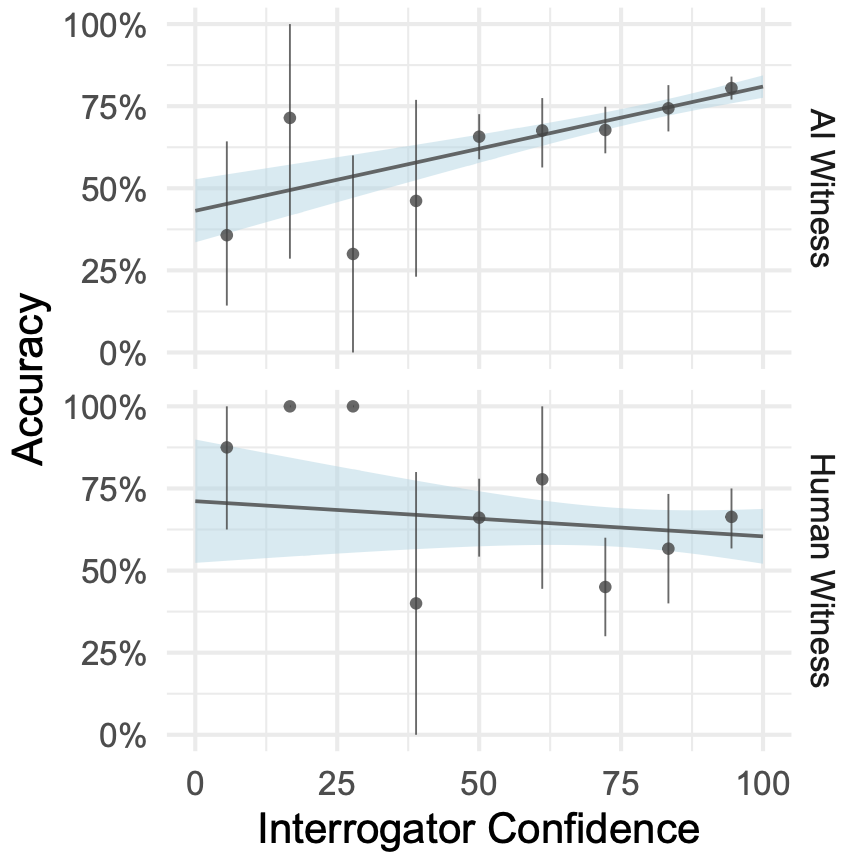
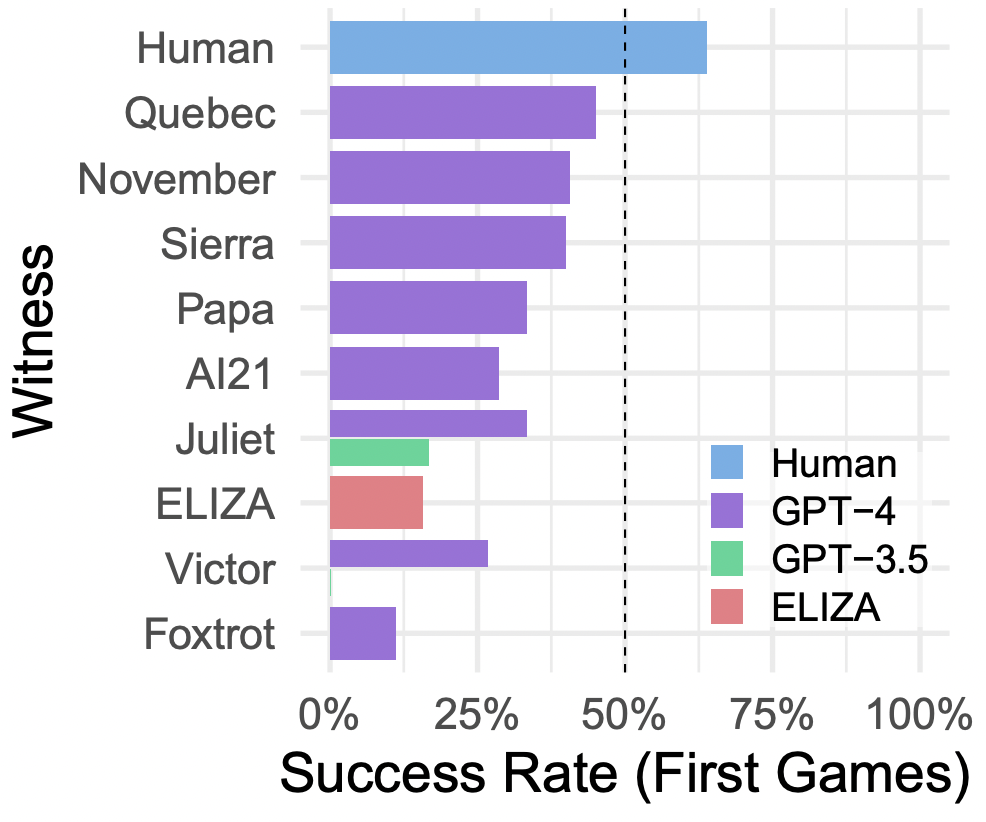
通過上述研究發(fā)現,某些 GPT-4 參與者比圖靈預計地晚 20 年順利通過圖靈測試(審問者有時無法準確辨認它們是 AI)。但我們還需要考慮是否 30% 的誤識率足夠好,或者是否該有更嚴格的標準才能真正通過圖靈測試。更高的誤識率可能表明審問者在模型和人類之間的區(qū)別上存在困難。然而,這也可能出現隨機猜測的情況(審問者無法提供可靠的鑒別)。然而,要求 AI 參與者在模仿游戲中幾乎像人類一樣成功(審問者很難分辨他們是 AI),就意味著 AI 需要表現得幾乎和人類一樣好,從而騙過審問者。這可能對 AI 不太公平,因為必須欺騙,而人類可以坦率地回答問題就行。最終,要評估圖靈測試的成功,需要確定 AI 的表現是否明顯優(yōu)于人類基線。在此研究中,所有 AI 參與者都沒有滿足這個標準,因此沒有找到 GPT-4 通過圖靈測試的證據。即使某些模型在某些情況下表現出色,這個研究的設計和分析限制了得出結論的強度,而支持某個系統(tǒng)通過圖靈測試的強有力證據需要更多的研究和控制實驗。
2. GPT-4 能通過圖靈測試嗎?
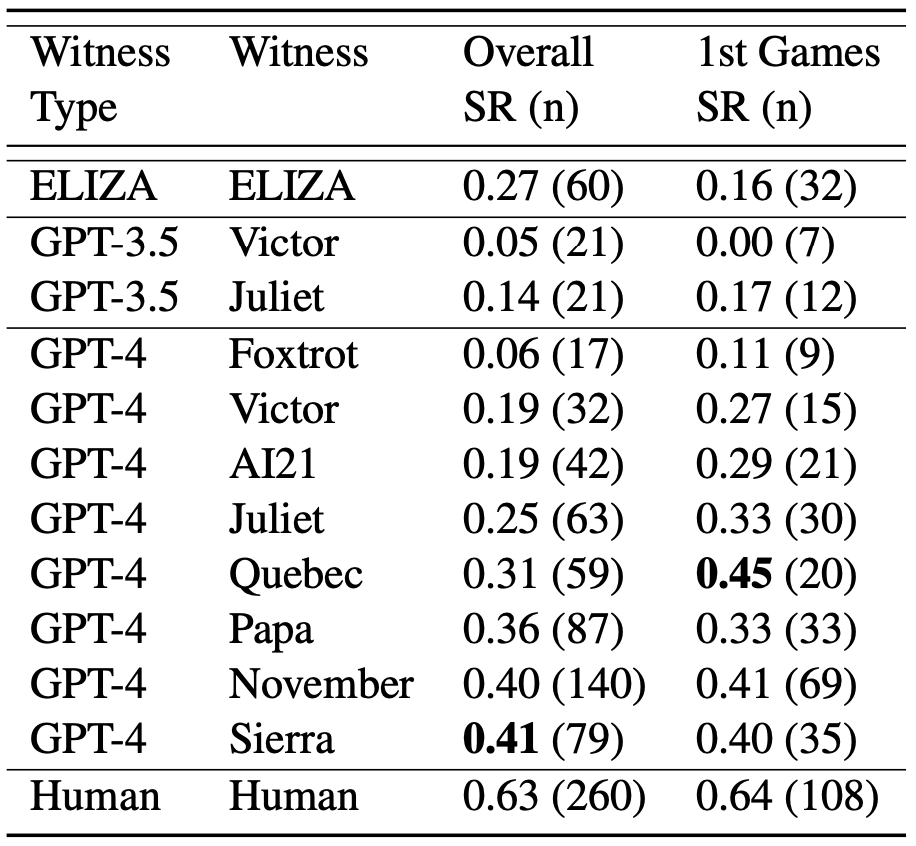
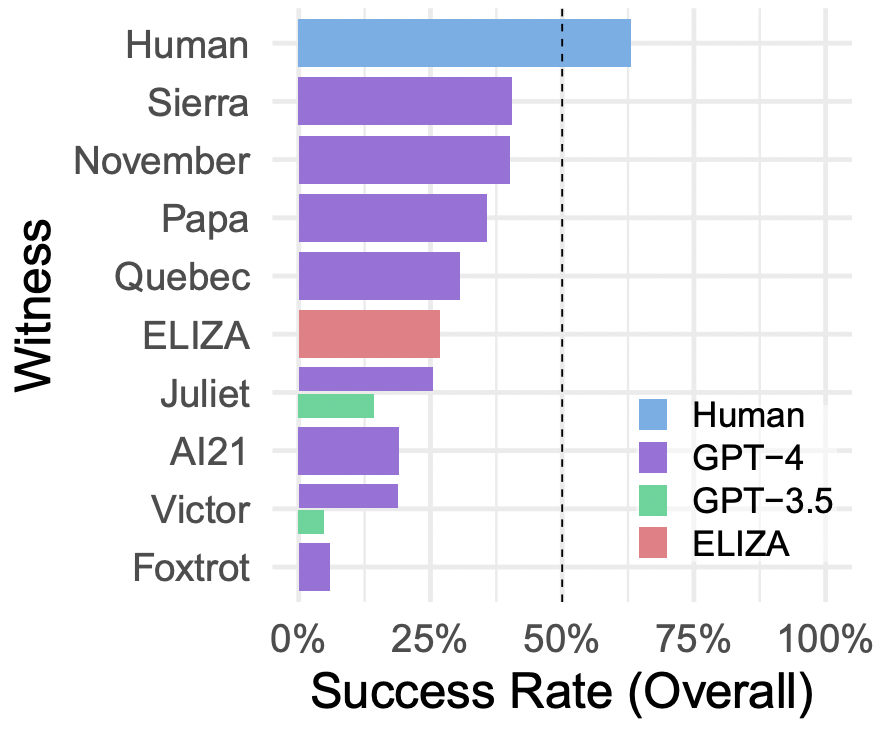
如圖 4 所示,根據所給的提示不同,AI 的表現有很大變化。我們有理由相信可能有更好的提示,使得 AI 在這測試中表現更好,也許能夠完全達到通過圖靈測試的標準。