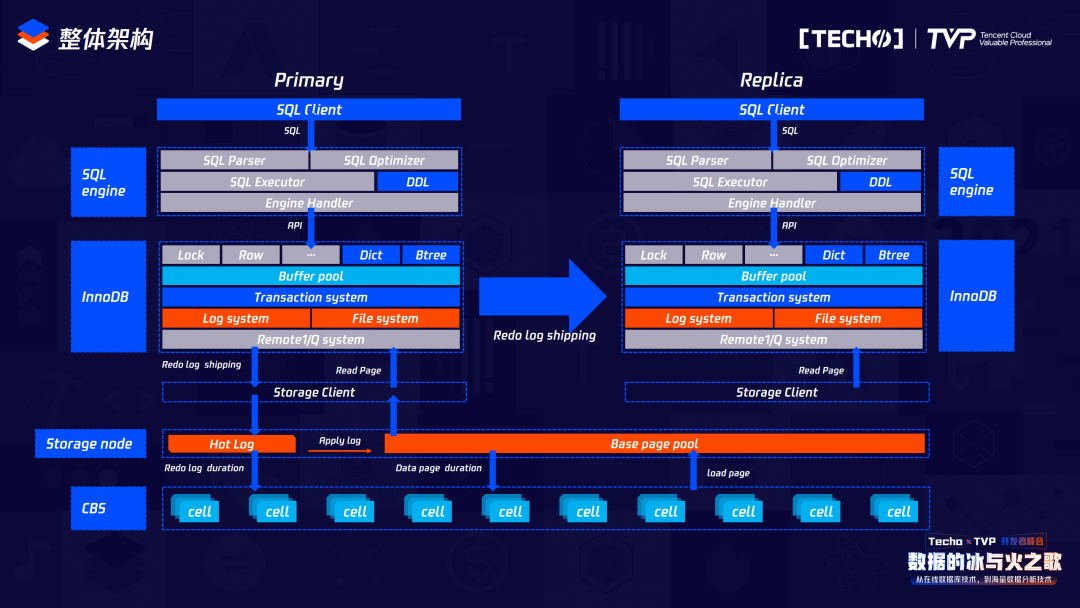
這是我們整體TDSQL-C的架構(gòu)圖,它和傳統(tǒng)的MySQL類似,支持一個(gè)讀寫節(jié)點(diǎn)、多個(gè)備庫節(jié)點(diǎn),備庫節(jié)點(diǎn)最多可以支持15個(gè)讀節(jié)點(diǎn)。它分為計(jì)算和存儲(chǔ)兩部分,計(jì)算節(jié)點(diǎn)主要負(fù)責(zé)數(shù)據(jù)庫的傳統(tǒng)業(yè)務(wù)邏輯領(lǐng)域,包括像事務(wù)、鎖以及常用的DML,傳統(tǒng)數(shù)據(jù)庫領(lǐng)域里所有在數(shù)據(jù)庫的操作,除了兩部分不在計(jì)算層以外,其他都在計(jì)算層,計(jì)算層不負(fù)責(zé)數(shù)據(jù)的持久化操作,數(shù)據(jù)的持久化操作會(huì)下發(fā)到存儲(chǔ)層,存儲(chǔ)層來負(fù)責(zé)數(shù)據(jù)的持久化操作。存儲(chǔ)層是 HiStore (網(wǎng)絡(luò)存儲(chǔ)),本身最大支持的存儲(chǔ)規(guī)模現(xiàn)在有1PB。而主備之間和原生MySQL不同的是它使用Redo log進(jìn)行主備數(shù)據(jù)同步,Redo log發(fā)送到備庫之后只負(fù)責(zé)同步備庫之間的BP。
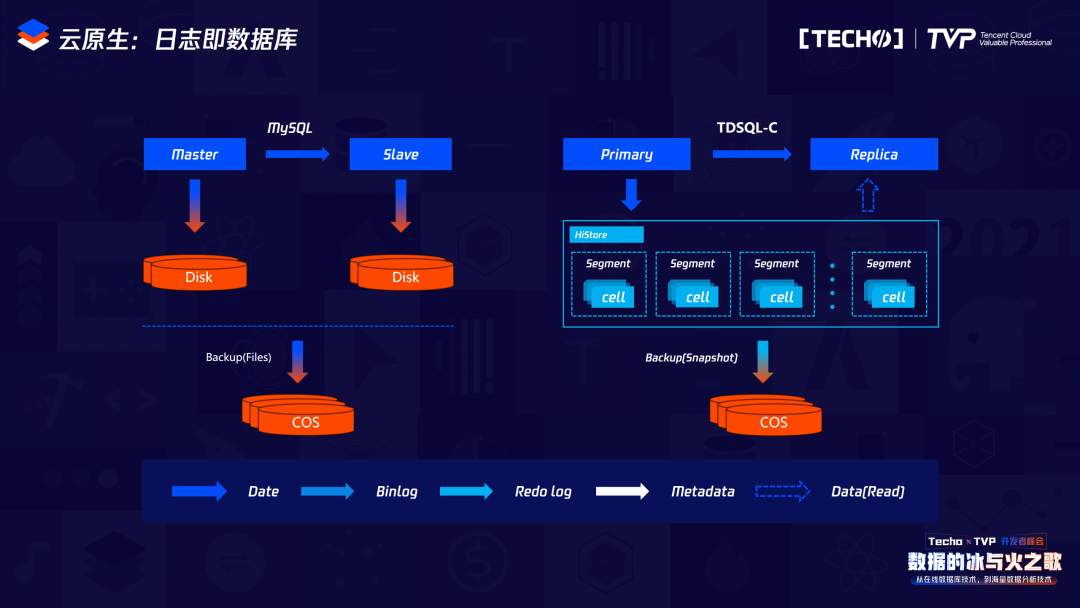
我們來看整體原生的MySQL一主一備的架構(gòu)和現(xiàn)在TDSQL-C的架構(gòu)。原生的MySQL里的存儲(chǔ)是在本地進(jìn)行的,依賴于本地的Dict存儲(chǔ),受限于本地的存儲(chǔ)空間;TDSQL-C里的存儲(chǔ)是網(wǎng)絡(luò)云盤,它分為兩級存儲(chǔ),上面是HiStore,負(fù)責(zé)存儲(chǔ)數(shù)據(jù),下面負(fù)責(zé)存儲(chǔ)備份。
