
詳解MySQL MVCC多版本并發(fā)控制
目? 錄
一、事務(wù)是什么
二、隔離性與隔離級(jí)別
三、事務(wù)隔離的實(shí)現(xiàn)
四、事務(wù)的啟動(dòng)方式
五、一致性讀
六、當(dāng)前讀
一、事務(wù)是什么
事務(wù)保證一組數(shù)據(jù)庫(kù)操作,要么全部成功,要么全部失敗。在Mysql中,事務(wù)支持是在引擎層實(shí)現(xiàn)的。MySQL 是一個(gè)支持多引擎的系統(tǒng),但并不是所有的引擎都支持事務(wù)。比如 MySQL 原生的 MyISAM 引擎就不支持事務(wù),這也是 MyISAM 被 InnoDB 取代的重要原因之一。
事務(wù)具備ACID四個(gè)特性:
原子性(Atomicity):事務(wù)是一個(gè)不可分割的工作單位,事務(wù)中的操作要么全部成功,要么全部失敗;
一致性(Consistency):事務(wù)執(zhí)行前后,數(shù)據(jù)庫(kù)都必須處于一致性狀態(tài);
隔離性(Isolation):在并發(fā)環(huán)境中,并發(fā)的事務(wù)是相互隔離的,一個(gè)事務(wù)的執(zhí)行不能被其他事務(wù)干擾
持久性(Durability):一旦事務(wù)提交,那么它對(duì)數(shù)據(jù)庫(kù)中的對(duì)應(yīng)數(shù)據(jù)的狀態(tài)的變更就會(huì)永久保存到數(shù)據(jù)庫(kù)中。即使發(fā)生系統(tǒng)崩潰或機(jī)器宕機(jī)等故障,只要數(shù)據(jù)庫(kù)能夠重新啟動(dòng),那么一定能夠?qū)⑵浠謴?fù)到事務(wù)成功結(jié)束的狀態(tài)
下邊重點(diǎn)介紹隔離性:
二、隔離性與隔離級(jí)別
當(dāng)數(shù)據(jù)庫(kù)上有多個(gè)事務(wù)同時(shí)執(zhí)行的時(shí)候,就可能出現(xiàn)臟讀(dirty read)、不可重復(fù)讀(non-repeatable read)、幻讀(phantom read)的問題,為了解決這些問題,就有了“隔離級(jí)別”的概念。
在談隔離級(jí)別之前,你首先要知道,你隔離得越嚴(yán)實(shí),效率就會(huì)越低。因此很多時(shí)候,我們都要在二者之間尋找一個(gè)平衡點(diǎn)。SQL 標(biāo)準(zhǔn)的事務(wù)隔離級(jí)別包括:讀未提交(read uncommitted)、讀提交(read committed)、可重復(fù)讀(repeatable read)和串行化(serializable ):
讀未提交是指,一個(gè)事務(wù)還沒提交時(shí),它做的變更就能被別的事務(wù)看到。
讀提交是指,一個(gè)事務(wù)提交之后,它做的變更才會(huì)被其他事務(wù)看到。
可重復(fù)讀是指,一個(gè)事務(wù)執(zhí)行過程中看到的數(shù)據(jù),總是跟這個(gè)事務(wù)在啟動(dòng)時(shí)看到的數(shù)據(jù)是一致的。當(dāng)然在可重復(fù)讀隔離級(jí)別下,未提交變更對(duì)其他事務(wù)也是不可見的。
串行化,顧名思義是對(duì)于同一行記錄,“寫”會(huì)加“寫鎖”,“讀”會(huì)加“讀鎖”。當(dāng)出現(xiàn)讀寫鎖沖突的時(shí)候,后訪問的事務(wù)必須等前一個(gè)事務(wù)執(zhí)行完成,才能繼續(xù)執(zhí)行。
事務(wù)A | 事務(wù)B |
|---|---|
我們來看看在不同的隔離級(jí)別下,事務(wù) A 會(huì)有哪些不同的返回結(jié)果,也就是圖里面 V1、V2、V3 的返回值分別是什么:
若隔離級(jí)別是“讀未提交”, 則 V1=2。這時(shí)候事務(wù) B 雖然還沒有提交,但是結(jié)果已經(jīng)被 A 看到了。V2=2,V3=2。
若隔離級(jí)別是“讀提交”,則 V1=1,V2=2。事務(wù) B 的更新在提交后才能被 A 看到。V3=2。
若隔離級(jí)別是“可重復(fù)讀”,則 V1=1,V2=1,V3=2。之所以 V2 還是 1,遵循的就是這個(gè)要求:事務(wù)在執(zhí)行期間看到的數(shù)據(jù)前后必須是一致的。
若隔離級(jí)別是“串行化”,則在事務(wù) B 執(zhí)行“將 1 改成 2”的時(shí)候,會(huì)被鎖住。直到事務(wù) A 提交后,事務(wù) B 才可以繼續(xù)執(zhí)行。所以從 A 的角度看, V1=1,V2=1,V3=2。
在實(shí)現(xiàn)上,數(shù)據(jù)庫(kù)里面會(huì)創(chuàng)建一個(gè)視圖,訪問的時(shí)候以視圖的邏輯結(jié)果為準(zhǔn)。
在“可重復(fù)讀”隔離級(jí)別下,這個(gè)視圖是在事務(wù)第一個(gè)select語句時(shí)創(chuàng)建的(整個(gè)庫(kù)的視圖,而不僅僅selec語句用到的表),整個(gè)事務(wù)存在期間都用這個(gè)視圖。
在“讀提交”隔離級(jí)別下,這個(gè)視圖是在每個(gè) select語句開始執(zhí)行的時(shí)候創(chuàng)建的。
“讀未提交”隔離級(jí)別下直接返回記錄上的最新值,沒有視圖概念;
而“串行化”隔離級(jí)別下直接用加鎖的方式來避免并行訪問。
三、事務(wù)隔離的實(shí)現(xiàn)
理解了事務(wù)的隔離級(jí)別,我們?cè)賮砜纯词聞?wù)隔離具體是怎么實(shí)現(xiàn)的。這里我們展開說明“可重復(fù)讀”。
在 MySQL 中,實(shí)際上每條記錄在更新的時(shí)候都會(huì)同時(shí)記錄一條回滾操作。記錄上的最新值,通過回滾操作,都可以得到前一個(gè)狀態(tài)的值。
假設(shè)一個(gè)值從 1 被按順序改成了 2、3、4,在回滾日志里面就會(huì)有類似下面的記錄。
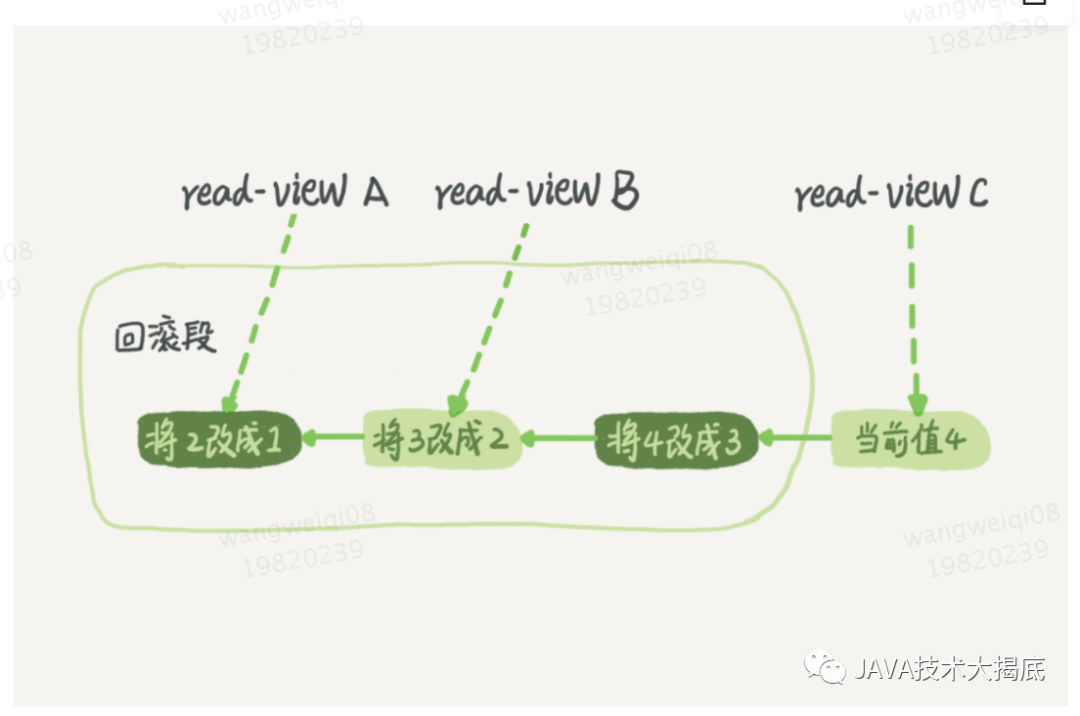
