
詳解pd.DataFrame中的幾種索引變換
導讀
pandas中最常用的數(shù)據(jù)結(jié)構(gòu)是DataFrame,而DataFrame相較于嵌套list或者二維numpy數(shù)組更好用的原因之一在于其提供了行索引和列名。本文主要介紹行索引的幾種變換方式,包括rename與reindex、index.map、set_index與reset_index、stack與unstack等。
慣例開局一張圖
Series和DataFrame是pandas中的主要數(shù)據(jù)結(jié)構(gòu)類型(老版本中曾有三維數(shù)據(jù)結(jié)構(gòu)Panel,是DataFrame的容器,后被取消),而二者相較于傳統(tǒng)的數(shù)組或list而言,最大的便利之處在于其提供了索引,DataFrame中還有列標簽名,這些都使得在操作一行或一列數(shù)據(jù)中非常方便,包括在數(shù)據(jù)訪問、數(shù)據(jù)處理轉(zhuǎn)換等。關于索引的詳細介紹可參考前文:python數(shù)據(jù)科學系列:pandas入門詳細教程。
這里,為了便于后文舉例解釋,給出基本的DataFrame樣例數(shù)據(jù)如下:
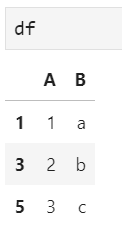
后文將以此作為操作對象,針對索引的幾種常用變換進行介紹。
注:這里的索引應廣義的理解為既包擴行索引,也包括列標簽。
學習pandas之初,reindex和rename容易使人混淆的一組接口,就其具體功能來看:
reindex執(zhí)行的是索引重組操作,接收一組標簽序列作為新索引,既適用于行索引也適用于列標簽名,重組之后索引數(shù)量可能發(fā)生變化,索引名為傳入標簽序列
rename執(zhí)行的是索引重命名操作,接收一個字典映射或一個變換函數(shù),也均適用于行列索引,重命名之后索引數(shù)量不發(fā)生改變,索引名可能發(fā)生變化
另外二者執(zhí)行功能和接收參數(shù)的套路也是很為相近的,均支持兩種變換方式:
一種是變換內(nèi)容+axis指定作用軸(可選0/1或index/columns);
另一種是直接用index/columns關鍵字指定作用軸



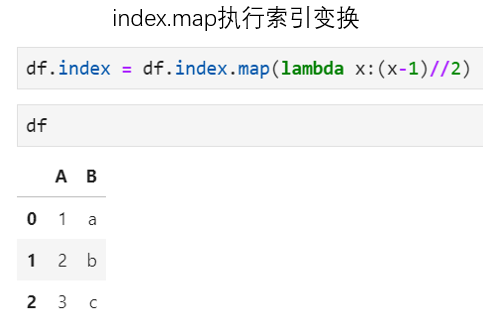
針對DataFrame中的數(shù)據(jù),pandas中提供了一對功能有些相近的接口:map和apply,以及applymap,其中map僅可用于DataFrame中的一列(也即即Series),可接收字典或函數(shù)完成單列數(shù)據(jù)的變換;apply既可用于一列(即Series)也可用于多列(即DataFrame),但僅可接收函數(shù)作為參數(shù),當作用于Series時對每個元素進行變換,作用于DataFrame時對其中的每一行或每一列進行變換;而applymap則僅可作用于DataFrame,且作用對象是對DataFrame中的每個元素進行變換。也就是說,三者的最大不同在于作用范圍以及變換方式的不同。

這也是一對互逆的操作,其中stack原義表示堆疊,實現(xiàn)將所有列標簽堆疊到行索引中;unstack即解堆,用于將復合行索引中的一個維度索引平鋪到列標簽中。實際上,二者的操作即是SQL中經(jīng)典的行轉(zhuǎn)列與列轉(zhuǎn)行,也即在長表與寬表之間轉(zhuǎn)換。
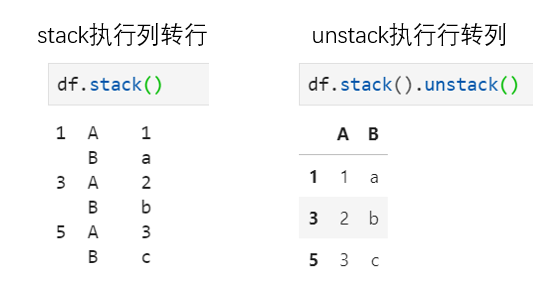
當然,實現(xiàn)unstack操作的方式還有pivot,此處不再展開。
相關閱讀: