
聊聊sql優(yōu)化的幾個真實場景
大家好,我是蘇三,最近給新人code review,差點吐血,也有一些調(diào)優(yōu)方面的知識,所以順便記錄了下來分享給大家。
這里的主要是分享索引方面的調(diào)優(yōu),在工作中,很多同學(xué)都有建立索引的一些經(jīng)驗,但是是否有自己深入的思考過,怎么樣建立索引才最合適。
字符串怎么建立索引、怎么優(yōu)化聯(lián)合索引、怎么避免回表等一些問題,是否有結(jié)合自己的實際項目進行深入的思考呢?
這里,我就將自己實際中遇到的一些問題分享給大家,下面開始我們的正題,首先開始之前,先來回顧一些基礎(chǔ)的知識。
什么是Mysql的索引,聯(lián)合索引是什么?回表是什么?回表怎么解決?
Mysql索引
Mysql的索引是一種加快查詢速度的數(shù)據(jù)結(jié)構(gòu),索引就好比書的目錄一樣能夠快速的定位你要查找的位置。
Mysql的索引底層是使用B+樹的數(shù)據(jù)結(jié)構(gòu)進行實現(xiàn),結(jié)構(gòu)如下圖所示:
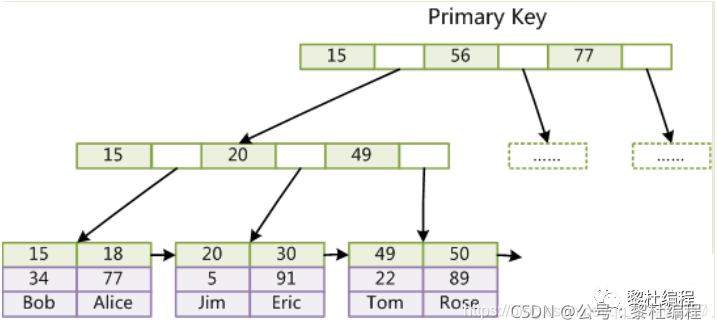 索引的一個數(shù)據(jù)頁的大小是16kb,從磁盤加載到內(nèi)存中是以數(shù)據(jù)頁的大小為單位進行加載,然后供查詢操作進行查詢,若是查詢的數(shù)據(jù)不在內(nèi)存中,才會從磁盤中再次加載到內(nèi)存中。
索引的一個數(shù)據(jù)頁的大小是16kb,從磁盤加載到內(nèi)存中是以數(shù)據(jù)頁的大小為單位進行加載,然后供查詢操作進行查詢,若是查詢的數(shù)據(jù)不在內(nèi)存中,才會從磁盤中再次加載到內(nèi)存中。
索引的實現(xiàn)有很多,比如hash。hash是以key-value的形式進行存儲,適合于等值查詢的場景,查詢的時間復(fù)雜度為O(1),因為hash儲存并不是有序的。
所以,對于范圍查詢就可能要遍歷所有數(shù)據(jù)進行查詢,而且不同值的計算還會出現(xiàn)hash沖突,所以hash并不適合于做Mysql的索引。
有序數(shù)組在等值查詢和范圍查詢性能都是非常好的,那為什么又不用有序數(shù)組作為索引呢?因為對于數(shù)組而言作為索引更新的成本太高,新增數(shù)據(jù)要把后面的數(shù)據(jù)都往后移一位,所以也不采用有序數(shù)組作為索引的底層實現(xiàn)。
最后二叉樹,主要是因為二叉樹只有二叉,一個節(jié)點存儲的數(shù)據(jù)量非常有限,需要頻繁的隨機IO讀寫磁盤,若是數(shù)據(jù)量大的情況下二叉的樹高太高,嚴重影響性能,所以也不采用二叉樹進行實現(xiàn)。
而B+樹是多叉樹,一個數(shù)據(jù)頁的大小是16kb,在1-3的樹高就能存儲10億級以上的數(shù)據(jù),也就是只要訪問磁盤1-3次就足夠了,并且B+樹的葉子結(jié)點上一個葉子結(jié)點有指針指向下一個葉子結(jié)點,便于范圍查詢:

