
jvm層gc調(diào)優(yōu)
點擊上方藍(lán)色字體,選擇“標(biāo)星公眾號”
優(yōu)質(zhì)文章,第一時間送達(dá)
jvm的內(nèi)存結(jié)構(gòu)
java 8 jvm官方文檔
https://docs.oracle.com/javase/specs/jvms/se8/html/index.html
運行時數(shù)據(jù)區(qū)
官方文檔:
https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-2.html#jvms-2.5
運行時數(shù)據(jù)區(qū)有:方法區(qū)、虛擬機棧、本地方法棧、堆、程序計數(shù)器
計數(shù)器pc register
jvm支持多線程同時執(zhí)行,每一個線程都有自己的pc register,線程正在執(zhí)行的方法叫做當(dāng)前方法,如果是java代碼pc register里面存放的就是當(dāng)前正在執(zhí)行的指令的地址,如果是c代碼,則為空
虛擬機棧jvm stacks
java虛擬機棧(java virtual machine stacks)是線程私有的,它的生命周期與線程相同。虛擬機棧描述的是java方法執(zhí)行的內(nèi)存模型;每隔方法在執(zhí)行的同事都會創(chuàng)建一個棧幀,用于存儲局部變量表、操作數(shù)棧、動態(tài)鏈接、方法出口等信息,每一個方法從調(diào)用直至執(zhí)行完成的過程,就對應(yīng)著一個棧幀在虛擬機中入棧到出棧的過程。
堆heap
java堆是java虛擬機所管理的內(nèi)存中最大的一塊。堆是被所有線程共享的一塊內(nèi)存區(qū)域,在虛擬機啟動時穿件。此內(nèi)存區(qū)域的唯一目的就是存放對象實例,幾乎所有的對象實例都在這里分配內(nèi)存。java堆可以處于物理上不連續(xù)的內(nèi)存空間中,只要邏輯上是連續(xù)的就可以。
方法區(qū)Method Area
方法區(qū)域java堆一樣,是哥哥線程共享的內(nèi)存區(qū)域,它用于存儲已被虛擬機加載的類信息、常量、靜態(tài)變量、即時編譯器編譯后的代碼等數(shù)據(jù)。雖然java虛擬機規(guī)范把方法區(qū)描述為堆的一個邏輯部分,但是它卻又一個別名叫做non-heap(非堆),目的是與java堆區(qū)分開來。
常量池 run-time constant pool
運行時常量池是方法區(qū)的一部分。class文件中除了有類的版本、字段、方法、接口等描述信息外,還有一項信息是常量池(constant pool table),用于存放編譯期生成的各種字面量和符號引用,這部分內(nèi)容將在類加載后進入方法區(qū)的運行時常量池中存放。
本地方法棧native method stacks
本地方法棧與虛擬機棧所發(fā)揮的作用是非常相似的,他們之間的區(qū)別不過是虛擬機棧為虛擬機執(zhí)行java方法(也就是字節(jié)碼)服務(wù),而本地方法棧則為用虛擬機使用到的native方法服務(wù)。
堆區(qū)
堆區(qū)分為老年代old和新生代(Young),新生代又分為eden和s0和s1區(qū)。
非堆區(qū)
metaspace=class、package、method、field、字節(jié)碼、常量池、符號引用等。
css:32位指針的class
通過添加虛擬機參數(shù):+UseCompressedClassPointers使用ccs,通過:jstat -gc pid查看CCS
codecache:JIT編譯后的本地代碼、JNI使用的C代碼
關(guān)于一些名詞的解釋
常用參數(shù)
-Xms -Xmx
-XX:NewSize -XX:MaxNewSize
-XX:NewSize -XX:MaxNewSize