它的計(jì)算和存儲(chǔ)分離,但是計(jì)算節(jié)點(diǎn)的主備節(jié)點(diǎn)會(huì)共享存儲(chǔ),就是下面這個(gè)HiStore。和傳統(tǒng)MySQL架構(gòu)不同,它是一個(gè)可計(jì)算存儲(chǔ),體現(xiàn)了兩點(diǎn):主節(jié)點(diǎn)的計(jì)算節(jié)點(diǎn)會(huì)把產(chǎn)生的Redo日志下發(fā)到存儲(chǔ)層,存儲(chǔ)層會(huì)依賴于它的Base page以及所產(chǎn)生的Redo log來負(fù)責(zé)數(shù)據(jù)的持久化操作,存儲(chǔ)層在收到Redo log后才會(huì)向計(jì)算層反饋信息,說明Redo log已經(jīng)持久化,證明現(xiàn)在的事務(wù)已經(jīng)結(jié)束,可以讓業(yè)務(wù)邏輯繼續(xù)進(jìn)行。業(yè)務(wù)邏輯在進(jìn)行的同時(shí),存儲(chǔ)層會(huì)異步處理Redo log,計(jì)算中存儲(chǔ)下來的Redo log共同生成新的,由這個(gè)新的持久化到HiStore里負(fù)責(zé),從而將數(shù)據(jù)持久化操作。所以它和傳統(tǒng)的CDB或傳統(tǒng)的MySQL架構(gòu)下面沒有數(shù)據(jù)的持久化操作,也就不會(huì)有WAL帶來的一些性能抖動(dòng)問題。
在HiStore把數(shù)據(jù)持久化之后,會(huì)把之前Redo log所占的內(nèi)存空間回收。而我們的存儲(chǔ)也有以下特性:我們在把本地磁盤映射到網(wǎng)絡(luò)存盤時(shí),是根據(jù)它的物理地址映射到底下存儲(chǔ)空間的某一個(gè)cell中,所以它的日志是按照頁面來進(jìn)行分發(fā),每一個(gè)cell里都有相應(yīng)的數(shù)據(jù)頁和Redo log,因?yàn)樽庸?jié)點(diǎn)和主節(jié)點(diǎn)是共享存儲(chǔ)數(shù)據(jù)的,所以要求我們的存儲(chǔ)支持?jǐn)?shù)據(jù)多版本,它的數(shù)據(jù)多版本是由我們的Base page加上從計(jì)算中傳遞下來的Redo log共同生成的一個(gè)具有指定版本的數(shù)據(jù)來進(jìn)行的。