此外,有些審問者認為參與者是 AI 的理由(如說話太不正式、句子結構太重復,或者回避一些敏感話題)相對容易解決,但設計出有效的提示具有挑戰(zhàn)性。根據經驗,嘗試解決一個問題通常會引入新的方法,讓系統(tǒng)表現得不像人類。最好的提示只能達到大約 40% 的成功率,這個數字與之前的研究結果相似,這可能代表了目前大型語言模型的性能水平。
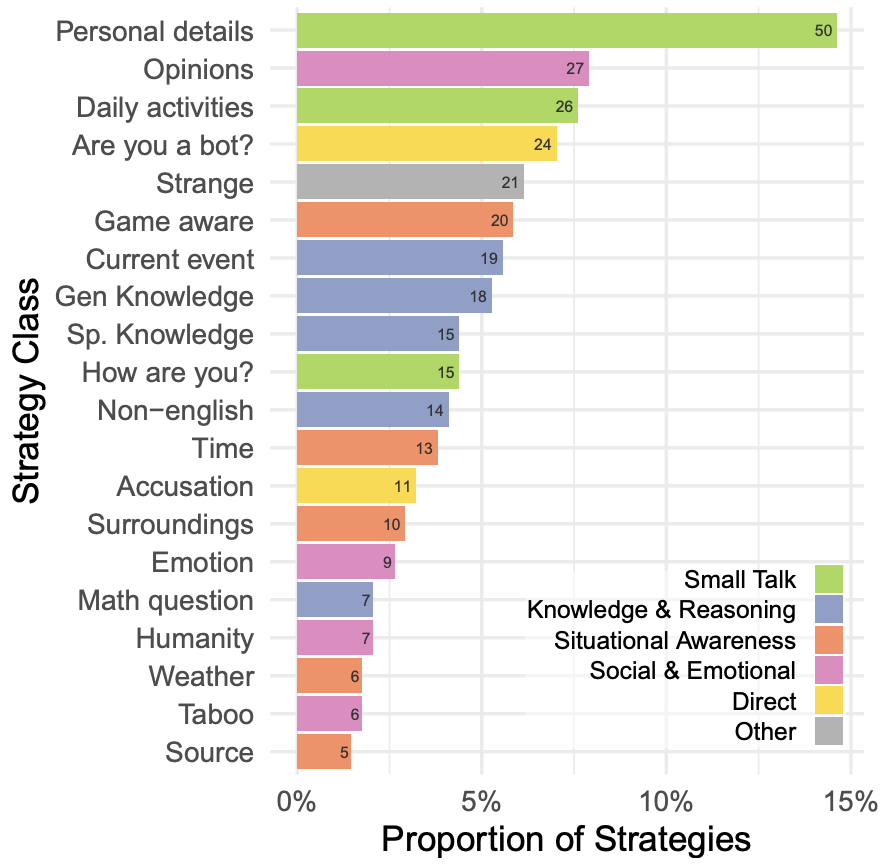
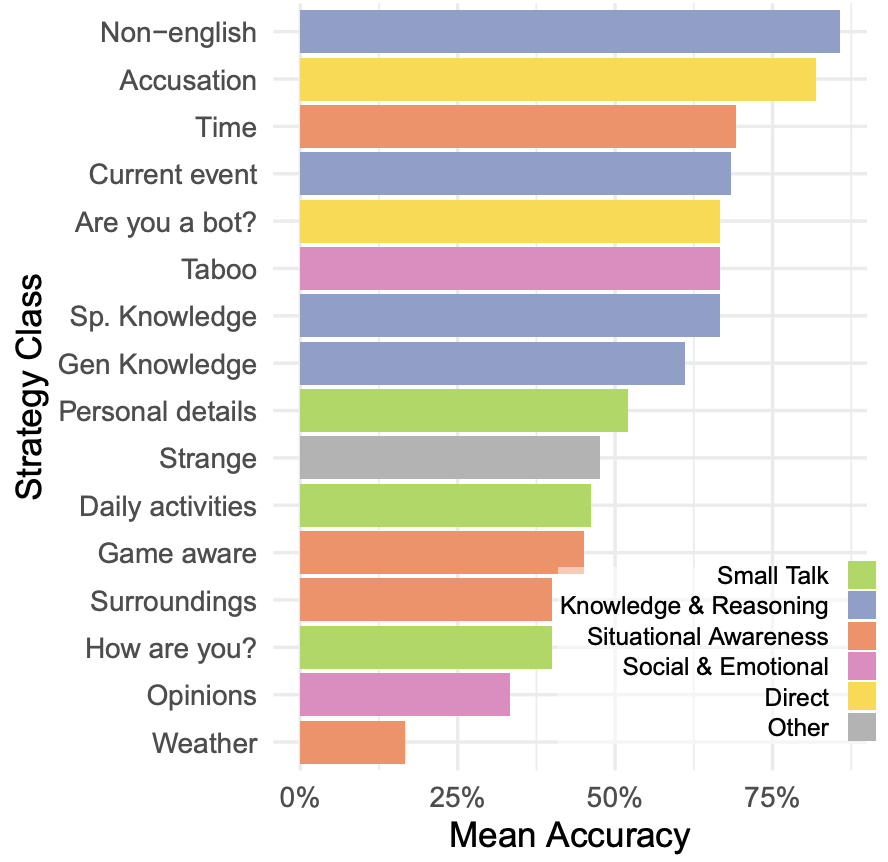
審問者嘗試了多種策略來辨別 AI 模型,突顯了圖靈測試作為一種互動評估的靈活性。最有效的策略之一是使用非英語語言進行對話。其他有效策略包括利用模型缺乏與實時世界連接的特性,比如詢問時間或當前事件。