圖1
當(dāng)前值是 4,但是在查詢這條記錄的時(shí)候,不同時(shí)刻啟動(dòng)的事務(wù)會(huì)有不同的 read-view。如圖中看到的,在視圖 A、B、C 里面,這一個(gè)記錄的值分別是 1、2、4,同一條記錄在系統(tǒng)中可以存在多個(gè)版本,就是數(shù)據(jù)庫(kù)的多版本并發(fā)控制(MVCC)。對(duì)于 read-view A,要得到 1,就必須將當(dāng)前值依次執(zhí)行圖中所有的回滾操作得到。
同時(shí)你會(huì)發(fā)現(xiàn),即使現(xiàn)在有另外一個(gè)事務(wù)正在將 4 改成 5,這個(gè)事務(wù)跟 read-view A、B、C 對(duì)應(yīng)的事務(wù)是不會(huì)沖突的。
那么回滾日志什么時(shí)候刪除呢?就是當(dāng)系統(tǒng)里沒有比這個(gè)回滾日志更早的 read-view 的時(shí)候。
因此,建議你盡量不要使用長(zhǎng)事務(wù)。長(zhǎng)事務(wù)意味著系統(tǒng)里面會(huì)存在很老的事務(wù)視圖。由于這些事務(wù)隨時(shí)可能訪問數(shù)據(jù)庫(kù)里面的任何數(shù)據(jù),所以這個(gè)事務(wù)提交之前,數(shù)據(jù)庫(kù)里面它可能用到的回滾記錄都必須保留,這就會(huì)導(dǎo)致大量占用存儲(chǔ)空間。
四、事務(wù)的啟動(dòng)方式
MySQL 的事務(wù)啟動(dòng)方式有以下幾種:
顯式啟動(dòng)事務(wù)語句, begin 或 start transaction。配套的提交語句是 commit,回滾語句是 rollback。
set autocommit=0,這個(gè)命令會(huì)將這個(gè)線程的自動(dòng)提交關(guān)掉。意味著如果你只執(zhí)行一個(gè) select 語句,這個(gè)事務(wù)就啟動(dòng)了,而且并不會(huì)自動(dòng)提交。這個(gè)事務(wù)持續(xù)存在直到你主動(dòng)執(zhí)行 commit 或 rollback 語句,或者斷開連接。
如果用set autocommit=0,接下來的查詢都在事務(wù)中,如果是長(zhǎng)連接,就導(dǎo)致了意外的長(zhǎng)事務(wù)。
因此,建議總是使用 set autocommit=1, 通過顯式語句的方式來啟動(dòng)事務(wù)。但這樣就“多一次間交互”,對(duì)于一個(gè)需要頻繁使用事務(wù)的業(yè)務(wù),建議在提交時(shí),使用 commit work and chain 語法(提交事務(wù)并自動(dòng)啟動(dòng)下一個(gè)事務(wù))
可以在 information_schema 庫(kù)的 innodb_trx 這個(gè)表中查詢長(zhǎng)事務(wù),比如下面這個(gè)語句,用于查找持續(xù)時(shí)間超過 60s 的事務(wù)。