-XX:NewRatio -XX:SurvivorRatio
-XX:MetaspaceSize -XX:MaxMetaspaceSize
-XX:+UseCompressedClassPointers
-XX:CompressedClassSpaceSize
-XX:InitialCodeCacheSize
-XX:ReservedCodeCacheSize
垃圾回收算法
思想
枚舉根節(jié)點,做可達(dá)性分析
根節(jié)點
類加載器、Thread、虛擬機棧的本地變量表、static成員、常量引用、本地方法棧的變量等等
標(biāo)記清除
算法
算法分為“標(biāo)記”和“清除”兩個階段:首先標(biāo)記處所有需要回收的對象,在標(biāo)記完成后統(tǒng)一回收所有
缺點
效率不高。標(biāo)記和清除兩個過程的效率都不高。產(chǎn)生碎片。碎片太多會導(dǎo)致提前GC
復(fù)制算法
它將可用內(nèi)存按容量分為大小相等的兩塊,每次只使用其中的一塊,當(dāng)這一塊的內(nèi)存用完了,就將還存活的對象復(fù)制到另外一塊上面,然后再把已使用過的內(nèi)存空間一次清理掉。
優(yōu)缺點
實現(xiàn)簡單。運行高效,但是空間利用率低。
標(biāo)記整理
算法
標(biāo)記過程仍然與“標(biāo)記-清除”算法一樣,但后續(xù)步驟不是直接對可回收對象進行清理,而是讓所有存活的對象都向一端移動,然后直接清理掉端以外的內(nèi)存
優(yōu)缺點
沒有了內(nèi)存碎片,但是整理內(nèi)存比較耗時
分代回收算法
Young區(qū)用復(fù)制算法
Old區(qū)用標(biāo)記清除或者標(biāo)記整理
對象分配
對象優(yōu)先在Eden區(qū)分配
大對象直接進入老年代:-XX:PretenureSizeThreshold
長期存活對象進入老年代:-XX:MaxTenuringThreshold -XX:+PrintTenuringDistribution -XX:TargetSurvivorRatio
垃圾收集器
知乎上優(yōu)秀的回答:
https://www.zhihu.com/question/35164211
垃圾收集器
串行收集器Serial:Serial、Serial Old
并行收集器Parallel:Parallel Scavenge、Parallel Old,吞吐量
并發(fā)收集器Concurrent:CMS、G1、停頓時間
并行vs并發(fā)
并行(Parallel):指多條垃圾收集線程并行工作,但此時用戶線程仍然處于等待狀態(tài)。適合科學(xué)計算、后臺處理等弱交互場景
并發(fā)(Concurrent):指用戶線程與垃圾收集線程同時執(zhí)行(但不一定是并行的,可能會交替執(zhí)行),垃圾收集線程在執(zhí)行的時候不會停頓用戶程序的運行。適合對響應(yīng)時間有要求的場景,比如web。
停頓時間vs吞吐量
停頓時間:垃圾收集器做垃圾回收中斷應(yīng)用程序執(zhí)行時間。-XX:MaxGCPauseMillis
吞吐量:花在垃圾收集的時候和花在應(yīng)用時間的占比 .
XX:GCTimeRatio=,垃圾收集的時間占比:1/1+n
并行收集器
吞吐量優(yōu)先
-XX:+UseParallelGC,-XX:+UseParallelOldGC
Server模式下的默認(rèn)收集器
查看:jinfo -flag UseParallelOldGC pid
并行收集器
響應(yīng)時間優(yōu)先
CMS:XX:+UseConcMarkSweepGC -XX:+UseParNewGC
G1:-XX:+UseG1GC
查看:jinfo -flag UseConcMarkSweepGC pid
垃圾收集器搭配
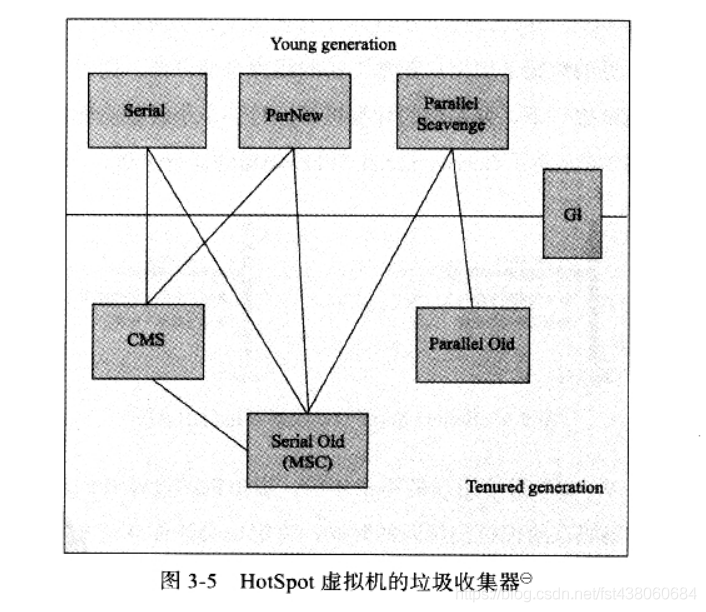