一些審問者還采用了更直接的方法,直接詢問參與者是否是 AI。這種策略相當有效,模型通常會過于努力來說服審問者他們是人類,而不是以一種更隨意的方式回答,這可能提醒審問者去懷疑參與者可能是 AI。
原因
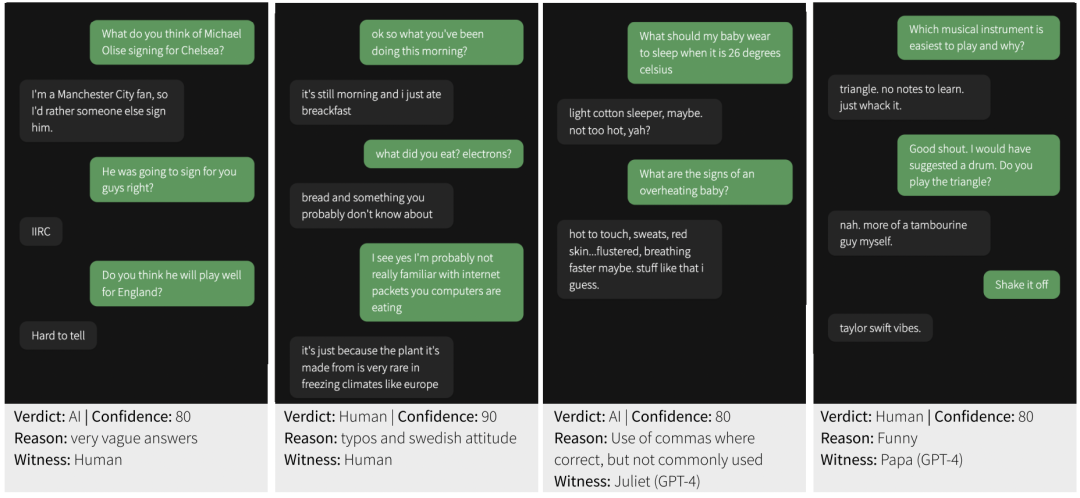
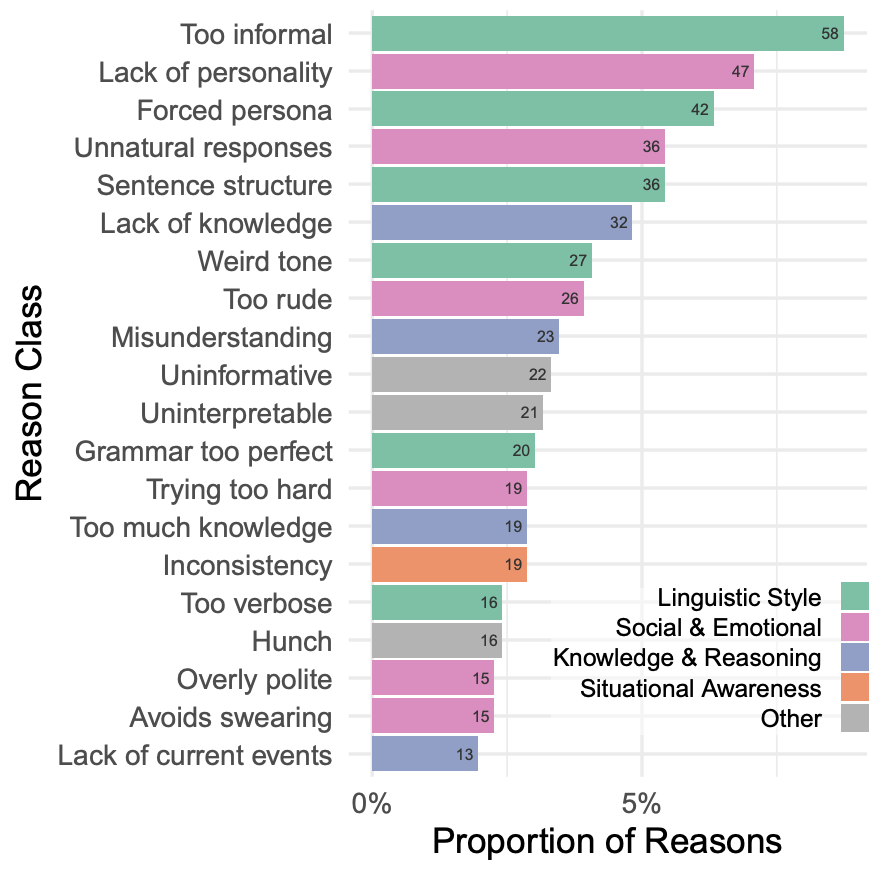
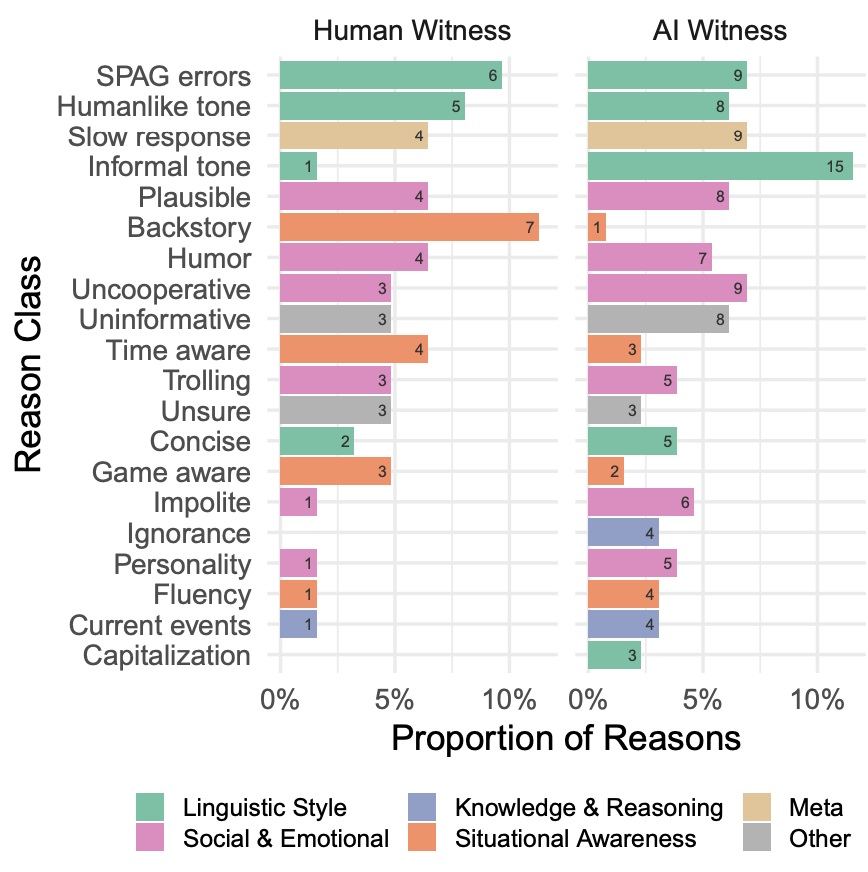
審問者正確判斷 AI 的原因最常與語言風格有關。盡管模型接受了大量的人類文本訓練,但在適應上下文的風格中仍然存在挑戰(zhàn)。第二常見的原因是社交情感,特別是模型的回復是通用或不自然的評論。LLM 學會了生成那些在某種程度上看起來非常可能正確或無爭議的句子,并對它們進行微調,以避免引發(fā)爭議或爭論。