
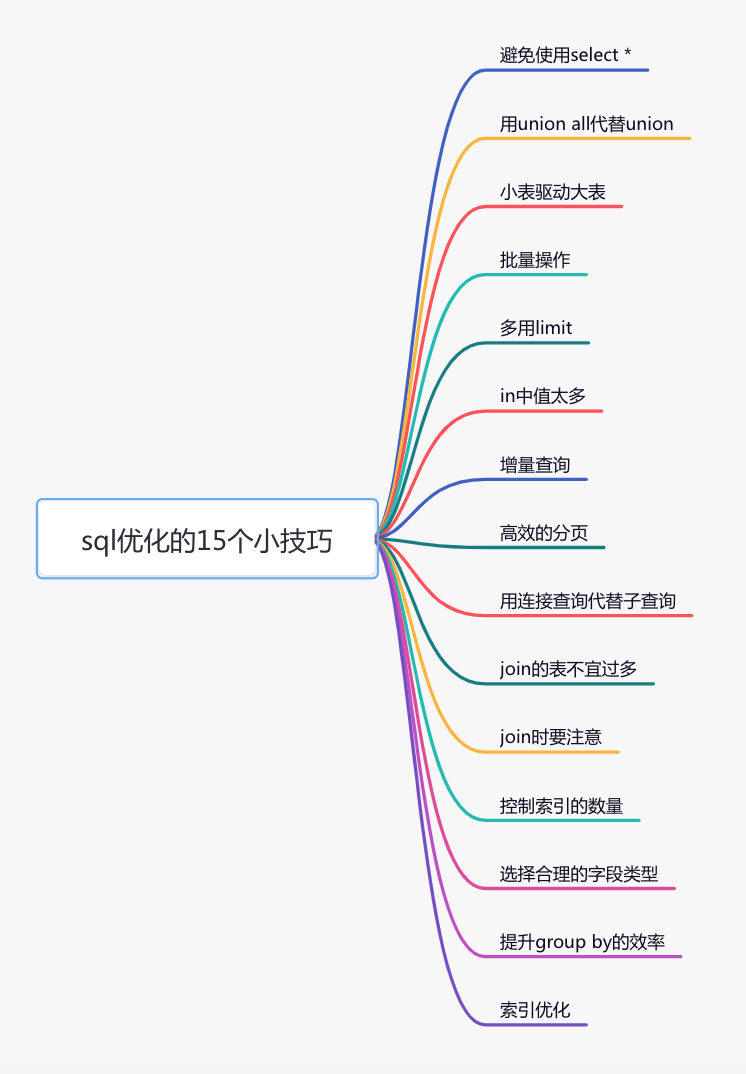
Sql優(yōu)化的15個(gè)小技巧,這也太實(shí)用了叭!
前言
sql優(yōu)化是一個(gè)大家都比較關(guān)注的熱門話題,無(wú)論你在面試,還是工作中,都很有可能會(huì)遇到。
如果某天你負(fù)責(zé)的某個(gè)線上接口,出現(xiàn)了性能問(wèn)題,需要做優(yōu)化。那么你首先想到的很有可能是優(yōu)化sql語(yǔ)句,因?yàn)樗母脑斐杀鞠鄬?duì)于代碼來(lái)說(shuō)也要小得多。
那么,如何優(yōu)化sql語(yǔ)句呢?
這篇文章從15個(gè)方面,分享了sql優(yōu)化的一些小技巧,希望對(duì)你有所幫助。
1 避免使用select *
很多時(shí)候,我們寫(xiě)sql語(yǔ)句時(shí),為了方便,喜歡直接使用select *,一次性查出表中所有列的數(shù)據(jù)。
反例:
select?*?from?user?where?id=1;
在實(shí)際業(yè)務(wù)場(chǎng)景中,可能我們真正需要使用的只有其中一兩列。查了很多數(shù)據(jù),但是不用,白白浪費(fèi)了數(shù)據(jù)庫(kù)資源,比如:內(nèi)存或者cpu。
此外,多查出來(lái)的數(shù)據(jù),通過(guò)網(wǎng)絡(luò)IO傳輸?shù)倪^(guò)程中,也會(huì)增加數(shù)據(jù)傳輸?shù)臅r(shí)間。
還有一個(gè)最重要的問(wèn)題是:select *不會(huì)走覆蓋索引,會(huì)出現(xiàn)大量的回表操作,而從導(dǎo)致查詢sql的性能很低。
那么,如何優(yōu)化呢?