剛才介紹了我們本身的架構(gòu),而從整體上的架構(gòu)來看,TDSQL-C有以下特性:第一是海量存儲(chǔ)、智能擴(kuò)容。存儲(chǔ)由HiStore支持,網(wǎng)絡(luò)存儲(chǔ)最大可支持1PB,相對于現(xiàn)在單機(jī)容量幾十T或者幾T來說,不是一個(gè)級別的。第二是我們整體的QPS存儲(chǔ)量可以達(dá)到百萬級別,所以它的性能也得到了線性擴(kuò)充。第三是兼容MySQL和PG,也沒有分布式事務(wù)鎖帶來的一些問題,不進(jìn)行數(shù)據(jù)分片,所以是天然支持分布式的。其次是擴(kuò)展性,相對于傳統(tǒng)的CDB架構(gòu)或者傳統(tǒng)RDS架構(gòu)來說,它不依賴于本地的物理備份或者邏輯備份導(dǎo)數(shù)據(jù)來進(jìn)行擴(kuò)容,而是直接從文件系統(tǒng)做一個(gè)快照,快照加上Redo log來做擴(kuò)容,所以整個(gè)擴(kuò)容的時(shí)間基本在一分鐘以內(nèi),可以說是秒級擴(kuò)容。再次是和Serverless、備份以及故障切換相關(guān)的,我們下面一一來看。
二、騰訊云原生數(shù)據(jù)庫在核心指標(biāo)上的突破
1. 突破一
這是整體上TDSQL-C的一些架構(gòu)和所支持的特性,也是我們的現(xiàn)狀。在實(shí)現(xiàn)TDSQL-C這款計(jì)算和存儲(chǔ)分離的分布式產(chǎn)品里,我們?yōu)榻鉀Q用戶實(shí)際問題而做的一些特性:
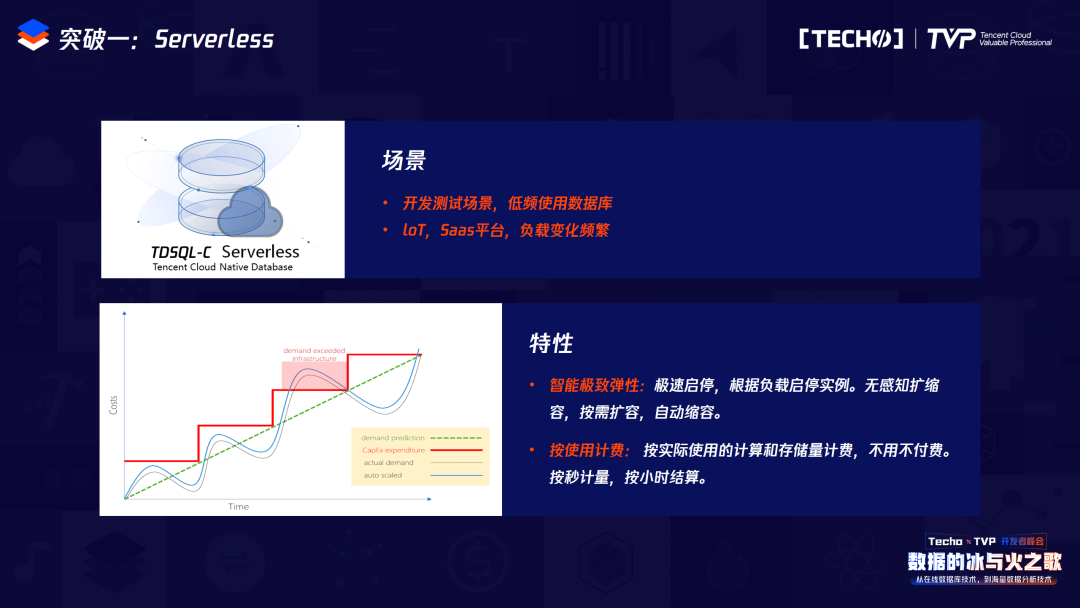
首先是Serverless場景。在支持Serverless之前,我們在做業(yè)務(wù)開發(fā)和運(yùn)維時(shí),會(huì)先購買一個(gè)計(jì)費(fèi)的數(shù)據(jù)庫實(shí)例,包括存儲(chǔ)空間、網(wǎng)絡(luò)存儲(chǔ)空間和計(jì)算資源,都會(huì)從購買的這一刻起開始計(jì)費(fèi)。但是在業(yè)務(wù)開發(fā)的時(shí)候肯定是屬于低頻使用時(shí)期,那么在我們整體的開發(fā)場景,使用數(shù)據(jù)庫的場景較少,在Serverless場景下會(huì)根據(jù)你所使用的時(shí)間來進(jìn)行計(jì)費(fèi),每5秒對這個(gè)實(shí)例打一個(gè)點(diǎn),一分鐘內(nèi)會(huì)有12個(gè)點(diǎn),一小時(shí)之內(nèi)有720個(gè)點(diǎn),真正在打點(diǎn)的時(shí)候使用時(shí)間才會(huì)作為真正的計(jì)費(fèi)時(shí)間。