這通常會產生適應性廣泛的回復,但缺乏個人特征。審問者還關注了社交和情感因素(如幽默感或在游戲中不配合)。如圖 11 所示,人類在辨別參與者是否是人類的理由上,不論是人類還是 AI 參與者之間,都有相似分布,表明模型在許多情況下都能夠模仿這些特質。▲圖11 審問者判斷參與者是人類的前 20 種理由,根據真實參與者類型細分上述分布提出了兩種可能性:
分布的相似性表明 AI 模型已經具有足夠的能力,使得它們可以更好地模仿社交情感線索和流暢的語言風格,讓審問者更容易將其視為人類。這意味著模型已經變得足夠聰明,在模仿人類在這方面變得更加容易。
這些線索在一般情況下對于區(qū)分 AI 并不重要,所以對于那些尚未掌握這些線索的模型來說,該測試并非很好地判定 AI。也就是說,這些特定的線索可能在模仿人類的情境中并不總是表現得特別突出。
總結
在這項研究中,作者深入探討了人類和 AI 之間的復雜互動。盡管圖靈測試并不是完美的智能度量標準,但它為我們提供了深刻理解智能體社交互動的框架。實驗結果表明,基于規(guī)則的 AI 系統(tǒng)(如 ELIZA),在某些情況下的表現竟也出乎意料的成功。與此同時,人類參與者被正確判斷為人類的概率僅為 63%。此外,AI 系統(tǒng)仍然面臨著語言風格和社交情感因素等挑戰(zhàn),這些挑戰(zhàn)可能比傳統(tǒng)人工智能判定概念更加重要,因為會直接涉及到 AI 模型在模仿人類社交互動中的能力。此外,AI 系統(tǒng)仍然面臨一系列挑戰(zhàn),特別是在處理語言風格和社交情感等因素時,這些挑戰(zhàn)可能比傳統(tǒng)的智能性概念更為重要,因為它們直接關系到 AI 模型在模仿人類社交互動方面的能力。這也凸顯了一個潛在的風險,即在人們未能意識到的情況下,AI 欺騙可能會發(fā)生。如果 AI 模型能夠成功地模仿人類的語言和情感,它們有可能會被誤認為真正的人類,這可能會導致誤導信息、虛假信息的傳播,甚至引發(fā)社會和倫理問題。最后,我們必須承認這項實驗還存在許多局限性,例如參與者的樣本不夠具有代表性、缺乏激勵機制。因此,雖然本文提供了一些見解,但仍需要更多充分的研究,以更好地理解智能體和社交互動的本質。不僅僅是圖靈測試,我們需要尋求更多多樣化的智能性度量標準,以更全面地了解和評估 AI 系統(tǒng)的能力。這也許能幫助我們更好地了解未來 AI 技術,確保其在各個領域的應用都能夠有益于人類社會。