正例:
select?name,age?from?user?where?id=1;
sql語(yǔ)句查詢時(shí),只查需要用到的列,多余的列根本無(wú)需查出來(lái)。
2 用union all代替union
我們都知道sql語(yǔ)句使用union關(guān)鍵字后,可以獲取排重后的數(shù)據(jù)。
而如果使用union all關(guān)鍵字,可以獲取所有數(shù)據(jù),包含重復(fù)的數(shù)據(jù)。
反例:
(select?*?from?user?where?id=1)?
union?
(select?*?from?user?where?id=2);
排重的過(guò)程需要遍歷、排序和比較,它更耗時(shí),更消耗cpu資源。
所以如果能用union all的時(shí)候,盡量不用union。
正例:
(select?*?from?user?where?id=1)?
union?all
(select?*?from?user?where?id=2);
除非是有些特殊的場(chǎng)景,比如union all之后,結(jié)果集中出現(xiàn)了重復(fù)數(shù)據(jù),而業(yè)務(wù)場(chǎng)景中是不允許產(chǎn)生重復(fù)數(shù)據(jù)的,這時(shí)可以使用union。
3 小表驅(qū)動(dòng)大表
小表驅(qū)動(dòng)大表,也就是說(shuō)用小表的數(shù)據(jù)集驅(qū)動(dòng)大表的數(shù)據(jù)集。
假如有order和user兩張表,其中order表有10000條數(shù)據(jù),而user表有100條數(shù)據(jù)。
這時(shí)如果想查一下,所有有效的用戶下過(guò)的訂單列表。
可以使用in關(guān)鍵字實(shí)現(xiàn):
select?*?from?order
where?user_id?in?(select?id?from?user?where?status=1)
也可以使用exists關(guān)鍵字實(shí)現(xiàn):
select?*?from?order
where?exists?(select?1?from?user?where?order.user_id?=?user.id?and?status=1)
前面提到的這種業(yè)務(wù)場(chǎng)景,使用in關(guān)鍵字去實(shí)現(xiàn)業(yè)務(wù)需求,更加合適。
為什么呢?
因?yàn)槿绻鹲ql語(yǔ)句中包含了in關(guān)鍵字,則它會(huì)優(yōu)先執(zhí)行in里面的子查詢語(yǔ)句,然后再執(zhí)行in外面的語(yǔ)句。如果in里面的數(shù)據(jù)量很少,作為條件查詢速度更快。
而如果sql語(yǔ)句中包含了exists關(guān)鍵字,它優(yōu)先執(zhí)行exists左邊的語(yǔ)句(即主查詢語(yǔ)句)。然后把它作為條件,去跟右邊的語(yǔ)句匹配。如果匹配上,則可以查詢出數(shù)據(jù)。如果匹配不上,數(shù)據(jù)就被過(guò)濾掉了。
這個(gè)需求中,order表有10000條數(shù)據(jù),而user表有100條數(shù)據(jù)。order表是大表,user表是小表。如果order表在左邊,則用in關(guān)鍵字性能更好。
總結(jié)一下:
in適用于左邊大表,右邊小表。exists適用于左邊小表,右邊大表。
不管是用in,還是exists關(guān)鍵字,其核心思想都是用小表驅(qū)動(dòng)大表。
4 批量操作
如果你有一批數(shù)據(jù)經(jīng)過(guò)業(yè)務(wù)處理之后,需要插入數(shù)據(jù),該怎么辦?
反例:
for(Order?order:?list){
???orderMapper.insert(order):
}
在循環(huán)中逐條插入數(shù)據(jù)。
insert?into?order(id,code,user_id)?
values(123,'001',100);
該操作需要多次請(qǐng)求數(shù)據(jù)庫(kù),才能完成這批數(shù)據(jù)的插入。
但眾所周知,我們?cè)诖a中,每次遠(yuǎn)程請(qǐng)求數(shù)據(jù)庫(kù),是會(huì)消耗一定性能的。而如果我們的代碼需要請(qǐng)求多次數(shù)據(jù)庫(kù),才能完成本次業(yè)務(wù)功能,勢(shì)必會(huì)消耗更多的性能。
那么如何優(yōu)化呢?
正例:
orderMapper.insertBatch(list):
提供一個(gè)批量插入數(shù)據(jù)的方法。
insert?into?order(id,code,user_id)?
values(123,'001',100),(124,'002',100),(125,'003',101);
這樣只需要遠(yuǎn)程請(qǐng)求一次數(shù)據(jù)庫(kù),sql性能會(huì)得到提升,數(shù)據(jù)量越多,提升越大。
但需要注意的是,不建議一次批量操作太多的數(shù)據(jù),如果數(shù)據(jù)太多數(shù)據(jù)庫(kù)響應(yīng)也會(huì)很慢。批量操作需要把握一個(gè)度,建議每批數(shù)據(jù)盡量控制在500以內(nèi)。如果數(shù)據(jù)多于500,則分多批次處理。
5 多用limit
有時(shí)候,我們需要查詢某些數(shù)據(jù)中的第一條,比如:查詢某個(gè)用戶下的第一個(gè)訂單,想看看他第一次的首單時(shí)間。
反例:
select?id,?create_date?
?from?order?
where?user_id=123?
order?by?create_date?asc;
根據(jù)用戶id查詢訂單,按下單時(shí)間排序,先查出該用戶所有的訂單數(shù)據(jù),得到一個(gè)訂單集合。然后在代碼中,獲取第一個(gè)元素的數(shù)據(jù),即首單的數(shù)據(jù),就能獲取首單時(shí)間。
List?list?=?orderMapper.getOrderList();
Order?order?=?list.get(0);
雖說(shuō)這種做法在功能上沒(méi)有問(wèn)題,但它的效率非常不高,需要先查詢出所有的數(shù)據(jù),有點(diǎn)浪費(fèi)資源。
那么,如何優(yōu)化呢?
正例:
select?id,?create_date?
?from?order?
where?user_id=123?
order?by?create_date?asc?
limit?1;
使用limit 1,只返回該用戶下單時(shí)間最小的那一條數(shù)據(jù)即可。
此外,在刪除或者修改數(shù)據(jù)時(shí),為了防止誤操作,導(dǎo)致刪除或修改了不相干的數(shù)據(jù),也可以在sql語(yǔ)句最后加上limit。
例如:
update?order?set?status=0,edit_time=now(3)?
where?id>=100?and?id<200?limit?100;
這樣即使誤操作,比如把id搞錯(cuò)了,也不會(huì)對(duì)太多的數(shù)據(jù)造成影響。
6 in中值太多
對(duì)于批量查詢接口,我們通常會(huì)使用in關(guān)鍵字過(guò)濾出數(shù)據(jù)。比如:想通過(guò)指定的一些id,批量查詢出用戶信息。
sql語(yǔ)句如下:
select?id,name?from?category
where?id?in?(1,2,3...100000000);
如果我們不做任何限制,該查詢語(yǔ)句一次性可能會(huì)查詢出非常多的數(shù)據(jù),很容易導(dǎo)致接口超時(shí)。
這時(shí)該怎么辦呢?
select?id,name?from?category
where?id?in?(1,2,3...100)
limit?500;
可以在sql中對(duì)數(shù)據(jù)用limit做限制。
不過(guò)我們更多的是要在業(yè)務(wù)代碼中加限制,偽代碼如下:
public?List?getCategory(List?ids) ? {
???if(CollectionUtils.isEmpty(ids))?{
??????return?null;
???}
???if(ids.size()?>?500)?{
??????throw?new?BusinessException("一次最多允許查詢500條記錄")
???}
???return?mapper.getCategoryList(ids);
}
還有一個(gè)方案就是:如果ids超過(guò)500條記錄,可以分批用多線程去查詢數(shù)據(jù)。每批只查500條記錄,最后把查詢到的數(shù)據(jù)匯總到一起返回。
不過(guò)這只是一個(gè)臨時(shí)方案,不適合于ids實(shí)在太多的場(chǎng)景。因?yàn)閕ds太多,即使能快速查出數(shù)據(jù),但如果返回的數(shù)據(jù)量太大了,網(wǎng)絡(luò)傳輸也是非常消耗性能的,接口性能始終好不到哪里去。
7 增量查詢
有時(shí)候,我們需要通過(guò)遠(yuǎn)程接口查詢數(shù)據(jù),然后同步到另外一個(gè)數(shù)據(jù)庫(kù)。
反例:
select?*?from?user;
如果直接獲取所有的數(shù)據(jù),然后同步過(guò)去。這樣雖說(shuō)非常方便,但是帶來(lái)了一個(gè)非常大的問(wèn)題,就是如果數(shù)據(jù)很多的話,查詢性能會(huì)非常差。
這時(shí)該怎么辦呢?