代碼塊
SQL
select?*?from?information_schema.innodb_trx?where?TIME_TO_SEC(timediff(now(),trx_started))>60五、一致性讀
讀取快照中的數(shù)據(jù),多次讀取的數(shù)據(jù)完全一致,包括select語句
一致性視圖:?jiǎn)?dòng)時(shí)刻的活躍事務(wù)ID數(shù)組 + 高水位
高水位:當(dāng)前系統(tǒng)里面已經(jīng)創(chuàng)建過的事務(wù) ID 的最大值加 1
低水位:獲取事務(wù)ID數(shù)組中的最小值
在可重復(fù)讀隔離級(jí)別下,事務(wù)在執(zhí)行第一個(gè)select語句的時(shí)候就“拍了個(gè)快照”。注意,這個(gè)快照是基于整庫(kù)的。
但我們并不需要將整個(gè)庫(kù)拷貝一遍,我們先來看看這個(gè)快照是怎么實(shí)現(xiàn)的。
InnoDB 里面每個(gè)事務(wù)有一個(gè)唯一的事務(wù) ID,叫作 transaction id。它是在事務(wù)開始的時(shí)候向 InnoDB 的事務(wù)系統(tǒng)申請(qǐng)的,是按申請(qǐng)順序嚴(yán)格遞增的。
而每行數(shù)據(jù)也都是有多個(gè)版本的。每次事務(wù)更新數(shù)據(jù)的時(shí)候,都會(huì)生成一個(gè)新的數(shù)據(jù)版本,并且把 transaction id 賦值給這個(gè)數(shù)據(jù)版本的事務(wù) ID,記為 row trx_id。同時(shí),舊的數(shù)據(jù)版本要保留,并且在新的數(shù)據(jù)版本中,能夠有信息可以直接拿到它。
也就是說,數(shù)據(jù)表中的一行記錄,其實(shí)可能有多個(gè)版本 (row),每個(gè)版本有自己的 row trx_id。
如圖所示,就是一個(gè)記錄被多個(gè)事務(wù)連續(xù)更新后的狀態(tài)。
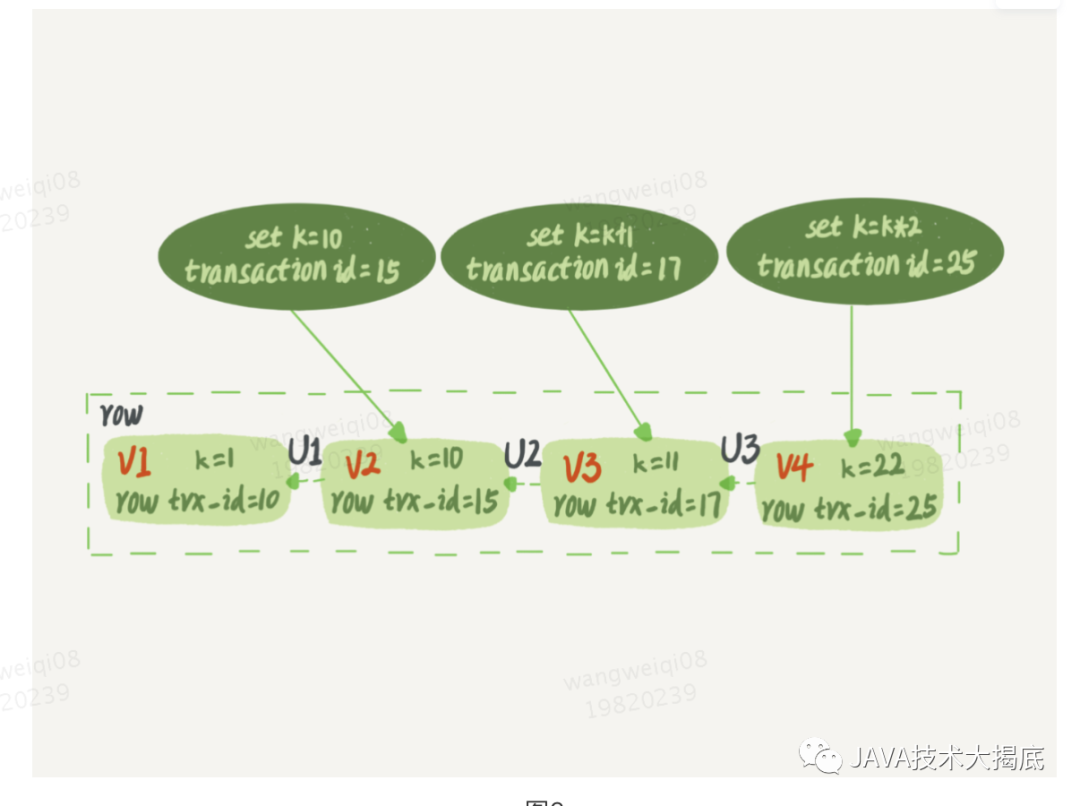
圖2
中虛線框里是同一行數(shù)據(jù)的 4 個(gè)版本,當(dāng)前最新版本是 V4,k 的值是 22,它是被 transaction id 為 25 的事務(wù)更新的,因此它的 row trx_id 也是 25。
圖中的三個(gè)虛線箭頭(U1、U2、U3),就是 回滾日志(undo log);V1、V2、V3 并不是物理上真實(shí)存在的,而是每次需要的時(shí)候根據(jù)當(dāng)前版本和 undo log 計(jì)算出來的。比如,需要 V2 的時(shí)候,就是通過 V4 依次執(zhí)行 U3、U2 算出來。
明白了快照怎么實(shí)現(xiàn)后,我們?cè)賮砜纯慈绾味x一個(gè)快照的?