在Serverless場景之下買一個(gè)實(shí)例時(shí),你會(huì)有一個(gè)計(jì)算資源和一個(gè)存儲(chǔ)空間,真正使用時(shí)是全部計(jì)費(fèi)的,但你不使用時(shí),它的計(jì)費(fèi)空間只是存儲(chǔ)空間,所以能降低我們的消費(fèi),并且用戶利潤可以達(dá)到最大化。
也不用關(guān)心什么時(shí)候啟動(dòng)和關(guān)閉Serverless,當(dāng)對它沒有訪問的時(shí)候就自動(dòng)關(guān)閉,當(dāng)再一次發(fā)送請求時(shí),我們會(huì)有中間的方式來自動(dòng)界定它需要再次訪問,那么它會(huì)迅速的把這個(gè)實(shí)例拉起來。所以它有兩個(gè)特性,第一個(gè)是智能極致彈性:極速啟停,第二個(gè)是真正的按使用計(jì)費(fèi)。
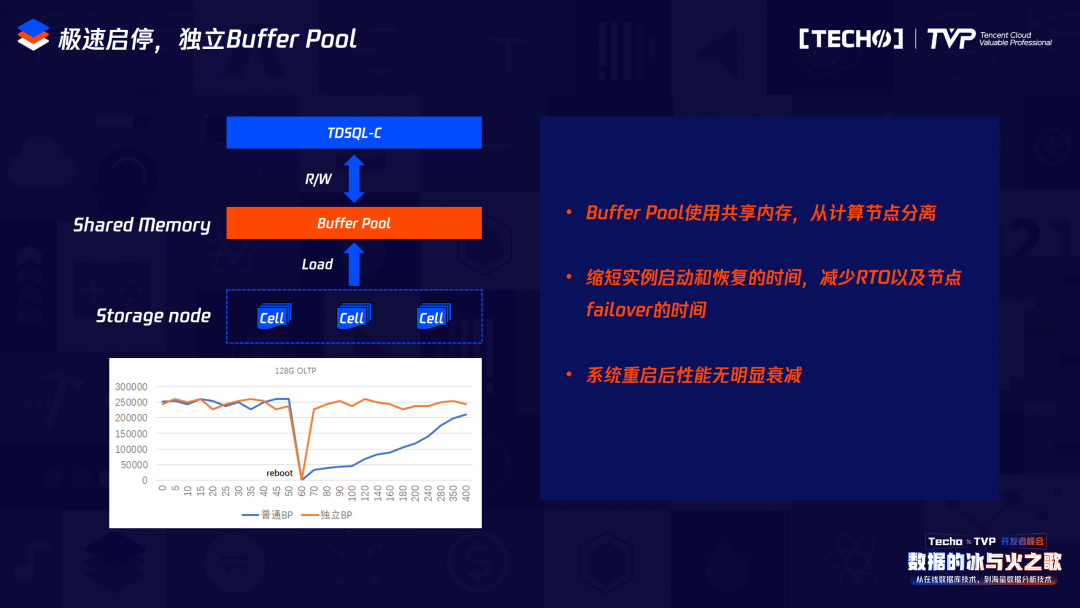
為了實(shí)現(xiàn)Serverless,我們做了以下事情。由于我們是本地網(wǎng)絡(luò),所以網(wǎng)絡(luò)延遲會(huì)增加,為了實(shí)現(xiàn)極速啟停,我們把BP獨(dú)立在MySQL之外,在購買MySQL實(shí)例的或在創(chuàng)建BP的時(shí)候,實(shí)際上它是獨(dú)立于MySQL進(jìn)程之外的。
因?yàn)榉治龅秸麄€(gè)MySQL啟停過程中耗時(shí)間,我們也做了并行化處理,為了能夠滿足真正的“所用即所費(fèi)”。因?yàn)樵贛ySQL里創(chuàng)建一個(gè)表,這時(shí)會(huì)預(yù)先分配表的空間,無論用或不用,這些空間都會(huì)作為使用空間,我們在分配空間的時(shí)候是以exten或者1兆來進(jìn)行分配的,如果你沒有使用這1兆的話,那么這1兆就不會(huì)在你的計(jì)費(fèi)空間以內(nèi),只有真正當(dāng)你寫數(shù)據(jù)在1兆空間的某一頁時(shí),才會(huì)真正災(zāi)容計(jì)費(fèi)存儲(chǔ)量。所以從用戶的角度出發(fā),把用戶的計(jì)費(fèi)存儲(chǔ)量基本降到最低,后續(xù)我們還會(huì)繼續(xù)優(yōu)化,真正做到頁級別的使用計(jì)費(fèi)。
