
Spark 特性 | 即將發(fā)布的 Apache Spark 3.2 將內(nèi)置 Pandas API
在即將發(fā)布的 Apache Spark? 3.2 版本中 pandas API 將會成為其中的一部分。Pandas 是一個強(qiáng)大、靈活的庫,并已迅速發(fā)展成為標(biāo)準(zhǔn)的數(shù)據(jù)科學(xué)庫之一。現(xiàn)在,pandas 的用戶將能夠在他們現(xiàn)有的 Spark 集群上利用 pandas API。
幾年前,我們啟動了 Koalas 這個開源項目,它在 Spark 之上實(shí)現(xiàn)了 Pandas DataFrame API,并被數(shù)據(jù)科學(xué)家廣泛采用。最近,Koalas 作為 Project Zen 的一部分被正式合并到 PySpark 中,具體參見 SPIP: Support pandas API layer on PySpark,也可以參見 Data + AI Summit 2021 中的 Project Zen: Making Data Science Easier in PySpark 議題分享。
在即將發(fā)布的 Spark 3.2 版本中,pandas 用戶僅需要修改一行就可以以分布式的方式使用現(xiàn)有工作負(fù)載:
from pandas import read_csvfrom pyspark.pandas import read_csvpdf = read_csv("data.csv")修改為from pyspark.pandas import read_csvpdf = read_csv("data.csv")
本文總結(jié)了 Spark 3.2 上的 Pandas API 支持,并重點(diǎn)介紹了值得注意的特性、變化和路線圖。
更好的擴(kuò)展性
眾所周知,pandas 的一個限制是只能單機(jī)處理,它不能隨數(shù)據(jù)量線性伸縮。例如,如果 pandas 試圖讀取的數(shù)據(jù)集大于一臺機(jī)器的可用內(nèi)存,則會因內(nèi)存不足而失敗:
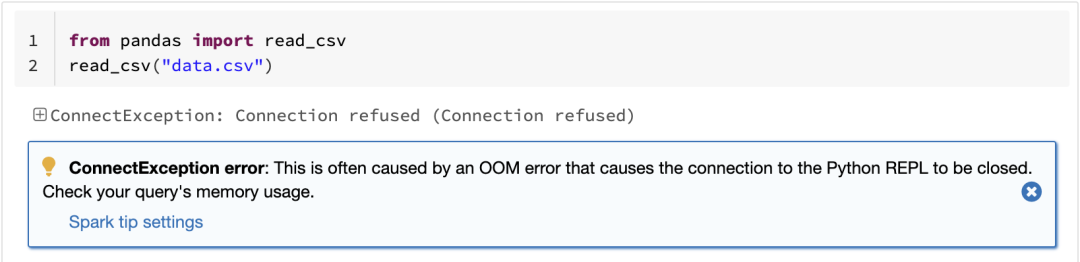
Spark 上的 pandas API 克服了這個限制,使用戶能夠通過利用 Spark 來處理大型數(shù)據(jù)集:

如果想及時了解Spark、Hadoop或者HBase相關(guān)的文章,歡迎關(guān)注微信公眾號:過往記憶大數(shù)據(jù)?
Spark 上的 pandas API 也可以很好地擴(kuò)展到大型節(jié)點(diǎn)集群。下圖顯示了使用部分規(guī)模的集群分析 15TB 大小的 Parquet 數(shù)據(jù)集時的性能。集群中的每臺機(jī)器都有 8 個 vCPU 和 61 GiBs 內(nèi)存。
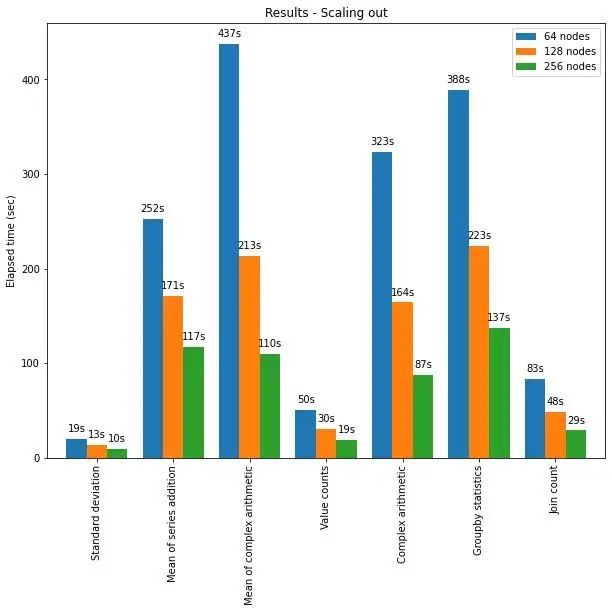
在此測試中,Pandas API 在 Spark 上的分布式執(zhí)行幾乎呈線性擴(kuò)展。當(dāng)集群中的機(jī)器數(shù)量增加一倍時,運(yùn)行時間減少一半。與單臺機(jī)器相比,加速也很顯著。例如,在標(biāo)準(zhǔn)偏差基準(zhǔn)(Standard deviation benchmark)測試中,由 256 臺機(jī)器組成的集群可以在大致相同的時間內(nèi)處理比單臺機(jī)器多 250 倍的數(shù)據(jù)(每臺機(jī)器有 8 個 vCPU 和 61 GiB 內(nèi)存):