按照可重復(fù)讀的定義,一個(gè)事務(wù)啟動(dòng)的時(shí)候,能夠看到所有已經(jīng)提交的事務(wù)結(jié)果。但是之后,這個(gè)事務(wù)執(zhí)行期間,其他事務(wù)的更新對(duì)它不可見。
因此,一個(gè)事務(wù)只需要在啟動(dòng)的時(shí)候聲明說,“以我啟動(dòng)的時(shí)刻為準(zhǔn),如果一個(gè)數(shù)據(jù)版本是在我啟動(dòng)之前生成的,就認(rèn);如果是我啟動(dòng)以后才生成的,我就不認(rèn),我必須要找到它的上一個(gè)版本”。
當(dāng)然,如果“上一個(gè)版本”也不可見,那就得繼續(xù)往前找。還有,如果是這個(gè)事務(wù)自己更新的數(shù)據(jù),它自己還是要認(rèn)的。
在實(shí)現(xiàn)上, InnoDB 為每個(gè)事務(wù)構(gòu)造了一個(gè)數(shù)組,用來保存這個(gè)事務(wù)啟動(dòng)瞬間,當(dāng)前正在“活躍”的所有事務(wù) ID。“活躍”指的就是,啟動(dòng)了但還沒提交。
數(shù)組里面事務(wù) ID 的最小值記為低水位,當(dāng)前系統(tǒng)里面已經(jīng)創(chuàng)建過的事務(wù) ID 的最大值加 1 記為高水位。
這個(gè)視圖數(shù)組和高水位,就組成了當(dāng)前事務(wù)的一致性視圖(read-view)。
而數(shù)據(jù)版本的可見性規(guī)則,就是基于數(shù)據(jù)的 row trx_id 和這個(gè)一致性視圖的對(duì)比結(jié)果得到的。
這個(gè)視圖數(shù)組把所有的 row trx_id 分成了幾種不同的情況。

圖3
這樣,對(duì)于當(dāng)前事務(wù)的啟動(dòng)瞬間來說,一個(gè)數(shù)據(jù)版本的 row trx_id,有以下幾種可能:
如果落在綠色部分,表示這個(gè)版本是已提交的事務(wù)或者是當(dāng)前事務(wù)自己生成的,這個(gè)數(shù)據(jù)是可見的;
如果落在紅色部分,表示這個(gè)版本是由將來啟動(dòng)的事務(wù)生成的,是肯定不可見的;
如果落在黃色部分,那就包括兩種情況
若 row trx_id 在數(shù)組中,表示這個(gè)版本是由還沒提交的事務(wù)生成的,不可見;
若 row trx_id 不在數(shù)組中,表示這個(gè)版本是已經(jīng)提交了的事務(wù)生成的,可見。
比如,對(duì)于圖 2 中的數(shù)據(jù)來說,如果有一個(gè)事務(wù),它的低水位是 18,那么當(dāng)它訪問這一行數(shù)據(jù)時(shí),就會(huì)從 V4 通過 U3 計(jì)算出 V3,所以在它看來,這一行的值是 11。
六、當(dāng)前讀
更新數(shù)據(jù)時(shí),讀取最新的已提交數(shù)據(jù),包括update、insert、delete語句,以及加鎖的select語句
如果在更新語句時(shí),也按照一致性讀,會(huì)出現(xiàn)什么問題呢?