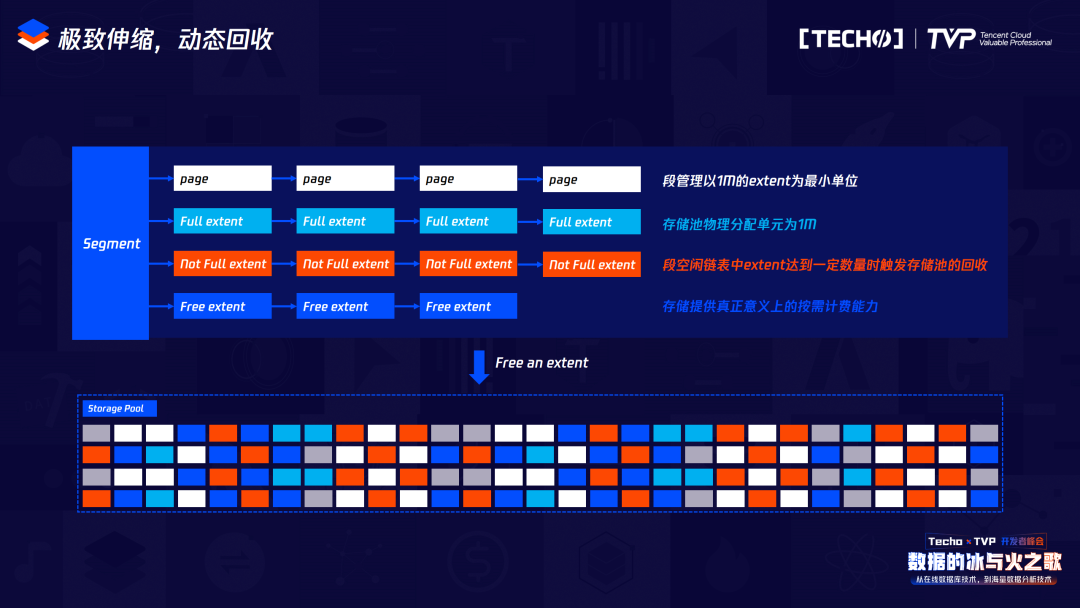
2. 突破二
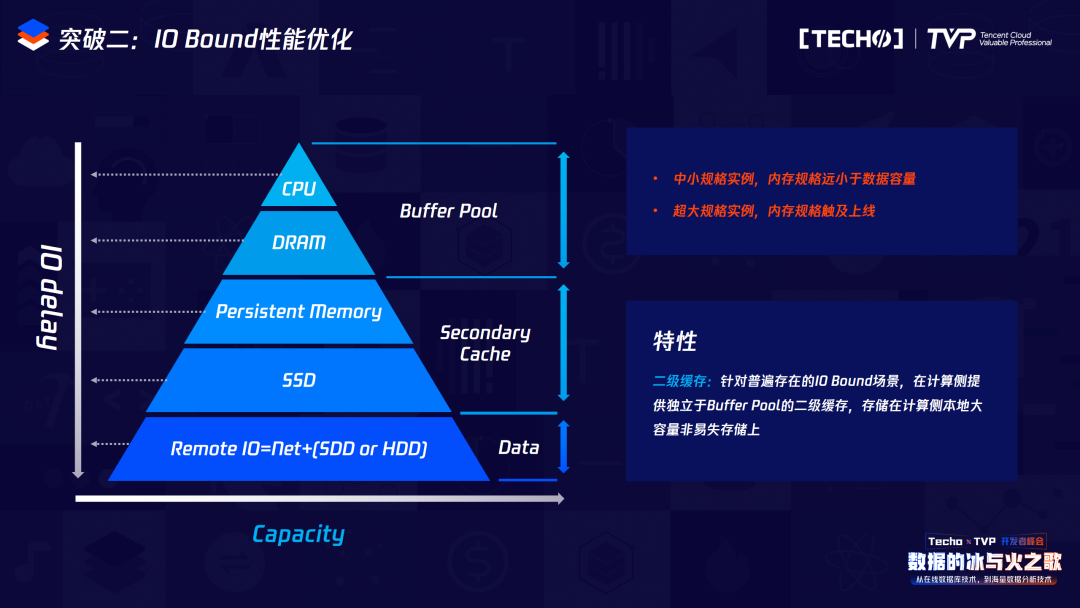
我們單機(jī)容量可能在幾G或幾十G,這個(gè)時(shí)候它的內(nèi)存是比較小的,比如只有幾百個(gè)G的內(nèi)存或者不到一個(gè)T,但是存儲(chǔ)空間可能會(huì)有幾百個(gè)T,這時(shí)屬于典型的IO Bound類型,為了解決這個(gè)問題,我們把這種BP內(nèi)存放到本地做二級緩存,在IO Bound場景之下,實(shí)際上并不是淘汰,而是把它淘汰到我們本地的SSD存儲(chǔ)或者本地的AEP存儲(chǔ),下次用的時(shí)候,可以直接從本地讀取,這樣就可以最大限度降低網(wǎng)絡(luò)IO的消耗。在我們的測試場景里,當(dāng)命中率比較低,甚至在50%以下的時(shí)候,整體的性能是呈指數(shù)級性能提升的。
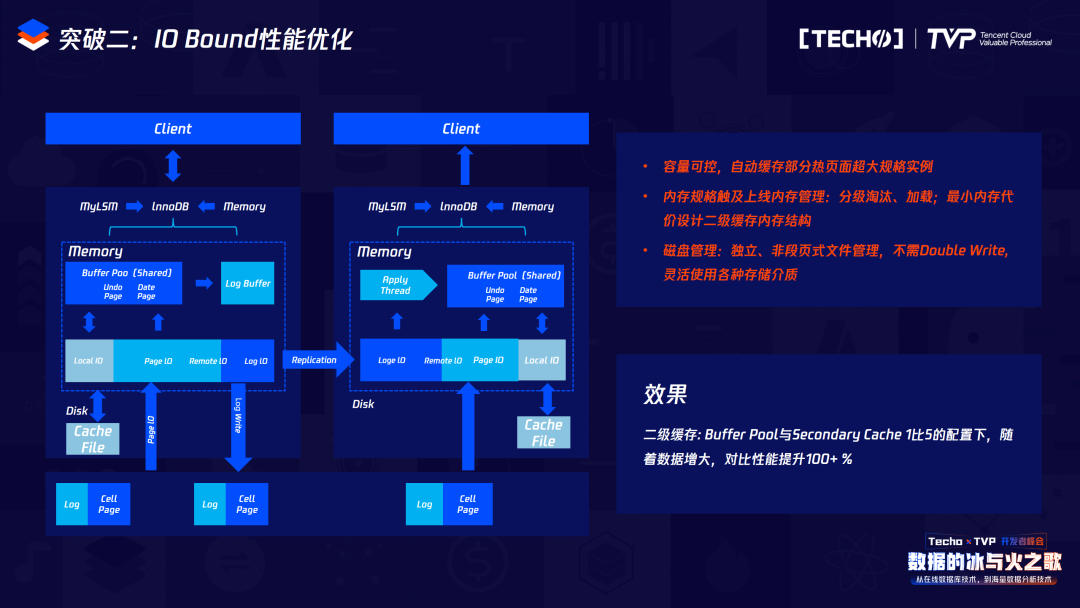
另外是我們越來越本地的磁盤空間做二級緩存的時(shí)候,首先是容量可控的,可以自動(dòng)配置這一塊占用多大的存儲(chǔ)空間作為本地BP的二級緩存。內(nèi)存規(guī)格以及內(nèi)存管理也和BP的內(nèi)存管理是類似的,淘汰的時(shí)候會(huì)首先淘汰本地的二級緩存,當(dāng)本地文件不夠大的時(shí)候,它也會(huì)遵循一系列淘汰算法來進(jìn)行淘汰。磁盤管理獨(dú)立于本地文件,所以它走的不是網(wǎng)絡(luò)IO,那么用本地IO可以彌補(bǔ)整體網(wǎng)絡(luò)IO的消耗,因此整體性能的收益比較明顯。這張圖就是我們本地二級緩存的架構(gòu)圖。
3. 突破三
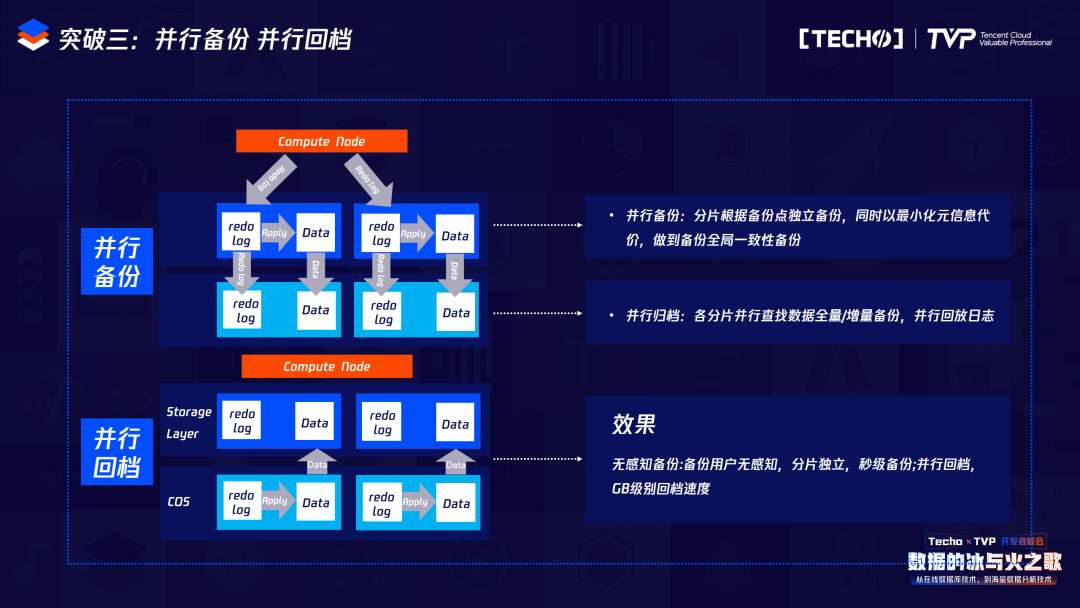
突破三是無感知備份。傳統(tǒng)CDB架構(gòu)或傳統(tǒng)RDS架構(gòu),我們在做備份時(shí)一般都使用邏輯備份或者物理備份,這里面會(huì)有典型的兩個(gè)問題,無論是邏輯備份還是物理備份,都涉及大量的IO操作,會(huì)極大占用集體資源。為了獲取位點(diǎn)做之后的增量備份,會(huì)有一把大鎖。
我們在備份中追求兩個(gè)目標(biāo):第一是無感知備份,讓用戶沒有察覺;第二是極速回檔,因?yàn)樵趥鹘y(tǒng)的備份恢復(fù)時(shí),恢復(fù)是基于本地的,如果是邏輯備份,要導(dǎo)數(shù)據(jù),如果是物理備份,要拷貝數(shù)據(jù),再加上增量備份。所以我們的目標(biāo)是無感知備份和極速回檔,真正做到這兩個(gè)才能實(shí)現(xiàn)秒級擴(kuò)容。
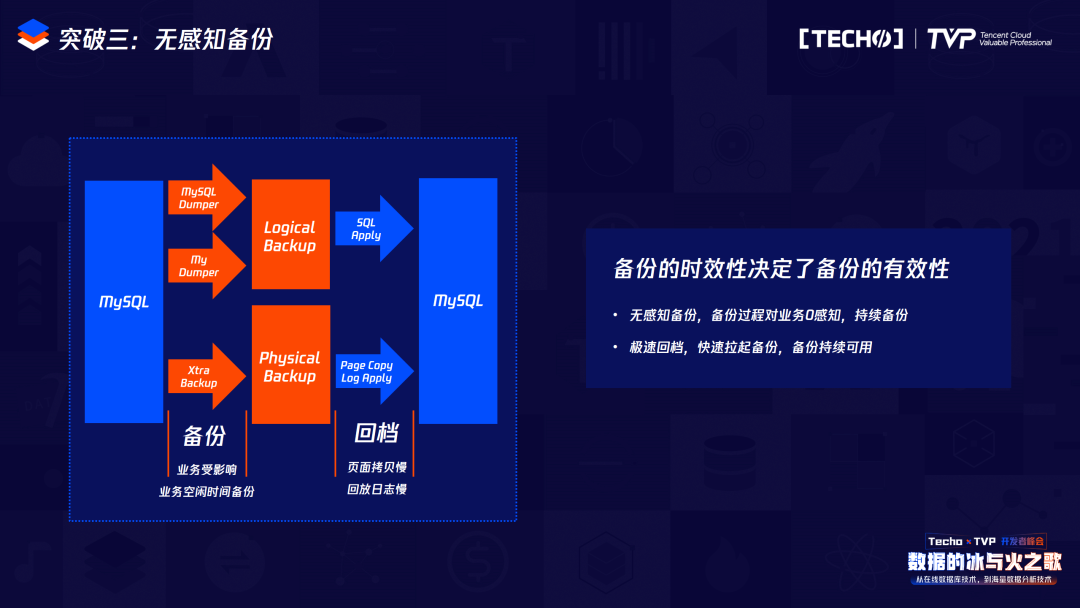
這就是在TDSQL-C里的備份和回檔,備份實(shí)際上是依賴于HiStore做的文件系統(tǒng)的快照備份,相當(dāng)于我如果發(fā)送一個(gè)備份命令,這時(shí)首先會(huì)對我之前的HiStore打一個(gè)快照,之前的寫操作會(huì)寫到新的數(shù)據(jù)存儲(chǔ)的地方,那么在備份時(shí)就會(huì)直接拷貝我原先的數(shù)據(jù),同時(shí)把它上傳到COS里,因?yàn)槲覀兊讓拥膫浞菔欠稚⒌蕉鄠€(gè)cell里,所以備份也是并行備份。在回檔的時(shí)候也屬于并行回檔,它得把Redo log下發(fā)到cell里,那么這個(gè)cell包含原始數(shù)據(jù)以及Redo log,它在回檔的時(shí)候每個(gè)cell會(huì)自行來應(yīng)用這些Redo log。所以無論是備份還是回檔,我們都是實(shí)現(xiàn)并行的,并且在回檔的時(shí)候不是像Binlog的邏輯修改,而是直接定位到一些物理修改,回檔速度也是GB級的。依賴于本地的可計(jì)算存儲(chǔ)以及HiStore的一系列特性,我們可以實(shí)現(xiàn)自動(dòng)的無感知備份以及秒級回檔。
三、TDSQL-C的未來探索
基于我們現(xiàn)在所做的一系列事情,一方面是0-1,另一方面是結(jié)合在運(yùn)維過程中遇到的問題,TDSQL-C后續(xù)的發(fā)展方向有兩點(diǎn):第一點(diǎn)是極簡數(shù)據(jù)庫運(yùn)維。從運(yùn)維的角度來鑒定之后的發(fā)展方向,首先是智能挑戰(zhàn),用過MySQL或CDB的人都應(yīng)該會(huì)在MySQL的優(yōu)化器上遇到一些問題,比如升級時(shí)發(fā)現(xiàn)它的執(zhí)行計(jì)劃走錯(cuò),或者當(dāng)數(shù)據(jù)量達(dá)到一定程度的時(shí)候執(zhí)行計(jì)劃也會(huì)走錯(cuò),TDSQL-C的內(nèi)核會(huì)在優(yōu)化器里優(yōu)化整體的統(tǒng)計(jì)信息,并且對它的執(zhí)行計(jì)劃進(jìn)行判定,動(dòng)態(tài)調(diào)優(yōu)。