| Single machine | Cluster of 256 machines | |
| Parquet Dataset | 60GB | 60GB x 250 (15TB) |
| Elapsed time (sec) of Standard deviation | 12s | 10s |
優(yōu)化單機(jī)性能
由于 Spark 引擎中的優(yōu)化,Spark 上的 pandas API 甚至在單臺機(jī)器上的性能都優(yōu)于 pandas。下圖展示了在一臺機(jī)器(具有 96 個 vCPU 和 384 GiBs 內(nèi)存)上運(yùn)行 Spark 和單獨(dú)調(diào)用 pandas 分析 130GB 的 CSV 數(shù)據(jù)集的性能對比。
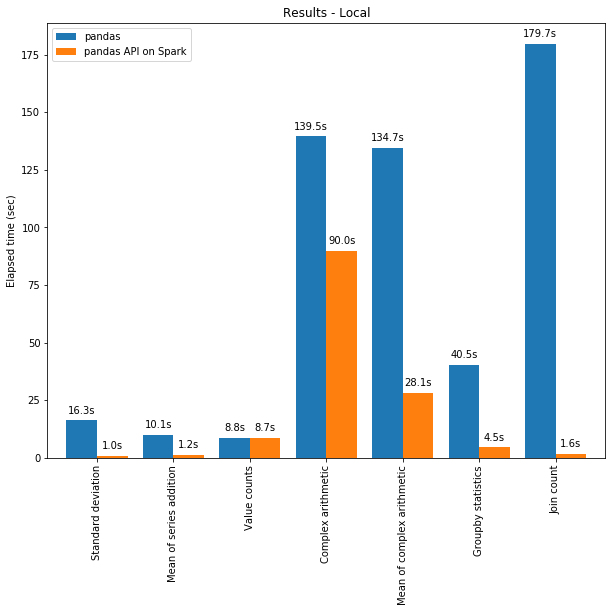
多線程和 Spark SQL Catalyst Optimizer 都有助于優(yōu)化性能。例如,Join count 操作在整個階段代碼生成時快 4 倍:沒有代碼生成時為 5.9 秒,代碼生成時為 1.6 秒。
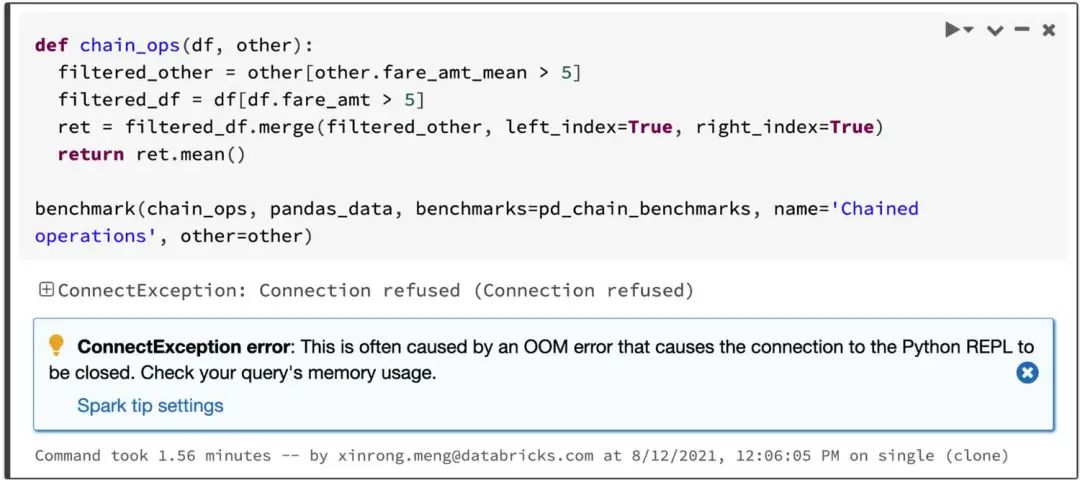
Spark 在鏈?zhǔn)讲僮鳎╟haining operations)中具有特別顯著的優(yōu)勢。Catalyst 查詢優(yōu)化器可以識別過濾器以明智地過濾數(shù)據(jù)并可以應(yīng)用基于磁盤的連接(disk-based joins),而 Pandas 傾向于每一步將所有數(shù)據(jù)加載到內(nèi)存中。
考慮兩個過濾數(shù)據(jù)進(jìn)行 JOIN,然后計算數(shù)據(jù)集的平均值的查詢,Spark 上的 Pandas API 在 4.5 秒內(nèi)成功,而 Pandas 由于 OOM(內(nèi)存不足)錯誤而失敗,如下所示:
以可視化的方式交互式操作數(shù)據(jù)
pandas 默認(rèn)使用 matplotlib,它提供靜態(tài)繪圖圖表。例如,下面的代碼生成一個靜態(tài)圖表:
# Areapandas.DataFrame(np.random.rand(100, 4), columns=list("abcd")).plot.area()

相反,Spark 上的 Pandas API 默認(rèn)使用 plotly,它提供交互式圖表。例如,它允許用戶交互地放大和縮小。根據(jù)圖的類型,Spark 上的 pandas API 在生成交互式圖表時會自動確定在內(nèi)部執(zhí)行計算的最佳方式:
# Areapandas.DataFrame(np.random.rand(100, 4), columns=list("abcd")).plot.area()
利用 Spark 中的統(tǒng)一分析功能
pandas 是為 Python 數(shù)據(jù)科學(xué)的批處理而設(shè)計的,而 Spark 是為統(tǒng)一分析而設(shè)計的,包括 SQL、流處理和機(jī)器學(xué)習(xí)。為了填補(bǔ)它們之間的空白,Spark 上的 Pandas API 為高級用戶提供了許多不同的方式來利用 Spark 引擎,例如:
用戶可以使用 Spark 優(yōu)化后的 SQL 引擎直接通過 SQL 查詢數(shù)據(jù),如下圖:
>>> import pandas as pd>>> import pyspark.pandas as ps>>> pdf = pd.DataFrame({"a": [1, 3, 5]}) # pandas DataFrame>>> sdf = spark.createDataFrame(pdf) # PySpark DataFrame>>> psdf = sdf.to_pandas_on_spark() # pandas-on-Spark DataFrame>>> # Query via SQL... ps.sql("SELECT count(*) as num FROM {psdf}")
它還支持字符串插值語法(string interpolation syntax)以自然地與 Python 對象交互:
>>> pred = range(4)>>> # String interpolation with Python instances... ps.sql("SELECT * from {psdf} WHERE a IN {pred}")
Spark 上的 pandas API 也支持流處理:
>>> def func(sdf, _):... # pandas-on-Spark DataFrame... psdf = sdf.to_pandas_on_spark()... psdf.describe()...>>> spark.readStream.format(... "kafka").load().writeStream.foreachBatch(func).start()
用戶可以輕松調(diào)用 Spark 中可擴(kuò)展的機(jī)器學(xué)習(xí)庫:
>>> from pyspark.ml.feature import StringIndexer>>> sdf = psdf.to_spark() # PySpark DataFrame>>> indexer = StringIndexer(... inputCol="category", outputCol="categoryIndex")>>> indexed = indexer.fit(sdf).transform(sdf)>>> indexed.show()
下一步
對于下一個 Spark 版本,重點(diǎn)關(guān)注以下幾個方向:
更多類型提示
Spark 上的 Pandas API 中的代碼目前是部分類型化的,它仍然支持靜態(tài)分析和自動完成。將來,所有代碼都將是完全類型化的。
性能提升
Spark 上的 Pandas API 有幾個地方,我們可以通過與引擎和 SQL 優(yōu)化器更密切的交互來進(jìn)一步提高性能。
穩(wěn)定性
有幾個地方需要修復(fù),特別是與缺失值相關(guān)的地方,例如 NaN 和 NA 具有行為差異的極端情況。
此外,在這些情況下,Spark 上的 Pandas API 將遵循并將其行為與最新版本的 Pandas 匹配。
更多 API 覆蓋
Spark 上的 Pandas API 達(dá)到了 Pandas API 的 83% 覆蓋率,并且這個數(shù)字還在繼續(xù)增加,現(xiàn)在目標(biāo)高達(dá) 90%。