正例:
select?*?from?user?
where?id>#{lastId}?and?create_time?>=?#{lastCreateTime}?
limit?100;
按id和時(shí)間升序,每次只同步一批數(shù)據(jù),這一批數(shù)據(jù)只有100條記錄。每次同步完成之后,保存這100條數(shù)據(jù)中最大的id和時(shí)間,給同步下一批數(shù)據(jù)的時(shí)候用。
通過(guò)這種增量查詢的方式,能夠提升單次查詢的效率。
8 高效的分頁(yè)
有時(shí)候,列表頁(yè)在查詢數(shù)據(jù)時(shí),為了避免一次性返回過(guò)多的數(shù)據(jù)影響接口性能,我們一般會(huì)對(duì)查詢接口做分頁(yè)處理。
在mysql中分頁(yè)一般用的limit關(guān)鍵字:
select?id,name,age?
from?user?limit?10,20;
如果表中數(shù)據(jù)量少,用limit關(guān)鍵字做分頁(yè),沒(méi)啥問(wèn)題。但如果表中數(shù)據(jù)量很多,用它就會(huì)出現(xiàn)性能問(wèn)題。
比如現(xiàn)在分頁(yè)參數(shù)變成了:
select?id,name,age?
from?user?limit?1000000,20;
mysql會(huì)查到1000020條數(shù)據(jù),然后丟棄前面的1000000條,只查后面的20條數(shù)據(jù),這個(gè)是非常浪費(fèi)資源的。
那么,這種海量數(shù)據(jù)該怎么分頁(yè)呢?
優(yōu)化sql:
select?id,name,age?
from?user?where?id?>?1000000?limit?20;
先找到上次分頁(yè)最大的id,然后利用id上的索引查詢。不過(guò)該方案,要求id是連續(xù)的,并且有序的。
還能使用between優(yōu)化分頁(yè)。
select?id,name,age?
from?user?where?id?between?1000000?and?1000020;
需要注意的是between要在唯一索引上分頁(yè),不然會(huì)出現(xiàn)每頁(yè)大小不一致的問(wèn)題。
9 用連接查詢代替子查詢
mysql中如果需要從兩張以上的表中查詢出數(shù)據(jù)的話,一般有兩種實(shí)現(xiàn)方式:子查詢 和 連接查詢。
子查詢的例子如下:
select?*?from?order
where?user_id?in?(select?id?from?user?where?status=1)
子查詢語(yǔ)句可以通過(guò)in關(guān)鍵字實(shí)現(xiàn),一個(gè)查詢語(yǔ)句的條件落在另一個(gè)select語(yǔ)句的查詢結(jié)果中。程序先運(yùn)行在嵌套在最內(nèi)層的語(yǔ)句,再運(yùn)行外層的語(yǔ)句。
子查詢語(yǔ)句的優(yōu)點(diǎn)是簡(jiǎn)單,結(jié)構(gòu)化,如果涉及的表數(shù)量不多的話。
但缺點(diǎn)是mysql執(zhí)行子查詢時(shí),需要?jiǎng)?chuàng)建臨時(shí)表,查詢完畢后,需要再刪除這些臨時(shí)表,有一些額外的性能消耗。
這時(shí)可以改成連接查詢。具體例子如下:
select?o.*?from?order?o
inner?join?user?u?on?o.user_id?=?u.id
where?u.status=1
10 join的表不宜過(guò)多
根據(jù)阿里巴巴開(kāi)發(fā)者手冊(cè)的規(guī)定,join表的數(shù)量不應(yīng)該超過(guò)3個(gè)。
反例:
select?a.name,b.name.c.name,d.name
from?a?
inner?join?b?on?a.id?=?b.a_id
inner?join?c?on?c.b_id?=?b.id
inner?join?d?on?d.c_id?=?c.id
inner?join?e?on?e.d_id?=?d.id
inner?join?f?on?f.e_id?=?e.id
inner?join?g?on?g.f_id?=?f.id
如果join太多,mysql在選擇索引的時(shí)候會(huì)非常復(fù)雜,很容易選錯(cuò)索引。
并且如果沒(méi)有命中中,nested loop join 就是分別從兩個(gè)表讀一行數(shù)據(jù)進(jìn)行兩兩對(duì)比,復(fù)雜度是 n^2。
所以我們應(yīng)該盡量控制join表的數(shù)量。
正例:
select?a.name,b.name.c.name,a.d_name?
from?a?
inner?join?b?on?a.id?=?b.a_id
inner?join?c?on?c.b_id?=?b.id
如果實(shí)現(xiàn)業(yè)務(wù)場(chǎng)景中需要查詢出另外幾張表中的數(shù)據(jù),可以在a、b、c表中冗余專門的字段,比如:在表a中冗余d_name字段,保存需要查詢出的數(shù)據(jù)。
不過(guò)我之前也見(jiàn)過(guò)有些ERP系統(tǒng),并發(fā)量不大,但業(yè)務(wù)比較復(fù)雜,需要join十幾張表才能查詢出數(shù)據(jù)。
所以join表的數(shù)量要根據(jù)系統(tǒng)的實(shí)際情況決定,不能一概而論,盡量越少越好。
11 join時(shí)要注意
我們?cè)谏婕暗蕉鄰埍砺?lián)合查詢的時(shí)候,一般會(huì)使用join關(guān)鍵字。
而join使用最多的是left join和inner join。
left join:求兩個(gè)表的交集外加左表剩下的數(shù)據(jù)。inner join:求兩個(gè)表交集的數(shù)據(jù)。
使用inner join的示例如下:
select?o.id,o.code,u.name?
from?order?o?
inner?join?user?u?on?o.user_id?=?u.id
where?u.status=1;
如果兩張表使用inner join關(guān)聯(lián),mysql會(huì)自動(dòng)選擇兩張表中的小表,去驅(qū)動(dòng)大表,所以性能上不會(huì)有太大的問(wèn)題。
使用left join的示例如下:
select?o.id,o.code,u.name?
from?order?o?
left?join?user?u?on?o.user_id?=?u.id
where?u.status=1;
如果兩張表使用left join關(guān)聯(lián),mysql會(huì)默認(rèn)用left join關(guān)鍵字左邊的表,去驅(qū)動(dòng)它右邊的表。如果左邊的表數(shù)據(jù)很多時(shí),就會(huì)出現(xiàn)性能問(wèn)題。
要特別注意的是在用left join關(guān)聯(lián)查詢時(shí),左邊要用小表,右邊可以用大表。如果能用inner join的地方,盡量少用left join。
12 控制索引的數(shù)量
眾所周知,索引能夠顯著的提升查詢sql的性能,但索引數(shù)量并非越多越好。
因?yàn)楸碇行略鰯?shù)據(jù)時(shí),需要同時(shí)為它創(chuàng)建索引,而索引是需要額外的存儲(chǔ)空間的,而且還會(huì)有一定的性能消耗。
阿里巴巴的開(kāi)發(fā)者手冊(cè)中規(guī)定,單表的索引數(shù)量應(yīng)該盡量控制在5個(gè)以內(nèi),并且單個(gè)索引中的字段數(shù)不超過(guò)5個(gè)。
mysql使用的B+樹(shù)的結(jié)構(gòu)來(lái)保存索引的,在insert、update和delete操作時(shí),需要更新B+樹(shù)索引。如果索引過(guò)多,會(huì)消耗很多額外的性能。
那么,問(wèn)題來(lái)了,如果表中的索引太多,超過(guò)了5個(gè)該怎么辦?
這個(gè)問(wèn)題要辯證的看,如果你的系統(tǒng)并發(fā)量不高,表中的數(shù)據(jù)量也不多,其實(shí)超過(guò)5個(gè)也可以,只要不要超過(guò)太多就行。
但對(duì)于一些高并發(fā)的系統(tǒng),請(qǐng)務(wù)必遵守單表索引數(shù)量不要超過(guò)5的限制。
那么,高并發(fā)系統(tǒng)如何優(yōu)化索引數(shù)量?
能夠建聯(lián)合索引,就別建單個(gè)索引,可以刪除無(wú)用的單個(gè)索引。
將部分查詢功能遷移到其他類型的數(shù)據(jù)庫(kù)中,比如:Elastic Seach、HBase等,在業(yè)務(wù)表中只需要建幾個(gè)關(guān)鍵索引即可。
13 選擇合理的字段類型
char表示固定字符串類型,該類型的字段存儲(chǔ)空間的固定的,會(huì)浪費(fèi)存儲(chǔ)空間。
alter?table?order?
add?column?code?char(20)?NOT?NULL;
varchar表示變長(zhǎng)字符串類型,該類型的字段存儲(chǔ)空間會(huì)根據(jù)實(shí)際數(shù)據(jù)的長(zhǎng)度調(diào)整,不會(huì)浪費(fèi)存儲(chǔ)空間。
alter?table?order?
add?column?code?varchar(20)?NOT?NULL;
如果是長(zhǎng)度固定的字段,比如用戶手機(jī)號(hào),一般都是11位的,可以定義成char類型,長(zhǎng)度是11字節(jié)。
但如果是企業(yè)名稱字段,假如定義成char類型,就有問(wèn)題了。
如果長(zhǎng)度定義得太長(zhǎng),比如定義成了200字節(jié),而實(shí)際企業(yè)長(zhǎng)度只有50字節(jié),則會(huì)浪費(fèi)150字節(jié)的存儲(chǔ)空間。
如果長(zhǎng)度定義得太短,比如定義成了50字節(jié),但實(shí)際企業(yè)名稱有100字節(jié),就會(huì)存儲(chǔ)不下,而拋出異常。
所以建議將企業(yè)名稱改成varchar類型,變長(zhǎng)字段存儲(chǔ)空間小,可以節(jié)省存儲(chǔ)空間,而且對(duì)于查詢來(lái)說(shuō),在一個(gè)相對(duì)較小的字段內(nèi)搜索效率顯然要高些。
我們?cè)谶x擇字段類型時(shí),應(yīng)該遵循這樣的原則:
能用數(shù)字類型,就不用字符串,因?yàn)樽址奶幚硗葦?shù)字要慢。 盡可能使用小的類型,比如:用bit存布爾值,用tinyint存枚舉值等。 長(zhǎng)度固定的字符串字段,用char類型。 長(zhǎng)度可變的字符串字段,用varchar類型。 金額字段用decimal,避免精度丟失問(wèn)題。
還有很多原則,這里就不一一列舉了。
14 提升group by的效率
我們有很多業(yè)務(wù)場(chǎng)景需要使用group by關(guān)鍵字,它主要的功能是去重和分組。
通常它會(huì)跟having一起配合使用,表示分組后再根據(jù)一定的條件過(guò)濾數(shù)據(jù)。
反例:
select?user_id,user_name?from?order
group?by?user_id
having?user_id?<=?200;
這種寫(xiě)法性能不好,它先把所有的訂單根據(jù)用戶id分組之后,再去過(guò)濾用戶id大于等于200的用戶。
分組是一個(gè)相對(duì)耗時(shí)的操作,為什么我們不先縮小數(shù)據(jù)的范圍之后,再分組呢?
正例:
select?user_id,user_name?from?order
where?user_id?<=?200
group?by?user_id
使用where條件在分組前,就把多余的數(shù)據(jù)過(guò)濾掉了,這樣分組時(shí)效率就會(huì)更高一些。
其實(shí)這是一種思路,不僅限于group by的優(yōu)化。我們的sql語(yǔ)句在做一些耗時(shí)的操作之前,應(yīng)盡可能縮小數(shù)據(jù)范圍,這樣能提升sql整體的性能。
15 索引優(yōu)化
sql優(yōu)化當(dāng)中,有一個(gè)非常重要的內(nèi)容就是:索引優(yōu)化。
很多時(shí)候sql語(yǔ)句,走了索引,和沒(méi)有走索引,執(zhí)行效率差別很大。所以索引優(yōu)化被作為sql優(yōu)化的首選。
索引優(yōu)化的第一步是:檢查sql語(yǔ)句有沒(méi)有走索引。
那么,如何查看sql走了索引沒(méi)?