比如在升級的時(shí)候,如果發(fā)現(xiàn)它的執(zhí)行計(jì)劃出錯(cuò),可以自動(dòng)對它進(jìn)行糾正,并且發(fā)給運(yùn)維。
因?yàn)樵趯?shí)現(xiàn)計(jì)算和存儲(chǔ)分離產(chǎn)品的時(shí)候我們對內(nèi)核的代碼修改量較大,并且要增加存儲(chǔ)量,在讀寫極致性能優(yōu)化上我們也做了相應(yīng)的修改,所以我們?yōu)榱吮WC它的邏輯嚴(yán)謹(jǐn)性也會(huì)做相應(yīng)的事,包括會(huì)引入業(yè)界相關(guān)的設(shè)施,從原理上進(jìn)行把控對于內(nèi)核的修改。從成本的角度來看,在Serverless場景下成本大部分是存儲(chǔ)所帶來的,所以要降低用戶的成本。可以從兩方面:一方面是用戶真正用的才是他所需要付費(fèi)的內(nèi)容。這里有一個(gè)存儲(chǔ)空間的概念,存儲(chǔ)空間我們要真正做到頁級別,另外一種現(xiàn)在是三副本,可以通過數(shù)據(jù)壓縮存儲(chǔ)、糾刪碼等技術(shù)降低存儲(chǔ)空間,把本身的災(zāi)容數(shù)據(jù)存儲(chǔ)空間降低在1/3左右,這也是我們后續(xù)的一個(gè)發(fā)力方向。
第三點(diǎn)是效率問題,因?yàn)樽鯠DL,當(dāng)我們單機(jī)單表容量達(dá)到上T級別的時(shí)候,在MySQL內(nèi)部會(huì)首先掃描它的索引,來掃描所有這個(gè)索引相關(guān)的數(shù)據(jù),每個(gè)進(jìn)行排序,再做歸并排序,再建立索引,這一系列的過程實(shí)際上是很費(fèi)時(shí)的。針對這種操作,我們有兩方面的優(yōu)化思路:第一方面是instant DDL,對于每個(gè)字節(jié)所占用大小之間的改變,會(huì)支持更多的instant DDL。第二是通過它創(chuàng)建索引的這個(gè)過程,會(huì)把剛才所涉及到的像掃描B樹、排序、建B+樹這一系列過程全部并行化,如果能夠走instant DDL的,可以實(shí)現(xiàn)秒級 ddl 操作,如果不能走instant DDL的操作,會(huì)進(jìn)行parallel index 處理。