事務(wù)A | 事務(wù)B |
|---|---|
事務(wù)A先查詢一次,創(chuàng)建一個(gè)一致性試圖,然后再增加1,那么k應(yīng)該為2,這樣就造成事務(wù)B的更新被丟失了。
所以,這里就用到了這樣一條規(guī)則:更新數(shù)據(jù)都是先讀后寫的,而這個(gè)讀,只能讀當(dāng)前的值,稱為“當(dāng)前讀”(current read)。
因此,在更新的時(shí)候,當(dāng)前讀拿到的數(shù)據(jù)是事務(wù)B更新后的2,更新后生成了新版本的數(shù)據(jù) 3。在執(zhí)行事務(wù)A的查詢語句時(shí),查詢到的k值就應(yīng)該是3。
不僅僅是更新語句,加鎖的select語句也同樣使用“當(dāng)前讀”。
代碼塊SQL:
select * from table lock in share mode; -- 讀鎖,共享鎖select * from table for update; -- 寫鎖,排他鎖
接下來用一個(gè)實(shí)際的例子來說明一致性讀和當(dāng)前讀。
下邊是一個(gè)只有兩行數(shù)據(jù)的表
代碼塊SQL
CREATE TABLE `t` (`id` int(11) NOT NULL,`k` int(11) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB;insert into t(id, k) values(1,1),(2,2);
三個(gè)事務(wù)的執(zhí)行順序如下:
事務(wù)A(trx_id=100) | 事務(wù)B(trx_id=101) | 事務(wù)C(trx_id=102) |
|---|---|---|
在這三個(gè)事務(wù)中,事務(wù)A的查詢結(jié)果是1,事務(wù)B的查詢結(jié)果是3
下邊詳細(xì)解釋原因:
這里,我們不妨做如下假設(shè):
事務(wù) A 開始前,系統(tǒng)里面只有一個(gè)活躍事務(wù) ID 是 99;
事務(wù) A、B、C 的版本號(hào)分別是 100、101、102,且當(dāng)前系統(tǒng)里只有這四個(gè)事務(wù);
三個(gè)事務(wù)開始前,(1,1)這一行數(shù)據(jù)的 row trx_id 是 90。