可以從老年代記起:SerialOld最厲害,可以搭配所有的新生代收集器;
ParallelOld只能搭配Parallel新生代的,也就是Parallel Scavenge;
CMS 只能搭配Serial和ParNew;
最后G1只能自己和自己玩。
如何選擇垃圾收集器
優(yōu)先調(diào)整堆的大小讓服務(wù)器自己來選擇
如果內(nèi)存小于100M,使用串行收集器
如果是單核,并且沒有時間停頓的要求,串行或者讓jvm自己選
如果允許停頓時間操作1秒,選擇并行或者讓jvm自己選
如果響應(yīng)時間最重要,并且不能操作1秒,使用并發(fā)收集器
GC調(diào)優(yōu)指南:
https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/toc.html
如何選擇垃圾收集器:
https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/collectors.html
Parallel Collector
-XX:+UseParallelGC 手動開啟,Server默認(rèn)開啟
-XX:ParallelGCThreads= 多少個GC線程
CPU>8 N=5/8
CPU< 8 N=CPU
-XX:MaxGCPauseMillis=
-XX:GCTimeRatio=
-Xmx
動態(tài)內(nèi)存調(diào)整
-XX:YoungGenerationSizeIncrement=也就是每次gc之后發(fā)現(xiàn)之前的內(nèi)存不夠,那么就會動態(tài)增加內(nèi)存
-XX:TenuredGenerationSizeIncrement=
-XX:AdaptiveSizeDecrementScaleFactor=
CMS Collector
特點
并發(fā)收集
低停頓 低延時
老年代收集器
CMS垃圾收集過程
1、CMS initial mark:初始標(biāo)記root,STW
2、CMS concurrent mark:并發(fā)標(biāo)記
3、CMS-concurrent-preclean:并發(fā)預(yù)清理
4、CMS remark:重新標(biāo)記,STW
5、CMS concurrent sweep:并發(fā)清除
6、CMS-concurrent-reset:并發(fā)重置
CMS的特點
CPU敏感
浮動垃圾
空間碎片
CMS的相關(guān)參數(shù)
-XX:ConcGCThreads:并發(fā)的GC線程數(shù)
-XX:+UseCMSCompactAtFullCollection:FullGC之后做壓縮
-XX:CMSFullGCsBeforeCompaction:多少次FullGC之后壓縮一次
-XX:CMSInitiatingOccupancyFraction:觸發(fā)FullGC
-XX:+UseCMSInitiatingOccupancyOnly:是否動態(tài)調(diào)整
-XX:+CMSScavengeBeforeRemark:FullGC之前先做YGC
-XX:+CMSClassUnloadingEnabled:啟用回收Perm區(qū)
iCMS
使用于單核或者雙核
G1 Collector
G1垃圾收集器介紹:https://zhuanlan.zhihu.com/p/22591838
簡介:
The first focus of G1 is to provide a solution for users running applications that require large heaps with limited GC latency.This means heap sizes of around 6GB or larger,and a stable and predictable pause time below 0.5 senconds.