面向業(yè)務(wù)的Low Database開發(fā),特別是在TDSQL-C這款產(chǎn)品里,數(shù)據(jù)存儲(chǔ)規(guī)模會(huì)比較大,比如上幾百個(gè)T或者類似于最大容量的P級別,那么這個(gè)時(shí)候數(shù)據(jù)分析能力就要提升,首先我們會(huì)提升它的最大存儲(chǔ)量,通過優(yōu)化器以及并行執(zhí)行框架,最大限度地使用機(jī)器的資源來提升單機(jī)存儲(chǔ)量。我們在存儲(chǔ)方面會(huì)利用新的介質(zhì),比如AEP或者SSD,來極大提升本地的比如剛才所介紹的二級緩存,或者是把一系列可以在本地操作的做到最大加速。
從業(yè)務(wù)類型來看,比如金融或是政務(wù)容災(zāi)合規(guī)這類業(yè)務(wù),我們會(huì)進(jìn)行全鏈路審計(jì),包括字段加密,同時(shí)也會(huì)就全球異地容災(zāi)、就近訪問的原則優(yōu)化 TDSQL-C 的產(chǎn)品能力。

最后是會(huì)在TDSQL-C產(chǎn)品里集成AP的能力,我們現(xiàn)在正在開發(fā)一款列存產(chǎn)品,內(nèi)置到TDSQL-C里,在本地用列存來啟動(dòng)整個(gè)場景加速。
講師簡介

張青林
騰訊云數(shù)據(jù)庫技術(shù)總監(jiān)
騰訊云數(shù)據(jù)庫CDB、TDSQL-C數(shù)據(jù)庫內(nèi)核研發(fā)負(fù)責(zé)人。騰訊云數(shù)據(jù)庫技術(shù)總監(jiān),騰訊云布道師,MySQL架構(gòu)師,現(xiàn)騰訊云架構(gòu)平臺(tái)部云原生數(shù)據(jù)庫內(nèi)核研發(fā)團(tuán)隊(duì)技術(shù)負(fù)責(zé)人,Mariadb 基金董事會(huì) & Mariadb 社區(qū)版本開發(fā)成員,專注于MySQL內(nèi)核開發(fā)和相關(guān)架構(gòu)、產(chǎn)品化工作。
點(diǎn)擊觀看峰會(huì)的精彩總結(jié)視頻??

<b id="afajh"><abbr id="afajh"></abbr></b>