種類的索引
索引從數(shù)據(jù)結(jié)構(gòu)進行劃分的分為:B+樹索引、hash索引、R-Tree索引、FULLTEXT索引。
索引從物理存儲的角度劃分為:聚族索引和非聚族索引。
從邏輯的角度分為:主鍵索引、普通索引、唯一索引、聯(lián)合索引以及空間索引。
什么是回表
再詳細了解什么事回表之前,我們先來詳細的深入了解一下什么是InnoDB的索引存儲形式,InnoDB的主鍵索引存儲形式是聚族索引,索引與數(shù)據(jù)都在一起:
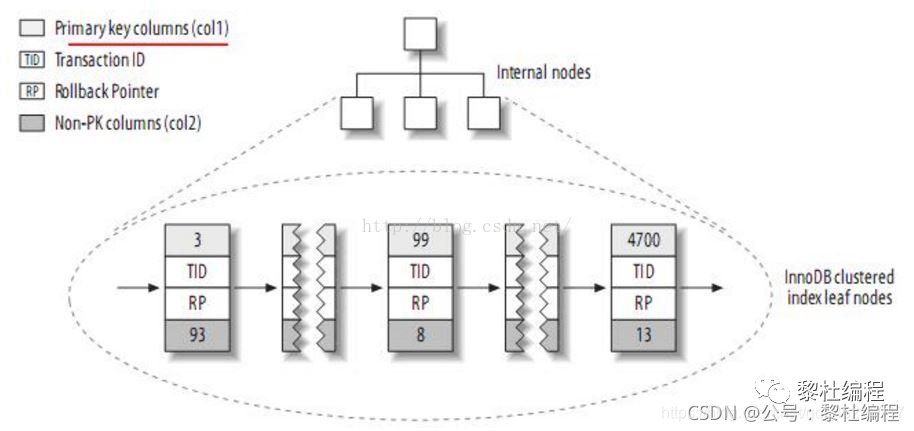 InnoDB的主鍵索引中葉子結(jié)點并不是存儲行指針,而是存儲行數(shù)據(jù),二級索引中MyISAM也是一樣的存儲方式,InnoDB的二級索引的葉子結(jié)點則是存儲當(dāng)前索引值以及對應(yīng)的主鍵索引值。
InnoDB的主鍵索引中葉子結(jié)點并不是存儲行指針,而是存儲行數(shù)據(jù),二級索引中MyISAM也是一樣的存儲方式,InnoDB的二級索引的葉子結(jié)點則是存儲當(dāng)前索引值以及對應(yīng)的主鍵索引值。
InnoDB的二級索引帶來的好處就是減少了由于數(shù)據(jù)移動或者數(shù)據(jù)頁分列導(dǎo)致行數(shù)據(jù)的地址變了而帶來的維護二級索引的性能開銷,因為InnoDB的二級索引不需要更新行指針:
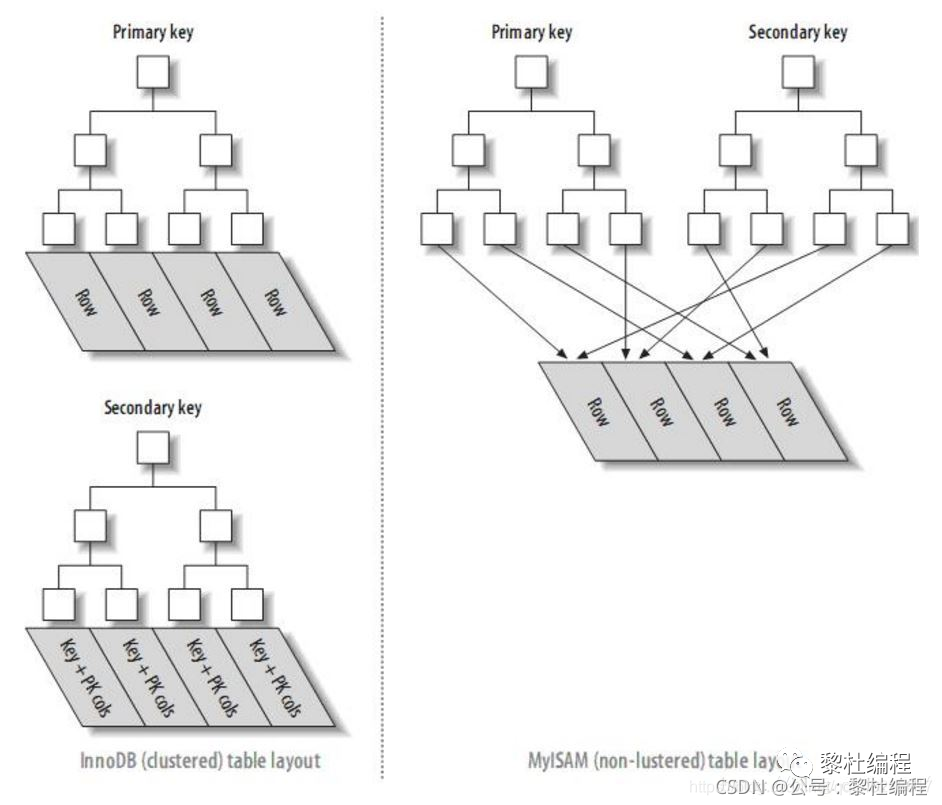
上面說到InnoDB引擎的主鍵索引存儲的是行數(shù)據(jù),二級索引的葉子結(jié)點存儲的是索引數(shù)據(jù)以及對應(yīng)的主鍵,所以回表就是根據(jù)索引進行條件查詢,回到主鍵索引樹進行搜索的過程:
因為查詢還要回表一次,再次查詢主鍵索引樹,所以實際中應(yīng)該盡量避免回表的產(chǎn)生。
解決回表
解決回表問題可以建立聯(lián)合索引進行索引覆蓋,如圖所示根據(jù)name字段查詢用戶的name和sex屬性出現(xiàn)了回表問題:
那么我們可以建立下面這個聯(lián)合索引來解決:
create?table?user?(
?id?int?primary?key,
?name?varchar(20),
?sex?varchar(5),
?index(name,?sex)
)?engine?=?innodb;
建立了如上所示的index(name,sex)聯(lián)合索引,在二級索引的葉子結(jié)點的位置就會同時也出現(xiàn)sex字段的值,因為能夠獲取到要查詢的所有字段,因為就不用再回表查詢一次。
最左前綴原則
最左前綴原則可以是聯(lián)合索引的的最左N個字段,也可以是字符串索引的最左的M個字符。舉個例子,假如現(xiàn)在有一個表的原始數(shù)據(jù)如下所示:
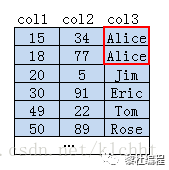
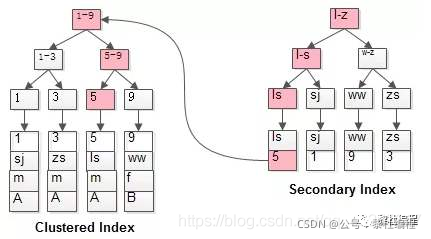
并根據(jù)col3 ,col2的順序建立聯(lián)合索引,此時聯(lián)合索引樹結(jié)構(gòu)如圖下所示:

葉子結(jié)點中首先會根據(jù)col3的字符進行排序,若是col3相等,在col3相等的值里面再對col2進行排序,假如我們要查詢where col3 like 'Eri%',就可以快速的定位查詢到Eric。
若是查詢條件為where col3 like '%se',前面的字符不確定,表示任意字符都可以,這樣就可以導(dǎo)致全表掃描進行字符的比較,就會使索引失效。
調(diào)優(yōu)案例一
其中第一個案例新人寫了一個這樣的sql,由于業(yè)務(wù)的原因就不粘貼全部sql,其中sql的條件如下所示WHERE ( STATUS = '1' AND shop_code = 'XXX' ) ?GROUP BY act_id。
并且他在表中建立的這樣的一個索引idx_status_shop_code,當(dāng)時看到就吐血一地。
我給新人提出建議是把shop_code為''空字符串的(數(shù)據(jù)庫默認值)是設(shè)為一個特殊的00000這樣的類型,不要把商店的shop_code默認值設(shè)置為空字符串。
并且,索引中shop_code字段放在前面,建idx_shop_code_status_act_id索引。
因為一般狀態(tài)值status只有0和1,區(qū)分度不大,而shop_code的區(qū)分度大,在執(zhí)行where條件篩選的時候,區(qū)分度大的放在前面,第一層過濾的時候就能過濾掉大部分行數(shù),減少掃描的行數(shù),提高效率。
并且將act_id,和store_code也加入其中,sql中涉及分組(group by)操作,這樣就能避免filesort排序,因為索引本來就是有序的:

并且從他的sql中可以看到他只要返回act_id,而實際中只用到了act_id,所以將act_id也加入索引中就可以避免回表的操作,所以再索引中最后加入act_id有兩大好處:避免回表以及避免filesort排序。
因為寫sql的不良習(xí)慣造成回表操作,平時也沒有注意建立索引的一些原則,以及理解索引的一些原理,所以新人對于一些優(yōu)化的理解還有要一步一步的指導(dǎo),畢竟自己也是從新人過來的。
對于索引的順序的建立,以及出現(xiàn)filesort的解決方案在阿里的開發(fā)手冊中也有提到:

order by和group by都可以利用索引的有序性。

說真的這本開發(fā)手冊還是非常好用的,里面很多經(jīng)驗總結(jié),慢慢的遇到場景就能夠瞬間頓悟,畢竟是眾多阿里人的開發(fā)經(jīng)驗的結(jié)晶。
調(diào)優(yōu)案例二
第二個案例是關(guān)于字符串的,新人接到一個需求需要比較電話,但是一般電話在數(shù)據(jù)庫中都會加密md5。
所以,新人為了提高查詢的效率新建KEY idx_mobile_md5_type (mobile_md5,type)使用md5全字段建立索引。
我是建議他使用select count(distinct left(mobile_md5, 5))/count(*) from XXX.users查找最大的區(qū)分度:

在實際中當(dāng)md5值長度為5以及大于5的長度都不變了:

實際情況只要前五個字符就能達到80%的區(qū)分度,并且再加字段長度區(qū)分度也不變,所以個人提出只要建立前五個字符的索引即可,可以大大節(jié)約空間。
這個在阿里的開發(fā)手冊也有提到,其實一般來說達到90%的區(qū)分度是比較好的,區(qū)分度越大,就類似于越趨向于唯一索引,過濾的行數(shù)就越多:

調(diào)優(yōu)案例三
最后一個字符串的案例就是userId,這個userId使用有20位的長度的字符串左右,有點類似于身份證號碼,大家都知道身份證號碼的前多少位是基本一樣的,區(qū)別大的在后面的幾位(具體幾位沒去了解過)。
我們這邊的場景也是一樣,userId前10位左右基本都是一樣,反而只有后面的幾位區(qū)別度高達90%以上。
所以,建議新人建立userId的反轉(zhuǎn)之后的前幾位索引即可,區(qū)別度可以通過:select count(distinct left(REVERSE(userId), 7))/count(*) as '區(qū)分度' from XXX.users;
具體sql如下的sql:select u.city_code from XXX.city_role_user u where ?role_key = 'XXX' and uc_id = 'XXX' and status = 1;
這個sql有兩個問題,一個是把區(qū)分度不大的role_key放在前面,因為一般角色key在PC端只有幾種,區(qū)別度很小;另一個就是前面說的uc_id字符串問題。
我是建議把where條件的條件uc_id放在前面,建立索引也是如此,并且uc_id是由20位的數(shù)字組成,前面的10位左右都是一樣的,只有后面的幾位區(qū)分度才大。
所以個人也建議通過查詢區(qū)分度,并且建立翻轉(zhuǎn)字符串后的索引來達到節(jié)省空間,并且還可以提升查詢效率,最后就是city_code也加入索引中建立聯(lián)合索引就可以避免回表操作。
所以,這就要sql優(yōu)化的關(guān)鍵點有三個:區(qū)分度大的放在前面、字符串減少長度、避免回表。
其它的code review
通過code review新人的代碼,還發(fā)現(xiàn)一些問題,就是不遵循接口的單一原則,比較喜歡寫通用的接口,一個接口多個場景使用,通常使用select * 返回數(shù)據(jù),對于一些where條件的查詢需要大量的回表操作,但是一些接口中只需要用到其中select 回來的一個字段,所以導(dǎo)致慢sql,慢接口的產(chǎn)生。
并且,在實際的編碼中主要是面向于實現(xiàn),對于一些整體的模塊沒有把控,類似于一些可以使用到策略模式、建造者模式等設(shè)計模式的,都沒有使用,代碼的擴展性比較差。
還要在代碼中大量的使用Java 8的stream流操作,代碼的可讀性差,對于stream流其實可以用來并行流處理還是挺高效的,因為stream流的底層使用到了Fork/Join。
在服務(wù)器配置允許的條件下,使用如下代碼,數(shù)據(jù)量大的時候是可以有效率提升的,下面引用redspider的一個案例:
public?class?StreamParallelDemo?{
????public?static?void?main(String[]?args)?{
????????System.out.println(String.format("本計算機的核數(shù):%d",?Runtime.getRuntime().availableProcessors()));
????????//?產(chǎn)生100w個隨機數(shù)(1?~?100),組成列表
????????Random?random?=?new?Random();
????????List?list?=?new?ArrayList<>(1000_0000);
????????for?(int?i?=?0;?i?????????????list.add(random.nextInt(100));
????????}
????????long?prevTime?=?getCurrentTime();
????????list.stream().reduce((a,?b)?->?a?+?b).ifPresent(System.out::println);
????????System.out.println(String.format("單線程計算耗時:%d",?getCurrentTime()?-?prevTime));
????????prevTime?=?getCurrentTime();
????????list.stream().parallel().reduce((a,?b)?->?a?+?b).ifPresent(System.out::println);
????????System.out.println(String.format("多線程計算耗時:%d",?getCurrentTime()?-?prevTime));
????}
????private?static?long?getCurrentTime()?{
????????return?System.currentTimeMillis();
????}
}
一路code review,發(fā)現(xiàn)還是挺多問題,也是非常基礎(chǔ)的東西,這里就順手做了個記錄,不過也情有可原,畢竟是新人,只能慢慢的指導(dǎo),一行代碼一行代碼的手把手教。
1.Mysql完結(jié)匯總篇(18W字送給大家),完結(jié)撒花
2.如何啃下JVM這座大山,完結(jié)撒花(完結(jié)篇)
5.【面經(jīng)】深入Spring Cloud架構(gòu)組成
7.SQL優(yōu)化最干貨總結(jié)-MySQL(2020最新版)