這樣,事務(wù) A 的視圖數(shù)組就是[99,100], 事務(wù) B 的視圖數(shù)組是[99,100,101], 事務(wù) C 的視圖數(shù)組是[99,100,101,102]。
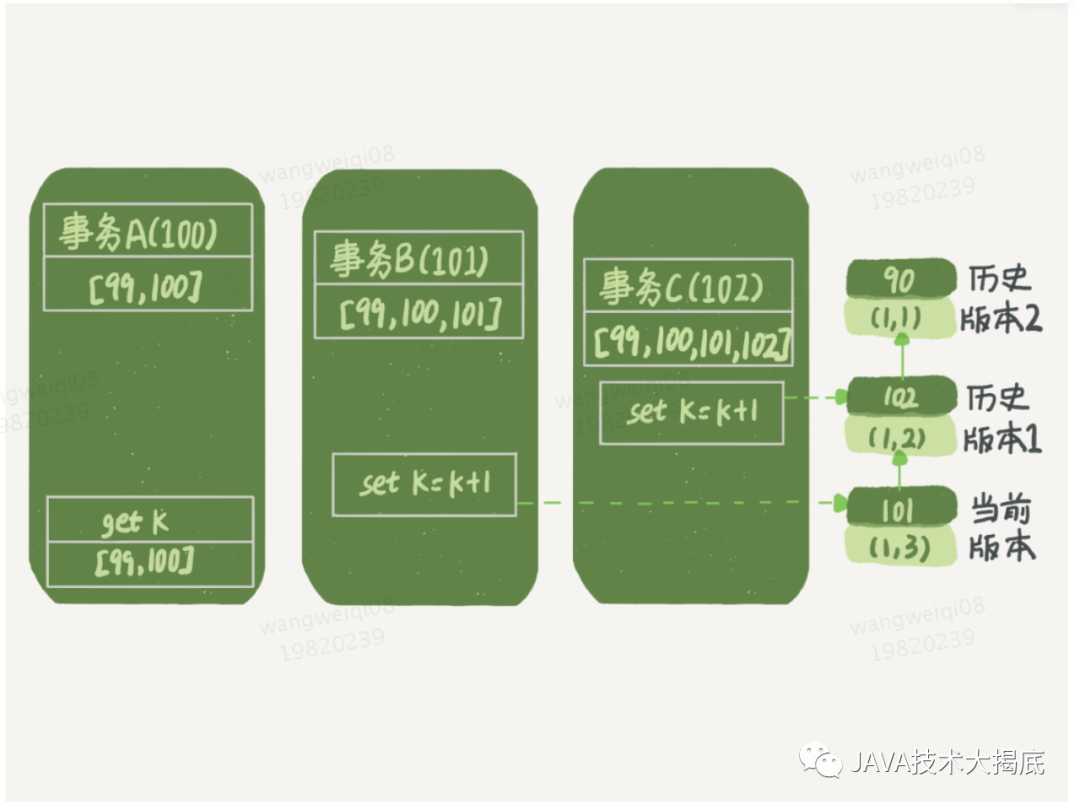
圖4
從圖中可以看到,第一個(gè)有效更新是事務(wù) C,把數(shù)據(jù)從 (1,1) 改成了 (1,2)。這時(shí)候,這個(gè)數(shù)據(jù)的最新版本的 row trx_id 是 102,而 90 這個(gè)版本已經(jīng)成為了歷史版本。
第二個(gè)有效更新是事務(wù) B,采用當(dāng)前讀,讀到最新的已提交數(shù)據(jù)是(1,2),把數(shù)據(jù)從 (1,2) 改成了 (1,3)。這時(shí)候,這個(gè)數(shù)據(jù)的最新版本(即 row trx_id)是 101,而 102 又成為了歷史版本。
在事務(wù) A 查詢的時(shí)候,其實(shí)事務(wù) B 還沒有提交,但是它生成的 (1,3) 這個(gè)版本已經(jīng)變成當(dāng)前版本了。但這個(gè)版本對(duì)事務(wù) A 必須是不可見的,否則就變成臟讀了。
現(xiàn)在事務(wù) A 要來讀數(shù)據(jù)了,它的視圖數(shù)組是[99,100],高水位101,低水位99。當(dāng)然了,讀數(shù)據(jù)都是從當(dāng)前版本讀起的。所以,事務(wù) A 查詢語句的讀數(shù)據(jù)流程是這樣的:
找到 (1,3) 的時(shí)候,判斷出 row trx_id=101,比高水位大,處于紅色區(qū)域,不可見;
接著,找到上一個(gè)歷史版本,一看 row trx_id=102,比高水位大,處于紅色區(qū)域,不可見;
再往前找,終于找到了(1,1),它的 row trx_id=90,比低水位小,處于綠色區(qū)域,可見。
這樣執(zhí)行下來,雖然期間這一行數(shù)據(jù)被修改過,但是事務(wù) A 不論在什么時(shí)候查詢,看到這行數(shù)據(jù)的結(jié)果都是一致的,所以我們稱之為一致性讀。
簡(jiǎn)單來說,可以總結(jié)為以下3個(gè)規(guī)則:
版本未提交,不可見;
版本已提交,但是是在視圖創(chuàng)建后提交的,不可見;
版本已提交,而且是在視圖創(chuàng)建前提交的,可見。