可以使用explain命令,查看mysql的執(zhí)行計(jì)劃。
例如:
explain?select?*?from?`order`?where?code='002';
結(jié)果: 通過(guò)這幾列可以判斷索引使用情況,執(zhí)行計(jì)劃包含列的含義如下圖所示:
通過(guò)這幾列可以判斷索引使用情況,執(zhí)行計(jì)劃包含列的含義如下圖所示: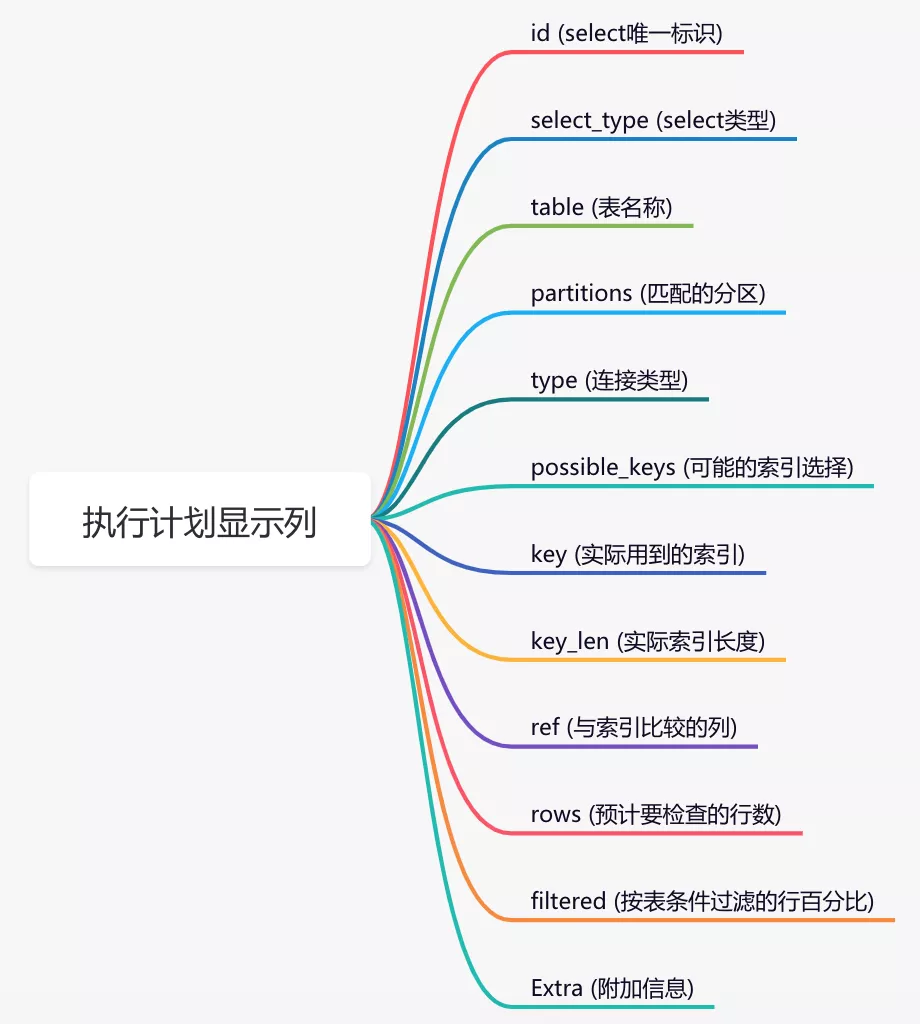
說(shuō)實(shí)話,sql語(yǔ)句沒(méi)有走索引,排除沒(méi)有建索引之外,最大的可能性是索引失效了。
下面說(shuō)說(shuō)索引失效的常見(jiàn)原因: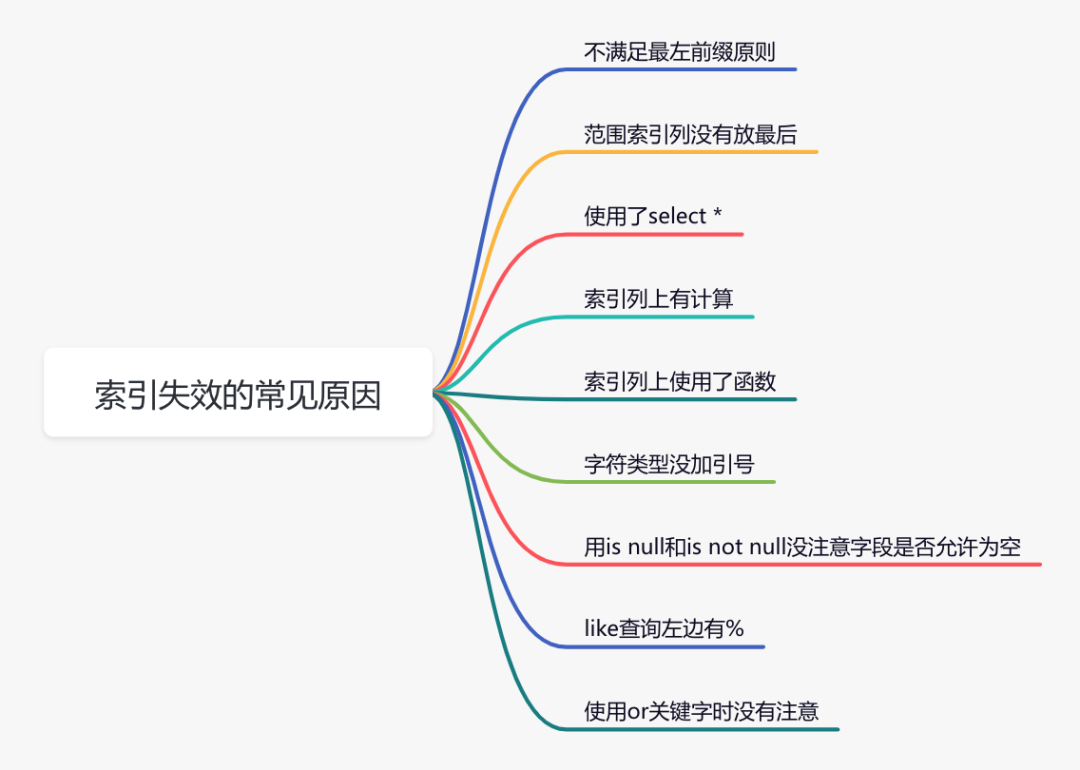 如果不是上面的這些原因,則需要再進(jìn)一步排查一下其他原因。
如果不是上面的這些原因,則需要再進(jìn)一步排查一下其他原因。
此外,你有沒(méi)有遇到過(guò)這樣一種情況:明明是同一條sql,只有入?yún)⒉煌选S械臅r(shí)候走的索引a,有的時(shí)候卻走的索引b?
沒(méi)錯(cuò),有時(shí)候mysql會(huì)選錯(cuò)索引。
必要時(shí)可以使用force index來(lái)強(qiáng)制查詢sql走某個(gè)索引。
至于為什么mysql會(huì)選錯(cuò)索引,后面有專門的文章介紹的,這里先留點(diǎn)懸念。
程序汪資料鏈接
程序汪接的7個(gè)私活都在這里,經(jīng)驗(yàn)整理
Java項(xiàng)目分享 最新整理全集,找項(xiàng)目不累啦 06版
堪稱神級(jí)的Spring Boot手冊(cè),從基礎(chǔ)入門到實(shí)戰(zhàn)進(jìn)階
臥槽!字節(jié)跳動(dòng)《算法中文手冊(cè)》火了,完整版 PDF 開(kāi)放下載!
臥槽!阿里大佬總結(jié)的《圖解Java》火了,完整版PDF開(kāi)放下載!
字節(jié)跳動(dòng)總結(jié)的設(shè)計(jì)模式 PDF 火了,完整版開(kāi)放下載!
歡迎添加程序汪個(gè)人微信 itwang009? 進(jìn)粉絲群或圍觀朋友