G1屬于新生代和老生代收集器
G1的幾個概念
Region
SATB:Snapshot-At-The-Beginning,它是通過Root Tracing得到的,GC開始時候存活對象的快照。
RSet:記錄了其他Region中的對象引用本Region中對象的關(guān)系,屬于points-into結(jié)構(gòu)(誰引用了我的對象)
YoungGC
新對象進入Eden區(qū)
存活對象拷貝到Survivor區(qū)
存活時間達(dá)到年齡閾值是,對象晉升到Old區(qū)
MixedGC
不是FullGC,回收所有的Young和部分Old
global concurrent marking
global concurrent marking
1、initial marking phase:標(biāo)記GC Root,STW
2、Root region scanning phase:標(biāo)記存活Region
3、Concurrent marking phase:標(biāo)記存活的對象
4、Remark phase:重新標(biāo)記,STW
5、Cleanup phase:部分STW
MixedGC時機
initiationHeapOccupancyPercent:堆占有率達(dá)到這個數(shù)值則觸發(fā)global concurrent marking,默認(rèn)45%
G1HeapWastePercent:在global concurrent marking結(jié)束之后,可以知道區(qū)有多少空間要被回收,在每次YGC之后和再次發(fā)生Mixed GC之前,會檢查垃圾占比是否達(dá)到此參數(shù),只有達(dá)到了,下次才會發(fā)生Mixed GC
MixedGC相關(guān)參數(shù)
G1MixedGCLiveThresholdPercent:Old 區(qū)的region被回收時候的存活對象占比
G1MixedGCCountTarget:
一次global concurrent marking之后,最多執(zhí)行Mixed GC的次數(shù)
G1OldCSetRegionThresholdPercent:一次Mixed GC中能被選入CSet的最多old區(qū)的region數(shù)量
常用參數(shù)
-XX:+UseG1GC 開啟G1
-XX:G1HeapRegionSize=n,region的大小,1~32M,2048個
-XX:MaxGCPauseMilles=200最大停頓時間
-XX:G1NewSizePercent,-XX:G1MaxNewSizePercent
-XX:G1ReservePercent=10, 保留防止to space溢出
-XX:ParallelGCThreads=n STW線程數(shù)
-XX:ConcGCThreads=n 并發(fā)線程數(shù)=1/4*并發(fā)
最佳實踐
年輕代大小
避免使用-Xmn、-XX:NewRatio等顯示設(shè)置Young區(qū)大小,會覆蓋停頓時間目標(biāo)
暫停時間目標(biāo)
暫停時間不要太苛刻,其吞吐量目標(biāo)是90%的應(yīng)用程序的時間和10%的垃圾回收時間,太苛刻會直接影響到吞吐量
關(guān)于MixedGC調(diào)優(yōu)
-XX:InitiatingHeapOccupancyPercent
-XX:G1MixedGCLiveThresholdPercent、-XX:G1HeapWastePercent
-XX:G1MixedGCCountTarget
-XX:G1OldCSetRegionThresholdPercent
MixedGC調(diào)優(yōu)推薦:
https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/g1_gc_tuning.html#recommendations
G1垃圾收集器介紹:
https://zhuanlan.zhihu.com/p/22591838
是否需要切換到G1
50%以上的堆被存活對象占用
對象分配和晉升的速度變化非常大
垃圾回收的時間特別長、超過了一秒
可視化gc日志分析工具
打印日志相關(guān)參數(shù)
-XX:+PrintGCDetails -XX:+PrintGCTimeStamps
-XX:+PrintGCDateStamps
-Xloggc:$CATALINA_HOME/logs/gc.log :打印日志的位置
-XX:+PrintHeapAtGC
-XX:+PrintTenuringDistribution
cms日志
https://blogs.oracle.com/poonam/understanding-cms-gc-logs
g1日志
https://blogs.oracle.com/poonam/understanding-g1-gc-logs
在線工具:http://gceasy.io/
GCViewer
https://github.com/chewiebug/GCViewer
直接啟動java -jar 啟動就可以了
主要關(guān)注吞吐量和停頓時間這些值
Tomcat的gc調(diào)優(yōu)實戰(zhàn)
調(diào)優(yōu)步驟:
打印gc日志
根據(jù)gc日志得到關(guān)鍵性指標(biāo)
分析gc原因,調(diào)優(yōu)jvm參數(shù)
初始化參數(shù):
-XX:+PrintGCDetails -XX:+PrintGCTimeStamps
-XX:+PrintGCDateStamps -XX:+DisableExplicitGC
-Xloggc:$CATALINA_HOME/logs/gc.log :打印日志的位置
-XX:+PrintHeapAtGC
-XX:+PrintTenuringDistribution
關(guān)于DisableExplicitGC這個,有必要了解一下,如果啟動了這個參數(shù),不能顯示調(diào)用gc,System.gc()這個方法就沒用了,那么在某一些使用到堆外內(nèi)存的框架如netty中,就會存在內(nèi)存泄漏的風(fēng)險。
參考:https://blog.csdn.net/aitangyong/article/details/39403031
Parallel collector調(diào)優(yōu)
parallel gc調(diào)優(yōu)指南:
除非確定,否則不要設(shè)置最大堆內(nèi)存
優(yōu)先設(shè)置吞吐量目標(biāo)
如果吞吐量目標(biāo)達(dá)不到,調(diào)大最大內(nèi)存,不能讓os使用swap,如果仍然達(dá)不到,降低目標(biāo)。
吞吐量能達(dá)到,GC時間太長、設(shè)置停頓時間的目標(biāo)。
在官方文檔的這個地方:
https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/ergonomics.html#sthref15
介紹了parallell gc調(diào)優(yōu)的兩種方式:
1、設(shè)置最大停頓時間XX:MaxGCPauseMillis
2、設(shè)置吞吐量XX:GCTimeRatio
這兩個參數(shù)只適用于paraller collector
而在介紹Parallel collector的的文章這里:
https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/parallel.html#CHDCFBIF
說了另外兩種方式:
3、設(shè)置內(nèi)存動態(tài)變化:
XX:YoungGenerationSizeIncrement、XX:TenuredGenerationSizeIncrement、XX:AdaptiveSizeDecrementScaleFactor,每次gc之后,都會看gc前后的內(nèi)存,從而增加或者減少內(nèi)存
4、通過查看gc的情況,設(shè)置內(nèi)存大小,可以設(shè)置Xms(initial heap size) 、Xmx(maximum heap size)和Xmn(新生代的大小)還有MetaspaceSize和MaxMetaspaceSize
CMS GC調(diào)優(yōu)
由于jdk1.8之后更加推薦使用G1,所以cms的調(diào)優(yōu)自己看官網(wǎng):
https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/cms.html#concurrent_mark_sweep_cms_collector
G1 GC調(diào)優(yōu)
g1gc調(diào)優(yōu)指南:
年輕代大小
避免使用-Xmn、-XX:NewRatio等顯示設(shè)置Young區(qū)大小,會覆蓋停頓時間目標(biāo)
暫停時間目標(biāo)
暫停時間不要太苛刻,其吞吐量目標(biāo)是90%的應(yīng)用程序的時間和10%的垃圾回收時間,太苛刻會直接影響到吞吐量
關(guān)于MixedGC調(diào)優(yōu)
-XX:InitiatingHeapOccupancyPercent
-XX:G1MixedGCLiveThresholdPercent、-XX:G1HeapWastePercent
-XX:G1MixedGCCountTarget
-XX:G1OldCSetRegionThresholdPercent
其實這里的介紹就是官網(wǎng)的介紹
官網(wǎng):
https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/g1_gc_tuning.html#recommendations
這里介紹了調(diào)優(yōu)的三種方式:
1、避免設(shè)置固定的內(nèi)存例如Xms(initial heap size) 、Xmx(maximum heap size)和Xmn(新生代的大小)還有MetaspaceSize和MaxMetaspaceSize,但是可以必要條件下可以調(diào)這些參數(shù)
2、設(shè)置最大停頓時間例如;MaxGCPauseMillis=100
3、對于mixed gc參數(shù)的設(shè)置,如:
-XX:InitiatingHeapOccupancyPercent、
-XX:G1MixedGCLiveThresholdPercent、
-XX:G1HeapWastePercent、
-XX:G1MixedGCCountTarget 、
-XX:G1OldCSetRegionThresholdPercent
ps:最后思考一點,fullgc和young gc是相對parallel gc,而mixed是相對g1gc的嗎?
————————————————
版權(quán)聲明:本文為CSDN博主「kynni」的原創(chuàng)文章,遵循CC 4.0 BY-SA版權(quán)協(xié)議,轉(zhuǎn)載請附上原文出處鏈接及本聲明。
原文鏈接:
https://blog.csdn.net/fst438060684/article/details/83514806
鋒哥最新SpringCloud分布式電商秒殺課程發(fā)布
??????
??長按上方微信二維碼 2 秒
感謝點贊支持下哈 